甘肅榆中縣常見草本植物檢索系統的設計與實現
2021-07-28 07:19:50修煬景侯蒙京謝玉鴻馮琦勝梁天剛
草業科學 2021年6期
修煬景,侯蒙京,謝玉鴻,馮琦勝,梁天剛
(蘭州大學草地農業生態系統國家重點實驗室 / 蘭州大學農業農村部草牧業創新重點實驗室 /蘭州大學草地農業教育部工程研究中心 / 蘭州大學草地農業科技學院, 甘肅 蘭州 730020)
植物分類是研究不同類群植物起源進化、發展規律和物種親緣關系的學科,其方法是將不同類群的植物按照形態和生理特征,由主到次的異同進行分類直到種并最終按照系統的規則排列,以便于人類認識和利用植物[1]。植物檢索是依照植物分類的規律和方法,通過深入了解某植物的特征后,在眾多的植物中找到目標植物的過程[2]。植物分類與檢索是植物學的重點和基礎,也是眾多生物學科發展的前提,這對植物資源的調查、物種多樣性的認識與保護以及種群起源及進化的研究有著極其重要的作用[3]。
傳統的植物分類研究主要依據生殖器官特征和營養體特征,采用平行式或定距式檢索表進行檢索和鑒定植物[2]。隨著計算機的發展和普及,圖像分類與識別技術有了新的手段和方法[4]。早在1996 年,英國國家植被分類系統(National Vegetation Classification)就基于法國的FLORA-SYS 開發而成,全面系統地總結了全英國的植被類型信息[5]。近年來,因多媒體數據庫技術可以把圖像和文字有機地結合起來,進而圖像數據庫構建、分類和檢索工作在計算機應用領域被進一步拓寬[6]。其中,Access 技術因具有占據空間小、操作簡便等優點,被成功地應用于植物分類檢索中[7]。
徐世偉等[8]使用Delphi 編程工具和Access 數據庫技術,實現了常見軍事救生植物的查詢與識別;胡楊[9]依據虛擬設計的使用環境不同,使用Access、SQL 以及VBA (Visual Basic for Applications)技術,完成了內蒙古地區唇形科植物數字化檢索系統;袁小鳳等[10]對三峽庫區珍貴瀕危植物數據進行調查,建立了基于Access 的植物地理分布信息查詢數據庫。盡管現存的植物數據庫檢索系統較多,主要是對某一范圍內各種植物資源的整合,而針對單獨某種特定類型植物的數據庫較為少見。此外,現有的植物數據庫中對植物形態特征多以文字或平面示意圖的形式表達,缺乏相應草本植物的數字圖像信息[6],致使現存的眾多數據庫檢索系統中涵蓋的草本植物信息數據不精不全,且檢索查詢的范圍較大,操作極為不便,難以滿足特定情況下的使用需求。
基于以上內容,本研究以甘肅省榆中縣為研究區,使用攝影測量的方式采集草本植物資源信息,構建了包括植物名稱、地理分布、形態特征、生態特征和3D 立體圖像等信息的數字圖像數據庫,利用Access數據庫和VBA 語言設計開發出了常見草本植物的檢索系統,針對特定的草本植物類群進行相關數據的收集、歸納和整合,旨在為草地資源調查、草類植物鑒別分類以及科研教學工作提供數據與技術支持。
1 材料與方法
1.1 研究區概況
