基于XML的自動化異構系統(tǒng)數據一致性校驗方法
2021-07-11 08:16:26韓圣亞朱韶松
電子設計工程 2021年13期
韓圣亞,嚴 莉,劉 蔭,徐 浩,朱韶松
(國網山東省電力公司信息通信公司,山東濟南 250001)
當前互聯網和大數據技術正朝著縱深方向發(fā)展,分布于不同網絡空間的異構數據源具有典型的分布性和異構性特征[1]。數據的異構性容易導致原始數據在提取、分析、集成和融合過程中的復雜度和難度[2-3]。異構數據處理系統(tǒng)可以有效減少多源異構數據庫之間的差異性[4-5]。異構數據處理的一致性程度,是評價異構數據自動化系統(tǒng)性能的主要指標之一,而且數據融合處理完畢后必須對數據集做一致性檢驗[6-8]。
匯總現有針對多源異構數據一致性校驗的方法,文獻[9]提出通過數據庫模擬轉換的方式來同步源數據,但該方法對異構數據的規(guī)模和復雜程度都有要求,無法處理過于復雜的數據集;文獻[10]利用HTML 語言工具實現對異構數據的復制和校驗,但該方法的適用場景較少,靈活性不足,且對于通信網絡的健壯性要求較高。針對上述問題,文中提出基于XML(可擴展標記語言)語言的數據一致性校驗方法。XML 是一種標準化、結構化的通用計算機語言,有效彌補了傳統(tǒng)HTML 語言的漏洞和不足,且該語言在結構化設計、兼容性、可拓展性等方面具有較大的優(yōu)化空間,能夠更好地對異構數據進行標準化處理,滿足不同用戶的具體使用需求。
1 XML語言的映射關系及數據轉換
XML 語言具有良好的軟件伸縮性、靈活性和可拓展性,對于現有的Web 應用而言,不僅能夠實現數據的兼容和共享,還可以集成不同結構的異構數據庫,拓展數據庫的應用方向和應用場景[11]。XML 工具對傳統(tǒng)的HTML 語言功能進行了深度完善,更便于比對異構數據庫,提取關鍵信息。XML工具的最大優(yōu)勢在于針對異構數據深度交換和標準化,并能夠參與關系型數據庫之間映射關系的轉換。XML 工具的映射關系采用基于模型的驅動方式,如圖1 所示。
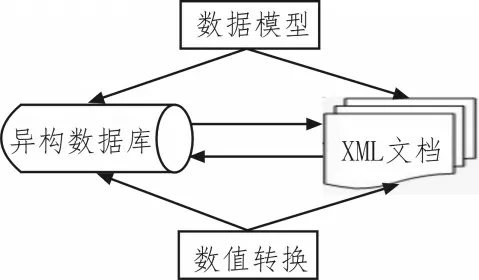
圖1 XML語言與異構數據庫的關系轉換
其中,一種對應關系轉換方式是從關系數據庫的具體模式中識別出映射的具體類型,再基于關系模式重構與其對應的有向圖;另一種映射關系為根據XML 文檔結構,提取具體的文檔和示例[12]。基于XML 語言轉換的異構數據庫表包含可參照、可引用的主鍵列,首先構建多源異構數據庫表的主鍵約束關系,再建立外鍵約束和表的索引約束,確定出兩者之間映射關系的主體框架結構,完成異構數據庫的結構映射與XML 文檔關系映射的融合處理。
在XML 文檔模式與異構關系型數據庫之間的關系轉換前后,需要保持數據表信息的一致,XML 文檔在結構設計上比HTML 更為復雜。因此在功能設計和應用范圍上,為保持XML 文檔信息的完整性和一致性,模型轉換中僅允許定義單個主元素,并以該元素作為異構數據網絡的一個子節(jié)點。利用XML工具文檔與異構性數據庫之間的映射關系,可以實現對異構數據格式的轉換,這是最終異構數據一次性校驗的關鍵環(huán)節(jié),異構數據轉換的主要步驟如下:
Step1:將XML 文檔中的主元素和子元素形成元素集合,元素集合可以準確地描述XML 文檔的結構和類型。
Step2:確定出不同數據庫表之間的映射關系、節(jié)點關系及網絡拓撲結構,并明確數據類型映射與閾值約束映射之間的關系。
Step3:依據映射關系集合生成與異構數據庫對應的XML 格式語言,并按照關系模型找出與異構數據庫表同步變化的主鍵、外鍵、索引等工具。
Step4:按照最終的映射結果將數值轉換過的XML 語句插入數據庫中。只有經過映射關系調整和數值轉換后,自動化異構系統(tǒng)在數據結構、數據類型及檢驗標準上才具有一定的可比性。
2 基于XML 語言的異構數據一致性校驗
XML 語言及多元異構數據庫文檔,均具有良好的數據庫兼容性,且內部允許運行國際上通用的IEC61850 標準。語義模式是一種較為完善的計算機高級指令集,利用語義指令集構造以XML語言為基礎的模型及自動化異構系統(tǒng),以便于在計算機語義層面上相互操作[13]。IEC61850 標準是國際上通用的映射標準,利用該標準構建的XML 語言模型,可以實現在語義空間范圍內的數據交互、數據傳輸及共享。
使用XML 語言工具包解析相應的文本模型,再遍歷異構數據庫中的各個數據表,比較數據類別、數據關系及屬性之間的關系性。對異構數據的一致性校驗包括對副本數據的一致性校驗,核對單表數據的一致性校驗,分析等效數據集與原數據集的符合程度。等效數據集是在數據復制、傳輸過程中形成,隨著時間的推移而產生,因此,數據的復制與拷貝時間指標,也是評價一次性校驗的重要指標之一。首先構建數據一致性校驗函數f如式(1)所示。

