一種高精度的卷積神經網絡安全帽檢測方法
2021-07-14 01:30:20李天宇陳明舉劉益岑
液晶與顯示 2021年7期
李天宇,李 棟,陳明舉*,吳 浩,劉益岑
(1.四川輕化工大學 人工智能四川省重點實驗室,四川 宜賓 644000;2.國網四川省電力公司電力研究院,四川 成都 610000)
1 引 言
在施工環境中,施工人員佩戴安全帽可以有效避免或減小安全事故的傷害。通過人工巡檢監控視頻實現安全帽佩戴檢測費時費力,且容易造成誤檢和漏檢。利用機器視覺技術對施工現場工作人員是否佩戴安全帽進行檢測,可有效地代替人工巡檢,提高識別的精度,避免安全事故的發生。
傳統的安全帽檢測主要通過對監測視頻進行目標檢測,提取目標的幾何、顏色等特征進行對比識別。劉曉慧等人[1]利用膚色檢測實現人頭區域的定位,再采用SVM分類器對安全帽的Hu矩特征進行識別;周艷青等人[2]將人頭區域的統計特征、局部二進制模式特征和主成分特征訓練分類器,建立了多特征的安全帽檢測算法;賈峻蘇等人[3]結合局部二值模式直方圖、梯度直方圖和顏色特征,利用SVM對安全帽進行檢測。基于目標圖像特征提取的傳統檢測方法,泛化能力較差[4],而實際施工環境復雜多樣,通常存在雨霧、遮擋等的影響。因此,基于目標圖像特征提取的傳統檢測方法檢測能力有限。
近年來,基于深度學習的目標檢測技術能夠利用卷積網絡自動學習大樣本數據有用的特征,建立的檢測網絡模型泛化能力較強,有效地實現了特殊環境下的安全帽識別。基于深度學習的目標檢測技術主要為基于區域建議和基于回歸策略的目標檢測網絡。基于區域建議的目標檢測網絡需要先生成可能含有待檢測物體的預選框,然后再利用主干網絡提取特征信息進行分類和回歸。基于回歸策略的單階段目標檢測算法則直接在網絡中提取特征預測出物體的類別以及位置[5]。通常二階段的檢測算法精度高,但檢測速度遠低于單階段的檢測速度。經典的二階段網絡Faster RCNN[6]采用RPN預選框生成網絡和主干特征提取網絡,實現目標的準確識別,但檢測耗時較大。徐守坤等人[7]在二階段檢測算法Faster RCNN的基礎上利用多層卷積特征優化區域建議網絡,建立改進的faster-RCNN算法,雖然提高了網絡檢測的準確率,但是延長了檢測時間,其檢度時間仍然遠大于一階網絡,未能達到實時檢測的要求。基于回歸策略的目標檢測網絡主要是YOLO、SSD、RFBNet等[8-12]。