基于MADDPG的多無人機(jī)協(xié)同任務(wù)決策
2021-08-13 00:27:30越凱強(qiáng)甘志剛高佩忻
宇航學(xué)報(bào) 2021年6期
李 波,越凱強(qiáng),甘志剛,高佩忻
(西北工業(yè)大學(xué)電子信息學(xué)院,西安 710114)
0 引 言
近年來,無人機(jī)不但在房地產(chǎn)[1]、農(nóng)業(yè)[2]、安保[3]、搜索救援[4]、地面勘探[5]、特殊物流[6]等許多商業(yè)領(lǐng)域取得了不俗的成績[7],而且在軍事領(lǐng)域也大放異彩,出色的完成了許多有人駕駛飛機(jī)難以完成的任務(wù)。然而,單個(gè)無人機(jī)受其飛行距離、飛行范圍、彈載能力和應(yīng)對突發(fā)狀況能力的制約,難以發(fā)揮出其應(yīng)有的作戰(zhàn)效能。因此現(xiàn)有的研究都是基于多無人機(jī)系統(tǒng)[8]開展的,相比于單個(gè)無人機(jī),多無人機(jī)系統(tǒng)具有更強(qiáng)的作戰(zhàn)優(yōu)勢。對于多無人機(jī)系統(tǒng)而言,任務(wù)決策問題是重中之重,各國軍事專家都在為如何解決無人機(jī)的任務(wù)決策問題而不斷努力。
各國學(xué)者對于多無人機(jī)任務(wù)決策的研究都在如火如荼的進(jìn)行,在多無人機(jī)協(xié)同搜索[9]、跟蹤[10]、任務(wù)分配[11-12]、航跡規(guī)劃[13]和編隊(duì)控制[14]等研究中,都已取得了不俗的成果。同時(shí),深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)的快速發(fā)展,也極大地加快了無人機(jī)系統(tǒng)智能化[15]的發(fā)展進(jìn)程。賴俊和饒瑞[16]提出了一種基于空間位置標(biāo)注的好奇心驅(qū)動的深度強(qiáng)化學(xué)習(xí)方法,解決了室內(nèi)無人機(jī)隨機(jī)目標(biāo)搜索效率不高、準(zhǔn)確率低等問題。Xu等[17]設(shè)計(jì)了一種新型仿生變形無人機(jī)模型,并采用了深度確定性策略梯度(Deep deterministic policy gradient,DDPG)算法作為仿生變形無人機(jī)的控制策略,可以使無人機(jī)在不同任務(wù)和飛行條件下完成快速的自主變形和空氣動力學(xué)性能優(yōu)化。王濤等[18]提出了一種基于強(qiáng)化學(xué)習(xí)方法暨模糊Q學(xué)習(xí)的多約束條件下自主導(dǎo)航控制算法,提高了復(fù)雜環(huán)境下無人機(jī)器人自主導(dǎo)航控制系統(tǒng)的自適應(yīng)性和魯棒性,通過對非完整性約束移動機(jī)器人運(yùn)動模型的仿真,證明了該算法具有可移植性和通用性,可應(yīng)用于無人機(jī)的空中躲避和攔截。Zhu等[19]以深度學(xué)習(xí)中的行動家-評論家(Actor-Critic)架構(gòu)為基礎(chǔ),并結(jié)合預(yù)訓(xùn)練的ResNet網(wǎng)絡(luò),完成了無人機(jī)在離散3D環(huán)境中進(jìn)行自主導(dǎo)航到達(dá)目的地的任務(wù)。
結(jié)合現(xiàn)有的研究成果進(jìn)行分析可以發(fā)現(xiàn),現(xiàn)有研究的不足有以下幾點(diǎn):
1) 大部分基于強(qiáng)化學(xué)習(xí)的無人機(jī)問題的研究都是針對靜態(tài)任務(wù)展開的,且以DDPG為代表的智能算法具有學(xué)習(xí)和收斂速度慢,精度不高的缺陷。