研究區位于甘肅省榆中縣,地處103°49′15″ –104°34′40″ E,35°34′20″ – 36°26′30″ N,總面積3 259.77 km2,海拔1 430~3 670 m,年均降水量300~400 mm,年均氣溫6.6 ℃,屬于溫帶半干旱氣候。榆中縣北部地形主要為低山丘陵,中部主要為黃土丘陵,植被類型主要以草原植被和荒漠植被為主;南部大部分位于興隆山自然保護區境內,植被類型多樣,植被覆蓋度良好,植被類型主要以寒溫性針葉林、落葉闊葉灌叢為主。榆中縣整體位于甘肅省中部,地處森林植被向荒漠草原植被的典型過渡帶,草本植物類型多樣,數量較多,因此易于開展草本植物的數據收集工作[11](圖1)。
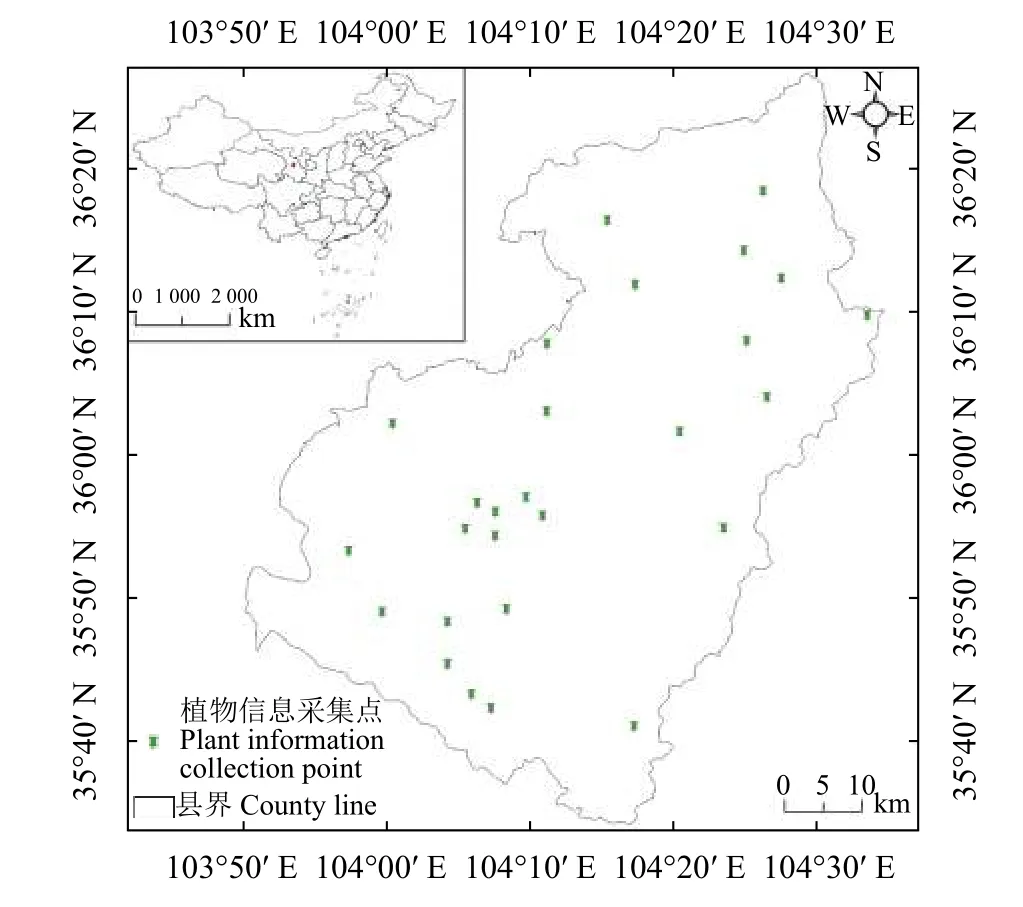
圖1 研究區采樣點空間分布圖Figure 1 Spatial distribution map of sampling points in the study area
1.2 數據收集與3D 建模
研究區內草本植物種類繁多,且許多草本植物的形態結構都較為類似,通過實地調查對植物進行分類識別。植物信息采集的主要步驟包括:1)位置確定:以GPS 數據為主,參考榆中縣植物分布圖[12],確定植物生長的位置;2)植物識別標注:對所有種類的植物進行人工標注,確定植物名稱并記錄,對于一些不能確定的物種,參照《中國植物志》或咨詢草本植物識別經驗豐富的專家,對這些植物進行反復驗證,確保識別精確;3)植物圖像數據采集:通過攝影測量方法,以適當的距離從植物各部分(花、葉、莖和果實等)進行多角度拍照;遇到植株較小或根系較淺的草本植物,還需挖取其地下部分拍攝,從而獲得全方位、完整的植物數字圖像信息。采集的植物圖像數據要求主體突出,背景簡單,細節清晰。通過中國植物圖像庫網站(http://ppbc.iplant.cn/)下載圖像對植物圖像數據做進一步補充說明[13]。
植物信息預處理:以人工篩查的方式對實地拍攝圖像進行清選,從中篩除模糊、高反光和背景雜亂等未達到拍攝要求的圖像數據。由于清選后部分物種的圖像數量較少,因此選擇水平鏡像翻轉,順、逆時針90°翻轉,裁剪等方式進行數據擴增并進一步歸納整理[14]。最后以《中國植物志》為標準,對各種植物數據進行標準化處理,建立草本植物圖像數據集。將搜集到的植物信息歸納整理且把每個物種作為一個單獨的子數據集;Access 數據庫中每個數據集為單個文件,最大理論容量2 G;當數據儲量過大時,可使用Access 的數據項目直接聯系到SQL(Structured Query Language),通過新建一個數據庫項目將其導入即可實現。
利用Agisoft Photoscan 軟件實現植物3D 模型的建立。Agisoft Photoscan 是一款根據數碼相片將2D圖片數據轉化為3D 模型數據的三維重組軟件,該軟件的三維重組技術的最大特點和優勢是無需設置初始值,軟件即可自主識別所添加圖片數據的重疊部分,從而完成建模任務(http://www.agisoft.cn/)。通過添加模塊、添加照片、對齊照片、成對預選、建立密集點云、設置工作區、生成網絡、生成紋理等一系列方法構建植物三維模型(圖2、圖3)。
