一種深度森林算法的乳腺癌檢測方法研究
2021-07-30 13:37:16李進,何冉
新一代信息技術(shù) 2021年8期
李 進,何 冉
(河北地質(zhì)大學(xué) 信息工程學(xué)院,河北 石家莊 050031)
0 引言
目前,許多學(xué)者出將機器學(xué)習(xí)(Mechine Le-arning, M L)算法應(yīng)用于人類疾病的檢測。如趙培培等[3]使用多種機器算法對糖尿病進行分類檢測,最終發(fā)現(xiàn)投票聚合模型 Voting最適合糖尿病的分類檢測;孔德峰等使用傳統(tǒng)機器學(xué)習(xí)算法應(yīng)用在乳腺癌診斷中,通過構(gòu)建邏輯回歸、決策樹、SVM、KNN四種機器學(xué)習(xí)方法對該問題進行建模與分析,證明了KNN[4]分類器較其他算法有明顯優(yōu)勢;苗立志等人[5]基于多個弱分類器的隨機森林并行化進行乳腺癌發(fā)病概率的預(yù)測,并利用皮爾遜和Spearman系數(shù)的相關(guān)度分析,提高了乳腺癌發(fā)病概率的預(yù)測精度;葉明等[6]提出了SELEDAT算法,在集成學(xué)習(xí)中引入動態(tài)權(quán)重的思想,解決了數(shù)據(jù)不平衡問題,提高了疾病預(yù)測的分類性能。Pawlovsky等人[7]基于兩種距離的集成KNN算法,提高了UCI標準化數(shù)據(jù)集的分類精確度。在實踐調(diào)查中發(fā)現(xiàn),到目前為止沒有任何一種分類方法能在不同的數(shù)據(jù)類型和不同的領(lǐng)域中證明比其它的分類方法的性能更好[8],而且由于傳統(tǒng)機器學(xué)習(xí)算法無法對數(shù)據(jù)的深層特征進行深度挖掘,導(dǎo)致在很多領(lǐng)域中無法應(yīng)用傳統(tǒng)機器學(xué)習(xí)算法,此時深度學(xué)習(xí)應(yīng)運而生。深度學(xué)習(xí)[9]是一種通過多個變換階段對數(shù)據(jù)特征進行分層處理最終得到這些特征的抽象表示的機器學(xué)習(xí)過程,但是目前常見的深度學(xué)習(xí)結(jié)構(gòu)基本都是基于神經(jīng)網(wǎng)絡(luò)[10]的。直至 2017年,周志華等人給出了另外一種與神經(jīng)網(wǎng)絡(luò)類似的深度結(jié)構(gòu)——深度森林(multi-Grained Cascade forest, Gcfor-est)[11]。深度森林的出現(xiàn)無疑為深度學(xué)習(xí)在除神經(jīng)網(wǎng)絡(luò)應(yīng)用之外的應(yīng)用領(lǐng)域給出了另外一個選擇。
