基于Linux快速文件快速檢索工具實現
2021-08-06 03:03:18任啟紅
卷宗 2021年20期
任啟紅
(三江學院 計算機科學與工程學院,江蘇 南京 210012)
Linux系統自帶的find命令、locate命令、xagrs命令可以用于對文件路徑、文件內容進行檢索,但速度比較慢從幾分鐘到幾十分鐘不等(具體視文件數量、硬盤類型、目錄深度等等具體情形而定),如何快速進行文件路徑和文件內容檢索是一個比較重要的問題。本文提出基于內存建立索引、根據用戶實時輸入快速檢索的計算方法。
1 概述
使用linux自帶的命令find、locate,效率比較低下,需要花費數分鐘至數十分鐘才能完成檢索文獻[1]內存文件列表的建立和內存跳表的構建兩個功能模塊,這兩種功能模塊都是基于自定義的內存管理方法。先申請固定大小的內存塊,里面包括32比特的位圖、32個數據塊,每一比特的位圖依次對應一個數據塊,這種方案為每條索引記錄分配的內存都相同,比較耗費內存;文獻[2]提出把文件系統內生成子目錄散列槽,且通過唯一標識符標志每個子目錄散列槽并在文件系統內快速接收文件的方法,把業務目錄根據業務人員分別配置權限,不過這個比較適用于詳細的某行業定制;文獻[3]采用把索引存放到數據庫進行管理,我們采用把目錄、文件路徑存放到內存進行檢索,速度會更快。
2 快速檢索方案及實現
我們采用C語言實現,工具名為Found,開發的系統分為如下幾個步驟:
1)讀取配置文件(里邊有包含目錄或排除目錄),并解析需要包含的目錄列表;
2)根據目錄列表遞歸讀取所有文件和所在目錄,并存儲到內存記為數組pAllFiles;
3)創建兩個線程、一個讀取鍵盤輸入;一個執行操作(如檢索數組、更新索引);
4)按每個路徑大小分配內存,并建立索引,內存額外開銷比較小;
5)每次輸入后進行一次檢索,因為計算機處理比鍵盤操作快約106倍,這樣節省了查詢的時間;
詳細流程圖如圖1。

圖1 系統工程流程圖
本軟件優點:
1)軟件運行中途也可更新檢索;
2)字符串比較采用KMP算法,減少檢索時比較次數;
3)采用上一次計算的結果更新索引(nextIndex)下一跳索引作為比較輸入,減少比較次數:
4)用C語言開發,速度快;
5)實時根據用戶輸入進行檢索速度快;
6)可根據文件刪除、新增,手動更新索引列表;
7)基于內存比較,速度快;
8)每個路徑+文件名按照實際使用長度申請,浪費的額外內存較少;
9)可支持目錄排除建立索引;

圖2 每輪搜索更新下一跳示意圖
本軟件缺點:
1)界面不太友好;
2)建立索引需要時間(Linux下find命令不需要建立索引時間);
3)每次讀取一個文件名都需要新申請內存,添加到索引指針數組;
4)開始需要配置申請件數量大小指針數組空間,可能有一些浪費;
5)當前是全量更新索引;
6)更新索引不是自動的;
進行檢索時:設置線程睡眠時間為usleep(1000);
3 實驗結果與分析
測試環境:
處理器:Inter(R) Core(TM) i5-6200 CPU @ 2.30GHz 2.40GHz
內存:8.00GB
主機操作系統Windows10,
使用VMware? Workstation 14 Pro版本:14.1.3 build-9474260
虛擬機操作系統:Ubuntu 20.10測試文件數量:1172814
測試用例及結果,如表1所示:
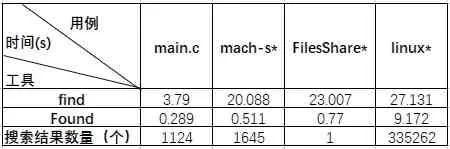
表1 測試結果
從結果看,Found工具比find命令整體上是快不少。
4 結語
當前軟件由于是純C實現,界面不太友好,需要進一步完善。
