網絡形式背景下的社區劃分方法研究
2021-08-07 07:42:24劉文星李金海
計算機與生活 2021年8期
劉文星,范 敏+,李金海
1.昆明理工大學 數據科學研究中心,昆明 650500
2.昆明理工大學 理學院,昆明 650500
社會網絡分析(social network analysis,SNA)起源于物理學中的適應性網絡。通過研究網絡關系及其結構,有助于把個體間相互關系即“微觀”網絡與大規模的社會系統的“宏觀”結構相結合,從而得到一些有意義的概念、模式和分析結果。近年來,把復雜網絡分析技術、社會網絡分析理論與圖論以及社會學、心理學、人類學、數學、通信科學等領域相結合,逐步發展成一個非常有潛力的研究分支。它在許多方面獲得了重要的研究成果,比如:生物社區研究、傳染病網絡研究、城市化研究、網絡經濟體系研究等。
社會網絡分析中的社區劃分是從網絡中獲取概念、模式的基礎,也是社會網絡分析研究中的重點。現有的社會網絡社區劃分的研究主要集中在分布式算法設計、有先驗信息的劃分算法設計、模糊結構社區劃分和進化網絡劃分等方面。文獻[1]提出了一種分布式局部搜索算法,該算法是以頂點為中心的計算模型,采用了分布式圖著色策略來區分相鄰節點。文獻[2]提出了一種基于信息熵的劃分方法,并運用模擬退火算法,引入了一個新的定義,即超邊切分、微切割。文獻[3]主要通過構造特征矩陣和網絡中的先驗內容信息提出了一種基于半監督矩陣分解和隨機游走的算法。文獻[4]通過對網絡的擬合,提出了一種新的假設檢驗框架,能夠自動確定各種網絡中的社區數量,并且快速檢測模擬網絡和實際網絡中的社區結構。文獻[5]設計了一種新的鏈路預測策略,能夠劃分具有模糊社區結構的網絡。文獻[6]給出了一種基于懲罰矩陣分解的復雜網絡社區結構發現算法。文獻[7]利用模糊粗糙方法檢測進化網絡中的重疊、非重疊和內在社區。以上研究各有特色,但是均未考慮網絡節點自身具有的一些屬性特征。
