面向大規模MIMO 檢測的粗粒度可重構架構設計
2021-07-09 17:19:20劉陶然李杰
現代計算機 2021年14期
關鍵詞:信號
劉陶然,李杰
(1.上海交通大學電子信息與電氣工程學院,上海 200240;2.上海航天測控通信研究所,上海 201109)
0 引言
大規模MIMO(Multi-Input Multi-Output,MIMO)是當今5G 通信系統的核心技術。大規模MIMO 檢測是最為關鍵的信號處理任務之一。隨著通信技術的發展,其服務標準,質量需求也在不斷提升,這對用于大規模MIMO 算法的硬件架構在面積效率、能量效率和靈活性等方面提出更高的要求。
基于通用處理器的硬件結構擁有較高的靈活性,但是能效比較低。ASIC 為定制化硬件,其高性能是以犧牲靈活性為代價,因而無法滿足大規模MIMO 領域的需求。FPGA 具有較好的硬件可編程能力,這一特性使得其在大規模MIMO 領域得到了廣泛應用[1-3]。然而FPGA 細粒度的實現方式帶來更高的能耗需求。于是,基于粗粒度實現方式的CGRA(Coarse-Grained Recon?figurable Array,CGRA)以其非常高的面積效率、能量效率以及靈活性,成為大規模MIMO 領域硬件架構新的研究方向。
通用的CGRA[4-6]在處理大規模MIMO 算法時是低效的,因為其核心計算單元僅支持標量操作,無法很好地適用于大規模MIMO 的向量類型操作,從而帶來大量的互聯、控制開銷。有研究[7]面向MIMO 算法提出了一種異構的支持增強型向量計算方案的CGRA 架構,但是其全并行的訪存方式以及數據處理策略,使得其僅適用于傳統較小規模(4×4)的MIMO 算法,而非大規模MIMO。并且,現有可重構架構多采用處理器核與CGRA 相結合的指令流控制模式[4,8],雖然能夠實現靈活控制,但是能耗較高。
盡管現有技術通過計算和訪存優化成功提高了吞吐性能,但其并未重視整體硬件資源、互聯和面積開銷的優化。為此本文提出了一種基于數據流驅動的CGRA 架構,能夠以較低的硬件開銷實現有效的數據流控制與數據計算。
