一種可拓語(yǔ)義分析的農(nóng)產(chǎn)品生產(chǎn)銷(xiāo)售知識(shí)檢索方法
2021-07-23 12:51:54楊春蕾
新一代信息技術(shù) 2021年6期
楊春蕾
(河北地質(zhì)大學(xué),河北 石家莊 050022)
0 引言
知識(shí)檢索是一種基于語(yǔ)義和知識(shí)關(guān)聯(lián)的高級(jí)信息檢索方式。相較于信息檢索,知識(shí)檢索實(shí)現(xiàn)了信息查詢語(yǔ)義化、智能化,提高了檢索的效率和準(zhǔn)確率。知識(shí)檢索過(guò)程中最重要的一步便是語(yǔ)義相似度計(jì)算,它用來(lái)表示概念之間的相關(guān)性,語(yǔ)義相似度越高,則越符合檢索要求。因此,提出一種計(jì)算結(jié)果準(zhǔn)確且高效的計(jì)算方法尤為重要。
近年來(lái),一些學(xué)者研究了多種語(yǔ)義相似度計(jì)算方法并將其運(yùn)用到了多個(gè)領(lǐng)域。文獻(xiàn)[1]提出了一種基于農(nóng)業(yè)本體的語(yǔ)義相似度計(jì)算方法,但是該算法受到地理實(shí)體、文獻(xiàn)資料、經(jīng)驗(yàn)等各個(gè)因素的影響,效率較低。文獻(xiàn)[2]提出了一種計(jì)算義原相似度的算法,提高了檢索結(jié)果的準(zhǔn)確性,但第一獨(dú)立義原對(duì)結(jié)果影響很大。文獻(xiàn)[3]提出了加權(quán)語(yǔ)義復(fù)雜網(wǎng)絡(luò)文本相似度計(jì)算方法,利用了文本網(wǎng)絡(luò)中特征詞節(jié)點(diǎn)間的信息,對(duì)于復(fù)雜的文本網(wǎng)絡(luò)仍有一定的局限性。文獻(xiàn)[4-5]提出了基于WordNet的語(yǔ)義相似度計(jì)算方法,具有更高的皮爾森相關(guān)系數(shù),但只適用于詞匯語(yǔ)義相似度計(jì)算。文獻(xiàn)[6]提出一種自適應(yīng)相似度綜合加權(quán)計(jì)算方法,解決了傳統(tǒng)綜合加權(quán)計(jì)算時(shí)人工賦權(quán)的不足。文獻(xiàn)[7]利用結(jié)構(gòu)化的維基百科節(jié)點(diǎn)中的最短路徑關(guān)系,對(duì)2個(gè)詞條之間的關(guān)系進(jìn)行刻畫(huà),過(guò)程略顯復(fù)雜。
本文運(yùn)用可拓學(xué)基礎(chǔ),提出的語(yǔ)義相似度算法,充分考慮信息量、距離、屬性等信息對(duì)語(yǔ)義相似度的影響,具有更高的準(zhǔn)確性。將本文算法應(yīng)用于農(nóng)產(chǎn)品生產(chǎn)銷(xiāo)售知識(shí)檢索,為農(nóng)產(chǎn)品的供需雙方提供便利。
