基于眾源數據的地理知識存儲方法研究
2021-07-24 16:03:16楊波趙英俊
世界核地質科學 2021年2期
楊波,趙英俊
(核工業北京地質研究院遙感信息與圖像分析技術國防科技重點實驗室,北京 100029)
在眾源數據中,數據的收集和管理是眾源數據應用的基礎。隨著日常需求量的變化,以單一文件來收集與管理眾源地理知識已經無法滿足地理信息應用需求。目前眾源數據主要利用數據庫技術進行存儲管理。但是,眾源數據的地理知識的數據節點和其屬性關系的復雜性,造成經典關系數據庫無法滿足對眾源地理知識進行存儲的場景需求。因此,本次研究以核電站場景為例,探究核電站眾源地理知識的存儲方法。為了更好地進行三元組地理數據的存儲,筆者查閱了相關研究文獻,發現,當前主流方法是利用圖數據庫的方法對地理知識數據進行存儲[1-4]。本研究首先分析核電站圖數據模型和圖查詢語言等模型設計原理,詳細分析了如何利用各種主流知識圖譜數據庫構建地理知識圖譜,包括基于關系數據庫的存儲方案、面向資源描述框架(Resource Description Framework,RDF)的三元組存儲結構和知識圖數據庫。其次以圖數據庫Neo4j為例設計核電站圖模型數據的底層存儲原理,同時梳理圖數據索引和查詢處理等關鍵技術[5]。最后,以Neo4j為例,針對知識圖譜數據庫開源工具進行眾源地理信息的實踐,數據結果與技術流程可利用于地理信息領域。
1 眾源數據知識模型
從數據模型角度來看,知識圖譜本質上是一種圖數據[6-9]。不同領域的知識圖譜均需遵循相應的數據模型。往往一個數據模型的生命力要看其數學基礎的強弱,關系模型長盛不衰的一個重要原因是其數學基礎為關系代數。知識圖譜的初始發展來自數學經典圖論理論,在圖論中,圖是二元組G=( )V,E,其中,V是節點集合,E是邊集合。圖論認為客觀現實可以用實體及其屬性集合來抽取,而眾源數據的知識模型也因此發展而來。
1.1 資源描述框架
RDF是萬維網聯盟(World Wide Web Consortium,W3C)官方認證的W3C指定的知識描述眾源數據知識模型。在RDF三元組集合中,單一的眾源事件信息都配有一個身份信息。事件信息的抽取方法是用三元組的形式進行抽取,三元組模型的抽取結構是(s,p,o)[10-11]。其中,s是主語,p是謂語,o是賓語。(s,p,o)表示知識s與知識o之間具有關聯p,或表示知識s具有屬性p且其結果為o。