為提高單階段網絡的檢測精度,董永昌等人[13]在SSD檢測算法的基礎上,引入了DenseNet作為主干網絡提取特征,充分利用了各層的特征信息,提高了網絡的檢測精度。陳柳等人[14]在RFBNet檢測算法的基礎上,引入SE-Ghost模塊來輕量化檢測模型,并利用FPN提高網絡對小目標檢測的魯棒性。唐悅等人[15]針對單階段算法YOLOv3的缺點,引入GIoU代替IoU來優化錨框選取,但是GIoU具有在錨框包含時會退化為IoU的缺點。同時檢測網絡采用了密集連接結構來加強特征的傳遞,所得到算法的檢測效果優于傳統YOLOv3。以上改進的單階段網絡雖然都提高了檢測精度,但是檢測速度有所下降。
本文針對施工現場的復雜環境與實時性要求,以YOLOv3網絡為基礎建立一種基于回歸策略的高精度安全帽檢測網絡。該網絡在YOLOv3的檢測網絡中,構建特征金字塔網絡CPANet模塊提高弱小安全帽目標的檢測精度,同時采用了CIoU來代替IoU進行回歸預測,在優化錨框回歸的同時能夠提高模型的收斂能力。通過對比實驗證明,在有遮擋的復雜施工環境下,該網絡能實現弱小安全帽目標的準確檢測,且檢測速度較快,滿足實時檢測的要求。
2 YOLOv3目標檢測網絡
YOLOv3是基于回歸策略的目標檢測算法,網絡包括Darknet53特征提取網絡和檢測網絡兩部分,其中Darknet53主要用來提取圖像特征信息,檢測網絡用來進行多尺度的目標預測。DarkNet53是全卷積網絡,共有53個卷積層,采用1×1和3×3的卷積組成帶有跳躍連接的殘差塊來構建殘差網絡,減少了因網絡太深而帶來的梯度消失現象,能夠提取更加深層的語義信息。同時,使用步長為2的卷積來代替最大池化進行下采樣,降低了池化帶來的梯度負面效果。
為了提高網絡對目標的檢測能力,YOLOv3檢測層中使用了類似特征金字塔網絡的上采樣和特征信息融合的做法。當輸入圖像歸一化到416×416送入網絡進行檢測時,Darknet53會輸出3個檢測尺度,分別為13×13,26×26,52×52。根據特征金字塔網絡結構,13×13與26×26大小的特征圖要依次經2倍上采樣操作與26×26和52×52大小的特征圖進行信息融合,將深層的語義信息通過快捷連接傳入到淺層,得到3個帶有語義和位置信息融合的特征圖。YOLOv3的網絡結構如圖1所示。
