并行程序性能和功耗的測試分析工具研究
2021-08-02 03:35:26潘曉東孫曉樂鄭文旭
計算機技術與發展 2021年7期
潘曉東,孫曉樂,鄭文旭,吳 丹
(國防科技大學 計算機學院,湖南 長沙 410073)
0 引 言
高性能計算(high performance computing,HPC)現在已經成為促進軍事進步、科技創新和經濟發展的重要手段,無論是科學計算還是新興的人工智能都對HPC的性能提出了新的更高的要求。隨著Dennard縮放效應的失效,處理器單核的頻率到達極限,多核、眾核并行以及異構并行成為HPC發展的趨勢,同時隨之不斷增長的能耗成為阻礙HPC發展的重要因素[1],HPC開始轉向高能效并行方向。
HPC能量有效性提高的策略大致可以分為系統和應用兩方面。從系統角度就是調節與運行相關的系統硬件參數或者軟件環境參數,例如靜態的基礎架構節能、電路的低功耗設計、運行時基于硬件的參數調優[2];以及系統各部件的動態電源管理技術(DPM),包括任務映射(mapping)、器件動態休眠、動態電壓頻率縮放(dynamic voltage and frequency scaling,DVFS)[3]等。而從應用角度而言是在應用執行之前通過對并行程序本身進行優化來達到節能的目的。包括常用的軟件代碼優化、編譯優化和運行庫優化[4]。
這兩方面策略的制定,都需要對應用進行性能和功耗的檢測分析,并作為基準對策略部署后的情況進行對比,以此來迭代修訂策略,同時在HPC運行當中往往也需要對性能和功耗數據進行檢測匯總。并行計算的性能檢測分析與體系結構、并行算法、并行程序設計一同構成了并行計算研究的四大分支。
長期以來國內高性能計算的基礎并行環境落后于計算機系統的發展[5],軟件的性能分析工具(performance analysis tools,PAT)也是如此。國內出現過一些并行分析工具,如中科院的ParaVT、清華大學的VIMP、曙光上的Para Vision以及面向云計算資源監控的并行科技的Paramon,盡管使用分析工具對于理解HPC應用中的程序行為、性能瓶頸和優化潛力很有幫助,但由于使用太復雜或者是售價和推廣的原因,這些工具并沒有流行起來。通過調查,發現許多實驗室在進行性能和功耗檢測時,最常用的方法仍是手工插樁(使用時間戳)輸出日志,再進行統計后處理的方法,這種方法雖然簡單直觀,但是工作量大,并且得到的信息量過少,缺少對軟件運行的整體認識,后續處理也相對困難,給并行程序的能耗和性能調優帶來了不便。
隨著HPC系統復雜性的提高,以及大規模應用軟件開發的需要,手工檢測和分析的方法已經不能達到要求,因此該文介紹了性能和功耗檢測的原理和相關工具,并對4類跟蹤和分析工具進行了對比分析,以便在后續工作中使用。
1 性能和功耗檢測原理