圖1所示是核電站員工的基于眾源數據的知識圖譜。其中,有運行二部的張某、李某與運行三部的趙某、王某4名研究人員。張某、李某來自運行二部,屬同事關系。趙某、王某來自運行三部,也屬同事關系,且李某與趙某屬多元關系。他們4人共同參與了運營管理和實驗2個項目,其中,實驗項目[12]是屬于運營管理項目。由于受本文內容的限制,只做簡要的方法建設,現實中的人員與項目內容節點與屬性的眾源知識遠比圖中所示的復雜度高。
值得注意的是,RDF本身的節點和屬性并無元數據信息。各類節點及屬性的表示方式如圖1中實線四邊形,即圖中的矩形。邊上的屬性存儲方法表示起來稍顯繁瑣,在眾源數據的表示過程中,通過抽象一類總節點本體[13]來對地理實體進行統稱。如在圖2中,通過設計超節點ex:參與實例類(ex:zhang,參與,ex:operation)來實現節點屬性的表達,該節點通過RDF內置屬性rdf:主語、rdf:謂語和rdf:賓語進行眾源地理知識的內部建模,其中實例(ex:參與,權重,0.4)就實現了為原三元組增加邊屬性的效果。
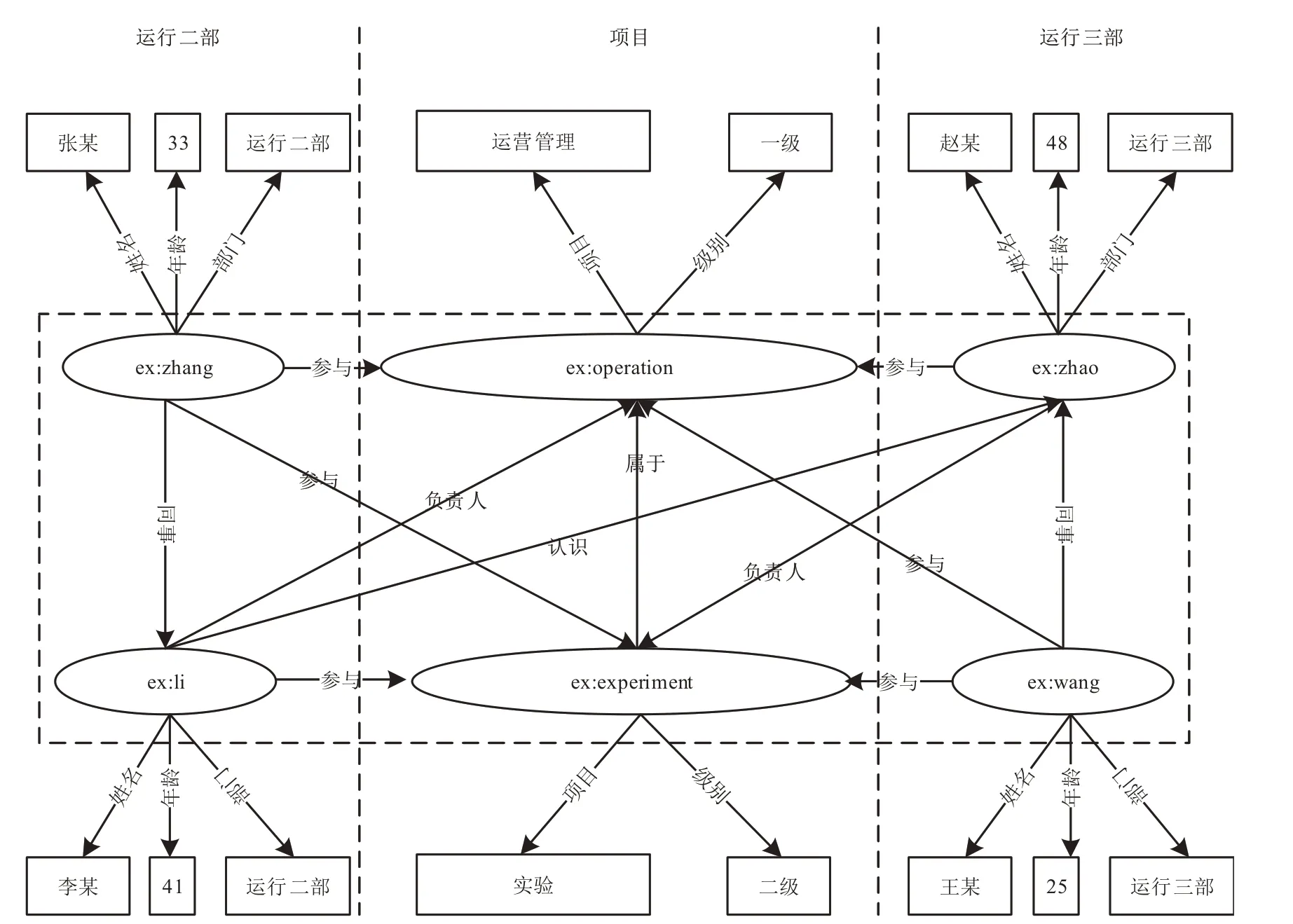
圖1 A廠眾源知識Fig.1 Crowdsourcing data of A factory
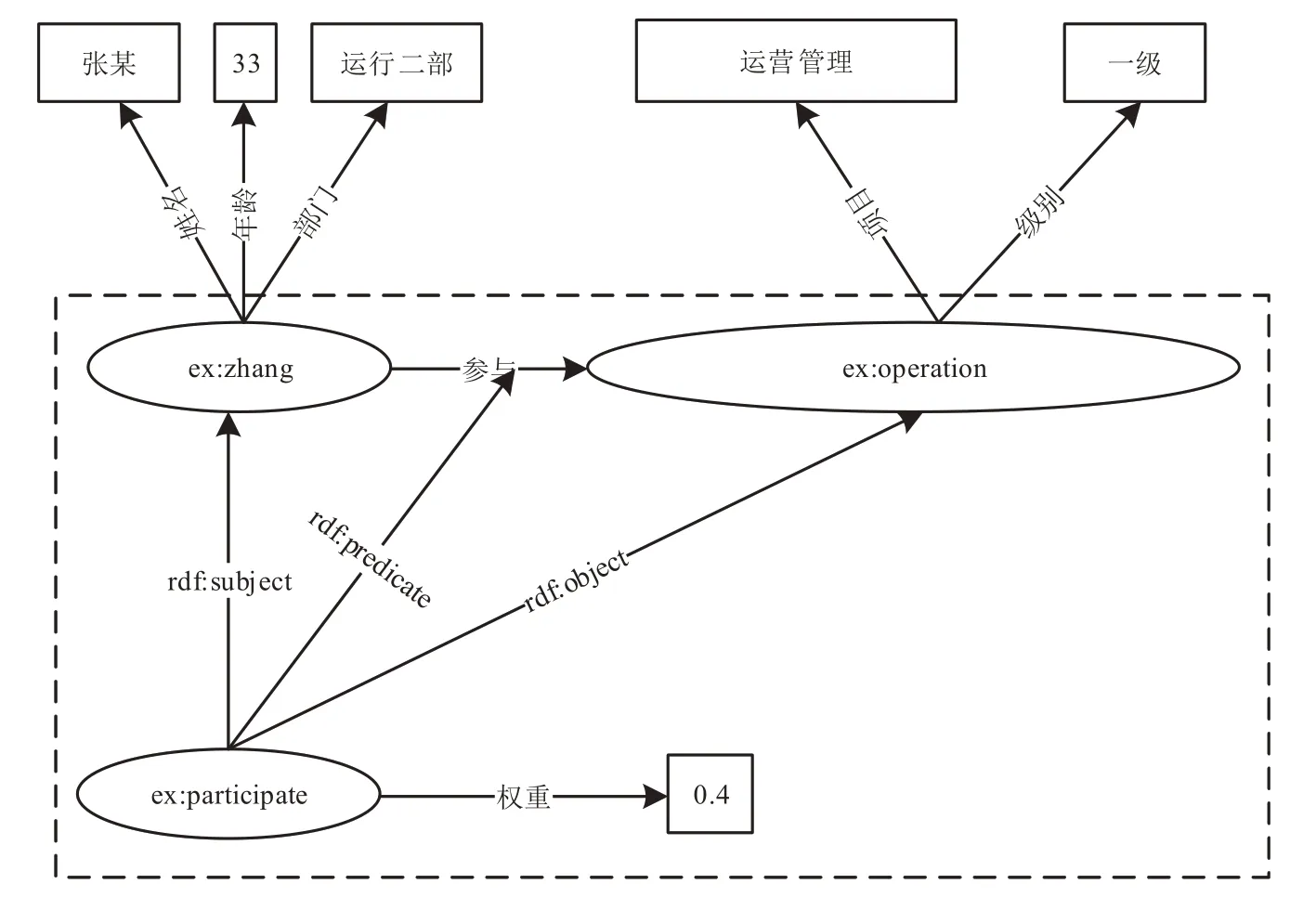
圖2 眾源知識中邊屬性的表示Fig.2 Representation of edge attributes in RDF graph
1.2 屬性知識建模
屬性知識可以說是目前被圖數據庫業界采納最廣的一種圖數據模型。屬性知識由節點集和邊集組成,且滿足如下性質:
(1)每個節點具有唯一的id;
(2)每個節點具有若干條出邊;
(3)每個節點具有若干條入邊;
(4)每個節點具有一組屬性,每個屬性是一個鍵值對;
(5)每條邊具有唯一的id;
(6)每條邊具有一個頭節點;
(7)每條邊具有一個尾節點;
(8)每條邊具有一個標簽,表示聯系;
(9)每條邊具有一組屬性,每個屬性是一個鍵值對。
圖3的每個節點和每條邊均有id,遵照屬性知識的要素,節點1的出邊集合為{邊11,邊18},入邊集合為{邊10,邊15},屬性集合為{姓名=趙某,年齡=48,部門=運行三部};邊11的頭節點是節點5,尾節點是節點1,標簽是“參與”,屬性集合為{權重=0.4}。
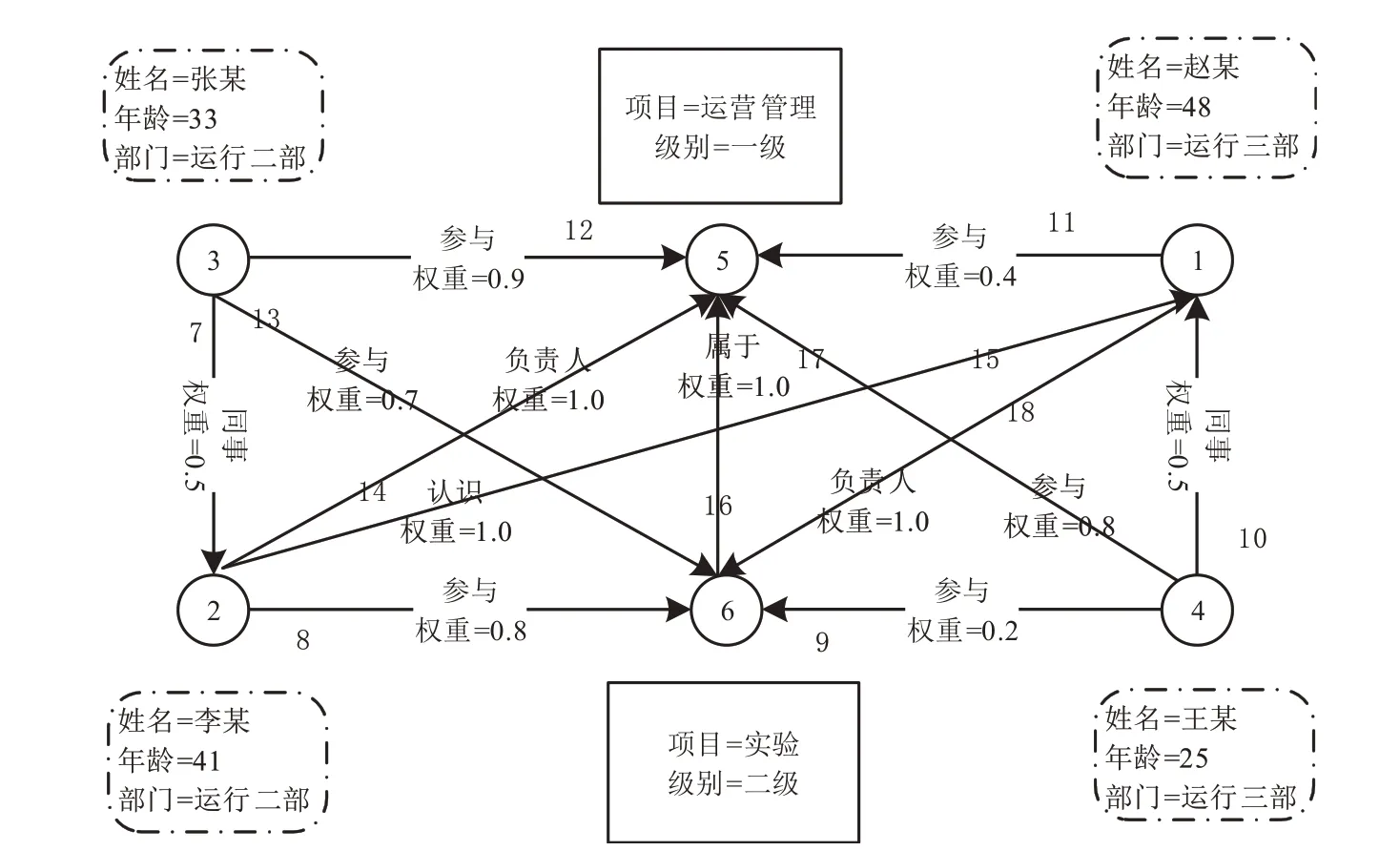
圖3 屬性知識示例Fig.3 Example of property graph
2 眾源知識存儲方法