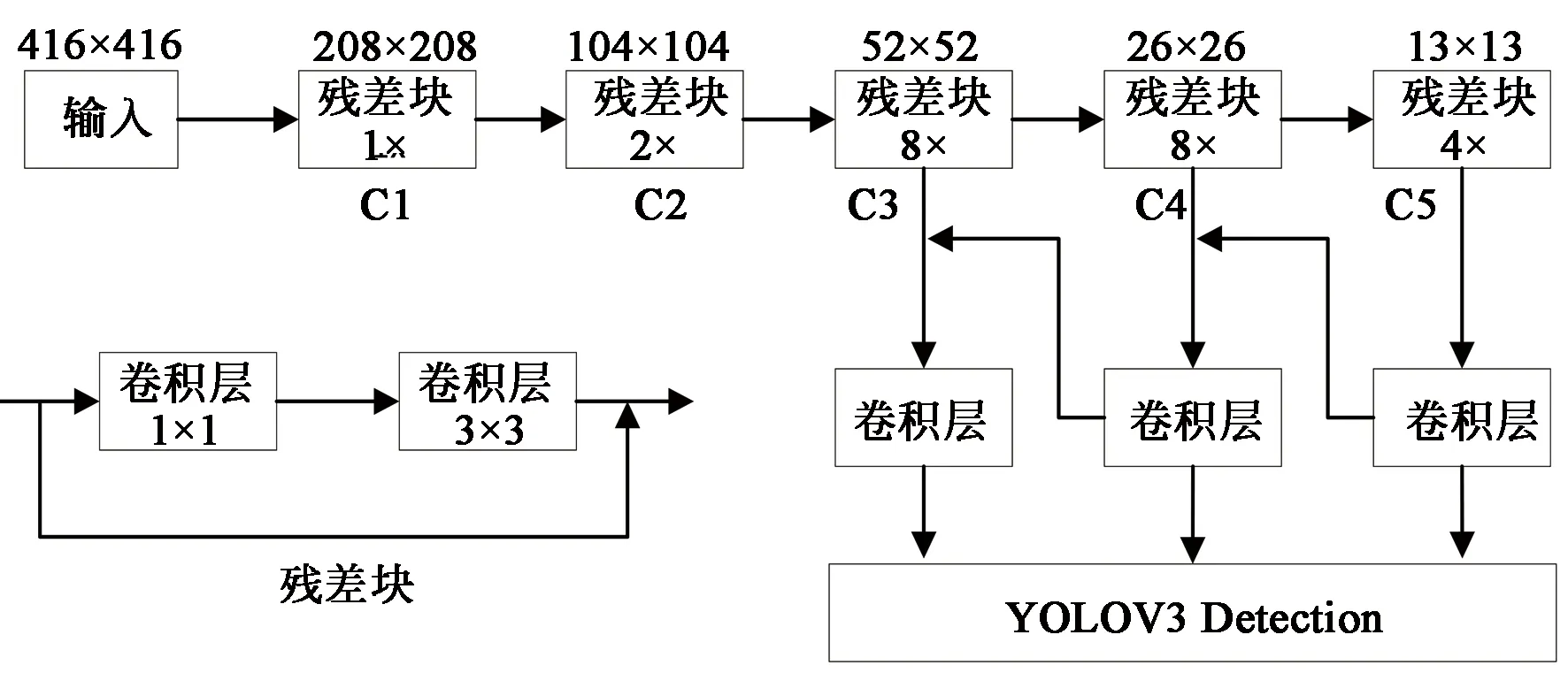
圖1 YOLOv3算法結構示意圖Fig.1 Diagram of YOLOv3 algorithm structure
YOLOv3網絡能夠快速實現目標的檢測,并利用FPN引入多尺度的目標預測來提高其檢測能力。但其FPN網絡只采用3個尺度,只進行了一次自上而下的特征融合,各層信息利用不足,對于一些小目標和有遮擋目標,其檢測能力有限。
YOLOv3在實現邊界框預測時,通過 k-means算法對數據集中的目標框進行維度聚類,得到9組不同大小錨框,將錨框平均分配到3個檢測尺度上,每個尺度的每個錨點分配3組錨框。但是這樣操作會帶來大量的錨框,于是YOLOv3采用了最大交并比(IoU)來對錨框進行回歸。IoU計算的是預測邊界框和真實邊界框的交集和并集的比值,一般來說預測邊界框和真實邊界框重疊度越高,則其IoU值越大,反之越小。并且IOU對尺度變化具有不變性,不受兩個物體尺度大小的影響。其計算公式如式(1)所示:
(1)
其中,A屬于真實框,B屬于預測框。
但是IoU無法精確地反應真實框和預測框重合位置的關系,存在兩個較大的缺點,第一,無法衡量兩個框之間的距離,如圖2所示,圖2(a)明顯要比圖2(b)中的距離近,但僅從IoU數值上無法判斷兩框的遠近;第二,無法反映真實框與預測框的重疊方式,如圖2(c)與圖2(d)的重疊方式完全不一樣,從IoU的數值上無法判斷其重疊方式。當上述情況出現時,會導致網絡沒有梯度回傳,造成模型難以收斂等問題的出現。
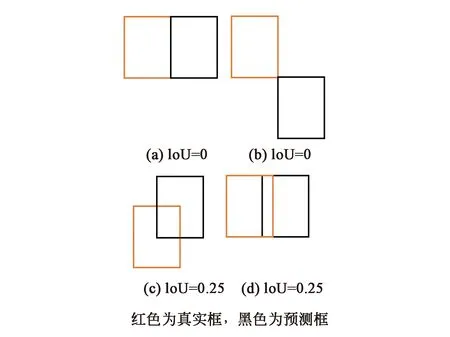
圖2 真實框與預測框位置表示圖Fig.2 Representation of the position of the prediction frame and the real frame
3 一種高精度的卷積神經網絡安全帽檢測方法
為了實現施工現場的復雜環境中弱小目標與遮擋目標的有效檢測,并提高網絡的收斂能力,本文在YOLOv3網絡的基礎上引入CPANet與CIoU,建立一種高精度的安全帽檢測網絡(YOLO_CPANet_CIoU)來提高檢測精度與模型收斂能力。
3.1 CPANet的特征金字塔網絡
