基于住戶差異性的住宅建筑在室行為預(yù)測模型
2021-07-01 20:54:14俞準(zhǔn)劉竹清李郡周亞蘋黃余建張國強(qiáng)
湖南大學(xué)學(xué)報(bào)·自然科學(xué)版 2021年5期
俞準(zhǔn) 劉竹清 李郡 周亞蘋 黃余建 張國強(qiáng)


摘 ? 要:現(xiàn)有住宅建筑在室行為預(yù)測模型缺乏對住戶差異性的合理考慮,導(dǎo)致模型往往存在整體預(yù)測精度不高和適用性受限等問題. 針對這一問題,提出一種考慮住戶差異性的馬爾可夫鏈在室狀態(tài)預(yù)測模型. 該模型首先通過Spearman相關(guān)性分析確定了不同影響因素(即特征參數(shù))與住戶總在室時(shí)長的相關(guān)性,將相關(guān)系數(shù)作為特征參數(shù)權(quán)值并結(jié)合聚類分析對住戶群體進(jìn)行分類. 在此基礎(chǔ)上采用馬爾可夫鏈模型對住戶在室狀態(tài)進(jìn)行預(yù)測. 為評估所建立預(yù)測模型的性能,以英國TUS(Time Use Survey)數(shù)據(jù)庫為例,將改進(jìn)模型與傳統(tǒng)馬爾可夫鏈模型進(jìn)行對比分析. 結(jié)果表明,該方法能夠綜合考慮不同住戶特征參數(shù)及其對在室行為的影響,對住戶進(jìn)行合理的分類,與傳統(tǒng)馬爾可夫模型相比,所建預(yù)測模型顯著提升了整體性能,平均絕對誤差和均方根誤差分別減小了20.57%和15.35%.
關(guān)鍵詞:在室行為;住戶差異;相關(guān)性分析;聚類分析;馬爾可夫鏈模型
中圖分類號:T111.1 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 文獻(xiàn)標(biāo)志碼:A
Abstract:Existing occupancy prediction models for residential buildings often lack the reasonable consideration of resident diversity, which generally results in poor prediction accuracy and limited applicability. To address this issue, this study proposes a Resident-differentiated, Markov Chain Occupancy Prediction Model with Cluster (RMCPMC) analysis ?to fully consider the resident diversity so as to improve the model predictive performance. First, Spearman correlation analysis is employed to identify the correlation between different influencing factors (i.e. resident characteristics) and total occupancy duration. The identified correlation coefficients are used as the weights for corresponding factors, and cluster analysis is subsequently performed to classify residents into different groups. Finally, RMCPMC models are established for obtained clusters to predict the occupancy pattern. To validate the performance of the proposed model, it is applied to the UK Time Use Survey (TUS) dataset and its performance is compared with the conventional Markov Chain(MC) model. Compared with the conventional MC model, the Mean Absolute Error and the Root Mean Square Error of the prediction accuracy decrease by 20.57% and 15.35%, respectively. The results indicate a significant improvement in model prediction accuracy through reasonably considering resident diversity and their impacts on occupancy patterns.