為了對眾源數據進行有效存儲和管理,調研發現,眾源數據管理方法有三種類型,關系型、三元組型及原生圖數據庫型,通過文獻調研和核電站數據實驗發現,第三種方法最適合本次研究內容。其中,關系數據庫擁有40多年的發展歷史,從理論到實踐有著一整套的成熟體系[14]。數據庫體系從層次數據庫到關系數據庫轉變,這也帶來了一系列商業數據庫的誕生與發展[15]。以此類推,知識型數據管理方法的誕生也催生了一類知識型商業數據管理與存儲產品。因此,本此研究核心部分將要利用知識型數據的管理及存儲方法對眾源數據進行有效的收集和管理。為此,構建了眾源數據的知識管理方法、橫向存儲方法、屬性存儲方法、縱向存儲方法、多重查詢方法以及混合管理方法,為基于眾源數據的地理知識存儲提供多元存儲方案。
圖4所示是以收集并處理核電站的眾源數據集的RDF數據作為知識圖譜進行實驗和舉例。該知識圖譜構建了N公司及其董事長陳某和M公司及其董事長劉某的節點屬性和弧關聯。該實驗數據對于其他格式的知識圖譜,這種存儲方案同樣適用。
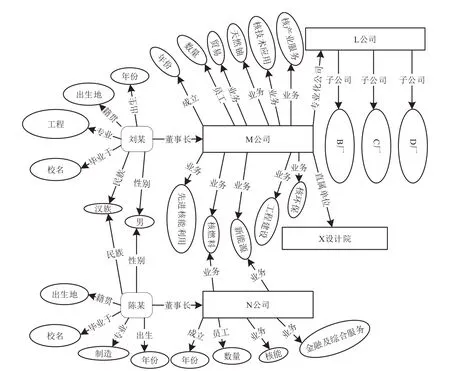
圖4 核電站眾源數據RDF知識圖譜Fig.4 Crowdsourcing data RDF knowledge graph for nuclear power plant
2.1 知識管理
知識管理方法的核心組成如下:知識管理方法(主語,謂語,賓語)
如表1所示,以M和N公司員工為例,對眾源數據中的知識信息進行抽取挖掘得到下表。每一個實體代表一個類似的主語節點,謂語表示屬性信息,賓語是尾節點知識。
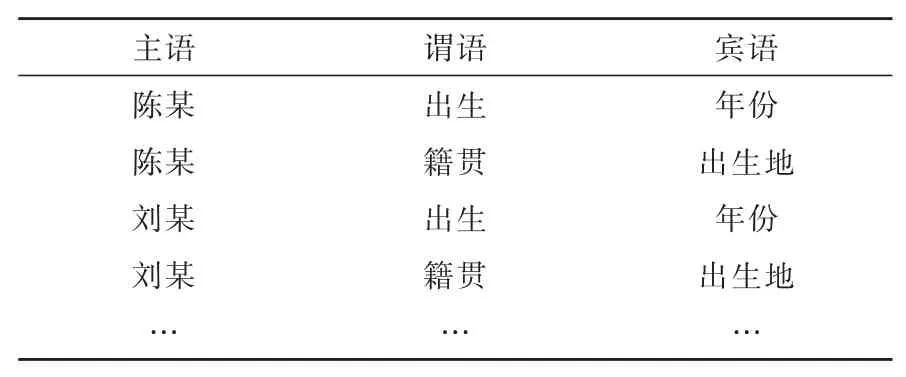
表1 三元組存儲案例Table 1 Triple storage case
知識管理方法的優點是結構簡單,眾源數據的技術入門比較低[16]。但缺點是規則混亂,無標準可參考。圖5所示的SPARSQL查詢時查找某年份出生且是某出生地的某公司的董事長,并且可以將該SPARSQL查詢轉換為關系型數據庫查詢。
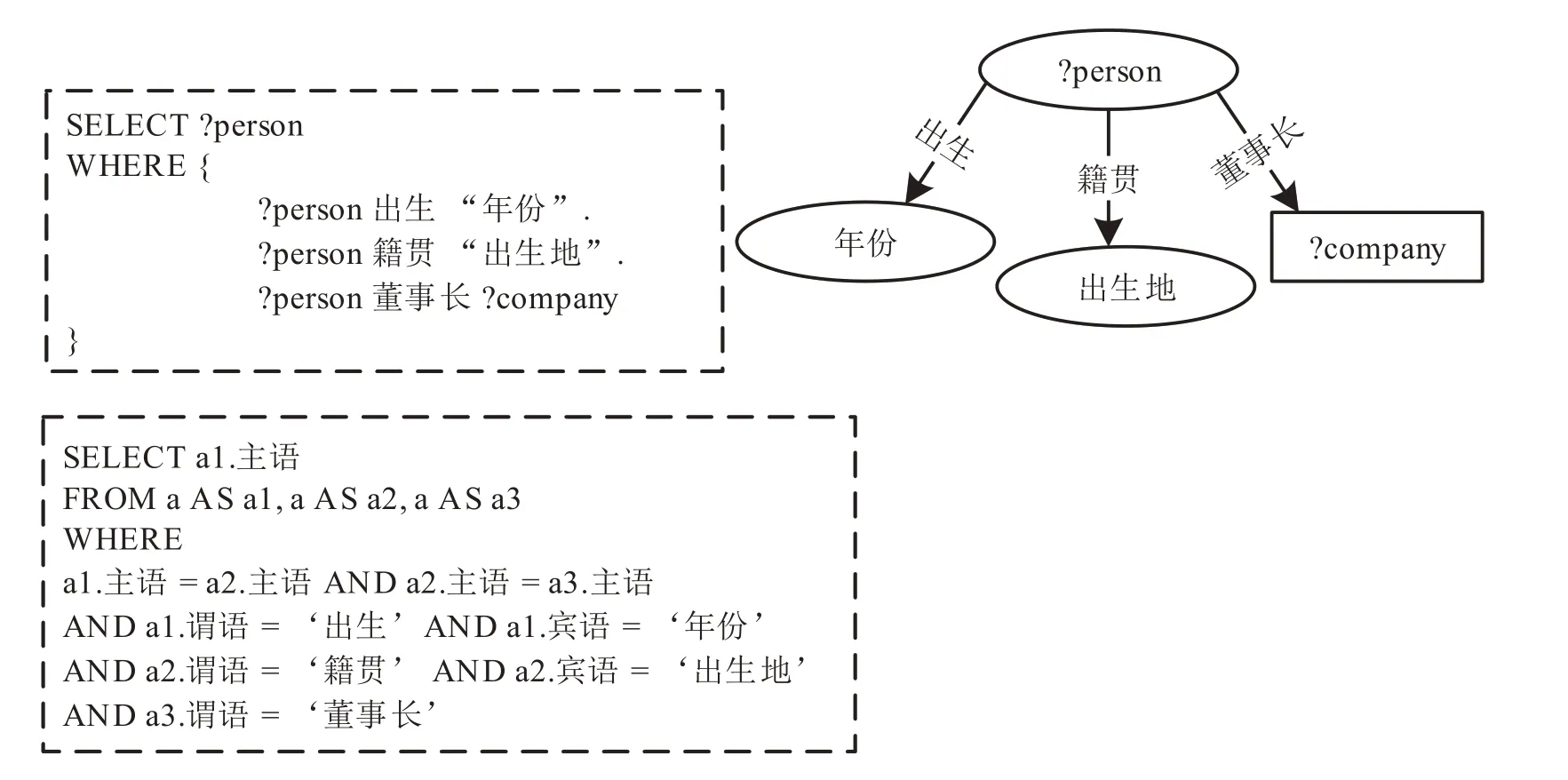
圖5 SPARQL查詢與SQL查詢對比Fig.5 Comparison between SPARQL query and SQL query
2.2 橫向存儲
橫向存儲法的特點是存儲結構框架模式,該方法與知識管理方法不同,這里的方法是將眾源數據按照行優先的策略進行存儲。具體內容如表2所示,其共有5行、5列,限于篇幅省略了若干列。不難看出,橫向存儲法用列創建眾源數據的屬性信息,而行用于創建事件的頭節點內容。
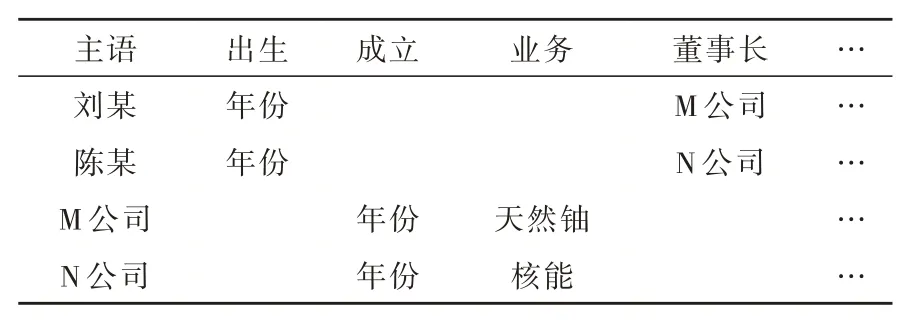
表2 橫向存儲案例Table 2 Horizontal storage case
橫向存儲方法,其眾源數據的核心查詢語法規則是:
SELECT主語
FROM a