形式背景下的概念認知學習是一個新興的交叉研究領域,它由形式概念分析、粗糙集、粒計算和認知計算等理論融合而來。近年來,在大數據環境下的概念認知學習中表現出諸多的認知優勢,也取得了許多有價值的研究成果[8-10]。比如,文獻[11]提出的概念認知模型為后續進一步研究提供了參考[12]。文獻[13]闡述了從多個視角研究概念認知的重要性。文獻[14]討論了概念認知系統的迭代算法。形式背景下的概念分類是進行概念認知的基礎和前提。文獻[15]在文獻[16]的基礎上設計了一個新的并行概念學習框架,以滿足增量式分類任務的要求。文獻[17]從屬性拓撲的角度探討了概念認知學習。文獻[18]采用按類標號進行劃分的方法對形式背景進行劃分,并把劃分后的形式背景按屬性項分割。文獻[19]指出形式背景拆分的方法可以采用粗糙集中等價類劃分的方法來完成。現有的概念認知研究為網絡上的概念認知和網絡社區劃分提供了堅實的理論基礎。
基于上述討論,不難發現傳統的社會網絡社區劃分沒有考慮網絡節點的屬性信息,而這些信息在某些方面的作用明顯,因為它反映了節點的內涵與特征,對社區劃分具有重要意義。而傳統的形式背景下的劃分,沒有考慮研究對象所處的網絡及其結構。因此,有必要把二者結合起來,對網絡形式背景下的網絡社區劃分進行研究,從而使得生成的網絡社區分類既能描述其網絡特征,又能體現出其概念內涵特征,這對網絡數據挖掘與網絡概念認知具有重要的理論意義和實際應用價值。
現有研究還表明,社會網絡的不同角色在網絡中的地位不同。某些網絡,從其中一個角色出發形成的社區更有意義。比如:營銷網絡中以賣家出發形成的社區就更有意義,這種特點對應著單角色網絡社區劃分。而有些網絡中,不同角色形成的社區具有不同的含義。比如:學術網絡中,引用者形成的社區和被引用者形成的社區就有不同的含義,這種特點對應著雙角色網絡社區劃分。同時某些作者引用別人和被別人引用都比較多,那么綜合這兩種角色形成的學術活躍度相似社區也能夠被刻畫出來。因此,在進行網絡社區劃分之前,先應該區分該網絡的特點:適用于單角色網絡社區劃分還是雙角色網絡社區劃分。在此基礎上,結合網絡結構和節點屬性對網絡進行社區劃分,這將使得網絡劃分更高效地貼合實際情況。
文獻[8]構造了網絡形式背景,主要得到了網絡概念等。本文將在文獻[8]的基礎上,把網絡拓撲結構與屬性相結合,對網絡社區劃分進行研究。
1 基礎理論
本章介紹網絡形式背景中的基本概念,如形式概念、節點的中心度、網絡的中心勢、網絡社區概念,詳見文獻[8,20-21]。
