基于近鄰傳播算法的負(fù)荷不良數(shù)據(jù)辨識(shí)
2021-07-08 02:33:30李常剛
山東電力技術(shù) 2021年6期
關(guān)鍵詞:方法
李 山,楊 冬,蔣 哲,周 寧,房 俏,李常剛
(1.國(guó)網(wǎng)山東省電力公司電力科學(xué)研究院,山東 濟(jì)南 250003;2.山東大學(xué)電氣工程學(xué)院,山東 濟(jì)南 250061)
0 引言
狀態(tài)估計(jì)是電力調(diào)度系統(tǒng)中的一項(xiàng)重要的基礎(chǔ)功能,其通過(guò)數(shù)據(jù)采集和監(jiān)測(cè)系統(tǒng)(Supervisory Control and Data Acquisition,SCADA)和廣域量測(cè)系統(tǒng)(Wide Area Measurement System,WAMS)所收集到的電氣量量測(cè)數(shù)據(jù)估計(jì)電網(wǎng)的運(yùn)行狀態(tài)[1]。由于電力系統(tǒng)規(guī)模龐大,所采集到的數(shù)據(jù)復(fù)雜多樣,在數(shù)據(jù)的采集、傳輸、處理等各個(gè)環(huán)節(jié)中,數(shù)據(jù)均可能出現(xiàn)偏差或錯(cuò)誤,造成狀態(tài)估計(jì)的結(jié)果不準(zhǔn)確。有較大偏差或錯(cuò)誤的量測(cè)數(shù)據(jù)稱為不良數(shù)據(jù),為提高狀態(tài)估計(jì)的準(zhǔn)確度,需要對(duì)不良數(shù)據(jù)進(jìn)行辨識(shí),進(jìn)一步采取相關(guān)措施對(duì)其處理。
不良數(shù)據(jù)的辨識(shí)方法主要分為兩大類,傳統(tǒng)的不良數(shù)據(jù)檢測(cè)辨識(shí)方法和基于數(shù)據(jù)挖掘的不良數(shù)據(jù)檢測(cè)辨識(shí)方法。傳統(tǒng)的不良數(shù)據(jù)檢測(cè)法包括有標(biāo)準(zhǔn)殘差檢測(cè)法、量測(cè)量突變檢測(cè)法、混合檢測(cè)法、量測(cè)量相關(guān)性檢測(cè)法等[2];傳統(tǒng)的不良數(shù)據(jù)辨識(shí)法主要包括有殘差搜索辨識(shí)法、零殘差辨識(shí)法等[3]。