其中,A表示精準率,計算公式為a為一致性的數據記錄,b為不一致性的數據記錄;B是召回率指標,計算公式為c為未檢測出不一致的記錄數。根據公式(1)及其指標計算公式得出數據一致性校驗的測量函數f′:

其中,fi表示第i次測量得到的校驗值,ti表示該次校驗所耗費的時間,h表示測量的總次數。使用fi指標分別對副本數據、單表數據做一致性校驗,異構數據的一致性檢驗主要關注數據的內容。對于異構數據的副本而言一致性的校驗項目主要包括校驗實體、元素、及函數等,利用統(tǒng)計特征識別出滿足條件的特定值,使用測量函數校驗數據是否一致[14]。異構數據庫測量工作的前提是完成一致性的校驗,如果校驗完畢并獲取檢測結果,即可以利用測量函數配置數據庫副本數據,并分塊計算數據的差異數值;如果測量后發(fā)現異構數據庫中的A指標值與B指標值過低,表明該異構數據庫的數據一致性較差,使用XML 語義值判斷數據庫表的一致性,使驗證總體效率得到本質地改善。
對于單數據表而言,以XML 語言和判斷函數為基礎,使用XML 程序語句可直接實現對內容復制前后的數據庫表進行對照和判斷[15-16]。獲取單表檢查的結果后,再計算f′的函數值,判斷數據庫表的一致性程度,異構數據庫副本校驗與數據庫表的校驗流程如圖2 所示。

圖2 異構數據的一致性校驗流程
在異構數據校驗中,使用統(tǒng)一化的URI 標識符對整體的資源框架進行描述。在執(zhí)行查詢指令中,利用XML 直接編輯查詢語句,按照模型中匹配的查詢結果,完成對語義的檢索和一致性校驗。
3 實驗與仿真
3.1 實驗環(huán)境搭建
異構源數據節(jié)點采用分布式方式部署,通過200 M 的局域網連接,節(jié)點數據之間的異構性主要從軟件的層面體現,涉及到的網絡集群環(huán)境設置如表1所示。

表1 集群環(huán)境設置
在操作系統(tǒng)和數據庫關系中都能夠顯示出數據庫的異構性,實驗用的操作系統(tǒng)選擇Windows10,實驗用的數據庫類型、數據表數量、記錄數量等信息如表2 所示。
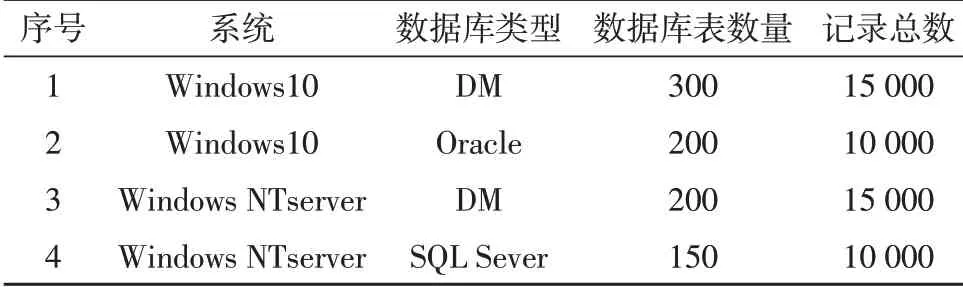
表2 數據環(huán)境設置
3.2 數據的一致性校驗
在200 ms、100 ms 和0 ms 的網絡延遲下,分析不同規(guī)模的異構集群數據一致性恢復耗時,數據的統(tǒng)計結果如圖3 所示(為了使實驗結果更為直觀,引入了文獻[9]和文獻[10]參與對比)。

