面向位置聚合的泛在地圖信息分類模型
2021-06-29 00:28:38王光霞田江鵬
測繪學報 2021年6期
王 思,王光霞,田江鵬
信息工程大學地理空間信息學院,河南 鄭州 450052
信息分類是人類思維所固有的一種活動,是人們日常生活中用以認識、區別和判斷事物的一種邏輯方法[1]。人們通過對現有的信息和知識的提取、組織、分類和管理之后才能對信息進行有效的認識和使用。地圖學和GIS中,地理信息按照一定的原則和方法進行分類和編碼,建立了特定的通用或專用地理信息分類體系,以便于地理信息的存儲、檢索、管理、分析與共享。地理信息分類是地理數據得以綜合分析和共享利用的重要基礎。
在ICT和大數據技術的推動下,地圖學發展迎來了空前的機遇與挑戰[2-3]。伴隨著信息量的急劇增長,地理信息逐漸表現出實時性強、空間覆蓋面廣、來源多、體量大、復雜度高、碎片化和不確定性等特點,呈現出“時空泛在”[4]的新質特征。地圖作為表達和傳輸地理信息的重要工具,也開始呈現“泛在化”的發展趨勢[5-6]。與傳統地圖類似,泛在地圖可認為是在地圖投影、制圖綜合和地圖可視化支撐下對地理對象、現象、過程等從現實空間到地圖空間的映射[7],具備傳輸和表達地理信息的功能[2]。所不同的是,泛在地圖對傳統地圖進行了進一步的拓展,表現出更加包羅萬象的內涵和特征。特別是在時空大數據[3]的背景下,更加強調其信息價值大、復雜但稀疏[8]、實時性強等特點。因而,如何在信息層面抽象泛在地圖的本質特征,抓取泛在地圖的信息維度,實現泛在地圖信息的科學分類和管理,已經成為地圖學面向泛在化發展而衍生的新問題。
構建泛在地圖信息的分類體系,旨在為如何認識和理解泛在地圖,以及如何管理和使用泛在地圖提供依據與規范。泛在地圖信息的大數據特點使得其難以直接套用傳統地理信息分類方法,需要對泛在地圖信息的特征、分類模型等基本問題進行重新思考。針對這一需求,本文提出一種面向位置聚合的泛在地圖分類模型,希冀以此來探究泛在地圖的信息維度本征。
1 現狀分析
地理信息分類在一定時期內已經形成了相對穩定的多級分類標志體系和模型[9],并作為一種概念模型長期以來支撐了地圖和GIS的發展。傳統地理信息分類主要依托專家的知識和經驗構建地理信息分類的原則、方法和標準規范,采用規范的術語和清晰的層級關系描述地理要素,屬于專家分類法(taxonomy)的范疇。在諸如《GB/T13923—2006基礎地理信息要素分類與代碼》等標準形成之后,分類問題逐漸面向語義一致性方向發展,出現了基于本體的地理信息分類[10-11]和基于形式語義的地理信息分類[12]等研究,旨在達成不同領域分類體系之間的共享與互操作。從廣義的信息學視角來看,地理信息分類可認為是信息分類的一個具例,但將地理信息分類與信息學分類進行比較分析,可以發現地理信息分類存在下述不足:
(1) 面向網絡地理信息資源的分類研究不足。隨著網絡技術的發展,帶有時空標識的泛在網絡資源已經將地理信息由傳統的地理空間全面擴展至社會人文空間,物理域到認知域的擴展使得專家分類法難以適應。突破分類受控詞只能由專家產生的限制,基于用戶協作式創建的標簽實現網絡資源分類的大眾分類法(folksonomy)[13],成為海量網絡信息快速分類的主流方法。雖然Web地圖學和WebGIS已經取得長足的進步,但本質上仍沿用的是傳統地圖信息的分類模型,缺乏真正面向網絡信息資源的地圖信息分類模型與方法的研究。
(2) 缺乏兼容人機各自優勢的分類模型設計。大眾分類法依賴于機器學習的自動分類或者帶有專家驗證的自動分類。而機器分類通常有兩類任務:①構建特定的類別層次;②指定待分類對象在類別層次中所屬的類別[14]。這些任務的實現均依賴于算法抽取的特征。例如,ImageNet借助于圖像的特征標注,已經給出了涉及地圖在內的不同領域的圖像數據分類方案[15]。然而,算法語義與人類語義之間存在鴻溝,機器分類算法獲得的類別層次和分類效果與人的分類結果之間存在一定的差異性。這一問題雖然已經得到部分學者的關注,例如文獻[16]將影像光譜特征語義詞匯與地圖要素分類體系進行結合的研究,但總體上仍缺乏兼容人機各自優勢的分類模型的設計。
2 分類模型
2.1 基本認識約定
(1) 泛在地圖信息:泛在信息的一種類型。泛在信息通常表現為文本、圖表、圖像、音頻、視頻和地圖等模態,泛在地圖信息即以泛地圖[6]形式而存在的信息類型。泛在地圖信息也是專題地圖信息的一種,存在于泛在網絡中用以表示自然和社會人文環境要素的地圖,包括專題內容要素、表示方式和地圖說明信息。
(2) 位置:特指一種擴展的“位置”概念。地圖信息整體上可分為時間、空間和屬性[3]3個維度,傳統上的位置是指空間中的坐標或區域。在時空大數據背景下,單純以空間位置為基本框架來組織和關聯信息,并不能完全滿足全息制圖和表達[17]的需求。位置需由空間維擴展到時間維和語義維,突破笛卡兒幾何空間至多要素相統一的高維語義空間,形成時空和語義為整體的描述能力。對位置進行拓展后,尤其到語義維,能夠突破傳統位置計算的“幾何算法”屬性,可衍化出時間位置、空間位置和語義位置[18]等更為細致的位置分類,共同支撐高維語義空間中的概念、實體及其關系的結構化描述。
(3) 位置聚合:面向時空泛在信息的信息聚合[19-20]模式。泛在信息的復雜稀疏性特點,與越來越精準化、個性化的用戶需求之間形成了矛盾。為解決這一問題,一方面可通過對離散分布、異構無序的多類型“信息碎片”進行篩選、關聯、組織、匯集與呈現[21];另一方面,可采用擴展的位置為框架組織和關聯信息,以全面反映位置本身及其相關的事物或事件的各種屬性。因此,位置聚合是一種以時空泛在信息為對象,以位置為框架關聯信息碎片,以構建專題化地理場景[22]為目標的時空泛在信息應用新模式。