在檢測網絡中,YOLOv3采用一次自上而下單向特征融合的特征金字塔網絡(圖3),利用C3~C5的輸入層經上采樣得到P3~P5三個不同尺度的輸出特征層。從C5到P5的過程經過了5次卷積,再經過一次3×3的卷積和一次1×1的卷積調整通道數后輸出;C3-P3、C4-P4的過程,首先要與上一層特征圖的兩倍上采樣結果進行特征融合,然后再經過和C5到P5同樣的運算過程并輸出對應的特征圖;最后特征金字塔網絡會輸出3個不同尺度的特征圖進行目標預測。一般來說,低層的特征圖包含更多的位置信息,高層的特征圖則擁有更好的語義信息,FPN網絡就是將這個兩者特征結合,增強網絡的檢測準確率。但是YOLOv3中自上而下的特征金字塔網絡,只將深層的語義信息通過便捷通道送入淺層,提高淺層特征的分類準確率,但并沒有利用便捷通道將淺層的位置信息傳入深層,深層特征的定位準確性有限。
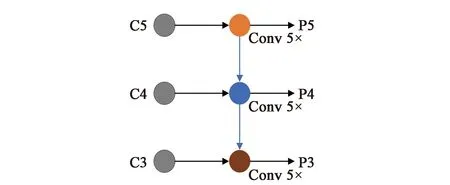
圖3 YOLOv3算法特征金字塔網絡Fig.3 YOLOv3 algorithm feature pyramid network
于是,為了實現對佩戴安全帽的工人準確檢測,減少網絡特征損失,并有效利用高低層的特征信息來提高網絡的定位準確率,本文引入了雙向特征融合的特征金字塔網絡PANet[16],在原始單向特征融合的FPN后加入了一條位置信息特征通道,使得淺層的特征能夠通過便捷通道在損失較小的情況下將位置信息傳送到深層進行特征融合,進一步提高了對弱小目標的定位準確性。PANet結構如圖4所示。
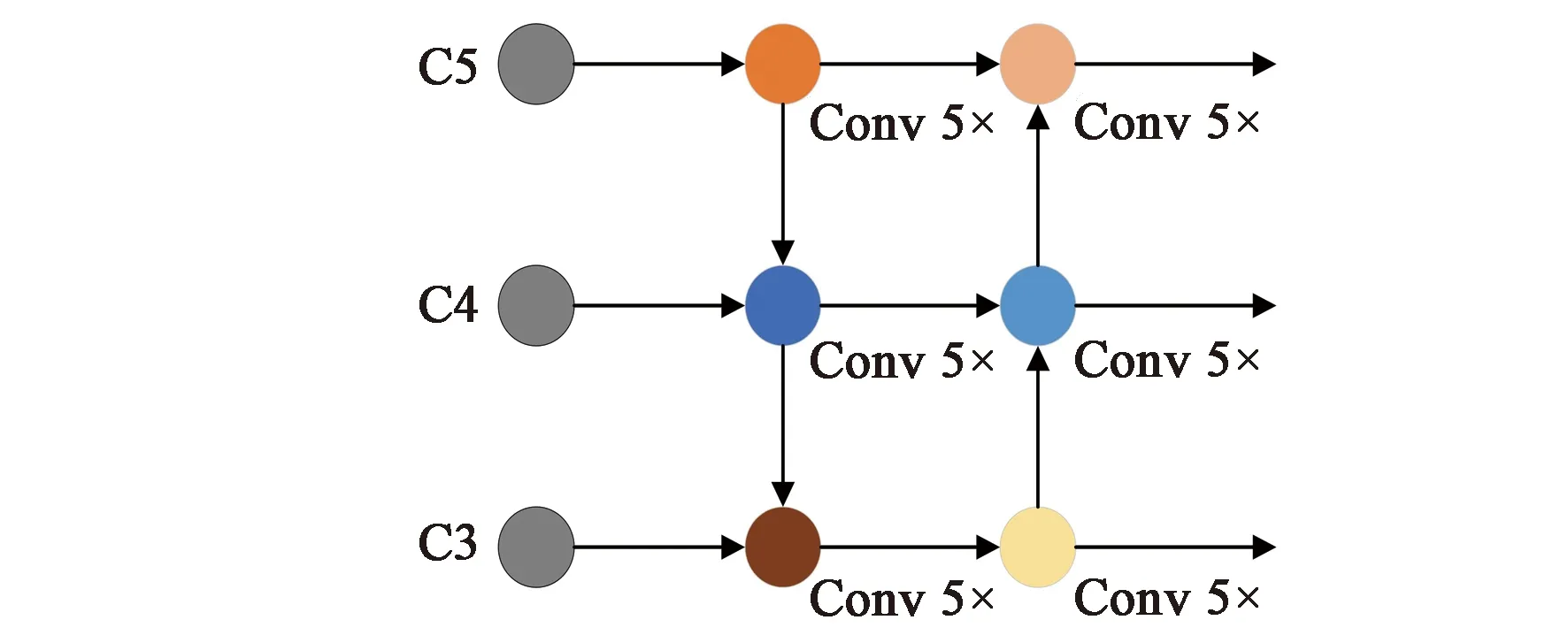
圖4 PANet雙向特征金字塔結構Fig.4 PANet bidirectional feature pyramid structure
相應的研究表明[17],與多次學習冗余的特征相比,特征重用是一種更好的特征提取方式。于是本文在特征金字塔上的橫向傳播通道添加3條跳躍連接,直接將主干網絡C3、C4、C5層的特征傳入到最后的輸出部分進行融合,使得最終輸出能夠得到前幾層特征圖上的原始信息。這樣做也能夠在一定程度上加快網絡的收斂速度,提高網絡結構的表征能力,增強對安全帽這類小目標物體的檢測效果。