定義1四元組(U,M,A,I)稱為網絡形式背景,其中U={x1,x2,…,xn}是非空有限節點集,M={M1,M2,…,Mk}是網絡的結構矩陣,Mt(t=1,2,…,k) 為網絡的t階鄰接矩陣,A={a1,a2,…,am} 是非空有限屬性集,I={I1,I2,…,Ik,Ik+1},I1,I2,…,Ik是笛卡兒積U×U上的二元關系,Ik+1是笛卡兒積U×A上的二元關系。約定,(xi,xj)∈Il(l=1,2,…,k)表示節點xi和xj是l階鄰接的,(xi,ap)∈Ik+1表示節點xi擁有屬性ap。
表1 給出了網絡形式背景的二維表。實際上,一個網絡形式背景對應著一個網絡。因此,如無特別說明,下文中提到的網絡均指網絡形式背景對應的網絡。
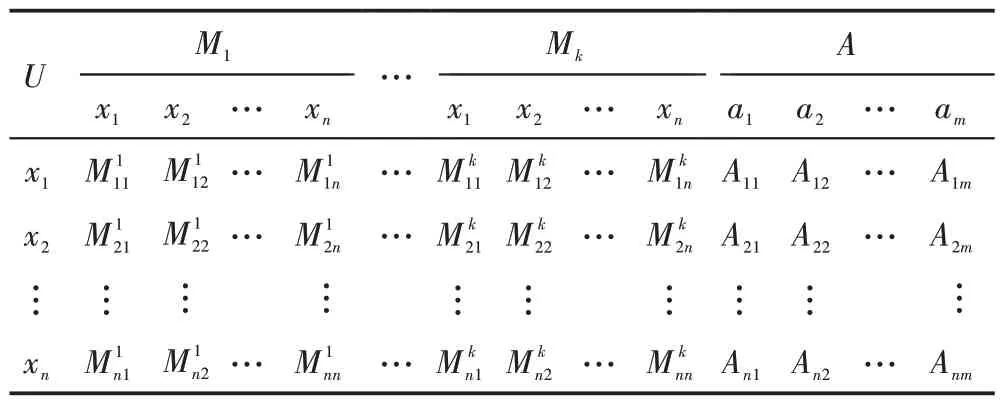
Table 1 Network formal context (U,M,A,I)表1 網絡形式背景(U,M,A,I)
定義2給定網絡形式背景(U,M,A,I),對于任意X?U,B?A,定義:
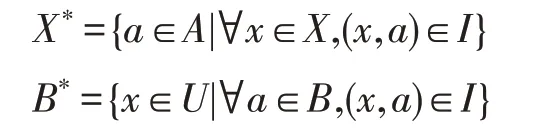
其中,X*表示X中所有對象共同擁有的屬性組成的集合;B*表示擁有B中所有屬性的對象組成的集合。如果X*=B且B*=X,那么稱(X,B)為形式概念。
在有向圖中,需要討論網絡節點的入度中心度和出度中心度。
定義3節點xi的入度中心度和出度中心度分別定義為:
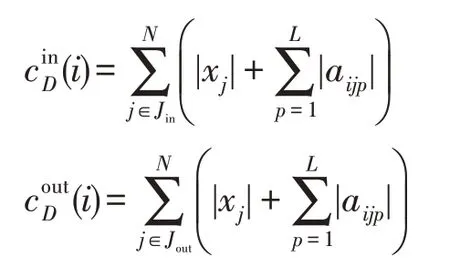
其中,Jin表示與xi形成入度的節點的下標構成的集合,Jout表示與xi形成出度的節點的下標構成的集合。特別地,在無向圖中,中心度記為cD(i)。
在有向圖中,節點的相對中心度區分為入度相對中心度和出度相對中心度:
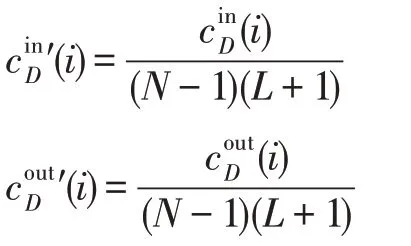
定義4網絡的中心勢定義為:
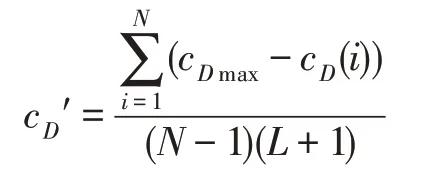
定義5對于網絡形式背景(U,M,A,I),稱三元組(M,C,C*)為網絡社區C的對象概念,簡稱為社區對象概念;同理,稱為屬性B對應的網絡屬性概念,簡稱為社區屬性概念。(M,C,C*)、統稱為網絡社區概念。
