基于多維度匹配的知識庫問答實體鏈接
2021-07-03 03:51:36張森張攀
現(xiàn)代計算機 2021年12期
關鍵詞:實驗
張森,張攀
(1.四川大學計算機學院,成都610065;2.四川大學視覺合成圖形圖像技術國家級重點實驗室,成都610065)
0 引言
近年來,隨著知識圖譜(Knowledge Graph,KG)技術的不斷發(fā)展,其易擴展、表達友好等特性越來越被認可。KG 常見的知識組織形式有RDF(Resource Description Framework)、RDFS(Resource Description Framework Schema)和OWL(Web Ontology Language)。不同的知識組織形式也催生出了不同的KG,其中常見的有Freebase[1]、WikiData[2]、DBpedia[3]和YAGO[4]等。KG 作為一個知識庫被廣泛的應用在需要先驗知識的智能系統(tǒng)之中,例如:用戶興趣推薦系統(tǒng)、精準搜索和問答系統(tǒng)。其中問答系統(tǒng)就是利用自然語言處理技術對問句進行語義與語法分析,理解用戶問句中表達的含義,隨后結(jié)合知識庫搜索出用戶想要的答案。
常見的KG 大多以RDF 三元組的形式表示知識,三元組通常可以表示為如下形式:<eh,r,et>其中eh代表頭實體,r表示實體之間的關系,et代表尾實體。而基于知識庫問答系統(tǒng)的工作原理為首先分析確定問句中的eh和r,然后利用正確的eh和r到知識庫中查詢到對應的et。在自然語言式的問句中得到eh的過程稱之為實體對齊,解析出r的過程稱之為關系檢測或者關系抽取。
實體對齊主要分為兩部分:命名實體識別(Named Entity Recognition,NER)和實體鏈接(Entity Linking)。命名實體識別主要將問句中的實體名(通常包含人名、地名、機構(gòu)名等)標注出來。通常短文本的NER 效果很好,因此實體對齊重點往往聚焦于實體鏈接部分。
在KG 中可能存在多個實體名字相同或者相似的情況,但是每個實體有唯一的ID 進行辨識。其中實體名相似或相同的實體集合稱之為實體候選集,而實體鏈接就是從實體候選集中選出正確的實體。
1 相關工作
實體鏈接本質(zhì)上是一個實體消歧的過程,實體消歧根據(jù)不同類型的數(shù)據(jù)有不同的消歧的手段。在面向單條短問句的實體消歧過程中,常見的方法主要有兩種:基于實體顯著性和基于實體上下文相似度[5]。實體顯著性描述的是實體固有的屬性,通過對實體顯著性的統(tǒng)計從候選集篩選出顯著性最高的實體從而完成消歧的過程。通常實體顯著性的各種指標均為手工定義的規(guī)則或范式,因此不具有泛化性,并且顯著性特征定義的好壞會直接影響實體消歧的結(jié)果。相比顯著性統(tǒng)計,上下文相似度的方法具有了更大的靈活性并且考慮到了實體語義層面的含義。常見的上下文相似度方法有:分類法[6]、聚類法[7]、主題法[8]、概率語言模型法[9]。隨著深度學習的興起,上下文相似度出現(xiàn)了新的度量方式[10-15],通常該類方法將文本嵌入到一個低維的分布式向量空間,運用不同的網(wǎng)絡模型提取語義特征,根據(jù)語義相似度最終完成實體消歧。