針對不同平臺和不同編程模型,性能和功耗檢測也有所區別。并行程序的編程模型分為消息傳遞和共享主存兩種模型,消息傳遞接口(message passing interface,MPI)和OpenMP(open multi-processing)已經成為兩種模型的代表,而異構計算引入了在加速器上使用的和OpenMP類似的CUDA(compute unified device architecture)、OpenCL(open computing language)以及OpenACC(open accelerators)。現在的并行性能和功耗檢測多集中于采用MPI、OpenMP和CUDA,OpenCL和OpenACC在國內超算集群中應用較多,但目前缺乏成體系的檢測工具。
1.1 性能檢測
計算機的理論峰值性能是所有處理器性能的總和,而實際性能受限于系統和軟件,使得程序執行過程中集群有很多處理器處于松弛狀態(即空閑或阻塞),這樣性能無法達到最優,松弛狀態的功耗也就浪費了。如果不能掌握程序的計算性能、通信狀況、處理器狀態、內存狀態等性能數據,對程序的優化調整就無從下手。HPC程序測試中通常采用動態測試的辦法,在中小規模核心數目上進行實際運行并收集性能數據,經過整理得出分析結果匯報給使用者。
性能檢測一般分為確定數據采集種類、獲取和記錄數據、數據分析表達幾個步驟。性能檢測方式有追蹤(tracing)和輪廓(profiling)兩種方式[6]。前者采用插樁技術(instrumentation),對應用程序進行修改,在程序中插入附加指令,詳細記錄程序執行過程中發生的事件,從而進行事件跟蹤(event-based tracing),通過日志文件記錄,之后可以用時間軸的方式來呈現結果,幫助用戶了解程序執行過程中的詳細特征。后者的典型形式是對路徑調用(call-path)信息或者硬件計數器進行統計,即在并行程序執行過程中,定期對程序當前執行的指令和對執行過的函數堆棧進行回溯,得到子程序、基本塊和語句的執行時間和執行次數等信息。
性能檢測的步驟如圖1所示。
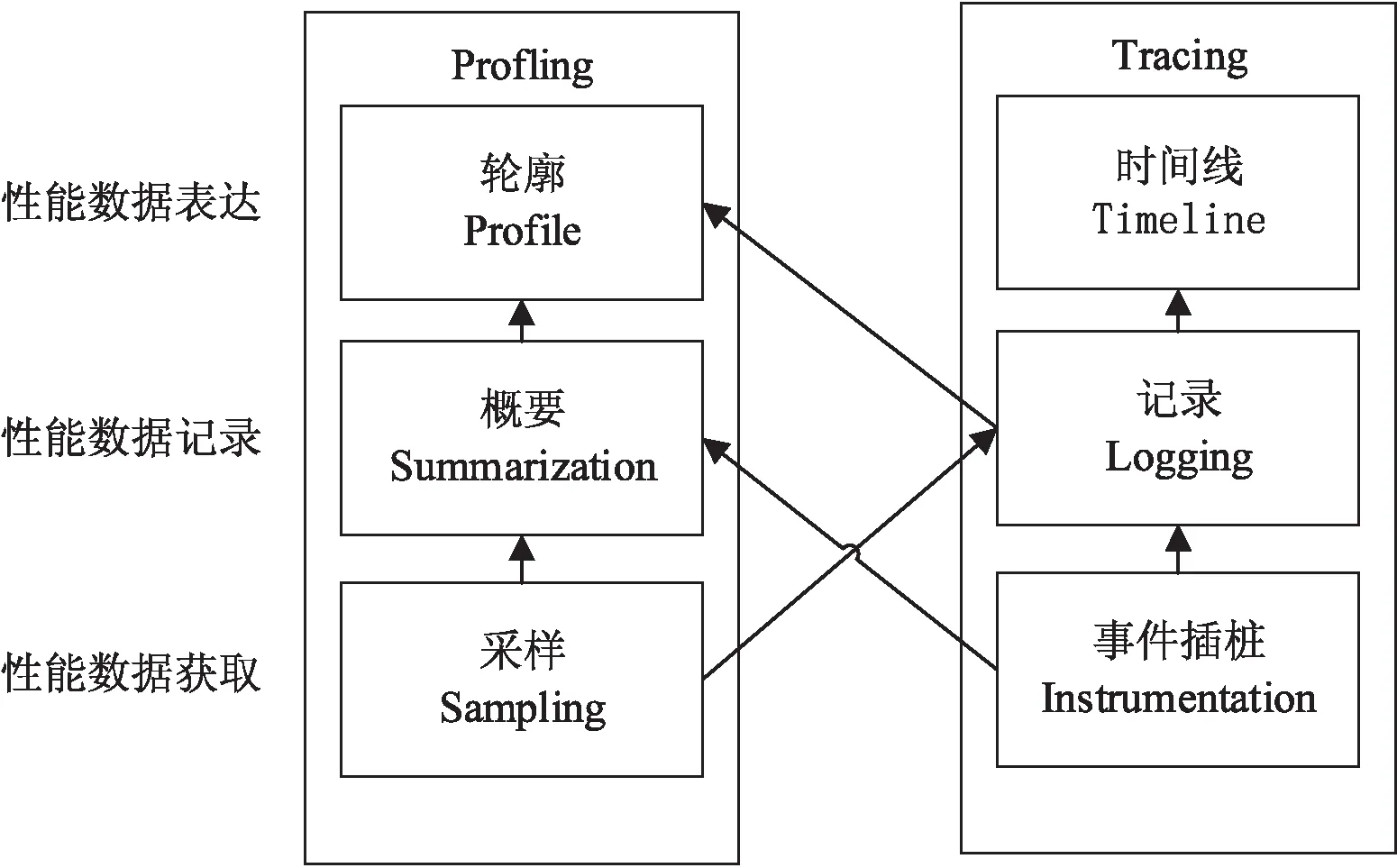
圖1 性能檢測的三個步驟
1.1.1 數據選擇
并行程序一般用運行時間、加速比和并行效率來衡量性能。因此通常會選擇MPI通信時間、通信量、程序各階段運行時間,以及各硬件性能計數器數據作為需要采集的數據。
1.1.2 數據獲取和記錄
數據獲取主要有兩種方法,其中插樁技術也被稱為軟件打點技術,目的是通過在程序中插入指令來獲取程序的狀態,可以分為三種:(1)源代碼插樁,在程序源代碼或庫的源代碼中直接插入性能分析函數,這種最為直觀,對于實驗中使用的測試程序的源代碼可以根據語法和語義信息,準確進行標記。由于手工插樁較為繁瑣,因此也可以采用自動化分析插樁工具如Program Database Toolkit(PDT)來減少工作量;(2)二進制插樁,通過對靜態或者運行中的可執行文件進行二進制代碼插入,不需要重新編譯程序,但是插樁的開銷較大,主要工具有Pin和Dyninst;(3)庫替換(instrumentation-library interposition),使用帶有測試接口的.so動態庫調用替換I/O、MPI、CUDA、OpenCL的API以及內存分配/釋放例程,通過攔截應用程序對共享庫的函數調用,來獲得調用數據。
