加密流量中的惡意流量識別技術
2021-07-01 14:27:04吳正遠董麗華劉志宏馬建峰
西安電子科技大學學報 2021年3期
曾 勇,吳正遠,董麗華,劉志宏,馬建峰,李 贊
(1.西安電子科技大學 網絡與信息安全學院,陜西 西安 710071;2.西安電子科技大學 綜合業務網理論及關鍵技術國家重點實驗室,陜西 西安 710071)
在互聯網技術日益健全的今天,網絡流量識別技術對網絡管理、服務質量保障和網絡安全等具有重大的意義。伴隨著加密技術的不斷發展,加密流量在互聯網流量中的數量和比例也不斷上升。根據最近的互聯網研究趨勢報告[1],如今87%的web流量是加密的,文獻[2]預計在2020年超過70%的惡意軟件活動將使用某種類型的加密來隱藏惡意軟件的傳輸、控制命令活動和數據滲漏。由于加密后流量的特征發生了改變,因而傳統流量檢測方式在加密環境下難以復現。如何在加密流量上進行有效的惡意流量識別,已成為了網絡安全領域的重要挑戰。
已有文獻[3-7]綜述了當前加密流量識別技術的研究進展。其中,文獻[3]總結了網絡加密流量的基本概念、研究進展和評價指標等概念。文獻[4]總結了用于加密流量識別的方法以及影響加密流量識別的因素,文獻[5]總結了流量識別的四種常用方法:基于端口號、深度報文檢測、機器學習和深度學習,著重介紹了常用于深度學習訓練的幾種特征和深度學習模型。但是這些綜述并未涉及加密流量中的惡意流量識別。文獻[6]對加密流量數據集和加密流量中的惡意流量檢測步驟進行了小結,并介紹了基于機器學習的識別方法。文獻[7]介紹了通過將流量轉化為圖像后采用計算機視覺的方法進行惡意流量識別的模型,這類方法目前僅在三大類惡意流量上有比較好的識別結果,且僅部分識別方法面向加密流量。
上述惡意流量檢測工作均為基于機器學習的方法,由于基于機器學習方法的識別效果嚴重依賴于樣本數量和質量,而當前在加密流量領域尚且缺乏類似ImagNet[8]的經典數據集,不僅如此,基于機器學習的方法無法有效應對混淆和整形后的流量[9-10]。近年來研究人員發現,基于密碼學的方法可以通過密文檢索技術與深度報文檢測技術的融合來避免此類問題。為了更好地理解這些方法,筆者對已有的相關技術進行了如下總結:
(1) 加密算法區分。當前流量中采用的加密算法種類繁多,不同的加密方式會產生不同的特征,需要不同的識別方法。當前尚無通用方法能夠應用于所有類型的加密流量,而惡意流量識別的任務之一需要先將加密流量按照不同精細度區分開,例如區分AES、DES、3DES、Grain等密碼體制,為后續惡意流量區分提供支撐[11-55]。
(2) 惡意特征識別。基于機器學習的惡意流量識別效率和準確率隨著機器學習技術的發展而提高。其最新進展是通過改進加密流量中惡意特征提取方式,構建不同的帶標簽惡意特征集,并將其輸入各種機器學習模型進行訓練;通過模型設計與參數調優等方法來保證加密流量中對惡意流量識別的準確度[56-81]。
(3) 惡意密文檢索。基于密碼學的惡意流量識別技術,結合流量審查機制、可搜索加密技術以及可證明安全模型,通過在加密流量上檢索惡意關鍵詞,從而達到在加密流量中識別惡意流量的效果,并對用戶數據與檢測方的檢測規則同時提供保護[82-113]。
1 加密算法區分
加密算法區分是識別加密流量中惡意流量的第一步。將加密流量按照不同加密算法區分開,可以有效精簡數據集大小,提高識別效率,并為后續加密流量中的惡意流量識別做先驗準備。不同密碼算法所產生的密文在統計特性上存在一定的差異。這些差異是識別密碼算法的重要依據。基于統計學和機器學習的方法可以較有效地區分加密算法。
1.1 加密非加密流量區分