傳統(tǒng)不良數(shù)據(jù)檢測(cè)與辨識(shí)方法大部分是基于殘差計(jì)算進(jìn)行的,通常以標(biāo)準(zhǔn)殘差或者加權(quán)殘差作為特征值,通過(guò)概率論的假設(shè)檢驗(yàn),對(duì)量測(cè)結(jié)果進(jìn)行邏輯判斷,進(jìn)而對(duì)不良數(shù)據(jù)進(jìn)行辨識(shí)。傳統(tǒng)以殘差為基礎(chǔ)的方法容易出現(xiàn)殘差污染和殘差淹沒(méi)現(xiàn)象,造成漏檢或誤檢,降低了不良數(shù)據(jù)的辨識(shí)準(zhǔn)確度。許多學(xué)者為了克服傳統(tǒng)辨識(shí)方法的缺點(diǎn),采取了多種手段或方法對(duì)傳統(tǒng)基于殘差的辨識(shí)方法進(jìn)行了改進(jìn),如估計(jì)辨識(shí)法、量測(cè)系統(tǒng)誤差方差估計(jì)辨識(shí)法[4]、假設(shè)檢驗(yàn)辨識(shí)法、基于新息差向量辨識(shí)不良數(shù)據(jù)的方法、基于模糊動(dòng)態(tài)的不良數(shù)據(jù)辨識(shí)法等[5]。這些方法在計(jì)算速度、檢測(cè)與辨識(shí)精度等方面取得了較大進(jìn)步,一定程度上避免了殘差污染和殘差淹沒(méi)現(xiàn)象。
機(jī)器學(xué)習(xí)與數(shù)據(jù)挖掘技術(shù)的進(jìn)步,為不良數(shù)據(jù)檢測(cè)辨識(shí)提供了新的研究思路和方法。近年來(lái),部分學(xué)者提出了一些基于數(shù)據(jù)挖掘的不良數(shù)據(jù)辨識(shí)方法,如基于間隙統(tǒng)計(jì)算法(Gap Statistic Algorithm,GSA)的不良數(shù)據(jù)辨識(shí)方法[6]、基于核學(xué)習(xí)的不良數(shù)據(jù)檢測(cè)與辨識(shí)方法[7]、基于模糊聚類算法的不良數(shù)據(jù)辨識(shí)方法[8]等。基于數(shù)據(jù)挖掘的不良數(shù)據(jù)辨識(shí)方法能夠避免殘差污染和殘差淹沒(méi)現(xiàn)象,準(zhǔn)確度較高,計(jì)算速度快,是學(xué)者們研究的重點(diǎn)方向。
為提高狀態(tài)估計(jì)的準(zhǔn)確度,提出了一種基于近鄰傳播(Affinity Propagation,AP)算法的負(fù)荷不良數(shù)據(jù)辨識(shí)方法,并以某地區(qū)實(shí)際負(fù)荷采樣數(shù)據(jù)為算例,驗(yàn)證了所提不良數(shù)據(jù)辨識(shí)方法的有效性。