雖然實體鏈接方法眾多,但是針對簡單問句的實體鏈接仍然具有很大的挑戰(zhàn)性,其主要的困難主要包含以下幾點:
(1)簡單問句中實體名稱不規(guī)范,可能出現(xiàn)縮寫、別名以及拼寫錯誤等情況;
(2)簡單問句上下文不豐富,對實體消歧起到的作用微小甚至無用;
(3)知識庫中實體的描述信息不充分甚至缺乏,導致比對候選實體上下文相似度無法進行。
針對上述問題,本文提出了一種多維度匹配方法。該方法是實體顯著性與深度學習的組合。其中,文本維度匹配較大程度保證實體名不規(guī)范等情況;統(tǒng)計維度匹配能在不需要問句上下文的情況下完成實體鏈接;最后實體屬性匹配利用實體屬性信息進一步修正實體鏈接結(jié)果。該方法在合適的組合方式下能達到較高的實體鏈接準確度。
2 本文方法
實體對齊分為命名實體識別與實體鏈接兩個過程。命名實體識別在簡短式的問句中通常表現(xiàn)很好,本文主要聚焦于實體鏈接這個過程。
2.1 多維度匹配的總體設計
實體鏈接主要從文本匹配、統(tǒng)計匹配和實體屬性匹配這三個維度展開,其過程如圖1 所示。
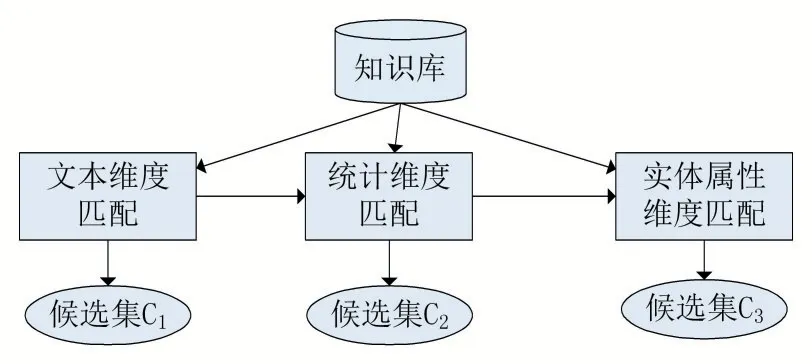
圖1 多維度匹配總設計
其中文本維度匹配主要功能是產(chǎn)生一個合理大小的實體候選集c1,統(tǒng)計維度匹配利用實體的一些顯著性指標(例如:實體熱度)完成候選集重排序,得到新的候選集c2。實體屬性匹配利用實體屬性(例如:實體關系、實體類型)進一步修正實體候選集的排序,得到最終候選集c3。
2.2 文本維度匹配
問句中實體名稱由命名實體識別得到,要將其鏈接到知識庫中一個正確的實體上,首先應該進行文本維度匹配篩選出實體候選集。實體名稱的文本相似度可以采用編輯距離來衡量。編輯距離是指將字符串a(chǎn)轉(zhuǎn)化為字符串b 最小操作次數(shù)。其遞推過程如式(1)所示。
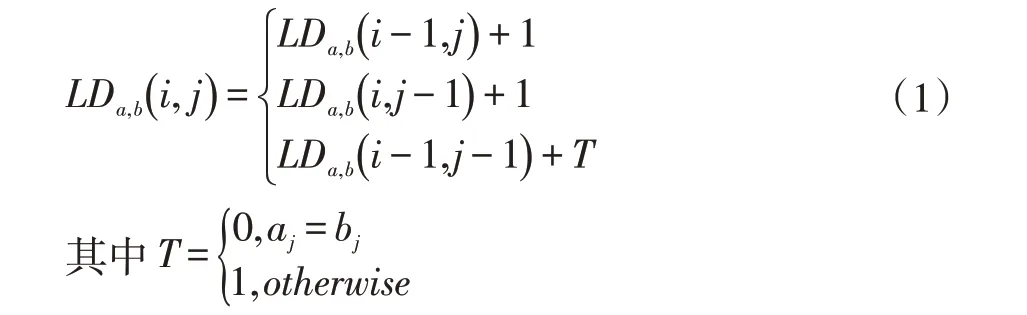
其中LDa,b(i,j)表示字符串a(chǎn) 的前i 個字符子串轉(zhuǎn)化到字符串b 前j 個字符子串所需的最少操作次數(shù)。得到編輯距離LDa,b后,再根據(jù)字符串a(chǎn),b 的長度La與Lb,即可通過式(2)計算出相似度Ra,b。

不難看出,實體候選集為了盡可能地覆蓋到正確答案就必須采用較小的相似度R,但是過小的R可能導致實體候選集過大同樣也會影響實體鏈接的最終效果。通常R≥0.8 表示有微小的拼寫錯誤,而R<0.8 則表明實體名拼寫完全錯誤不予識別。