將加密與非加密流量區分開是進行惡意流量識別的基礎。筆者總結了近三年在公開的ISCXVPN/Non-VPN[11]流量數據集上的相關工作,詳細工作見表1。該數據集包含七種VPN流量和七種非VPN流量,每種類型內又包含多個應用的流量。其中瀏覽器類型的流量可能包含了其他類型的部分流量,因此實際識別中常見的區分方法有二分法(區分VPN與非VPN流量)和六分法(區分流量來源于何種類型)。LOTFOLLAHI等[12]提出了深度數據包框架Deep packet。主要提取加密數據包的有效負載特征,并采用了棧式自動編碼器(SAE)和卷積神經網絡(CNN)兩種深度神經網絡結構,從而對VPN和非VPN網絡流量進行二分類。并可對VPN或者非VPN中的流量進行大類區分。例如可區分出VPN或者非VPN的聊天、郵件、視頻等類別。BAGUI等[13]使用與時間相關的特征進行了類似的研究。WANG等[14]提出了一種基于CNN的端到端深度學習模型。通過將流量轉化為圖像的方式自動選取特征,從而實現VPN與非VPN的二分類與大類區分。GUO等[15]用收縮自動編碼器(CAE)和卷積神經網絡(CNN)兩種方法進行比較,對WANG等的工作進行了改進。唐舒燁等[16]引入基于分段熵分布的隨機性檢測方法,實現了對加密VPN流量與非加密VPN流量的細粒度分離。ZHOU等[17]采用了熵估計和人工神經網絡的方法進行二分類。CASINO等[18]提出了基于數據流隨機性評估的流量識別方法HEDGE,可識別壓縮流量和加密流量。該方法可以應用于單個數據包,而無需訪問整個數據流。ACETO等[19]使用深度學習技術,基于自動提取的特征建立識別器,能夠對手機的加密流量進行分類操作。上述方法均基于對有效載荷的統計。NIU等[20]提出了一種結合統計和機器學習的啟發式統計測試方法。該方法優于僅統計或機器學習的方法。
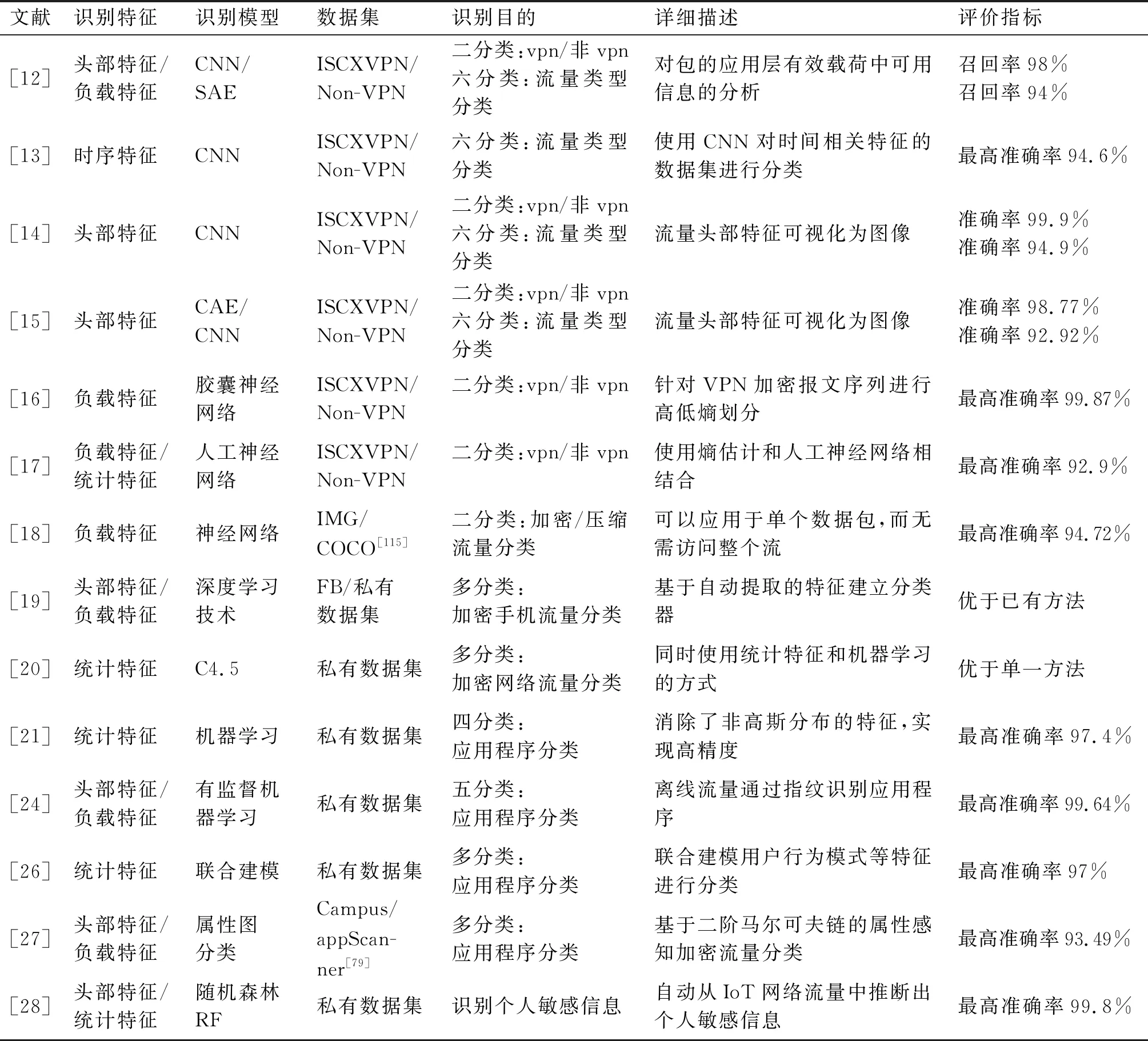
表1 密/非密流量區分及應用程序分類方法小結
1.2 加密流量中的應用識別
將加密非加密流量區分后,另一個重要的工作是將加密流量所屬的應用程序進行分類,詳細內容見表1。OKADA等[21]使用統計特征的最佳組合進行識別。由于消除了非高斯分布的特征,因此能夠以較少的計算量實現高精度的識別。為了提高現有方法在鑒別準確度方面的性能,HE等[22-23]指出攻擊者精心選擇一些流量特征,并利用一些有效的機器學習算法對不同類型的應用程序進行建模。這些模型可用于對目標的洋蔥路由(Tor)流量進行識別并推斷其應用程序類型。類似地,ALMUBAYED等[24]指出,通過使用監督學習方式,Tor流量仍可以在網絡中的其他HTTPS流量中識別。考慮到用戶使用同一應用程序做出不同的行為時會產生不同的流量,CONTI等[25]指出,即便是在加密的條件下,攻擊者依然可以通過特定的方法識別用戶在網絡中的行為,這些行為導致了隱私泄露的風險。FU等[26]開發了一個名為CUMMA的系統,通過聯合建模用戶行為模式、網絡流量特征和時間依賴性,可對應用程序內的使用進行識別。SHEN等[27]指出應用程序長度二元組有助于應用程序識別。該二元組由證書包長度和SSL/TLS會話中的首個應用程序數據長度組成。SUBAHI等[28]開發了IoT-app作為隱私檢查器的工具。該工具可以通過其應用程序的數據包,自動從IoT網絡流量中推斷出敏感個人身份信息(例如用戶的位置等)。
1.3 加密算法識別
當流量中的明密文區分開后,密文所采用的加密算法也可以進行區分。早在上世紀80年代,密碼學者已開始關注機器學習與密碼學的聯系,并提出一些相關的概念和結論[29]。RIVEST等發表《密碼學與機器學習》[30],探討了機器學習應用于密碼學的可行性。不同密碼算法所產生的密文在統計特性上存在一定的差異,這些差異可以作為識別密碼算法的重要依據[31]。基于這些差異,機器學習在古典密碼體制識別[24]、分組密碼體制識別[32-33]、布爾函數設計[34-36]等方向取得了初步的研究成果。機器學習方法亦可用于密碼攻擊,包括基于神經網絡的明文恢復[37-39]、基于機器學習的側信道攻擊[40-42]等。表2總結了用于加密算法識別的詳細方法。

表2 加密算法識別小結