為了進一步減少遮擋目標的誤檢,提高安全帽檢測精度,在特征金字塔網絡的輸出部分引入CBAM[18]注意力模塊建立CPANet特征金字塔網絡,如圖5所示。利用CBAM分別從通道和空間的角度來增強特征信息,在一定程度上擴大特征圖對全局信息的感知范圍,增強特征的表達能力。CBAM模塊首先通過通道注意力模塊,對每個通道的權重進行重新標定,使得表達小目標和遮擋目標的區域特征通道對于最終卷積特征有更大的貢獻,從而在背景中突出小目標和遮擋目標,并且抑制一些對分類作用不大的通道,減少網絡計算量;再利用空間注意力機制來突出目標區域,通過統計特征圖的空間信息得到空間注意圖用于對輸入特征進行重新激活,從而引導網絡關注目標區域并抑制背景干擾。
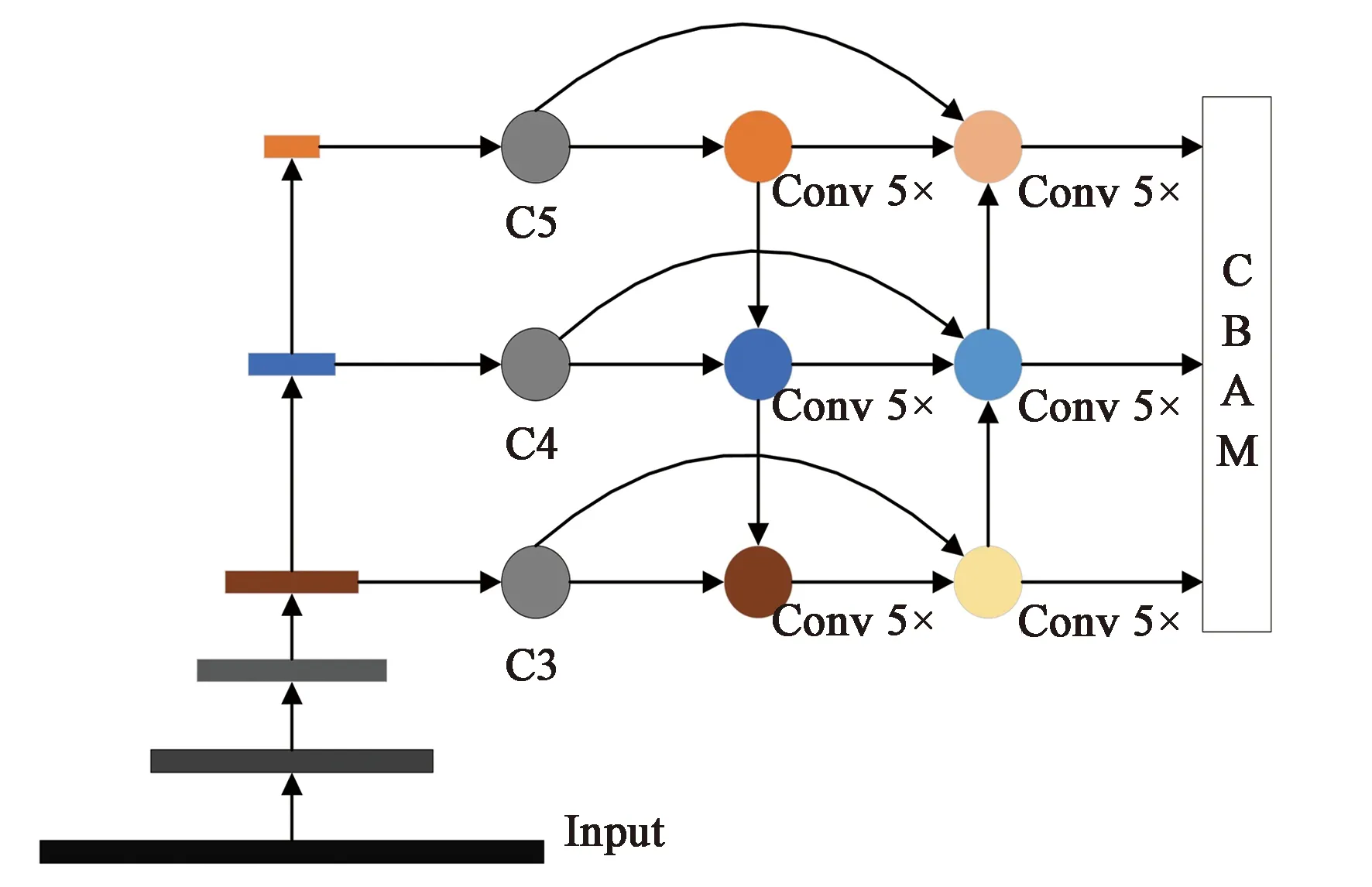
圖5 CPANet特征金字塔結構Fig.5 CPANet feature pyramid structure
3.2 CIoU邊界框損失函數
YOLOv3中使用了IoU對錨框進行回歸,但是根據前文分析,IoU無法衡量兩個框之間的距離和重疊方式,會導致模型收斂能力較弱。所以,一個好的回歸框應該考慮重疊面積、中心點距離、長寬比3個集合因素,文獻[19]針對這些問題首先提出了DIoU,同時考慮了真實框與預測框之間的距離和重疊面積,DIoU Loss的計算公式如下所示。
(2)
其中:b和bgt分別為預測框和真實框的中心點,ρ(·)為兩中心點之間的歐氏距離計算公式,c為在同時包含預測框和真實框的最小閉包區域的對角線距離。
其距離示意圖如圖6所示,d為預測框與真實框中心點距離,c為兩框對角點距離。可知DIoU能夠同時考慮中心點距離與重合兩框的對角點距離,改進了IoU存在的缺點,能夠在兩框未重合情況下為模型提供優化方向。
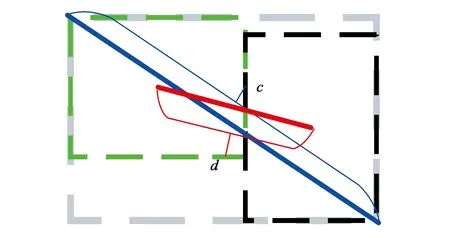
圖6 距離示意圖Fig.6 Distance diagram
同時,CIoU在DIoU的基礎上進一步考慮長寬比因素,在DIoU Loss的計算公式中加入懲罰項,CIoU Loss計算公式如式(3)所示。
(3)
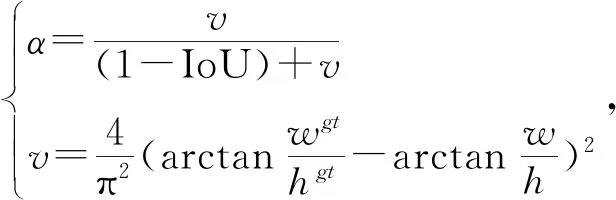
(4)
其中,α是正權衡參數,v是衡量長寬比一致性的參數。所以,CIoU同時考慮了重疊面積、中心點距離、長寬比三要素,能夠直接最小化兩個目標框的距離,并且在真實框與預測框不重合時,為預測框提供移動的方向。而且CIoU能替換NMS中的IoU算法,加快模型的收斂速度。