由于實體名拼寫是否規(guī)范,通常與實體名本身復雜程度有關,針對簡單且易于拼寫的實體名而言,如果固定的閾值R太小,導致實體候選集過大,相反,復雜不易拼寫的實體名,如果R太大,則實體候選集過小。可見,固定R很難獲得一個合理大小的候選集,從而間接影響最終實體鏈接效果。因此,本文采用一種多級閾值的方法生成實體候選集。即設置一組從大到小的閾值依次進行匹配,其中本文設置三級閾值分別為:精確匹配閾值(R=1.0);較精確匹配閾值(R≥0.9);一般匹配閾值(R≥0.8)。其中下一級閾值只在上一級閾值沒有匹配到實體的情況下生效。
2.3 統(tǒng)計維度匹配
文本維度匹配生成實體候選集,在統(tǒng)計維度匹配中利用實體顯著性特征對進行實體候選集進行重排序。其中統(tǒng)計維度匹配主要是統(tǒng)計實體熱度,然后根據(jù)熱度對初始候選集進行重排序。
在Freebase 知識庫中,每條知識按照三元組(<eh,r,et>)方式組織。因此,實體熱度大小用該實體在知識庫中r的數(shù)量表示,r的數(shù)量越多熱度越高。反之越低。其中實體作為eh出現(xiàn),那么所有r的數(shù)量總和稱為出度。實體作為et出現(xiàn),那么所有r的數(shù)量總和稱為入度。通常出、入度之和代表實體熱度。但是本文只用出度代表實體熱度。其第i 個實體熱度得分scoreh(i)由熱度值hoti歸一化得到,其計算方式如式(3)所示:
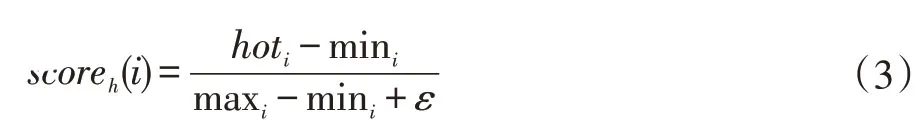
其中maxi、mini為最大與最小熱度值,ε參數(shù)為防止下溢,本文取0.001。
2.4 實體屬性維度匹配
在統(tǒng)計維度匹配后,可以根據(jù)實體排名先后選出top-1 或者top-k 的實體作為最終鏈接結(jié)果。但是實體熱度高不一定是鏈接的目標實體,因此為進一步提高鏈接準確度,再利用關系屬性對實體候選集進行新一輪排序。
在Freebase 知識庫中實體一般包含多種關系,不同實體由于類型不同包含的關系也不同。例如針對于“蘋果”這一詞,在知識庫中與之對應的可能是水果也可能是公司,但是對于問句“蘋果現(xiàn)在的市值是多少?”可以得到其實體為“蘋果”,預測的關系為“股票總市值”,而水果類型的蘋果肯定不包含“股票總市值”這一關系,因此通過實體關系是可以達到區(qū)分實體的目的。
實體類型預測作為一種分類任務,其采用整個問句作為預測上下文,即從問句完成到實體關系的一個分類過程。為了達到更好的預測效果,本文提出了一種基于Transformer[16]的關系預測模型。其模型架構(gòu)如圖2 所示。該模型為一個典型的編碼器(Encoder)-解碼器(Decoder)結(jié)構(gòu),其左邊為編碼器部分,右邊為解碼器部分。
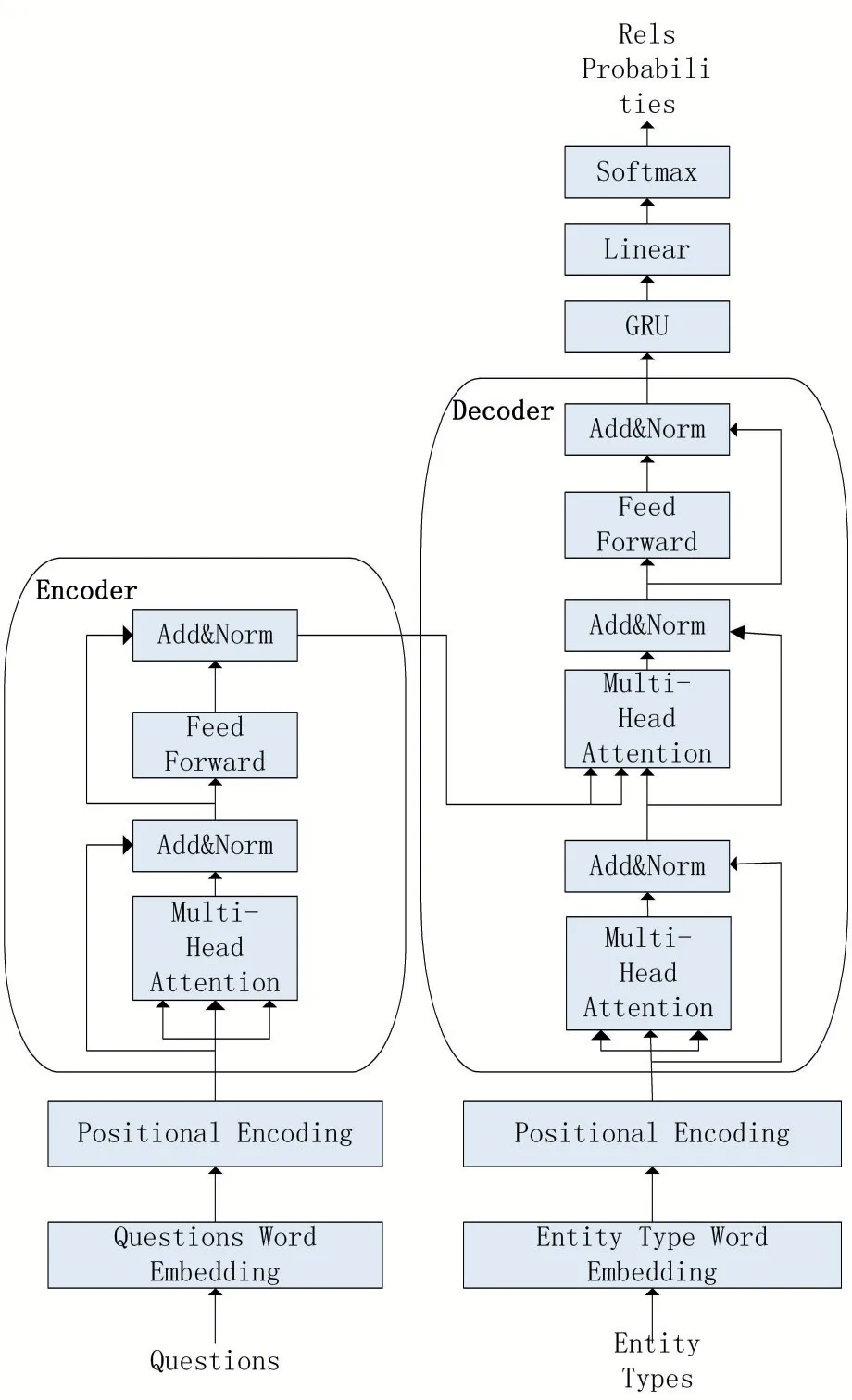
圖2 Transformer關系預測模型