(4) 分類模型:特指用于指導泛在地圖信息分類的理論模型。分類的兩類主要任務[14],使得當前存在構建類別層次的分類模型和對象類別劃分的分類模型;同時,由于研究的層次需求,存在理論模型、數據模型和算法模型等區別。本文瞄準地理信息分類研究中存在的兩點不足,面向位置聚合應用需求,試圖從理論的層次探討泛在地圖信息的分類問題,因此分類模型是一種側重類別層次建模(即泛在地圖信息分類分級)的理論模型。
2.2 分類需求與研究思路
泛在地圖信息分類既需要延續傳統地理信息分類的一般原則和要求,也需要顧及泛在地圖的信息維度特征。歸納起來,需要滿足下述需求:①支撐位置聚合應用——分類模型旨在建立泛在地圖信息的層級化組織結構,實現泛在地圖信息作為一種“大數據”的管理,進而為位置聚合提供信息索引作用;②揭示微內容——泛在地圖信息的稀疏性特點,使得有效揭示和描述其中蘊含的“細粒度”信息碎片成為突出需求,因此其分類應有助于信息碎片的描述;③符合認知結構——泛在地圖信息分類分級結構中,類別之間應有明確、規范和清晰的語義關系,符合人們對地理事物的認知結構;④自動化分類能力——傳統地理信息分類方案制定和分類實施均由人完成,費時費力且更新升級周期長,泛在地圖信息分類需要一種數據驅動、自由靈活、快速迭代的自動化分類方法。
泛在地圖信息分類需求,決定了其分類需要從模型和方法上進行改進和創新。基于現有的研究成果,本文的試圖從以下兩個方面進行改進:
2.2.1 結合專家分類法和大眾分類法的各自優點
專家分類法可以認為是自頂向下的分類模式,而大眾分類法則是立足資源標注的自下而上的分類模式,二者各具優劣,具有互補融合的特點[23]。泛在地圖信息分類不僅需要延續傳統地理信息分類的層級化結構、使用受控詞描述層級語義、符合人的認知習慣等優點,也需要吸納網絡信息資源分類的細粒度語義描述、成本低、周期短、自動化程度高等優點。表1展示了泛在地圖信息分類的具體特點。
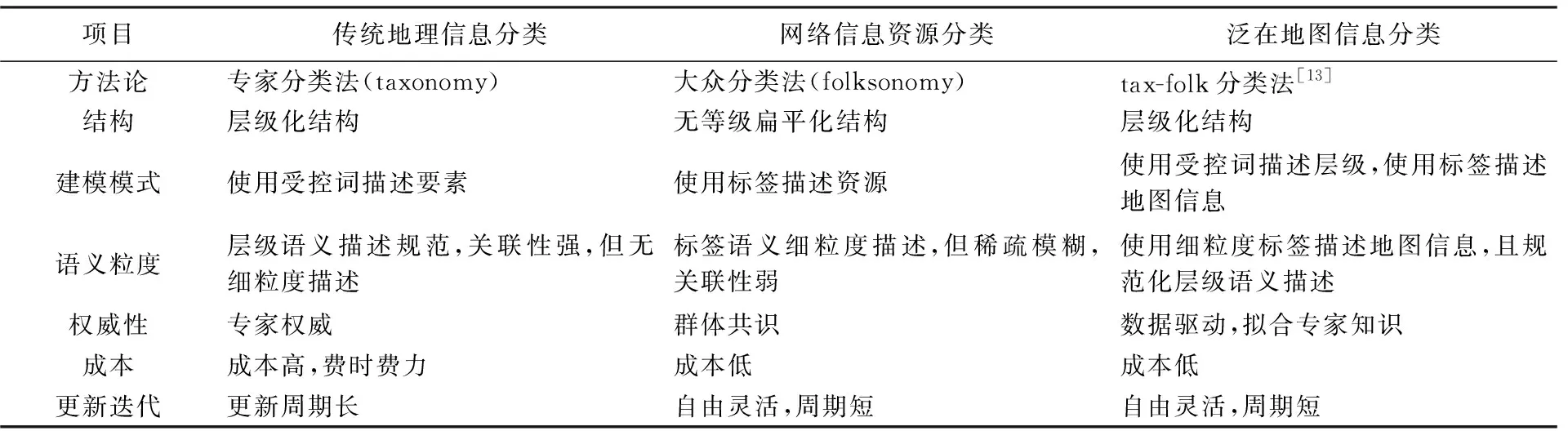
表1 泛在地圖信息分類需融合傳統地理信息分類和網絡信息資源分類的各自優點
2.2.2 耦合認知規律和數據驅動的模型設計
人工分類和機器分類有著各自的優點,人類自古以來就進化出對環境事物的抽象和分類的能力,能夠輕松完成概念化、關系推理和模式識別等任務,而機器則擅長于快速、高精度的數據處理。因此,較為可行的路線是設計耦合人機各自優勢的分類模型,即一方面自上而下,擴展經典地理信息分類中細粒度語義信息的描述能力;另一方面則是自下而上,基于現有機器分類模型在數據和特征層面的算力,拓展其在概念、語義和知識層面的建模能力。
這種設計理念本質上符合“視覺序列→視覺描述?知識模式?認知表達”這一人類理解地圖的認知原理[24],也是縮短算法語義與人類語義之間的鴻溝的有益嘗試。因此,耦合人機各自優勢的分類模型,就是將之前全部由人類認知系統完成的工作,現在部分交由機器去完成——將泛在地圖的數據組織管理、特征抽取、聚類分析等工作交由算法去實現,而人則是在概念術語、分類模式、知識推理等更高層次進行約束。
2.3 模型設計