對于傳統(tǒng)機器學(xué)習(xí)分類算法在醫(yī)療診斷領(lǐng)域效果不理想的情況,本文將深度森林算法應(yīng)用于乳腺癌腫瘤數(shù)據(jù)分類問題,首先通過類似卷積操作中的滑動窗口提取原始數(shù)據(jù)特征并增強表征學(xué)習(xí)能力,使學(xué)習(xí)后的數(shù)據(jù)具有和感受野類似的結(jié)構(gòu)感知能力;級聯(lián)隨機森林具有分層結(jié)構(gòu),可以對增強后的特征進行逐層學(xué)習(xí),最終對乳腺癌腫瘤數(shù)據(jù)良惡性進行分類。經(jīng)過對比實驗發(fā)現(xiàn),深度森林算法較支持向量機(Supoort Vector Machine,SVM)和決策樹(Decsion Tree)算法更優(yōu)。通過深度森林進行訓(xùn)練得到可信度和準確率都較高的模型,在乳腺癌腫瘤的良惡性檢測上給出較為可靠的結(jié)果輔助影像醫(yī)師對病患進行診斷。
1 深度森林
1.1 隨機森林(RandomForest, RF)
集成學(xué)習(xí)[12]是訓(xùn)練若干個個體學(xué)習(xí)器,并通過特定的結(jié)合策略,最終形成一個性能較之原個體學(xué)習(xí)器更加優(yōu)越和穩(wěn)健的強學(xué)習(xí)器的過程。隨機森林屬于集成學(xué)習(xí)中的 Bagging(Bootstrap Aggegation)方法,包含多個決策樹分類器,學(xué)習(xí)過程是每次從候選分類器中選擇最優(yōu)的分類屬性,最終輸出的類別是由森林中決策樹輸出類別的眾數(shù)決定。隨機森林中每個個體學(xué)習(xí)器之間都不存在強依賴關(guān)系,對超參數(shù)設(shè)置不敏感,并且可以判斷輸入數(shù)據(jù)特征的重要程度,所以不管是在小規(guī)模數(shù)據(jù),還是大規(guī)模數(shù)據(jù)上都具有較為良好的泛化性能,這使得隨機森林生成的模型不容易造成過擬合現(xiàn)象且可以平衡非對稱數(shù)據(jù)集造成的預(yù)測誤差。
隨機森林算法流程:
Input: 1.訓(xùn)練集
2. 待測樣本xt?Rd

(I)對原始訓(xùn)練集S采用 Boostrap抽樣,生成訓(xùn)練集Si
理論空燃比時,在電動勢小于約0.4V的情況下AF+側(cè)端子與AF-側(cè)端子的電壓相等,因此電流不會流向任何一側(cè)。過濃時,在電動勢大于約0.4V的情況下,AF-側(cè)的電壓比較高,因此從AF-側(cè)流向AF+側(cè)的電流與電壓差成比例。過稀時,在電動勢小于約0.4V的情況下,AF+側(cè)的電壓比較高,因此從AF+側(cè)流向AF-側(cè)的電流與電壓成比例。所以空燃比傳感器的輸出電壓與空燃比的大小成正比。由圖1可知,空燃比小于14.7混合汽過濃時,傳感器輸出較小的電壓(小于3.3V);空燃比大于14.7混合汽過稀時,傳感器輸出較大電壓(大于3.3V)。
(II)使用Si生成一顆不減枝的樹hi:
a. 從d個特征中隨機選取M個特征
b. 在每個節(jié)點上從M個特征依據(jù)Gini指標中選取最優(yōu)特征
c. 分裂直到樹長到最大
End
Output:1.樹的集合{hi,i=1,2,…,N}
2. 對待測樣本xt,決策樹hi輸出hi(xi)