該模型的編碼器部分主要由兩部分組成,第一部分為輸入預處理部分,完成對問句的詞嵌入(Questions Word Embedding)與位置編碼(Positional Encoding)任務。第二部分為問句編碼部分,主要有三個模塊:多頭注意力(Multi-Head Attention)模塊;層歸一化(Norm)模塊;全連接前饋神經(jīng)網(wǎng)絡模塊(Feed Forward)。此外,每進行一次多頭注意力或全連接前饋神經(jīng)網(wǎng)絡模塊都會進行一次殘差連接。
解碼器部分與編碼器類似,主要包括三個部分。第一個部分為輸入預處理,該輸入是針對實體類型進行的,其中實體類型的詞嵌入(Entity Types Word Em?bedding)與編碼器中問句的詞嵌入共享參數(shù)。第二部分解碼部分,解碼器進行了兩次多頭注意力模塊的計算,第一次多頭注意力機制是對實體類型進行的,第二次多頭注意力機制是對問句與實體類型共同進行的。最后為輸出預測部分,通過一個單向的GRU 得到一個全局的語義表示,該層是為了進一步提升語義抽取與位置信息表達的能力,最后通過一個線性映射和Soft?max 層輸出某種實體關系。
由于關系預測總會存在錯誤,因此本文額外選取了top3 實體預測關系進行候選集匹配,其第i個實體得分scorer(i)計算如式(4)-(5)所示。
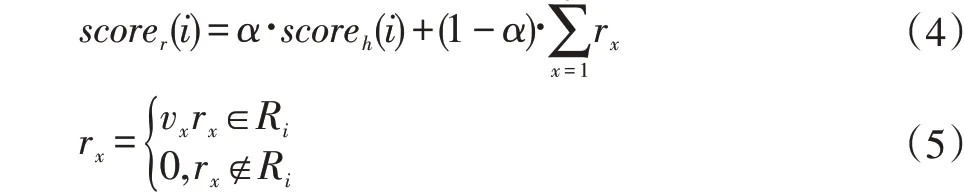
其中α為權(quán)重參數(shù),rx表示第x個預測關系,vx則為對應關系權(quán)重,Ri為第i個實體所有關系集合。
3 實驗
本節(jié)主要驗證本文提出的多維度匹配方法在實體鏈接中的有效性,以及多維度相比單維度的提升效果。因此,實驗主要包含統(tǒng)計維度匹配實驗,以及實體屬性匹配中的關系預測實驗。
3.1 實驗數(shù)據(jù)
本文實驗選取的數(shù)據(jù)集為SimpleQuestions[17],它是一個基于Freebase 知識庫的問答數(shù)據(jù)集,其訓練集與測試集樣本數(shù)分別為75910、21687 條,其樣本如表1所示。

表1 原始數(shù)據(jù)集
Freebase 在2016 年停止運維,因此本實驗采用Freebase 的子集FB2M[17]作為知識庫,由于原始的Sim?pleQuestions 數(shù)據(jù)集某些樣本的實體無法識別以及無法在FB2M 中查詢到,因此經(jīng)過整理后其數(shù)據(jù)信息如表2 所示。
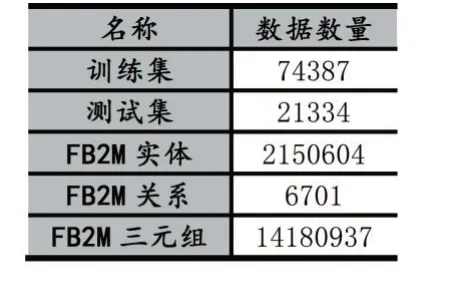
表2 數(shù)據(jù)信息
此外,由于SimpleQuestions 數(shù)據(jù)集只包含真實的實體ID,沒有對應的實體候選集,因此需要根據(jù)實體ID 在FB2M 中查詢出該實體名稱,利用文本維度匹配方法,即在知識庫中篩選出所有與該實體名稱相似的所有實體ID,生成初始的實體候選集。其數(shù)據(jù)如表3所示。