而另一種是采樣,是一種統計方法,按照一定的周期程序的性能數據進行采樣和記錄,據此來分析應用程序部分代碼的性能特征,以代表整個應用程序特征。采樣不需要對應用程序做修改,操作簡單,開銷小,但是不能獲得應用的完整性能視圖,并且很難確定合適的采樣頻率。
在獲取性能數據的過程中也會根據檢測目的來進行選擇,或者是同時使用兩種采集方式。在采集的同時會將采集到的數據記錄到特定格式的文件中去,以便分析工具進行處理。記錄的形式一般分為記錄的類型、記錄的時間戳、性能計數器的讀數等。
1.1.3 數據表達
數據表達也就是將采集到的數據通過報告或圖表的方式展示給用戶。根據數據分析整理的時機可以分為在線分析和離線分析,在線分析就是在程序運行時實時分析程序的運行狀態和性能特征,將分析結果實時展現給用戶;離線分析是在程序執行期間收集性能數據并進行存儲,在程序運行完畢后,基于程序運行時的全部性能數據進行分析和展示。由于當前高性能并行程序的規模大,運行時間較長,需要對多節點多方面的性能數據進行綜合分析,在線分析無法滿足要求,因此離線分析是實際中常用的研究方法。
1.2 功耗檢測
由于高功耗對高性能計算發展的制約,以及帶來的高昂運行和維護成本,對HPC以及程序進行功耗測量,以掌握其工作情況也變得相當重要。早期的功耗研究使用基于模擬器的測量分析,可以在硬件設計階段用來平衡性能和功耗[7],但由于精度低和速度慢,實際難以推廣使用。實際使用的功耗檢測方法一般分為兩類[8]。
(1)基于設備直接測量結果的硬件測量法。是指用各種外接或者集成的傳感儀器設備來測量硬件設備的電流和電壓,接著使用測量值來計算被測對象的功耗值,如使用智能配電單元(intelligent power distribution units,iPDU)、傳感器電阻、Plug-wise智能插頭、Watts up pro功耗計、IPMI(intelligent platform management interface)、數字萬用表等[9]。這種方式精度很高,但是缺點也很明顯,如基于硬件的測量接口各異,數據只能夠離線記錄到運行機器之外的設備上,不能夠對部件內部的更小器件進行功耗分析和測量,成本較高。
(2)基于性能事件或者寄存器讀數的軟件方法。操作系統提供的系統事件可以反映軟硬件狀態,并且現代主流的處理器中都集成了硬件性能監控計數器(performance counter,PMC),可以用來監控硬件相關活動事件的發生次數,更直觀反映其硬件使用情況[10]。因此結合系統事件和PMC事件的讀數來建立模型,可以做到實時性和非侵入性,現在使用的較多[11]。常見的采用軟件方法的功耗檢測工具有PowerTOP、Likwid-Power meter、PAPI。
