面向航空發動機多傳感器并行預測模型的設計與實現
2021-08-04 04:08:30李曉瑜姚艷玲唐曉瀾王書福
電子科技大學學報 2021年4期
陸 超,李曉瑜,姚艷玲,唐曉瀾,彭 宇,王書福
(1. 中國航發四川燃氣渦輪研究院高空模擬技術重點實驗室 四川 綿陽 621000;2. 電子科技大學信息與軟件工程學院 成都 610054;3. 西南石油大學計算機科學學院 成都 610500)
航空發動機是飛機最重要的部件之一,在飛機飛行發生的故障中發動機故障占相當大的比例,且一旦發生故障會致命。航空發動機中各傳感器的數據曲線反應了當前該發動機是否處于正常的工作狀態。因此,通過有效的手段監控航空發動機傳感器數據變化趨勢對飛機飛行安全有著重大的意義。
由于航空發動機傳感器數據屬于時序數據,因此對于航空發動機傳感器數據的預測可以看作是時序數據預測。傳統的時間序列預測模型主要為線性模型,如AR(autoregressive)、MR(moving average)、ARMA(autoregressive moving average)、ARIMA(autoregressive integrated moving average)等[1-8],針對平穩時間序列預測有著較好的效果。但大部分數據如股市數據、水文數據或者航空發動機傳感器數據都具有非線性特征,傳統的線性預測很難得到較好的預測結果。神經網絡和自適應算法等非線性模型的提出解決了此問題[9-20]。其中通過基于深度學習構建神經網絡模型因其自身強大的特征提取能力和自我學習能力,對具有非線性特征的時間序列數據的預測有著良好的效果。文獻[21]提出了基于LSTM的預測模型,對有明顯的非線性和不確定性波動的PM2.5濃度進行了預測。文獻[22]提出了一種基于注意力機制的CNN(convolutional neural networks)和LSTM(long short-term memory)的聯合模型,在真實的熱電聯產供熱時序數據上進行預測,相較于傳統的時序預測模型得到了更為精確的預測結果。
本文就發動機高壓壓氣機轉子轉速(N2)、發動機燃燒室燃油噴嘴壓力(Ptk)、發動機渦輪后溫度(Tt6)等航空發動機主要傳感器數據,使用滑動窗口算法構建數據集并對其進行標準化,并提出了一種基于Seq2Seq的面向航空發動機多傳感器預測神經網絡模型(aeroengine multi-sensor data prediction neural network, AMSDPNN)。Seq2Seq模型是基于編解碼器架構的常用于時序數據預測的神經網絡模型,其隱藏層可以由CNN、RNN(recurrent neural networks)、LSTM等構成,本文采用LSTM,最終以0.1%左右的均方誤差實現了對多個傳感器數據的預測。