其中,式(1)中xi,yi為第i個數(shù)據(jù)的特征和標簽,R為實數(shù),hi(xi),f(xi)為分類結(jié)果,majority Vote表示多數(shù)投票,得到最終分類結(jié)果
1.2 深度森林(DeepForest)
深度森林[11]又叫多粒度級聯(lián)森林,它首先采用了類型滑動窗口的方法對原始輸入進行特征變換,增強其特征表達能力,然后再通過級聯(lián)的多個隨機森林層做逐層表征學(xué)習(xí)。
深度森林是由多個隨機森林構(gòu)成一個森林層,然后通過級聯(lián)的方式連接多個森林層,最終形成層間連接。其中森林中每一層的輸出類向量都是一組對上一層輸入特征向量轉(zhuǎn)換之后的表征學(xué)習(xí),隨后將變換表征之后的處理結(jié)果提交給下一森林層,同時使用驗證集判定這一層輸出是否滿足預(yù)設(shè)輸出條件,若不滿足則將輸出向量組合與原始訓(xùn)練向量相連接,并以連接之后的向量作為下一森林層的輸入,直至輸出向量組合的預(yù)測值滿足預(yù)設(shè)條件。深度森林網(wǎng)絡(luò)結(jié)構(gòu)模型如圖1所示。
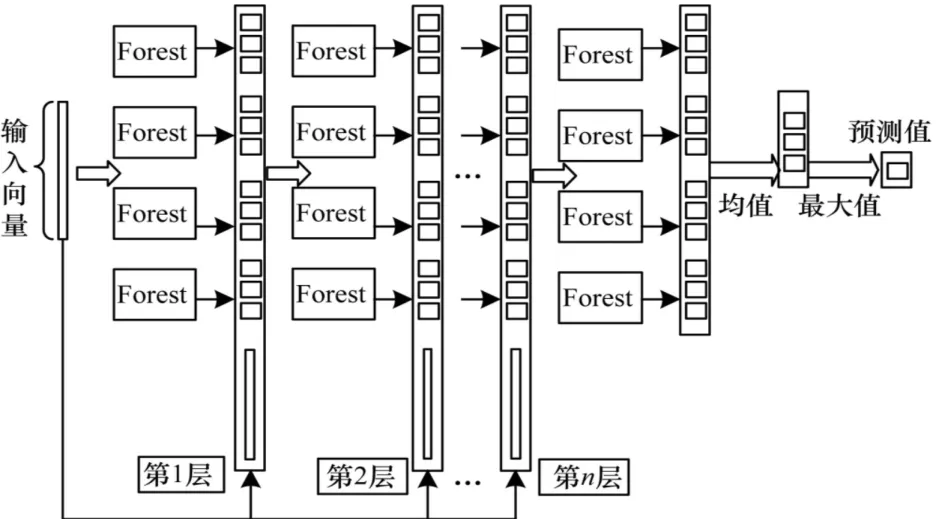
圖1 深度森林網(wǎng)絡(luò)結(jié)構(gòu)模型Fig.1 Structure Model of deep forest network
在圖1中,輸入向量輸入第一個森林層之后,森林層的所有森林分別計算所有樣本的類別概率,將得到的類別概率組合作為輸出向量并與原始數(shù)據(jù)進行拼接或組合,隨后將組合的數(shù)據(jù)作為下一森林層的輸入,循環(huán)直至達到預(yù)設(shè)的循環(huán)次數(shù)或者收斂條件后停止對訓(xùn)練數(shù)據(jù)進行處理,并最終對輸出層的向量組合求均值,并將輸出概率最大的類別輸出為預(yù)測的樣本類別。
2 實驗與分析基于深度森林算法的乳腺癌良惡性檢測
2.1 實驗環(huán)境介紹
本文實驗所用的計算機硬件環(huán)境配置為Inter(R) Core(TM) i7-8750H 2.2 GHz,內(nèi)存 16 GB,實驗所運行的軟件環(huán)境為安裝在windows10操作系統(tǒng)下的python3.6.5
2.2 實驗數(shù)據(jù)
本文實驗采用的數(shù)據(jù)集為William H. W olberg博士提供的標準乳腺癌腫瘤數(shù)據(jù),此數(shù)據(jù)集可以從UCI數(shù)據(jù)集官網(wǎng)上獲取。
乳腺癌腫瘤數(shù)據(jù)集共包括569個觀測樣本,其中每個數(shù)據(jù)樣本都有30種特征屬性,這些特征都是對乳腺癌腫瘤的各個維度特征的抽象表征,每種特征的數(shù)據(jù)類型均為64為浮點數(shù)類型,每個樣本有且僅有一個標簽,標簽一共分為兩大類,分別是惡性(malignant)和良性(benign)。樣本集中,212個樣本被標注為惡性,357個樣本被標注為良性。部分樣本特征名稱及其解釋如表1。
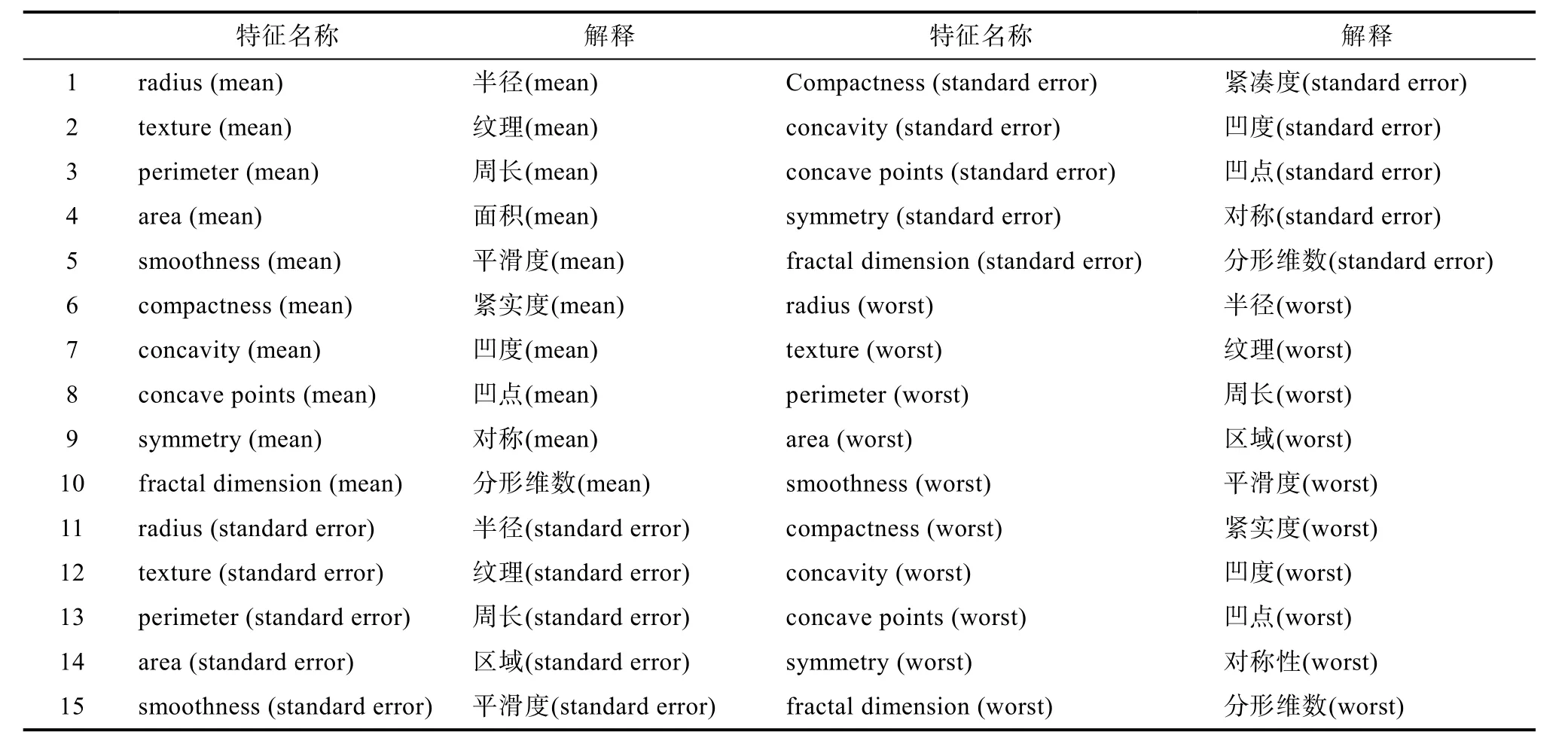
