基于用戶偏好和項(xiàng)目偏差的創(chuàng)新型科研項(xiàng)目推薦技術(shù)研究
2021-07-30 01:17:42贠濤
微型電腦應(yīng)用 2021年7期
關(guān)鍵詞:創(chuàng)新型用戶
贠濤
(中國科學(xué)技術(shù)交流中心,北京 100045)
0 引言
各種網(wǎng)絡(luò)平臺的創(chuàng)新型項(xiàng)目推薦功能能夠使用戶快速獲取有價(jià)值的信息,因此對此類技術(shù)開展研究十分必要。協(xié)同過濾算法在創(chuàng)新型項(xiàng)目推薦技術(shù)中的應(yīng)用非常普遍,但由于沒有充分考慮用戶的個(gè)性化需求以及推薦項(xiàng)目間類似元素存在相互干擾的問題,該算法的準(zhǔn)確性受到了嚴(yán)重的限制。本文提出了一種基于用戶偏好和項(xiàng)目偏差的協(xié)同過濾算法(IUCF算法)用于創(chuàng)新型項(xiàng)目推薦,首先進(jìn)行用戶和項(xiàng)目的聚類再分別計(jì)算評分,最后基于二者融合后的預(yù)測評分結(jié)果實(shí)現(xiàn)項(xiàng)目推薦。
1 概論
1.1 用戶評分協(xié)同過濾算法
該算法的計(jì)算流程為:基于用戶—項(xiàng)目評分矩陣獲取不同用戶的相似度;利用相似度進(jìn)行相鄰用戶匹配;通過相鄰用戶進(jìn)行預(yù)測評分。選取皮爾森相關(guān)系數(shù)進(jìn)行用戶的相似度計(jì)算[1],如式(1)。
(1)
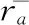
1.2 LDA主題模型
LDA(latent Dirichlet allocation,潛在Dirichlet分布)模型通過Dirichlet概率分布對文本文件的潛在概率進(jìn)行設(shè)定,再通過抽樣算法分別對文本—主題以及主題—詞組的潛在分布進(jìn)行預(yù)估。基于Gibbs采樣的抽樣算法[2]為式(2)。
(2)
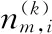
1.3 算法分析
在對創(chuàng)新型項(xiàng)目進(jìn)行評分預(yù)測時(shí),項(xiàng)目間類型較為相近的元素會互相產(chǎn)生干擾進(jìn)而造成項(xiàng)目偏差,同理,用戶通常是在整個(gè)用戶集中選擇近鄰,沒有考慮用戶本質(zhì)的差異,因而無法明確表達(dá)用戶對于項(xiàng)目的個(gè)性化需求,此外,用戶的偏好對用戶給出的項(xiàng)目評分存在實(shí)際的影響,所以必須以充分挖掘用戶偏好和項(xiàng)目偏差為基礎(chǔ)對創(chuàng)新型項(xiàng)目進(jìn)行評分。