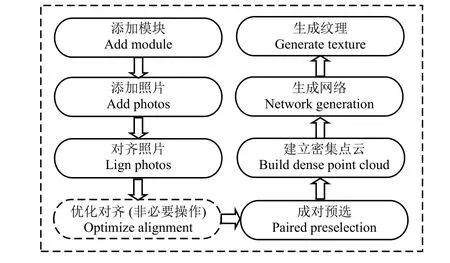
圖2 Agisoft Photoscan 3D 建模流程圖Figure 2 Flow diagram of Agisoft Photoscan 3D modeling

圖3 植物三維模型圖(示例)Figure 3 Plant 3D model diagram (sample)
草本植物數字圖像數據收集時間為2019 年4 月至9 月,共獲得9 372 張照片。其中,數碼相機實地攝影測量采集到256 種草本植物的圖像數據,涉及禾本科、豆科、十字花科等13 個科,共5 664張;通過中國圖像數據庫下載到的圖像數據共3 708張。由于在植物圖像數據實地采集過程中不可避免存在未達到建模標準的圖像數據,會造成建模成功率降低,因此最終共建立植物3D 模型211 種(表1)。

表1 進行3D 建模的植物物種清單Table 1 List of plant species for 3D modelling
1.3 關鍵技術介紹
該軟件系統開發基于Delphi 編程工具和Office中的Access 來設計實現。其中前端的操作功能利用Delphi 編寫VBA 語言完成,后臺數據庫采用Access管理工具。Delphi 是一種基于窗口、面向對象和可高速編譯的可視化編程工具。Delphi 能完成從底層、網絡到平臺開發等一系列工作,運用范圍廣,尤其是在數據庫開發方面更具優勢[15]。VBA 是新一代標準宏語言,該語言簡單且功能強大。它由微軟公司開發,在其桌面應用程序中執行通用的自動化任務的編程語言,是可視化、解釋性以及面向對象的BASIC 語言。Access 是一種數據庫管理系統,它所占據的空間較小,系統邏輯清晰且操作簡便,一直以來都被廣泛作為中小型數據庫后臺存儲的理想介質。它具有和Office 軟件功能相似的數據庫,允許使用子數據表,允許從Excel 或向Excel 導入數據,能對數據的相關數據自動更正,能通過設置條件來控制結果輸出,并在關閉時對文件自動進行壓縮調整[16]。
1.4 草本植物檢索功能精度評價
為了保證檢索系統的可靠性,分別用正向檢索途徑和反向檢索途徑兩種檢索方式進行精度評價。正向檢索的精度評價是從數據庫中所涵蓋的所有物種中,通過隨機選擇的方式挑選出10 種草本植物,查詢字段選擇為名稱并在查詢內容中輸入中文名稱(或拉丁名),逐一判斷輸出結果是否與目標植物一致。其精度評價公式如下:
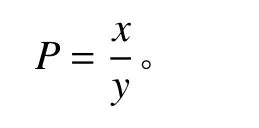
式中:P為識別準確率;x為檢索結果正確的物種數,y為正向檢索的物種總數。