基于上述設計理念,本文提出了由“實例層→特征層?維度層?主題層”4個層次構成的泛在地圖信息分類模型,如圖1所示。
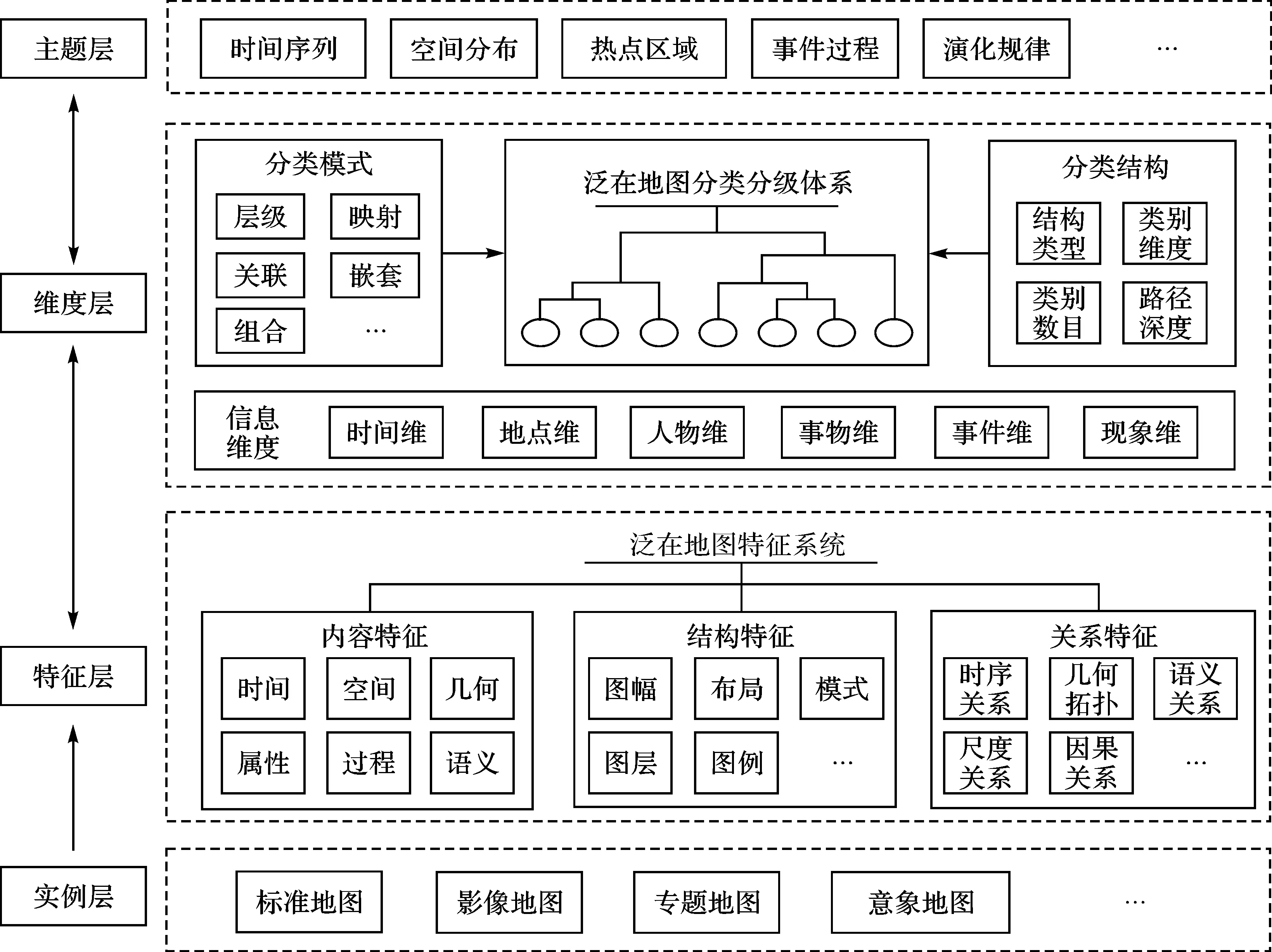
圖1 面向位置聚合的泛在地圖信息分類模型Fig.1 Classification model of ubiquitous map information facing location-based aggregation
2.3.1 實例層
實例層涵蓋了不同類型的泛在地圖實例,是分類的數據基礎。根據地圖的“泛化”程度,可以將標準地圖、矢量地圖、影像地圖、專題地圖和意象地圖(例如旅游心象地圖)等實例納入泛在地圖的分類范圍之內。
2.3.2 特征層
特征層描述了能夠從泛在地圖中抽取的信息碎片的類型和值。泛在地圖的構成和形式較為靈活多樣,圖名、圖例和要素內容等構成元素均可能存在缺省情況,因此特征層的核心任務是建立泛在地圖特征系統,以支撐不同類型泛在地圖的統一特征抽取與要素描述。借鑒適用于描述復雜地理數據的地理信息六要素[25]理念,結合泛在地圖自身特點,本文從內容特征、結構特征和關系特征3個方面構建泛在地圖的特征系統。①內容特征——側重描述地圖中所表達的信息,例如地理對象或現象發生的時間和空間節點(時間定位、空間定位),地理對象的組成和演化結構(幾何形態),地理對象和現象的固有屬性(屬性特征)、地理現象的發生與演化(演化過程)以及基于人類認知的地理特征(語義描述)。②結構特征——側重描述地圖的元數據或幅面構成,例如圖名、副圖名、出版單位、出版時間、圖廓等,可以抽象地概括為圖幅、布局、模式、圖層、圖例等部分。③關系特征——側重描述特征之間存在的定性或定量的關系。泛在地圖需要顯式地抽取和描述這些基本關系,并作為特征記錄下來,例如時序關系(例如正序、逆序、插序)、拓撲關系(例如九元組模型)、語義關系(例如部分整體關系、上下義關系)、尺度關系和因果關系等。
2.3.3 維度層
借鑒文獻[6]的觀點,在分類層級系統中,一個維度實質上就是它的一個側面,同一維度下的具體維度值形成了視角面,不同維度值按照一定規則關聯并疊加組合構成了泛在地圖信息的一個種類。因此,維度是泛在地圖信息的基本量,一個維度實際上代表了信息特征的一個側面,能夠使用不同細化程度的特征予以表示。鑒于泛在地圖信息的社會屬性和大數據特點,由時空信息X和屬性信息Z構成最簡二元組〈X,Z〉的地理信息描述范式[26],已經難以覆蓋泛在信息范疇。因此,引入社會學領域信息分類[27]思想,并借鑒場景學[22]理論,宏觀上將泛在信息劃分為時間維、地點維、人物維、事物維、事件維和現象維6個維度。信息維度的劃分來源于社會學的歸納,在認知層面界定了地圖信息的不同歸屬,是信息層面的范疇劃定,理論上任何粒度或類型的泛在地圖信息均可以劃分到此6個信息維度之中。
