知識圖譜在智能問答中的應用研究
2021-08-02 03:48:50謝藝菲潘志松
計算機技術與發展 2021年7期
盧 琪,謝藝菲,謝 鈞,潘志松
(中國人民解放軍陸軍工程大學 指揮控制工程學院,江蘇 南京 210000)
0 引 言
智能問答(question answering,QA)是自然語言處理(natural language processing,NLP)領域一個重要分支,經過多年的發展,已逐漸成為NLP中最為火熱的研究方向之一。智能問答最早可以追溯到二十世紀五六十年代的圖靈測試,要求計算機在有限時間內回答用戶給出的一系列問題,并且要讓用戶做出超過30%的誤判。第一個問答系統[1]一般認為是誕生于20世紀60年代的“Eliza”,用于對精神病人進行心理治療。
按照數據可以把問答分為三種類型:
(1)基于文本問答:也稱為機器閱讀理解式(machine reading comprehension,MRC)問答,每個問題對應若干篇非結構化文本數據,然后從文本數據中檢索和抽取答案;
(2)基于知識庫問答:也稱為知識圖譜問答(knowledge graph question answering,KGQA),即直接從構建好的結構化知識庫中檢索答案;
(3)基于社區的問答:用戶生成的問答對組成了社區問答的數據,例如百度知道、搜狗問答、知乎等論壇。
該文在簡單介紹知識圖譜和智能問答的基礎上,總結歸納了知識圖譜用于智能問答系統的研究進展和挑戰,并討論了新興的研究趨勢。
1 知識圖譜
知識表示是知識組織的前提和基礎。語義網便是早期知識表示的代表,它通過萬維網聯盟(world wide web consortium,W3C)標準來擴展萬維網,使之變成一個數據網。
1.1 知識圖譜問答
知識圖譜問答的關鍵在于把用戶的自然語言問題轉化為機器可以理解的形式查詢。傳統的知識圖譜問答方法主要包括三種:
(1)基于語義解析的方法:把用戶給出的自然語言問題轉化成邏輯形式,在知識圖譜上查詢;
(2)基于模板的方法:根據模板提取問題中的信息表示成特征向量,用分類器對問題特征向量進行篩選,得到答案;
(3)基于向量建模的方法:把問題和候選答案用分布式表示,用分布式表示訓練模型,使問題和正確答案的分數盡可能高。
隨著深度學習領域不斷發展,神經網絡在KGQA中也取得了非常優秀的性能,得到廣泛關注。
1.2 知識圖譜和KGQA數據集
近年來出現眾多大型的開源知識圖譜,推動了知識圖譜領域的快速發展。利用這些開源的知識圖譜構建出各種大規模KGQA的數據集,也極大地促進了知識圖譜問答的發展。該文將知識圖譜數據集根據規模、語言、來源等特征進行整理,如表1所示。將知識圖譜問答數據集根據規模、有無形式查詢、來源等特征進行整理,如表2所示。這些數據集彌補過去數據集缺陷的同時,也提出新的挑戰,為KGQA發展提供了研究基礎。

表1 知識圖譜數據集匯總

表2 知識圖譜問答數據集匯總

續表2
2 智能問答