此外,M={M1,M2}為網絡社區概念的網絡特征值,為社區概念的平均度,它表示社區概念內部平均重要度,為社區概念的平均勢,它表示社區概念內部的差異程度。
(M,C,C*)中的C*可能為空,此時說明這些對象雖然能劃分在同一社區,但沒有共同屬性。換言之,將共有算子進一步弱化成似然算子,就可以從另一個角度定義另一種網絡社區概念。
其次,在有向圖中,網絡的中心勢區分為入度中心勢和出度中心勢:
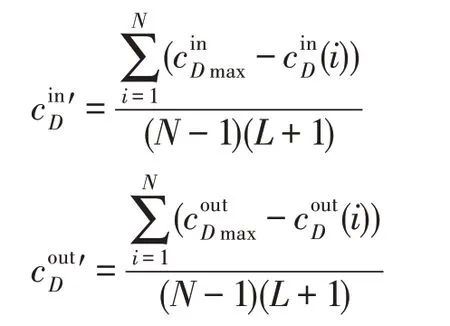
在有向網絡中,網絡社區概念的網絡特征參數M 也需要區分入度和出度的情況:,。因此,網絡社區概念在有向圖中分為入度網絡概念和出度網絡概念,分別記為(Min,C,C*)、。
2 網絡社區劃分
本章主要從網絡拓撲結構與屬性相結合的角度對網絡社區進行劃分研究。具體地,先找到網絡中度最大的節點,再找到與其相連的其他節點,并將具有一定屬性相似度的相連節點劃為一類。
2.1 單角色網絡社區劃分
定義6對象xi的k階鄰接集定義為:
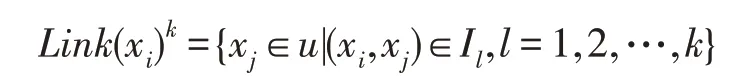
它表示與對象xi有k階鄰接關系的對象構成的集合。特別地,一階的情形記為Link(xi)。
定義7對象xi的β∈[0,1]屬性相似集定義為:
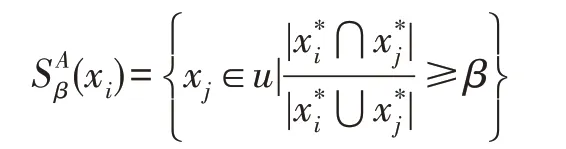
它表示與對象xi有屬性相似程度達到β以上的對象構成的集合。
下面給出基于網絡結構與節點屬性相結合的網絡劃分算法。
算法1基于網絡結構與節點屬性的單角色網絡劃分算法
輸入:網絡形式背景(U,M,A,I)和β值。
輸出:劃分的對象塊CL。
步驟1計算網絡中每個節點的出(入)度。
步驟2從出(入)度最大的節點xi開始,計算Link(xi)。
步驟3在Link(xi)中計算,令CL={Link(xi),,并刪除M中的CL。
步驟4判斷M中是否存在不為0 的元素,若有則返回步驟2;否則,輸出CL,算法結束。未進行分類的對象,單獨劃為一類。
在上述算法中,步驟1 的時間復雜度為O(n)(n為網絡形式背景中的對象個數),步驟2 的時間復雜度為O(n2),步驟3 和步驟4 的時間復雜度為O(n2),因此算法1 的時間復雜度為O(n2)。