信息維度的劃分,為不同特征值提供了類型標注,形成了〈特征,維度〉最簡二元標注單位。分類分級體系通常是一個層次化、結構化的多維層級系統。因此以〈特征,維度〉標注單位為基本信息單元構建泛在地圖信息分類分級,具有以下優勢。一是最簡二元標注單位能夠讓分類分級體系具備多維特征描述特點,這是實現由特征數據(算法語義)到分類分級(人類語義)之間銜接的關鍵。二是采用最簡二元標注單位標注的泛在地圖信息,能夠與擴展的位置(時間位置、空間位置和語義位置等)之間產生深層次的關聯性:時間維信息與時間位置是同質的,地點維信息和空間位置是同質的,人物維、事物維、事件維和現象維信息適宜于使用語義位置進行關聯,這種關聯性是實現信息和位置之間進行關聯和聚合計算的基礎。
基于信息維度,可通過設置不同分類模式、分類結構參數等構建泛在地圖信息的分類分級體系。分類分級體系包含了譜系、模式(schema)和特征等部分。譜系體現了層級化結構,模式體現了受控詞和信息維度之間的關聯關系,而特征則映射了細粒度地圖信息內容。
2.3.4 主題層
主題層描述了面向不同聚合主題的分類需求,例如按照時間序列、空間分布、事件過程、演化規律等主題進行分類。
概括而言,該模型立足泛在地圖信息自身特點,以不同的位置聚合主題為牽引,通過對地圖實例中抽取的信息碎片進行信息維度分析和聚類,構建數據驅動、全面系統、精確合理的泛在地圖信息分類分級體系,為實現海量、多源異構泛在地圖的管理、聚類和分析等提供認知結構保證。本質上,該分類模型將傳統地理信息分類的“實例→維度?主題”模式擴展為“實例→特征?維度?主題”模式,特征層的擴展為機器提供了細粒度語義信息的描述能力,同時也能夠保持經典地理信息分類模型的層級化認知結構,這種擴展是滿足泛在地圖信息分類需求的根本原因。
3 模型驗證
3.1 驗證方法
為了驗證泛在地圖信息分類模型,本文設計并實現了一種泛在地圖信息分類建模方法,技術路線如下:①輸入泛在地圖數據集;②主題特征標注——面向位置聚合主題需求,以〈特征,維度〉為基本單元抽取泛在地圖中的特征信息并標注信息維度;③特征頻率矩陣構建——將不同信息維度的非結構化特征數據映射到統一的向量空間中;④層次聚類——基于特征頻率矩陣進行層次聚類計算,建立泛在地圖信息分類分級體系;⑤輸出分類分級體系。
3.1.1 主題特征標注
主題特征標注旨在從泛在地圖中抽取出與位置聚合主題相關的特征信息,側重解決兩個問題:
(1) 特征描述框架,即抽取和標注哪些信息。根據分類模型,為了實現非結構化泛在地圖的統一解構,可從特征系統和信息維度兩個方面建立泛在地圖特征描述框架,并抽取獲得〈特征,維度〉基本標注單元。以圖2所示的“薔薇”臺風路徑概率預報圖的標注為例。該圖的結構包括圖名、附圖名、出版單位、發布時間和圖例等,不同的結構可以抽取不同的特征,例如在圖名結構中可以抽取得到〈今年,時間維〉、〈未來48 h,時間維〉、〈“薔薇”臺風,事件維〉、〈路徑概率預報圖,事物維〉等特征。內容結構中主要包括底圖和專題圖層,例如在專題圖層中,可以抽取得到〈8月9日05時,時間維〉、〈概率范圍,地點維〉、〈熱帶風暴,現象維〉、〈薔薇,事件維〉等不同特征值。