表1 樣本部分特征及其解釋Tab.1 Partial characteristics of samples and their explanations
其中半徑指從中心到周界各點的平均距離,紋理指腫瘤灰度圖的標準差,平滑度指半徑的局部變化的程度,密實度指周長的平方除面積-1,凹度指腫瘤輪廓凹陷部分的嚴重程度,凹點指論文凹面部分的數(shù)量。mean代表平均值,standard error代表標準差,worst代表最差的或者最大值。乳腺癌訓(xùn)練集及測試集分布如表2所示。

表2 乳腺癌訓(xùn)練集測試集分布Tab.2 Test set distribution of breast cancer training set
2.3 網(wǎng)絡(luò)超參數(shù)配置
為了選取隨機森林最佳超參數(shù)集合,需要多次對隨機森林參數(shù)進行調(diào)試,并從得到的超參數(shù)集合中選取最好的超參數(shù)集對模型超參數(shù)進行初始化,使模型在測試集上擁有更高的分類準確率和泛化性能。隨機森林中著重需要配置的超參數(shù)分別為max_depth和n_estimators。其中max_depth為構(gòu)建決策樹的深度,值越大越容易過擬合,n_estimators為構(gòu)建隨機的個體決策樹的個數(shù)。隨機森林中最大迭代次數(shù)和決策樹個數(shù)對深度森林分類曲線如圖2。

圖2 隨機森林中最大迭代次數(shù)和決策樹個數(shù)對深度森林分類曲線Fig.2 The relationship between the maximum number of iterations and the number of decision trees in a random forest to the depth forest classification curve
由圖2不難看出,隨機森林的最大迭代深度和個體決策樹個數(shù)能較大地影響深度森林的分類性能,所以對于最大迭代深度和個體決策樹個數(shù)的選擇需要選取使得深度森林分類效果最好的極點值。網(wǎng)格搜索是一種基于窮舉的調(diào)參手段,在所有的候選參數(shù)中通過循環(huán)遍歷,嘗試每一種可能性,并從中找出表現(xiàn)最好的參數(shù)。經(jīng)網(wǎng)格搜索之后得到的最優(yōu)max_depth和n_estimators如表3。

表3 深度森林超參數(shù)配置Tab.3 Super parameter configuration of deep forest
2.4 實驗結(jié)果及對比分析
為了更好地驗證深度森林的模型性能,本文通過將乳腺癌腫瘤數(shù)據(jù)分別輸入已經(jīng)訓(xùn)練好的支持向量機、決策樹和深度森林,其中支持向量機和決策樹均采用模型自帶值初始化,采用準確率和F1-度量評價指標對每個模型的性能進行評估。不同模型算法得到的乳腺癌腫瘤數(shù)據(jù)良惡性分類對比結(jié)果如表4,三種不同模型算法得到的乳腺癌腫瘤數(shù)據(jù)就良惡性分類評價曲線如圖3。