圖3 不同網絡延遲條件下的數據一致性恢復耗時對比
當通信網絡不存在數據延遲時可以觀測出,隨著數據規(guī)模的增加,3 種不同算法的數據一致性恢復耗時均有所增加,但3 種算法的效率差距較小;當網絡延遲增加到100 ms時,受到網絡延遲的影響數據一致性恢復的耗時有所增長,但文中提出的基于XML 工具的耗時要明顯低于文獻[9]和文獻[10]提出的方法;當網絡延遲進一步增加到200 ms 時,基于XML 語言的數據一致性校驗方法的效率優(yōu)勢更為明顯。
數據庫中全部的數據記錄總數為50 000 條,隨機將全部數據記錄分為10 組,通過網絡在線傳輸,驗證一次性校驗的穩(wěn)定性情況,選取數據波動的均值指標μ和方差指標σ2作為評價標準(μ和σ2的取值越低表明數據校驗的一致性越穩(wěn)定),統(tǒng)計結果如表3 所示。

表3 數據的一致性校驗均值指標效果對比(μ)

表4 數據的一致性校驗方差指標效果對比(σ2)
統(tǒng)計結果顯示,無論是數據一次性校驗的均值指標還是方差指標,相對于兩種傳統(tǒng)的校驗方法,基于XML 工具的數據一次性校驗方法的指標值都更低,具有相對優(yōu)勢。最后在0~200 ms 的網絡延遲范圍內,分析不同的一致性校驗方法在讀寫性能上的差異,網絡延遲設定為0 ms、50 ms、100 ms、150 ms 和200 ms,讀取數據的吞吐率指標值變化如圖4 所示。
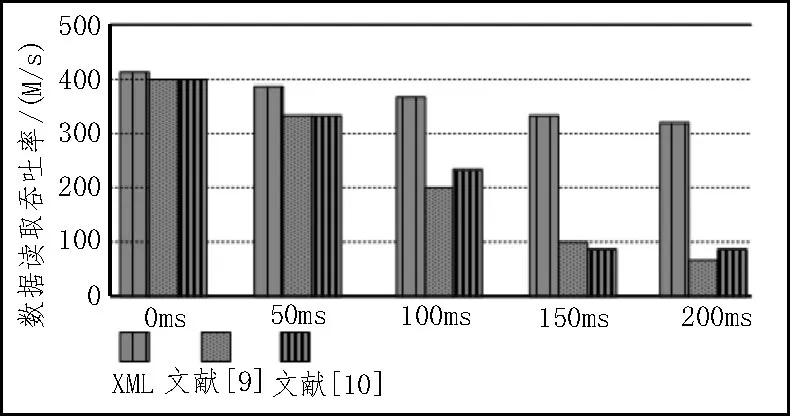
圖4 異構數據讀取的吞吐率指標差異
當網絡延遲較低的條件下,3 種一致性校驗方法的數據讀取吞吐率相差較小;隨著網絡延遲的提升,兩種傳統(tǒng)校驗方法的數據讀取吞吐率衰減過快,會嚴重影響到數據的一致性校驗。在不同網絡延遲條件下數據寫入的吞吐率變化情況如圖5 所示。
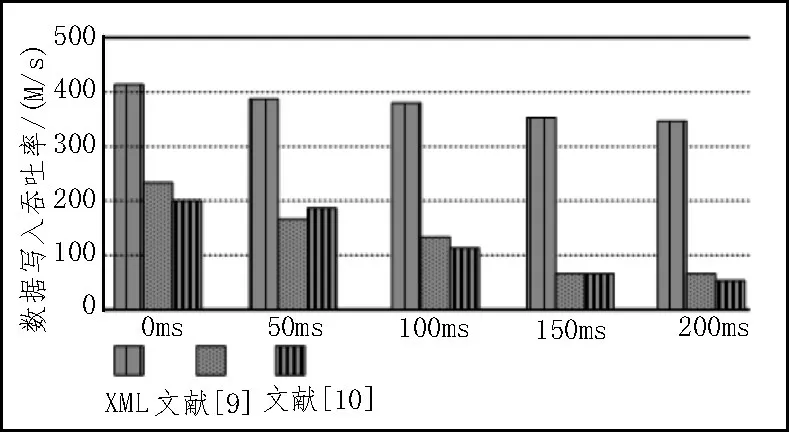
圖5 異構數據寫入的吞吐率指標差異
與數據讀取時的吞吐率變化不同,當網絡延遲為0 ms 的條件下,基于XML 供給的一致性校驗方法并沒有出現性能上的衰減,表明該一致性校驗方法具有更強的數據復制與轉換性能。
4 結束語
數據資源作為最重要的社會資源之一,在社會經濟生活中發(fā)揮出越來越重要的作用。大數據不僅表現為總量上的海量性,還表現為結構上的復雜性,數據一致性檢驗也成為數據集成和融合的關鍵環(huán)節(jié)之一。文中基于XML 語言對異構性數據庫進行一致性檢驗,仿真結果表明提出方法數據一致性校驗效果更好,數據讀寫的能力更強。
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
中醫(yī)眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
財經(2017年2期)2017-03-10 14:35:35
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