1 AP算法
1.1 AP算法介紹
AP 算法[9]基于數(shù)據(jù)點(diǎn)間的“信息傳遞”進(jìn)行聚類。將全部樣本看作網(wǎng)絡(luò)的節(jié)點(diǎn),然后通過(guò)網(wǎng)絡(luò)中各條邊的消息傳遞計(jì)算出各樣本的聚類中心。聚類過(guò)程中,共有兩種消息在各節(jié)點(diǎn)間傳遞,分別是吸引度消息和歸屬度消息。AP 算法通過(guò)迭代過(guò)程不斷更新每一個(gè)點(diǎn)的吸引度和歸屬度值,直到產(chǎn)生m個(gè)高質(zhì)量的聚類中心。在得到聚類中心后,將其余的數(shù)據(jù)點(diǎn)按距離分配到相應(yīng)的聚類中。與K?means 聚類算法或k 中心點(diǎn)算法等其他有監(jiān)督聚類算法不同,AP 算法是一種半監(jiān)督聚類算法,在運(yùn)行算法之前不需要指定聚類中心個(gè)數(shù)。AP 算法尋找的聚類中心點(diǎn)是數(shù)據(jù)集合中實(shí)際存在的點(diǎn),作為每類的代表。
假設(shè)數(shù)據(jù)樣本集為{x1,x2,…,xn},為刻畫(huà)數(shù)據(jù)樣本之間的相似度,采用歐氏距離定義相似度矩陣S的元素為
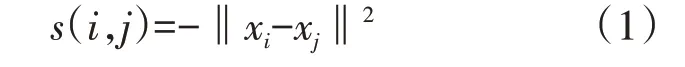
顯然,當(dāng)且僅當(dāng)xi與xj的相似性程度大于xi與xk的相似性時(shí),s(i,j)>s(i,k)。
AP 算法進(jìn)行交替兩個(gè)消息傳遞的步驟,以更新兩個(gè)矩陣。
吸引度矩陣R的更新公式為
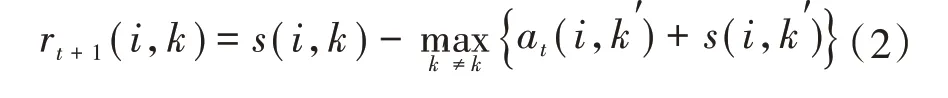
式中:t為迭代次數(shù);s(i,k)為數(shù)據(jù)對(duì)象k和i之間的相似度;at(i,k′)為對(duì)象i與對(duì)象k′之間的歸屬度,rt+1(i,k)為吸引度,描述了對(duì)象k適合作為對(duì)象i的聚類中心的程度,表示的是從i到k的消息。
歸屬度矩陣A的更新公式為:
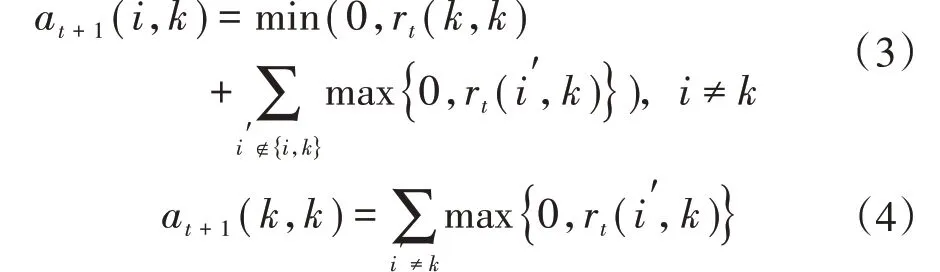