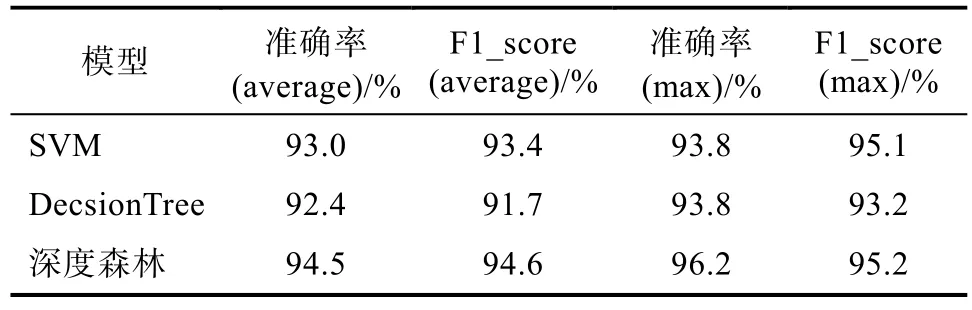
表4 乳腺癌腫瘤數(shù)據(jù)良惡性分類對比結(jié)果Tab.4 Comparison results of benign andmalignant breast cancer data

圖3 乳腺癌腫瘤數(shù)據(jù)就良惡性分類評價曲線Fig.3 Classification curve of benign and malignant breast cancer data
由表4可知三種算法的準確率和f1_score的均值及最大值均大于90%,說明對于二分類問題來說三種算法都能有較好的分類預(yù)測效果,其中深度森林擁有最好的分類性能,最高分類準確率達 96.2%,出現(xiàn)這樣的情況是由于乳腺癌腫瘤數(shù)據(jù)集的數(shù)據(jù)不均衡問題,支持向量機和決策樹這兩個算法不能很好地解決數(shù)據(jù)不均衡問題,而深度森林由于其有隨機抽樣算法使其獲得了更好地分類準確率。從圖3中在乳腺癌腫瘤數(shù)據(jù)良惡性分類曲線可以看出深度森林的分類性能明顯好于另外兩種分類器,且在綜合評價指標f1_score上具有明顯優(yōu)勢。
綜合上述實驗結(jié)果,深度森林在乳腺癌腫瘤良惡性分類預(yù)測上的模型性能要優(yōu)于支持向量機和決策樹模型。
3 結(jié)論與展望
本文針對當(dāng)前醫(yī)療領(lǐng)域乳腺癌腫瘤分類預(yù)測中淺層機器學(xué)習(xí)算法無法對腫瘤數(shù)據(jù)的特征屬性進行深度挖掘和常規(guī)腫瘤數(shù)據(jù)中特征屬性較少的問題,利用深度森林中的隨機抽樣方法對原始如數(shù)進行特征變換以增強原始腫瘤數(shù)據(jù)的特征表達能力,然后通過級聯(lián)森林結(jié)構(gòu)對增強特征進行逐層表征學(xué)習(xí),獲取腫瘤數(shù)據(jù)原始特征中無法表達的高維屬性,達到提高分類乳腺癌腫瘤良惡性準確率的目的,更好更高效地提高乳腺癌良惡性診斷水平。實驗結(jié)果表明,基于深度森林的乳腺癌腫瘤良惡性分類準確率及 f_score均好于支持向量機和決策樹算法。在醫(yī)療領(lǐng)域中對乳腺癌腫瘤良惡性輔助診斷上有較大幫助。然而,該算法的預(yù)測性仍然沒有到達完全準確判斷乳腺癌腫瘤良惡性分類的結(jié)果,所以下一步將研究如何改進深度森林算法以進一步提高該算法的分類預(yù)測性能。
猜你喜歡
中老年保健(2022年6期)2022-08-19 01:41:48
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
中國生殖健康(2019年2期)2019-08-23 08:11:42
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
中國生殖健康(2019年6期)2019-01-06 09:20:12
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
