內核網(wǎng)絡堆棧的Go 語言實現(xiàn)與分析
2021-07-11 08:16:10柴艷娜
電子設計工程 2021年13期
關鍵詞:語言
柴艷娜
(長安大學信息與網(wǎng)絡管理處,陜西西安 710064)
計算機是現(xiàn)代日常生活的一種必需品,其高效可靠的運行需要依賴于一套穩(wěn)健無缺陷(Bug-free)的操作系統(tǒng)。現(xiàn)代操作系統(tǒng)都會使用內核(Kernel)來對硬件進行管理,因此,可以說內核的安全穩(wěn)定決定了人們與計算機相處的體驗。內核中的缺陷(Bug)將可能使用戶的應用程序甚至操作系統(tǒng)本身變得不可靠[1]。
大多數(shù)成熟的操作系統(tǒng)內核都是用C 語言實現(xiàn)的,C 語言因其允許高度自由控制內存使用等諸多低級程序操作特性,從而成為最受歡迎的的內核開發(fā)語言[2]。這種高度的自由也會帶來一些代價,比如內存釋放兩遍的錯誤、數(shù)組越界的錯誤以及死鎖[3]。同時它也不能防止數(shù)據(jù)類型的錯誤解析,保證不了類型的安全性。C 語言也無法方便高效地使用現(xiàn)代多核處理器的全部性能。
如果用Go 等高級語言來開發(fā)內核,則可能規(guī)避掉很多上述問題。為此,該文用Go 語言實現(xiàn)了內核網(wǎng)絡堆棧子系統(tǒng),進行了可行性研究,并設計實驗進行驗證。
1 Linux系統(tǒng)網(wǎng)絡堆棧
Linux 的網(wǎng)絡堆棧(Network Stack)是其內核的一個子模塊,如果在源代碼基礎上從零開始編譯Linux內核,可以通過menuconfig 對該模塊進行選擇和修改配置。位于Linux/net 目錄的源代碼是Linux 官方自帶的默認網(wǎng)絡堆棧實現(xiàn)[4]。
Linux 網(wǎng)絡堆棧模型如圖1 所示。

圖1 Linux網(wǎng)絡堆棧
網(wǎng)絡堆棧共分為6 層,每一層都分別執(zhí)行不同的處理任務,對于流入、流出數(shù)據(jù)都會進行處理。最頂層的應用層是操作系統(tǒng)用戶空間(User Space)的一部分,用戶常駐使用的應用程序如瀏覽器、IM 軟件等便工作在這一層。
中間4 層是內核空間(Kernel Space),以內核模塊(Module)形式工作,最底層則是物理層,處理真實的物理媒介數(shù)據(jù)傳送和接收的真實物理設備,如網(wǎng)卡、交換機及路由器等。
Socket 接口層是創(chuàng)建Socket 以及提供API 接口給應用層進行調用的地方,也叫系統(tǒng)調用接口(System Call Interface)[3]。
協(xié)議層則實現(xiàn)各種網(wǎng)絡協(xié)議的解析,是數(shù)據(jù)正確發(fā)送與接收的核心。
網(wǎng)絡設備驅動接口及驅動層,則是提供了操作實際物理設備的手段,同時也提供了相應的監(jiān)控和調優(yōu)手段,方便調整實際物理設備的工作狀態(tài)和性能。
完整地實現(xiàn)一個操作系統(tǒng)內核是一項工作量巨大的工程,得益于Linux內核的良好分層模型,替換某些模塊便可進行研究和對比,因此,該文代之以實現(xiàn)一個內核子系統(tǒng),即網(wǎng)絡堆棧,從而方便下一步的研究工作。
該文用Go 語言實現(xiàn)一個Linux 內核網(wǎng)絡堆棧,用于演示用高級語言開發(fā)內核的相對優(yōu)勢。之所以選擇Go 是因為語言本身自帶優(yōu)秀的CSP 并發(fā)模型(Concurrent Sequential Processes)[5-6]。CSP 模型將 復雜任務解構成更小的、更加可管理的子任務。這些子任務都能被單個進程所處理,進程之間彼此保持通信,共同完成原始的復雜任務。
CSP 模型的目標是幫助程序員設計、實現(xiàn)和驗證復雜的計算機系統(tǒng),十分重要,特別是要設計一個如內核般復雜的軟件。Go 提供了線程安全(Thread-safe)方式的CSP 模型,Go 語言的線程即協(xié)程(Goroutines),同步的通信構造即通道(Channel)[7]。Go 語言運行時自動根據(jù)計算機的物理內核數(shù)量來管理調度協(xié)程。CSP 模型能讓人很容易地使用計算機的所有內核,同時改善代碼的可讀性,進行更簡單的調試和減少產(chǎn)生缺陷。網(wǎng)絡堆棧很自然地可以被劃分成多個子任務去運行,可以充分利用Go 協(xié)程去動態(tài)調度,高效利用所有可用物理內核[8]。
CSP 模型只在垃圾回收語言里有可行性,Go 提供了必要的垃圾回收。Go 是一門強類型語言,能減少一大類錯誤,包括錯誤類型轉換,內存釋放兩遍,對象釋放后再使用等。Go的延遲聲明(Defer Statement)允許在函數(shù)結束時更方便地清理,減少那些疏于管理的資源導致死鎖的可能性。
2 實 現(xiàn)
文中實現(xiàn)的獨立網(wǎng)絡堆棧(下文以項目代號NStack 稱呼之)是建立在Tap 虛擬網(wǎng)卡基礎上,所有基礎網(wǎng)絡協(xié)議,包括以太網(wǎng)(Ethernet)、ARP、IPv4、ICMP、UDP 和TCP,都能被實現(xiàn)。為確保性能不受影響,延遲(Latency)和吞吐量(Through-out)會被測試,并與C 語言實現(xiàn)的網(wǎng)絡堆棧Tapip 進行比較。
2.1 Tap接口
Tap 接口即一種虛擬網(wǎng)絡接口(虛擬網(wǎng)卡),它用軟件來模仿實際硬件。NStack 會將Tap 接口當作正常物理接口一樣讀寫[9]。Tap 接口會關聯(lián)一橋接接口,就好像一個路由器作為主機的一個子網(wǎng)接入其中,這樣可以允許NStack 能使用它自己的MAC 地址和IP 地址,連接到外部網(wǎng)絡。
2.2 協(xié)議實現(xiàn)
NStack 會實現(xiàn)數(shù)據(jù)鏈路層、網(wǎng)絡層和傳輸層的協(xié)議,每一層獨立運行自己的協(xié)議,如圖2 所示。分層模型可以增加并行,在高負載下提供高效服務[10]。