2)相比于單架無人機(jī),多無人機(jī)的相關(guān)問題研究過少。現(xiàn)在多數(shù)的多無人機(jī)協(xié)同任務(wù)決策依然使用DDPG算法[20],傳統(tǒng)DDPG等智能算法在單架無人機(jī)相關(guān)領(lǐng)域表現(xiàn)優(yōu)異,但是在多無人機(jī)環(huán)境下,由于涉及到的智能體數(shù)量多且復(fù)雜,收斂速度慢和精度不高的缺陷被放大,且隨著無人機(jī)數(shù)量的增多,其適用能力下降。
2017年,多智能體深度確定性策略梯度(Multi-agent deep deterministic policy gradient,MADDPG)算法由OpenAI發(fā)表于NIPS,主要應(yīng)用于多智能體的協(xié)同圍捕、競爭[21-23]等場景,但MADDPG算法在多無人機(jī)協(xié)同任務(wù)決策作戰(zhàn)應(yīng)用中,特別是作戰(zhàn)環(huán)境未知的情況下存在空白。為提高多無人機(jī)協(xié)同任務(wù)決策作戰(zhàn)能力,本文提出了將深度強(qiáng)化學(xué)習(xí)中的MADDPG算法引入到多無人機(jī)系統(tǒng)中,設(shè)計(jì)一種能夠符合多無人機(jī)系統(tǒng)特點(diǎn)的任務(wù)決策方法。
1 無人機(jī)任務(wù)決策與數(shù)學(xué)建模
1.1 任務(wù)決策分類
在解決多無人機(jī)任務(wù)決策問題時(shí),首先要考慮戰(zhàn)場環(huán)境的特殊背景。戰(zhàn)場環(huán)境的多變性在一定程度上決定了任務(wù)決策的方法和難度。根據(jù)對戰(zhàn)場環(huán)境的理解狀況,可以將任務(wù)決策分為以下幾種情況。任務(wù)決策分類如圖1所示。
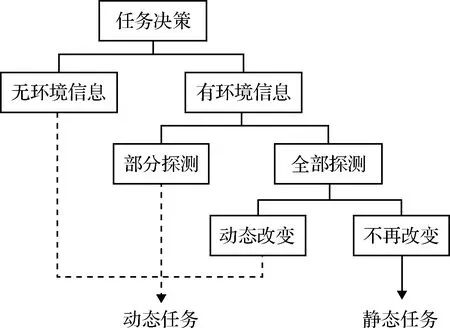
圖1 任務(wù)決策分類Fig.1 Task decision classification
1)在開始任務(wù)之前已經(jīng)掌握所有的戰(zhàn)場環(huán)境。目標(biāo)位置和戰(zhàn)場中的防空雷達(dá)、防空導(dǎo)彈等一系列威脅區(qū)域均已被提前探測到,并且在無人機(jī)執(zhí)行任務(wù)過程中不再發(fā)生改變,這一類戰(zhàn)場情況對于無人機(jī)任務(wù)決策來說是最簡單的,同時(shí)也是目前研究最為成熟的。只需要在任務(wù)開始執(zhí)行之前,運(yùn)用相關(guān)算法規(guī)劃出最為合理且高效的航路,給無人機(jī)分配目標(biāo)等任務(wù)信息,并加載給無人機(jī),無人機(jī)就能夠按照預(yù)定任務(wù)決策方案完成作戰(zhàn)任務(wù)。
2)在任務(wù)開始前,只知道目標(biāo)的位置,但是對作戰(zhàn)區(qū)域的具體火力和威脅情況并未全部探測到或者只探測到一部分。這時(shí)就需要無人機(jī)一邊執(zhí)行任務(wù)一邊進(jìn)行探測,在執(zhí)行任務(wù)的過程中對航路進(jìn)行再規(guī)劃,必要時(shí)對目標(biāo)進(jìn)行重分配。
3)還有一種情況更為復(fù)雜,目標(biāo)區(qū)域的情況并未全部探測到,而且目標(biāo)的位置也不是固定的,會隨著時(shí)間移動。這是一種動態(tài)的戰(zhàn)場環(huán)境,這種環(huán)境對無人機(jī)的智能化有著極高的挑戰(zhàn),需要無人機(jī)在復(fù)雜多變的環(huán)境中協(xié)同作戰(zhàn),動態(tài)實(shí)現(xiàn)規(guī)劃航路以及目標(biāo)任務(wù)分配,這也是最為復(fù)雜且最為困難的情況。