因此,在保持網絡的檢測性能不下降的前提下,本文利用CIoU來代替IoU 進行錨框的回歸,實現真實框和預測框無重合時的梯度回傳,提高模型收斂能力。同時,使用CIoU能夠降低模型的訓練難度,提高對于安全帽檢測的準確率。
4 實驗結果與分析
4.1 實驗環境與訓練過程
本次實驗在服務器上搭建環境并進行訓練,服務器硬件配置為CPU(Inter Xeon E5-2695)、GPU(Nvidia TITAN Xp)、主板(超微X10DRG-Q);操作系統為Windows10專業版;軟件配置為Anaconda、Pycharm;編程語言為Python,深度學習框架為Keras。
實驗數據為網上收集的開源安全帽檢測數據集[20],共有5 000張施工現場照片。所有的圖像用“labelimg”標注出目標區域及類別,共分為兩個類別,佩戴安全帽的標記為“helmet”,未佩戴安全帽的標記為“head”。并將數據集按 8∶1∶1 的比例分成訓練集、驗證集、測試集,分別用于模型的訓練、驗證以及測試過程。
本文采用安全帽數據集對檢測網絡進行訓練,為了提高本文算法的魯棒性并防止模型過擬合,在訓練集數據輸入模型訓練前使用圖像縮放、長寬扭曲、圖像翻轉、色域扭曲以及為圖像多余部分增加灰條等操作對訓練集進行預處理,同時采用了標簽平滑策略來防止模型過擬合。
訓練時,輸入圖片尺寸設置為416×416,采用預訓練模型,優化器為Adam。網絡訓練分兩次進行,第一階段訓練凍結Darknet53主干部分,初始學習率(Learning rate)設置為0.001,batch size(一次訓練所選取的樣本數)設置為32,訓練50輪,使用學習率下降策略,連續2輪驗證集的損失值未改善,學習率將乘以0.5;第二階段訓練釋放凍結部分微調模型,初始學習率設置為0.000 1,batch size設置為6,訓練60輪,使用學習率下降和提前終止策略,連續2輪驗證集的損失值未改善,學習率將乘以0.5,連續10輪驗證集損失未改變將提前中止訓練。損失下降曲線如圖7所示。
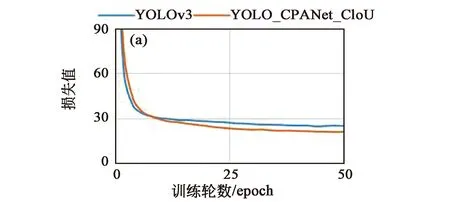
圖7 損失下降曲線圖。(a)前50輪;(b)后60輪。Fig.7 Loss decline graph.(a)The first 50 rounds;(b)The last 60 rounds.