1 算法分析及架構優化技術
1.1 大規模MIMO信號檢測算法原理和特點
在具有Nt個發射天線和Nr個接收天線(Nr>Nt)的大規模MIMO 系統中,接收信號可表示為:

大規模MIMO 信號檢測是指利用接收信號y,和信道矩陣H,恢復出發送信號s的過程。將接受信號y與權重矩陣相乘即可得到估計的發射向量

MMSE(Mini-Mental State Examination,MMSE)作為典型的線性檢測算法,定義預處理變量Gram 矩陣G=HHH和yMF=HHy,其中G是正定的埃爾米特矩陣,可以得到:

公式(3)中逆矩陣通常通過迭代估計方式求得。定義矩陣M1,M2,向量v1,v2。表1 總結了常見迭代算法的核心算子及其乘除法計算量:
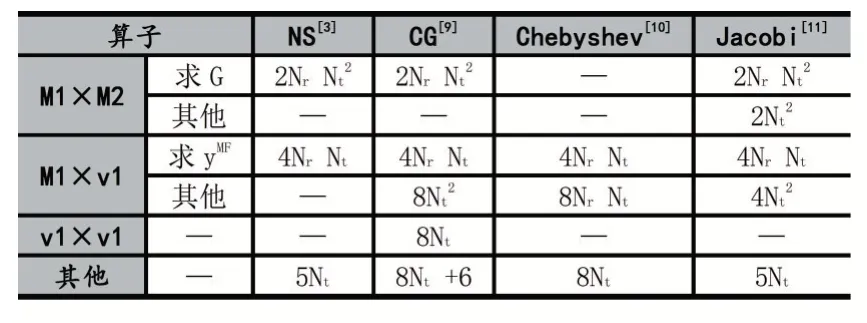
表1 迭代求逆算法一次迭代下完整運算的乘除法計算量
以Nr×Nt=128×8 的天線規模為例,得到矩陣和向量類操作的占比高達99%,特別是算法預處理部分Gram 矩陣和yMF向量的求解平均占比82%。這些算法特點要求硬件設計能夠有效支持矩陣和向量類操作,支持復數的高效計算,并且能夠以較低的硬件開銷支持數據密集型計算。而傳統CGRA 無法同時滿足上述要求,為此本文將從以上算法需求出發,設計基于數據流驅動的CGRA 架構。
1.2 基于反饋機制的數據流通信技術
現有的粗粒度可重構架構多基于指令流驅動,其靈活性高但是會產生較大的能耗和控制開銷。為此本文研究數據流驅動模式,并提出了一種基于反饋機制的通信方式,實現自動化的數據流控制。
圖1 展示了反饋機制的基本單元FBU(Feedback Unit,FBU),其數據傳遞受到單bit 的fb 反饋信號控制。反饋信號產生的原因在于訪存單元和存儲器的交互發生堵塞:當陣列向存儲器發出寫請求但存儲器無法接收數據時,如果數據流沒有停止傳遞新數據,則會造成數據丟失。同理,當讀請求未被響應,PE 就可能會造成計算錯誤。為了解決數據流驅動的通信問題,反饋機制設置FBU 單元,并配合來自于后一級的fb 信號實現自動化控制。