近年來智能問答取得了很大的發展,很多智能問答系統走進了人們的生活,為人們帶來了極大的便利。蘋果公司研發的智能語音助手Siri不僅能智能問答還可以對手機進行語音控制等,之后各大公司也推出了自己的語音助手或者問答系統。
2.1 機器閱讀理解問答
2.2 機器閱讀理解問答數據集
2016年斯坦福大學公布了SQuAD[12]數據集,包含了涉及500篇文章的超過10萬條問題-答案對,SQuAD是一個抽取式問答數據集,答案被限定為段落中的一個連續子片段;同年,微軟發布了MARCO數據集,包含10萬個問題,每個問題有10個左右的相關段落,MARCO是一個生成式問答數據集,答案詞匯不一定來自于段落本身,而是由人工編寫的。然而也有檢索完文檔發現無法回答問題的情況,這時候就希望模型能給出“Unanswerable”的答案,所以斯坦福大學又公布了SQuAD2.0[13]數據集。TriviaQA[14]數據集包含超過65萬個問題-答案-證據三元組,該數據集包含相對復雜的問題,簡單的文本匹配方法無法適應該數據集。QAngaroo[15]數據集考慮到有些問題需要考慮多個文檔才能回答,利用知識圖譜技術構造了兩個多跳閱讀理解數據集,要求模型不僅需要正確回答出答案,還需要提供支持答案的證據。HotpotQA[16]數據集包含了11.3萬個基于維基百科的問題-答案對,能夠訓練可執行多跳推理并提供答案支持的問答系統。中文方面,百度發布了大規模開放域數據集DuReader[17],包含20萬個問題、100萬個文章和42萬個答案,這些問題和文章都來源于百度搜索引擎數據和問答社區。哈工大訊飛聯合實驗室發布的CMRC數據集[18],該數據集包含專家在Wikipedia段落上標注的近2萬個真實問題。這些數據集的提出為問答系統的研究提供了極大的便利。
2.3 機器閱讀理解問答系統
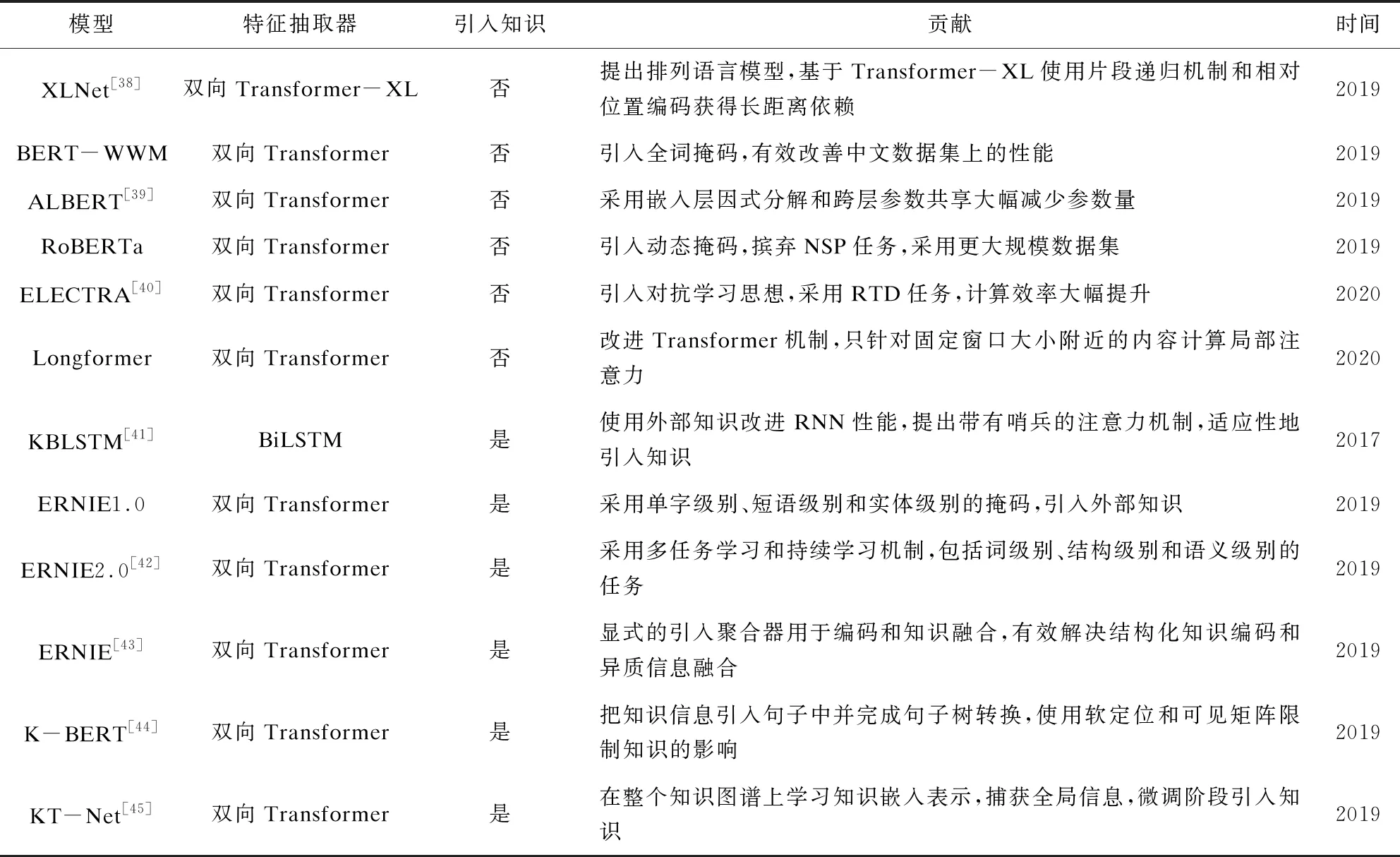
把近年機器閱讀理解模型根據特征提取器、是否引入知識等特征進行整理,如表3所示。
神經網絡由于其強大的表示能力,如今在問答系統中已取得很大的進展。基于神經網絡的問答模型常用框架為“編碼-交互-預測”,如圖1所示。

圖1 問答系統常用框架

交互層的作用是把問題和文章的編碼進行交互,首先計算文章和問題中每對單詞之間的相似度:
S=α(Hp)THq
(1)
然后通過注意力機制或者LSTM得到交互后的表示。
預測層的作用是根據相似度預測答案,通過把候選答案在文章中的開始位置和結束位置的概率相乘得到該候選答案的分數。訓練過程中的目標函數為:
(2)
其中,p1,p2為開始和結束位置的概率,si,ei分別表示起始位置和結束位置的groundtruth。
Vaswani等人提出了Transformer[27]架構,其中自注意力機制(self-attention)使得每個詞都有全局的語義信息,長距離依賴關系的提取能力要強于RNN。使用多頭注意力機制在多個語義空間上進行表示,性能遠好于RNN和CNN。
3 知識圖譜問答
