基于動態權重的商品混合推薦系統
2021-07-28 12:51:32周雙杰高鳳玲孫知信
科技資訊 2021年10期
周雙杰 高鳳玲 孫知信

摘? 要:推薦系統已經在日常生活中扮演著舉足輕重的角色,單一的推薦系統往往會存在冷啟動、數據稀疏等問題,該文將各推薦服務的結果通過動態權重的方式加以調整并混合,避免單一算法帶來的問題,提升個性化推薦效果。將大數據技術和推薦算法結合,設計并實現基于大數據的商品混合推薦系統。最后使用Amazon的數據集進行系統測試,該文提出的動態權重混合方式比傳統線性混合擁有更好的性能。
關鍵詞:推薦系統? 混合推薦? 動態權重? 個性化推薦
中圖分類號:TP391.3? ? ? ? ? ? ? ? ? ? ? ?文獻標識碼:A文章編號:1672-3791(2021)04(a)-0032-03
Commodity Hybrid Recommendation System Based on Dynamic Weight
ZHOU Shuangjie1? GAO Fengling2? SUN Zhixin1
(1.School of Modern Posts, Nanjing University of Posts and Telecommunications, Nanjing, Jiangsu Province, 210000 China; 2.China Electronics System Engineering NO.2 Construction Co., Ltd.,
Wuxi, Jiangsu Province, 214135? China)
Abstract: Recommendation systems have played an important role in daily life. A single recommendation system often has problems such as cold start and data sparseness. This article adjusts and mixes the results of each recommendation service through dynamic weights to avoid a single algorithm. To improve the effect of personalized recommendation. Combine big data technology and recommendation algorithm to design and implement a product hybrid recommendation system based on big data. Finally, use Amazon's data set for system testing. The dynamic weight mixing method proposed in this article has better performance than traditional linear mixing.
Key Words: Recommendation system; Hybrid recommendation; Dynamic weight; Personalized recommendation
單一的推薦算法往往存在各種各樣的局限性,因此一個推薦系統往往由多種推薦算法組成,這些不同的算法能夠對信息達到不同的過濾效果。最常見的有內容過濾(Content Based,CB)、協同過濾(Collaborative Filtering, CF)、關聯規則(Association Rules)等。內容過濾需要提取對象的關鍵詞作為標簽并計算相似度來使用,協同過濾只需通過用戶的歷史行為數據進行推薦,包括基于物品(ItemCF)與基于用戶(UserCF)的推薦,而關聯規則發揮了“啤酒與尿布”效應,通過挖掘海量用與商品之間的規則進行推薦。以上推薦算法若單獨使用,都會存在準確度不足或是冷啟動的問題,但如果針對不同場景,將不同的算法結果加以混合,或是將某推薦算法的結果使用另一個推薦算法繼續運算,都能在某種程度上克服單一算法帶來的局限性。
1? 混合推薦簡介
在如今推薦系統中,混合方法的使用已變得更加普遍[1],單一推薦技術僅適用于解決簡單的推薦問題,而不適用于復雜的場景,每一種傳統的推薦方法在向目標用戶生成推薦時都會遇到各種問題,例如:協同過濾在增量數據上的表現不夠出色[2],但通過結果的線性混合可以獲得更高的精度[3],混合推薦系統以不同方式組合兩個或多個推薦策略,以從其互補優勢中受益[4]。除了線性混合外,也有元級混合推薦技術[5],以分層的方式結合了協作方法和基于內容的方法,提升推薦效果。