本文主要針對第二類情況做出任務(wù)決策,即目標(biāo)和威脅源位置只進(jìn)行一次初始化且均固定不變,作戰(zhàn)區(qū)域的具體火力和威脅情況并未探測到。
1.2 無人機(jī)模型和威脅模型
1.2.1無人機(jī)建模
由于多無人機(jī)任務(wù)決策問題本身就具有高維度、高復(fù)雜性的特點(diǎn),所以為簡化研究問題,做出假設(shè):認(rèn)為多無人機(jī)為同構(gòu)機(jī)型,具有相同的物理特性,并且在研究過程中不考慮無人機(jī)的形狀大小等物理特性,將無人機(jī)簡化為質(zhì)心運(yùn)動。則無人機(jī)質(zhì)點(diǎn)在二維空間的簡化運(yùn)動模型定義為:
(1)

無人機(jī)在飛行過程中,由于慣性原因無法毫無約束的進(jìn)行飛行轉(zhuǎn)彎,在進(jìn)行轉(zhuǎn)彎飛行時(shí)會有一個(gè)最小轉(zhuǎn)彎半徑Rmin。如果航跡決策中的轉(zhuǎn)彎半徑Ruav小于無人機(jī)的最小轉(zhuǎn)彎半徑,則實(shí)際環(huán)境中無人機(jī)無法完成此動作決策。
1.2.2威脅建模
無人機(jī)在執(zhí)行任務(wù)時(shí),不但會遭遇來自地形和自然氣候的威脅,而且還會遭遇來自敵方防空雷達(dá)、防空導(dǎo)彈等一系列防御措施的威脅,將這一系列對無人機(jī)安全能夠造成危險(xiǎn)的事物稱為無人機(jī)威脅源。一般情況下,將無人機(jī)威脅分為自然威脅和軍事威脅。本文在無人機(jī)攻擊任務(wù)決策時(shí),將環(huán)境因素理想化,忽略來自環(huán)境對無人機(jī)的威脅,主要考慮無人機(jī)的軍事威脅,并且軍事威脅以敵方雷達(dá)威脅和導(dǎo)彈威脅為主要威脅源。
雷達(dá)威脅主要是指無人機(jī)在敵方空域飛行時(shí),能夠探測并且對無人機(jī)造成影響的防空雷達(dá)。本文假設(shè)敵方防空雷達(dá)的探測范圍是360度,在二維空間環(huán)境中等效為以雷達(dá)位置為中心,雷達(dá)水平方向探測最遠(yuǎn)距離Rmax為半徑的圓周,定義為:
(2)
因此雷達(dá)威脅的數(shù)學(xué)模型為:
(3)
式中:UR是無人機(jī)當(dāng)前位置與雷達(dá)位置的相對距離。
導(dǎo)彈威脅主要是指可以影響無人機(jī)正常飛行的防空導(dǎo)彈。和雷達(dá)威脅相同,導(dǎo)彈威脅在二維空間環(huán)境中也可以等效為圓周。但是不同的是,無人機(jī)與導(dǎo)彈的距離越近越容易被擊中,無人機(jī)被擊中的概率與無人機(jī)和導(dǎo)彈的距離成一定比例,因此導(dǎo)彈威脅數(shù)學(xué)模型如式(4)所示。
(4)
其中:UR是無人機(jī)當(dāng)前位置與導(dǎo)彈位置的距離;dMmax為導(dǎo)彈所能攻擊的最遠(yuǎn)距離,dMmin為導(dǎo)彈攻擊允許的最近距離,一旦無人機(jī)與導(dǎo)彈的距離小于dMmin,則無人機(jī)一定會被擊中。
無人機(jī)執(zhí)行任務(wù)過程中,無論是靜態(tài)任務(wù)還是動態(tài)任務(wù)都需要通過機(jī)載雷達(dá)設(shè)施對任務(wù)區(qū)域進(jìn)行探測,以確定防空導(dǎo)彈等無人機(jī)威脅源的位置信息或者確保能夠及時(shí)探測到突發(fā)威脅源的狀況。這種探測行為可以更好的決策飛機(jī)的機(jī)動動作,規(guī)避危險(xiǎn),提高無人機(jī)的存活率。在無人機(jī)飛行探測過程中,將以機(jī)載雷達(dá)最大探測距離作為探測范圍。