KGQA主流方法有基于語義解析(semantic parsing)的方法和基于信息檢索這兩種。下面分別介紹這兩個主流方法的具體算法和發展。
3.1 基于語義解析的KGQA
基于語義解析的KGQA方法把要解決的問題看作語義解析問題,即把自然語言問題轉化成語義表示,再映射成邏輯形式。基于語義解析的KGQA可以看作答案能否回答問題的二分類任務,也可以看作候選答案的排序問題,隨著編碼-解碼模型在翻譯領域的廣泛使用,也有學者使用翻譯中的模型解決KGQA問題。
3.1.1 基于分類的KGQA
分類任務即預測問題q中的關系屬于n種關系r1,…,rn中的哪一類,可以分為三個步驟:
(1)使用編碼器把可變長度的輸入q映射成固定維度的向量q∈Rd;
(2)問題編碼經過映射計算得到分數向量:
s(q)=WOq+bo
其中,Wo∈Rn×d,bo∈Rn。
(3)輸出層中,模型會基于softmax函數把分數向量轉化成條件概率分布:
其中,k=1,2,…,n,選擇給定q時概率最高的關系。
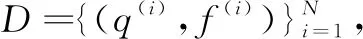
f(i)=(e(i),r(i))
使用最大化對數似然函數來訓練模型:
Mohammed等人[28]提出:對于簡單問題,基于分類的系統使用最基本的神經網絡結構(CNN、LSTM)加上一些簡單的規則就能夠達到SOTA性能。
3.1.2 基于排序的KGQA
給定自然語言問題q和知識圖譜時,基于排序的KGQA通常會使用一些搜索策略來尋找合適的候選形式查詢集合:C(q)={f1,f2,…,fN},然后使用基于神經網絡的排序模型選擇最匹配的形式查詢。一般有兩個步驟:
(1)問題q和候選形式查詢f通過編碼器映射到向量空間;
(2)形式查詢向量f和編碼后的問題q一起送入評分函數,返回的分數s(q,f)表示形式查詢f和問題q的匹配程度。得分最高的形式查詢作為模型的預測:
Li等人[29]提出使用多列卷積神經網絡(multi-column CNN)從答案路徑、答案類型和答案上下文三個角度來表示問題,提取了更豐富的信息并且不依賴手工特征和規則。
3.1.3 基于編碼-解碼模型的KGQA


圖2 Seq2Seq架構
Alvarezmelis等人[31]提出了一種改進型樹狀解碼器,使用兩個獨立的RNN分別對父-子和兄弟-兄弟節點之間的信息流建模,提供了使用RNN從自然語言查詢生成可執行的查詢語言這一思路。
3.2 基于信息檢索的KGQA
基于信息檢索的KGQA通常先確定用戶查詢中的中心實體,然后鏈接到知識圖譜中確定相關實體得到候選答案集合,之后通過評分或者排序的方式找出最可能的答案。該方法不需要大量手工特征或者規則,將復雜語義問題轉化為大規模可學習問題。基于信息檢索的KGQA根據使用的方法可以分為基于特征工程的方法和基于深度學習的方法。
3.2.1 基于特征工程的方法
Yao等人[32]率先提出了該類方法的通用模型,作者首先對用戶查詢進行句法分析,然后把依存關系轉化成更通用的問題特征圖。接著利用問題主題詞在知識圖譜中提取相關的節點,構成主題圖。最后把問題中的特征與主題圖中的特征進行組合,通過分類器學習特征的權重。