IUCF(item deviation and user preference combin filtering,項(xiàng)目偏差與用戶偏好組合過濾)算法充分體現(xiàn)了用戶和項(xiàng)目的本質(zhì)差異,依據(jù)用戶本質(zhì)和項(xiàng)目類別實(shí)現(xiàn)聚類,能夠獲得準(zhǔn)確的項(xiàng)目偏差分析結(jié)果。項(xiàng)目中某類型出現(xiàn)次數(shù)的占比與用戶評分矩陣相結(jié)合,能夠使出現(xiàn)次數(shù)較多的類型獲得對應(yīng)的高分,從而明確用戶的偏好。
2 算法設(shè)計(jì)
IUCF算法的模型如圖1所示。
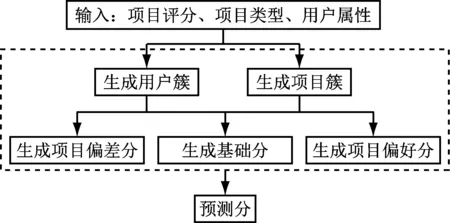
圖1 IUCF算法模型
該算法包含兩個(gè)部分,一是分別基于用戶簇和項(xiàng)目簇完成不同類型項(xiàng)目的用戶偏好評分和項(xiàng)目偏差評分,二是利用項(xiàng)目簇中目標(biāo)用戶對項(xiàng)目的評分均值,通過線性加權(quán)處理得到最終的預(yù)測評分。
2.1 聚類處理
(1)項(xiàng)目簇創(chuàng)建
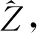
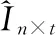
(3)
通過該矩陣的一個(gè)行可獲得項(xiàng)目主題簇CNn,通過一個(gè)列可獲得主題項(xiàng)目簇CTt[4],即式(4)。
(4)
式中,CNn為包含項(xiàng)目n的主題的集合;CTt為主題是t的項(xiàng)目的集合;i、j分別為主題號和項(xiàng)目號。
項(xiàng)目n的找尋過程為:首先確定項(xiàng)目所在集合CNn,接下來確定對應(yīng)每個(gè)主題的CTt,通過對CTt的并集處理獲取包含項(xiàng)目n的項(xiàng)目簇Cn,其表達(dá)式為式(5)。
(5)
(2)用戶簇創(chuàng)建
用戶的職業(yè)、性別、年齡都可以作為用戶的屬性元素。設(shè)Q為用戶的集合,Q={Q1,…,Qi},Qi為第i個(gè)用戶,每個(gè)用戶的屬性集合為Qi={q1,…,qk},qk為i用戶所具有的第k個(gè)屬性。