在反向檢索途徑中,根據限定信息的數目,對不同科屬物種的識別精度進行分類評價。從各類不同科屬植物中隨機選擇5 種(車前科除外),隨機選擇每個植物較為明顯或較易觀察的形態特征(如葉形、葉序、花色、花序、萼片數和種子類型等特征)進行查詢,得到目標物種數并計算其平均數,進而計算出該科屬植物識別準確率。其精度評價公式如下:
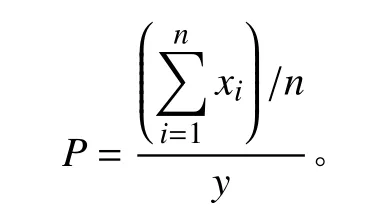
式中:P為識別準確率;n為隨機選擇的物種個數(n= 5);x為各物種經查詢得到的目標物種數;y為數據庫中的總物種數(y= 256)。

續表1Table 1 (Continued)
2 系統設計
2.1 系統構架設計
該系統遵循 MVC 的分層設計思想,將系統整體上分為數據層、應用邏輯服務層以及表現層[17](圖4)。數據層由植物素材知識庫和植被信息知識庫組成,通過植物編號字段進行一對一主鍵關聯。這樣設計便于清晰明了地表示實物顯示中的關系,方便數據管理以及功能擴展。表現層由登錄界面和系統前臺界面組成,其中登錄界面包含用戶名、密碼、登錄按鈕和退出按鈕,這樣設計的優點在于操作簡潔,便于對用戶標識鑒別和后臺登錄信息的審核管理。系統前臺界面包含查詢字段、查詢內容、查詢按鈕、重置按鈕以及植物的各類相關信息,此設計方便查詢操作,且能清楚地顯示植物信息。邏輯服務層可以實現數據的“查改增刪”,利于對存取控制和視圖機制的安全管理。通過ID 唯一身份標識碼檢索,邏輯層面的檢索成功率可達100%,能準確地查詢到目標對象;通過植物各字段信息關鍵詞檢索,邏輯層面的檢索成功率較高,且隨著關鍵詞數目的增加而提升。
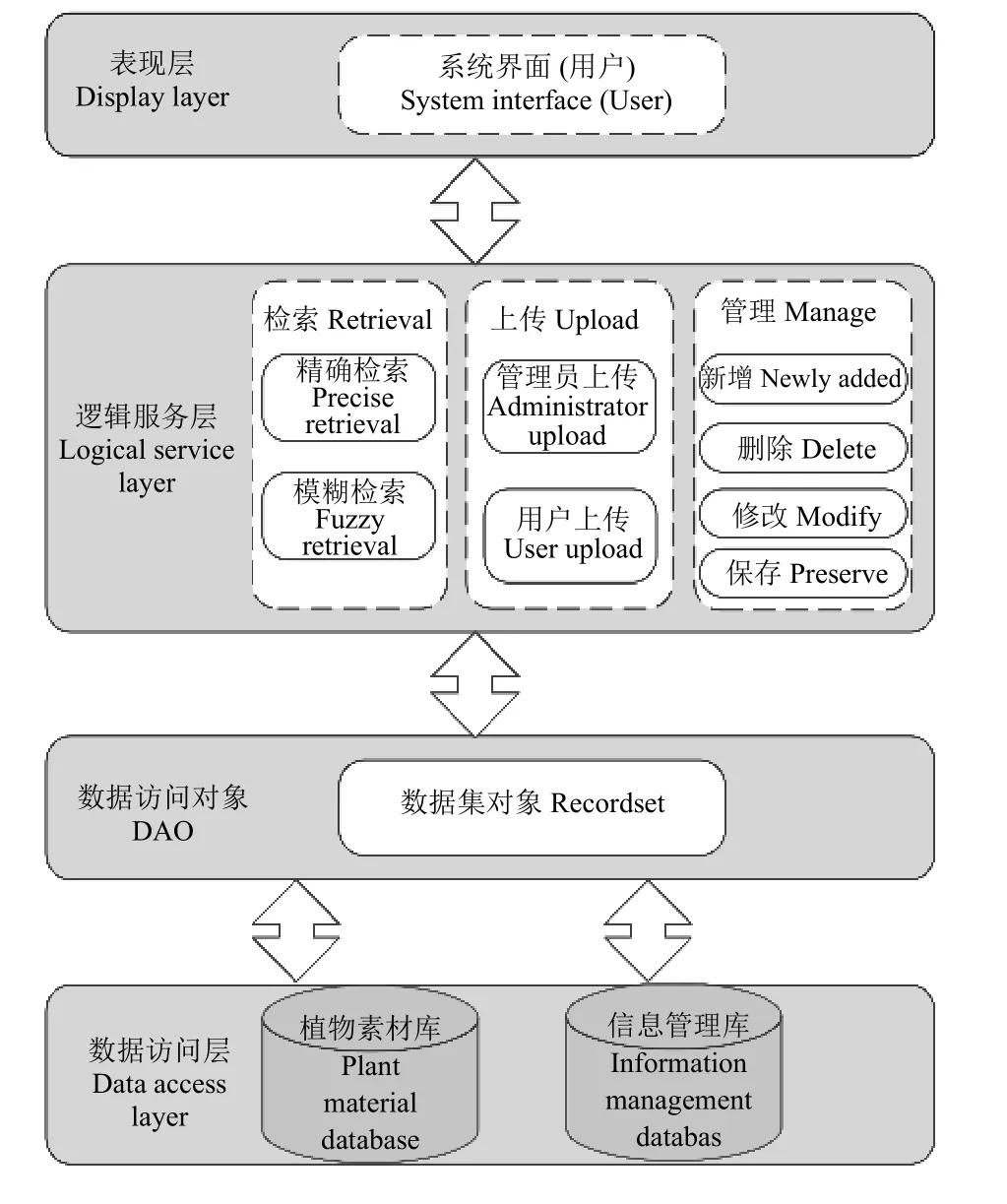
圖4 檢索系統結構層次圖Figure 4 Hierarchy of retrieval system structure
2.1.1 數據層(Model)設計
新建類模塊并命名為Model,為tblData 中各字段定義私有變量,使用DAO 中的Recordset 對象作為中介。上述代碼對Recordset 對象變量mrst 的定義完成后,在類的實例化事件中為mrst 創建基于表tblData 的數據集,其中tblData 位于本地,若轉移tblData 只需修改此處的代碼即可。此外為Model 類模塊設計外部接口,在考慮外部接口對私有變量讀取的基礎上設計“查改增刪”接口。
1)查詢接口:查詢接口通過函數設計實現。該函數由植物名稱,葉形、葉序、花色、種子類型,耐寒性,水分要求和地理位置等字符串構成,這些字符串將形成一個唯一標識的ID,通過form 表單傳遞的方法進行傳參。需注意的是一個函數只能返回某單一值,而此處需返回的值包括多個字段,因此將返回值保存在類的私有變量中。此處使用到Recordset的Seek 方法[18],該方法需為其提供索引值,具有較快的查詢效率。