Bast等人[33]提出了一種端到端的系統可以自動將自然語言問題轉化成SPARQL查詢語言。以交互方式回答問題,要求用戶反饋關鍵決策,大大提高準確性。
3.2.2 基于深度學習的方法
基于特征工程的方法需要預先定義并抽取特征,受主觀因素限制,并且難以處理復雜問題。而深度學習可以很好地解決這些問題,通過神經網絡把問題和候選答案映射為空間向量,然后進行匹配。
Yih等人[34]〗使用卷積神經網絡解決單關系問答。通過CNN構建兩個不同的匹配模型,分別用來識別問題中出現的實體和匹配實體與KG中實體的相似度,最后給所有關系三元組打分,分數最高的三元組作為問題的答案。但是模型難以處理復雜的多關系情況。Hao等人[35]更關注問題的表示,提出了一種新的基于cross-attention的模型,根據不同的答案類型賦予問題中不同單詞的權重,這種動態表示不僅精確而且更加靈活。
4 知識圖譜用于機器閱讀理解問答
除了知識圖譜問答,知識圖譜還能用于機器閱讀理解問答。機器閱讀理解要求從給定的文章中提取信息回答問題,而當人類在做閱讀理解任務時,利用給定上下文回答問題的同時,也會利用一些先驗知識。
百度Sun等人發布的ERNIE(enhanced representation from knowledge integration)模型,在預訓練時引入了多源數據知識:百科類、新聞資訊類以及論壇對話類數據,通過建模這些海量數據中的詞、實體以及實體之間的關系,把知識編碼到預訓練模型中,增強了模型的語義表示能力。
清華大學Zhang等人提出ERNIE(enhanced language representation with informative entities)模型,不同于百度通過MASK的方法隱式地引入知識,清華的ERNIE通過改進BERT模型結構,將知識和語義信息顯式地在預訓練時進行編碼學習。模型在編碼過程中引入一個聚合器(aggregator)用于知識編碼以及知識融合,有效解決了結構化的知識編碼和異質信息融合問題。
Liu等人提出了K-BERT(knowledge-enabled bidirectional encoder representation from transformers)模型,在模型中引入了軟定位和可見矩陣來限制知識的影響。首先把句子中提到所有的命名實體提取出來去知識圖譜中查詢對應的三元組,然后把提取的三元組引入句子中生成句子樹,以此來引入知識,提高模型的表達能力。
上面的這三種模型都是在模型預訓練階段引入知識圖譜,Yang等人提出了KT-Net(knowledge and text fusion net),模型的知識整合(knowledge integration)模塊在面向下游任務的微調階段引入知識圖譜中的信息。