WHERE出生=‘年份’AND籍貫=‘出生地’董事長LIKE‘_%’
橫向存儲方法的語法,本文用符號a代替為查詢表,而且,單表查詢即可完成該任務,不用進行連接操作。在基于眾源數據的地理信息數據集中,該數據的存儲方法對于行優先存儲來說,會出現大量的存儲空間閑置的情況。如果將該方法應用到實際場景中,這種方法會增加數據庫管理的復雜度和運營數據的成本。
2.3 屬性存儲
屬性存儲方法是把橫向存儲方法進行更加詳細的劃分描述,即把一個橫向存儲方法分為人、專業化公司和母子公司三個分欄。對于圖5中SPARQL查詢,在屬性存儲方法上等價的SQL查詢如下所示:
SELECT主語
FROM人
WHERE出生=‘年份’AND籍貫=‘出生地’董事長LIKE‘_%’
該查詢與橫向存儲方法上查詢的唯一區別是將欄名由a變成了員工。
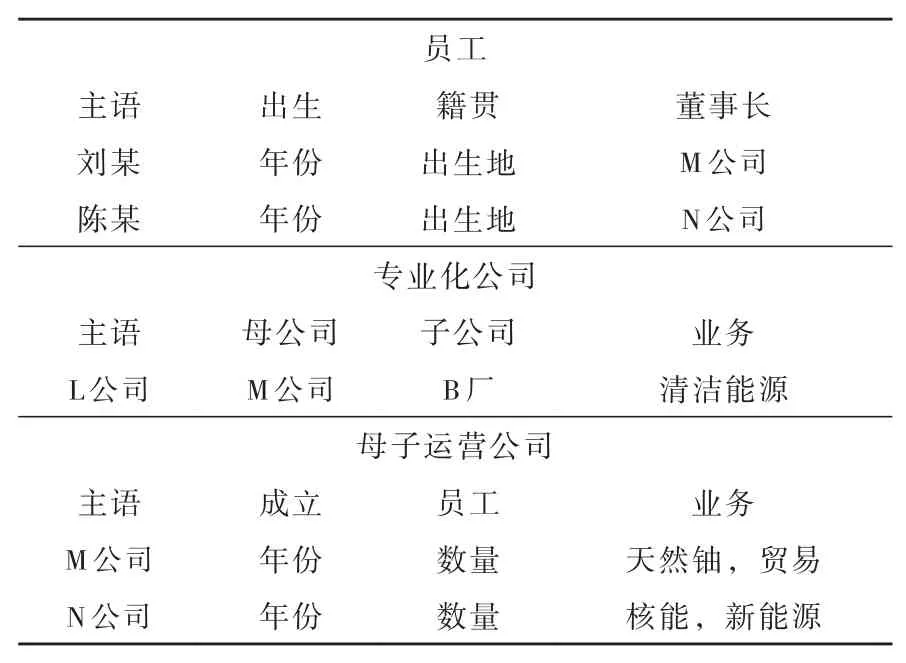
表3 屬性存儲方法Table 3 Store of attribute
屬性存儲方法是在對知識管理方法和橫向存儲法上的優化升級,反過來看,知識管理方法和橫向存儲法又是屬性存儲法的特例。按照屬性存儲方法,雖然它彌補了上面兩個方法的缺點,但是,其本身也出現了數據冗余的缺點。而且,屬性存儲方法仍然會進行多個表之間的連接操作,從而影響查詢效率。
2.4 縱向劃分
縱向劃分起源于美國高等學府,該方法以三元組的謂語作為劃分維度,將RDF知識圖譜劃分為若干張只包含(主語,賓語)兩列的表,該表的突出特征是以眾源數據的屬性信息為分表。也就是說,圖6中分表分別是出生、董事長、業務、子公司等眾源屬性信息。
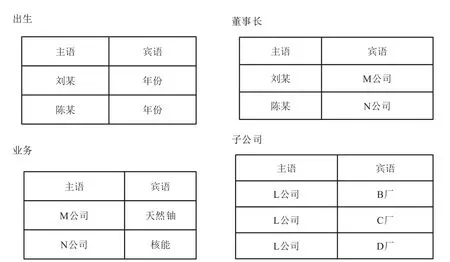
圖6 縱向劃分存儲方案Fig.6 Vertical partition storage solution
對于圖6中的SPARQL查詢,在縱向劃分存儲方案中等價的SQL查詢如下:
SELECT出生.主語
FROM出生,業務,董事長
WHERE出生.賓語=‘年份’AND業務.賓語=‘天然鈾’AND出生.主語=業務.主語AND出生.主語=董事長.主語
該查詢涉及3項謂語屬性,出生、業務和董事長的連接操作。由于謂語表中的行都是按照主語列進行排序的,可以快速執行這種以“主語-主語”作為連接條件的查詢操作,而這種連接操作又是常用的。
2.5 多重查詢
多重查詢法是對RDF存儲的一種延伸,該方法利用主、謂、賓語之間的概率分布關系進行自由組合,其典型的三元組排列組合方式如表4所示。因為該方法將所有RDF進行排列組合,這極大地提升了數據庫查詢檢索的效率,但也增加了存儲空間的消耗。