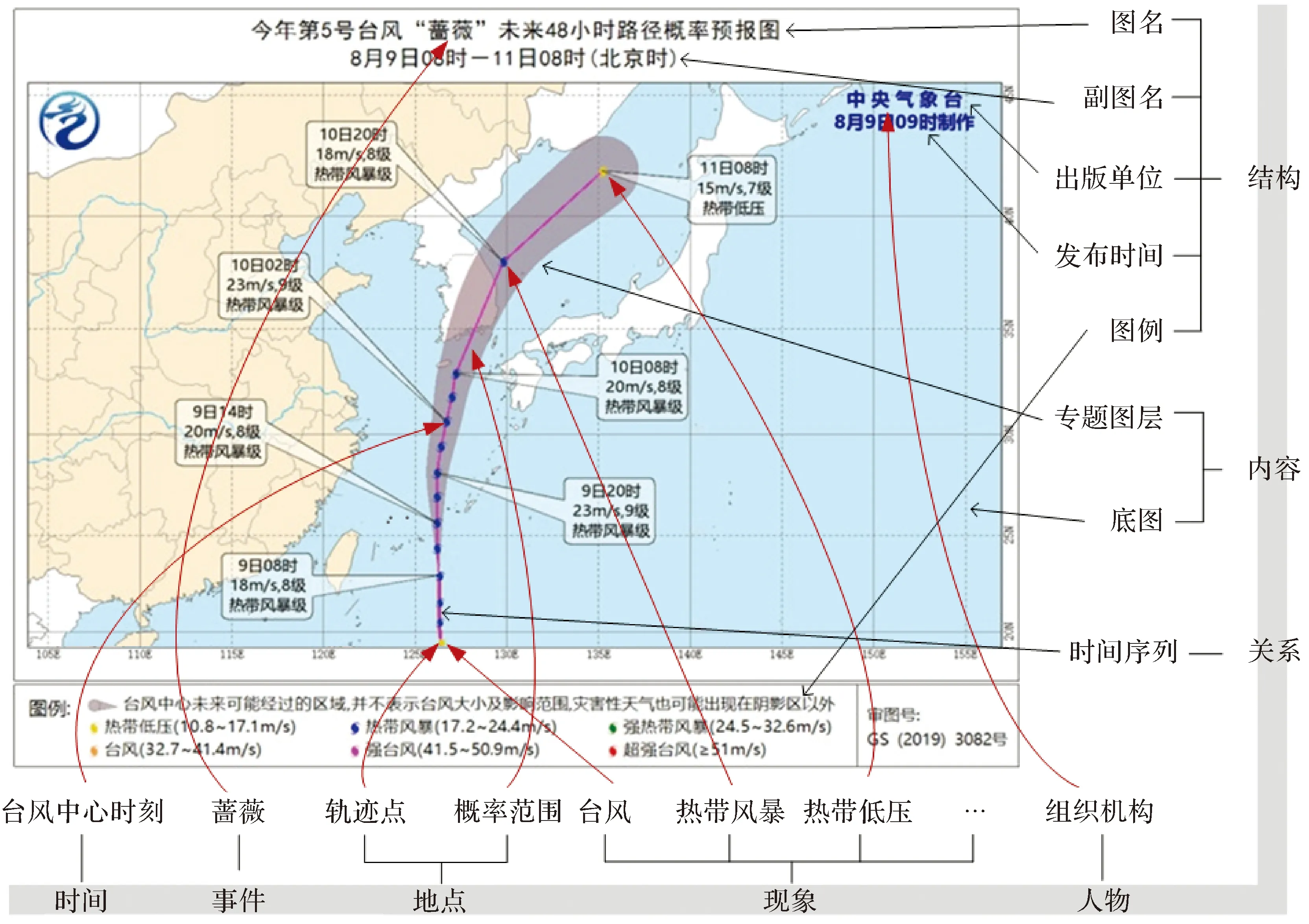
注:本圖僅作地圖樣圖展示,不涉及國家版圖相關問題。圖2 泛在地圖解構與特征抽取示例Fig.2 Deconstruction and feature extraction of ubiquitous map
(2) 主題信息過濾。基于特征描述框架抽取的特征可能覆蓋不同的特征結構和信息維。然而這些特征與位置聚合主題的相關性不盡相同,其能夠發揮出的作用有大有小,部分作用小的特征甚至無法反映地圖的核心信息,在一定程度上會干擾后續地圖信息分類的準確性。因此,在具體的抽取實現過程中,需顧及位置聚合的主題需求,選取出能最能代表地圖主題特色的那部分特征,并作為泛在地圖信息維度抽象的數據基礎。
3.1.2 特征頻率矩陣構建
泛在地圖中抽取的特征,通常是由符號、文字、數字等構成,但這些特征信息通常不能直接參與分類體系構建,需要通過特定的運算轉換形成統一向量空間的表達,以便于后續的聚類計算。特征頻率矩陣是一種特征的向量空間表示,即每個特征項在向量空間某一維度上都采用特定的數值表示,使得符號、文字、數字等形式的特征值能夠統一轉化為向量表示。特征頻率矩陣構建的總體思路如圖3所示。
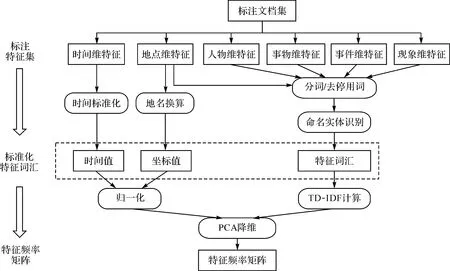
圖3 特征頻率矩陣構建流程Fig.3 Construction process of feature frequency matrix
(1) 對特征值進行規范化處理。時間類特征值通常表現出相對性和模糊性特點,需要將相對時間、時間省略現象等表示為統一的、標準的表達形式。參照時間規范化[28]的方法進行轉換,例如“8月9日05時”可轉換為數值“2020-08-09 T05:00:00”。地點類特征值通常表現為坐標形式和地名形式,具有多級別性、相對性和模糊性等特點。特別對于地名值,一種方法是采用地名解析和換算方法,轉換為坐標數值;另一種方法則是針對無法完成坐標換算的情形,可將其作為自然語言文本進行處理。對于人物、事物、事件和現象類特征值,由于它們通常表現為自然語言描述形式,可采取自然語言處理中的詞袋[29]模型表示,并采取分詞/去停用詞、命名實體識別等技術,計算得到特征詞匯集合。
(2) 生成特征頻率矩陣。對時間值和坐標值采用歸一化、特征詞匯采用TF-IDF[30]計算方法,獲得標注文檔的全部特征頻率矩陣。初步獲得的特征頻率矩陣通常具有高維、稀疏的特點,為提高后續分類計算效率,還需對其進行降維計算。降維是在保證向量空間基本特性不變的前提下,將高維度的特征空間映射到一個較低維度的空間中。本文采用主元分析(PCA)[31]降維計算方法,獲得最后的低維度的特征頻率矩陣。
3.1.3 基于層聚類分析的分類分級體系生成