圖7(a)為前50輪凍結主干網絡Darknet53的損失下降曲線,圖7(b)為后60輪模型微調訓練損失下降曲線,可以看出本文算法的收斂能力較改進前的YOLOv3強,最終本文算法損失下降至13左右便不再繼續下降。
4.2 實驗結果與分析
為了驗證本文算法的有效性,選取了FasterRCNN、SSD、RFBNet、YOLOv3網絡在相同的實驗環境下利用相同的訓練方式和數據集進行訓練,得到相應的安全帽檢測模型。
為了說明本文YOLO_CPANet_CIoU網絡的性能,選取了4張不同施工環境、遮擋以及人群密集程度的圖片,用上述訓練好的模型進行測試,并對測試結果進行對比分析。圖8為4張不同環境下的測試圖片,圖9(a)、(b)、(c)、(d)從左至右分別為Faster RCNN、SSD、RFBNet、YOLOv3以及YOLO_CPANet_CIoU網絡下的測試結果。從圖9中可以看出,Faster RCNN檢測效果較好,可以將大部分的遠處小目標安全帽以及有遮擋的安全帽目標檢測出來,但是存在一些誤檢現象,如測試圖1、測試圖2和測試圖4中,Faster RCNN都將一些相似的目標判定為安全帽,這是由于檢測網絡學習能力不足造成的誤檢測。其次,SSD算法在4幅不同場景的測試圖片中的檢測性能最差,如測試圖1未檢測出目標,測試圖2和測試圖4則未檢測出遠處小目標,測試圖3未檢測出一些遮擋目標。這是由于主干網絡的特征提取能力不強,且對于小目標和遮擋目標學習能力不足造成的。RFBNet的檢測效果要優于SSD,雖然測試圖1、測試圖2、測試圖4都對遠處弱小安全帽目標存在少量漏檢,但是能夠針對大多數的顯著目標和有遮擋的安全帽進行檢測,造成漏檢的原因是其未利用FPN網絡對高底層特征進行融合,導致對小目標的檢測不夠魯棒。YOLOv3是檢測性能僅次于本文算法,由于其擁有較深的特征提取網絡和FPN網絡,對弱小安全帽目標檢測的性能較好,能對大部分的遠距離以及近距離的安全帽進行檢測。但是針對測試圖1和測試圖3中存在一定遮擋的安全帽,YOLOv3并不能準確地檢測出來,存在漏檢現象。

圖8 原始測試圖片Fig.8 Original test pictures

(a)測試圖1檢測結果(a)Test picture 1 recognition results
本文的YOLO_CPANet_CIoU是4種網絡中檢測效果最好的,能夠針對測試圖1到測試圖4中所有的遠處弱小安全帽目標和有遮擋安全帽目標進行準確檢測,這說明了本文所提出的安全帽檢測方法能夠很好地融合高低層的特征信息,高效引導網絡注意目標區域,從而提高了算法對于弱小以及有遮擋安全帽目標的檢測準確率。