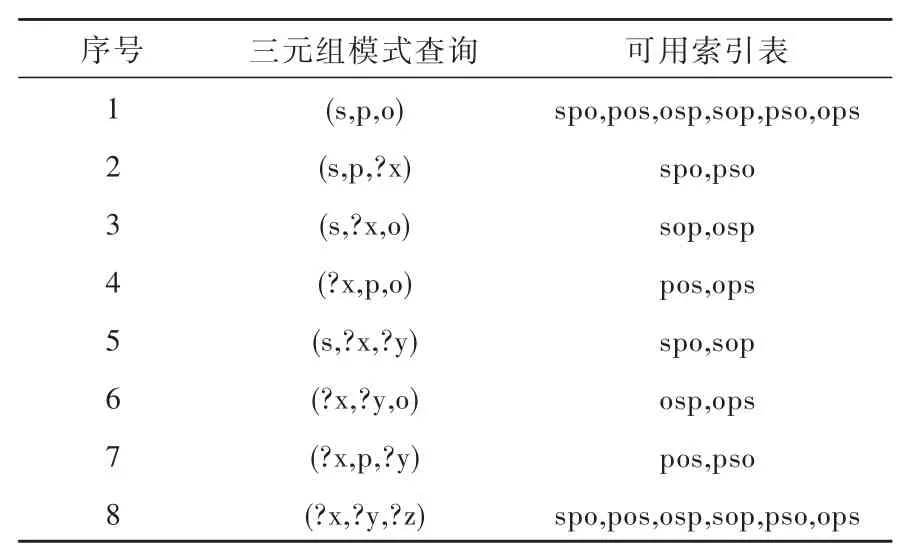
表4 三元組模式查詢能夠使用的索引Table 4 Usable indexes for triple query
圖7所示的鏈式SPARQL查詢“查找生于某年份目前是公司的董事長的人”,可以通過spo和pso表的連接快速執行三元組模式“?person董事長?company”與“?company行業?ind”的連接操作,避免了單表的自連接。
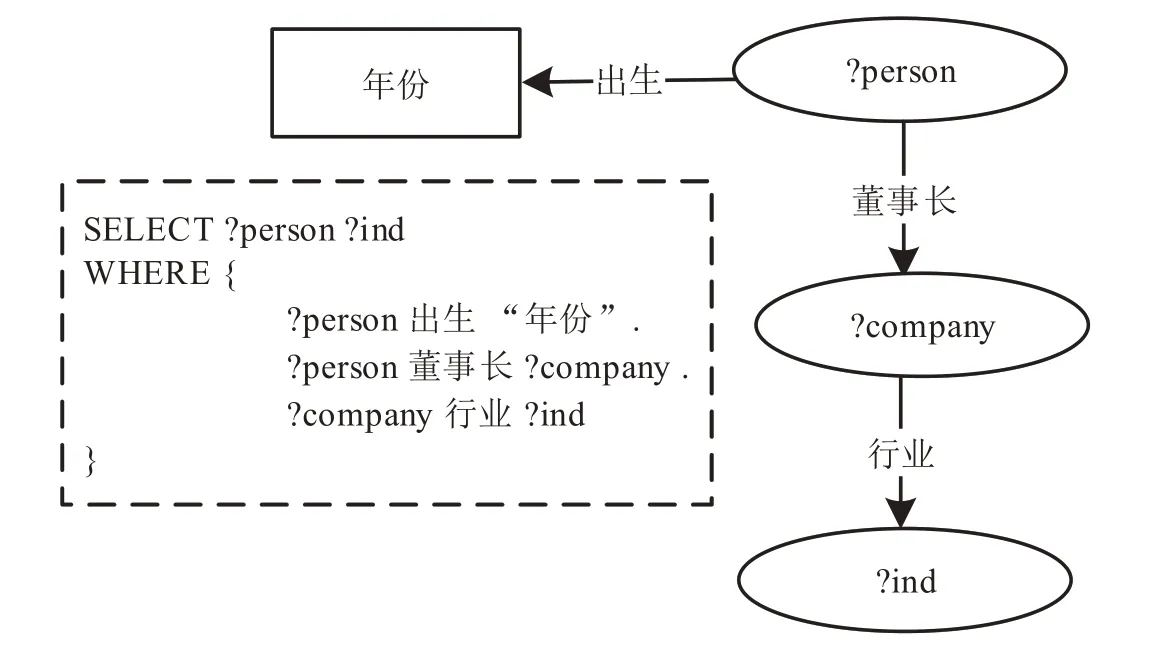
圖7 一個鏈式SPARQL查詢Fig.7 A chained SPARQL query
2.6 混合管理
例如,在表5中的dph欄中,主語劉某的謂語行業(pred1列)是多值謂語,則在其賓語列(val1)存儲id值lid:1。例如,主語劉某和陳某的謂語董事長都被分配到pred3列,該列也存儲了主語M公司的謂語專業化公司和直屬單位。
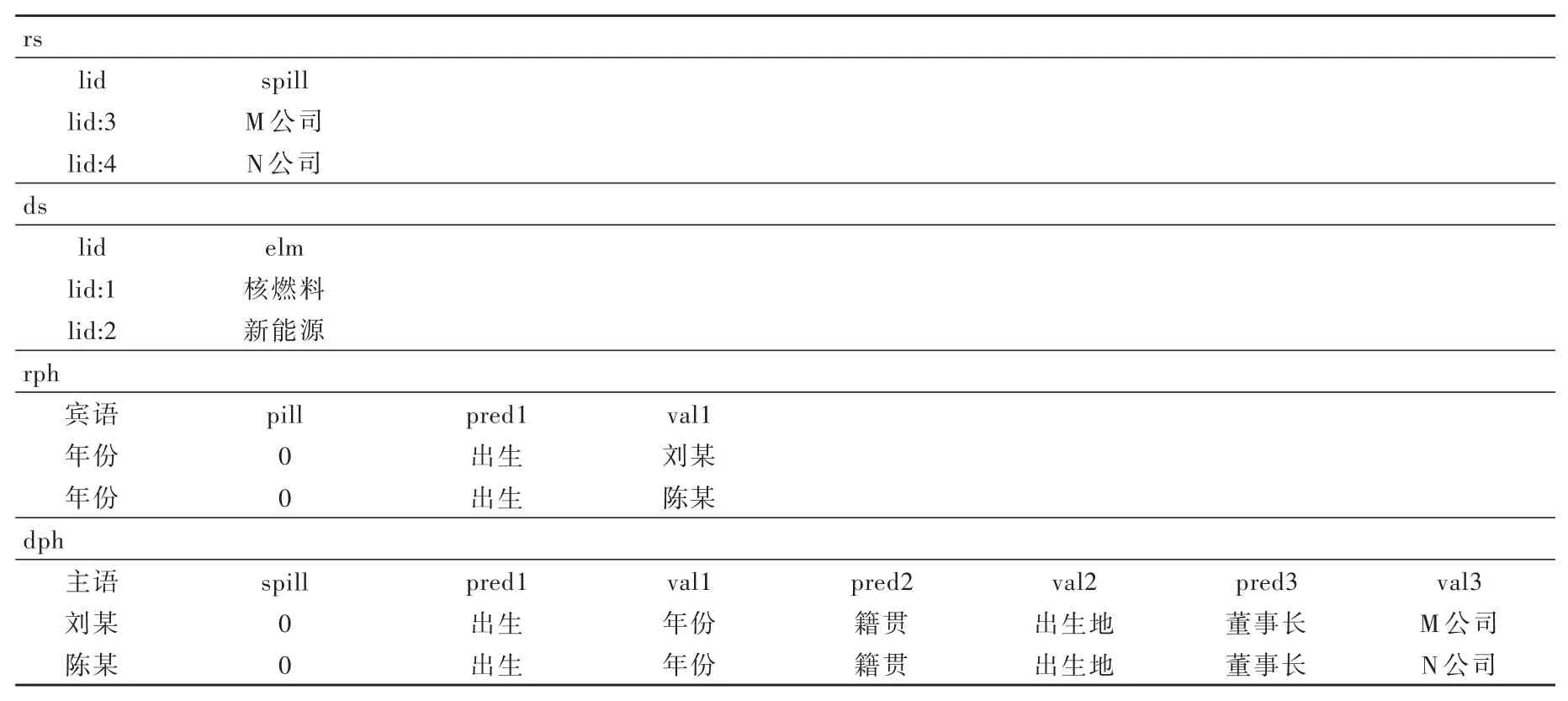
表5 混合管理方案Table 5 Hybrid management solution
SELECT a.主語
FROM dph AS a
WHERE a.pred1=‘籍貫’AND a.val1=‘出生地’AND a.pred2=‘出生’AND a.val2=‘年份’AND a.pred3=‘董事長’
從中可以看出,對于知識圖譜的星型查詢,混合管理存儲方案只需查詢dph欄即可完成,無須進行連接操作。
現在開始存儲以L公司作為主語的三元組,見表6所示。將(L公司,母公司,M公司)進行數據添加時,根據h1的值將謂語母公司存入列pred1。將(L公司,子公司,C廠)進行數據添加時,根據h1的值將謂語子公司存儲到pred2。在對(L公司,業務,清潔能源)進行數據添加時,將謂語業務被h1映射到列pred1,但該列已被占用,因而接著被h2映射到列pred3。將(L公司,子公司,B廠)插入到知識庫時,謂語子公司被h1映射到列predk。在把(M公司,直屬單位,X設計院)添加到知識庫中時,此時數據庫原有位置被占用,會自動添加到額外空間內容。
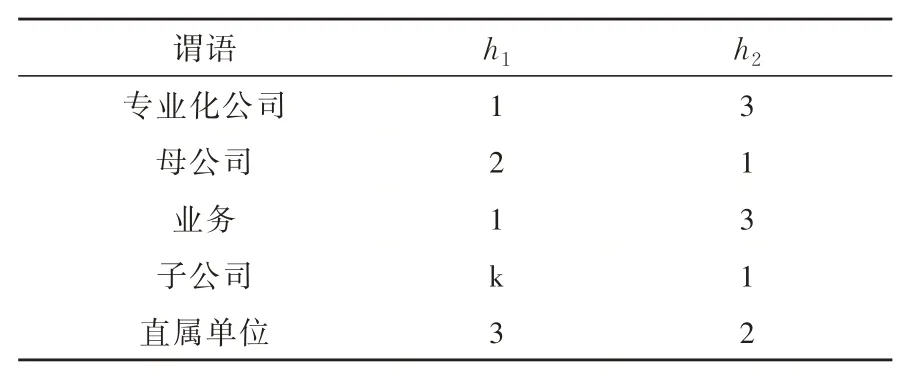
表6 謂語到列映射的散列函數Table 6 Hash function of predicate-to-column mapping