以特征頻率矩陣為基礎,可以通過聚類分析將特征區分為不同的類別,不同的類別又可進一步通過聚類分析區分為更高層次的類別,如此不斷迭代收斂,最終可獲得基于特征值的泛在地圖信息分類分級體系。
本文基于BIRCH算法[32]實現分類維度聚類,并使用LDA(latent Dirichlet allocation)算法對每一個聚類簇進行主題提取,算法描述如下。
輸入:特征頻率矩陣weight,特征字典dict,距離閾值T,分支數量約束B
輸出:帶有節點主題標簽的CFTree
(1) 將特征頻率矩陣weight轉化為向量{v1,v2,…,vn}
(2) 初始化CFTree,使其根節點為一個空的node
(3) forviin {v1,v2,…,vn}
尋找CFTree中與vi距離最近的節點node(k)以及距離d(i,k)
ifd(i,k)≤T
將vi插入到節點node(k)中,計算node(k)節點數num(k)
if num (k)≤B
更新node(k)節點到根節點路徑上的所有結點的(N,LS,SS,TAG)值
else
分裂node(k)為兩個新節點node(k1)和node(k2),按照距離重新分配node(k)中的向量
更新node(k1)和node(k2)到根節點路徑上的所有結點(N,LS,SS,TAG)值
else
創建一個新的節點node并插入node(k)之中,將vi插入到節點node中
更新node節點到根節點路徑上的所有結點的(N,LS,SS,TAG)值
(4) 遍歷CFTree所有節點,基于TAG值自底向上對每個節點使用LDA算法獲得主題標簽
(5) 打印輸出CFTree
BIRCH算法是典型的聚類算法之一,能夠通過拆分特征向量構建樹狀層次結構,較好地適應本文的聚類需求。根據BIRCH算法原理,本文對聚類特征樹(cluster feature tree,CFTree)進行了改進設計,將樹中每一個節點由(N,LS,SS)三元組擴展為(N,LS,SS,TAG)四元組,使得特征個數N、特征之和LS以及特征的平方和SS 3個參數用于樹的構建,TAG記錄當前節點包含的特征值,用于當前節點主題的計算。
3.2 試驗與分析
3.2.1 數據說明
地圖的泛在性體現在數據來源、內容信息和表達形式等方面。為了驗證分類模型的可行性,本文圍繞地圖內容信息的泛在性,通過網絡爬蟲構建了一個以各類圖像格式為主的泛地圖數據集。數據集包含地圖共計1605幅,表2按照分類模型的實例層對所收集的地圖數據進行了歸納,并結合地圖實例進行了說明。數據集的信息內容涉及行政區劃、經濟生產、交通出行、人文旅游、自然資源、日常生活等多個方面,特別是手繪地圖、語義地圖和知識地圖等這類非標準化但廣泛存在于社會媒介中的地圖實例的納入,力圖體現對地理空間和社會人文空間的覆蓋。

表2 試驗數據說明和統計
3.2.2 分類體系生成
為了驗證面向特定主題的地圖數據特征標注和分類分級建模方法的可行性,并展現建模過程細節,從專題地圖數據集中按照氣象主題選取的部分地圖實例,涵蓋臺風事件、大風/降水預報、干旱、火險等專題內容進行試驗。圖4為按照分類建模的流程,取距離閾值T=1.8,分支數量約束因子B=8的分類體系效果圖。