其中PAPI(performance application progra-mming interface)[12]使用更為廣泛,PAPI是田納西大學開發的,可以在多種平臺上對硬件性能計數器進行訪問的標準接口,可以監測和采集由計數器記錄的處理器事件信息。對程序運行中帶來的功耗,更多關注處理器,加速器及內存的動態功耗。PAPI既提供了程序調用接口,也提供了一些組件的PAPI-C接口對上述部件進行功耗檢測,如NVML(Nvidia management library)、RAPL(running average power level)、libmsr的接口組件。可以在外部工具中調用PAPI中的這些組件接口來獲取功耗值,因此為性能和功耗的協同檢測提供了可能,例如TAU、Extrae就已經支持在追蹤性能數據的時候調用PAPI來提供性能和功耗數據。
2 性能和功耗分析工具
性能和功耗的檢測數據采集之后,往往需要某種方式來呈現給用戶,以便用戶從大量數據中找出規律,發現程序性能的瓶頸和能量優化的機會。這樣就需要一些工具來對數據進行處理,工具應當具有可視化、易操作等特性。由于當前沒有比較完善的能耗可視化工具,通常是調用PAPI或者第三方硬件儀器的接口來采集能耗信息,并且在性能可視化工具中進行展示,因此這里選用了幾類常見的支持PAPI的性能可視化工具。
2.1 基于Score-P檢測的工具
由于傳統的性能測試工具采用了各自不同的測量系統和輸出格式,給使用帶來不便。但是各種測量工具在MPI函數插樁、事件記錄和數據記錄格式上往往具有相同的特征,這給統一測量工具提供了可能。針對這個問題,SILC(scalable infrastructure for the automated performance analysis of parallel codes)項目開發了Score-P[13]測量系統,采用了開源數據記錄格式CUBE4和OTF2(open trace format V2)[14]。Score-P支持MPI框架,支持CUDA、OpenACC和OpenCL,也支持使用PAPI來獲得硬件性能技術器和功耗信息。并得到了Vampir、Scalasca、TAU和Intel Trace Analyzer等分析軟件的支持(見圖2)。
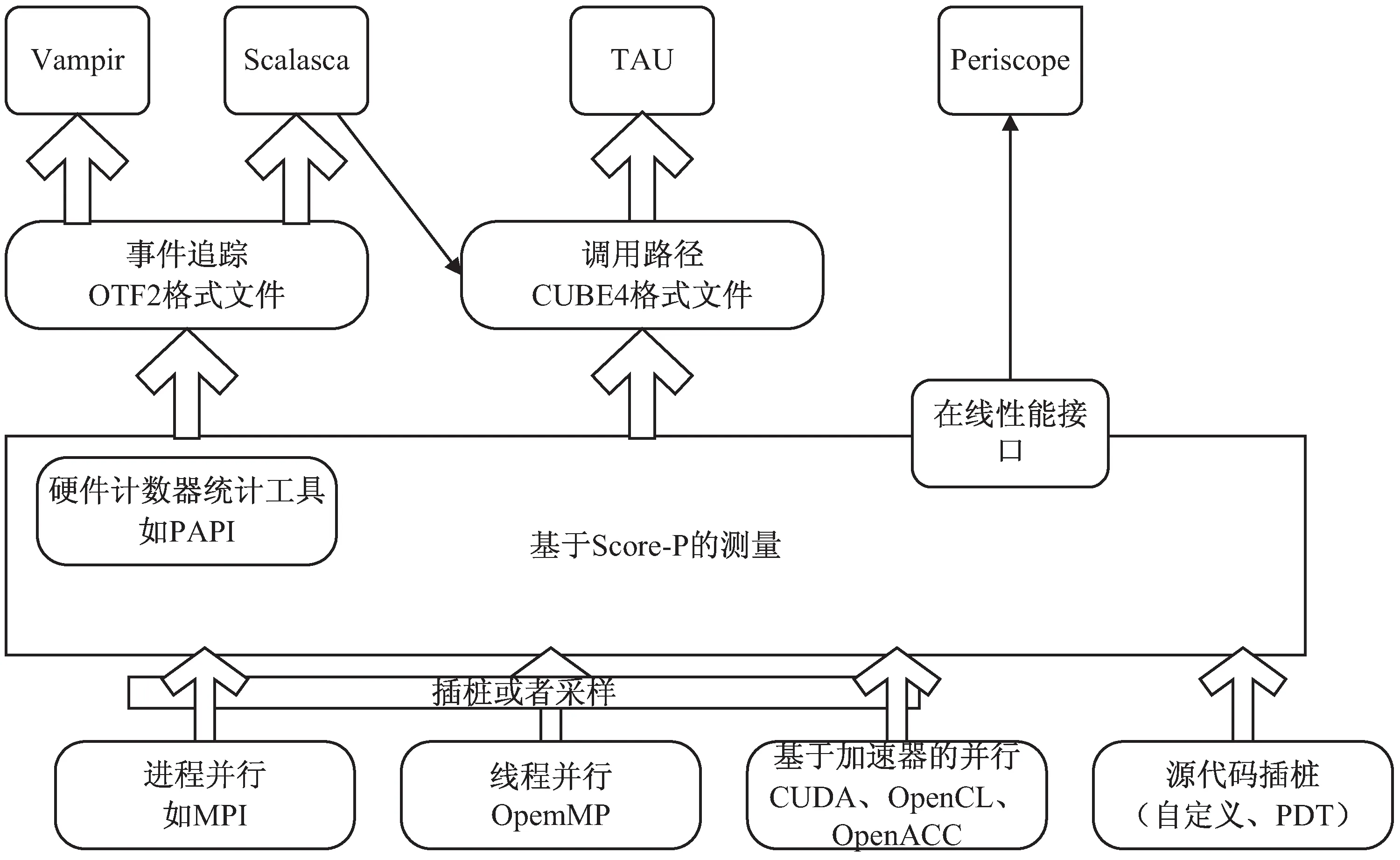
圖2 基于Score-P檢測工具
Scope-P需要對用戶程序在編譯和鏈接時進行插樁,需要在相應命令前添加scorep前綴來替換成Score-P的插樁命令,如mpicc就需要更改為scorep mpicc。通過插樁后生成的可執行程序通過mpirun或者直接執行完成后,就會生成profile文件和trace文件,以供下列幾種工具分析。Score-P支持C/C++和Fotran,但是安裝和參數設置較為繁瑣,并且不能對未使用Score-P編譯的二進制可執行程序進行檢測。