DILEEP等[43]采用文檔分類技術,在分組密碼的ECB、CBC模式下,使用機器學習中的支持向量機(SVM)算法對AES、DES、3DES、Blowfish、RC5這5種密碼體制進行識別。CHOU等[44]采取類似的識別方案表明在CBC模式下的分組密碼的密文不能很好地區分。NAGIREDDY[45]使用SVM分析同樣5種密碼算法加密后的密文的直方圖信息。SONI等[46]提出使用Adaboost算法對5種分組密碼算法進行分類學習。MISHRA等[33]提出包含11種密碼算法的密碼體制,采用C 4.5算法生成的決策樹研究密碼體制識別。在多分類任務下,從密文中提取8個特征進行識別。文獻[47-48]分別使用8種不同分類器模型對分組密碼進行識別。結果表明組合分類器模型隨機森林(RF)效果的識別準確率最佳。SOUZA等[49]提出選取機器學習方法中的神經網絡進行RC6、Rijndael等5種AES最終輪候選密碼算法。BHATEJA等[50]提出了一種基于反向傳播網絡的方法來區分RC4密鑰流和隨機密鑰流。WU等[51]使用機器學習方法中的K均值聚類(K-Means)算法識別加密后的密文,并分析AES、Camellia、DES、3DES、SMS4共5種分組密碼構成的密碼體制。文獻[52-54]提出密碼體制分層識別方案,選擇機器學習的隨機森林算法進行識別。隨后,ZHAO等[55]研究Grain-128算法與其他11種密碼算法的識別。主要進行了二分類任務識別(即密碼算法兩兩識別),其中涉及的序列密碼算法包括Grain-128、RC4與Salsa。
2 基于機器學習的惡意流量識別
不同類型的流量具備不同的網絡行為模式,這些信息直觀地體現在其數據包上。例如,惡意流量與良性流量在進行握手協議時會產生不同的數據包頭部信息,而不同類型的惡意流量在其平均包長、包間間隔等方面也存在差異;這些行為模式的差異是識別惡意流量的重要依據。因此可從采集到的加密流量中提取惡意流量的行為模式,將其進一步歸納為惡意流量的特征,并利用機器學習模型進行識別。
基于機器學習的惡意流量識別是將加密流量進行惡意特征提取,從而構建惡意特征集,并作為訓練集輸入訓練模型,通過模型設計與參數調優等方法得到理想的準確度。該類方法具有效率高、適用性廣的優點。因此,基于機器學習的加密流量識別成為了當前研究熱點。基于機器學習的惡意流量識別體系如圖1所示。首先需要采集所需數據集,通常有使用公開流量數據集和私有流量數據集兩種方法;然后對采集到的流量數據進行預處理工作,包括流量清洗、流量分割、特征集構建和流量轉換;最后將數據集作為輸入,利用機器模型學習惡意流量的惡意特征,通過迭代訓練識別出惡意流量。
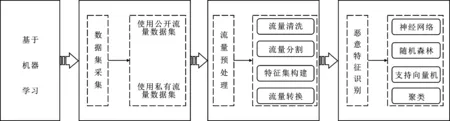
圖1 基于機器學習的惡意流量識別體系
2.1 數據集采集
使用機器學習模型進行惡意流量識別首先需要一個有代表性的數據集。盡管當前已有一些公開的加密流量數據集(例如ISCX2012[120],CTU-13[121]和CICIDS2017[123]),但目前加密流量領域仍然缺乏一個普遍被認可的加密流量數據集。其原因在于:通過不同方式加密后的流量需要不同的收集方法和場景,而一個數據集幾乎不可能包含所有的流量類型。
因此,研究人員更傾向于首先使用私有流量數據集進行識別,利用腳本或者沙箱生成特定類型的加密流量,然后采集這些特定流量并打上標簽。通過這種方法采集到的流量比直接從真實網絡環境中進行采集更為精純,同時易于貼上標簽。但使用私有流量數據集的惡意流量識別方法往往難以復現,同時不方便與已有方法進行比較。
2.2 流量預處理
通常情況下,收集到的流量數據集并不能直接作為機器學習模型的輸入,需要對其進行預處理工作。預處理通常包括流量清洗、流量分割、特征集構建和流量轉換。流量清洗需要將收集到的流量中重復和無效部分清除。流量分割需要將過長的影響識別效率的流量分割為片段。將收集到的流量進行流量清洗和分割后,下一步是構建特征集,機器學習常用的流量特征有時空特征、頭部特征、負載特征和統計特征4種。4種特征在流量包上的表現如圖2所示。
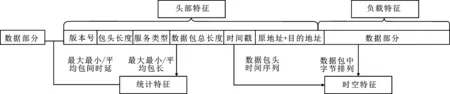
圖2 機器學習四種特征示意圖
流量轉換則將構建后的流量轉化為圖像[62-67]、矩陣[56-61,75-79]或者N-gram[68-74],以便于機器學習模型識別。這一過程的一個關鍵步驟是對數據的標準化和歸一化。二者的目的是將原始數據限定在一定的范圍內,從而降低奇異樣本數據產生的負面影響。歸一化是對原始數據進行變換,并按照不同的處理方式固定到某個區間中(如圖像區間為[0,255]等)。歸一化數學表達如下:
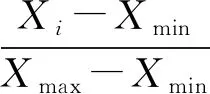
(1)
其中,Xi表示當前樣本的值,Xmax表示樣本最大值,Xmin表示樣本最小值。
標準化對數據進行變換,使其符合均值為0、標準差為1的分布。標準化數學表達如下:
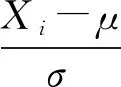
(2)
其中,μ表示樣本數據的均值,σ表示樣本數據的標準差。
2.3 惡意特征識別
將轉化后的流量集導入CNN、RF、SVM、聚類等機器學習模型進行訓練以識別惡意特征;識別結果反饋信息給訓練模型,通過模型設計與參數調優等方法得到理想的準確度,最終實現將流量進行良性和惡意的二分類,并進一步地對惡意流量進行細粒度的分類。圖3總結了這一過程,表3歸納了基于機器學習的加密流量中的惡意流量識別相關工作。下文將對相關工作按照不同特征集構建方式進行詳細介紹。

圖3 機器學習流程圖
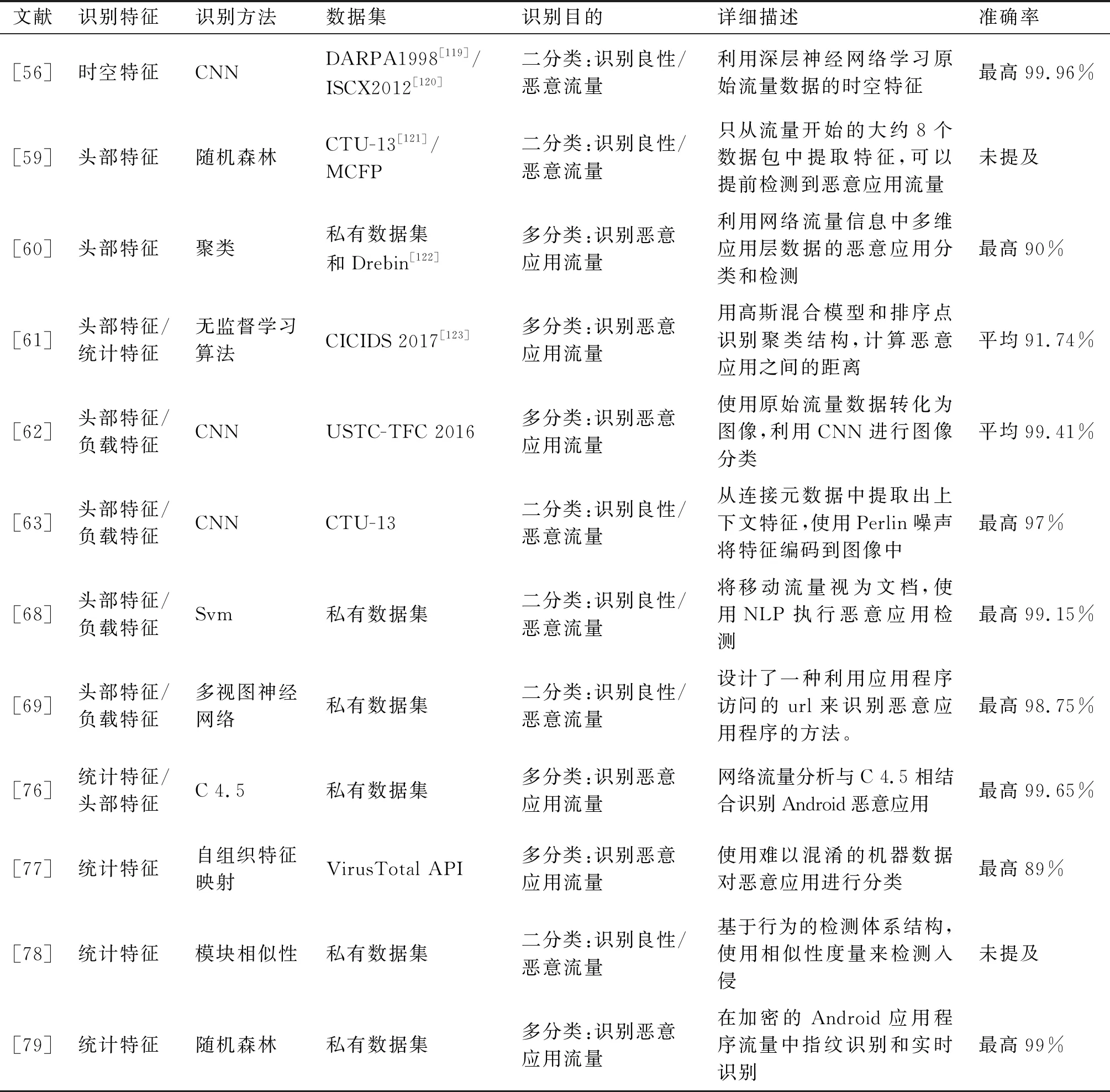
表3 基于機器學習的惡意流量識別小結
時空特征包括流量的時間特征和空間特征。WANG等[56]提出了基于分層時空特征的入侵檢測系統(HAST-IDS)。首先使用深度卷積神經網絡(CNN)學習網絡流量的淺層空間特征,然后使用長短期記憶網絡(LSTM)學習深層時間特征。實驗表明,使用時空特征相結合方式的識別結果要優于只使用其中一種方法的識別結果。類似地,KIM等[57]通過同時查看時間和空間中的多個計算元素來檢測惡意流量,并建立了一個隨機圖模型來表示網絡攻擊行動在時間和空間上的組合。該系統能夠有效地檢測到未知攻擊。
頭部特征包括流量包頭部包含的用戶信息相關特征。ANDERSON等[58]通過學習加密流量的數據特征,提出了基于TLS握手數據包中暴露的版本號、密鑰長度等非加密信息來檢測惡意流量的方法。為了避免機器學習中手動選擇特征的繁瑣,LIU等[59]提出了MalDetect,僅在流量開始時從大約8個數據包中提取特征,這使其能夠在惡意應用行為產生實際影響之前而不是流量傳輸完成后檢測惡意應用流量。LI等[60]引入了DroidClassifier系統框架,通過從多個HTTP標頭字段中提取通用標識符來構建模型,并利用監督學習的方法進行識別。LIU等[61]計算惡意軟件之間的距離并利用該距離的聚類結構定義新的惡意軟件類,并利用無監督學習算法高斯混合模型(GMM)和排序點進行辨識。
負載特征包括流量包中的有效載荷部分。WANG等[62]提出了一種新的流量分類方法。將流量數據可視化為圖像,再通過圖像使用CNN進行分類。通過這種方法,可以實現端到端的惡意流量識別,并且能夠滿足實際應用的精度。BAZUHAIR等[63]從連接元數據中提取上下文特征,然后使用Perlin噪聲將給定的連接特征編碼為圖像,最后訓練深度學習模型進行二進制識別。WANG等[68]認為移動應用程序生成的每個HTTP流都可視為文本文檔。因此處理自然語言的方式同樣可以用于處理網絡流量的語義,并提出了一種使用自然語言處理對網絡流量文本語義檢測的惡意應用檢測模型。基于同樣的思路,WANG等[69]設計了一種利用應用程序訪問時HTTP流中的統一資源定位器(URL)來識別惡意應用程序的方法。
統計特征包括流量包平均包長、平均包間時延等特征。早在2008年,WRIGHT等[75]就證明了利用音素與VoIP(Voice over Internet Protocol)編解碼器在呈現這些音素時輸出的數據包長度之間存在相關性。加密的VoIP包的長度可以用來識別通話中所說的短語。WANG等[76]通過收集TLS的6個統計特征(上傳字節、下載字節大小等)和HTTPS流中的4個統計特征(用戶代理、請求URL等),用C 4.5算法識別出惡意應用流量。BURNAP等[77]使用通過創建無監督聚類的方式建立應用的活動度標準來識別正常應用和惡意應用。類似地,NEU等[78]提出了一種新的基于相似度來檢測惡意流量的檢測體系結構。TAYLOR等[79]介紹了稱為AppScanner的框架,用于自動加密和實時識別Android應用程序的加密網絡流量。在物理設備上自動運行應用程序以收集其網絡跟蹤,通過網絡跟蹤生成指紋并用于流量識別。