1 理論基礎
1.1 長短時記憶神經網絡
由于數據是時間序列數據,因此在模型隱藏層的網絡模型選擇上優先考慮時序數據的首選神經網絡——循環神經網絡RNN[23]。這是因為RNN中的每一個Cell能夠記住時序數據中每一個時刻的數據信息,當前Cell的隱藏層不僅由該時刻的輸入決定,也由上一時刻隱藏層的輸出決定。通過這樣的方式,RNN能有效分析出時序數據的語義特征信息。一般的DNN不具備此功能。但RNN在長時序信息的保存和特征提取上表現并不好,容易產生梯度消失或梯度爆炸的問題,從而影響訓練效果。因此本文采用了RNN的一個變種模型,即長短時記憶神經網絡模型(LSTM)[24-25]。相較于RNN,LSTM使用了輸入門、輸出門和遺忘門來控制是否遺忘或保留序列中的歷史信息,很好地解決了長期依賴問題。其單元結構如圖1所示。
相較于一般RNN結構,每個循環網絡單元變得復雜了,這是因為多了3道控制門,分別是遺忘門、輸入門、輸出門。這里的“門”是帶有激活函數的全連接層,能夠選擇性地對信息進行過濾,激活函數一般是使用Sigmoid函數(圖1中σ表示),并且相較于原始RNN,LSTM多出了一個單元狀態變量C,用于保存長期的狀態,稱為單元狀態(cell state)。
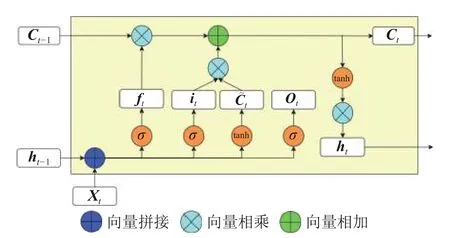
圖1 LSTM單元體結構示意圖
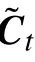
1.2 Seq2Seq網絡模型
上面提到的深度神經網絡模型不論是RNN還是LSTM模型,它們都可以生成與輸入長度一樣長的固定長度序列,如果想要獲得不定長的序列通常需要維度變換,效果不理想。為了解決不定長的預測序列數據的生成,文獻[24]提出了Seq2Seq模型,該模型采用編解碼器結構,可以采取CNN、RNN、LSTM等不同模型作為隱藏層。本文采用LSTM,其工作原理是首先輸入一個序列到編碼器的LSTM層,取其最后一個LSTM單元的輸出為編碼向量,該向量為二維向量,再將該特征向量復制生成與預測序列長度一樣長的三維特征向量輸入到解碼器的LSTM層中,最終得到預測序列向量。Seq2Seq模型中的主要架構編解碼器如圖2所示。
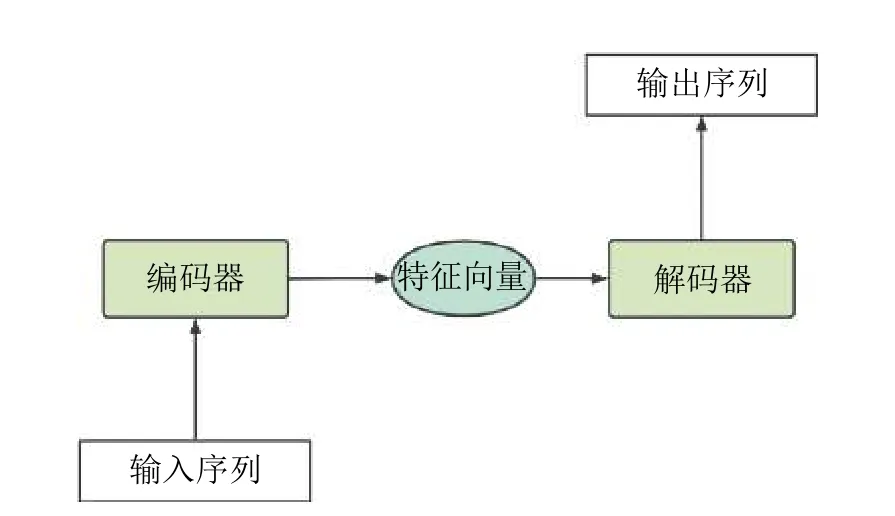
圖2 Seq2Seq模型中的主要架構編解碼器
2 數據預處理及劃分