2.1.1 Vampir
Vampir(visual and analysis of MPI resource)是由Pallas GmnH公司開發的商業工具,主要用來分析并行程序執行過程中的MPI調用,以便了解通信模式、發現程序熱區和性能瓶頸,可以提供事件和通信時間的詳細時間視圖、程序執行分析、通信操作的統計分析等功能,廣泛應用于許多超算中心。Vampir提供了時間線視圖,MPI通信矩陣,性能計數器視圖和MPI信息詳情。
Vampir的安裝和使用是在基于Score-P的可視化分析工具中最為方便的,并且提供了上述豐富的分析功能,可以直觀看出程序的MPI詳細通信過程。缺點是只針對MPI,沒有其余函數調用的分析。
2.1.2 Scalasca
Scalasca(scalable performance analysis of large scale applications)是由德國于利希研究中心以及模擬科學學院開發的開源工具,通過Scout中預定義的低效應用程序行為模式,利用自動分析工具識別MPI中的不平衡到達(unbalanced process arrival,UPA)等問題。Scalasca更多像是一個列表式的分析工具,分析出結果之后,輸出給CUBE-GUI顯示分析結果,并可以通過輸出Cube4格式到Vampir或TAU中來進行可視化,Scalasca和Cube不支持時間線視圖。
2.2 Intel Parallel Studio
Intel公司的Parallel Studio也是普遍使用的商業并行程序性能檢測和分析工具套件,ITAC(Intel trace analyzer and collector)是MPI通信的分析工具,Vtune Amplifier是其中的多線程性能分析組件。
ITAC主要關注基于MPI的通信,該部分提供基于事件的追溯機制,提供計算能力統計、線程跟蹤功能,對于資深的開發人員還可以通過插入二進制指令對MPI函數調用以及MPI通信信息的參數進行動態調試。ITAC支持底層MPI和硬件配置的調優,并且可以進行MPI正確性的檢查,主要用于跨節點的并行程序通信性能分析。
Vtune針對程序運行過程中產生的事件計數,可以進行多線程的代碼分析、堆棧采樣和硬件事件采樣,然后利用二進制文件中的編譯信息將樣本統計數據對應到進程、線程、函數、反匯編代碼和源代碼中[15]。Vtune通過Intel處理器上的片上性能監控單元,可以搜索由于緩存失效和錯誤分支預測而導致的系統停滯,幫助用戶識別性能瓶頸。Vtune主要用于各節點內性能分析。
Intel Parallel Studio在并行程序應用中也較為廣泛,但是缺乏對各類非MIC加速器和非Intel x86處理器的支持,并且由于是商業軟件,售價高昂,不利于在大規模集群上進行使用。
2.3 Nvidia性能分析工具