為此,構建圖著色算法的沖突圖。圖中節點為知識圖譜中的所有謂語。每對共現謂語節點之間由一條邊相連。圖著色問題的要求是為沖突圖中的節點著上顏色使得每個節點的顏色不同于其在鄰接節點的顏色,并使所有顏色數最少。對應到謂語映射問題,即為沖突圖中的謂語節點分配列,使得每個謂語映射到的列不同于其任一共現謂語映射到的列,并使用所用的列數目最少。圖8給出了圖4中知識圖譜的沖突圖。可見,對于13個謂語,僅使用了5種顏色,即只需使用5列。需要指出的是,圖著色是經典的NP難題,對于規模較大的沖突圖可用貪心算法求得近似解。
圖8 沖突圖Fig.8 Interference graph
3 眾源知識存儲關鍵技術
為了適應大規模知識圖譜數據的存儲管理與查詢處理,知識圖譜數據庫內部針對圖數據模型設計了專門的存儲方案和查詢后處理機制,以圖數據庫Neo4j為例創建其存儲核電站知識場景方案。
這一部分將深入Neo4j圖數據庫底層,探究其原生的圖存儲方案。作為對比,將原有的眾源數據知識庫與關系數據庫進行存儲原理進行分析。圖9左邊給出了一個全局索引的示例,典型方法是利用B+樹進行全局檢索,如查找“張某”的同事,需要O( logn)帶代價,其中,n為節點總數。如果覺得這樣的查找代價還是可以接受的話,那么換一個問題,誰認識“趙某”的查找代價是多少?顯然,對于這個查詢,需要通過全局索引檢查每個節點,看其認識的人或共事的人中是否有趙某,總代價為O(nlogn),這樣的復雜度對于圖數據的遍歷操作是不可接受的。也有學者認為,可為“被認識”關系再建一個同樣的全局索引,但那樣索引的維護開銷就會翻倍,而且仍然不能做到圖遍歷操作代價與圖規模無關。
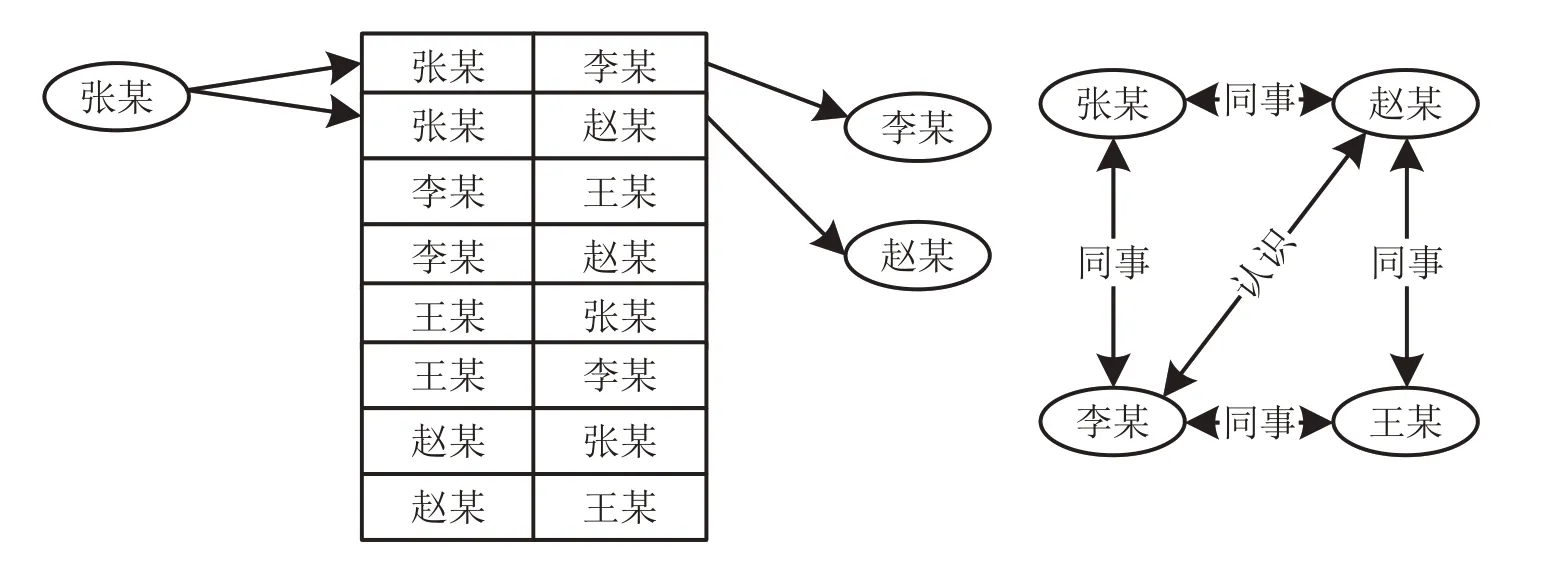
圖9 鄰接關系的全局索引示例Fig.9 Example of global index for adjacency
在圖數據庫中,把屬性信息認為是區別于關系數據庫的關鍵點,即數據庫中最基本、最核心的概念,如關系數據庫中的“關系”,才能實現真正的“無索引鄰接”特性。在圖6右邊查找“張某”的同事時,可以通過張某的“同事”出邊進行索引。搜索認識“趙某”的員工,可以通過趙某入邊進行索引。當然,目前這種方法的時間復雜度為O(1)。
Neo4j與其它眾源數據知識庫不同,它是將屬性數據集和節點數據集分開管理。該方法的提出,使得Neo4j的運行和管理效率都在同行業數據庫中處于領先地位。首先,在Neo4j中是如何存儲圖節點和邊。圖10所示,在Neo4j中,存儲單個節點和屬性分別占用9和33個物理存儲單位。其中,節點集數據存儲在neostore.nodestore.db里,在每一個節點集中分別存儲著不同的記錄信息。包括,相連節點、本節點的身份信息、本節點的屬性信息以及該節點屬性信息的身份信息等內容。在眾源數據屬性信息集中,屬性集存儲在neostore.relationshipstore.db里,在單個屬性數據中,會依次存儲該屬性物理位置是否使用、該屬性的頭節點和尾節點位置信息、還會包含屬性連接節點相應的身份信息,最后還有頭節點指向下一個節點的地址以及尾節點指向下一個節點的地址信息。