2 基于MADDPG的多無人機(jī)任務(wù)決策問題研究
2.1 DDPG算法
DDPG算法是Actor-Critic框架和DQN(Deep Q network)算法的結(jié)合體,解決了DQN算法收斂困難的問題。根據(jù)DDPG算法的特點(diǎn)可以將其分為D(Deep)和DPG(Deterministic policy gradient)兩個(gè)部分。其中第一部分的D是指DDPG算法具有更深層次的網(wǎng)絡(luò)結(jié)構(gòu),該算法繼承了DQN中經(jīng)驗(yàn)池和雙層網(wǎng)絡(luò)的結(jié)構(gòu),能夠更有效的提高神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)效率。第二部分的DPG是指DDPG算法采用了確定性策略,Actor不再輸出每個(gè)動作的概率,而是一個(gè)具體的動作。相比隨機(jī)性策略,DPG大大減少了算法的采樣數(shù)據(jù)量,提高了算法的效率,更有助于網(wǎng)絡(luò)在連續(xù)動作空間中的學(xué)習(xí)。
DDPG算法從網(wǎng)絡(luò)結(jié)構(gòu)上來說應(yīng)用了Actor-Critic的框架形式,所以具有兩個(gè)網(wǎng)絡(luò):行動家(Actor)網(wǎng)絡(luò)和評論家(Critic)網(wǎng)絡(luò)。同時(shí),Actor和Critic也都具備雙網(wǎng)絡(luò)結(jié)構(gòu),擁有各自的目標(biāo)(Target)網(wǎng)絡(luò)和估計(jì)(Eval)網(wǎng)絡(luò)。DDPG的網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示。
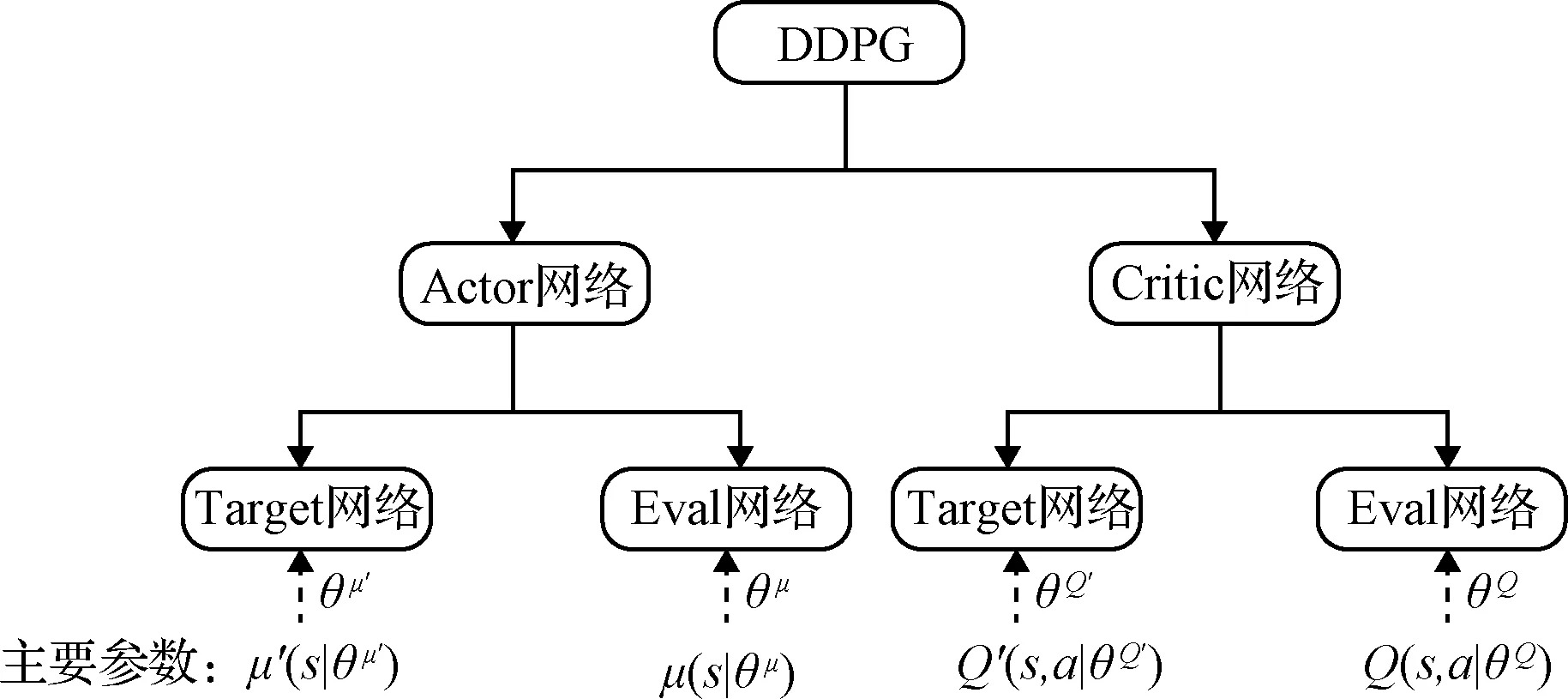
圖2 DDPG的網(wǎng)絡(luò)結(jié)構(gòu)Fig.2 Network structure of DDPG
2.2 MADDPG算法模型
在多無人機(jī)的環(huán)境當(dāng)中,傳統(tǒng)的強(qiáng)化學(xué)習(xí)算法受到極大的挑戰(zhàn)。在多無人機(jī)系統(tǒng)中每一個(gè)無人機(jī)都是獨(dú)立的智能體,都需要不斷的學(xué)習(xí)來達(dá)到改進(jìn)其策略的目的。這樣就導(dǎo)致從每一個(gè)無人機(jī)的角度來看,環(huán)境從靜態(tài)轉(zhuǎn)變?yōu)閯討B(tài)。這與傳統(tǒng)強(qiáng)化學(xué)習(xí)收斂的條件大不相同,在一定程度上導(dǎo)致無法僅僅通過改變單個(gè)智能體自身的策略來適應(yīng)不穩(wěn)定的環(huán)境,并且傳統(tǒng)策略梯度算法中方差大的問題會因?yàn)橹悄荏w數(shù)量的增多而被放大。而MADDPG算法就是針對這類問題而提出的一種基于多智能體環(huán)境的強(qiáng)化學(xué)習(xí)算法。
MADDPG算法基于Actor-Critic和DDPG進(jìn)行了一系列的改進(jìn),并且采用集中式學(xué)習(xí)和分布式應(yīng)用的原理,使其能夠適用于傳統(tǒng)強(qiáng)化學(xué)習(xí)算法無法處理的復(fù)雜多智能體環(huán)境。傳統(tǒng)強(qiáng)化學(xué)習(xí)算法在學(xué)習(xí)和應(yīng)用時(shí)都必須使用相同的信息數(shù)據(jù),而MADDPG算法允許在學(xué)習(xí)時(shí)使用一些額外的信息(即全局信息),但是在應(yīng)用決策的時(shí)候只使用局部信息。相對于傳統(tǒng)Actor-Critic算法,MADDPG算法環(huán)境中共有M個(gè)智能體,第i個(gè)智能體的策略用πi表示,且其策略參數(shù)為θi,則可以得到M個(gè)智能體的策略集為π=π1,π2,…,πM,策略參數(shù)集合為θ=θ1,θ2,…,θM。第i個(gè)智能體的累計(jì)期望收益為:
(5)
其中:ri表示第i個(gè)智能體的獎(jiǎng)勵(lì)。
則針對隨機(jī)策略,可以得到策略梯度公式為:
(6)

P(s′|s,a1,…,aM,π1,…,πM)=P(s′|s,a1,…,
aM)=P(s′|s,a1,…,aM,π′1,…,π′M)
(7)
同樣可以將AC算法延伸到確定性策略μθi上,其回報(bào)期望梯度為:
(8)

(9)
其中,y由式(10)得到:
(10)
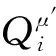
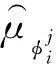
(11)
只要最小化上述代價(jià)函數(shù),就能得到其他智能體策略的逼近。因此y可變?yōu)椋?/p>
(12)

算法整體框架圖如圖3所示,根據(jù)算法整體框架圖可知,針對單個(gè)智能體,首先將其狀態(tài)輸入到自身的策略網(wǎng)絡(luò)當(dāng)中,得到一個(gè)動作后輸出并作用于環(huán)境中,此時(shí)會得到一個(gè)新的狀態(tài)和回報(bào)值,最后將狀態(tài)轉(zhuǎn)移數(shù)據(jù)存入到智能體自身的經(jīng)驗(yàn)池當(dāng)中。所有智能體都會和環(huán)境進(jìn)行不斷的交互,不斷的產(chǎn)生數(shù)據(jù)并存儲到各自的經(jīng)驗(yàn)池當(dāng)中。
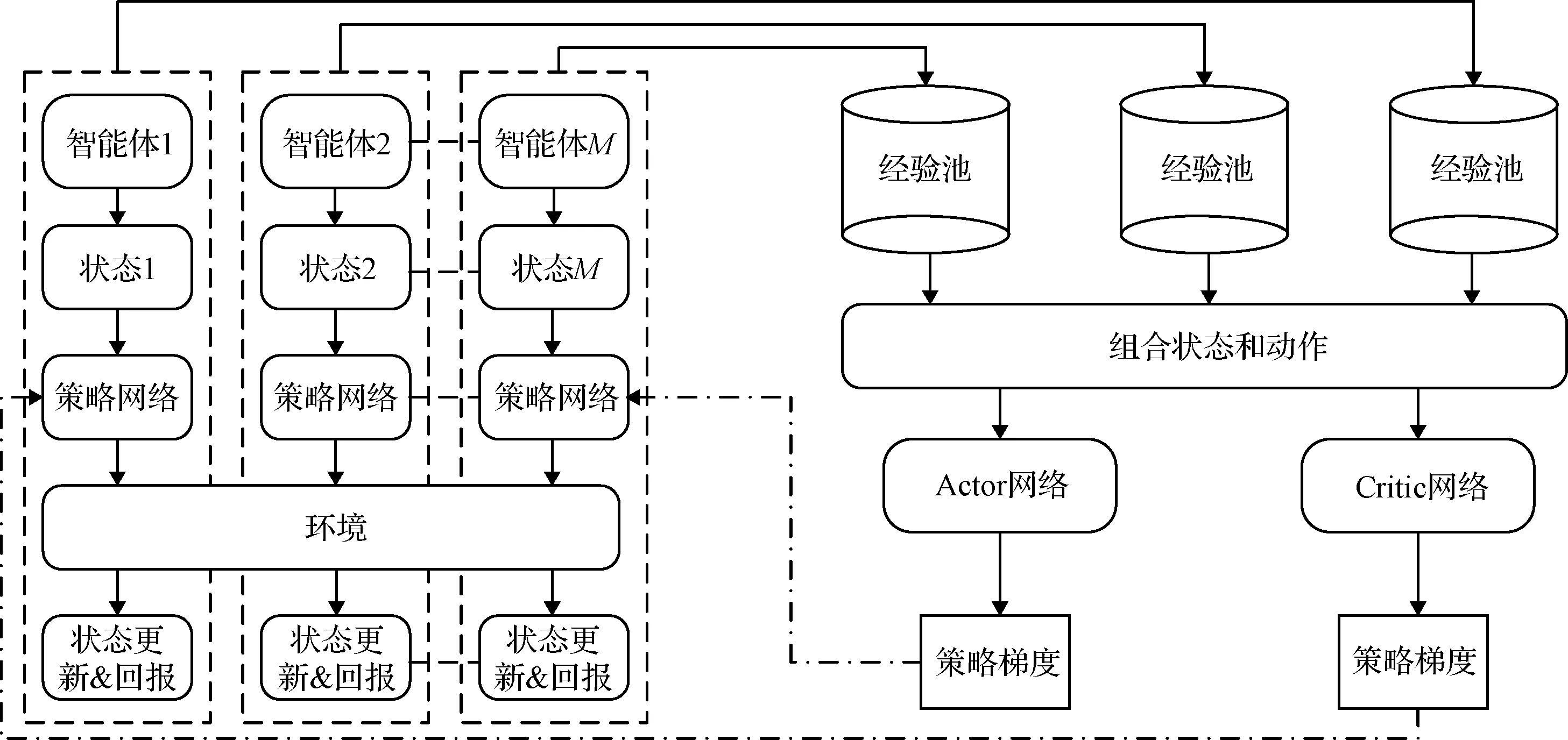
圖3 MADDPG算法框架Fig.3 Algorithm framework of MADDPG
在更新網(wǎng)絡(luò)的過程中,隨機(jī)從每個(gè)智能體的經(jīng)驗(yàn)池中取出同樣時(shí)刻的一批數(shù)據(jù),并將其拼接得到新的經(jīng)驗(yàn)
yi=ri+γQ′(si+1,μ′(si+1|Qμ′)|θQ′)
(13)
實(shí)際的Q值通過使用評價(jià)網(wǎng)絡(luò)得到,再利用TD偏差[24]來更新評價(jià)網(wǎng)絡(luò),用Q值的策略梯度來更新策略網(wǎng)絡(luò)。所有智能體依照相同的方法來更新自身的網(wǎng)絡(luò),只是每一個(gè)智能體的輸入有所差別,而在其它方面的更新流程相同。策略網(wǎng)絡(luò)與價(jià)值網(wǎng)絡(luò)的具體結(jié)構(gòu)如圖4所示。

圖4 網(wǎng)絡(luò)結(jié)構(gòu)Fig.4 Network structure
2.3 多無人機(jī)任務(wù)決策算法模型設(shè)計(jì)
本文主要基于二維平面環(huán)境開展研究,共有k架無人機(jī)分別為: UAV1,UAV2,…,UAVk。其中每一架無人機(jī)自身狀態(tài)Suavi包含當(dāng)前時(shí)刻的速度矢量(vuavi,x,vuavi,y)和在環(huán)境中的坐標(biāo)位置(puavi,x,puavi,y)。環(huán)境狀態(tài)Senv包含了環(huán)境中N個(gè)威脅區(qū)的坐標(biāo)位置、威脅半徑和M個(gè)目標(biāo)的坐標(biāo)位置。其中第i個(gè)威脅區(qū)的坐標(biāo)位置和威脅半徑分別表示為(Wi,x,Wi,y)和i,y,第i個(gè)目標(biāo)在環(huán)境中的坐標(biāo)位置可以表示為(Mi,x,Mi,y)。