2)修改接口:由邏輯分析可知,對于tblData 某條數據的修改,需找到目標數據所在字段,如植物編號、植物名稱、生長環境、地理分布范圍和形態特征等,再將修改值返回到函數數據中。此處通過向接口函數傳遞Model 類型的參數實現,即向Model類中的函數Update 傳遞Model 類參數,再將Model類對象作為Update 參數,即使用新的植物信息數據覆蓋原有的數據。這兩類參數均為動態參數,參數文件內容包含植物的文字信息數據或圖象信息數據。此方法的優點是既能傳遞所需修改的目標信息,又可以傳遞修改后的目標值。
3)新增接口:向tblData 添加一條記錄,需要提供新記錄所有字段的值。綜上,此處仍為接口函數傳遞Model 類型的參數,即代碼首先根據提供的參數查看是否能在已有數據中查詢到目標(此處提供的參數以植物編號和植物名稱為主)。若不能查詢到目標則允許將記錄添加到tblData 中。
4)刪除接口:該接口提供數據的某一字段信息(此處字段以植物編號和植物名稱為主),找到后將其刪除即可。
2.1.2 邏輯服務層(Controller)設計
再次創建類模塊,命名為Controller。定義兩個對象變量,分別為數據層和視圖層中的植物信息參數并點擊系統前臺界面中的重置按鈕將其初始化。由于View 初始化時,需要向其指定一個具體窗體,即需將該窗體作為系統的前臺界面。因此為Controller設計一個Init 接口,該接口可鏈接到目標窗口從而將植物的信息數據傳入具體的窗體對象。使用控制器層(Controller)實現“查改增刪”接口。重新實現“查改增刪”無需重寫數據層代碼,而是將以上操作代理給模型層(Model)對象變量mobjModel。
2.1.3 視圖層(View)設計
設計一個將數據顯示到窗體界面的接口,并用窗體(Form)作為用戶界面。此處不直接在窗體代碼模塊中處理數據的顯示問題,而是額外用一個類模塊View。聲明一個Access 窗體變量,將數據顯示到窗體上。雖然已有mfrm 窗體對象變量,但在代碼運行時并不確定該對象變量將會指向的具體窗體,因此在View 對象在初始化后為mfrm 指定一個具體窗體用以完整的顯示各類型植物信息。同時,在View 類對象銷毀時釋放掉mfrm 的指針,實現接口函數Display 用以將植物的各字段信息顯示到mfrm窗體上,該接口函數Display 使用超鏈接的方法傳遞參數:當點擊檢索系統前臺的查詢按鈕后跳轉到類模塊View 的初始化對象,進而傳遞植物編號(ID)和植物名稱(Name)參數。設計一個反向接口GetDisplayedData 用以獲取mfrm 窗體上所顯示的數據。最后添加幫助函數,該函數同樣通過超鏈接的方法傳參,方法是點擊系統前臺界面中的重置按鈕,用以清空mfrm 窗體上數據的顯示。
2.2 數據庫邏輯設計
數據庫邏輯設計是將系統接收到的用戶需求通過信息的提取進而轉化為概念模型信息的過程,該設計得以實現的理論依據是各個數據信息內部存在的語義關聯性,通過信息內部的關聯得到抽象模型。本系統用到的模型為E-R 模型[19],該模型是對于現實的抽象表現,其基本語義包括實體(科屬種)、實體屬性(科屬種拉丁名和中文名、地理分布、形態特征以及生長環境)與集合之間存在的聯系(屬從屬于科、種從屬于屬)。本系統的邏輯設計原則是將E-R 圖,即實體與實體、實體與屬性之間的關聯性按照一定的原則轉化為關系模型,并確定模型的屬性和碼[19]。轉化原則如表2 所列。