Key words:occupancy;resident diversity;correlation analysis;cluster analysis;Markov chain model
建筑在室行為是影響建筑能耗的主要因素之一[1]. 就住宅建筑而言,研究表明對其住戶的在室行為,尤其是在室狀態(tài)(即居民是否在室),進(jìn)行合理定量描述和準(zhǔn)確長期預(yù)測,是提升建筑能耗預(yù)測和模擬精度的有效手段[2]. 現(xiàn)有住宅建筑在室狀態(tài)預(yù)測模型主要包括統(tǒng)計(jì)概率模型、數(shù)據(jù)挖掘模型、馬爾可夫鏈(Markov Chain,MC)模型和Agent-based模型,其中應(yīng)用最為廣泛的是馬爾可夫鏈模型[3],該模型考慮了在室狀態(tài)在時(shí)間上的關(guān)聯(lián)性并能在一定程度上刻畫建筑住戶行為的隨機(jī)性. 例如,Richardson等人[4]基于英國TUS數(shù)據(jù)庫,分別針對工作日及非工作日建立MC模型以預(yù)測住戶在室狀態(tài). 結(jié)果表明該方法可以較好地預(yù)測在室狀態(tài),但其局限性也較為明顯,主要體現(xiàn)在該方法是對數(shù)據(jù)庫中所有住戶進(jìn)行統(tǒng)一預(yù)測,忽略了不同住戶之間的差異性. 考慮到不同特征住戶的在室規(guī)律有所不同,該方法必然導(dǎo)致模型預(yù)測性能下降. 對此,有學(xué)者在對住戶進(jìn)行分類的基礎(chǔ)上進(jìn)行在室狀態(tài)預(yù)測. 例如,F(xiàn)lett等人[5]首先選取部分住戶特征參數(shù)對英國住宅進(jìn)行分類,然后對不同類住戶在室狀態(tài)進(jìn)行分別預(yù)測. 該方法可在有效降低計(jì)算量的同時(shí)提高模擬精度,但仍存在明顯的局限性:一是所選取的住戶特征參數(shù)受研究者自身經(jīng)驗(yàn)和主觀因素影響,容易忽略部分與在室行為相關(guān)的重要因素;二是沒有考慮不同因素對住戶在室行為的影響程度大小,限制了模型預(yù)測性能的提升. 此外,部分學(xué)者嘗試采用無監(jiān)督聚類分析方法從住戶在室狀態(tài)信息中直接獲取不同住戶群體[6],再對不同群體住戶在室狀態(tài)進(jìn)行預(yù)測. 該方法可保證同一住戶群體具有相似的在室作息規(guī)律,從而提升了模型預(yù)測性能,但由此獲取的住戶群體其社會經(jīng)濟(jì)背景等特征可能具有顯著差異,導(dǎo)致在實(shí)際應(yīng)用中對某一住戶進(jìn)行能耗模擬時(shí)難以確定該住戶屬于哪類群體,從而限制了該方法的實(shí)用性.
針對上述問題,本文通過引入Spearman相關(guān)性分析及聚類分析對馬爾可夫鏈模型進(jìn)行改進(jìn),提出一種基于住戶差異性的馬爾可夫鏈在室狀態(tài)預(yù)測模型(Resident-differentiated,Markov Chain Occupancy Prediction Model with Cluster analysis,RMCPMC). 該模型綜合考慮了不同特征參數(shù)對住戶在室行為的影響差異,對住戶進(jìn)行合理的分類,在此基礎(chǔ)上進(jìn)一步建立在室狀態(tài)預(yù)測模型. 本研究采用英國2000年TUS數(shù)據(jù)庫對模型結(jié)果進(jìn)行驗(yàn)證,并與傳統(tǒng)馬爾可夫鏈模型進(jìn)行了對比分析.