式中:a(i,k)為歸屬度,描述了數(shù)據(jù)對(duì)象i選擇數(shù)據(jù)對(duì)象k作為其聚類中心的適合程度,表示從k到i的消息。
為防止數(shù)據(jù)出現(xiàn)振蕩,AP 算法在更新兩個(gè)矩陣時(shí)引入了衰減系數(shù)λ,λ是一個(gè)取值在0 到1 之間的實(shí)數(shù)。在加入衰減系數(shù)后,吸引度和歸屬度矩陣的第t+1次的迭代值為:
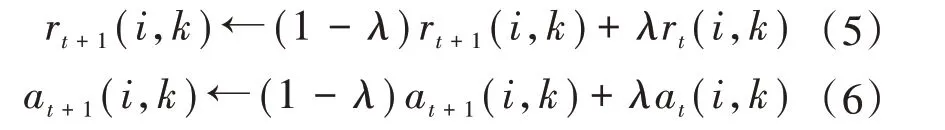
與K?means 聚類算法或k 中心點(diǎn)算法等其他有監(jiān)督聚類算法相比,AP算法的優(yōu)點(diǎn)為:
1)無(wú)須人為指定初始代表點(diǎn)集合。AP 算法在初始化時(shí),將所有數(shù)據(jù)對(duì)象都作為候選的聚類中心。因此,無(wú)須人為指定初始代表點(diǎn)集合。在提高聚類性能的同時(shí),也方便了人們的使用。
2)無(wú)須將數(shù)據(jù)對(duì)象表示成特征向量的形式,只需獲取數(shù)據(jù)對(duì)象之間的相似度,即可對(duì)數(shù)據(jù)對(duì)象進(jìn)行聚類,拓展了聚類方法的應(yīng)用范圍。
3)聚類中心個(gè)數(shù)的選擇更加合理,且無(wú)需人為指定。在處理無(wú)法確定中心數(shù)目的情況時(shí),能夠更加靈活方便。
1.2 算法步驟
AP算法的迭代步驟如圖1所示,具體為:
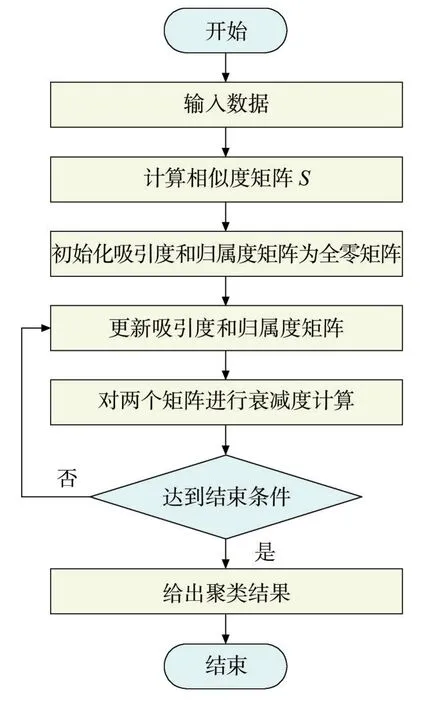
圖1 AP算法迭代步驟
1)計(jì)算相似度矩陣,初始化吸引度和歸屬度矩陣為全零矩陣;
2)根據(jù)式(2)更新吸引度矩陣;
3)根據(jù)式(3)和式(4)更新歸屬度矩陣;
4)根據(jù)式(5)和式(6)對(duì)兩個(gè)矩陣進(jìn)行衰減計(jì)算;
5)按照步驟2)、3)、4)進(jìn)行迭代,直到達(dá)到結(jié)束條件,退出計(jì)算。
迭代的結(jié)束條件為:決策經(jīng)過(guò)若干次迭代之后保持不變;算法執(zhí)行超過(guò)設(shè)定的迭代次數(shù);某一小區(qū)域內(nèi)的關(guān)于樣本點(diǎn)的決策經(jīng)過(guò)數(shù)次迭代后保持不變。當(dāng)滿足其中一個(gè)條件時(shí),迭代結(jié)束。
2 基于AP算法的負(fù)荷不良數(shù)據(jù)辨識(shí)