表2 系統邏輯算法流程Table 2 System logic algorithm flow
2.3 系統模塊(功能)設計
系統的設計模塊(圖5)顯示,用戶對該檢索系統使用過程中,可在主頁面下通過不同的檢索字段來選擇其中某一種方法,根據所掌握的數據信息選擇合適的查詢字段,例如植物中文名稱、拉丁名、形態特征、地理分布和生長環境等進行檢索操作,系統經過邏輯運算后,在頁面的下方給出所有符合限定條件的檢索結果。除此之外,用戶可通過輸入戶名和密碼進入管理界面,執行植物信息的增加刪除管理功能[20]。
在后臺管理模塊中,用戶可通過輸入用戶名和密碼進入系統的管理界面,在此可完成數據的修改,添加和刪除,包括植物名稱、形態特征、地理分布和生長環境等文本信息和圖像數據。在植物檢索模塊中,用戶可通過名稱、形態特征、生長環境、地理分布4 個方面的信息檢索植物(表3)。通過正向檢索途徑查詢某植物中文名或拉丁名,當系統在數據庫中檢索到目標植物后,會將結果輸出給用戶;用戶也可通過反向檢索途徑查詢某植物除名稱外其余不同字段的關鍵詞,即給出某種植物的形態特征等信息來確定植物名稱。每個部分都支持關鍵詞檢索,這提高了模糊查詢的成功率[21]。

表3 植物信息統計表Table 3 Statistical table of plant-related information
3 系統的實現
3.1 系統基礎功能實現
在系統登陸界面(圖6)輸入特定的戶名及密碼即可進入后臺管理界面,該界面與檢索系統界面相同,但區別在于當處于管理界面下,各文本信息模塊均可實現增刪和修改,且圖片信息模塊下方的添加/修改、保存并新增和刪除圖片按鈕可執行操作;而當處于訪客登陸狀態,即處于檢索界面時,以上操作均不可被執行和實現,但用戶可通過管理員獲得管理許可進行信息編輯。
圖6 系統登陸界面Figure 6 System login interface
在該系統中,可根據不同字段進行多條件聯合查詢(圖7)。系統主界面主要可分為檢索模塊、文字信息模塊(包括植物編號、名稱、生長情況、地理分布、形態特征等基本信息)和圖片信息模塊。使用者可通過檢索模塊正向檢索,將查詢字段選為名稱,在查詢內容中輸入物種名稱,點擊查詢即可顯示對應的植物信息,選擇重置即可重新檢索。使用者也可通過檢索模塊反向檢索,如:將查詢字段選為生長環境,輸入該植物的地理分布范圍,點擊查詢;繼續將查詢字段選為形態特征,輸入該植物的外部形態,點擊查詢;這樣通過逐級檢索的方式即可查詢到目標植物的名稱,最后選擇重置即可重新檢索。在反向檢索時,當輸入某植物的部分信息進行檢索并選擇查詢后,會展示當前限定條件下所有符合的植物類型。所以若想準確地確定目標植物名稱,須盡可能多的確定該植物的特征信息,從而縮小目標范圍,并對照各植物的特征信息、圖像數據以及3D模型,最終確定目標植物。

圖7 系統檢索界面Figure 7 Search system interface
