基于全局-時頻注意力網絡的語音偽造檢測
2021-07-23 02:04:24王成龍易江燕陶建華馬浩鑫田正坤傅睿博
計算機研究與發展 2021年7期
王成龍 易江燕 陶建華,3 馬浩鑫 田正坤 傅睿博
1(中國科學技術大學信息科學技術學院 合肥 230027)
2(模式識別國家重點實驗室(中國科學院自動化研究所) 北京 100080)
3(中國科學院大學人工智能學院 北京 100049)
自動說話人驗證(automatic speaker verification, ASV)[1-3]是指通過分析說話人的語音來自動接受或拒絕其身份.它作為一種身份識別技術,已經廣泛應用于各種場景,例如:電子購物、電話銀行、電子商務等.最近,越來越多的研究表明:ASV系統面臨著各種偽造語音攻擊的問題.常見的偽造語音可以分為4種方式:語音模仿、錄音重放、語音合成和語音轉換[4].因此,研究人員設法開發出有效的反欺騙系統,以保護ASV系統免受偽造語音的欺騙攻擊.
為了提高反欺騙系統的性能,最近的工作主要集中在2個方面:1)改善音頻的聲學特征;2)設計新的分類模型.選取能夠有效區別真實語音和偽造語音的聲學特征尤為重要.Todisco等人[5]將常數Q變換倒譜系數(constant Q cepstral coefficients, CQCC)應用于語音鑒偽中,使用常數Q變換(constant Q transform, CQT)而不是短時傅里葉變換來處理語音信號,其性能優于普通的梅爾倒譜系數(Mel frequency cepstrum coefficients, MFCC).Sahidullah等人[6]用線性濾波代替了梅爾刻度濾波,提出了線性頻率倒譜系數(linear frequency cepstrum coeffi-cients, LFCC),使其更加關注高頻段特征.此外,Sahidullah等人[6]還嘗試了翻轉梅爾倒譜系數(inverse Mel frequency cepstrum coefficients, IMFCC),將原先的梅爾刻度翻轉過來,使其在高頻段分布更密,從而更專注于高頻特征.另一種方法是設計新的分類模型,該模型可以學習到真偽語音的區分表示.高斯混合模型(Gaussian mixture model, GMM)是最常用的分類模型.隨著深度學習的發展,卷積神經網絡(convolution neural network, CNN)的性能,要比直接使用GMM更好[7-10].例如具有最大特征圖(max feature map, MFM)激活功能的輕量型卷積神經網絡(light convolution neural network, LCNN)[11],通過競爭學習的方法不僅可以分離噪聲信號和信息信號,還可以起到特征選擇的作用.殘差網絡(residual network, ResNet)[12]提出了殘差模塊,解決了網絡“退化”的問題,即隨著網絡模型的加深,學習效果反而變差.這2種方法均被證明是有效的,這表明使用適當的前端聲學特征以及出色的深度學習模型對于偽造語音檢測都是至關重要的.
雖然以上工作已經取得了比較好的表現,但仍存在2個方面問題:1)現有的卷積神經網絡及其變種忽視了每一維上特征圖的不同位置強調的信息是不一樣的,它們假設送入卷積神經網絡的特征圖的每一維對結果的影響是相同的.2)當前工作集中關注特征圖的局部信息,無法利用全局視圖中特征圖之間的關系.如何更全面精準地分析利用這些屬性特性找到真實語音和偽造語音的區別,將有限的注意力集中在重點信息上是目前語音偽造檢測研究所面臨的一項重要挑戰.
注意力機制在圖像識別、自然語言處理、語音識別等領域[13-17]有了很多成功應用.受到這些應用的啟發,我們考慮引入注意力機制來解決將有限的注意力集中在重點信息上這一挑戰.Lai等人[9]在語音偽造檢測領域中引入SE-Net,從全局維度分配注意力權重.Sarthak等人[18]在說話人識別領域引入時頻注意力,關注局部的注意力分配.但是他們沒有考慮到將全局注意力模塊和時頻注意力模塊聯合使用.本文融合了全局-時頻注意力模塊,同時從全局和時頻特征圖2個層面的注意力機制為不同的特征賦予不同的注意力權重,實現了真偽語音特征更全面精準的區分,從而保證了真偽語音的準確預測.此外,為了進一步獲得更具有區分性的真偽語音嵌入,我們將softmax損失函數替換成了angular softmax[19]損失函數,從優化內積空間到優化角度空間,使得類間距離擴大,類內距離縮小,從而使得真偽語音的區分性更大了.最后,我們在ASVspoof2019公開數據集上進行一系列實驗,結果顯示所提的模型取得不錯的效果,最佳模型的等錯誤率(equal error rate, EER)達到4.12%,刷新了單個模型的最好成績.
本文的主要貢獻包括2個方面:
1) 融合了全局-時頻注意力網絡,從全局和時頻特征圖2個層面的注意力機制為不同的特征賦予不同的注意力權重,實現了真偽語音特征更全面精準的區分;
2) 將softmax損失函數替換成了angular softmax損失函數,進一步提升了模型的性能.
1 相關工作
本節從輕量型卷積神經網絡、注意力機制、前端聲學特征研究和angular softmax損失函數4個方面介紹相關工作.
1.1 輕量型卷積神經網絡
輕量型卷積神經網絡(LCNN)最早應用于人臉識別,此后在ASVspoof2017比賽中,第1名的隊伍使用了LCNN的方法,隨后在語音偽造檢測領域中大量被使用.在LCNN中,每一個卷積層都用了最大特征圖MFM如圖1所示,具體而言就是將原輸入層分為2個部分,通過競爭學習,丟棄了輸出較小的部分,剩下輸出較大的部分.此外,LCNN相較于傳統卷積神經網絡不僅可以獲得更好的性能,還可以減少參數量.本文所提的整體網絡框架就在LCNN的基礎上進行了改進.