在進行基于CUDA的并行程序開發時,往往會使用Nvidia公司的開發工具和性能分析工具,如源代碼的可視化CUDA開發環境Nsight、可執行文件的性能可視化分析工具Visual Profiler(NVVP)。工具對Nvidia的API支持最為全面,主要用來精確定位CPU和GPU之間的負載不平衡或GPU上的性能瓶頸,以優化程序的配置。但是對于多節點的大規模并行并不適用,通常需要和MPI分析工具配合使用。可以查看插樁開銷、GPU函數、主從設備交換等時間線,并可以通過Nvidia Tools Extension插樁來查看CPU上具體函數的時間線視圖,同時提供GPU的功耗和能耗的輸出。優點是和本公司的計算卡結合緊密,在GPU異構計算上結合開發、調試和性能分析于一體,使用方便。缺點是只支持本公司的計算卡,并且對于主設備如CPU上運行的非OpenACC程序,就只能使用工具進行手動插樁。
2.4 BSC Tools
BSC Tools是一個由西班牙巴塞羅那超級計算中心開發的開源工具集,主要由Paraver(可視化分析器)、Extrae(測量工具)組成,還有一些額外的集群性能分析工具。Extrae使用不同的插入機制(庫替換、手動插樁、dyninst二進制插樁)將探針注入到目標應用程序中,以便收集性能指標。Extrae還使用PAPI接口來收集有關硬件性能的信息,允許在并行調用發生時捕獲此類信息,而且還可以在用戶例程的入口和出口點捕獲這些信息。Paraver是一個非常強大的開源可視化分析工具,該工具主要是支持用戶自定義模式和全局概覽。Paraver通過時間線和概要統計來分析數據記錄中的運行時間、函數調用、MPI以及硬件使用情況、PAPI事件、功耗等信息,并且通過自定義的cfg配置文件,可以靈活地對輸出形式進行配置,可以將某幾項指標綜合輸出展示[16],如將指令計數和周期計數進行處理,可以輸出IPC(instructions per cycle)數據。所得到的每種事件的數據都可以導出為csv格式由其他程序進行處理。
BSC Tools作為一款開源工具,在歐洲的巴塞羅那超算中心的多個集群長期開發使用,具有很多優點。(1)安裝簡單,配置靈活。安裝通過一條指令就可以配置好依賴環境,并且Paraver有win和mac系統下的安裝包,可以將跟蹤數據導出后處理,也可以直接在Linux下使用官方已經編譯好的壓縮包,直接解壓使用。Extrae通過在xml文件中簡單修改參數就可以進行配置,其集成的庫劫持和二進制插樁的功能可以使得在沒有源文件的情況下,對目標應用進行性能和功耗的跟蹤分析,在集群實際使用中更為靈活。并且Paraver中可以自由定制多種cfg文件,對采集的數據進行定制化輸出;(2)支持多種平臺,除了x86外,BSC Tools支持含arm和power,并且由于其對OpenCL的支持,理論上對CPU+xeon phi、CPU+FPGA、CPU+DSP都可以進行跟蹤分析。但是由于配置過于靈活,BSC Tools并沒有提供詳細的使用引導,其中Paraver的用戶說明長期未更新,已經失效。