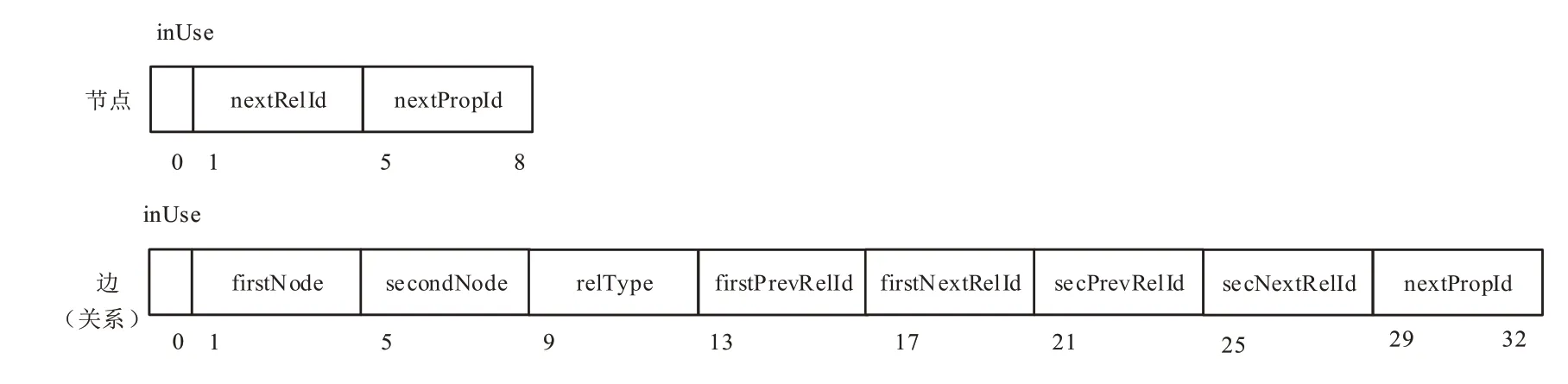
圖10 Neo4j中節點和邊記錄的物理存儲結構Fig.10 Physical storage structure of the node and edge records in Neo4j
圖11所示是以核電站員工為例,用Neo4j的各種節點集和屬性集進行舉例,來說明各種眾源數據的知識信息是如何相互之間進行信息溝通。以張某和趙某節點為例,二者在存儲關系上分別屬于數據存儲的初始位置。通過二者都關聯的同事信息,可以通過虛線鏈接來確定張某與趙某節點。對于圖中的核心節點與項目節點都使用雙向聯系,而對于單一位置員工的屬性信息,則使用單一方向聯系。該方法不僅方便查詢各個員工的關聯關系,同時對于眾源知識圖譜添加與管理也非常便捷。
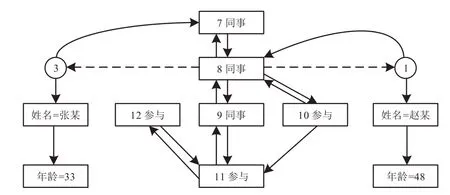
圖11 Neo4j中圖的物理存儲Fig.11 Physical storage diagram in Neo4j
例如,由節點3導航到節點1的過程為:
(1)由節點3知道其第1條邊為7;
(2)在邊文件中通過定長記錄計算出邊7的存儲地址;
(3)由邊7通過雙向鏈表找到邊8;
(4)由邊8獲得其中的終止節點id(secondNode),即節點1;
(5)在節點文件中通過定長記錄計算出節點1的存儲地址。
4 結果與分析
當前有多種知識圖譜開源及商業數據庫,本文以Neo4j為例,設計具體的核電站知識存儲過程,Neo4j的1.0版本發布于2010年。Neo4j是典型的以知識形式進行數據存儲與管理的數據庫,它不僅規定了專屬使用語言,而且還提供了數據庫專業的核心案例以幫助初學者更好地入門。同時,Neo4j還具備OLTP數據庫必須的ACID事務處理功能。
Neo4j的不足之處在于其社區版是單機系統,雖然Neo4j企業版支持高可用性(High Availability)集群,但其與分布式圖存儲系統的最大區別在于每個節點上存儲圖數據庫的完整副本(類似于關系數據庫鏡像的副本集群),不是將圖數據劃分為子圖進行分布式存儲,并非真正意義上的分布式數據庫系統。如果圖數據超過一定規模,系統性能就會因為磁盤、內存等限制而大幅降低。