加密電子設備在運行過程中產生的側信道信息也可用于惡意應用識別。文獻[80]中提出了HoMonit,在物聯網環境下通過側信道信息識別惡意智能應用。文章利用嗅探器從集線器和云平臺之間收集泄露的側信道信息(包大小和包間時序)。通過對加密流量進行流量分析來推斷出智能設備和集線器之間的事件序列,然后從智能應用的源代碼或UI接口中提取預期程序邏輯,二者通過DFA(有窮自動機)算法進行匹配,從而識別出越權或是行為異常的惡意智能家居應用。
以上惡意行為主要表現在加密流量上,文獻[81]提出了一種基于機器學習的安全分析模型來識別出認證與密鑰協商協議過程中對協議的攻擊。相比于傳統形式化協議中分析方案與分析精度往往取決于分析人員所掌握的先驗知識和對協議的主觀理解,將機器學習與協議形式化分析相結合是一種可行的嘗試。但該方案目前尚缺乏足夠的樣本對每一種攻擊進行細分類。
3 基于密碼學的惡意流量識別
基于密碼學的惡意流量識別的本質在于,檢索流量中是否存在加密后的惡意關鍵字,即在不解密所有數據包的前提下,實現在一段加密過的信息上實現惡意關鍵詞的搜索,這也是可搜索加密技術的一種應用。然而,檢測的中間盒設備往往沒有解密流量的權限或者密鑰,不僅如此,可搜索加密無法對檢測規則提供保護。因此,在網絡流量中的惡意流量識別不能直接應用可搜索加密,而是需要深度融合可搜索加密技術、深度報文檢測技術、流量審查機制和可證明安全模型,進行綜合設計,使其可以在保護用戶數據隱私以及檢測方檢測規則的前提下檢索加密流量上的惡意關鍵詞以識別惡意流量。基于密碼學的惡意流量識別的關鍵技術如圖4所示。筆者將從可搜索加密技術出發,介紹公鑰可搜索加密和對稱可搜索加密的技術難點,包括密文檢索和密文計算。其中密文檢索可依次區分為單關鍵詞檢索、多關鍵詞檢索、模糊關鍵詞檢索和區間檢索。密文計算可分為同態加密和函數(屬性)加密。最后介紹如何結合可搜索加密技術、深度報文檢測以及流量審查等機制進行加密流量中的惡意流量檢索。
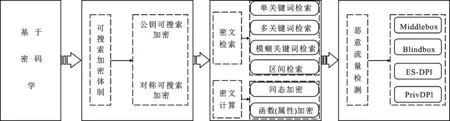
圖4 基于密碼學的惡意流量識別體系
3.1 可搜索加密體制
可搜索加密體制分為對稱可搜索加密體制和公鑰可搜索加密體制。SONG等[82]提出對稱可搜索加密,密鑰擁有者可以查詢檢索密文,但因為對稱密碼本身存在的密鑰管理和分發問題,導致這類方案在密鑰管理的開銷過大。因此,BONEH等[83]提出基于公鑰的可搜索加密受到更為廣泛的關注,該體制中發送者通過接收者公鑰進行關鍵字加密,擁有對應私鑰者可生成陷門進行密文搜索[84]。
3.2 密文檢索和密文計算
基于公鑰可搜索加密的技術難點主要集中在密文檢索和密文計算技術方向上。密文檢索可以通過檢索關鍵詞的方式直接對密文數據進行訪問[85]。密文檢索技術可以通過單個關鍵詞、多個關鍵詞、模糊關鍵詞到區間檢索惡意流量的特征。
單關鍵字檢索復雜度與數據庫的大小呈線性關系。為了提高搜索效率,GOH[86]為每個文檔構建了一個Bloom過濾器,服務器可以使用Bloom過濾器來測試文檔中是否有特定的關鍵字。CURTMOLA等[87]設計了一個基于關鍵字的倒排檢索。在這種結構中,服務器可以直接找到所查詢關鍵字的所有搜索結果。但服務器可能會返回不完整或不正確的結果。因此,KUROSAWA等[88]在每個關鍵字的搜索結果上使用消息驗證碼,確保搜索結果的完整性。
多關鍵詞檢索最早由GOLLE等[89]提出,該方案的檢索復雜度與查詢關鍵字數呈線性關系。為了解決檢索效率低下的問題,CASH等[90]提出了不經意交叉標記方案,搜索檢索由Tset和Xset組成。服務器首先根據Tset檢索匹配文檔數相對最少的搜索結果,然后根據Xset過濾包含其他查詢關鍵字的搜索結果。PAPPAS等[91]提出blind seer方案,樹狀圖上的節點對應Bloom過濾器,節點包括所有子節點中的所有記錄,通過遍歷找到所需的結果。