2.1 數據預處理
本文采用的數據格式為時間序列數據,是在不同時間點上收集到的數據,簡稱時序數據。這類數據反映了某一事物、現象等隨時間的變化狀態或程度。對于一般時序數據預測模型的訓練而言,其數據集是由原數據集截取得到的一個個固定長度的子序列構成。本文采用滑動窗口算法實現了對航空發動機不同傳感器數據的子序列截取來構建模型訓練所需的數據集。該數據集包括由真實數據組成的待預測子序列和預測子序列,前者作為模型輸入序列,得到預測序列數據后,后者會作為用于計算與預測序列數據之間均方誤差的對比序列。其子序列個數由滑動窗口的滑動步長決定。為了能夠得到更多的訓練數據,本文設置滑動窗口步長為1。
2.2 數據集劃分及標準化
當使用滑動窗口成功構建數據集后,需將數據集劃分為訓練集和測試集。一般傳統的數據集劃分方式是先將數據集里的數據打亂隨機排序,再按照比例進行劃分,目的是防止模型訓練時過擬合以及能夠提高模型的魯棒性。但本文研究的傳感器數據屬于時間序列數據,其數據具有高度自相關的特性,前后相鄰的數據有著一定的關聯度,如果打亂訓練會引入來自未來的數據而導致模型容易發生嚴重的過擬合現象,從而影響訓練效果。因此,本文劃分數據集的方法是將選擇一個合適的時間點,取該時間點前的來自過去的數據作為模型的訓練集,時間點后的來自未來的數據作為模型的測試集,按照訓練集和測試集4∶1的比例進行劃分。
最后在劃分好訓練集和測試集后還需要標準化處理。目的是消除由于量綱不同、不同傳感器數值范圍差距過大而引起的誤差,使其有利于學習率的調整,特別是在尋找模型損失函數最優解的過程中避免梯度更新時帶來數值問題,從而提高模型的訓練效果。一般情況下,如果數據沒有進行標準化,會因為數據中不同特征值的量綱差距過大,從而導致在進行梯度下降時,梯度的方向會偏離最快下降方向,使訓練時間變得很長。而在數據標準化后,其模型目標函數呈現會變“圓”,這樣梯度的下降方向能更貼近理想的最快下降方向,便能更快地找到最優解。為了防止在數據標準化的過程中引入未來數據導致訓練時發生過擬合現象,本文對數據進行標準化所用的均值和標準差均來自訓練集。
3 面向航空發動機多傳感器數據預測模型
本文針對航空發動機多傳感器數據預測多維多步預測問題,提出了一種基于Seq2Seq的多傳感器數據預測神經網絡模型(AMSDPNN),實現了航空發動機多傳感器數據的提前預測。模型的總體結構如圖3所示。
圖3 AMSDPNN模型的整體結構