對(duì)歷史負(fù)荷數(shù)據(jù)和實(shí)時(shí)負(fù)荷數(shù)據(jù)的分析有助于供電部門(mén)掌握負(fù)荷使用情況,在負(fù)荷預(yù)測(cè)、用戶行為分析等方面具有重要作用[10],因此需要保證負(fù)荷數(shù)據(jù)的準(zhǔn)確性。電力負(fù)荷曲線具有相似性和平滑性兩個(gè)重要特征[11],這兩個(gè)特征通常也分別稱為橫向相似性和縱向相似性。對(duì)一個(gè)負(fù)荷區(qū)域來(lái)說(shuō),不同日期負(fù)荷曲線的波峰和波谷大體在同一個(gè)時(shí)間段,相鄰幾天內(nèi)同一個(gè)時(shí)間段內(nèi)的負(fù)荷量也相差不大,曲線的形狀也非常相似,這就是橫向相似性。平滑性即縱向相似性是指在同一天內(nèi),相鄰采樣時(shí)間點(diǎn)內(nèi)的負(fù)荷過(guò)度會(huì)比較平滑,負(fù)荷不會(huì)有較大的突變。不良數(shù)據(jù)的存在會(huì)明顯破壞了日負(fù)荷曲線的相似性和平滑性特征,據(jù)此我們可以檢測(cè)出不良數(shù)據(jù)。
不良數(shù)據(jù)的辨識(shí)本質(zhì)上是一個(gè)分類問(wèn)題,對(duì)不良數(shù)據(jù)的辨識(shí)實(shí)際上就是對(duì)含有不良數(shù)據(jù)的日負(fù)荷曲線的辨識(shí),將不良數(shù)據(jù)和正常數(shù)據(jù)合理分類。不良數(shù)據(jù)辨識(shí)的實(shí)質(zhì)就是將含有不良數(shù)據(jù)的不正常曲線模式同正常的曲線模式分開(kāi)。根據(jù)橫向相似性和縱向相似性,首先定義兩個(gè)指標(biāo):
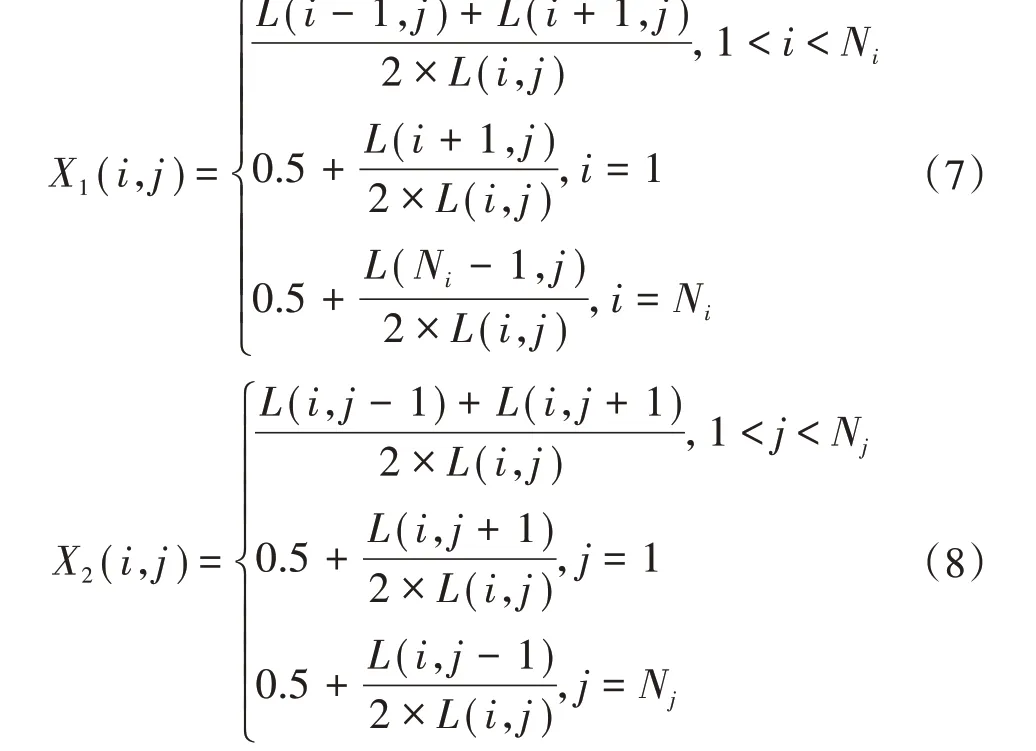
式中:L(i,j)為第i天第j個(gè)時(shí)刻的負(fù)荷量;Ni為總天數(shù);Nj為一天中的時(shí)刻數(shù);X1(i,j)和X2(i,j)分別為橫向相似性和縱向相似性,不良數(shù)據(jù)的出現(xiàn)會(huì)使這兩個(gè)指標(biāo)發(fā)生突變。為了消除不良數(shù)據(jù)對(duì)鄰近數(shù)據(jù)的影響,根據(jù)這兩個(gè)指標(biāo)定義了兩個(gè)特征值,作為分類依據(jù)。兩個(gè)特征值為:
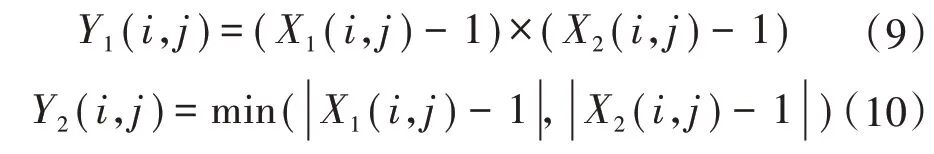
式中:Y1(i,j)被稱為乘積特征值;Y2(i,j)為最小特征值。利用AP 算法,便可以按照這兩個(gè)特征進(jìn)行聚類分析,辨識(shí)不良數(shù)據(jù),并且可以準(zhǔn)確找出不良數(shù)據(jù)出現(xiàn)的位置。
3 算例分析
為驗(yàn)證所提不良數(shù)據(jù)辨識(shí)方法的準(zhǔn)確性和實(shí)用性,以某地區(qū)供電部門(mén)的10 天共960 個(gè)采樣點(diǎn)的實(shí)測(cè)負(fù)荷數(shù)據(jù)為研究對(duì)象進(jìn)行算例分析。表1 給出了該地區(qū)1 天當(dāng)中00:00—24:00 共96 個(gè)采樣點(diǎn)的詳細(xì)負(fù)荷數(shù)據(jù),負(fù)荷曲線如圖2所示。
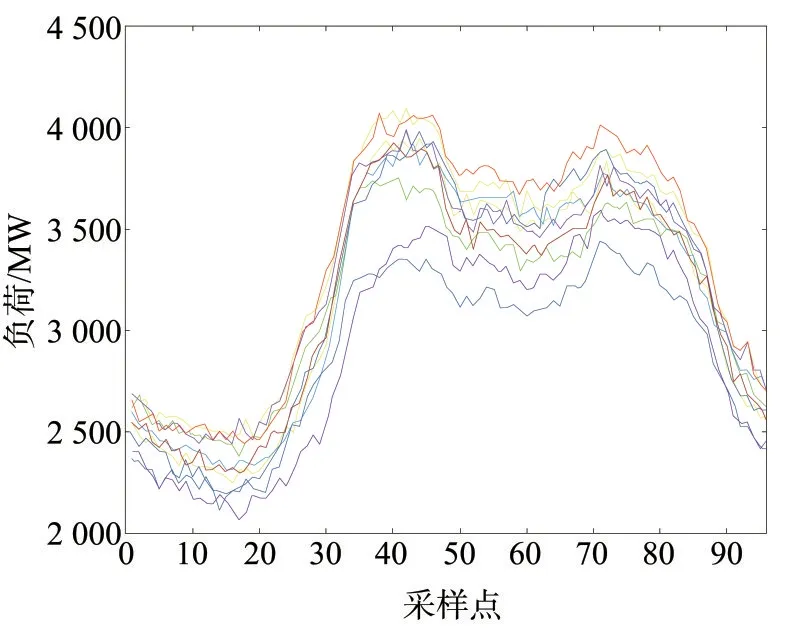
圖2 某地區(qū)日負(fù)荷曲線
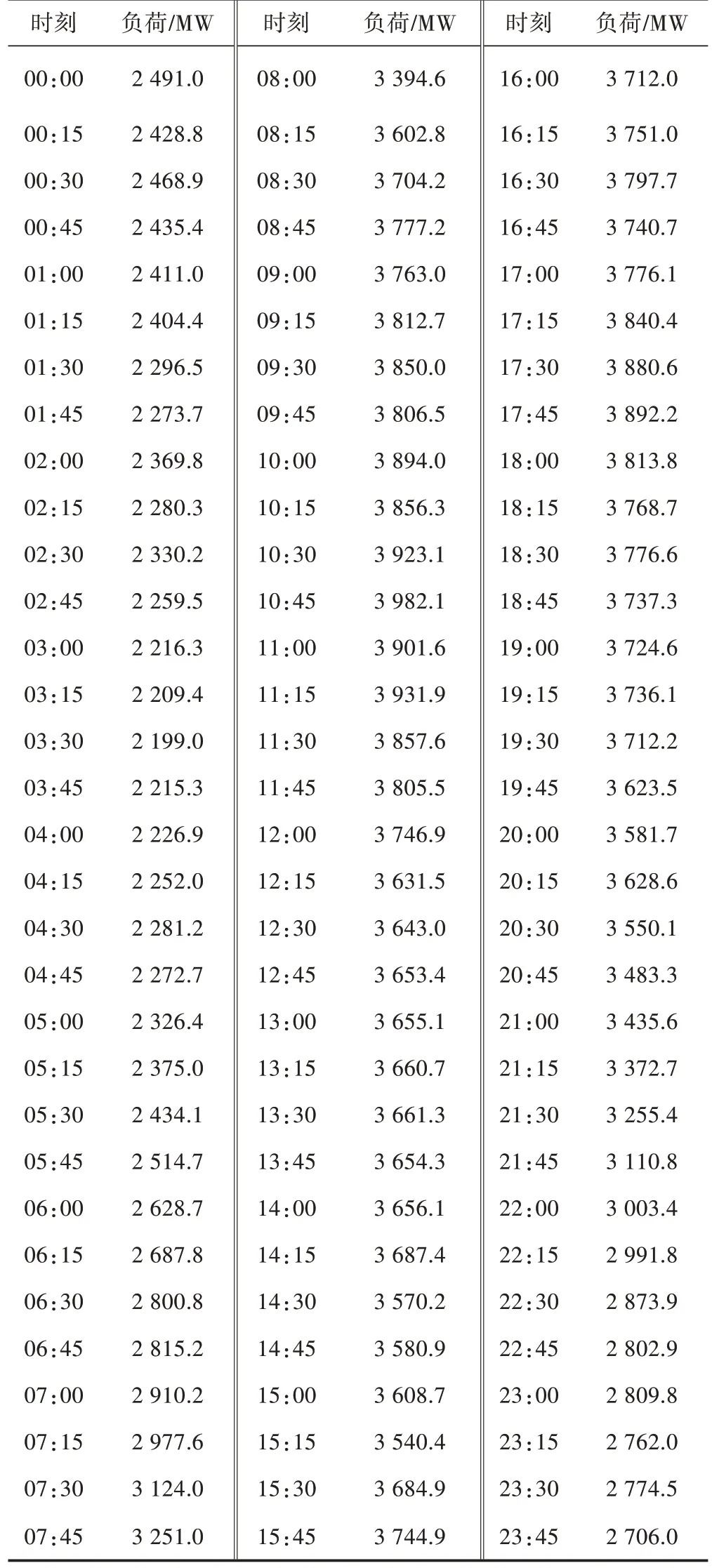
表1 某地區(qū)1天內(nèi)96點(diǎn)負(fù)荷數(shù)據(jù)
原始的負(fù)荷數(shù)據(jù)不包含不良數(shù)據(jù),為了驗(yàn)證所提方法的有效性,對(duì)原始數(shù)據(jù)進(jìn)行了改造。AP 算法中的衰減系數(shù)設(shè)為0.5,最大迭代次數(shù)設(shè)為100 次。在負(fù)荷數(shù)據(jù)中加入一個(gè)不良數(shù)據(jù),進(jìn)行不良數(shù)據(jù)辨識(shí)。首先求取負(fù)荷的乘積特征和最小特征,對(duì)其進(jìn)行聚類,聚類結(jié)果如圖3 所示。圖3 中,聚類1 表示的是不良數(shù)據(jù),聚類2 是正常數(shù)據(jù),通過(guò)該聚類方法,可以準(zhǔn)確地辨識(shí)出不良數(shù)據(jù),不良數(shù)據(jù)和正常數(shù)據(jù)具有明顯區(qū)別。

圖3 單一不良數(shù)據(jù)下AP算法聚類結(jié)果