圖1 演示了在兩個FBU 之間執行一個加法操作的數據流變化。在clk0,所有fb 均為0,使得clk1 時刻所有寄存器按順序存儲數據。在clk1,fb 輸入拉高,表示后續FBU 數據發生堵塞,于是clk2 時Reg_post1 數據保持不變,Reg_post0 存儲新數據,同時fb 信號向前傳遞給fb_post。在clk3,fb 輸入仍為1,Reg_pre1 和Reg_post0 保持不變,同時fb_pre 也變為1,使得下個周期Reg_pre0 以及即將輸入進來的數據保持不變。之后的幾個周期,fb 輸入置低,數據依次恢復向后傳遞。可以看到輸出數據未發生丟失,且輸出順序正確。在可重構設計中,部分FBU 會根據配置跳過寄存器,此時fb 也要選擇不過寄存器的支路,保證控制無誤。

圖1 基于反饋機制的數據流通信技術原理
除反饋fb 信號外,數據流驅動模式還包括正向控制信號valid 和last。valid 置高表示數據有效,并用于訪存單元的控制。last 作為循環結束信號,控制執行結束。
1.3 高數據復用率的脈動陣列架構設計
正如1.1 小節中描述,算法預處理中求解Gram 矩陣和yMF向量占據核心計算。而Gram 矩陣由于其自身的共軛對稱性,如果采用傳統的脈動陣列結構[12],不僅數據復用率低,還會造成訪存的浪費,增加能耗開銷。
本文設計了高數據復用率的可重構脈動陣列結構。同時復用了Gram 矩陣的兩個矩陣輸入,并且將Gram 矩陣和yMF的輸入矩陣復用,實現二者并行計算。如圖2 所示,第一列PE 接收來自左側輸入的HH矩陣和來自上方的y向量,經過PE 復數乘和自累加運算,得到yMF向量。輸入矩陣繼續向右和向下傳遞,用于計算Gram 矩陣。其中第二列PE 用于計算Gram 對角線,后三列PE 用于求共軛和計算Gram 下三角。最終經過LS 輸出可以得到完整Gram 矩陣。
