結(jié)合分數(shù)階邊緣檢測的改進DeepLabv3+模型
2021-08-06 05:48:12鄭淘
現(xiàn)代計算機 2021年16期
鄭淘
(四川大學計算機學院,成都 610065)
0 引言
語義分割(Semantic Segmentation)是當今計算機視覺(Computer Vision,CV)領域的核心問題之一,其任務是將同屬一種對象分類的像素聚集來實現(xiàn)圖像分割,被廣泛應用于地理信息系統(tǒng)、無人駕駛、醫(yī)療影像分析、機器人等領域。隨著深度學習技術(shù)研究的愈發(fā)火熱,許多計算機視覺問題開始使用深度架構(gòu)來進行研究,其中主要以深度卷積神經(jīng)網(wǎng)絡(DCNN)為熱點方向,常見架構(gòu)諸如AlexNet[1]、VGG-16[2]、GoogleNet[3]、ResNet[4]等,其實驗的準確率與學習效率都較傳統(tǒng)方法有極大的提高,這些模型也為后來語義分割模型的主體架構(gòu)做出了巨大貢獻。2014年,全卷積網(wǎng)絡FCN[5]開創(chuàng)性將深度卷積模型的全連接層用卷積替代,不僅提高了語義分割模型的學習效率,同時使得任意大小的輸入成為可能。Vijay.B等人提出SegNet[6]將最大池化指數(shù)轉(zhuǎn)移至解碼器,改善了分割分辨率,Yu等人提出使用空洞卷積[7](Atrous conv)來提高模型的感受野、Chen等人提出DeepLab系列[8-10]語義分割模型,在空洞卷積的基礎上實現(xiàn)了金字塔型空洞池化(ASPP)來獲取多尺度信息,并結(jié)合了概率圖模型方法,將全連接條件隨機場DCRFs引入學習場景等。其中,Google公司提出的DeepLab模型經(jīng)過幾個版本的迭代更新,目前發(fā)表的最新成果DeepLabv3+[11]在PASCAL VOC2012數(shù)據(jù)集上取得了SOTA的MIOU。
分數(shù)階微積分理論作為一門新興的數(shù)學學科,最開始僅是作為數(shù)學家們的純數(shù)學理論分析和公式推導。經(jīng)過幾十年的積累沉淀,在國內(nèi)外許多學者的研究努力下,發(fā)現(xiàn)分數(shù)階微分算子具有良好的記憶性和非局部性[12],因此被廣泛應用于各類科學與數(shù)學工程領域。目前,分數(shù)階微積分理論在數(shù)字圖像處理多個領域也實現(xiàn)了研究發(fā)展,其中包括圖像的增強、去噪、邊緣提取、分割、奇異性檢測等,許多學者在該方向上都獲得了突破性的研究成果,PU等人[13-14]通過選擇適當階次的分數(shù)階微分算子,在圖像增強邊緣的同時保留了平滑區(qū)域的紋理信息,也更加符合人類視覺特性;B.Mathieu等人[15]提出分數(shù)階微分邊緣檢測算子,能夠有效檢測出物體邊緣細節(jié),且在不同階次范圍內(nèi)取得了對抗噪聲與邊緣提取的混合結(jié)果;Liu等人[16]提出了將分數(shù)階奇異值分解方法用于人臉識別,在人臉劇烈抖動時取得了比傳統(tǒng)分類方法更加優(yōu)秀的性能。
針對原始DeepLabv3+模型在學習過程中因引入下采樣與空洞卷積帶來的精度損失和邊緣細節(jié)丟失,本文引入分數(shù)階微分邊緣檢測模塊優(yōu)化原始模型,盡可能減少了學習過程中流失的邊緣細節(jié)。通過實驗驗證,改進模型在邊緣分割效果上優(yōu)于原始模型,且優(yōu)化模塊具有良好的拓展性能,可以部署在任意FCN族類的語義模型中。
1 研究進展