表3 實體鏈接數(shù)據(jù)集
3.2 統(tǒng)計維度匹配實驗
(1)實驗設計
首先文本維度匹配生成對應的實體候選集,在統(tǒng)計維度匹配中,統(tǒng)計出實體熱度,然后根據(jù)式(3)算出scoreh,利用scoreh大小對候選集重排序,最后選出得分最高的實體作為最終鏈接結(jié)果,其中評價標準采用準確率(Accuracy,ACC)。
(2)實驗結(jié)果與分析
實體熱度采用入度、出度、入度+出度分別進行實驗,其實驗結(jié)果如表4 所示。
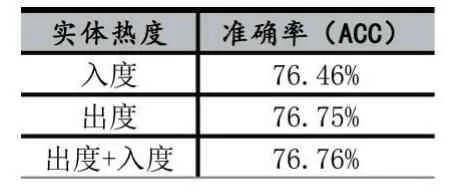
表4 統(tǒng)計維度匹配結(jié)果
從實驗結(jié)果可以得知,采用出度+入度的方式能達到最佳效果,但是三種衡量實體熱度的實驗結(jié)果差異不大,尤其是在只用出度表示實體熱度時。因此,只用出度代表實體熱度時,不僅不會造成準確度大幅下降,而且還能很大程度減少統(tǒng)計時間,尤其是在知識庫體量很大時,效果提升明顯。為此,本文額外采用了一個Freebase 的子集FB5M[17]作為對比,它包含比FB2M 更多的實體與關系,并在測試集下進行時間統(tǒng)計測試,其結(jié)果如表5 所示。

表5 統(tǒng)計耗時對比
3.3 實體屬性匹配實驗
該實驗分為兩部分,首先利用基于圖2 所示的關系預測模型對實體關系進行預測,其次利用預測關系對候選集進行匹配,最終得到實體鏈接結(jié)果。
(1)關系預測實驗設計
關系預測即利用問句與實體類型預測出對應的問句中包含的關系。此外,為了緩解關系預測錯誤帶來的影響,本實驗同時預測出top-1 與top-3 的實體關系,其中衡量指標仍采用ACC,最后為了驗證模型有效性,實驗同時還構(gòu)建了BiLSTM[18]、BiGRU[19]、Transformer共3 種關系預測模型作為對比研究。
(2)關系預測實驗結(jié)果與分析
關系預測實驗采用GloVe 作為預訓練詞向量,優(yōu)化器采用Adam,同時為了防止過擬合引入了Dropout,其模型主要配置參數(shù)如表6 所示。

表6 Transformer 關系預測模型主要參數(shù)
關系預測模型實驗結(jié)果如表7 所示。
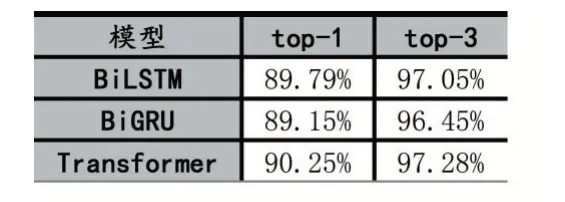
表7 關系預測結(jié)果
通過表6 可知,基于Transformer 的關系預測模型無論是在top-1 還是top-3 上都表現(xiàn)更好。其次相比于top-1,top-3 能明顯提高正確關系的覆蓋率。
(3)關系匹配實驗設計
實體關系匹配利用預測出的實體關系對實體候選集進行再次重排序。該實驗分別對第一個預測關系(top-1 rel)和前3 個預測關系集合(top-3 rels)進行候選集匹配,同時加入正確的關系(true rel)進行對照。
(4)關系匹配實驗結(jié)果與分析