為了進一步說明YOLO_CPANet_CIoU的性能,本文從模型的精確率、檢測速度和參數量等評價指標來驗證改進網絡的優越性,利用相同的測試樣本對4種網絡進行測試。圖10給出檢測網絡的模型精度對比,表 1給出檢測網絡的模型參數對比。圖10給出了4種檢測網絡的各類別的安全帽(Helmet)和未佩戴安全帽(Head)平均精確率(Average Precision,AP)以及平均精確率均值(mean Average Precision,mAP)。由圖中可知,本文檢測網絡的mAP值相較于YOLOv3、RFBNet、SSD、Faster RCNN分別增長了0.82,4.43,23.12,23.96,其中helmet和Head的AP值相較于改進前的YOLOV3分別提高了0.18和1.46。這說明YOLO_CPANet_CIoU中的CIoU以及提出的CPANet特征金字塔模塊能夠提高網絡對安全帽的檢測精度。
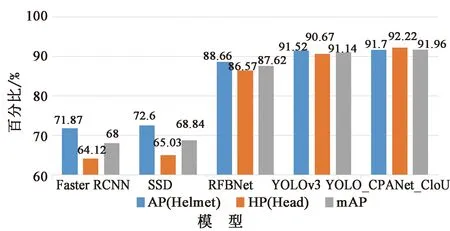
圖10 模型精度對比圖Fig.10 Model accuracy comparison chart
由表1可知,雖然YOLO_CPANet_CIoU的參數量最大有298 M,但是其檢測速度僅次于YOLOv3,能夠達到21 frame/s的速度,完全滿足實時性的要求。針對視頻圖像,能夠實時在視頻圖像中定位與追蹤佩戴安全帽和未佩戴安全帽的工作人員,到達施工現場安全帽檢測的要求。
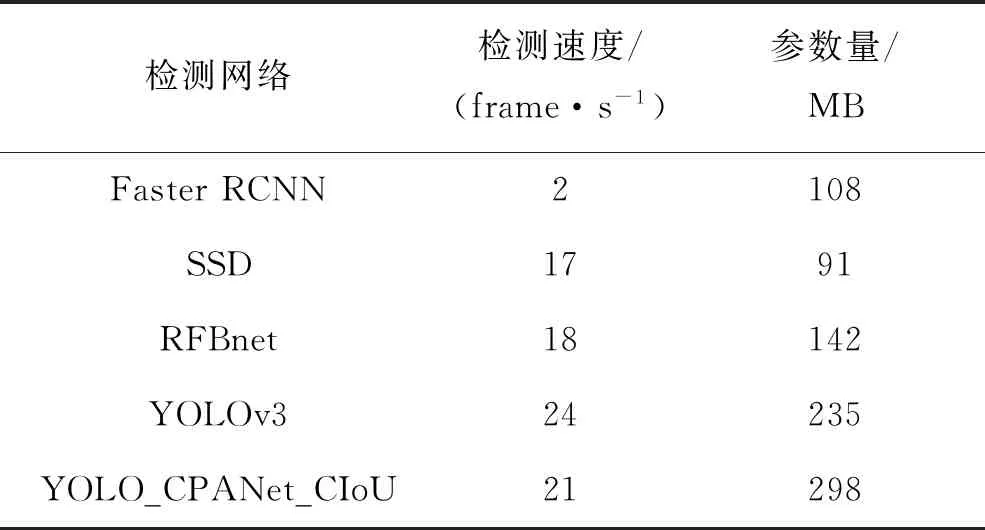
表1 模型參數對比表Tab.1 Model parameter comparison
5 結 論
為實現施工現場安全帽快速高精度檢測,本文在YOLOv3基礎上引入CPANet和CIoU構建安全帽檢測算法YOLO_CPANet_CIoU。首先該網絡為了減少特征損失,有效利用高低層的特征信息,引入了雙向特征融合的特征金字塔網絡PANet,并在檢測網絡中添加了跳躍連接和CBAM注意力機制,形成了新的特征金字塔網絡CPANet,使得淺層的位置信息與深層的語義信息能夠損失較少地在網絡中傳遞,增強網絡對小目標以及有遮擋目標的檢測能力。同時在保持網絡的檢測精度不下降的前提下,將CIoU來代替IoU,優化錨框的回歸并提高模型的收斂能力。經過實驗驗證,本文檢測算法mAP值為91.96%,檢測速度達到21 frame/s,能夠實現復雜施工環境下對安全帽的精確檢測,滿足實時性的要求,比其他檢測算法擁有更高的檢測精度和檢測效果。因此,本文提出的安全帽檢測算法YOLO_CPANet_CIoU具有較大的學術參考價值和工程應用價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