3.2 系統穩定性評價
本系統使用的工作站處理器為AMD Ryzen R5-4600H,主頻為3.00 GHz,動態加速頻率4.00 GHz,16 G 內存,顯卡GTX 1650Ti,運行系統為Windows 10。啟動該檢索系統時CPU 占用率約保持在20%,但隨著使用時間延長,CPU 占用率會隨之增長,在35%左右逐漸趨于平穩;內存使用率隨系統運行時間的延長變化不大,基本維持在17%左右(圖8)。在整個使用過程中系統響應時間較快,未出現明顯遲滯。Access 最大支持數據可達2 G,數據庫最多可支持約255 個并發訪問。除了在CPU 滿負載運行時,其余大部分情況下的使用一般不會感覺到明顯遲滯現象。說明系統運行較為穩定,可滿足絕大部分使用需求。
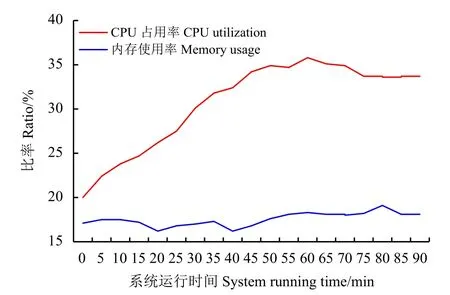
圖8 CPU 占用率以及內存使用率變化圖Figure 8 CPU utilization change chart
3.3 系統檢索功能精度評價
為了保證檢索系統的可靠性,分別對正向檢索途徑和反向檢索途徑兩種檢索方式進行精度評價(表4)。經判定,正向檢索途徑識別準確度接近100%,說明精確查詢準確性良好。在反向檢索途徑中,當輸入的形態特征信息數為3 條時,識別準確率最高的是車前科,達到100%,其次是莎草科和藜科,兩者分別達到77.7%和76.5%,準確率最低的是禾本科,為56.9%。當輸入的形態特征信息數為6 條時,識別準確率最高的是車前科、旋花科、莎草科和蒺藜科,均達到100%,其次是薔薇科和豆科,分別為90.0%和89.7%,準確率最低的仍是禾本科,為82.4%。隨著限定信息條數的增加,各科植物物種的識別精度都得到了提高,尤其是旋花科、禾本科等識別精度提升明顯,分別上升了28.6%和25.5%。該系統對各科物種識別準確率的高低存在差異的主要原因是由于各科不同種的植物形態特征的相似程度不同以及各科植物在數據庫中的總容量不同。但可以肯定的是,限定的信息數目越多,對植物的形態特征描述越準確,得到的目標范圍越小,也就越容易確定目標植物。
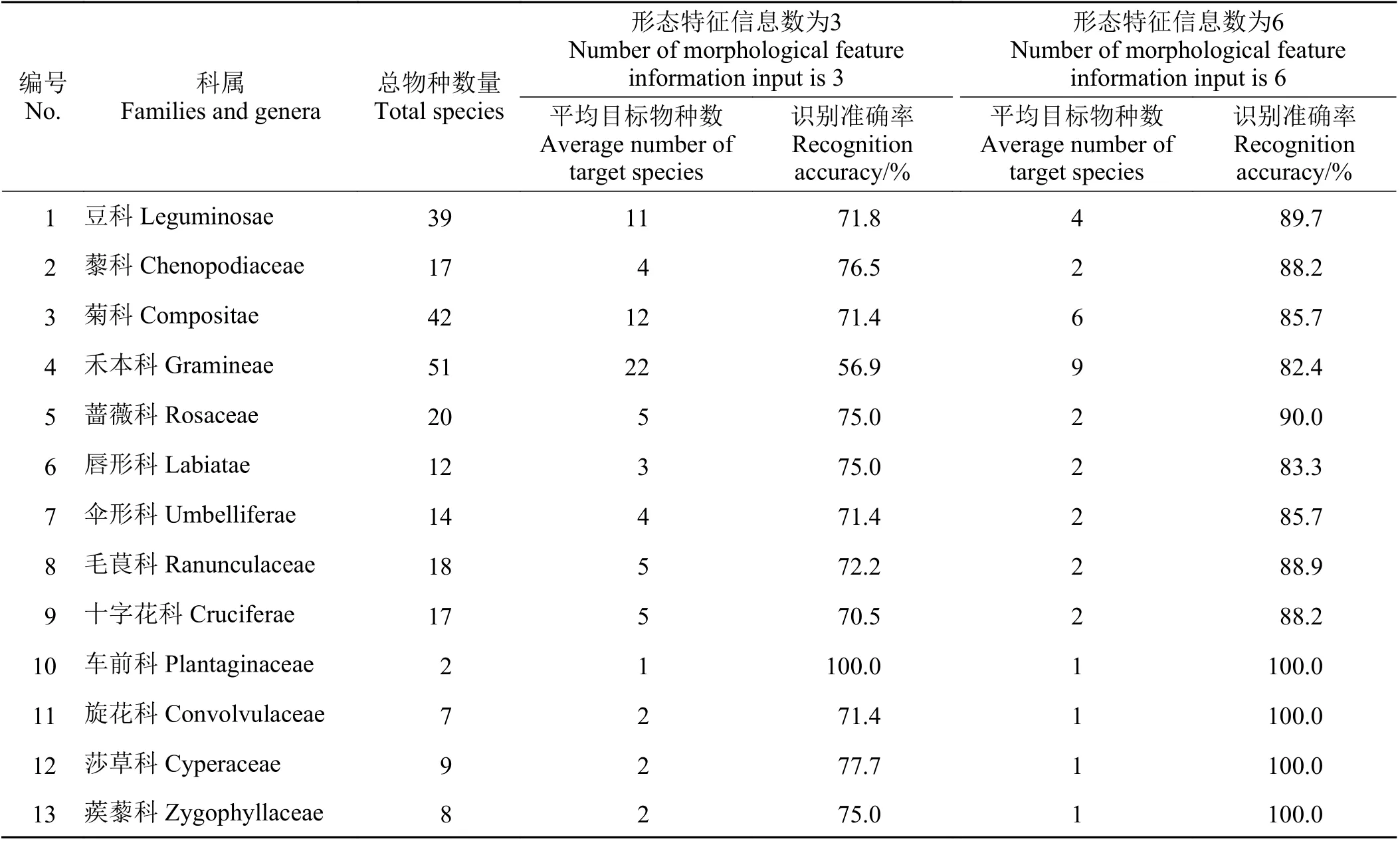
表4 不同科植物物種模糊查詢準確率Table 4 Accuracy of plant species identification in different families
4 討論與結論
本系統基于Access 數據庫,利用VBA 語言編寫完成,通過多種方式對256 種草本植物的數據進行收集、整理和分類,構建出草本植物檢索系統。經驗證,當輸入形態特征信息數為3 條時,除了禾本科以外,植物識別率均在70%以上;輸入形態特征信息數為6 條時,植物識別率均在80%以上,其中車前科、旋花科、莎草科和蒺藜科識別率可達到100%。該系統檢索準確度較好,能夠勝任日常使用需求。其中,禾本科識別精度較低,原因主要是禾本科各物種之間形態特征相似度較高,識別難度較大。