1.1 基于DeepLab的語義分割研究
近年來,學者們開始考慮從不同角度解決語義分割的兩個重點問題:信號下采樣和空間不變性。Olaf.R等人提出編解碼器結(jié)構(gòu)的U-Net[17]模型,將編碼部分采用多層卷積加池化來擴大感受野,解碼部分依然使用上采樣恢復圖像尺寸。同時將編碼與解碼部分特征圖對應串聯(lián),增加了圖像恢復的信息,提高了結(jié)果分辨率。SegNet[6]同樣采用編解碼結(jié)構(gòu),并且使用了帶有坐標(index)的池化方法,保留了位置信息,基本解決了多次池化造成的信息丟失問題。Zhao等人提出PSPNet[18]使用空間金字塔池化(Pyramid Pooling Module)在底層獲取一組不同感受野大小的feature map進行concatenate,完成了多層次的語義特征融合。DeepLab[8]的首次提出,是建立在FCN[5]和Atrous Conv[7]研究的基礎上,并結(jié)合概率圖統(tǒng)計方法將全連接CRF加入模型,增加了像素之間的關聯(lián)性。DeepLabv2[9]結(jié)合PSPNet[18]經(jīng)驗,在v1基礎上使用空洞空間金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)增加多尺度信息,并將backbone從VGG-16[2]替換為ResNet-101[4],在實驗結(jié)果上取得了更優(yōu)秀的表現(xiàn)。DeepLabv3[10]進一步改造ASPP,形成組合了空洞率為(6,12,18)的多尺度卷積對、加入Batch Normalization(BN)和1×1卷積、通過padding控制輸出尺寸的ASPP+結(jié)構(gòu)。同時,v3在結(jié)構(gòu)上比對了ASPP的級聯(lián)和并聯(lián)模式,最終選擇將并聯(lián)方式推向下一個階段。
DeepLabv3+[11]是DeepLab系列最新成果,融合了ASPP+并聯(lián)模式與編解碼結(jié)構(gòu),并通過將普通卷積替換為深度可分離卷積(Depthwise separable convolution)來降低計算量和參數(shù)量,采取對Xception[19]模型進行改進作為backbone,將所有的池化層替換為卷積,并參考MobileNet[20]結(jié)構(gòu)在每個3×3卷積后面添加額外的BN和ReLU。DeepLabv3+在PASCAL VOC2012數(shù)據(jù)集上取得了SOTA的MIOU。
作為目前最強大的語義分割模型之一,DeepLabv3+卻始終在物體的邊緣分割上表現(xiàn)一般,該優(yōu)化問題可以作為一門研究方向開展工作。Liu等人[21]通過增加從編碼器到解碼器的連接來豐富特征圖恢復過程中的邊緣信息,并在遙感數(shù)據(jù)集SpaceNet上取得了較好的分割效果;Wu等人[22]則使用了Kronecker卷積拓展了原始空洞卷積,提高了模型對部分信息的捕獲能力,且通過開發(fā)樹形結(jié)構(gòu)(Tree-structured)獲取分層上下文信息表示多尺度對象,有利于更好地理解復雜場景。
1.2 基于分數(shù)階微分的邊緣檢測
G-L分數(shù)階微分[23]定義是從研究連續(xù)函數(shù)的整數(shù)階導數(shù)的經(jīng)典定義出發(fā),將微積分的階數(shù)由整數(shù)擴展到分數(shù)推演而來的,即:
(4)
其中,Gamma函數(shù)的定義為:

(5)

(6)
(7)
根據(jù)式(4)(5)寫出差分方程右邊的前n項乘數(shù):
(8)
根據(jù)式(8)構(gòu)造像素點8個方向的各向同性濾波器,在8個方向上都具有旋轉(zhuǎn)同向性。隨著尺寸的增大,非運算方向上的值通過填0解決,可以構(gòu)造出經(jīng)典圖像增強的5×5的分數(shù)階微分算子[13-14]。

圖1 5×5分數(shù)階微分算子(Tiansi算子)
與圖像增強不同,邊緣檢測更加注重目標像素周圍梯度的變化,而應該盡可能忽略紋理等細節(jié)。本文提出一種滑動閾值方法的分數(shù)階邊緣檢測算子,在與經(jīng)典一二階邊緣檢測算子的對比實驗中,表現(xiàn)出更加優(yōu)秀的檢測性能。
邊緣檢測任務是將圖像中突變的信息進行提取[24],而圖像的突變信息往往對應的是高頻信息,即物體邊緣與紋理變化。傳統(tǒng)的邊緣檢測方法主要是基于梯度的邊緣檢測,比較經(jīng)典的算子包括:Robert、Sobel、Prewitt代表的一階算子以及Laplacian、Canny、Marri-Hildreth、LOG(Laplacian of Gaussian)、DOG(Difference Of Gaussian)代表的二階算子。主要原理都是通過求取梯度來獲取圖像突變部分的重要信息,主要是指灰度的變化,從而實現(xiàn)邊緣的獲取。但是,基于梯度的邊緣檢測算子的缺點也十分明顯,如一階的Sobel算子,邊緣定位準確,對噪聲友好,但是存在出現(xiàn)斷邊、邊緣過于粗糙的問題。二階的Laplacian算子,對階躍性邊緣定位準確,但是對噪聲極為敏感。作為整數(shù)階拓展的分數(shù)階微分算子,可以更加靈活的調(diào)整階次來適應不同的輸入圖像,實現(xiàn)抑制噪聲和邊緣連續(xù)的雙重標準。Jiang[25]結(jié)合Sobel算子和Tiansi算子的特性,通過手動調(diào)整分數(shù)階次和二值化閾值進行邊緣提取,對噪聲有一定的抑制能力。Zhang G M[26]將Canny算子中的梯度計算更換為分數(shù)階微分算子,有效降低了邊緣提取的錯誤率。Zhang W K[27]提出基于分數(shù)階微分差與高斯曲率濾波結(jié)合的算法,有效抑制非線性擴散產(chǎn)生的背景偽噪聲,對圖像增強和邊緣提取都有一定的補足。然而,這類方法均沒有實現(xiàn)分數(shù)階階次的自適應調(diào)整,需要靠人工和經(jīng)驗進行階次調(diào)整,對于不同的輸入信號無法實現(xiàn)端到端的處理。Li[28]、Wang[29]、Dai[30]等人則利用圖像的梯度、亮度、對比度、局部信息熵等來構(gòu)造局部信息函數(shù),將函數(shù)值為0設置為平滑區(qū)域,函數(shù)值為1設置為邊緣區(qū)域,由此可推導出適用于圖像增強的自適應分數(shù)階模型。這類方法在一定程度上實現(xiàn)了分數(shù)階微分階次的動態(tài)可調(diào),但是對于平滑和邊緣的判斷過于簡單,對于某些紋理復雜的圖像處理效果不是很理想。
2 本文方法
2.1 分數(shù)階滑動閾值邊緣檢測算子


圖2 3×3分數(shù)階(微分)邊緣檢測算子
為實現(xiàn)分數(shù)階微分的階次自適應可調(diào),利用滑動閾值的方法,取閾值集合為(10,30,50)來設置濾波過程中的分數(shù)階階次v,算法過程描述如下。
(1)將輸入圖像信號與3×3分數(shù)階(微分)邊緣檢測算子進行卷積;
(2)將算子與圖像信號左上角對齊,以步長為3開始向右滑動;
(3)以算子中心對應像素P(x,y)為目標像素,進行判斷:
①Set:grad_x,grad_y=|(P(x,y-1) -P(x,y+1)| ,|(P(x-1,y) -P(x+1,y)|
②ifgrad_x∈[0,10]andgrad_y∈[0,10]:v=0;
③else ifgrad_x∈(10,30]andgrad_y∈(10,30]:v=0.3;
④else ifgrad_x∈(30,50]andgrad_y∈(30,50],:v=0.5;
⑤else:v=0.8.
(4)向右滑動步長的距離,重復步驟3;到達圖像右邊緣后,向下移動步長距離,并回到最左端對齊。
(5)重復步驟3、4,直到對整個圖像完成濾波。
(6)將得到結(jié)果與原始圖像求差,獲得輸出結(jié)果。
階次v的自適應可調(diào)適用于任意輸入圖像,且對噪聲控制、紋理和邊緣的區(qū)分進行了有效的增強。將此算子引入語義分割模型中,可以設計出作用于圖像邊緣信息提取的子模塊。
2.2 分數(shù)階(微分)邊緣檢測模塊與改進的DeepLabv3+模型
DeepLabv3+以原始v3模型作為encoder,將ASPP前后的底層特征在Decoder模塊進行concatenate,并經(jīng)過4倍上采樣恢復尺寸。加入解碼器結(jié)構(gòu)緩解了模型對物體邊緣分割的弱特性,但決定圖像最終分割效果的還是原始圖像中物體的位置信息,當出現(xiàn)物體粘連和邊界信息較弱時,模型的最后分割結(jié)果表現(xiàn)就較差。
本文選擇在DeepLabv3+解碼器結(jié)構(gòu)中添加分數(shù)階(微分)滑動閾值邊緣檢測模塊FSTED(Fractional-Order Differential Slip Threshold Edge Detection module),模塊結(jié)構(gòu)如圖3所示。通過增強并捕獲圖像的邊緣特征,保留了原始編碼器中下采樣和空洞卷積對圖像的特征提取,經(jīng)特征融合后可以得到改善的分割結(jié)果。模型的pipeline如圖4所示。