算法1 是在單角色網絡中考慮網絡的出(入)度,研究網絡社區劃分;同樣,也可以考慮在無向網絡中討論社區劃分問題,只需把算法1 中節點的出(入)度替換成節點的度即可。
2.2 雙角色網絡社區劃分
類似于2.1 節,也可以給出基于網絡結構與節點屬性的雙角色網絡劃分算法。
算法2基于網絡結構與節點屬性的雙角色網絡劃分算法
輸入:網絡形式背景(U,M,A,I)和β值。
輸出:劃分的對象塊CL。
步驟1重復調用算法1,將其輸出結果分別記為CL1和CL2,其中CL1為出度劃分結果,CL2為入度劃分結果。
步驟2計算網絡中每個節點的度,它是入度與出度之和。
步驟3從度最大的節點xi開始,計算Link(xi)。
步驟4在Link(xi)中計算,記CL3={Link(xi),,并刪除M中的CL3。
步驟5判斷M中是否存在不為0 的元素,若有則返回步驟2;否則,輸出CL3,算法結束。未進行分類的對象,單獨劃為一類。
由于算法2 與算法1 的基本步驟相同,只是同時計算了節點的入度和出度,因此算法2 的時間復雜度也為O(n2)。
3 實例分析
例1圖1 是一個社交營銷網絡,其中x1~x10表示研究對象,xi到xj的弧表示xi將貨物賣給xj。由圖1可得表2 中的網絡形式背景。下面利用算法1 對該網絡進行劃分。
考慮出度的情況下計算網絡分類,具體過程如下:
(1)計算網絡中10 個節點的出度,則節點x1~x10的出度依次為4、0、2、0、0、0、1、0、1、0。
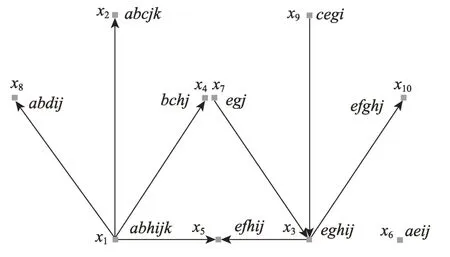
Fig.1 Network C圖1 網絡C
(2)找到出度最大的節點為x1,計算Link(x1)={x2,x4,x5,x8}。
(3)在集合Link(x1)={x2,x4,x5,x8}中計算出{x2,x4,x5,x8},則第一個分類為CL={x1,x2,x4,x5,x8},刪除節點x1,x2,x4,x5和x8的度,此時節點x1~x10的度依次為0、0、2、0、0、0、1、0、1、0。
(4)計算出此時度最大的節點為x3,Link(x3)={x10},在Link(x3)中計算,則第二個分類為CL={x3,x10},刪除節點x3和x10的度,此時節點x1~x10的度依次為0、0、0、0、0、0、1、0、1、0。