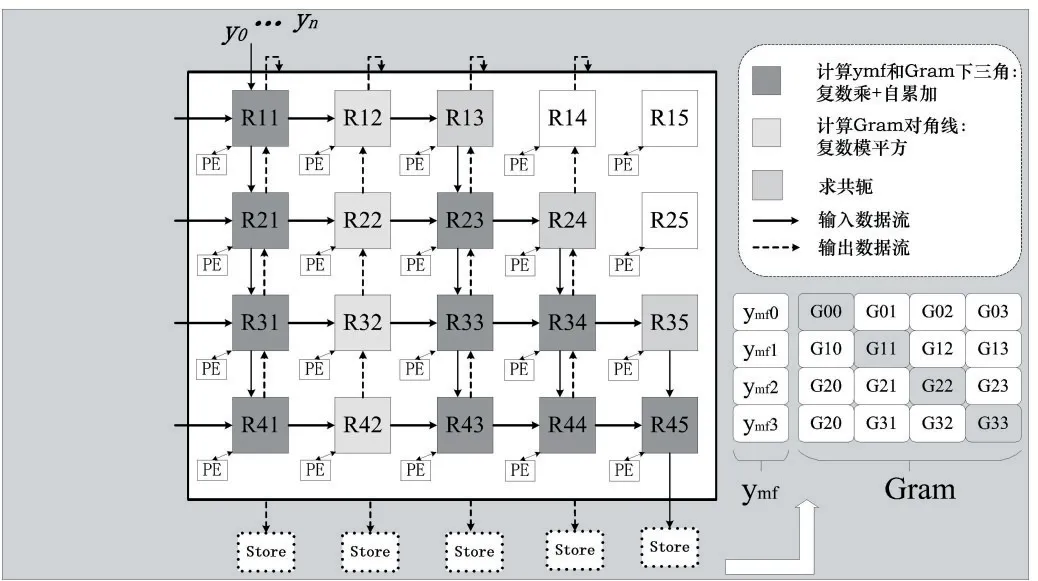
圖2 脈動陣列原理圖
使用PEx,y[t]來表示第x行第y列的PE,在第t個周期的累加結果。假設每個PE的執行周期相等,則第一列輸出表示為:
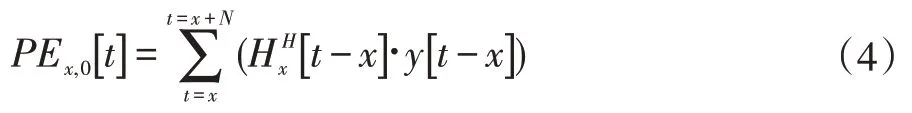
第二列Gram 對角線輸出表示為:

下三角元素輸出表示為:
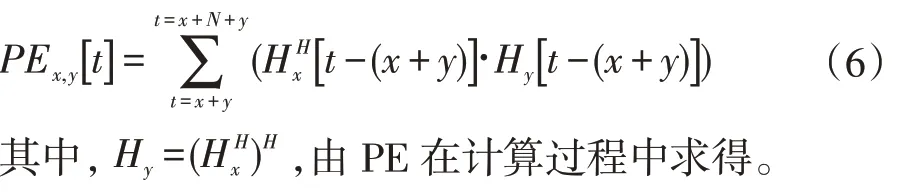
該架構很好地解決了傳統脈動陣列處理MIMO 算法數據復用率低的問題,提升了硬件效率。
2 數據流驅動的CGRA硬件結構設計
系統架構如圖3 所示,由全局控制器、片上存儲以及四個PEA(Processing Elements Array,PEA)組成。其中PEA 采用異構的結構,基本單元為用于計算的PE(Processing Elements,PE)和用于訪存的LS(Load Store,LS),通過Router(路由)形成互聯網絡。
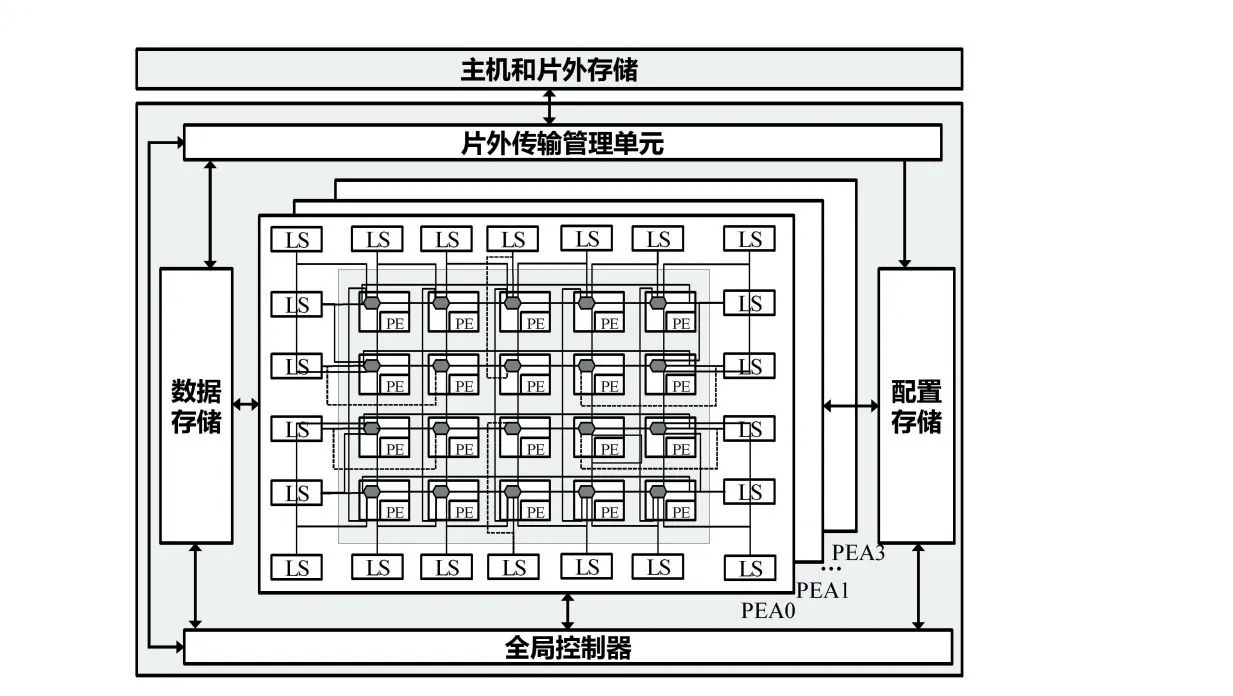
圖3 系統架構圖
2.1 適用于大規模MIMO的通用PE單元
傳統的CGRA 在計算一個復數乘法操作時,至少使用6 個PE[8],每個PE 包括一個乘法器和一個通用ALU,并且需要大量互連開銷。而本文設計的支持復數計算的PE 可以降低一半以上的硬件開銷。
如圖4(a)為本文設計的PE 單元,采用四級流水結構。第一級為輸入寄存器單元,用于接收輸入數據和立即數配置字,并監測操作數是否到齊,產生反饋信號。第二級為乘法單元,支持兩輸入乘法和自相乘兩種模式。第三級由支持16 種操作模式的主ALU 和精簡化的副ALU 組成。最后一級為累加單元和用于定點數處理的移位單元。