在MADDPG算法中,每一架無人機(jī)的狀態(tài)包括了自身的狀態(tài)、其它無人機(jī)的狀態(tài)和環(huán)境狀態(tài)。針對無人機(jī)UAV1在t時(shí)刻的狀態(tài)定義為:
St,uav1=(Suav1,Suav2,…,Suavk,Senv)
(14)
最終每架飛機(jī)在t時(shí)刻的狀態(tài)定義為:
St,uavi=(vuav1,x,vuav1,y,puav1,x,puav1,y,…,
vuavk,x,vuavk,y,puavk,x,puavk,y,
Wi,x,Wi,y,i,y,Mi,x,Mi,y)
(15)
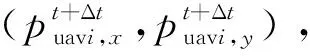
(16)
并且,無人機(jī)的動作輸出,受到最小轉(zhuǎn)彎半徑的約束,如果不符合約束條件,則被視為不合理動作輸出,需要進(jìn)行重新選擇。
本文主要從以下三個(gè)方面來設(shè)計(jì)獎(jiǎng)勵(lì)函數(shù)。
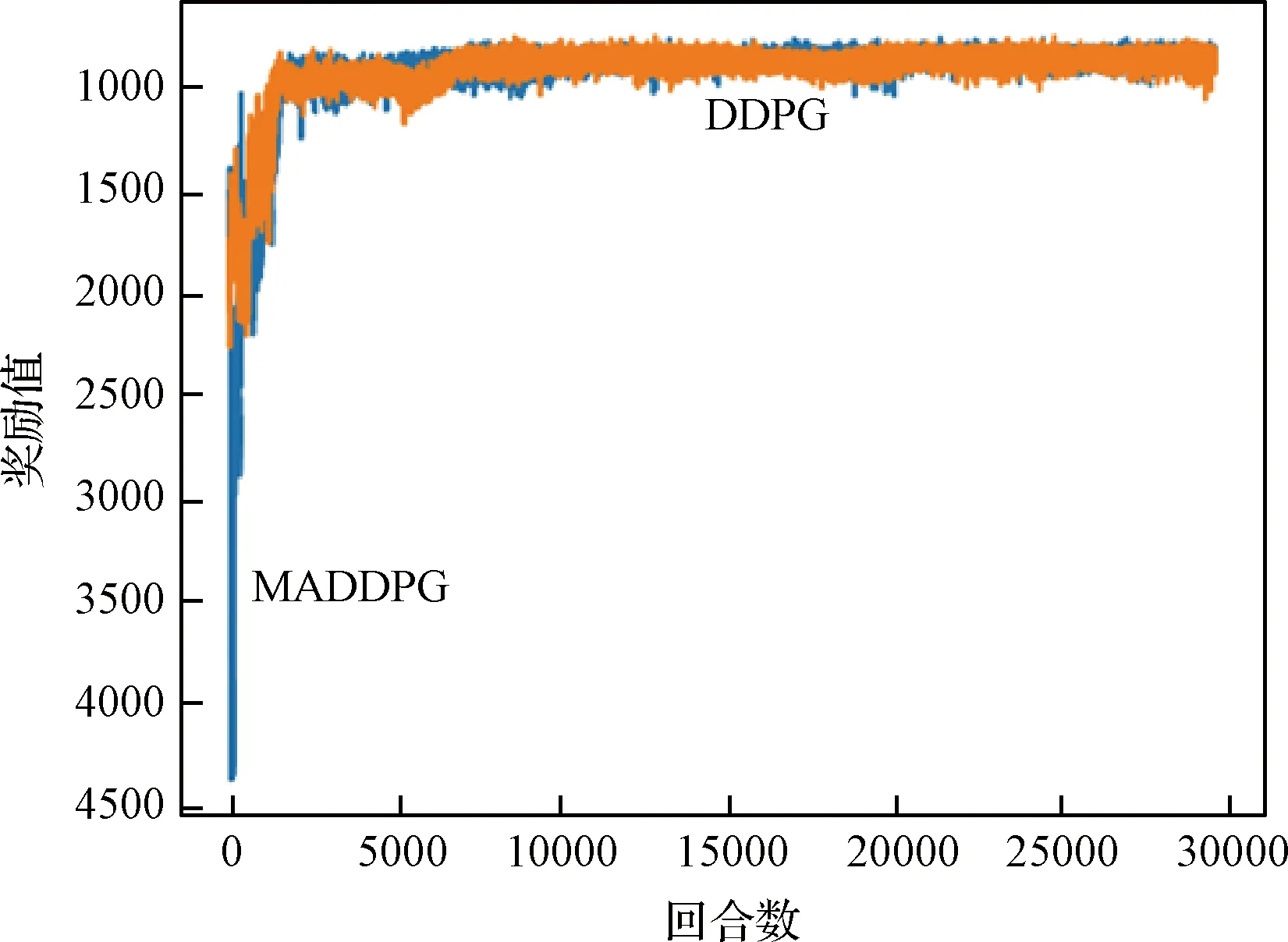
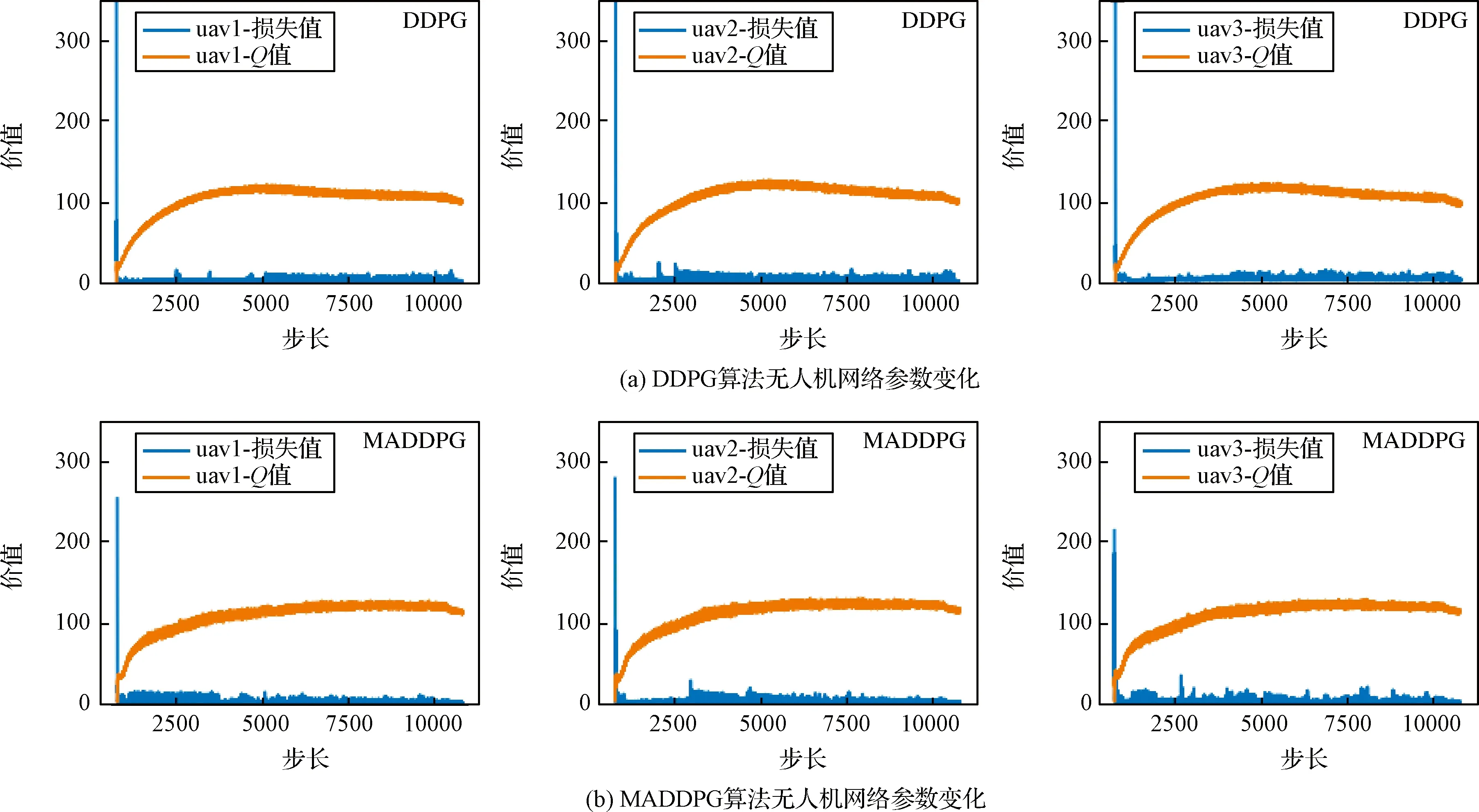
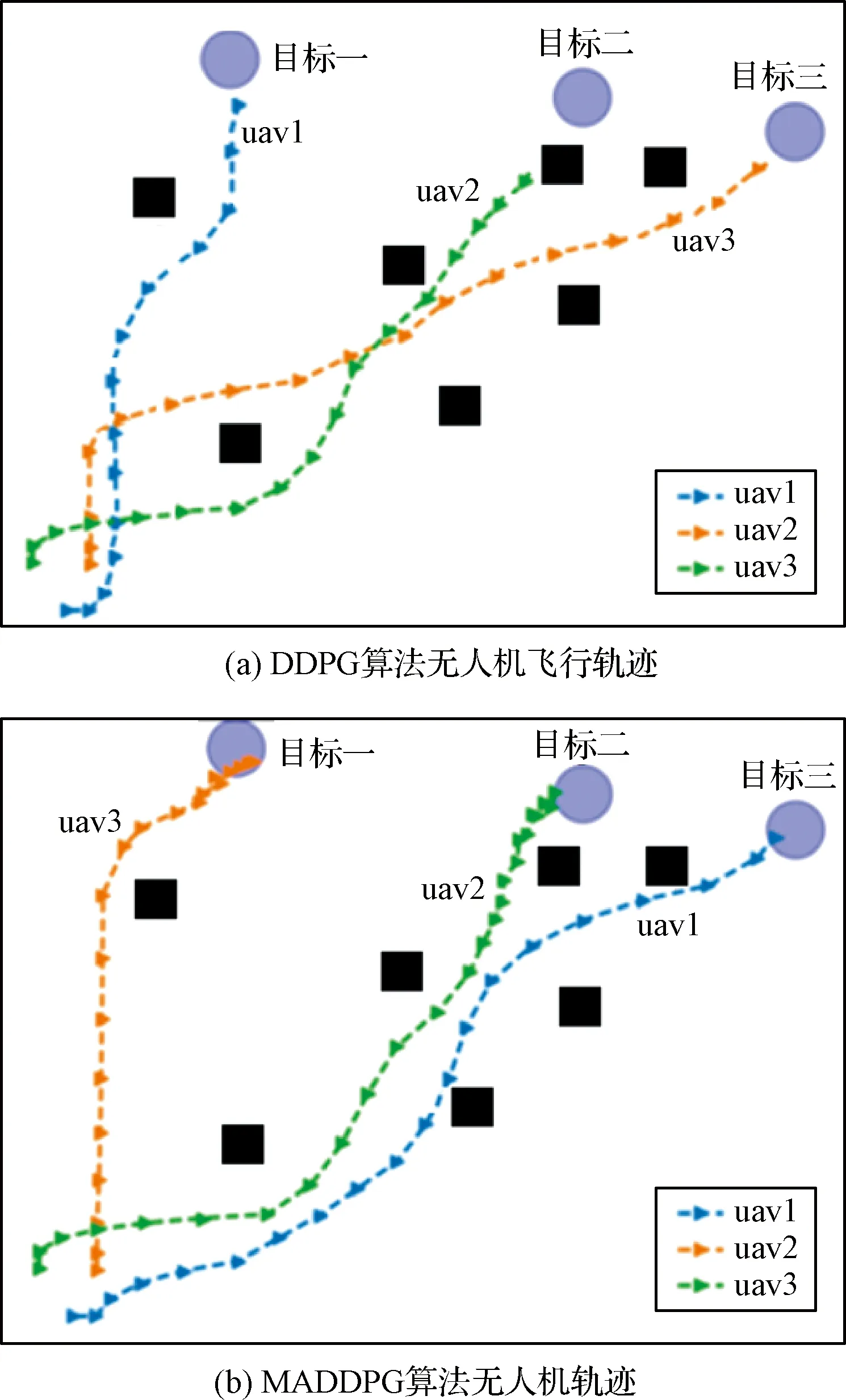
1)針對躲避威脅區(qū)設(shè)定一個(gè)威脅獎(jiǎng)勵(lì),當(dāng)無人機(jī)進(jìn)入威脅區(qū)后,會被給予一個(gè)負(fù)獎(jiǎng)勵(lì)。即Rf=-1,(DW 2)在無人機(jī)的飛行過程中,每一架無人機(jī)都應(yīng)和其它無人機(jī)保持安全距離,一旦無人機(jī)的位置過近,就會互相產(chǎn)生飛行威脅甚至發(fā)生碰撞,所以為了避免無人機(jī)發(fā)生碰撞,應(yīng)當(dāng)設(shè)定一個(gè)碰撞獎(jiǎng)勵(lì)Rp,當(dāng)無人機(jī)間的距離小于安全距離時(shí),就會給予其負(fù)獎(jiǎng)勵(lì)。即Rp=-1,(Ddij 3)為了在開始訓(xùn)練時(shí),能夠準(zhǔn)確的引導(dǎo)無人機(jī)的動作選擇,并且讓無人機(jī)每一步都擁有一個(gè)密集獎(jiǎng)勵(lì),在這里設(shè)計(jì)了一個(gè)距離獎(jiǎng)勵(lì)Rr,計(jì)算每一時(shí)刻,無人機(jī)與目標(biāo)的最近距離,以距離的負(fù)值作為獎(jiǎng)勵(lì)值,距離越近,獎(jiǎng)勵(lì)值越大。即Rr=-dmin,其中dmin是各個(gè)目標(biāo)和各架無人機(jī)之間最小距離的和。 最終無人機(jī)的獎(jiǎng)勵(lì)函數(shù)設(shè)計(jì)為: Ri=Rf+Rp+Rr (17) 本文設(shè)計(jì)了MADDPG算法模型,采用了確定性動作策略,即a=πθ(s)。網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)為:策略網(wǎng)絡(luò)結(jié)構(gòu)為[39;56;56;2]的全連接神經(jīng)網(wǎng)絡(luò);價(jià)值網(wǎng)絡(luò)的結(jié)構(gòu)是[123;118;78;36;1]的全連接神經(jīng)網(wǎng)絡(luò),神經(jīng)網(wǎng)絡(luò)隱藏層都采用RELU函數(shù)作為激活函數(shù),網(wǎng)絡(luò)結(jié)構(gòu)表示輸入層、隱藏層和輸出層對應(yīng)的節(jié)點(diǎn)數(shù)。