開發者注冊信息后可以免費下載Neo4j桌面打包安裝版,其中包括Neo4j企業版的全部功能,即Neo4j服務器、客服端及全部組件。安裝之后打開軟件為Neo4j Desktop數據庫管理界面,然后選擇瀏覽器,打開Neo4j瀏覽器。Neo4j瀏覽器是功能完成的Neo4j可視化交互式客戶端工具,可以用于執行Cypher語言。使用Neo4j內置的電影圖數據庫執行Cypher查詢,返回“湯姆·漢克斯”所出演的全部電影,如圖12所示。此外,成功啟動Neo4j服務器之后,會在7474和7473端口分別開啟HTTP和HTTPS。例 如,使 用 瀏 覽 器 訪 問http://localhost:7474/進 入Web界 面,執 行Cypher查詢,其功能與Neo4j瀏覽器一致。
本文以具體知識存儲過程為例。如圖12所示,對核電站的工作人員信息進行代碼案例測試,六名人員與四個地理位置信息的知識結果見圖12(a),通過分析可以發現,張某與孫某都是來自同一個城市,并且二人是夫妻關系;在兩類節點之間,王某是最受同事喜愛的人。從圖12(b)中可以看出,每個員工節點有不少于一類屬性關系,這表明各類知識節點的屬性關系,不僅僅只是同事和家屬關系,而且對比(a)與(b)可以看出,實體類的關系存儲和表示,并非是單一的行或列存儲。對眾源數據的地理知識的存儲,表現的具體實例上可以看出是節點與屬性知識的融合。

圖12 Neo4j數據庫實例Fig.12 Neo4j database instance
5 結論
針對眾源數據這一典型數據的存儲問題,利用當前流行的知識圖譜技術對眾源數據進行存儲,不僅利用關系數據庫的方法,還利用了圖數據庫的方法進行存儲。通過對各種方法的對比分析,發現傳統的關系數據庫在存儲眾源地理信息時,會造成存儲位置上的數據稀疏,并且弱化了眾源數據中地理知識的相關關系。與之對比,圖數據的優點明顯,不僅可以解決關系型數據庫在存儲眾源地理知識時數據存儲稀疏,造成大量空間浪費的問題,而且還可以刻畫了眾源數據的關系特征。最后通過具體案例分析進一步表明,利用知識圖譜數據庫存儲眾源地理信息可以達到復雜度為O(1)的需求。在后續研究中,應進一步優化對眾源數據的高效率知識抽取和挖掘,以及對抽取知識的智能化推理等問題。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
意林原創版(2016年10期)2016-11-25 10:28:30
財經(2016年15期)2016-06-03 07:38:02
Coco薇(2016年2期)2016-03-22 02:42:52
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