1 ? 在室狀態(tài)預(yù)測模型
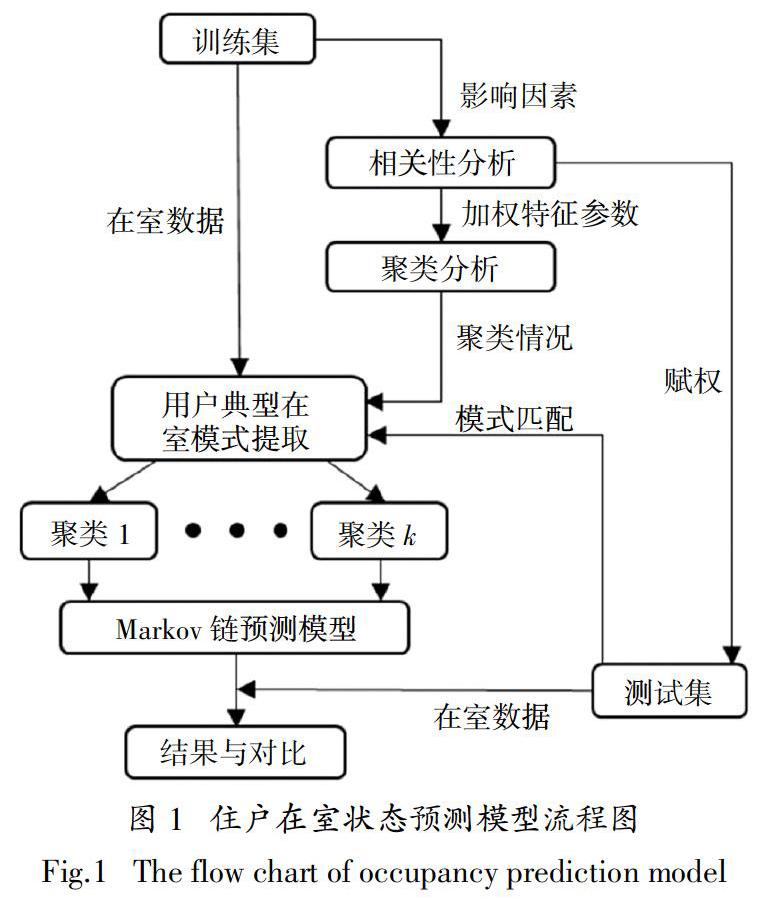
本文提出的基于相關(guān)性分析和聚類分析的住戶在室狀態(tài)預(yù)測模型流程如圖1所示.
由圖1可知,本研究所提出的模型主要包括以下步驟:
1)數(shù)據(jù)預(yù)處理. ?對數(shù)據(jù)進(jìn)行清理、篩選和轉(zhuǎn)換,并通過隨機(jī)抽樣選取80%數(shù)據(jù)作為訓(xùn)練集,20%數(shù)據(jù)作為測試集[7].
2)特征參數(shù)選取及賦權(quán). 通過Spearman相關(guān)性分析,計(jì)算不同特征參數(shù)與住戶總在室時(shí)長之間的相關(guān)系數(shù),在此基礎(chǔ)上選取合適的特征參數(shù),并將相關(guān)性系數(shù)作為權(quán)值賦予各特征參數(shù).
3)典型住戶在室狀態(tài)模式提取. 將賦權(quán)后的特征參數(shù)作為對象特征,采用聚類分析將住戶劃分成若干類.
4)預(yù)測模型建立. 確定各類住戶初始時(shí)刻在室狀態(tài)概率和狀態(tài)轉(zhuǎn)移概率矩陣,以分別建立馬爾可夫鏈預(yù)測模型.
5)模型驗(yàn)證. 對測試集住戶進(jìn)行在室模式匹配(即所屬聚類類別),并采用各馬爾可夫鏈模型分別進(jìn)行預(yù)測,將預(yù)測結(jié)果與實(shí)際在室狀態(tài)數(shù)據(jù)進(jìn)行對比分析.
1.1 ? 數(shù)據(jù)預(yù)處理
本文對原始數(shù)據(jù)的預(yù)處理過程主要包括數(shù)據(jù)清理、數(shù)據(jù)轉(zhuǎn)換和無量綱化處理.
1)數(shù)據(jù)清理:由于不同因素影響(如調(diào)查對象漏填等問題),數(shù)據(jù)庫存在部分住戶數(shù)據(jù)不完整的情況. 為避免缺失數(shù)據(jù)影響模型結(jié)果,本文剔除該部分?jǐn)?shù)據(jù).
2)數(shù)據(jù)轉(zhuǎn)換:數(shù)據(jù)庫中所測參數(shù)的類型包括數(shù)值型(如住戶年齡)和分類型(如住戶性別). 不同類型的數(shù)據(jù)難以直接進(jìn)行對比分析,因此本文將分類型參數(shù)轉(zhuǎn)換為數(shù)值型參數(shù),如住戶性別為“男”則轉(zhuǎn)化成數(shù)值1,反之則為2.