在訓(xùn)練時(shí)的mini-batch大小為1024,最大回合數(shù)(max episode)為30000,輔助網(wǎng)絡(luò)的更新率0.01,價(jià)值網(wǎng)絡(luò)的學(xué)習(xí)率為0.01,策略網(wǎng)絡(luò)的學(xué)習(xí)率為0.001,兩個(gè)網(wǎng)絡(luò)都采用了Adam Optimizer優(yōu)化器進(jìn)行學(xué)習(xí),經(jīng)驗(yàn)池的大小為1×106,一旦經(jīng)驗(yàn)池的數(shù)據(jù)超過最大數(shù)值,將會丟掉原始的經(jīng)驗(yàn)數(shù)據(jù)。 表1 MADDPG網(wǎng)絡(luò)結(jié)構(gòu)參數(shù)Table 1 Network structure parameters of MADDPG 初始化仿真環(huán)境包含三架無人機(jī)的初始位置、三個(gè)目標(biāo)的位置和7個(gè)威脅區(qū)的分布情況。具體初始環(huán)境如圖5所示。 圖5 初始環(huán)境Fig.5 Initial environment 通過建立DDPG和MADDPG兩種模型結(jié)構(gòu)進(jìn)行訓(xùn)練。最終得到獎(jiǎng)勵(lì)函數(shù)如圖6所示。 圖6為訓(xùn)練過程中,三架無人機(jī)在每一回合(episode)訓(xùn)練時(shí)的獎(jiǎng)勵(lì)變化圖。橫坐標(biāo)表示訓(xùn)練的回合數(shù)(episodes),縱坐標(biāo)表示每一回合訓(xùn)練時(shí)三架無人機(jī)的累計(jì)獎(jiǎng)勵(lì)。可以看出隨著訓(xùn)練次數(shù)的增多,獎(jiǎng)勵(lì)的絕對值減小,但是獎(jiǎng)勵(lì)逐漸增大,由于訓(xùn)練過程中存在隨機(jī)噪聲,所以訓(xùn)練時(shí)無論是哪個(gè)時(shí)刻都存在振蕩現(xiàn)象,但從圖6中依然可以看出,在訓(xùn)練回合數(shù)達(dá)到10000回合后,兩種算法的獎(jiǎng)勵(lì)曲線趨于平緩,總體呈收斂趨勢。 圖6 訓(xùn)練獎(jiǎng)勵(lì)收斂曲線Fig.6 Reward convergence curve of single step training 圖7是三架無人機(jī)網(wǎng)絡(luò)參數(shù)變化曲線圖,表示每架無人機(jī)網(wǎng)絡(luò)結(jié)構(gòu)中Actor網(wǎng)絡(luò)和Critic網(wǎng)絡(luò)的Q值(狀態(tài)動作值)和損失值(Q估計(jì)值和Q實(shí)際值之間差距的平方)的變化規(guī)律。圖7(a)是DDPG算法模型三架無人機(jī)網(wǎng)絡(luò)參數(shù)的變化曲線圖,圖7(b)是MADDPG算法模型三架無人機(jī)網(wǎng)絡(luò)參數(shù)的變化曲線圖。可以看出,兩種算法隨著訓(xùn)練次數(shù)的增加,Actor網(wǎng)絡(luò)的Q值逐漸增大,直到收斂。Critic網(wǎng)絡(luò)中損失值隨著訓(xùn)練的次數(shù)增加而逐漸減少,直到收斂。對比DDPG和MADDPG兩種算法中每架無人機(jī)網(wǎng)絡(luò)Q值和損失值的變化曲線,可以發(fā)現(xiàn)DDPG算法在訓(xùn)練過程中,每架無人機(jī)網(wǎng)絡(luò)的Q值在訓(xùn)練到5000回合之后有明顯的下降趨勢,而MADDPG算法整體呈上升收斂趨勢,沒有明顯的波動變化趨勢。