1 農(nóng)業(yè)知識(shí)表示和可拓描述
1983年,我國(guó)學(xué)者蔡文、楊春燕等人提出了一個(gè)新的學(xué)科—可拓學(xué)(extenics)。可拓論、可拓創(chuàng)新方法和可拓工程構(gòu)成了可拓學(xué)[8]。可拓學(xué)的主要思想是利用創(chuàng)新的方法和理論解決各個(gè)領(lǐng)域中的矛盾問(wèn)題。通過(guò)形式化描述矛盾問(wèn)題將其轉(zhuǎn)換為不矛盾問(wèn)題,研究解決該問(wèn)題的方法形成理論體系,形式化描述解決過(guò)程,轉(zhuǎn)換成計(jì)算機(jī)可讀的語(yǔ)言,智能化解決問(wèn)題。不管面對(duì)什么樣的問(wèn)題,都需要遵循可拓邏輯,充分考慮事物本身的概念和特征,定量的表示邏輯值,形成可拓模型,通過(guò)可拓變換,推導(dǎo)矛盾問(wèn)題,使計(jì)算機(jī)能夠處理該問(wèn)題。
實(shí)現(xiàn)農(nóng)產(chǎn)品的生產(chǎn)銷(xiāo)售平臺(tái)首先需要解決的是農(nóng)業(yè)知識(shí)表示這個(gè)關(guān)鍵問(wèn)題[9]。通過(guò)使用統(tǒng)一的規(guī)則將知識(shí)進(jìn)行描述,形成計(jì)算機(jī)可以識(shí)別的語(yǔ)言,方便進(jìn)行語(yǔ)義相似度的計(jì)算[10]。本文的研究通過(guò)可拓學(xué)中的創(chuàng)新方法來(lái)對(duì)農(nóng)業(yè)知識(shí)進(jìn)行相似度的計(jì)算,從而完成知識(shí)檢索。
本文所設(shè)計(jì)的流程圖如圖1所示。
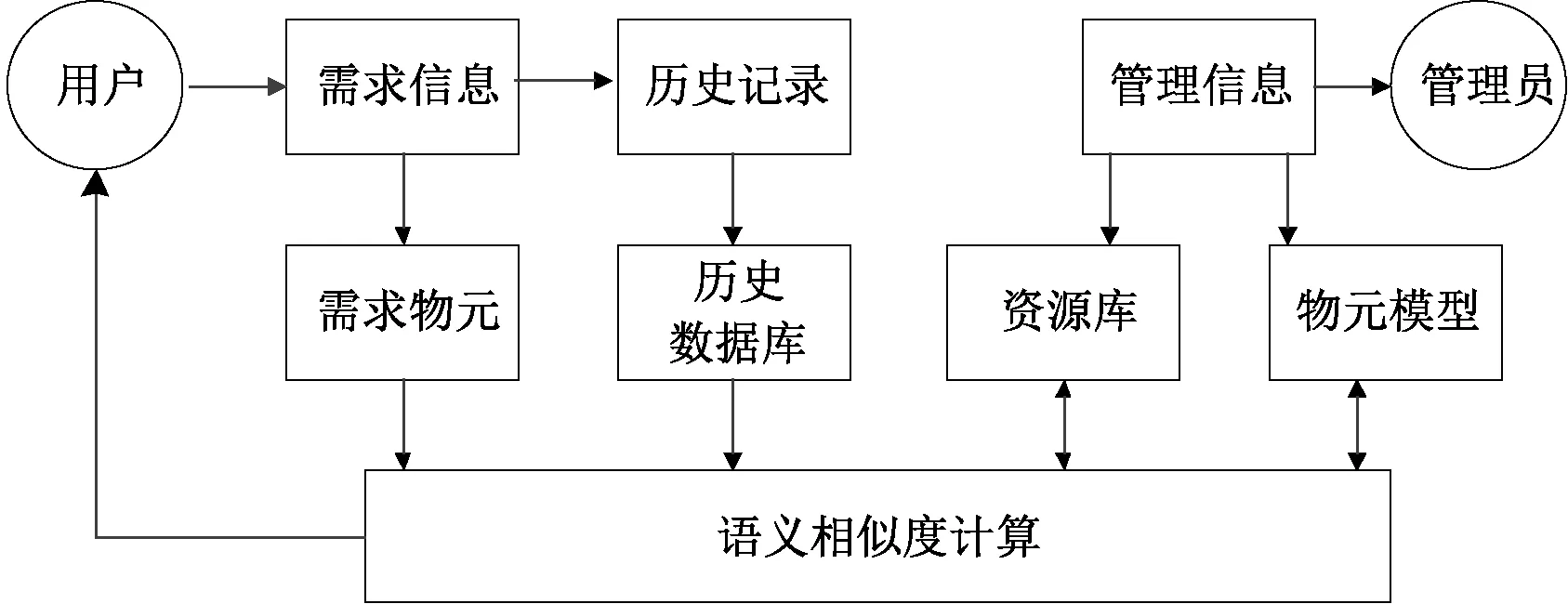
圖1 農(nóng)產(chǎn)品產(chǎn)銷(xiāo)平臺(tái)的知識(shí)檢索流程圖Fig.1 Knowledge retrieval flowchart of agricultural product production and marketing platform
2 基于可拓學(xué)的知識(shí)表示
本文引入可拓論,對(duì)農(nóng)業(yè)知識(shí)進(jìn)行表示,為語(yǔ)義相似度計(jì)算提供結(jié)構(gòu)化的描述。可拓學(xué)中事元、物元和關(guān)系元組成基元,是形式化描述事物及其相互關(guān)系的基本邏輯單元。我們以有序三元組R=(c,m,v)表示基元,其中c為對(duì)象,m為特征,v為量值,通過(guò)基元建立解決問(wèn)題的可拓模型。
定義系統(tǒng)中有概念c,此概念具有n個(gè)特征分別為m1,m2,…,mn,各自對(duì)應(yīng)的量值為v1,v2…,vn。所構(gòu)成的陣列即為物元R,物元模型為:

本文將農(nóng)業(yè)知識(shí)用物元模型表示,知識(shí)由信息構(gòu)成,信息的基元表示稱(chēng)為信息元。可拓學(xué)以可拓模型為基礎(chǔ),研究可拓信息-知識(shí)-策略的形式化體系[9]。在本系統(tǒng)中,c為相關(guān)概念,有多個(gè)取值,對(duì)于在農(nóng)產(chǎn)品生產(chǎn)銷(xiāo)售中所需要的特征稱(chēng)為m,每個(gè)特征對(duì)應(yīng)的值或描述稱(chēng)為v。
例如,對(duì)于農(nóng)產(chǎn)品玉米,其物元表示為:

該物元表示的對(duì)象是玉米,選取了價(jià)格、產(chǎn)地、品種和別名等四個(gè)特征,其中特征價(jià)格的量值是2.3/kg,產(chǎn)地是石家莊,品種是鄭丹958,別名有包谷、棒子、苞米等。該物元模型形象且準(zhǔn)確的表示了玉米這個(gè)農(nóng)業(yè)知識(shí)的相關(guān)信息,在農(nóng)產(chǎn)品銷(xiāo)售系統(tǒng)中,可以根據(jù)供需雙方的物元計(jì)算語(yǔ)義相似度。
3 語(yǔ)義相似度算法
本文語(yǔ)義相似度計(jì)算方法從信息、語(yǔ)義距離和屬性等方面來(lái)計(jì)算。在對(duì)農(nóng)業(yè)知識(shí)進(jìn)行可拓描述時(shí),了解到各個(gè)概念的信息及相關(guān)屬性值,形成物元模型,將其以樹(shù)形結(jié)構(gòu)存儲(chǔ)。這樣將各個(gè)概念進(jìn)行了分類(lèi),得到了知識(shí)的層次結(jié)構(gòu)。我們可以直觀形象地觀察出各個(gè)節(jié)點(diǎn)信息和節(jié)點(diǎn)之間的路徑長(zhǎng)度。
3.1 基于信息的語(yǔ)義相似度
基于信息的語(yǔ)義相似度計(jì)算是通過(guò)概念之間共有信息量來(lái)判斷的[12],兩個(gè)概念共有的信息的信息量需要追溯到二者的父節(jié)點(diǎn)[13],對(duì)共有信息在父節(jié)點(diǎn)中出現(xiàn)的次數(shù)進(jìn)行量化。共有信息越多時(shí),相似度越高[14]。概念C的信息量定義為:

其中,P(C)表示概念C出現(xiàn)的概率;n(C)表示概念C在物元中出現(xiàn)的次數(shù);N(O)是物元中概念的總數(shù);表示概念C的子概念集合。
計(jì)算概念C1,C2的相似度,計(jì)算方法可表示為:

通過(guò)該方式對(duì)兩個(gè)概念的相似度粗略計(jì)算后,需對(duì)其語(yǔ)義距離進(jìn)行計(jì)算以提高準(zhǔn)確率。
3.2 基于語(yǔ)義距離的語(yǔ)義相似度
將農(nóng)業(yè)知識(shí)的物元以樹(shù)形結(jié)構(gòu)進(jìn)行存儲(chǔ),計(jì)算兩個(gè)概念的語(yǔ)義距離,需從樹(shù)狀圖中分析兩個(gè)節(jié)點(diǎn)之間的距離。由于兩個(gè)節(jié)點(diǎn)之間的路徑不同,距離也就不同,本文以二者之間的最短路徑為準(zhǔn)[15]。同時(shí),將語(yǔ)義距離的單位距離統(tǒng)一為1。兩個(gè)概念節(jié)點(diǎn)C1,C2的語(yǔ)義距離表示為:
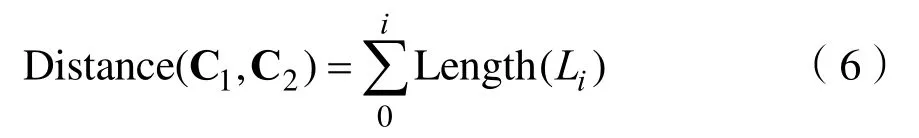
Distance(C1,C2)表示概念 C1,C2節(jié)點(diǎn)之間的語(yǔ)義距離,Length(Li)表示在連接 C1,C2兩個(gè)概念的最短路徑中,第i條邊Li的長(zhǎng)度。這樣一來(lái),概念之間的語(yǔ)義距離為:

上述將語(yǔ)義距離的單位距離定為 1,概念之間的語(yǔ)義距離可以定義為:
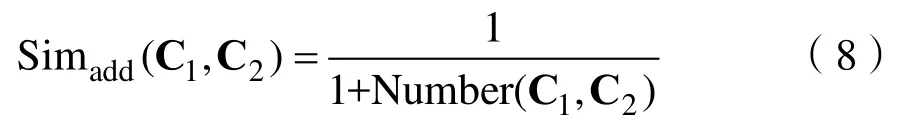
節(jié)點(diǎn)深度即概念節(jié)點(diǎn)在形成的結(jié)構(gòu)樹(shù)中的深度,若語(yǔ)義距離一定時(shí),兩個(gè)節(jié)點(diǎn)的深度越大,概念劃分的準(zhǔn)則越細(xì)致,則概念之間的相似度越大[16]。另Depth(C)表示概念C的節(jié)點(diǎn)深度,對(duì)于概念C1,C2,深度影響因子可以定義為:
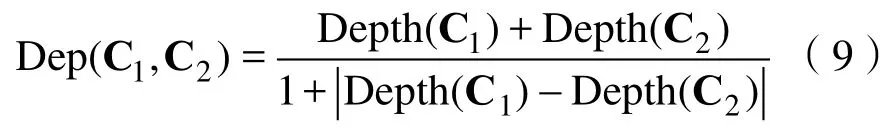
且 Dep(C1,C2)>1。
節(jié)點(diǎn)密度是針對(duì)于兩個(gè)概念節(jié)點(diǎn)的最近公共父節(jié)點(diǎn)而言,當(dāng)此節(jié)點(diǎn)所產(chǎn)生的直接子節(jié)點(diǎn)越多,它的節(jié)點(diǎn)密度越大,子節(jié)點(diǎn)之間的關(guān)聯(lián)程度越大,語(yǔ)義相似度也就越大[17]。同樣定義Density(C)為節(jié)點(diǎn)C的子節(jié)點(diǎn)數(shù)量,是節(jié)點(diǎn)C1,C2的最近公共父節(jié)點(diǎn),節(jié)點(diǎn)密度影響因子定義為:

其中,Degree(O)為在由物元形成的整顆樹(shù)中,最大的度。
綜上所述,這些條件對(duì)語(yǔ)義相似度的結(jié)果都有影響,為保證計(jì)算的準(zhǔn)確度,本文引入加權(quán)概念,根據(jù)對(duì)結(jié)果影響程度,對(duì)各個(gè)影響因素分配不同的權(quán)值。經(jīng)過(guò)分析,得到的加權(quán)之后的語(yǔ)義相似度計(jì)算公式為:

其中,α+β+γ=1
3.3 基于屬性的語(yǔ)義相似度
每個(gè)屬性都是對(duì)概念的一種描述,如果兩個(gè)概念之間屬性值相同或是相似,也能夠在一定程度上反應(yīng)兩個(gè)概念之間的相似程度。通過(guò)參考文獻(xiàn)[6]得出:

在式(12)(13)中,Pro(C1∩C2)表示概念C1,C2屬性的交集,即二者的公共屬性;Pro(C1–C2)表示概念的差集,即概念C1有而C2沒(méi)有的屬性,同理Pro(C1–C2)表示概念C2有而C1沒(méi)有的屬性;D(C1)和D(C2)表示在形成的物元結(jié)構(gòu)的樹(shù)中,概念所在的深度。
3.4 加權(quán)語(yǔ)義相似度
經(jīng)過(guò)對(duì)語(yǔ)義相似度影響因素的研究,我們得到信息、語(yǔ)義距離、屬性等三個(gè)影響因子,但若計(jì)算綜合語(yǔ)義相似度需要結(jié)合3.1-3.3中介紹的三種情況[18-20]。通過(guò)請(qǐng)教專(zhuān)業(yè)領(lǐng)域的專(zhuān)家得知,三種影響因子對(duì)計(jì)算結(jié)果的影響程度不盡相同,因此,得到最后的加權(quán)語(yǔ)義相似度計(jì)算公式:

4 案例研究
隨著互聯(lián)網(wǎng)的發(fā)展,工作生活中的各項(xiàng)服務(wù)越發(fā)智能化,各應(yīng)用系統(tǒng)迫切需要高準(zhǔn)確性的語(yǔ)義相似度算法,農(nóng)產(chǎn)品相關(guān)系統(tǒng)也不例外。
本文抽取部分實(shí)驗(yàn)數(shù)據(jù)進(jìn)行語(yǔ)義相似度計(jì)算,這些實(shí)驗(yàn)數(shù)據(jù)形成的結(jié)構(gòu)樹(shù)如圖2所示。
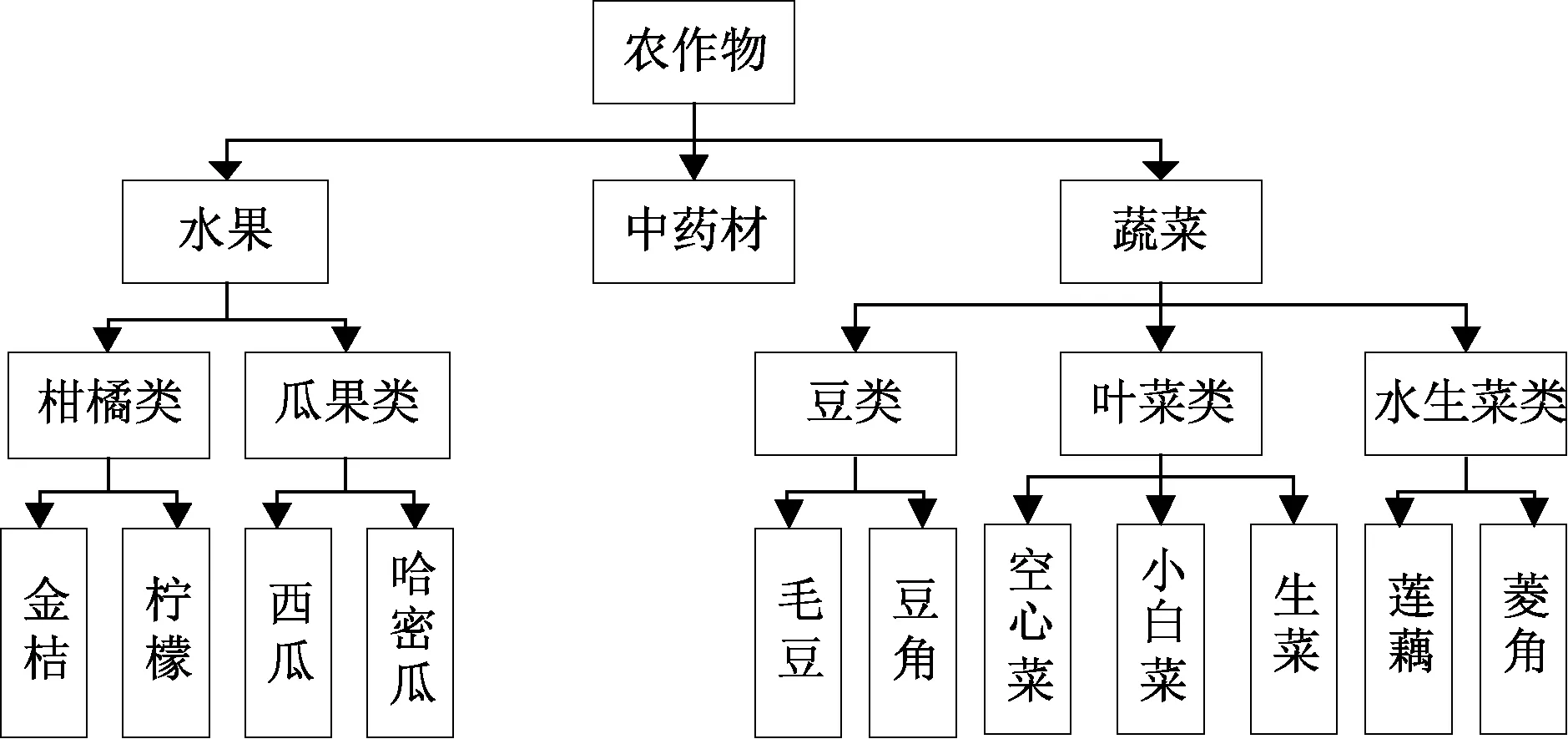
圖2 結(jié)構(gòu)樹(shù)Fig.2 S tructure tree
4.1 實(shí)例計(jì)算
經(jīng)過(guò)查閱相關(guān)資料與市場(chǎng)調(diào)查,選定對(duì)生產(chǎn)銷(xiāo)售影響較大的屬性,現(xiàn)選取物元中部分屬性進(jìn)行舉例,價(jià)格定為市場(chǎng)調(diào)查當(dāng)日的數(shù)值。本文選取的幾種概念的部分屬性如表1所示。