圖4(b)即為累加單元,為了支持多種類型脈動陣列累加操作,該設計創新性的支持三種累加模式:乘累加(a×b+c)、自累加(∑(a×b)) 和立即數累加(a×b+imm),自累加模式為研究重點。圖中config(配置)信號用來控制累加模式,并決定自累加的初值是來自In2 輸入還是可配置的立即數。利用valid 控制信號以及異或門邏輯來檢測第一個到達的數據,并開始執行自累加運算。如果數據流發生中斷,有非valid數據到來時,右側選擇器電路可以控制輸出數據保持不變,避免重復累加。由此實現了數據流控制的自累加單元。該可重構PE 單元整體利用1.3 小節提出的基于反饋機制的數據流控制方式,實現了可支持包括實數和復數在內的32 種操作模式。在不損失靈活性的前提下有效降低了硬件開銷。
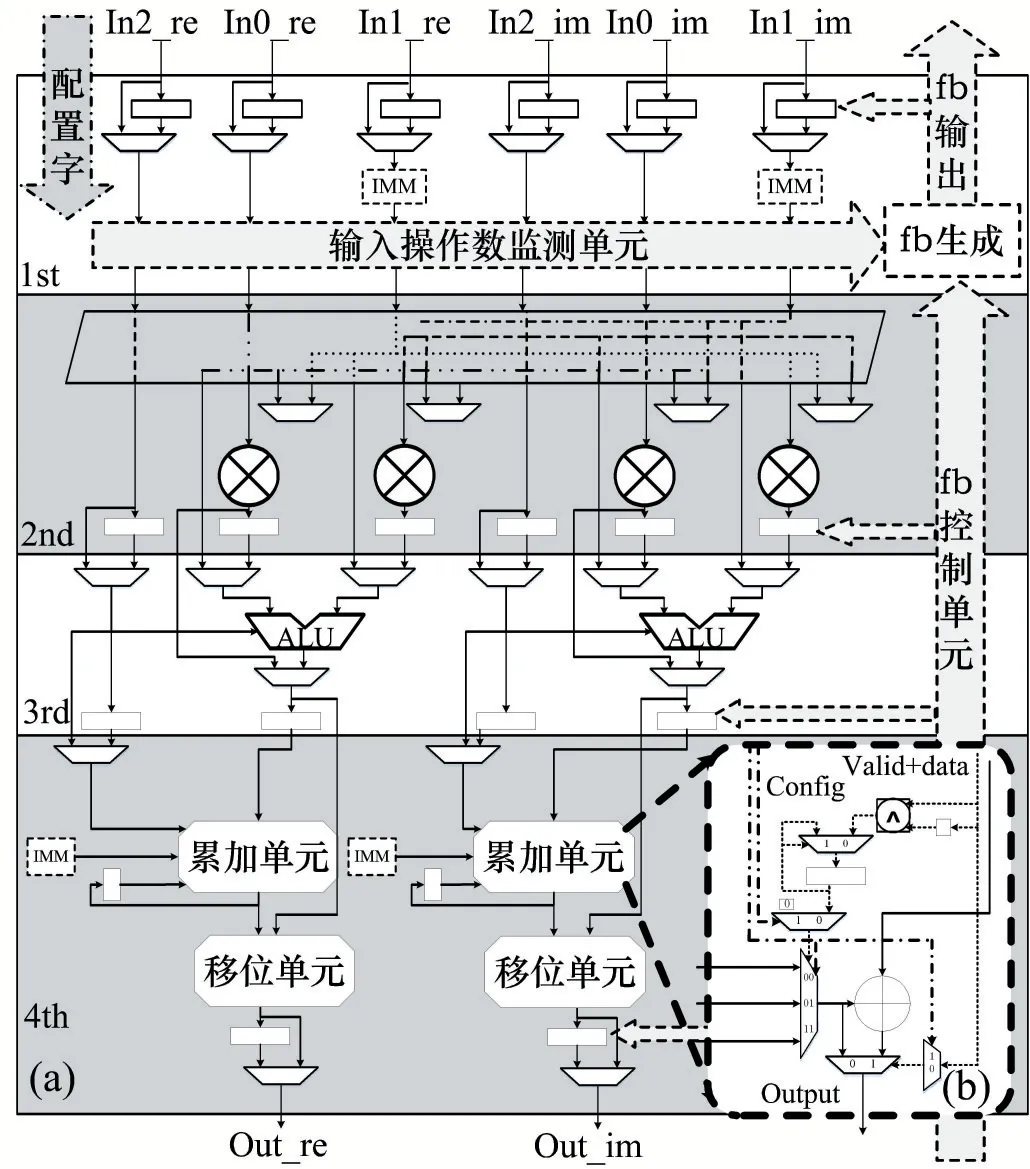
圖4 適用于大規模MIMO的通用PE單元
2.2 數據流驅動的Router單元
為了實現數據傳遞,每個PE 單元都有一個與之互連的Router 單元,以此進行不同PE 之間以及PE 與LS 之間的數據傳遞。如圖5 為本文提出的Router 單元結構,支持與N、E、S、W 四個方向的Router 以及多個LS 的互連,所有數據均為雙向傳遞。如圖5-b,每個傳輸方向都由data 和fb 兩個基本模塊組成,即每個數據流都有對應的fb 信號作為控制,由此實現數據流驅動的高效互連。
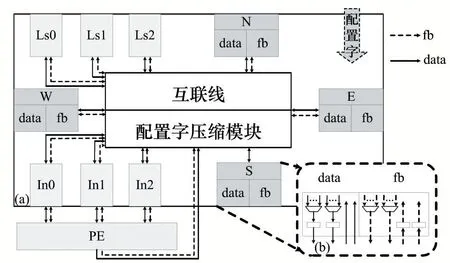
圖5 支持雙向數據流傳遞的Router單元
2.3 支持地址跳變的可編程LS單元
傳統的LS 使用通用的PE 進行地址計算[13],由于大量PE 用于地址計算而不是操作數計算,因此硬件利用率較低。為此,本文LS 采用訪存和計算解耦合的設計,將地址計算轉移至LS 的專用可編程硬件中進行,并結合大規模MIMO 算法特性,創新性的設計了可跳變的地址生成單元。
如圖6 為LS 結構。采用數據流驅動的fb 信號控制。控制邏輯接收fb 和valid 信號,并產生對其他模塊的內部控制信號。預處理/后處理單元主要用于算法中常見的復數求共軛等功能。循環發生器包括循環變量的產生,循環邊界的比較,循環變量的累加單元,并且依據MIMO 算法需求,設計支持兩層循環。存儲交互信號產生模塊主要用于產生與存儲器交互的讀/寫使能。