將奧卡姆剃刀原理延伸到深度學習模型的構建上,選擇適當復雜程度的模型能有效地防止過擬合,得到滿意的效果。基于本文模型的Encoder和Decoder模型都由一層LSTM層構成,其中間結果為編碼器中最后一個LSTM單元的輸出向量,而解碼器的輸入則都為該中間輸出向量,且解碼器的輸出能夠根據需求輸出對應時間步大小的矩陣向量,最后通過一層全連接層得到與需求輸出相對應的特征個數的預測序列數據。
而在模型的激活函數選擇上并沒有使用如Relu、Sigmoid、Tanh等激活函數,而是直接輸出值。這是因為首先在LSTM層中本身默認使用了Tanh函數進行最后輸出的激活,因此并沒有再次使用Tanh函數和與之類似的Sigmoid函數;Relu函數本身常用于避免深度神經網絡訓練中經常出現的梯度消失問題,而本文模型是屬于淺層神經網絡,故沒有采用。
關于損失函數的選擇上則采用均方誤差函數MSE。這里假設預測的序列數據為yp,與之對應的真實數據為yi。此時損失函數L的表達式為:
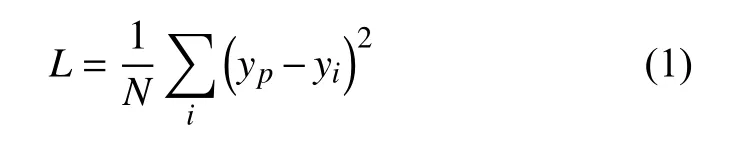
選擇AMSDPNN模型來搭建時序預測模型,相較于傳統的基于LSTM的時序預測模型有兩點優勢:1) 基于編解碼器結構的Seq2Seq模型輸入和輸出都是序列且長度可變,而傳統的LSTM模型通常需要將輸出的矩陣向量經過一系列的矩陣變換才能做到;2)1.2節提到的解碼器工作時每個LSTM單元里都會帶入編碼器輸出的編碼向量,其編碼向量可以看作是包含了輸入序列全部語義的語義向量,能夠在解碼器生成預測序列時充分吸納上一序列的語義信息,得到更好的預測結果。
4 實驗與分析
4.1 實驗環境
本文實驗所使用的操作系統為Windows10,CPU為i7-6700K,主頻4 GHZ,GPU型號GTX 1060,顯存6 GB,電腦內存16 GB。主要采用的編程語言為Python3.6,神經網絡結構的搭建選用Keras2.2.3。
在數據集方面,本文以多型渦扇發動機在空中慣性起動、空中風車起動、進氣畸變條件下的地面起動,及起動失速/喘振等12個不同場景下,約30萬條故障數據作為本文模型的訓練及測試數據。
4.2 試驗過程及分析
模型采用的訓練方法是基于批次的梯度下降法,批量大小根據整個數據集的規模而定,整個試驗采用Python的第三方工具庫Matplotlib對整個訓練過程進行可視化。
使用梯度下降法時,根據訓練效果來控制學習速率是模型能否訓練成功的關鍵。本文選取了Adadelta、Adam、Adagrad、RMSprop這4種優化算法進行比較,每個優化算法在整個訓練過程中的Loss曲線如圖4所示。
從圖4可以看到,相較于其余3個優化算法,Adam優化效果最好,其損失函數Loss能降至0.01左右,且收斂過程也較為穩定,故在模型搭建時,選擇Adam作為模型的優化函數。