K-means聚類應(yīng)以用戶基本屬性的預(yù)處理為前提,其過程以通過對具體的屬性進(jìn)行編碼分組實(shí)現(xiàn)。對于性別,以數(shù)字1和2分別代表男性和女性;對于年齡,可通過劃分不同的年齡段進(jìn)行分組,其中,1—80歲人群以20歲為間隔創(chuàng)建編號1—4的四個(gè)組,80歲以上人群全部劃入5號組;對于職業(yè),首先對所有用戶的職業(yè)進(jìn)行分類,再明確各種職業(yè)所對應(yīng)的用戶數(shù)量,根據(jù)成組元素二八定理的重要性權(quán)重理論,將用戶數(shù)量排名屬于前20%的職業(yè)分別編入1—4號組,剩余職業(yè)全部編入5號組。按照上述方式分組后,用戶屬性集合Qi即可通過數(shù)字編碼表示。
鑒于K-means聚類具有無監(jiān)督學(xué)習(xí)的特征,本文選用簇內(nèi)曲線拐點(diǎn)聚類法基于SSE(sum of squares errors,誤差平方和)確定聚類的實(shí)際數(shù)量。K-means聚類的結(jié)果即為包含用戶a的用戶簇Ua,即式(6)。
Ua={uj|uj∈Q,j∈[1,i]}
(6)
式中,uj為用戶簇所包含的第j個(gè)用戶。
2.2 項(xiàng)目偏差分計(jì)算
分別基于用戶簇和項(xiàng)目簇對用戶和項(xiàng)目進(jìn)行過濾,通過單個(gè)項(xiàng)目得分與所有項(xiàng)目平均得分的差值來量化項(xiàng)目偏離的程度。具體的計(jì)算過程如下。
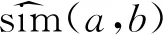
(7)

(2)在用戶簇中,計(jì)算目標(biāo)用戶與其余用戶的放大相似度,篩選出與目標(biāo)用戶a相關(guān)性最強(qiáng)的k個(gè)用戶作為其最近鄰,為式(8)。
(8)
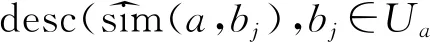
(3)在用戶簇中,用戶a對項(xiàng)目n的項(xiàng)目偏差I(lǐng)Dan分由加權(quán)平均偏差表示,即式(9)。
(9)
2.3 用戶偏好分計(jì)算
用戶偏好分表達(dá)了用戶對各種項(xiàng)目的主觀偏好,能夠彌補(bǔ)評分項(xiàng)過少的情況下項(xiàng)目偏差分調(diào)節(jié)能力不足的缺陷,具體的計(jì)算過程如下。
(1)通過用戶類型偏好明確用戶類型喜好,用戶偏好分是某一類型在所有類型的總評分中所做出的貢獻(xiàn)占比,即式(10)。