3)無量綱化處理:在應(yīng)用過程中,取值范圍小的參數(shù)易受取值范圍大的參數(shù)影響而被忽略其重要性. 為此,本文對參數(shù)進(jìn)行無量綱化處理,將不同參數(shù)的取值范圍轉(zhuǎn)化為相同區(qū)間,如[0,1][8].
1.2 ? Spearman相關(guān)性分析
由于住戶不同特征因素對其在室行為的影響程度不同,有必要對其相關(guān)性進(jìn)行分析,以確定不同影響因素對住戶在室狀態(tài)的影響程度. 本文采用Spearman相關(guān)性分析確定不同特征參數(shù)與住戶總在室時(shí)長的關(guān)聯(lián)程度. Spearman相關(guān)性分析是衡量2個(gè)變量的依賴性的統(tǒng)計(jì)方法,它利用單調(diào)方程評價(jià)2個(gè)統(tǒng)計(jì)變量的相關(guān)性. 其中相關(guān)系數(shù)用符號ρ表示,計(jì)算公式如(1)所示[9].
1.3 ?聚類分析
聚類分析是一種根據(jù)研究對象相似性將數(shù)據(jù)集劃分為若干類或簇的過程,目的是保證“類內(nèi)相似性和類間排他性”[10]. 本文選用劃分聚類分析中k-means算法對加權(quán)特征參數(shù)進(jìn)行聚類分析以得到不同住戶群體,其核心思想為指定初始聚類類別及質(zhì)心,并重復(fù)迭代直至算法收斂. 其最佳聚類數(shù)k可通過Calinski-Harabasz(CH)指標(biāo)和Davies- Bouldin(DB)指標(biāo)確定. 2指標(biāo)包含對類內(nèi)相似度與類間分離度的計(jì)算,CH指標(biāo)越大而DB指標(biāo)越小,則類內(nèi)相似度和類間分散度越高,說明聚類效果更優(yōu). 本文采用開源數(shù)據(jù)挖掘軟件RapidMiner[11]進(jìn)行聚類分析,該軟件是一個(gè)具有豐富數(shù)據(jù)挖掘分析和算法功能的開源軟件,通過將不同功能的算子連接形成流程來實(shí)現(xiàn)其功能,簡單易學(xué)且具有可視化特性.
1.4 ? 馬爾可夫鏈模型
該模型可通過初始在室概率p0和狀態(tài)轉(zhuǎn)移概率矩陣(Transition Probability Matrices,TPM)這兩個(gè)參數(shù)進(jìn)行描述. 將該模型應(yīng)用于住戶在室行為預(yù)測時(shí),TPM的大小取決于在室狀態(tài)數(shù)目(文中為“在室”和“離開”2種狀態(tài)),如圖2所示. 此外,考慮到在室狀態(tài)具有動態(tài)變化特征,本文采用隨模擬步長(即10 min)變化的不均勻TPM. 計(jì)算p0和TPM公式如下[14]:
在確定模型參數(shù)之后,為對在室狀態(tài)進(jìn)行隨機(jī)預(yù)測,本文基于初始概率和狀態(tài)轉(zhuǎn)移概率矩陣,通過生成0-1之間的隨機(jī)數(shù)并將其與相應(yīng)累計(jì)概率分布比較推斷出最可能出現(xiàn)的在室狀態(tài).
2 ? 數(shù)據(jù)庫與模型評價(jià)指標(biāo)
2.1 ? 數(shù)據(jù)庫簡介
英國國家統(tǒng)計(jì)局于2000年在全國范圍內(nèi)開展了時(shí)間利用調(diào)查,建立了Time Use Survey(TUS)數(shù)據(jù)庫[15],該數(shù)據(jù)庫以問卷調(diào)查的形式收錄了約2萬個(gè)住宅住戶單人日志,且對所有月份及星期天數(shù)均有涵蓋,其記錄的詳細(xì)日常活動信息能夠提供豐富的住戶行為數(shù)據(jù). 這些日志主要包含兩部分內(nèi)容:
1)與住戶日常活動相關(guān)的影響因素,包含詳細(xì)的個(gè)人信息(如年齡、性別、民族、職業(yè)、收入、住戶與其他住戶的關(guān)系等)和住宅信息(住宅類型、家用電器及車輛擁有權(quán)、家庭收入等).