模糊關鍵詞檢索可以檢索不夠精確的關鍵詞。LI等[92]通過距離來估計兩個關鍵詞的相似度,并利用通配符技術構造了模糊關鍵詞搜索方案。但該方案必須包含所有可能的錯誤關鍵字的檢索,這將導致檢索冗余。GIONIS[93]構造了另一種模糊關鍵字方案,其主要思想是局部敏感散列技術可以以很高的概率將相似的項映射到相同的哈希值。然而,一些正確的搜索結果可能無法檢索到。考慮惡意服務器可能返回錯誤,SUN等[94]提出了一種基于符號樹的可驗證模糊關鍵字搜索方案。該方案支持模糊關鍵字搜索,同時也實現了搜索者對排名關鍵字搜索的可驗證性。
區間檢索[95]是數據檢索的重要方式之一。被授權用戶利用私鑰生成陷門,服務器檢索陷門后返回對應密文,再由用戶解密得到明文。為了確保搜索關鍵詞的可用性,AGRAWAL等[96]提出了基于保序加密的區間檢索,但此方案沒有隱藏關鍵詞的信息,因而存在隱私泄露的風險。CAI等[97]提出了一種單斷言的區間檢索方案,該方案被證明是安全的,不會泄露敏感數據的特征。
全同態加密最早由GENTRY[98]設計完成。全同態加密公鑰方案含有4個算法:密鑰生成算法 (KeyGen)、加密算法 (Encrypt)、解密算法 (Decrypt) 和密文計算算法(Evaluate)。全同態加密的含義是對明文加密后,在密文上進行任意計算,其結果等同于對應明文計算結果,即
ε=(KeyGen,Encrypt,Decrypt,Evaluate),
(3)
f(Enc(μ))=Enc(f(μ)),
(4)
其中,ε表示全同態加密算法,f表示進行任意計算,Enc表示加密過程,μ代表明文數據。
由于全同態加密的特性,使其可以應用在密文檢索技術之中,這樣既可以保證用戶數據的安全,也可以在一定程度上提高密文檢索的效率。
密文計算主要有兩類:一類是同態加密,RIVEST等[99]首次提出同態加密的概念,同態加密可以直接應用于密文操作,并在解密后得到對應的明文;另一類是函數(屬性)加密,SAHAI等[100]提出利用屬性基加密(ABE)方案,用戶信息由用戶屬性組成,從而實現密文訪問控制。LI等[101]提出了一個新的安全外包ABE系統,該系統同時支持安全外包密鑰發布和解密。該構造以有效的方式提供了外包計算結果的可檢查性。SHAMIR[102]提出利用身份基加密(IBE)方案,用戶身份即為公鑰,解決公鑰認證繁瑣的問題。王贇玲[103]提出支持服務器端解密匹配的匿名屬性基加密方法,在不泄露用戶屬性的前提下進行高效檢索。
3.3 惡意流量檢測
目前的可搜索加密技術主要應用于數據庫上,在保證數據機密性的同時實現密文數據的高效檢索。雖然這項技術與在加密流量上檢索特征具備一定的相似性,但是可搜索加密技術不能直接應用于流量檢測,其原因是加密流量檢測工作在應用層或者TCP/IP層中,需要在用戶數據保護、加密規則保護、密鑰管理、檢索算法效率等方面進行深度融合。首先,可搜索加密技術雖然可以防止用戶數據泄露,但是無法保證用戶掌握檢測規則后通過混淆來逃避檢測。將可搜索加密技術應用于流量檢測的同時還需要保護加密規則不泄露。此外檢測效率的問題也制約了可搜索加密在惡意流量檢測上的應用。其次,可搜索需要密鑰,規則保護也需要密鑰,這兩種密鑰生成與管理不是簡單的協議組合,需要嚴格的密碼學意義上的安全協議來保證,同時還需要和網絡中間盒(Middlebox)上的流量檢測協議深度融合。最后,惡意流量識別需要高效的算法,否則過高的設置延遲和開銷大小在實際應用中是不現實的。因而學者開始探索如何行之有效地在Middlebox上檢索惡意流量的模糊特征以識別惡意流量。
網絡中間盒(Middlebox)是大型網絡的一部分,實現與安全性(例如防火墻和入侵檢測)和性能(例如緩存和負載平衡)相關的多種功能。Middlebox通過執行深度包檢測(DPI)以檢測網絡流量中的異常和可疑活動,然而一旦數據包以加密的方式發送,Middlebox即面臨失效,因為深度包檢測需要對有效負載進行分析,而Middlebox沒有權限解密有效負載。文獻[106-113]通過采用密文檢索的相關技術,以Middlebox技術為基礎,提出了對加密數據包上進行模糊關鍵詞檢索,以檢測加密流量中的惡意流量。