(10)
式中,pai為用戶a對第i個(gè)類型的用戶偏好分;sai為用戶a對第i個(gè)類型的打分次數(shù);paj為用戶a對項(xiàng)第j個(gè)類型的評分;m、n分別為類型數(shù)量和項(xiàng)目數(shù)量。sai為用戶—類型評分矩陣Sa×m內(nèi)的所有項(xiàng),Sa×m的獲取方法為式(11)。
(11)
z-score標(biāo)準(zhǔn)化能夠體現(xiàn)單項(xiàng)值與平均值差距的大小,該數(shù)值的正負(fù)說明了用戶對類型的喜好,即喜歡或不喜歡,用戶類型偏好分的z-score標(biāo)準(zhǔn)化處理方式為式(12)。
(12)
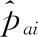
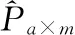
(13)
式中,dit為矩陣Dm×t的第m個(gè)類型與第t個(gè)主題相對應(yīng)的概率;Nn為主題簇CNn中主題的總數(shù)量。
2.4 綜合預(yù)測評分
在包含創(chuàng)新型項(xiàng)目的項(xiàng)目簇初始評分均值的基礎(chǔ)上,加入用戶偏好分和項(xiàng)目偏差分即可得到該項(xiàng)目的綜合預(yù)測評分。引入權(quán)重系數(shù)λ調(diào)節(jié)用戶偏好分和項(xiàng)目偏差分,則用戶a對項(xiàng)目n的綜合預(yù)測評分Tan的計(jì)算方式為式(14)。
(14)
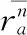
3 實(shí)驗(yàn)驗(yàn)證
實(shí)驗(yàn)采用國外某知名高校所建立的Movielens100k數(shù)據(jù)集,其中包含943位用戶對1 682個(gè)創(chuàng)新型項(xiàng)目的預(yù)測評分以及用戶的屬性和項(xiàng)目的類型。從數(shù)據(jù)集中選取80%的數(shù)據(jù)進(jìn)行評分訓(xùn)練,其余部分用以評分測試。
3.1 實(shí)驗(yàn)指標(biāo)
實(shí)驗(yàn)結(jié)果的準(zhǔn)確性通過MAE(平均絕對誤差)進(jìn)行衡量,其計(jì)算方式為式(15)。
(15)
式中,N為預(yù)測項(xiàng)目的數(shù)量。MAE值越小則項(xiàng)目推薦的準(zhǔn)確性越高。
3.2 參數(shù)確定實(shí)驗(yàn)
(1)K-means聚類數(shù)量