(5)計算出此時度最大的第一個節點為x7,Link(x7)=?,則第三個分類為CL={x7},刪除節點x7的度,此時節點x1~x10的度依次為0、0、0、0、0、0、1、0、1、0。
(6)計算出此時度最大的第一個節點為x9,計算Link(x9)=?,則第四個分類為CL={x9},刪除節點x9的度,此時節點x1~x10的度依次為0、0、0、0、0、0、0、0、0、0。
(7)此時,網絡中10 個節點的出度均為0,孤立點x6單獨歸為一類,即第五個類CL={x6}。綜上,得到以下社區劃分結果:
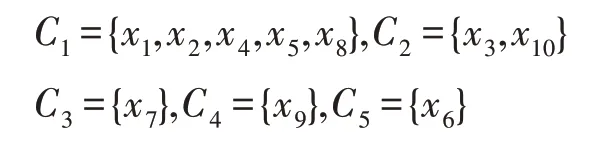
即該網絡總共分為5 個營銷社區。
下面繼續對5 個社區的網絡特征值進行分析:

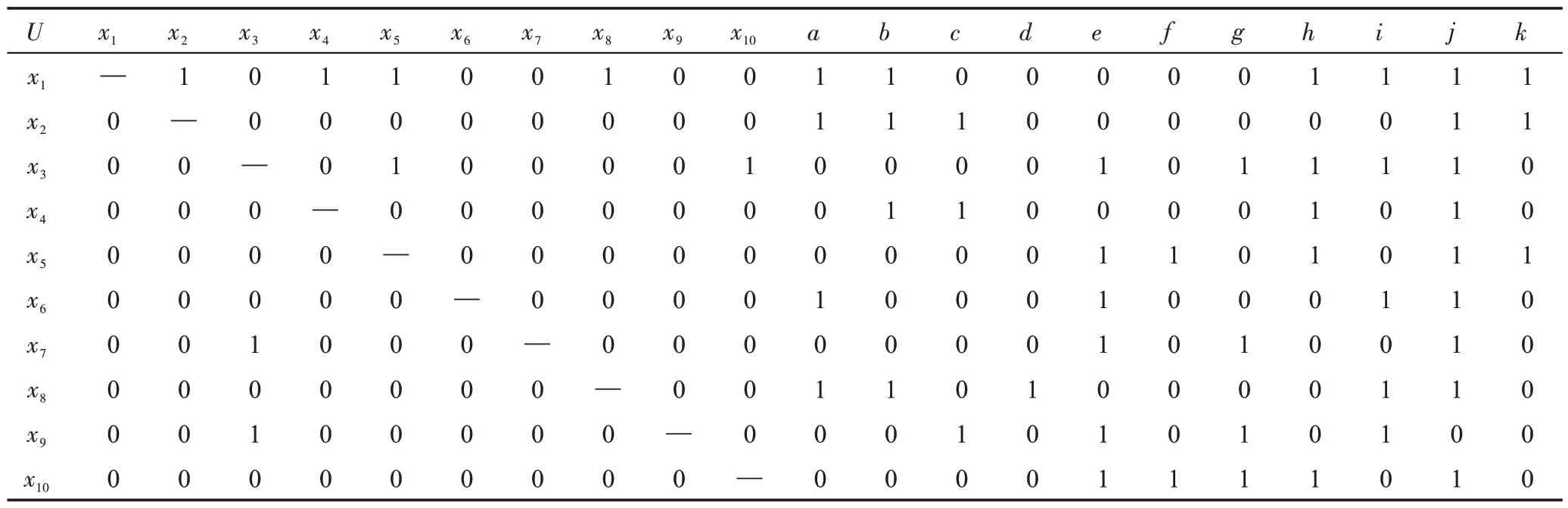
Table 2 Network formal context (U,M,A,I) of network in Fig.1表2 圖1 的網絡對應的網絡形式背景(U,M,A,I)
在該社交營銷網絡中,社區C1和C2的平均度差別不大,說明兩個賣家社區在網絡當中的重要性差別不大。但C1和C2的平均勢差別較大,說明兩個社區內部的賣家之間的重要性差別較大,這是因為在社區C1中含有x1,其重要性很大。
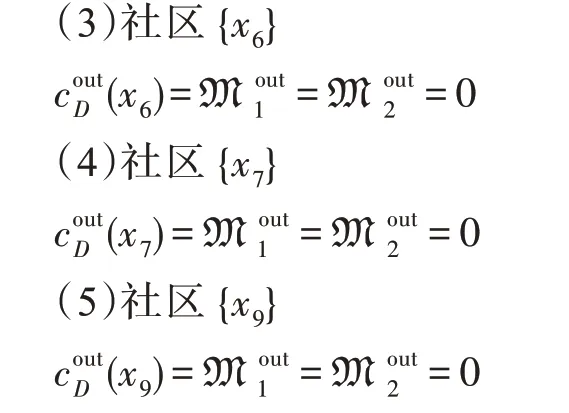
在該網絡中買家x6、x7和x9沒有售賣商品,因此在售賣網絡中重要性為0,故它們的網絡特征值M1=M2=0。
下面的例2 給出了一個雙角色網絡的社區劃分,以說明算法2 具體如何實施。
例2圖2 是一個學術引用網絡,網絡中節點x1~x20表示20 位作者,字母a~i表示網絡中作者經常使用的關鍵字。從節點x1指向節點x10的箭頭表示作者x1引用了作者x10的文章。圖2 對應的網絡形式背景(U,M,A,I)可由表3 和表4 合并得到,其中表3 為網絡中節點之間的連接關系,即作者間的引用關系,表4 為網絡中各對象所擁有的屬性。
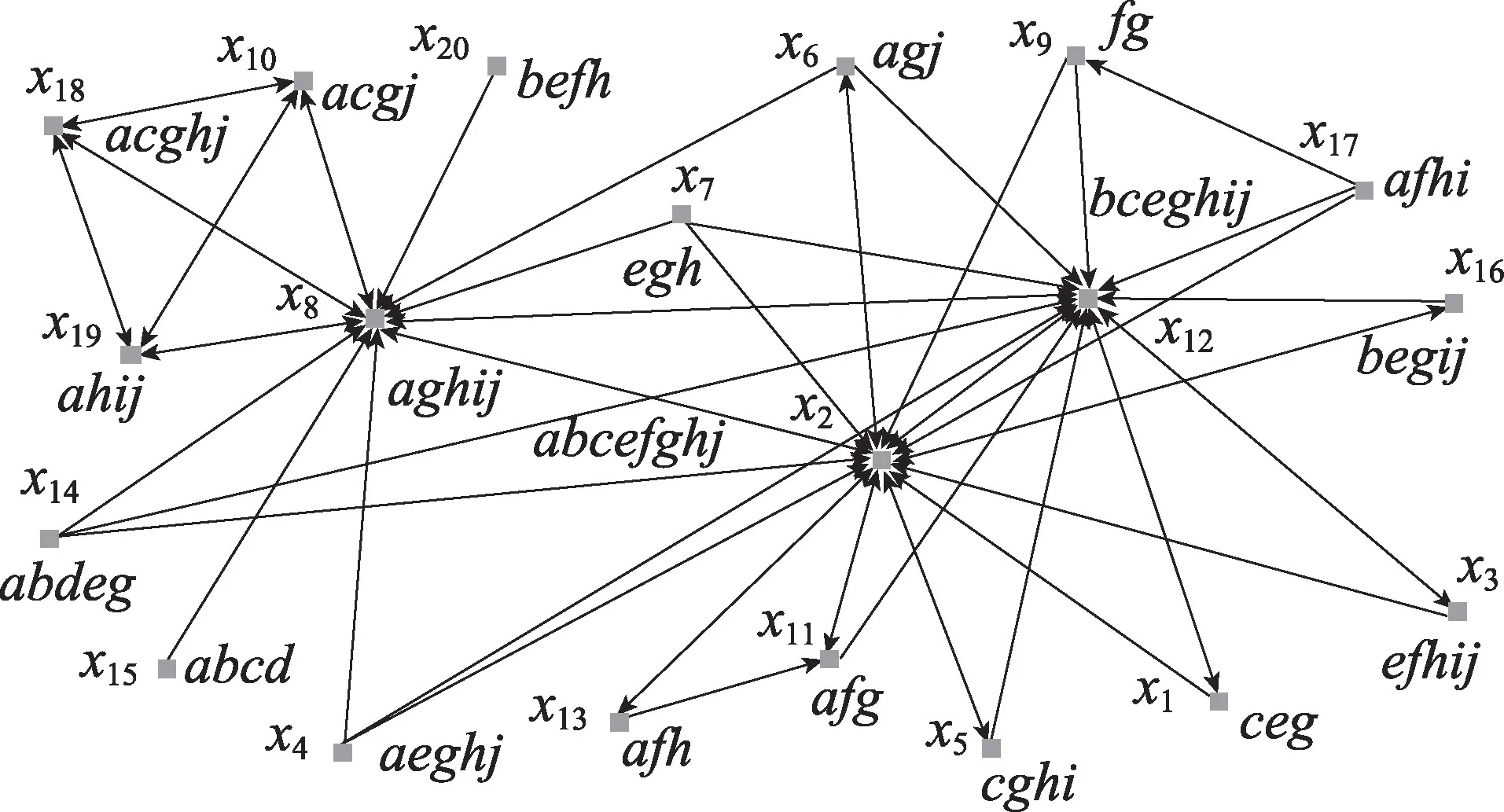