圖3 分數(shù)階(微分)滑動閾值邊緣檢測模塊

圖4 結(jié)合FSTEDmodule的DeepLabv3+語義模型
較高的階次可以帶來強的邊緣信息,但容易引入過量噪聲,從而導致像素分類失敗;較低的階次對邊緣的增強不夠明顯,最后導致邊緣分割差強人意。而滑動閾值方法通過對輸入信號的每一個3×3像素矩陣進行判斷,選擇合適的分數(shù)階階次來完成濾波操作。接著,將用仿真實驗證明改進后的DeepLabv3+具有更強的噪聲適應能力和邊緣分割效果。
3 實驗部分
3.1 分數(shù)階(微分)滑動閾值邊緣檢測算子與經(jīng)典算子的對比實驗
對比實驗選擇邊緣檢測常用數(shù)據(jù)集BSDS500作為驗證數(shù)據(jù)集,該數(shù)據(jù)集共計500張彩色圖片,其中訓練子集200張,驗證子集100張,測試子集200張,對應提供了500張ground-truth邊緣標注圖(需要預處理)。圖片大小均為481×321。
評估指標包括錯誤率(FR)、漏檢率(FRR)、誤檢率(FAR)、真邊緣(TER)、偽邊緣(FER)五項,計算公式如下:
定義邊緣標注圖中標注點的像素集合set(a),背景像素點
集合set(g),預測像素集合set(b)。其中,φ(set(a))表示集合a的像素總數(shù)。
(9)
(10)
FR=FRR+FAR
(11)
(12)
(13)
優(yōu)秀的邊緣檢測算法應該體現(xiàn)在更低的錯誤率FR與更高的真邊緣率TER,輸出圖像的邊緣應細膩而連續(xù),且對噪聲的控制更強,具有一定的紋理和邊緣識別能力。
首先選取了三類不同特點的圖片作為輸入,實驗結(jié)果如圖5所示。
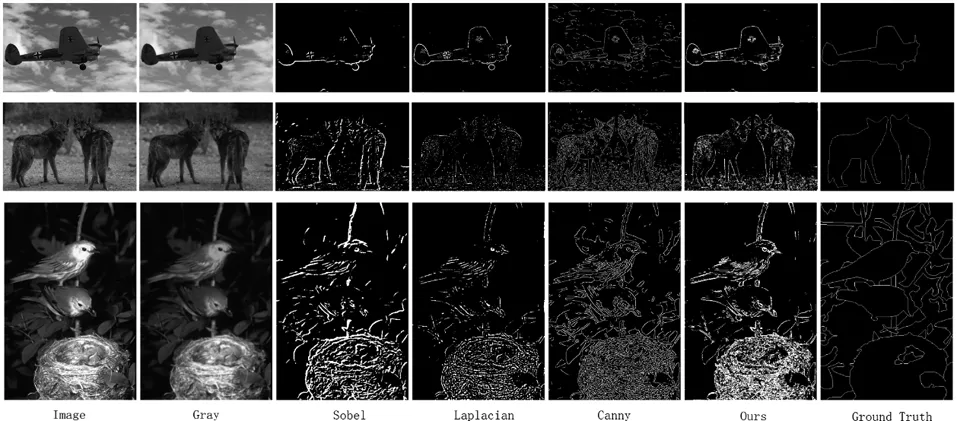
圖5 邊緣檢測輸出結(jié)果對比
第一類如行1所示,主體單一且突出,背景有部分紋理,邊緣/背景像素量比率(a/g)為0.647%,較為簡單。第二類如行2所示,雙主體且分離獨立,無粘連,與背景也很好區(qū)分,邊緣/背景像素量比率為1.44%,較為一般。第三類如行3所示,前景與背景交錯復雜,主體相對不夠突出,且紋理十分復雜,邊緣/背景像素比率為4.24%,較為復雜。通過計算,本文方法與經(jīng)典邊緣檢測算子的對比結(jié)果如表1所示。