2)住戶24 h(從4:00am到次日3:50am)具體的日常活動,包含一天工作日和一天非工作日,該信息是由住戶主動記錄每間隔10 min其主要日常活動、次要日常活動、相應(yīng)位置及是否有陪同人員等.
2.2 ? 模型評價(jià)
為評估模型的整體性能,本文采用平均絕對誤差(Mean Absolute Error,MAE)和均方根誤差(Root Mean Square Error,RMSE)兩個(gè)指標(biāo)對模型預(yù)測精度進(jìn)行評價(jià). MAE和RMSE反映預(yù)測在室狀態(tài)概率的整體誤差,計(jì)算公式如下:
3 ? 結(jié)果與討論
3.1 ? 數(shù)據(jù)預(yù)處理結(jié)果
對TUS數(shù)據(jù)清理后共有12 166個(gè)住戶日志數(shù)據(jù)完整且滿足研究需求,本文選取這部分?jǐn)?shù)據(jù)作為研究樣本,并從樣本中包含的日常活動分類中推斷出在室情況,其具體信息見表1. 此外,從數(shù)據(jù)庫中選取了12類可能對住戶在室行為產(chǎn)生影響的因素,具體分類及內(nèi)容見表2,其中表2中的分類數(shù)值均根據(jù)其相應(yīng)順序轉(zhuǎn)為有序數(shù)值,例如,工作狀態(tài)共計(jì)4種,依次編碼為1~4.
3.2 ? 相關(guān)性分析
本文以住戶總在室時(shí)長為目標(biāo)函數(shù),對影響因素進(jìn)行相關(guān)性分析,結(jié)果見表3. 由表3可知,在12個(gè)影響因素中,工作狀態(tài)、身份信息、經(jīng)濟(jì)活躍情況和年齡與住戶的總在室時(shí)長正相關(guān)系數(shù)較大,這意味著住戶的這四類因素與住戶在室持續(xù)時(shí)長具有顯著相關(guān)性. 在分析和預(yù)測住宅建筑住戶在室模式時(shí),應(yīng)重點(diǎn)考察這四種影響因素. 此外,住戶住宅類型以及生活狀況與總在室時(shí)長的相關(guān)性幾乎為零,這表明二者對在室行為的影響可忽略不計(jì). 因此在后續(xù)研究中將這兩個(gè)因素剔除,最終選取10個(gè)影響因素作為聚類特征參數(shù),并根據(jù)相關(guān)性系數(shù)為各特征參數(shù)賦予相應(yīng)權(quán)值.
3.3 ? 住戶典型在室模式
在得到相關(guān)系數(shù)后,應(yīng)以賦權(quán)特征參數(shù)為分類指標(biāo)對訓(xùn)練集數(shù)據(jù)進(jìn)行聚類分析. 針對不同聚類類別數(shù)目(本文設(shè)定范圍為2~10),分別計(jì)算CH和DB指標(biāo),結(jié)果見表4. 由表4可知,在k=2時(shí),CH指標(biāo)最大,DB指標(biāo)最小,即在保證類內(nèi)相似最高的情況下類與類之間的距離最遠(yuǎn),聚類效果最優(yōu). 因此,本文將樣本住戶分為2類進(jìn)行研究.