Fig.2 Academic citation network圖2 學術引用網絡
(1)依據算法2,先考慮基于出度的劃分,設β=0.2。從網絡中出度最大的節點x2開始劃分,可以得到以下分類:
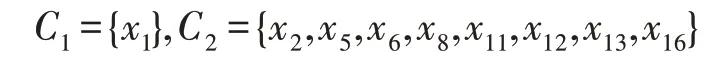

Table 3 Connection relation of network formal context (U,M,A,I) of Fig.2表3 圖2 對應的網絡形式背景(U,M,A,I)的連接關系
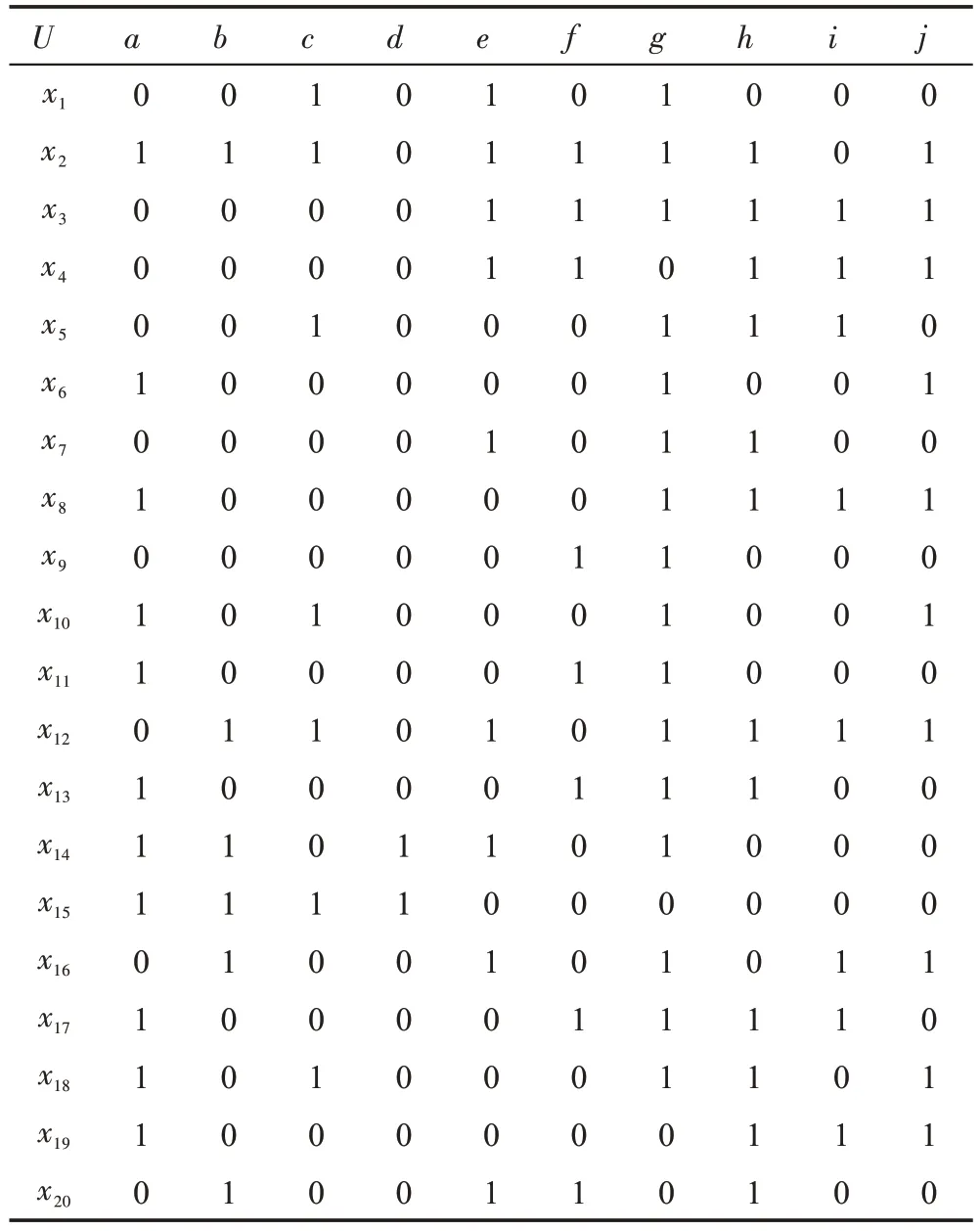
Table 4 Attributes possessed by objects in network formal context (U,M,A,I) of Fig.2表4 圖2 對應的網絡形式背景(U,M,A,I)所含對象擁有的屬性
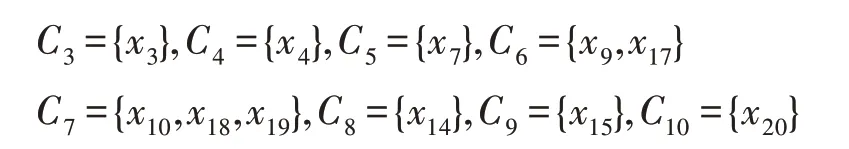
選取社區C2,C6和C7進行網絡特征值的討論,先分析社區C2:
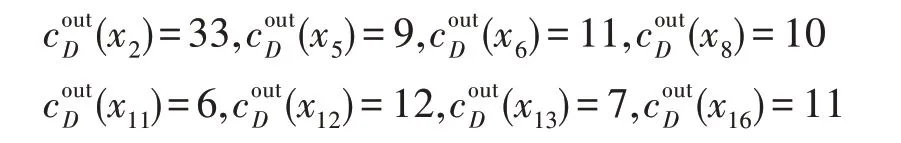
同理可以得到出度對象形式概念:
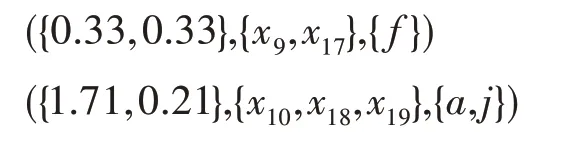
引用者社區C6和C7的平均度差別較大,說明它們在網絡中的重要性差別較大。而兩社區平均勢差小,說明兩者內部的引用者之間的差異小。
(2)考慮基于入度的劃分,設β=0.2。可以得到以下分類:
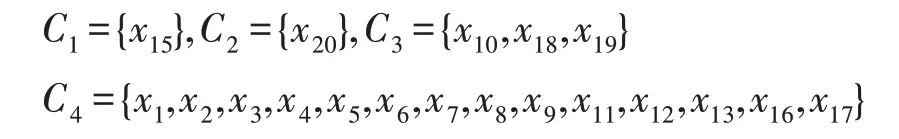
此處,選取C4進行網絡特征值分析:
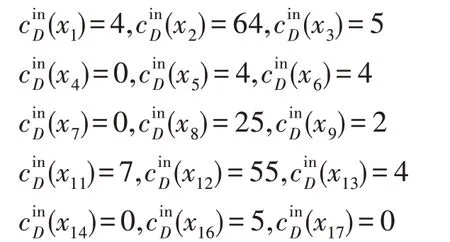
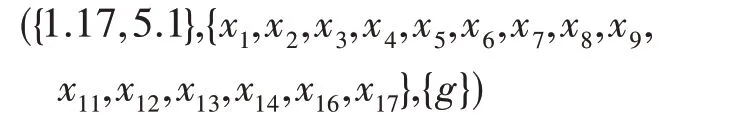
節點x12的入度為13,而節點x2的入度為14,兩者均為度較大的節點。同理,設β=0.2,以節點x12作為起始節點進行分類,可得以下分類結果:
節點x8的入度為11,在整個網絡中屬于度較大的節點,指向它的節點為:
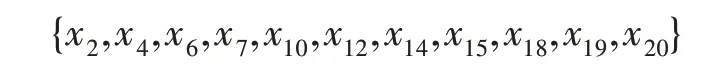