與傳統方法相比,本系統不必逐條判斷植物形態特征,檢索效率得到極大提高。為了體現與傳統檢索方法相比之下的高效性,分別測試了在正向檢索和反向檢索情況下兩種檢索方法的效率差異(表5)。在相同時間內對選取同一批植物依次進行檢索,并保證檢索結果正確無誤。經判定,5 min 內使用該檢索系統的正向檢索數目為66 個,反向檢索數目為19 個;5 min 內使用中國植物志的正向檢索數目為9 個,反向檢索的數目為4 個。

表5 5 min 內檢索正確的物種數量Table 5 Retrieval of the correct number of species in five minutes
本系統也仍有一些待改進之處,如利用實地拍攝和網絡數據補充兩種方式完成了對草本植物圖像數據的收集,并對部分物種數據進行了擴增,但仍存在部分植物圖像數據少的問題,進而影響3D建模的結果;本系統目前尚不支持網頁端和移動端的使用,使用中存在一定的局限性。這些都是在后期需要注意完善和改進優化的方面。今后進一步研究考慮擴大研究區域,收集更多草本植物圖像數據,優化數據庫結構,對常見的植物形態結構做出圖文示意,擴大系統適用群體。此外,將數據庫部署發布至網頁端和移動端,實現更加便利的草本植物信息檢索,以期為開展草地資源調查監測、科研教學等方面提供技術支持。
此外,該系統便攜性更好,更利于在戶外環境中的使用;其他同類檢索系統,如孫學剛等[22]完成的甘肅省稀有瀕危植物數據庫和田興軍等[5]完成的江蘇植物資源信息系統,其系統內的植物信息雖覆蓋面廣,但數據體量大,針對于草本植物的檢索效率低,且錄入的信息不夠精細,致使模糊查詢效果不理想。本數據庫所包含的數據僅限于草本植物,數據信息與之相比更加精細完整,模糊查詢準確度更高;數據體量較小,系統反應速度快,使用體驗良好。此外,本系統還為每種植物構建了3D 模型,使用戶對植物形態特征有更直觀的感受,同時也可依據其提高模糊查詢準確性。Access 在數據量過大或訪問人數較多時IIS(Internet Identity System)可能會出現假死現象。管理者可通過定期編輯數據、壓縮數據庫、限制注冊與登陸人數等措施來保證其良好的使用性。若系統使用的需求量較多或數據量很龐大時,可以考慮將Access 數據庫轉化為SQL 數據庫。
猜你喜歡
英語世界(2023年10期)2023-11-17 09:18:18
科學大眾(中學)(2019年3期)2019-05-17 10:04:30
汽車觀察(2018年10期)2018-11-06 07:05:26
紅領巾·萌芽(2017年5期)2017-06-23 10:35:59
財經(2017年2期)2017-03-10 14:35:35
爆笑show(2016年7期)2017-02-09 09:36:13
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
少兒科學周刊·兒童版(2015年10期)2015-11-07 03:42:03