表5為對賦權(quán)特征參數(shù)進(jìn)行聚類后,2個(gè)聚類的聚類中心(即每個(gè)特征參數(shù)的平均值)、住戶數(shù)量及占比情況. 圖3給出了4個(gè)重要特征參數(shù)在這2個(gè)聚類的詳細(xì)分布情況. 結(jié)合表5和圖3可看出,第1類住戶的工作狀態(tài)、身份信息、經(jīng)濟(jì)活躍和年齡均為最大,這表明該聚類多為不在工作且不在學(xué)校、退休、經(jīng)濟(jì)狀態(tài)不活躍、年齡較大的人員;第2類住戶多為處于工作狀態(tài)、擁有全職工作、經(jīng)濟(jì)狀態(tài)活躍、年齡較小的人員.
由上述結(jié)果可看出兩類住戶具有明顯不同的特征,為進(jìn)一步分析不同住戶特征對在室行為模式的影響,圖4給出了兩類住戶的在室狀態(tài)概率分布圖. 從圖中可知,兩類住戶的在室模式存在顯著差異. 例如,在8:00—18:00時(shí)間段,第2類住戶不在室概率明顯高于第1類住戶,其主要原因是第2類住戶大部分為年齡相對較小的全職工作人員,白天通常處于外出工作狀態(tài);相反,對于第1類住戶(年齡較大的退休或無工作住戶),其主要日常活動為個(gè)人護(hù)理、休閑娛樂等室內(nèi)活動,外出活動時(shí)間較短. 由此可知,兩種在室模式與聚類所獲取的住戶特征較為吻合,表明基于住戶典型特征參數(shù)能夠合理劃分住戶并識別不同住戶的在室行為模式,使得同一類住戶的在室行為模式更為接近.
3.4 ? 模型預(yù)測精度比較
在聚類分析所劃分的兩類住戶的基礎(chǔ)上,本文采用訓(xùn)練集建立了基于住戶差異性的馬爾可夫鏈在室狀態(tài)預(yù)測模型(RMCPMC模型). 為驗(yàn)證模型的有效性,以測試集樣本住戶加權(quán)特征參數(shù)與兩聚類中心的歐氏距離為依據(jù)評判住戶歸屬典型類別,分別根據(jù)所建立的RMCPMC模型進(jìn)行預(yù)測. 經(jīng)分析測試集中有955名住戶(39.25%)屬于第1類,1 478名住戶(60.75%)屬于第2類. 為保證驗(yàn)證結(jié)果的公平性與合理性,應(yīng)以數(shù)據(jù)集樣本數(shù)目為模擬次數(shù)進(jìn)行預(yù)測[4]. 因此,本文以測試集中各個(gè)聚類的樣本數(shù)量為模擬次數(shù)模擬住戶在室行為.
圖5(a)(b)分別給出了RMCPMC模型和傳統(tǒng)MC模型預(yù)測在室概率曲線與實(shí)際在室概率曲線對比圖及相應(yīng)的累計(jì)誤差對比圖. 結(jié)合兩圖可知,盡管2個(gè)模型均能大致刻畫實(shí)際在室模式,但RMCPMC模型的累積誤差上升速率明顯小于MC模型. 這意味著RMCPMC模型預(yù)測誤差明顯低于傳統(tǒng)MC模型. 其主要原因是傳統(tǒng)的MC模型將所有住戶視為同一群體進(jìn)行預(yù)測分析,忽略了住戶差異對在室模式的影響,導(dǎo)致基于訓(xùn)練樣本計(jì)算的住戶在室狀態(tài)轉(zhuǎn)移概率受個(gè)體差異的影響,與驗(yàn)證樣本中的實(shí)際轉(zhuǎn)移概率偏離較大. 而RMCPMC模型由于通過住戶之間的相似性分別計(jì)算模型的轉(zhuǎn)移概率,考慮了不同住戶的特征差異,使得其預(yù)測結(jié)果更符合同類住戶的實(shí)際在室情況. 值得強(qiáng)調(diào)的是,圖5給出的在室概率與累計(jì)誤差均為1 d的模擬結(jié)果,當(dāng)將RMCPMC和MC 模型應(yīng)用于在室行為長期預(yù)測時(shí)(如預(yù)測時(shí)長為1年,此時(shí)需將第一天的模型輸出作為第二天的模型輸入并不斷推進(jìn)),由于累積效應(yīng),RMCPMC模型預(yù)測在室概率誤差和累計(jì)誤差較傳統(tǒng)MC模型會有更明顯的降低,從而提高相應(yīng)住宅建筑能耗預(yù)測精度.