且MADDPG算法中每架無人機(jī)網(wǎng)絡(luò)的初始損失值明顯小于DDPG算法中的初始損失值,而且在兩種算法收斂后,MADDPG算法中的損失值要明顯小于DDPG算法中的損失值。說明了MADDPG比DDPG算法具有更強(qiáng)的穩(wěn)定性和更快的收斂性。最終兩種算法模型的軌跡圖如圖8所示。 圖7 不同算法無人機(jī)網(wǎng)絡(luò)參數(shù)變化Fig.7 Changes of UAV network parameters based on different algorithms 圖8(a)為DDPG算法模型經(jīng)過訓(xùn)練后得到的無人機(jī)軌跡圖。圖8(b)為MADDPG算法模型訓(xùn)練后得到的無人機(jī)軌跡圖。對比兩種算法模型的無人機(jī)飛行軌跡可以看出,DDPG算法最終的飛行軌跡 圖8 不同算流下的無人機(jī)軌跡Fig.8 Flight path of UAV based on different algorithms 并沒有完全進(jìn)入目標(biāo)區(qū)域,相對目標(biāo)有一定的距離,而且第二架無人機(jī)的軌跡還進(jìn)入了威脅區(qū)內(nèi)。而MADDPG算法模型的飛行軌跡全都進(jìn)入了目標(biāo)區(qū)域,而且躲避了所有的威脅區(qū)。綜合分析兩種算法的獎(jiǎng)勵(lì)曲線變化圖和飛行軌跡圖,可以得出結(jié)論:在該環(huán)境下,MADDPG算法優(yōu)于DDPG算法。 針對現(xiàn)有多無人機(jī)任務(wù)決策研究中的缺點(diǎn),進(jìn)行了基于MADDPG算法的多無人機(jī)任務(wù)決策問題的研究,詳細(xì)闡述了MADDPG算法的原理和特點(diǎn),并且基于多無人機(jī)任務(wù)背景,分別從網(wǎng)絡(luò)結(jié)構(gòu)、狀態(tài)空間、動作空間和獎(jiǎng)勵(lì)函數(shù)設(shè)計(jì)了MADDPG算法的模型結(jié)構(gòu),將MADDPG算法和多無人機(jī)任務(wù)決策問題相結(jié)合,實(shí)驗(yàn)證明MADDPG算法不僅可以解決多無人機(jī)任務(wù)決策問題,并且相對DDPG算法,針對傳統(tǒng)算法學(xué)習(xí)效率并不高的缺陷,本文提出的方法具有更快的收斂速度和學(xué)習(xí)效率。3 實(shí)驗(yàn)及分析
3.1 參數(shù)設(shè)計(jì)

3.2 結(jié)果分析

4 結(jié)束語
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40中國傳媒大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年1期)2021-06-09 08:43:00中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50中國生殖健康(2020年6期)2020-02-01 06:28:50小學(xué)生作文(低年級適用)(2019年9期)2019-10-08 08:37:10中國生殖健康(2019年11期)2019-01-07 01:28:02文苑(2018年23期)2018-12-14 01:06:06文苑(2018年19期)2018-11-09 01:30:14文苑(2018年17期)2018-11-09 01:29:26文苑(2018年21期)2018-11-09 01:22:32