表1 農(nóng)作物物元的部分屬性Tab.1 Some attributes of crop matter elements
下面以計(jì)算“生菜”“小白菜”為例,計(jì)算二者的語(yǔ)義相似度,過(guò)程如下。
根據(jù)圖 2物元樹(shù)狀圖,計(jì)算“生菜”和“小白菜的”語(yǔ)義相似度。為了確定各個(gè)權(quán)值和參數(shù),進(jìn)行了大量的數(shù)據(jù)研究和實(shí)際考察,采用專(zhuān)家經(jīng)驗(yàn)和試錯(cuò)法,得到結(jié)果 α=0.5,β=0.2,γ=0.3,ω1=0.2,ω2=0.1,ω3=0.7。
在圖2中,“生菜”和“小白菜”的父節(jié)點(diǎn)是“葉菜類(lèi)”,根據(jù)式(3)可以計(jì)算得到“葉菜類(lèi)”的概率為1/5,這樣根據(jù)式(4)計(jì)算出“葉菜類(lèi)”的信息量為 0.699,最后由式(5)得到“生菜”和“小白菜”的信息相似度為0.699。
在圖2中,“生菜”和“小白菜”的高度均為4,結(jié)合式(9)算得到,節(jié)點(diǎn)深度是 8。在圖 2所示的樹(shù)中,最大度為3,“生菜”和“小白菜”父節(jié)點(diǎn)的度也是3,利用式(10)節(jié)點(diǎn)密度是1。最終利用公式11二者語(yǔ)義距離為2.067。
根據(jù)上文計(jì)算“生菜”和“小白菜”的深度,可得到 λ=μ=1/2,參照表1中的屬性,“生菜”和“小白菜”的共有屬性為5,利用式(12)(13)性相似度為0.625。
最終,利用式(14)算出“生菜”和“小白菜”的語(yǔ)義相似度為0.785。
4.2 分析
根據(jù)項(xiàng)目需求分析和實(shí)際情況,得到對(duì)概念影響較大的屬性并確定相應(yīng)描述和數(shù)值,建立物元模型,對(duì)所有農(nóng)業(yè)信息進(jìn)行物元表示,然后根據(jù)調(diào)研結(jié)果將這些農(nóng)作物的物元采用樹(shù)的結(jié)構(gòu)存儲(chǔ),建立農(nóng)作物物元的樹(shù)形結(jié)構(gòu),最后計(jì)算語(yǔ)義相似度。本文現(xiàn)只選取圖2中的部分概念進(jìn)行語(yǔ)義相似度計(jì)算。
為了更好地驗(yàn)證本文算法的準(zhǔn)確性,采用文獻(xiàn)[1]中的算法和目前常用的計(jì)算方法與本文算法進(jìn)行對(duì)比,表 2為三種算法語(yǔ)義相似度計(jì)算結(jié)果。
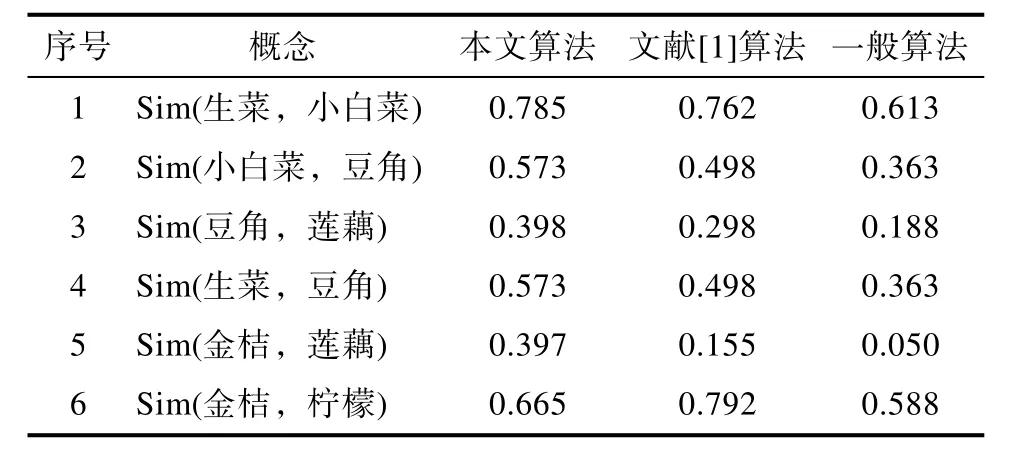
表2 三種算法語(yǔ)義相似度計(jì)算結(jié)果Tab.2 Se mantic similarity calculation results of three algorithms
圖3是三種算法的語(yǔ)義相似度計(jì)算結(jié)果的對(duì)比圖,其中橫坐標(biāo)代表用于計(jì)算語(yǔ)義相似度的概念對(duì),縱坐標(biāo)代表數(shù)值,藍(lán)色、橘色和灰色折線分別代表本文算法、文獻(xiàn)[1]算法和一般算法的計(jì)算結(jié)果。