表6給出了本文所提出的RMCPMC模型與傳統(tǒng)MC模型的整體預(yù)測結(jié)果. 從表6中可知,相比于傳統(tǒng)MC模型,本文所提出的預(yù)測模型的MAE和RMSE分別減少了20.57%和15.35%. 從總體預(yù)測結(jié)果來看,模型整體預(yù)測性能大幅提升. 這一結(jié)果表明,通過合理識別相似的建筑在室行為模式,能夠?qū)崿F(xiàn)提升在室行為預(yù)測精度的目的.
4 ? 結(jié) ? 論
本文主要結(jié)論如下:
1)住戶特征差異與建筑在室行為具有較強(qiáng)關(guān)聯(lián),因此在研究住戶在室行為時(shí)應(yīng)對住戶不同特征與在室行為進(jìn)行相關(guān)性分析. 就本文所采用的數(shù)據(jù)庫而言,其中相關(guān)性較強(qiáng)的影響因素包括住戶的工作狀態(tài)、經(jīng)濟(jì)水平、年齡和身份信息.
2)本文方法能綜合考慮住戶差異性對建筑在室行為的影響,通過合理區(qū)分不同建筑住戶特征以識別相應(yīng)的典型在室模式. 本次研究通過聚類分析獲得2類具有明顯不同特征的住戶:第1類住戶多為不在工作且不在學(xué)校、退休、經(jīng)濟(jì)狀態(tài)不活躍、年齡較大的人員;第2類住戶多為處于工作狀態(tài)、擁有全職工作、經(jīng)濟(jì)狀態(tài)活躍、年齡較小的人員. 且兩類住戶在室模式與聚類所獲取住戶特征較吻合.
3)與傳統(tǒng)MC模型相比,RMCPMC模型整體預(yù)測精度顯著提升,RMCPMC模型可根據(jù)住戶特征參數(shù)有效判別住戶所屬類別,獲得更加合理的模型輸入?yún)?shù),預(yù)測結(jié)果更符合實(shí)際,模型預(yù)測誤差MAE和RMSE分別減少了20.57%和15.35%.
本文模型的建立和評估均是以英國2000年TUS數(shù)據(jù)庫為例,將其應(yīng)用于我國時(shí)應(yīng)結(jié)合我國住宅建筑室內(nèi)人員特征,從數(shù)據(jù)采集、模型參數(shù)選取和聚類分析參數(shù)權(quán)重分配等方面進(jìn)行考慮. 同時(shí),就新建住宅住戶行為預(yù)測而言,考慮到其住戶特征難以獲取,應(yīng)基于其規(guī)劃設(shè)計(jì)信息選擇已有類似住宅并采用相關(guān)參數(shù)進(jìn)行預(yù)測,在后期業(yè)主入住后再收集住戶信息對模型進(jìn)行校核和修正.
此外,本文研究主要針對建筑住戶在室狀態(tài)(即在室和不在室)的預(yù)測進(jìn)行分析和驗(yàn)證,在此基礎(chǔ)上,未來應(yīng)進(jìn)一步細(xì)化住戶在室行為(如主動/被動在室狀態(tài)、與能耗相關(guān)行為等)建立相應(yīng)預(yù)測模型,以獲取住戶更全面且詳細(xì)的在室狀態(tài),并將其與能耗預(yù)測模型相耦合,達(dá)到提高能耗模擬精度的目的.
參考文獻(xiàn)
[1] ? ?LABEODAN T,ZEILER W,BOXEM G,et al. Occupancy measurement in commercial office buildings for demand-driven control applications-A survey and detection system evalua-tion[J]. Energy and Buildings,2015,93:303—314.