Fig. 1 Max feature map圖1 最大特征圖
1.2 注意力機制
眾所周知,注意力在人類感知中起著重要的作用.注意力機制最早在計算機視覺領域廣泛應用[13,20],當一幅場景擺在我們面前時,我們所能注意到的東西是不一樣的,換句話說,該場景下我們對每一處空間的注意力分布是不一樣的.同樣,這種情況也適用于語音場景.最近,一些基于卷積注意力的工作在說話人識別中開展[21-23].文獻[24]引入SE-Net到說話人嵌入提取器中來提高對說話人嵌入之間的微妙差異的學習能力.SE-Net可以通過動態地分配通道維度的權重來提高網絡的表達能力.具體而言,SE-Net是一個簡化的網絡,它可以插入基于CNN的網絡中,以學習通道之間的相互依賴性,并生成一組通道層面的權重,以強調有用的信息抑制無用的信息.這種從全局考慮長時說話人語音的方法被證實在說話人識別中是有效的.
1.3 前端聲學特征
在本節中,我們將介紹在DNN框架下不同的前端聲學特征.
1) 線性頻率倒譜系數LFCC
LFCC是一種基于三角濾波器組的倒譜特征,類似于廣泛使用的梅爾頻率倒譜系數(MFCC).它的提取方法于MFCC類似,但是濾波器是線性的而不是梅爾刻度.因此,LFCC在高頻區域可能具有更好的分辨率.
2) 翻轉梅爾倒譜系數IMFCC
IMFCC也是一種基于三角濾波器組的倒譜特征,與MFCC不同的是,IMFCC采用的的濾波器是逆梅爾刻度,即在高頻比較密集,在低頻比較稀稠.因此IMFCC也更關注高頻區域.
3) 常數Q變換倒譜系數CQCC
CQCC使用常數Q變換(即CQT)而不是短時傅里葉變換來處理語音信號,其性能優于普通的梅爾倒譜系數MFCC.
4) 濾波器組(Fbank)
Fbank是一種基于三角濾波器組的倒譜特征,它的提取過程與MFCC類似,在離散余弦變換之前得到的特征我們就稱為Fbank.
5) 語譜圖
給定語音序列t(n),Tn(ω)是其經過窗函數ω(n)的短時傅里葉結果.Tn(ω)可以表示為
Tn(ω)=|Tn(ω)|ejθn(ω),
(1)
其中,|Tn(ω)|指的是短時幅度譜,θn(ω)指的是相位譜.
1.4 angular softmax損失函數
傳統的softmax損失函數定義為
(2)
其中,N是訓練樣本的個數,xi是第i個樣本,yi是其對應的標簽w是最后一層全連接網絡的參數.

(3)
其中,θi,yi是矢量Wyi和xi之間的夾角,為了進一步讓真偽語音的分類間隔擴大,我們引入了一個參數m,使得cos(mθ1)>cos(θ2),就得到了angular-softmax損失函數,其表達式為
La=
(4)
其中,m是固定的角度間隔,m值越大角度間隔越大.
2 本文所提框架
在本節中,我們首先介紹全局-時頻注意力網絡的總體框架,然后分別介紹2個注意力模塊,它們分別捕獲時頻局部信息和全局信息.
2.1 全局時頻注意力網絡總體框架


Fig. 2 Global and temporal-frequency attention based network圖2 全局-時頻注意力網絡
總體注意力過程可以概括為
X′=Mg(X)?X,
X″=Mtf(X)?X,
(5)
X?=X′⊕X″,
2.2 全局注意力模塊和時頻注意力模塊
1) 全局注意力模塊

Fig. 3 Global attention module圖3 全局注意力模塊
(6)
其次是激活操作,它類似循環神經網絡中門的機制,通過參數來為每個特征通道生成權重,其中參數被學習用來顯式地建模特征通道間的相關性:
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z)),
(7)
其中,δ指的是ReLU激活函數,σ指的是sigmoid激活函數.