Middlebox需要以不解密負載的方式執行深度包檢測以保護用戶數據,但迫于硬件設備不足的壓力,Middlebox需要在不可信的外包設備上進行運算。為了保護用戶數據不被惡意泄露,GOLTZSCHE等[104]設計了Endbox系統,Endbox允許在不可信的客戶端機器上安全地部署和確保Middlebox功能。該系統允許將部分Middlebox功能外包給用戶,利用用戶的CPU資源進行計算。HUNT等[105]設計了Ryoan,通過沙箱保護系統免受潛在的惡意攻擊和防止用戶數據泄露,并允許各方在不信任的基礎架構上以分布式方式處理敏感數據,但目前沙箱的安全性暫未得到有效證明。文獻[104-105]雖然使用分布式和沙箱的方法保護了用戶隱私,但是沒有實現對加密規則的保護,因此無法識別出用戶的惡意行為。
保護用戶數據隱私的同時也需要對加密規則進行保護,因為加密規則一旦泄露,用戶就可以繞過規則檢測,使得Middlebox失效。為了能夠同時實現Middlebox的功能性和對加密規則的保護,YUAN等[106]設計了一個安全的DPI系統,使外包的Middlebox能夠對加密流量進行深度數據包檢查,而不需要揭示包的有效載荷或檢查規則。該系統建立了一個高性能的加密規則過濾器,過濾器安全地存儲從規則中提取的加密字符串對,并對從數據包有效負載中提取的隨機令牌進行加密檢查。該系統實現了同時對數據包有效負載和檢查規則的保護。SHERRY等[107]提出BlindBox,這是第一個同時提供Middlebox的功能性和加密的隱私性這兩個屬性的系統。具體而言,BlindBox利用亂碼電路生成加密規則,直接對加密流量進行深度包檢測而無需對底層流量進行解密。通過這樣的方法,BlindBox既可以進行深度包檢測,又不需要獲取過多的負載信息,保護了用戶的隱私。文獻[106-107]保護了加密數據和加密規則,但在實際應用中,每個會話都需要設置加密規則,這導致了設置延遲和開銷大小都很高,并且由于通信只能在生成加密規則之后才能開始,所以這種延遲在許多實時應用中是不可容忍的。
為了最大限度地減少設置階段的計算和通信開銷,許多研究者開始探索更好的加密規則生成算法和密鑰管理方法以同時保持BlindBox相同的屬性和隱私要求。REN等[108]提出了一種高效安全的深度包檢測方案ES-DPI。該方案中網關對數據包中的位串進行令牌化,同時混淆加密令牌的位置順序以防止令牌位置順序泄漏導致的問題,并對令牌進行加密以保護隱私。中間盒部分利用兩個非共謀云服務器進行規則匹配:令牌過濾服務器過濾掉大多數不匹配的令牌,規則匹配服務器執行單個關鍵字搜索,以確定是否有任何單個規則的關鍵字匹配,在保護包負載和中間盒規則的同時實現數據效用。該方案中加密規則集的安全性建立在文獻[109]的基礎之上,同時使用了文獻[110]中的協議以防止中間人攻擊。NING等[111]提出基于模糊規則的深度包檢測技術PrivDPI,通過模糊規則為每個會話產生新的加密規則。該方法規則生成快而且會話開銷小,并且同樣滿足深度包檢測和隱私要求。另外,PrivDPI中采用了高效的密鑰管理方案:用戶和服務器通過TLS握手協議生成會話密鑰Sk,Sk基于偽隨機數發生器生成另外3個密鑰。其中,kTLS用于加密流量,k用來生成可重用的模糊規則和會話規則,krand用做生成隨機數的種子。該方案在隨機預言機(Random Oracle)模型下給出了嚴格的密碼學安全證明。
PrivDPI的優勢在于:MB無需學習客戶C和服務器S的密鑰,而C和S也無需學習MB的規則,保證了數據通信與規則的安全和隱私。MB只需要生成一次模糊規則,就可以通過重用來為每個新會話生成加密規則,有效地減少了規則準備中的計算和通信開銷。該方法與BlindBox相比,計算規則生成快而且會話開銷小,并且同樣滿足深度包檢測和隱私要求。PrivDPI流程如圖5所示。
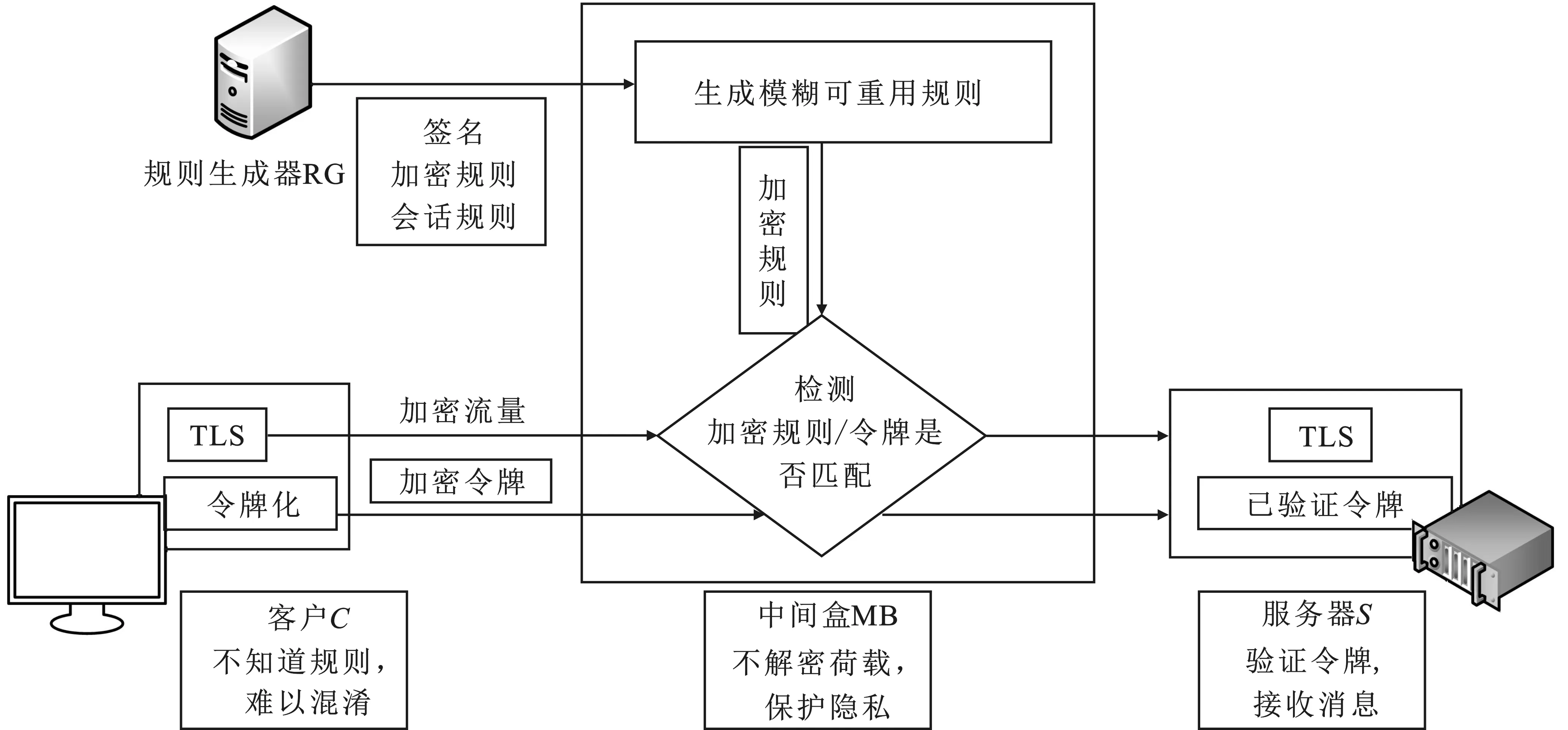
圖5 PrivDPI示意圖
PrivDPI有兩個數據流,一個是TLS會話,客戶C和服務器S通過TLS握手協議建立會話密鑰。另一個基于滑動窗口將數據令牌化,生成加密令牌Cti:
Cti=H(salt+cti,Tt),