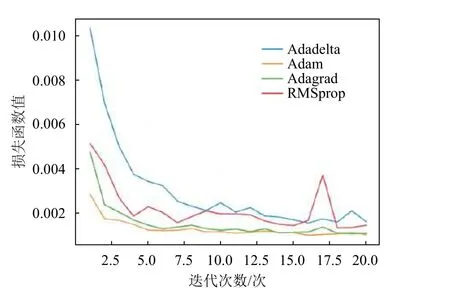
圖4 不同優化算法的loss曲線對比
4.3 試驗結果及分析
模型訓練完成后,某發動機發生喘振時多個傳感器的真實數據曲線以及預測數據曲線對比如圖5所示。
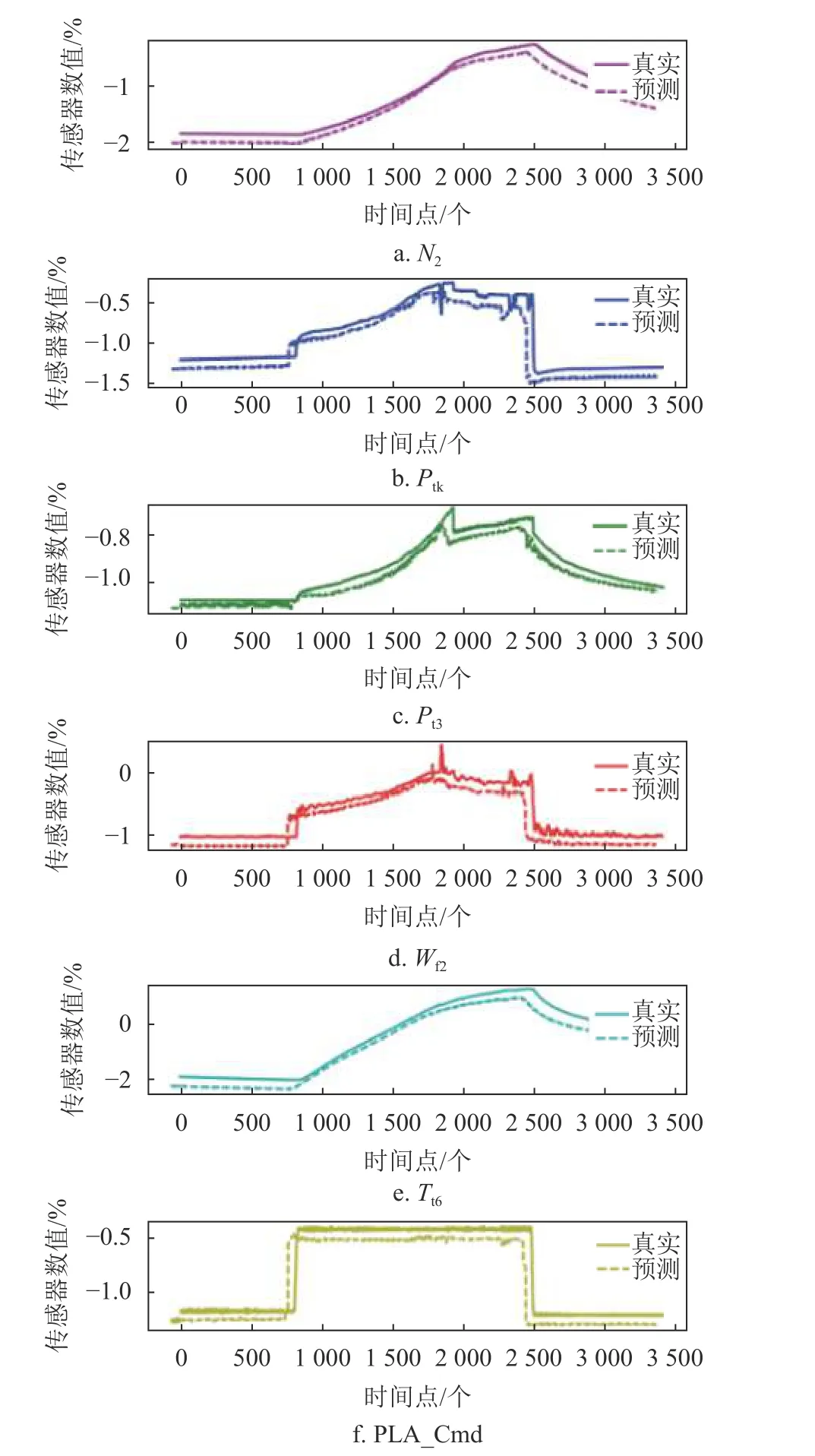
圖5 某發動機真實數據曲線與預測數據曲線對比
為了對模型的最終效果進行整體評估。本文以均方差MSE作為評估指標,將本文模型AMSDPNN與其他神經網絡CNN、RNN、LSTM的測試結果對比,結果如表1所示。

表1 各個算法的數據預測誤差對比
由表1的實驗結果可知,AMSDPNN模型相較其他3個模型,其預測誤差更小,說明使用基于Seq2Seq的AMSDPNN模型數據預測效果更好。
4.4 預測耗時評估
本文模型的最終目標是能夠預測發動機多傳感器的未來數據。因此需要通過模型的單次預測耗時計算出可以預測多長時間之后的數據。經實驗得到模型單次數據預測的耗時平均約為80 ms,由于預測序列的時間跨度達到了400 ms,因此經過計算模型可以提前預測320 ms后發動機的傳感器數據,如圖6所示。
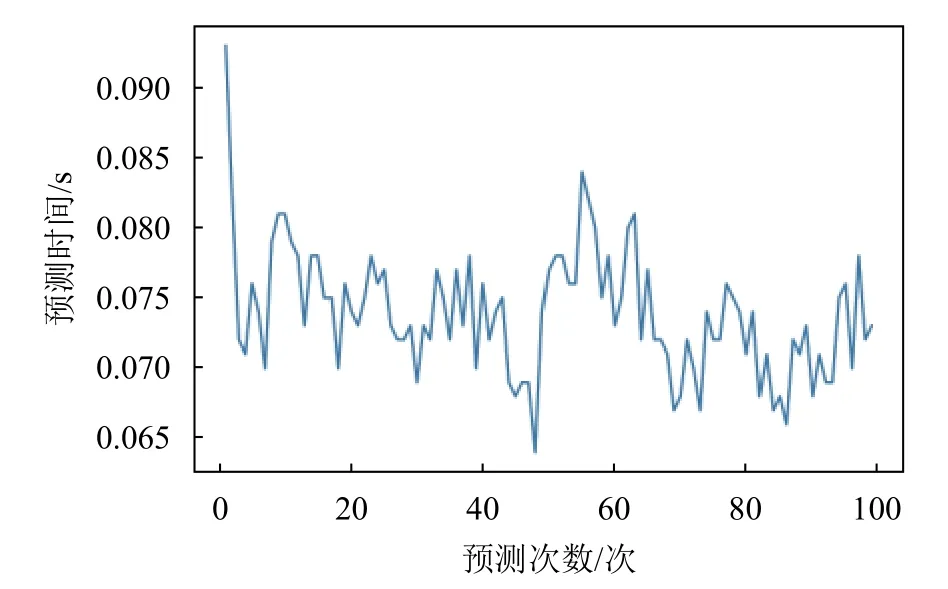
圖6 AMSDPNN模型單次預測耗時曲線
5 結 束 語
本文基于航空發動機傳感器數據集使用滑動窗口算法截取子序列構建時序數據集,并對其進行標準化。提出了一種面向航空發動機多傳感器數據預測神經網絡模型AMSDPNN,該模型主要基于Seq2Seq模型構成,其隱藏層使用LSTM網絡結構。實驗結果表明,該模型能夠以極短的時間預測出航空發動機未來的傳感器數據。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
汽車維修與保養(2021年8期)2021-02-16 00:28:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
汽車維修與保養(2020年11期)2020-06-09 05:42:06
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
汽車與新動力(2015年1期)2015-02-27 12:11:01
汽車與新動力(2014年2期)2014-02-27 12:10:15
汽車與新動力(2013年5期)2013-03-11 16:08:17