[2] ? ?俞準(zhǔn),周亞蘋,李郡,等. 建筑用戶在室行為預(yù)測新方法[J]. 湖南大學(xué)學(xué)報(bào)(自然科學(xué)版),2019,46(7):129—134.
YU Z,ZHOU Y P,LI J,et al. A new approach for building occupancy prediction[J]. Journal of Hunan University (Natural Sciences),2019,46(7):129—134. (In Chinese)
[3] ? ?JIA M D,SRINIVASAN R S,RAHEEM A A. From occupancy to occupant behavior:an analytical survey of data acquisition technologies,modeling methodologies and simulation coupling mechanisms for building energy efficiency[J]. Renewable and Sustainable Energy Reviews,2017,68:525—540.
[4] ? ?RICHARDSON I,THOMSON M,INFIELD D. A high-resolution domestic building occupancy model for energy demand simulations[J]. Energy and Buildings,2008,40(8):1560—1566.
[5] ? ?FLETT G,KELLY N. An occupant-differentiated,higher-order Markov Chain method for prediction of domestic occupancy[J]. Energy and Buildings,2016,125:219—230.
[6] ? ?AERTS D,MINNEN J,GLORIEUX I,et al. A method for the identification and modelling of realistic domestic occupancy sequences for building energy demand simulations and peer compar-ison[J]. Building and Environment,2014,75:67—78.
[7] ? ?周志華.機(jī)器學(xué)習(xí)[M]. 北京:清華大學(xué)出版社,2016:25.
ZHOU Z H. Machine learning[M]. Beijing:Tsinghua University Press,2016:25. (In Chinese)
[8] ? ?李郡,俞準(zhǔn),劉政軒,等. 住宅建筑能耗基準(zhǔn)確定及用能評價(jià)新方法[J]. 土木建筑與環(huán)境工程,2016,38(2):75—83.
LI J,YU Z,LIU Z X,et al. A method for residential building energy benchmarking and energy use evaluation[J]. Journal of Civil,Architectural & Environmental Engineering,2016,38(2):75—83. (In Chinese)
[9] ? ?陳功平,王紅. 改進(jìn)Pearson相關(guān)系數(shù)的個(gè)性化推薦算法[J]. 山東農(nóng)業(yè)大學(xué)學(xué)報(bào)(自然科學(xué)版),2016,47(6):940—944.
CHEN G P,WANG H. A personalized recommendation algorithm on improving Pearson correlation coefficient[J]. Journal of Shandong Agricultural University (Natural Science Edition),2016,47(6):940—944. (In Chinese)
[10] ?HAN J W,KAMBER M,PEI J. Data mining:concepts and techniques [M]. 3rd ed. Beijing:China Machine Press,2012:448—450.
[11] ?NAIK A,SAMANT L. Correlation review of classification algorithm using data mining tool:WEKA,rapidminer,Tanagra,orange and knime[J]. Procedia Computer Science,2016,85:662—668.
[12] ?FOUTZ R V,GRIMMETT G R,STIRZAKER D R. Probability and random processes[J]. Journal of the American Statistical Association,1993,88(424):1475.
[13] ?李欣然,陳鴻琳,冷華,等. 中長期電量預(yù)測的傅里葉-馬爾科夫修正模型[J]. 湖南大學(xué)學(xué)報(bào)(自然科學(xué)版),2016,43(10):62—69.
LI X R,CHEN H L,LENG H,et al. ?Mid-long term load forecasting model with Fourier series and Markov theory residual error correction[J]. ?Journal of Hunan University (Natural Sciences),2016,43(10):62—69. (In Chinese)
[14] ?WID?魪N J,W?魨CKELG?RD E. A high-resolution stochastic model of domestic activity patterns and electricity demand[J]. ?Applied Energy,2010,87(6):1880—1892.
[15] ?Ipsos-RSL and Office for National Statistics. United Kingdom Time Use Survey,2000. [EB/OL]. [2003-09]. https://census.ukdataservice.ac.uk/.