(5)
其中,Cti表示哈希后的加密令牌;H表示哈希函數;cti表示計數器;salt表示隨機數,其通過在密文任意固定位置插入隨機字符串,改變密文散列結果以防止頻率分析攻擊;Tt表示加密令牌,其基于以下公式計算出:
Tt=gkαt+k2,
(6)
其中,g表示規則生成器RG生成的參數,α表示隨機數,k表示會話密鑰,t表示準備階段的令牌。
隨后MB生成加密規則Cri:
Cri=H(salt+cri,Ii),
(7)
其中,Cri表示哈希后的加密規則,Ii表示可重用模糊規則。
中間盒通過RG生成的規則元組,建立一組可重用的模糊規則Ii:
Ii=gkαri+k2,
(8)
其中,ri表示規則生成器RG提供的初始規則。
隨后MB檢查Cri是否匹配Cti;如果二者匹配,則認為流量是惡意的。
PrivDPI不能直接應用于物聯網的場景,因為物聯網環境大多采用一對多或者多對多的通信模式。如果采用PrivDPI中一對一的握手方案,則產生的通信開銷是巨大的;此外,相應的密鑰生成和管理同樣會帶來巨大開銷。為此,文獻[112]提出了一種基于群組密鑰協商的物聯網加密流量檢測方案(GKA_DPI)。GKA_DPI使用BlindBox框架進行深度流量檢測,并通過動態組密鑰協議降低功耗,在不解密消息的情況下檢測惡意流量,保證傳感器網絡通信的安全性。該文同時在物聯網中廣泛使用的協議消息隊列遙測傳輸協議(MQTT)上證明了GKA_DPI更適用于物聯網群組通信,并能有效保證傳感器網絡通信的安全性和前向/后向保密性。
然而上述方案本質上是靜態的,因為檢測規則一經確定就無法隨意更改,添加任何規則都需要大量的預處理步驟和協議的重新實例化。為此,NING等[113]提出了改進方案Pine,在沒有任何客戶端參與的情況下,通過網關設備在本地執行規則添加過程。Pine允許動態添加新的規則而不影響連接,同時減小了用戶與服務器之間建立TLS連接的計算時間和通信開銷,并通過屬性規則隱藏保證了規則的隱私性不受中間盒設備的影響。從目前公開發表的文獻看,Pine在效率上達到了最高。
4 總 結
加密流量中的惡意流量識別問題是當前網絡安全領域的熱點和難點。筆者綜述了最新的相關工作,將其分類為基于機器學習和基于密碼學的兩類識別框架,并對兩大類的相關工作進行了總結。目前的工作已經在分類效率上與可證明安全取得了較大進展,但是還存在以下問題。
(1) 基于機器學習的惡意流量識別核心在于正確的數據集,正如開源數據集ImageNet[114]和 COCO[115]為計算機視覺領域的突飛猛進提供了重要支持。加密流量也需要一個開源、有正確標簽并且在惡意流量上有詳細分類的數據集。另外,QUIC[116]/HTTP 3[117]等新型協議的出現使得流量數據包中頭部的明文占比進一步下降,這對基于機器學習的惡意流量識別帶來了進一步的挑戰。
(2) 機器學習領域對抗樣本的飛速進展使得流量混淆與偽裝的難度進一步降低,攻擊者可通過學習流量數據,添加合適的噪聲將攻擊流量偽裝成正常流量,甚至誤導模型將正常流量識別為攻擊流量;另外,基于機器學習的惡意流量識別能力會隨著時間流逝而逐漸下降,同時在訓練/測試集中的惡意流量分布必須符合現實分布[118]。如何應對流量混淆和時間衰減等問題將是下一步的研究重點。
(3) 目前的基于密碼學的惡意流量識別建立在關鍵詞搜索之上,其本質上類似黑/白名單機制,攻擊者可通過混淆技術改變自己惡意特征的關鍵詞,從而混淆與正常流量的邊界,達到逃避檢測的目的。因此如何行之有效地應對加密流量混淆技術,將成為下一步的研究重點之一。
(4) 基于中間盒的深度包檢測技術在加密規則生成、數據包令牌化和加密規則匹配上都需要高效安全的算法支撐,否則過高的設置延遲和運算開銷在實際應用中是不現實的。而全同態加密算法將為基于密碼學的惡意流量識別技術帶來新的曙光。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
Coco薇(2017年11期)2018-01-03 20:59:57
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