圖4 氣象主題分類體系生成效果Fig.4 Generation result of the meteorological theme classification system
分類體系展現了整體的分類結構和分類節點的細節信息。本試驗結果共分為3個層級:層級Ⅰ為一級聚類節點,層級Ⅱ為二級聚類節點,層級Ⅲ為三級聚類節點。每一個節點中均包含了LDA算法獲得的按照概率排序的主題特征,例如“0.045*臺風”表示臺風主題的概率為0.045;帶有下劃線的是專家分類受控詞,通過主題特征詞匯匹配獲得。
定義準確率(P)=分類簇中正確的地圖數/分類簇中地圖總數,召回率(R)=分類簇中正確的地圖數/分類簇中應有的地圖數,F1=2PR/(P+R)。對不同層級的分類結果進行評價,計算每一分類層級準確率、召回率和F1值的均值,結果見表3。
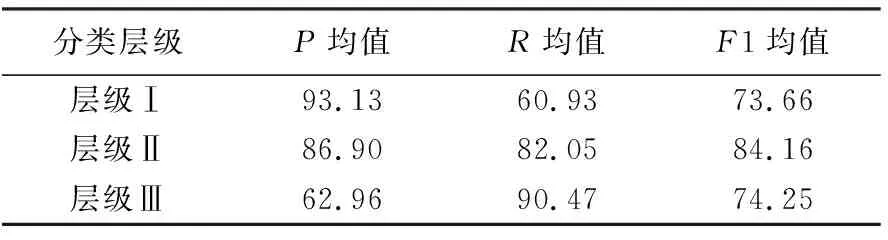
表3 不同分類層級的評測
試驗結果表明:①層級Ⅰ為直接分類簇,93.13%的P均值表明地圖實例得到較好的分類,但層級Ⅰ的R均值不高,其原因在于同一類型信息易被劃分為多個分類簇,例如臺風、干旱、冰雹雷暴分類簇;②隨著分類層級的遞增,P均值整體下降表明聚類性能逐級遞減,但R均值整體上升表明分類簇的語義綜合度得到一定的保證;③所有分類層級的F1均值均保持相對穩定水平,表明試驗能夠取得一定的分類分級效果,但仍存在進一步優化和提高的空間。
4 結 語
本文從泛在地圖的位置聚合應用需求出發,提出了一種泛在地圖信息分類模型,并通過相關試驗進行了驗證。該分類模型本質上是一種認知規律約束下數據驅動的分類體系自動建模,對泛在地圖數據分類、管理、分析和應用等具有參考價值。
本文的研究意義包括2個方面。一是能夠推進從海量泛在地圖數據中挖掘地理信息分類體系的自動化處理水平;二是能夠進一步改變地理信息分類模式,特征層將算法語義和人類語義有效銜接起來,使得傳統上由人類專家完成的認知分類模式,變為人機協作、甚至完全智能化的地理信息分類模式。
本文的局限性包括3個方面。一是特征抽取的有效性。精準、快速挖掘泛在地圖中的信息塊,并重建信息塊之間的關聯關系,需要進一步構建泛在地圖的理解模型,以及基于深度學習算法的高效自動標注方法。二是信息維度聚類算法的參數調優。例如BIRCH算法的參數B和T,對聚類的結構、分類粒度和收斂性等均具有重要影響,B和T參數如何調優并能夠解釋其實際意義,特別是對于不同量級和規模的數據集,乃是需要進一步研究的問題。三是分類結果的有效性。驗證方法雖然能夠得到分類分級結構,但相較于傳統地理信息的分類受控詞,其語義精準度還需進一步提高。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