2.5 對比分析
通過對上述工具的功能和特點進行對比,見表1,可以看出對于并行程序,作為硬件廠商自產的性能分析工具,Intel和Nvidia的工具套件對各自的產品針對性更強,功能和可操作性也更勝一籌,但是也由于其閉源,不可能移植到其他平臺上,也就給自主的硬件平臺或者強調自主可控的應用場景帶來了困難。

表1 幾種性能功耗測量工具的對比
Score-P對編程框架的支持最為廣泛,提供了對CUDA、OpenACC和OpenCL的支持。但是其安裝和配置較為復雜,并且需要對源程序進行修改,不能對已經生成的可執行文件進行性能和功耗的分析。在基于Score-P的分析工具中,Vampir使用最為方便,但是只有商業授權才可以使用完整功能。TAU的功能最強,提供了豐富的說明文檔,但是安裝使用較為復雜。Scalasca提供了中文說明文檔,但是本身缺乏時間線視圖的輸出。
BSC Tools的使用很靈活。Extrae可以支持arm平臺,并且也提供對python程序的插樁跟蹤。官方提供了各種編程框架的跟蹤樣例,可以直接拷貝到需要測試的場景,經過簡單修改即可使用。在Paraver中預制了大量的cfg配置文件,在進行基本測試上非常容易上手。但是如果要進階使用,自己定制跟蹤和分析時,配置較為繁瑣,也缺乏說明文件。
綜上所述,幾種工具各有優缺,在實際應用中,可以相互結合使用,對于Intel和Nvidia平臺無疑是官方軟件的支持最為強大,可以給出最全面的分析報告。對于定制化集群平臺,靈活配置Score-P和BSC Tools可以為優化工作帶來很多便利。由于許多實驗室集群中并沒有專用的成套工具,因此使用開源工具也是一個很好的辦法。BSC Tools、Score-P都能在Github上找到完整的源代碼,可以對不同的硬件平臺進行分析和移植,也可以作為基礎進行二次開發,使其更適用于特定應用場景。
3 結束語
由于高性能并行程序在性能和功耗上有更高的需求,因此要對其進行相關的檢測分析。由于傳統較多使用手動插樁輸出的辦法已經不太適宜當前的高性能并行軟件調優工作,因此該文以并行程序的性能和功耗檢測為主線,對目前國外常用的性能和功耗檢測工具進行了對比介紹,討論了其優缺點,以便后續使用,并希望能激發相關研究人員使用這類工具來進行軟硬件優化的興趣。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
人大建設(2019年12期)2019-05-21 02:55:44
電子制作(2018年18期)2018-11-14 01:48:24
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
山東工業技術(2016年15期)2016-12-01 05:31:22
海峽科技與產業(2016年3期)2016-05-17 04:32:12