該實驗中的top-1 rel 與true rel 方案只包含一個關系,因此從實體候選集選出scoreh值最大,并且包含該關系的實體即為最終結(jié)果,而top-3 rels 則是根據(jù)式(4)-(5)計算出關系得分scorer,然后將scorer值最大的實體作為最終結(jié)果。該實驗最終實體鏈接結(jié)果如表8所示。

表8 實體屬性維度匹配結(jié)果
利用true rel 進行實體候選集匹配,其最終實體鏈接準確度能達到85.64%,相比只用統(tǒng)計維度實體鏈接準確度(76.75%)有了明顯提升,證明實體關系能修正實體鏈接結(jié)果,同時多維度匹配的有效組合能大幅度提高實體鏈接準確度。此外,對比top1 rel 與top3 rels實驗,說明選取top3 實體關系提升了實體鏈接效果,其主要原因是緩解了實體關系預測錯誤而造成的錯誤累計問題。
此外本文還對比了state-of-the-art 方法,其結(jié)果如表9 所示。值得一提的是,本文前面的工作提前對不能識別出實體的樣本做了預處理,因此為了更加客觀公正地做出對比,實驗數(shù)據(jù)將不做預處理(測試集樣本數(shù)由21334 重新調(diào)整為21687)。
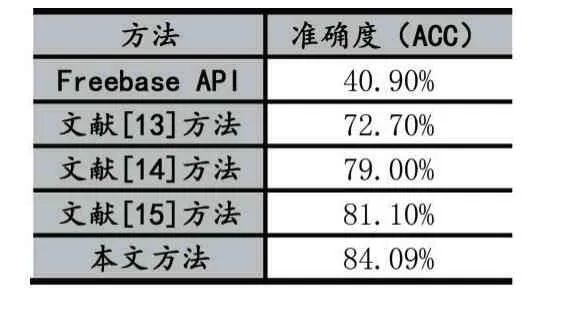
表9 實體鏈接方法對比
從表9 可知,本文提出的多維度匹配方法更能改善實體鏈接效果,并且方法中每個維度的匹配都為最后實體鏈接起到積極作用。此外,在不做預處理的情況下本文方法的ACC 下降到84.09%,說明預處理能提升最終實體鏈接效果,尤其是在噪聲很大的數(shù)據(jù)集上。
4 結(jié)語
本文針對簡單問句因?qū)嶓w名不規(guī)范、缺乏上下文等問題,提出了一種多維度匹配的方案。實驗表明文本匹配維度的多級閾值方法能較大程度上緩解實體名不規(guī)范問題,統(tǒng)計匹配維度能大幅度提高實體對齊效果,實體屬性匹配維度利用有限的問句上下文信息進一步修正了實體對齊的結(jié)果。最終多個維度組合能大幅度提高實體對齊準確度。
其次,為了避免流水線方式帶來的錯誤累計,每個維度匹配僅進行重排序,而維度疊加可以有權(quán)重系數(shù)控制每個維度重要性,從而到達最佳的實體對齊結(jié)果。其中最為核心的關系預測模塊,采用基于Trans?former 的預測模型,實驗表明相比其他關系預測模型該模型擁有更好的語義抽取能力,同時采取top-3 rels 的手段也能有效緩解關系預測錯誤帶來的影響。
最后,本文通過對實驗結(jié)果的分析發(fā)現(xiàn),一些不能對齊的實體大多是由于實體名拼寫不規(guī)范以及實體不具有顯著性(實體熱度、關系都相同或相近)。因此,針對于以上問題將來的工作主要是解決實體名糾錯,以及引入額外知識增加實體顯著性。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