基于肘方法分別代入2—8七個(gè)數(shù)值作為待定聚類數(shù)量,計(jì)算出每個(gè)數(shù)值對應(yīng)的SSE,計(jì)算結(jié)果如圖2所示。
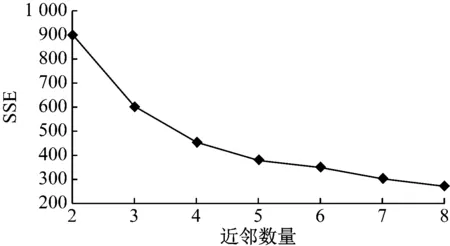
圖2 不同聚類數(shù)量下SSE的計(jì)算結(jié)果
由圖2可見,SSE的值隨聚類數(shù)量的增多而減小,聚類數(shù)量由2增加到3時(shí),SSE的減幅為約為300,且自此之后的減幅均比第一次調(diào)整小,可見聚類數(shù)量為3時(shí)對應(yīng)的坐標(biāo)點(diǎn)即為簇內(nèi)曲線拐點(diǎn)聚類法的拐點(diǎn),因此能夠確定最佳聚類數(shù)量為3。
(2)LDA聚類主題數(shù)量
設(shè)定λ=1,由式(14)可知此時(shí)預(yù)測評分僅受項(xiàng)目偏差分的影響,因此可以快速確定最合適的主題數(shù)量。將近鄰數(shù)量設(shè)定為10、30、50,基于Gibbs抽樣方法分別代入12—18七個(gè)數(shù)值作為待定主題數(shù)量,同時(shí)根據(jù)文獻(xiàn)[1]的實(shí)踐設(shè)定a=50/T,β=0.01,計(jì)算結(jié)果如圖3所示。
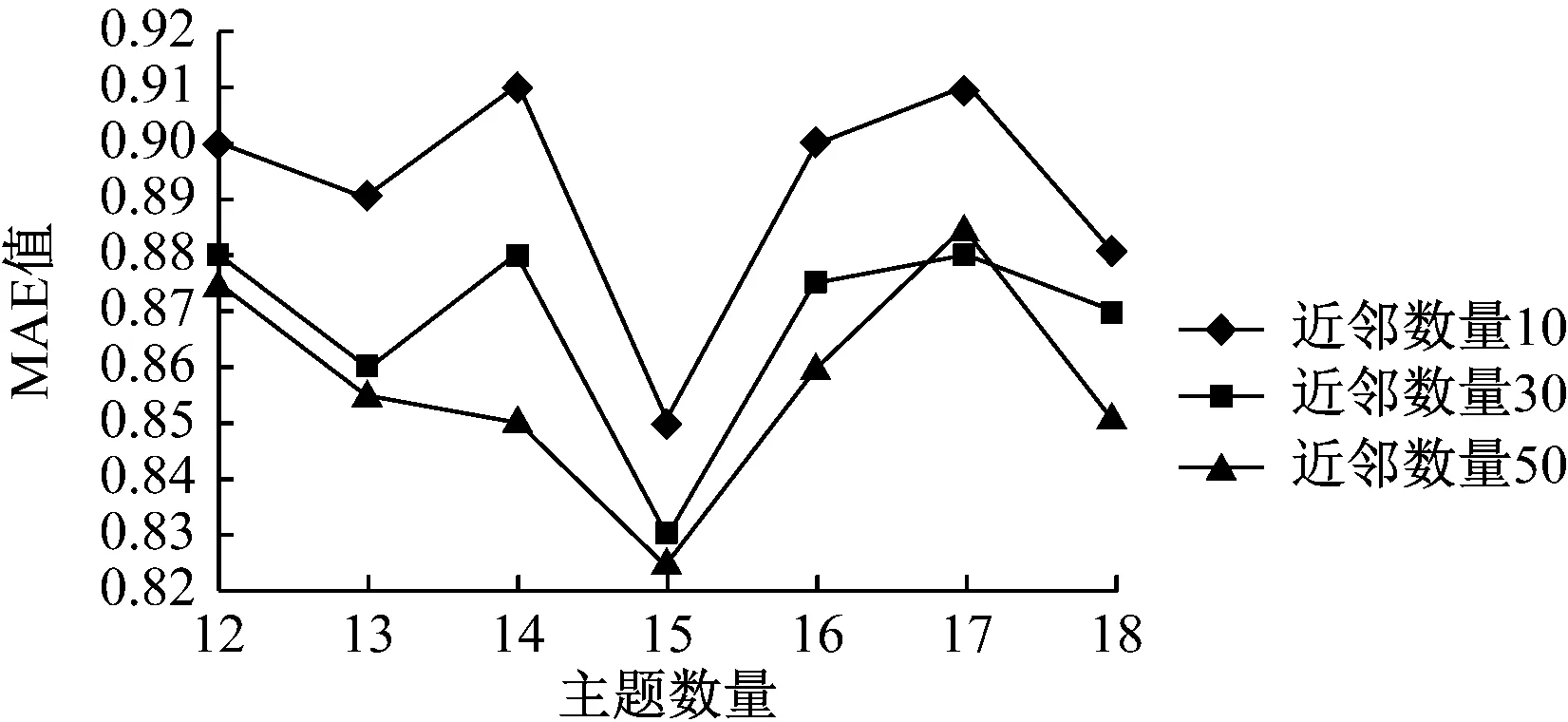
圖3 不同主題數(shù)量下MAE的計(jì)算結(jié)果
由圖3可見,在設(shè)定的3種近鄰數(shù)量條件下,MAE值均在主題數(shù)量為15時(shí)為最小,因此可以確定最佳LDA聚類主題數(shù)量為15。
(3)權(quán)重系數(shù)λ
將近鄰數(shù)量設(shè)定為10、30、50,反復(fù)對權(quán)重系數(shù)λ的值進(jìn)行調(diào)整,通過IUCF算法所得的MAE值,如圖4所示。
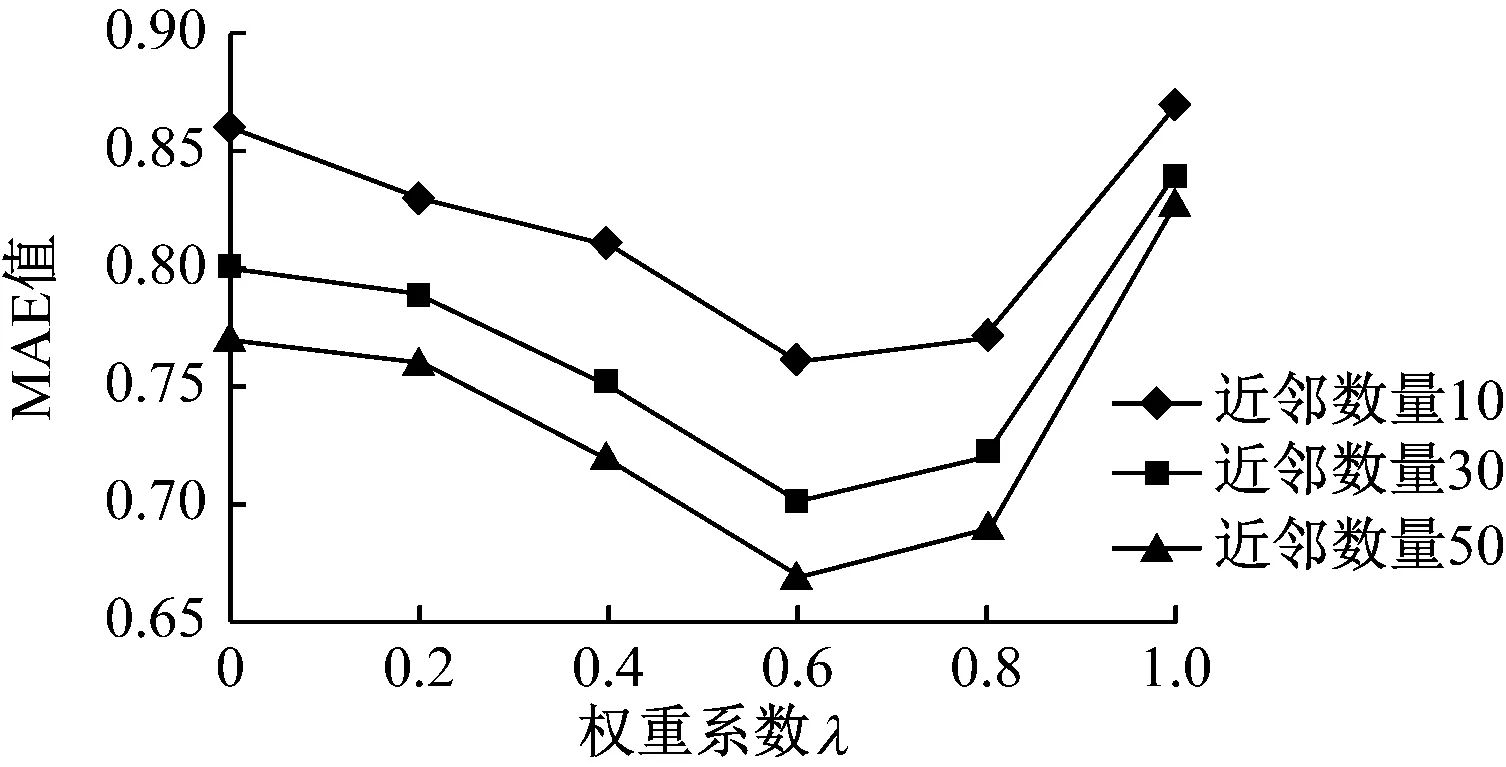
圖4 不同權(quán)重系數(shù)下MAE的計(jì)算結(jié)果
由圖4可見,在設(shè)定的3種近鄰數(shù)量條件下,MAE值均在λ=0.6時(shí)為最小,因此可以確定權(quán)重系數(shù)λ的最佳取值為0.6。
3.3 對比實(shí)驗(yàn)