Fig. 4 Temporal-frequency module圖4 時頻注意力模塊
最后是重新分配權重,我們將上一步輸出的權重看作是經過特征選擇后的每個特征通道的重要性,然后通過乘法逐個通道加權到先前的特征上,完成在通道維度上的對原始特征的重新標定.
2) 時頻注意力模塊
(8)
其中,sji表示第i個位置對第j個位置的影響,2個位置的特征表示越相似,他們之間的相關性越高.
(9)
其中,α初始化為0并逐漸學會分配權重.從式(9)可以得出,每個位置上的結果特征D是所有位置上的特征與原始特征的加權和.因此,它具有全局前后幀視圖,并根據時頻注意力圖選擇性地聚合前后幀.相似的語音特征實現了共同的促進,從而改善了類內部的緊湊性.
3 實 驗
3.1 數據集
本文所有的實驗都在ASVspoof2019[24]數據集上進行,我們關注的重點是合成語音和轉換語音對真實語音的干擾,因此我們采用的是logical access(LA)數據集.數據集的詳細說明可以在表1看到.LA數據集包含3個子集:訓練集、開發集和測試集.訓練集包含2 580條真實語音和22 800條用6種方式合成或轉換的偽造語音;開發集包含2 548條真實語音和22 296條用6種方式合成或轉換的偽造語音;測試集包含了7 355條真實語音和64 578條未知算法生成的偽造語音.
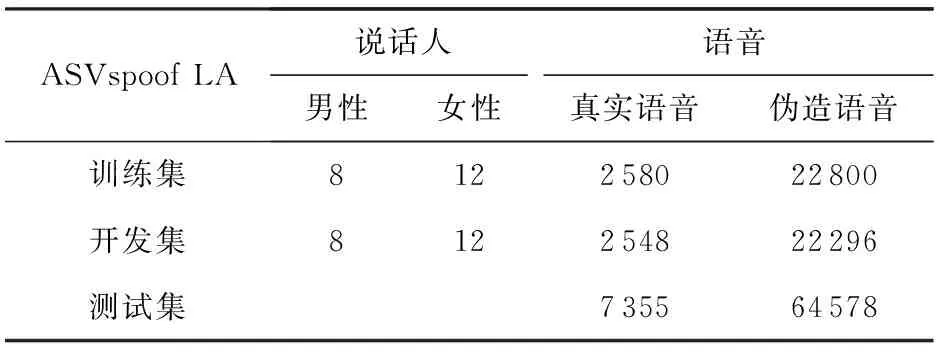
Table 1 ASVspoof2019 LA Dataset表1 ASVspoof2019 LA數據集
3.2 評價指標
本文采用等錯率(EER)來描述系統的指標.等錯率是一種權衡錯誤拒絕率和錯誤接受率的一項指標.
(10)
EER=Pfa(θEER)=Pmiss(θEER).
其中,Pfa(θ)是錯誤接受率,是指偽造語音被判定為真實語音的數量除以總的偽造語音的數量;Pmiss(θ)指的是錯誤拒絕率,指的是真實語音判定為偽造語音的數量除以總的真實語音的數量.錯誤接受率和錯誤拒絕率的值相等時,此值就是等錯率.
3.3 實驗模型配置與參數設置
本文在基于LCNN的語音偽造檢測的基礎上增加了批量歸一化層和全局-時頻注意力模塊,在減少其內部相關變量的偏移和加速網絡收斂的同時從全局和時頻特征圖2個層面的注意力機制為不同的特征賦予不同的注意力權重,實現了真偽語音特征更全面精準的區分.其網絡結構如表2所示:

Table 2 LCNN Architecture表2 LCNN網絡結構
首先對輸入的語音數據進行預處理、特征提取(如1.3節提到的LFCC,Fbank,CQCC,IMFCC等).其次基于全局-時頻注意力的LCNN網絡,提取語音的深層次非線性因子特征.最后,由全局-時頻注意力網絡的最后一層輸出輸入到全連接層,計算真實語音和偽造語音的得分,用于預測真偽語音類別的標簽.
為了驗證本文所提方法的有效性和聲學特征的影響,我們主要設置了11組實驗,具體配置為
1) LFCC-GMM.LFCC-GMM是ASVspoof2019提供的基線系統,其中高斯混合數為512.LFCC的提取參照基線系統——窗口長度設為20 ms,FFT維數為512,并且濾波器組數為20,并對其作一階和二階差分.
2) LFCC-LCNN.LCNN參照表2,但是沒有包含注意力模塊,總共有9層卷積層.LFCC的提取方式和LFCC-GMM類似.
3) LFCC-CMVN-LCNN.整個框架與LFCC-LCNN類似,不過在LFCC提取過程中作了均值和方差的歸一化處理.
4) CQCC-LCNN.CQCC的提取采用常規的默認值,即每八度音階96個譜線,窗口大小為1 724,步長為0.008 1.
5) Fbank-LCNN.Fbank的提取窗口長度設為20 ms,FFT維數為512,并且濾波器組數為40.
6) Spectrum-LCNN.語譜圖的提取窗口長度設為20 ms,FFT維數為512.
7) LFCC-LCNN-Global&TF.LCNN-Global& TF指的是含有全局-時頻注意力模塊的LCNN,其結構如表2所示.LFCC的提取方式和LFCC-GMM類似.
8) LFCC-LCNN-CBAM.同上,將注意力模塊換成了CBAM[15]模塊.
9) LFCC-LCNN-Global.整體框架與LFCC-LCNN-Global&TF保持一致,注意力模塊只選擇了全局注意力模塊.
10) LFCC-LCNN-TF.同上,注意力模塊方面只選擇了時頻注意力模塊.
11) LFCC-LCNN-Global&TF-Asoftmax.整體框架與LFCC-LCNN-Global&TF類似,不過將softmax換成了A-softmax.
本文所提模型基于深度學習框架PyTorch展開實驗.優化器為Adam,其中batchsize=32,初始學習率為0.0005,動量為0.9,模型迭代次數為200.
3.4 實驗結果與分析
3.4.1 前端聲學特征的影響
為了探究前端聲學特征對系統的影響,本文在保持后端分類器LCNN不變的情況下,設置了不同的前端聲學特征.實驗結果如表3所示.對比5種聲學特征,可以看出,LFCC的性能最好,這與先前的分析保持一致,這是由于LFCC的濾波器是線性的而不是梅爾刻度,因此在高頻區域有更好的分辨率.此外,對比表3中行5和行6,可以看出對LFCC做了均值和方差歸一化后效果反而變差了.這是由于測試集和訓練集、開發集的差異較大,因此做了歸一化結果變差.

Table 3 The Result of Front-End Acoustic Characteristics表3 前端聲學特征的結果 %
3.4.2 全局-時頻注意力的影響
由于表3的實驗驗證了LFCC的有效性,因此接下來我們統一將前端聲學特征固定為LFCC,通過更改后端網絡分類器來驗證本文所提的全局-時頻注意力網絡的有效性.實驗結果如表4所示.分別對比表4行1和行2~5,可以得到結論,加了注意力模塊的系統相較于原系統對結果都有提升.此外,我們還對全局-時頻注意力模塊做了消融實驗,以說明不同注意力模塊對整體性能的影響.具體而言,我們比較了3種注意力模塊:只包含全局注意力模塊(LCNN-Global)、只包含時頻注意力模塊(LCNN-TF)和并行的全局-時頻注意力模塊(LCNN-Global& TF).表4的行3到行5總結了不同注意力模塊安排方式的結果.從結果中,我們可以發現并行地使用全局-時頻注意力模塊要優于單獨使用任一注意力模塊,這表明將2種注意力模塊并行使用是有效果的.此外,單獨使用全局注意力模塊的性能要略好于單獨使用時頻注意力模塊.
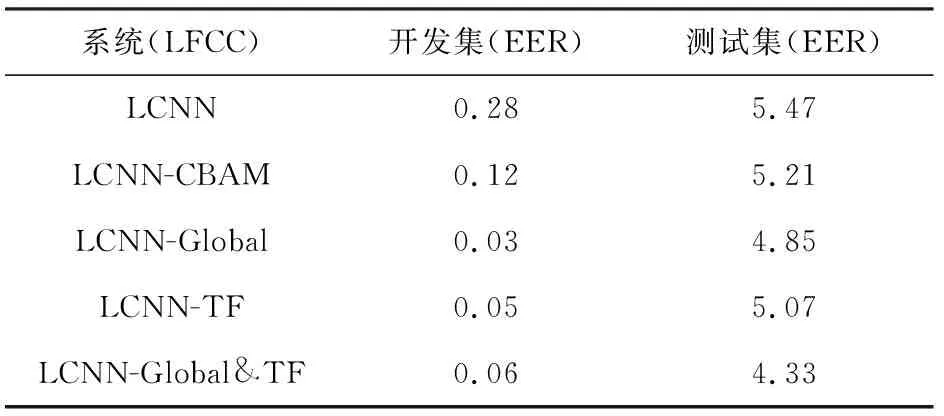
Table 4 The Result of Attention Module表4 注意力模塊的結果 %
3.4.3 A-softmax損失函數的影響
我們還驗證了A-softmax損失函數的有效性.從表5可以看出,將損失函數從softmax替換成了A-softmax之后,EER從4.33%下降到了4.12%,性能提升了5.1%.這一結果表明:A-softmax損失函數通過優化角度空間,使得類間距離擴大,類內距離縮小,從而擴大了真偽語音的區分性.此外,我們還對表4的5個系統和表6的A-softmax系統做了分數層面的融合,融合后的EER為3.21%.表6中,文獻[25]的方法與本文表2的LFCC方法類似,但是由于其沒有提供公開代碼,不能完全復現,性能比它略低.融合了表4的5個系統和表5的A-softmax系統,總共6個系統.