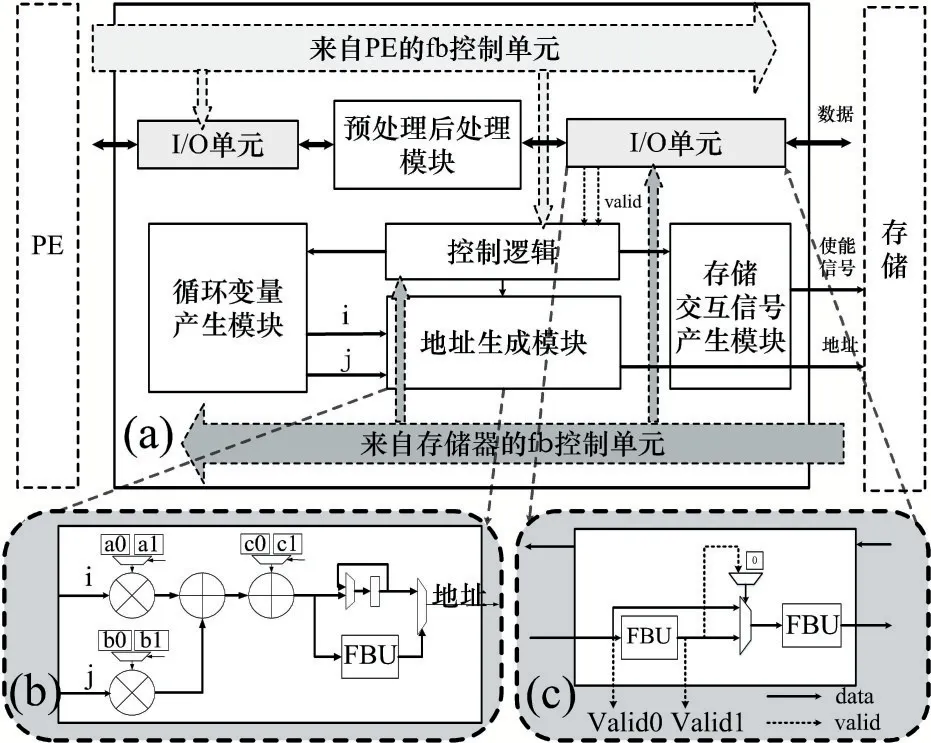
圖6 支持地址跳變的可編程LS單元
圖6(b)描述的地址生成單元可抽象為一個可編程的函數模塊,根據循環變量i、j以及系數a、b、c得到對應的地址輸出:ai+bj+c。地址跳變即根據算法需要自動改變地址系數。例如,圖2 中描述的求Gram 矩陣只計算了下三角部分,在輸出時經過LS 的后處理單元生成共軛數據,利用圖6(c)的I/O 單元中兩個FBU分別存儲原數據和經過后處理的數據,并提供對應的valid 信號。地址生成單元即可在共軛數據有效時,將訪存地址跳變為共軛數據對應的地址,當原下三角數據有效時再跳變回來,由此實現自動化的地址控制,減少訪存,提高數據復用。該結構通過可編程的方式,大大提升了LS 的靈活性。
3 實驗結果
3.1 大規模MIMO核心算子驗證結果
為了驗證結果,本文在40nm CMOS 工藝上進行了設計,并利用1.1 小節針對大規模MIMO 算法的統計結果,選取了該領域典型算法的核心算子進行功能映射。其中PE 利用率定義為:

Nop為算法總的計算量,II為啟動間隔,NPE為陣列的PE 數量。
(1)預處理Gram 矩陣和yMF向量驗證結果
實驗中僅使用一個PEA,采用1.3 小節中脈動陣列的方式進行映射,表2 中總結了相應的執行結果。可以看出,該架構很好地支持了多種規模的MIMO 系統,并且能夠保持82%以上的PE 利用率,具有較高的靈活性和硬件效率。

表2 不同規模MIMO 系統預處理Gram 矩陣和yMF 向量驗證結果
(1)矩陣向量乘法驗證結果
表3 為大規模MIMO 核心算子驗證結果。可以看出,在相應輸入規模下,矩陣乘矩陣和矩陣乘向量都能夠達到100%的PE 利用率,而向量內積操作的PE 利用率達到60%。表4 為本設計與其他研究的對比結果,可以看出本文實現了最高10.22 倍的吞吐性能提升。