其中知識表示是在整個知識圖譜上學習的嵌入表示,能夠捕獲整個知識圖譜的全局信息,并且知識融合也易于擴展至融合多個知識圖譜的信息。上述提到的把知識圖譜信息引入機器閱讀理解的模型也匯總到表3中。

表3 機器閱讀理解問答模型對比
續表3
5 挑戰與研究方向
近年來國內外涌現出多種把知識圖譜應用于問答的方法,在取得很大進展的同時仍然存在不同方面的挑戰。本章簡單介紹當前研究的幾個瓶頸問題,并提出下一步的研究方向。
5.1 存在的挑戰
(1)知識圖譜的數據問題。知識圖譜數據的質量顯著影響著問答系統的性能,如何確保知識圖譜中數據廣而準確非常關鍵。目前知識圖譜大多存在噪聲、數據稀疏、數據冗余等問題,這些問題會給問答系統帶來影響。
(2)用戶復雜查詢轉化成邏輯形式的問題。KGQA中的一大難點便是如何把用戶提出的自然語言查詢轉化成機器可以理解的邏輯形式。實際應用中用戶提出的往往是復雜問題,如何得到復雜問題的通用解決范式也是一大挑戰。
(3)機器閱讀理解問答引入知識的問題。在長尾問題、少樣本問題、樣本不均衡問題等背景下,引入哪些知識,如何引入知識是需要探索的方向,更具體的,使用何種方法把知識和文本語義信息融合起來,判斷哪些知識是相關的都是值得探索的。
5.2 下一步研究方向
(1)嘗試多個知識圖譜信息融合。針對知識圖譜數據質量低下的問題,考慮結合多個知識圖譜,保留不沖突、不重復的信息,可以一定程度上解決數據稀疏問題。同時可以檢測知識圖譜之間的沖突信息,并進行消解和避免,以此解決噪聲問題。
(2)借助于不斷涌現的語言模型強大的表示能力,從語義層面解析問題。近年隨著語言模型的飛速發展,使用語言模型得到問題的表示,再到知識圖譜中查詢會是未來的研究方向。
(3)知識圖譜用于多跳問答推理。多跳問答是機器閱讀理解問答的一大研究熱點,回答多跳問答需要結合多篇文章甚至外部知識,如何把知識圖譜中的信息有效利用起來會是接下來的研究方向。
(4)基于遷移學習的知識圖譜問答系統。由于某些領域沒有知識圖譜或者知識圖譜規模小,大量有標注的樣本難以獲得,考慮使用遷移學習解決這一問題。
6 結束語
該文從兩個方面介紹了知識圖譜在智能問答中的應用,對比了多個常用的數據集,概括了主流的方法以及存在的問題。智能問答作為自然語言處理的一個重要分支,能夠從海量數據中簡明扼要地給出用戶需要的答案,便于用戶獲得精準信息。而知識圖譜作為自然語言處理的另一個重要分支,被廣泛地應用于智能問答、推薦系統、搜索引擎以及輔助決策等領域,也是實現自然語言理解的重要一環。實現知識圖譜和智能問答的有機結合,則有望讓機器像人類一樣去理解和回答問題,是使機器實現知識應用并能夠與真實世界交互的關鍵環節。因此,在自然語言處理領域飛速發展的過程中,把知識圖譜應用于智能問答研究意義重大。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
意林原創版(2016年10期)2016-11-25 10:28:30
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