Table 5 The Influence of A-softmax Loss Function表5 A-softmax損失函數的影響 %

Table 6 Comparison of Proposed Method with State-of-the-art System表6 與其他方法比較的結果 %

Table 7 Multi-system Fusion表7 多系統融合 %
3.4.4 與其他最先進的系統對比
為了進一步證明本文所提方法的有效性,我們將本文的方法與其他在ASVspoof2019 LA數據集上的先進系統的結果做了對比.為了公平起見,我們將結果與其他系統的單個系統進行比較.從表6可以看出,本文所提的方法在單個系統中達到了最佳的性能,等錯誤率達到了4.12%,這個分數也是目前我們能了解到的在ASVspoof2019 LA數據集上單個系統的最佳成績,進一步地證明了本文方法的有效性.
4 討 論
據3.4節實驗結果可見,本文所提的方法在測試集上的EER均有明顯下降.
在單獨使用全局注意力模塊或時頻注意力模塊相較于原系統都有性能上的提升.此外,并行使用全局-時頻注意力模塊會進一步提升系統性能.這是由于全局-時頻注意力能夠有效地從全局維度和時頻維度關注全局和時頻特征的有效信息,抑制那些無用信息,從而提高了實驗結果.
除此之外,在損失函數層面用A-softmax代替softmax之后,性能進一步提升,在ASVspoof2019 LA數據集上單個系統上取得最佳成績.這是由于A-softmax損失函數通過優化角度空間,使得類間距離擴大,類內距離縮小,從而擴大了真偽語音的區分性.
5 總 結
語音偽造檢測是近年一個研究熱點.本文針對目前工作沒有考慮到每一維上特征圖的不同位置強調的信息是不同的問題,引入了一種基于全局-時頻注意力網絡的語音偽造檢測模型.首先,我們從卷積神經網絡輸出的三維特征圖壓縮到只剩下通道維度,再將其經過一個類似循環神經網絡中門控制的機制,通過參數為每個特征通道生成權重,其中參數被學習用來顯式建模特征通道間的相關性.通過這種辦法,我們可以得到特征通道上響應的全局分布.與此同時,我們通過使用加權求和在所有時頻特征圖上聚合特征來進行更新,其中權重由對應2個時頻點之間的相似性決定.此外,為了進一步獲得更具有區分性的真偽語音嵌入,我們將softmax損失函數替換成了A-softmax損失函數,從優化內積空間到優化角度空間,使得類間距離擴大,類內距離縮小,從而使得真偽語音的區分性更大了.最后,在ASVspoof2019 LA這個公開數據集中,通過一系列的實驗表明本文所提的全局-時頻注意力網絡模型取得了最好的分類結果,充分證明了模型在語音偽造檢測問題上的有效性.
未來的研究工作中,可以針對不同的特征組合拼接或者相位信息的聲學特征對語音偽造檢測的影響上進行更多的考慮和設計.
作者貢獻聲明:王成龍進行了該論文的模型設計、實驗編碼及運行、論文撰寫等工作;易江燕進行了前期方法的討論設計與論文修改;陶建華進行了論文修改;馬浩鑫進行了補充實驗以及模型調優;田正坤進行了損失函數的代碼支持,以及從語音識別角度對方法提供改良;傅睿博從語音偽造角度提出引入全局模塊.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