圖3 三種算法計(jì)算結(jié)果對(duì)比圖Fig.3 Comparison of calculation results of three algorithms
根據(jù)圖 3我們可以看出上述三種算法的走勢(shì)基本相同,其中在三種算法中相似度最高的均是金桔和檸檬,最低的是金桔和蓮藕。
為方便比較三種算法的準(zhǔn)確度,本文采用靈敏度比較,如式(15)所示:

其中,φmax為優(yōu)選中最大值,φsec為優(yōu)選中的次大值。
三種算法的靈敏度如表3所示。

表3 三種算法靈敏度比較Tab.3 Comparison of the sensitivity of the three algorithms
可見(jiàn)本文算法有較高的靈敏性,可以應(yīng)用到實(shí)際案例中。
5 系統(tǒng)實(shí)現(xiàn)
本文所描述的農(nóng)產(chǎn)品生產(chǎn)銷(xiāo)售知識(shí)檢索系統(tǒng)采用Java語(yǔ)言,數(shù)據(jù)庫(kù)使用MySql完成。
通過(guò)采用上文所述流程,完成需求分析,信息采集,將數(shù)據(jù)以物元形式提供給計(jì)算機(jī),完成語(yǔ)義相似度計(jì)算后,知識(shí)檢索的結(jié)果采用語(yǔ)義相似度由高到低的順序排列,提供給用戶。
6 結(jié)論
本文改進(jìn)了一種新的語(yǔ)義相似度算法并成功應(yīng)用與農(nóng)產(chǎn)品的生產(chǎn)銷(xiāo)售平臺(tái),該算法從信息量、語(yǔ)義距離、屬性等三個(gè)方面進(jìn)行分析,最后進(jìn)行加權(quán)計(jì)算。充分考慮各個(gè)影響因素的同時(shí),聯(lián)系實(shí)際情況,研究各個(gè)因素對(duì)實(shí)驗(yàn)結(jié)果的影響程度,得到參數(shù)值,物元模型的應(yīng)用直觀形象地展現(xiàn)各個(gè)信息的概念、關(guān)系和屬性,提高語(yǔ)義相似度的計(jì)算效率,節(jié)約存儲(chǔ)空間。同時(shí),為農(nóng)產(chǎn)品的供需雙方建立一個(gè)便捷可靠地平臺(tái)。但是本文仍存在一些問(wèn)題,計(jì)算結(jié)果容易受到主觀因素的影響,這是需要繼續(xù)研究的問(wèn)題。
猜你喜歡
現(xiàn)代裝飾(2022年1期)2022-04-19 13:47:32
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
現(xiàn)代裝飾(2020年2期)2020-03-03 13:37:44
中學(xué)生數(shù)理化·高一版(2018年9期)2018-10-09 06:46:48
中學(xué)生數(shù)理化·高一版(2017年9期)2017-12-19 12:15:14
中華手工(2017年2期)2017-06-06 23:00:31
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
中外會(huì)展(2014年4期)2014-11-27 07:46:46
外語(yǔ)學(xué)刊(2011年1期)2011-01-22 03:38:33