表1 三種類圖像的邊緣檢測結(jié)果對比
實驗結(jié)果表明,本文方法對比經(jīng)典邊緣檢測算子,具有更好邊緣提取效果與抗噪能力,邊緣更加連續(xù),具有更小的錯誤率與更高的真實邊緣命中率。但是,當圖片紋理邊緣交錯復雜,且主體融于背景,連標注的邊緣圖都無法很好表達主體時,本文方法表現(xiàn)略差于canny算子,但依然能達到優(yōu)秀水平。
為驗證算子的魯棒性,將BSDS 500張圖片作為測試對象進行邊緣檢測取并取平均值,最終的實驗結(jié)果如表2所示。由此證明,本文方法綜合評價優(yōu)于經(jīng)典的一二階邊緣檢測算子,且在噪聲控制和紋理邊緣區(qū)分上有更好的表現(xiàn)。

表2 BSDS數(shù)據(jù)集邊緣檢測結(jié)果對比
3.2 改進的DeepLabv3+模型的仿真實驗
我們選擇PASCALVOC2012數(shù)據(jù)集作為改進模型的驗證數(shù)據(jù)集,該數(shù)據(jù)集用于語義分割的子類擁有1464張訓練圖片,1449張驗證圖片以及1456張測試圖片,包含20個前景分類和1個背景分類共計21類,數(shù)據(jù)集中大部分圖像的分辨率接近500×500。
實驗平臺基于Windows10操作系統(tǒng),CPU為Intel Xeon E3-1230 v5@ 3.40GHz,GPU為NVIDIAGeForceGTX970,使用TensorFlow框架來訓練模型。模型以Xception65作為backbone,選擇使用經(jīng)ImageNet、MS-COCO、VOC2012增強數(shù)據(jù)集預訓練的權(quán)重初始化模型[31]。綜合考慮平臺性能,在訓練參數(shù)選擇上將訓練crop_size調(diào)整為321×321,batchsize為2,采用poly學習策略[32],初始學習率為0.0001,衰減因子為0.1,空洞率選擇(6,12,18)。
平均交叉比(Mean Intersection Over Union,MIOU)是語義分割算法性能的標準評估指標,IOU和MIOU的計算方法為:
(14)
(15)
其中,k+1為包含背景的類別總數(shù),Pij表示將類別i預測為類別j的像素數(shù)量。
實驗結(jié)果如表3所示,改進后的模型通過對多類標簽的邊緣進行了優(yōu)化,特別是邊緣規(guī)則的標簽對象,提升十分明顯,綜合比對下新模型具有更好的分割性能。

表3 語義標簽分割結(jié)果對比
同時為了驗證本文方法中微分算子有效性,我們還將其他的經(jīng)典算子也加入對比實驗。對比結(jié)果如表4所示。實驗表明只有分數(shù)階微分算子達到了89%以上的MIOU,證實了選擇分數(shù)階微分算子作為邊緣提取模塊算子的唯一性。

表4 幾類邊緣檢測算子的分割對比實驗
最后,將本文方法與目前比較先進的語義分割算法在PASCAL VOC2012數(shù)據(jù)集上進行了比對,結(jié)果如表5所示。本文方法的語義分割MIOU為89.10%,達到了SOTA水平,圖像分割結(jié)果如圖6所示。

表5 前沿語義分割模型對比實驗

圖6 語義分割輸出結(jié)果對比
實驗證明,結(jié)合分數(shù)階(微分)滑動閾值邊緣檢測模塊的新模型在邊緣分割上表現(xiàn)更加優(yōu)秀,且一定程度上解決了相同類別的粘連問題。同樣不可忽視的是,新的模型也沒能解決DeepLabv3+分割失敗的案例(如圖6行5所示),模型依舊不具備對小弱目標的分割能力。
4 結(jié)語
本文提出一種滑動閾值的分數(shù)階(微分)邊緣檢測算子,通過滑動閾值方法解決了分數(shù)階微分算子最核心的階次問題,在保證噪聲控制和區(qū)分邊緣與紋理的要求下,能夠獲取更加完整且連續(xù)的邊緣圖像。接著,將此算子設計為邊緣檢測模塊對原始DeepLabv3+模型的邊緣分割效果進行了優(yōu)化,減少了下采樣操作和空洞卷積對邊緣分割的負面影響,獲得了邊緣優(yōu)化的分割效果。經(jīng)過對比分析,本文方法具備可行性與先進性,且作為一種解碼結(jié)構(gòu)設計的邊緣特征提取模塊,該方法可以適用于任意FCN族類的語義分割模型,具備了一定的可拓展性。在最后的實驗中,本文方法沒能解決原始DeepLabv3+模型對于小弱目標分割能力差的問題,該問題可以作為下一步的方向開展新的研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