在原始數(shù)據(jù)中加入3 個(gè)不良數(shù)據(jù),進(jìn)行多不良數(shù)據(jù)辨識(shí),并與K?means 聚類進(jìn)行比較,由于在辨識(shí)之前無(wú)法知道聚類個(gè)數(shù),在使用K?means 聚類算法時(shí)將聚類中心數(shù)目設(shè)為2,希望能將數(shù)據(jù)分為不良數(shù)據(jù)和正常數(shù)據(jù)兩類。圖4 為本文所提方法的聚類結(jié)果,圖5 為K?means 聚類的聚類結(jié)果,本文所提方法將數(shù)據(jù)分為了3 類,能夠準(zhǔn)確識(shí)別出不良數(shù)據(jù),而K?means聚類只識(shí)別出一個(gè)不良數(shù)據(jù),誤將另外兩個(gè)不良數(shù)據(jù)納入到了正常數(shù)據(jù)中,發(fā)生了誤判。因此,本文所提方法在不確定不良數(shù)據(jù)聚類個(gè)數(shù)的情況下,具有更高的識(shí)別度。
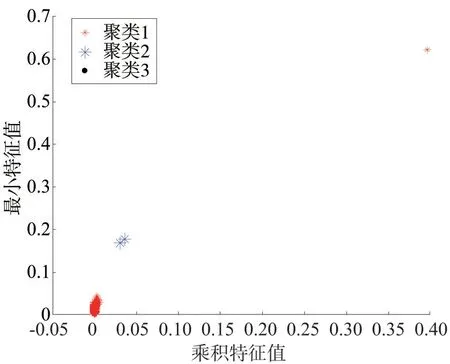
圖4 多不良數(shù)據(jù)下AP算法聚類結(jié)果
圖5 多不良數(shù)據(jù)下K-means算法聚類結(jié)果
4 結(jié)語(yǔ)
提出了一種基于AP 算法的負(fù)荷不良數(shù)據(jù)辨識(shí)方法。與傳統(tǒng)半監(jiān)督聚類方法相比,AP 算法具有準(zhǔn)確度高、無(wú)須指定聚類中心數(shù)目等優(yōu)點(diǎn),適合進(jìn)行不良數(shù)據(jù)辨識(shí)。基于負(fù)荷相似性和平滑性兩個(gè)特征,定義了乘積特征值和最小特征值作為分類依據(jù),可以提高分類準(zhǔn)確度。某地區(qū)的實(shí)際負(fù)荷采樣數(shù)據(jù)算例表明,本文所提方法在單一不良數(shù)據(jù)、多不良數(shù)據(jù)情況下,均具有較高的辨識(shí)度,彌補(bǔ)了傳統(tǒng)半監(jiān)督聚類方法的不足。此外,所采用的AP 算法也可以推廣到其他類型的不良數(shù)據(jù)辨識(shí)上,這是下一步的研究方向。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫(huà)報(bào)(2021年2期)2021-05-25 02:07:46
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫(huà)報(bào)(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