而這些節點大部分未與節點x8分為一類,主要原因是這些節點雖然與節點x8相連,但并不具有相同的屬性。因此,在劃分時,不僅要考慮節點的Link值,還要考慮節點所擁有的屬性。
(3)考慮基于綜合度的劃分,設β=0.2,可得以下分類:
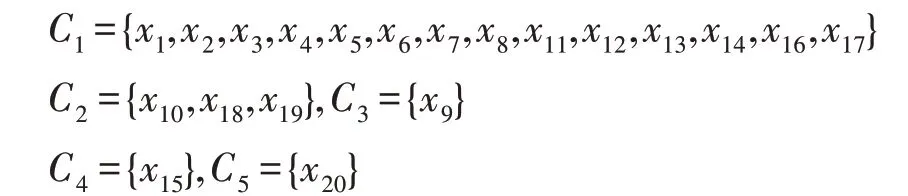
這里僅選取C2進行網絡特征值分析:
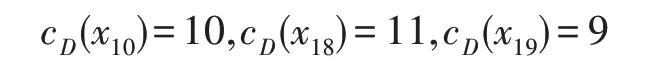
則M1=2.14,M2=0.21。故可得綜合度對象形式概念為({2.14,0.21},{x10,x18,x19},{a,j}),其中表示社區C2中的作者共同使用的關鍵字為a和j,M1=2.14 表示平均度,社區C2中節點重要性為2.14,M2=0.21 表示社區C2中節點之間影響力差異為0.21。
可以發現,在網絡社區劃分研究中,從不同的角度解決問題,如考慮入度、出度和綜合度,得到的社區劃分結果是不同的。
4 結束語
本文主要提出了網絡結構和屬性信息相結合的網絡社區劃分方法。該方法兼顧了網絡的結構特點和網絡中節點所擁有的內涵屬性。它可以針對不同網絡中結構與屬性的特點,選取不同的相似閾值對網絡進行社區劃分以得到社區特征值,從而更好地對網絡社區進行認知學習。在本文給出的網絡劃分算法的基礎上,今后可以進一步研究以下問題:(1)基于網絡形式背景的網絡規則提取;(2)非冗余網絡規則的快速提取算法;(3)保持非冗余網絡規則不變的知識約簡;(4)節點屬性特征矩陣為先驗信息的網絡劃分以及關聯規則挖掘等。
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
汽車工程師(2021年12期)2022-01-17 02:29:54
當代陜西(2020年14期)2021-01-08 09:30:42
奧秘(創新大賽)(2020年7期)2020-07-27 08:26:32
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
湘江法律評論(2016年0期)2016-06-15 20:29:32
紡織服裝流行趨勢展望(2016年1期)2016-05-04 03:45:20