圖2 分層協(xié)議棧
每一個協(xié)議的實現(xiàn)都使用了類似結構的包處理器(Packet Dealer)。IP 包處理器如圖3 所示。包處理器從低層級讀取數(shù)據(jù)包,并通過通道傳輸。通道以箭頭表示在圖2、3中。IP包處理器將數(shù)據(jù)包發(fā)給不同的IP Reader 協(xié)程,如圖3 所示,IP Reader 處理完接收到的數(shù)據(jù)包后,將處理結果轉發(fā)給下一層的包處理器。

圖3 IPv4包處理器
2.3 性能測試
NStack會與Tapip進行性能比較。Tapip是一個C語言開發(fā)的多線程網(wǎng)絡堆棧。這個比較允許評估用高級語言開發(fā)網(wǎng)絡堆棧的優(yōu)點和缺點。兩個網(wǎng)絡堆棧都實現(xiàn)了相似的協(xié)議,都在用戶空間(User Space)操作,都使用Tap 虛擬接口。測試機器是Ubuntu 14.04/Linux 3.13.0,16 GB 內存,Intel Xeon Quad Core Dual Socket 處理器。
2.3.1 延 遲
為測試延遲,將取50 次ping 響應時間的平均值作比較。測試環(huán)境的一臺Linux 虛擬機將運行兩個網(wǎng)絡堆棧,ping 請求從該虛擬機發(fā)出。為判斷堆棧在負載增加情況下的性能,多個ping 會被同時并發(fā)發(fā)送。從1 個增加到1 000 個并發(fā)ping“連接”來模擬網(wǎng)絡堆棧可能接受的負載。為保證對兩個網(wǎng)絡堆棧公平,其他的變量都將保持不變,包括每個ping“連接”發(fā)送的ping 請求數(shù),ICMP 接受緩沖區(qū)大小以及ping請求數(shù)據(jù)包大小。
2.3.2 吞吐量
第二個將要評估的性能指標便是吞吐量。一個堆棧的吞吐量是在給定時間內,它能發(fā)送或接收的數(shù)據(jù)量大小[11]。以下步驟將用來測量兩個堆棧的吞吐量:
1)初始化一個TCP 服務端。
2)初始化一個TCP 客戶端,連接會在local 網(wǎng)絡(localhost)中建立,以排除Tap虛擬網(wǎng)卡導致的開銷。
3)客戶端發(fā)送4 kB 數(shù)據(jù)給服務端。
4)計算堆棧完成上述過程的總時間,該時間和發(fā)送的數(shù)據(jù)量將用來計算吞吐量。
為測量堆棧的相對擴展能力,將會逐步增加客戶端數(shù)來測量性能[12],最大測試到100個并發(fā)客戶端。
有許多預防措施將用于保證吞吐量的準確測量,比如所有可比較的緩沖區(qū)大小都一致[13]。在Tapip 中,每個客戶端和服務端連接都運行在各自的線程里,NStack 類似,但是用的是Go 的協(xié)程而不是線程。另外,也會確保所有連接完成且連接的負載被完整傳輸之后再停止運行網(wǎng)絡堆棧[14-15]。
3 結果分析
NStack 的代碼與Tapip 比較類似,但是從結果來看,性能上包括延遲和吞吐量,相比之下NStack 出色得多。
3.1 準確性
NStack 和Tapip 都能準確地運行協(xié)議,這可以通過分別測試兩個協(xié)議棧與一臺Linux 終端的連接來進行判斷[16-18]。測試中發(fā)現(xiàn)Tapip 有內存泄漏的情況。這是因為Tapip 會開辟緩存區(qū)存儲數(shù)據(jù)包,在某些情況下這些緩存區(qū)不會被釋放或者重復釋放。當緩存區(qū)被重復釋放時,Tapip 會奔潰或者導致異常行為。當緩存區(qū)不會被釋放時,Tapip 會不斷侵占內存,直至系統(tǒng)奔潰。Go 則由于有內置的垃圾回收,可以很好地避免這種情況的發(fā)生。
3.2 代碼比較
雖然很難量化地評估編寫Go 語言相比較C 語言的優(yōu)點,但是一些代碼片段的比較還是可以看出高級語言的某些優(yōu)勢。以下以IP 報文分片重組的處理代碼舉例說明。
當添加分片到重組隊列時,Tapip 的C 語言代碼如下:

Go 可以用協(xié)程處理IP 報文分片,因此它可以簡單的將分片轉發(fā)給對應的協(xié)程處理,同時可以緊接著處理后續(xù)數(shù)據(jù)包。
在清理分片時,C 語言的Tapip 需要顯性地釋放每一個內存緩存區(qū),代碼如下:

而Go 語言只需跟蹤通道即可:
delete(ipr.fragBuf,bufID)
Go 語言的簡潔、友好、可讀,由此可見一斑。
3.3 延遲測試結果
延遲測試結果如圖4 所示。1 個ping 請求時,Tapip 的延遲為0.074 ms,優(yōu)于NStack 的0.234 ms,但是隨著并發(fā)請求的增加,當1 000 個ping 請求時,NStack的延遲為0.717 ms,差不多比Tapip的3.279 ms高4 倍。NStack 在連接數(shù)為600 時,開始領先于Tapip。NStack 延遲的增加是線性的,而Tapip 是指數(shù)型的。NStack 的延遲趨勢是優(yōu)于Tapip 的,因為在請求數(shù)很少時,兩者之間延遲的差距很小,但是在大量并發(fā)ping 時,差異就明顯變大。

圖4 延遲測試結果
3.4 吞吐量測試結果
吞吐量測試結果如圖5 所示。1 個并發(fā)連接時,NStack的吞吐量達到7.3 Mbit/s,對比Tapip的4.6 Mbit/s。當100 個并發(fā)連接時,NStack 達到了284.9 Mbit/s,而Tapip 則只有195 Mbit/s。并且,NStack 的吞吐量增加速度比Tapip 快得多。這表明NStack 可以繼續(xù)在更大量的并發(fā)情況下擴展吞吐量,而Tapip 則很可能處理不了這種負載。
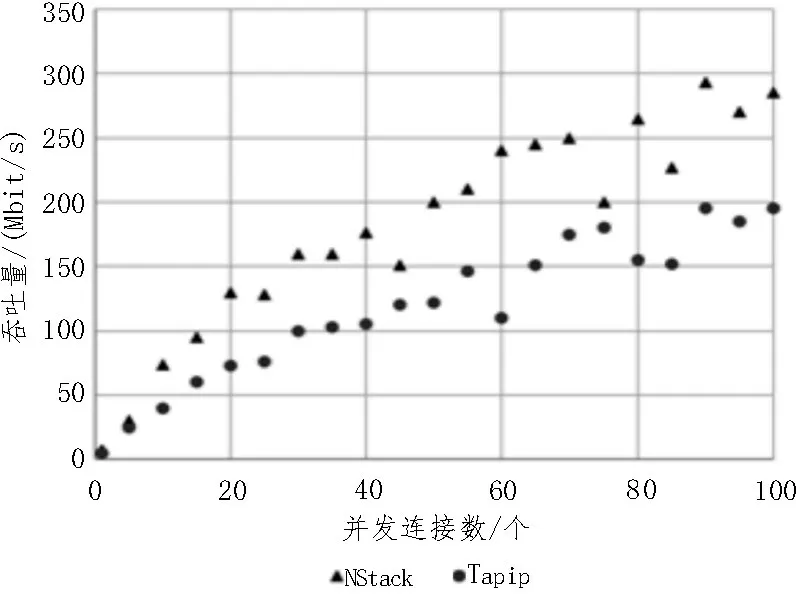
圖5 吞吐量測試結果
4 結束語
由該實驗可以得出,用Go 開發(fā)內核子系統(tǒng)可以改善代碼的可讀性和可靠性,結構模塊清晰,具有良好的并發(fā)能力和穩(wěn)定性,同時又對性能沒有重大不良影響。結果表明,對于內核開發(fā)來說,Go 語言可以是一個重要的C 語言替代者。
猜你喜歡
中華詩詞(2023年8期)2023-02-06 08:51:28
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
新聞傳播(2016年10期)2016-09-26 12:15:04
玉溪師范學院學報(2015年1期)2015-08-22 02:51:58
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
語文知識(2014年10期)2014-02-28 22:00:56
中學生英語高中綜合天地(2009年10期)2009-12-29 00:00:00