為了驗(yàn)證本文所提出的IUCF算法在準(zhǔn)確度方面是否具有優(yōu)勢,選取常規(guī)協(xié)同過濾算法UCF[2]、基于項(xiàng)目類型的協(xié)同過濾算法ICF[3]、基于概率矩陣分解和特征轉(zhuǎn)移的推薦算法FTMF[4]以及基于安全網(wǎng)絡(luò)的協(xié)同過濾算法ECFATN[5]共4種算法與本算法進(jìn)行準(zhǔn)確度對比,實(shí)驗(yàn)結(jié)果如圖5所示。
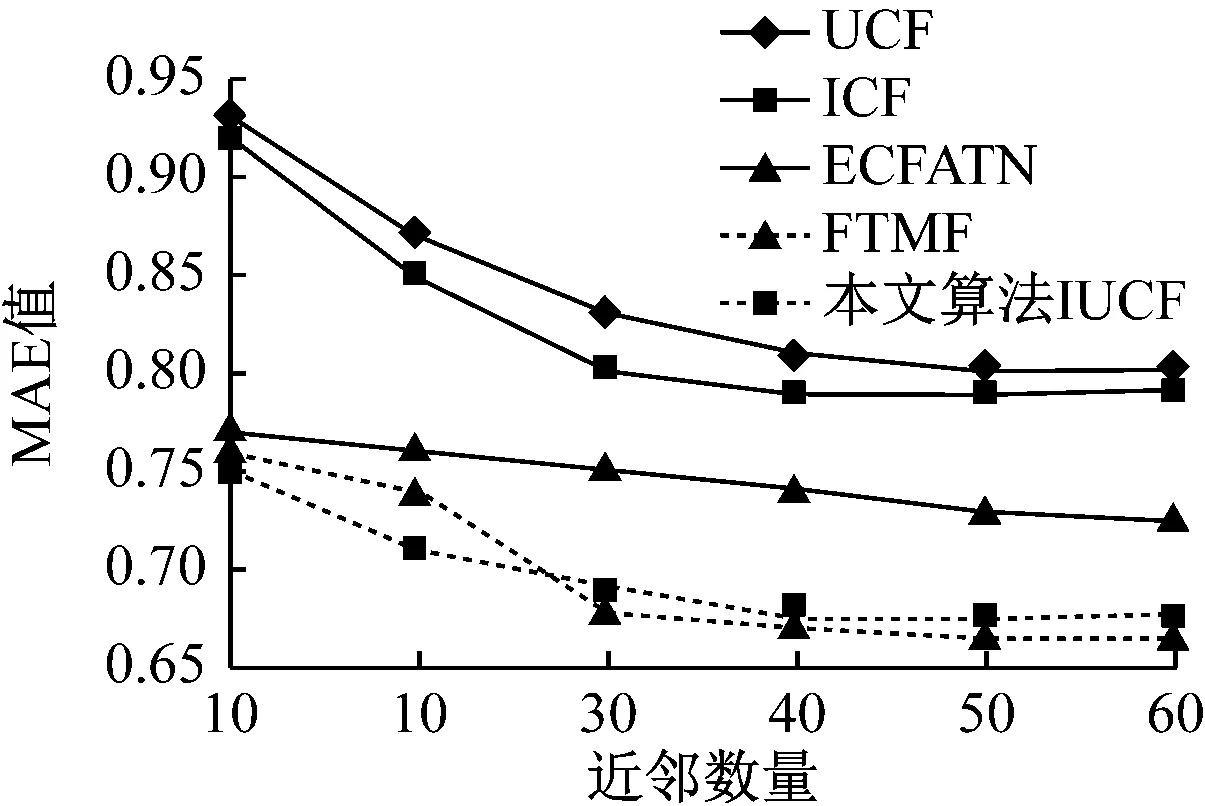
圖5 不同算法的MAE值對比結(jié)果
由圖5可見,通過IUCF算法所得的MAE值低于UCF、ICF與FTMF 3種算法,說明IUCF算法相較于其它協(xié)同過濾算法能夠?qū)崿F(xiàn)更準(zhǔn)確的推薦。在不同近鄰數(shù)量的條件下,IUCF算法的MAE值低于ECFATN算法,但近鄰數(shù)量達(dá)到30以上時(shí),MAE值較FTMF算法高,分析認(rèn)為可能是近鄰數(shù)量過多造成的,而只要近鄰數(shù)量少于30,IUCF算法的MAE值均低于FTMF算法,可見在近鄰數(shù)量不多于30的條件下IUCF算法的準(zhǔn)確度是具有優(yōu)勢的。
4 總結(jié)
為了解決創(chuàng)新型項(xiàng)目推薦技術(shù)原有算法準(zhǔn)確度受限的問題,本文提出了一種基于用戶偏好和項(xiàng)目偏差的IUCF算法,介紹了算法的實(shí)現(xiàn)機(jī)制,闡述了算法的設(shè)計(jì)過程,通過實(shí)驗(yàn)確定了算法關(guān)鍵參數(shù)的最佳取值,并通過與其它算法的對比驗(yàn)證了IUCF算法在創(chuàng)新型項(xiàng)目推薦方面所具備的高準(zhǔn)確度的優(yōu)勢。本文所設(shè)計(jì)的算法有效解決了用戶與項(xiàng)目間類似元素互相干擾所造成的準(zhǔn)確度較低的問題,目前已應(yīng)用于國內(nèi)人口年齡組劃分新方法的研究項(xiàng)目并發(fā)揮了顯著的作用,具有很強(qiáng)的實(shí)用性。
猜你喜歡
教育家(2022年18期)2022-05-13 15:42:15
中國市場(2021年34期)2021-08-29 03:25:40
上海建材(2020年12期)2020-12-31 13:24:26
中國制筆(2019年1期)2019-08-28 10:07:28
商用汽車(2016年11期)2016-12-19 01:20:16
新聞傳播(2016年4期)2016-07-18 10:59:20
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