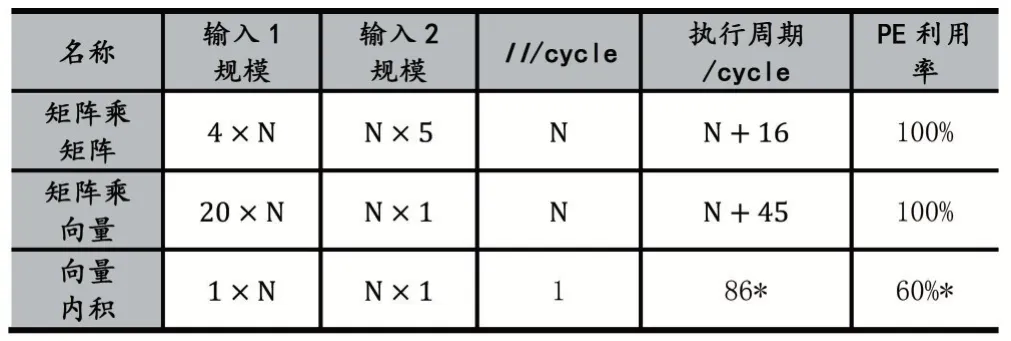
表3 大規模MIMO 核心算子驗證結果
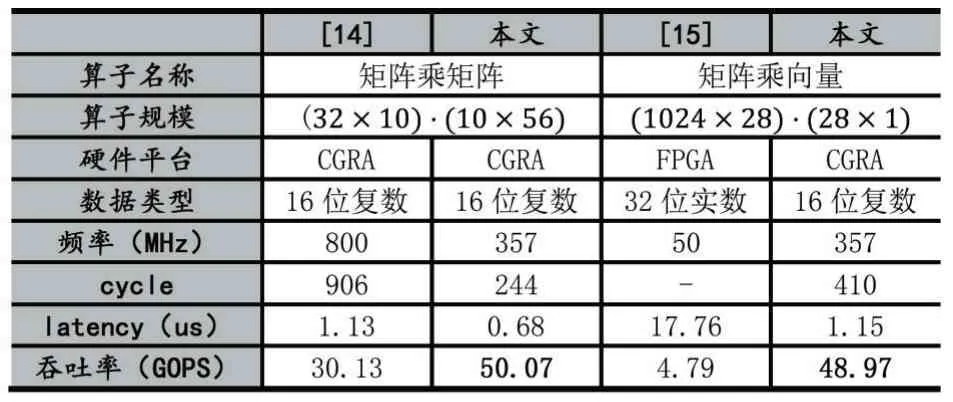
表4 大規模MIMO 核心算子對比結果
3.2 大規模MIMO檢測算法驗證
本文在設計的CGRA 架構上,使用4 塊PEA,驗證了迭代次數為2 的WeJi 算法[1](加權Jacobi)。與其他大規模MIMO 的可重構硬件實現結果對比見表5。

表5 不同大規模MIMO 的可重構硬件實現結果性能對比
為了能夠公平地對比FPGA 實現結果,這里將不同可重構硬件資源開銷歸一化到邏輯門的數量。同時為了公平地與其他CMOS 工藝比較,對不同工藝下的設計進行了如下歸一化[7]:

式中,Tech.代表工藝參數。
對比與已有可重構硬件實現的歸一化結果,本文提出的基于數據流的CGRA 設計在面積效率方面提升了32%~82%,同時取得了2.81 倍的能量效率提升。這主要是因為這些可重構硬件設計采用細粒度的控制結構,和本文提出的CGRA 架構相比需要更多的配置信息來實現復雜的電路控制。而本文設計的CGRA 采用基于反饋機制的數據流驅動方式,這大大簡化了控制邏輯并精簡了PE、LS 單元的硬件結構。同時利用精簡高效的互連方式和路由結構,降低了互連開銷,因此實現了更高的面積效率和能量效率。
4 結語
本文提出了一種數據流提驅動的CGRA 架構來優化面積效率和能效。通過基于反饋機制的數據流通信技術,極大降低了控制成本,減少了面積開銷。同時,本文對提出的面向大規模MIMO 算法的CGRA 架構進行了設計實現,并對計算單元、訪存單元和路由單元分別進行了優化設計。硬件實現的結果顯示,與當前MI?MO 領域的可重構硬件設計相比,本文的性能取得了32%~82%的面積效率提升,同時取得了2.81 倍的能量效率提升。今后研究將進一步優化電路,提高系統頻率,同時擴展算法的驗證。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