2? 動態權重混合推薦算法
細粒度的權重控制能夠提升推薦精度[6],該文提出的動態權重混合推薦算法會針對每個用戶建立推薦質量模型,將各個推薦算法的結果采用線性混合的方式加以混合,再輸出給用戶使用,首先對所有的結果進行過濾和標記,然后對所有推薦服務產生的商品評分進行歸一化處理:
(1)
是推薦算法k對用戶u推薦商品i經過歸一化的推薦得分,k(u,i)代表推薦算法k對用戶u推薦商品i的推薦分數,kmax代表該算法對用戶u推薦的最高分,kmin代表該算法對用戶u推薦的最低分。
將經過歸一化的得分乘以權重系數,得到最初質量評分加權公式:
式(2)中,Score為用戶u對應推薦商品i的得分:λ為推薦算法k對于用戶u的權重,λ0=1/n。由于線性混合參數是固定的,因此效果不夠理想,不同場景下的不同推薦算法產生的效果難以達到預期,難以形成個性化的推薦效果,為了提升混合效果,對線性混合對混合方式加以改良,引入動態參數調整機制,通過用戶行為對權重λ不斷調整。
(3)
式(3)中,P(k,u)為推薦算法k推薦出的商品被用戶u選擇的次數,當一個推薦算法被用戶選擇的次數越多時,它的比重會變得更高。所有權重和始終為1。
(4)
但即使權重經過線性調整,公式單純的分數計算會導致被多個推薦服務推薦且推薦得分高的商品過于靠前,而被多個推薦服務推薦,但推薦得分低的商品則會靠后,因此需要讓被推薦次數少的商品得到更有意義的排名,首先計算商品被推薦動態系數。
(5)
式(5)中,N為了已經被推薦過的商品的去重集合,C為所有商品被推薦過的總集合;D為每個商品被推薦的平均次數;然后將原來的歸一化得分進行貝葉斯平均數修正,得到最終得分。
(6)
式(6)中,為每個商品的平均推薦得分;C(i)為當前商品i被推薦的總次數,最后即得到改進后的用戶u對應推薦商品i的最終得分。
3? 仿真實驗與結果分析
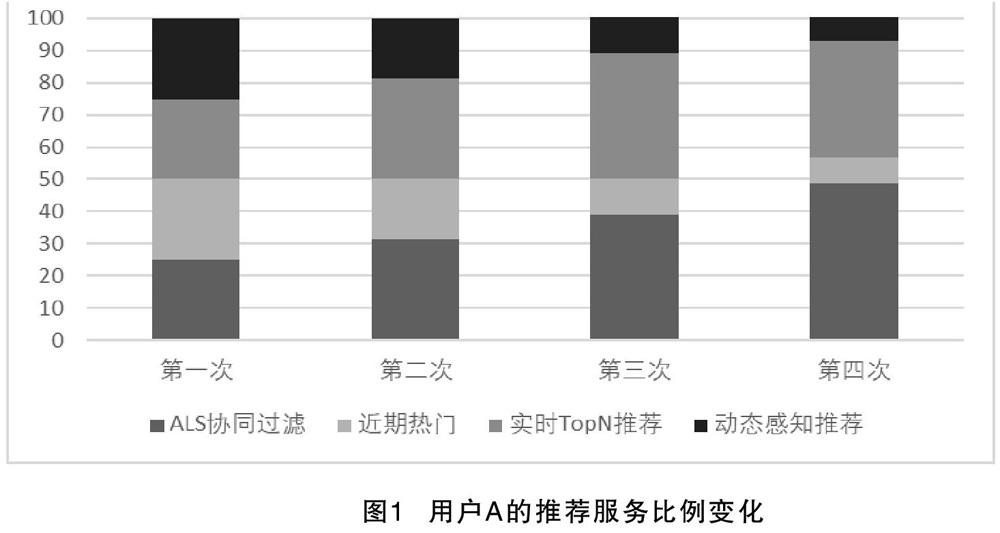
根據公式(6)計算出所有的Score(u,i)'之后,對每個用戶生成的Score進行排序,得到最終的推薦序列,以用戶A為例,在經過多次選擇之后,用戶A的λk會不斷變化,其推薦服務比例見圖1。
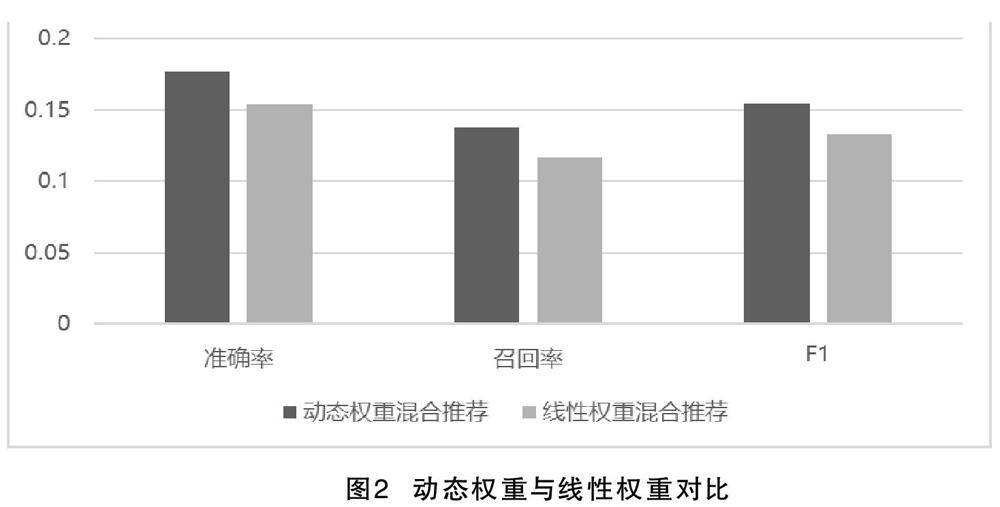
用戶在經過4次選擇之后,不同的推薦服務比重有所變化,并且ALS協同過濾對該用戶能夠起到較好的效果,但該用戶對近期熱門以及動態感知的反應并不及ALS協同過濾。圖2為動態權重與線性權重對比。
從表1結果中可以看出,經過用戶多次選擇之后,動態權重混合推薦相比線性權重混合表現更好,證明了不同用戶的確對不同的推薦方案組合存在不同的敏感性。
4? 結語
為了提升多種推薦算法的混合推薦效果,該文在現有線性混合的基礎上,提出了基于動態權重的混合推薦方法,在Amazon數據集中進行實驗,驗證該方法的有效性。該方法根據用戶對推薦結果的偏好程度來不斷改善推薦結果的權重因子,以契合不同用戶對于不同推薦算法的敏感程度,不斷提升個性化推薦效果。
參考文獻
[1] Santana M R.O., Melo L C., Camargo F H.F., et al. Contextual Meta-Bandit for Recommender Systems Selection[C]//Fourteenth ACM Conference on Recommender Systems,2020:444-449.
[2] 蔣偉.推薦系統若干關鍵技術研究[D].電子科技大學,2018.
[3] Zuo T, Zhu S, Lu J. A hybrid recommender system combing singular value decomposition and linear mixed model[C]//Science and Information Conference. Springer, Cham,2020:347-362.
[4] ano E, Morisio M. Hybrid recommender systems: A systematic literature review[J].Intelligent Data Analysis,2017,21(6):1487-1524.
[5] Immaneni N, Padmanaban I, Ramasubramanian B, et al. A meta-level hybridization approach to personalized movie recommendation[C]//2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI).IEEE, 2017:2193-2200.
[6] 王茄力.基于Spark的混合推薦系統[D].中國科學技術大學,2017.
