基于CGRA的神經(jīng)網(wǎng)絡(luò)高效數(shù)據(jù)流設(shè)計(jì)
2021-06-28 08:50:48李澤豪程利甫蔣仁興柳宜川王琴
電子測(cè)試 2021年1期
關(guān)鍵詞:特征設(shè)計(jì)
李澤豪,程利甫,蔣仁興,柳宜川,王琴
(1.上海交通大學(xué)電子信息與電氣工程學(xué)院,上海,200240;2.上海航天電子技術(shù)研究所,上海,201109)
0 引言
近年來(lái),人工智能已經(jīng)深入到人們生活中的每一個(gè)角落,現(xiàn)有的各類(lèi)神經(jīng)網(wǎng)絡(luò)架構(gòu)的計(jì)算量級(jí)達(dá)到了GB級(jí)別,網(wǎng)絡(luò)中權(quán)重個(gè)數(shù)也在百萬(wàn)數(shù)量級(jí),這導(dǎo)致對(duì)神經(jīng)網(wǎng)絡(luò)運(yùn)算的硬件載體的算力和存儲(chǔ)帶寬要求更加嚴(yán)格。傳統(tǒng)的基于馮諾依曼結(jié)構(gòu)的CPU已難以滿足要求,GPU和專(zhuān)用集成電路雖然可以大幅度提升運(yùn)算速度,但分別由于功耗問(wèn)題和靈活性問(wèn)題導(dǎo)致其適用范圍比較局限,因此兼具靈活性和低功耗的粗粒度可重構(gòu)架構(gòu)[1][2]逐漸成為了研究熱點(diǎn)。
本文結(jié)合了脈動(dòng)陣列的思想,設(shè)計(jì)了神經(jīng)網(wǎng)絡(luò)核心算法各個(gè)尺寸卷積操作的高效數(shù)據(jù)流,在保證PE利用率和運(yùn)算吞吐率的同時(shí)保證了配置的可重用特性。
1 通用CGRA陣列架構(gòu)
粗粒度可重構(gòu)架構(gòu)的核心計(jì)算資源是通過(guò)可重配置的互連網(wǎng)絡(luò)連接而成功能單元陣列,如圖1所示,可以將應(yīng)用中的計(jì)算密集型任務(wù)、控制密集型任務(wù)或是數(shù)據(jù)密集型任務(wù)放置與陣列中進(jìn)行硬件加速。

圖1 通用CGRA架構(gòu)
本文搭建的CGRA架構(gòu)中有4個(gè)相同的PEA陣列,每個(gè)PEA陣列由64個(gè)異構(gòu)PE組成,處理單元包括ALU、LSU、MUL、MAC等功能,如圖2所示。可以看到,每個(gè)PE有四根輸入線,分別是32bits位寬的IN1、IN2、IN3,以及1bit位寬的單比特控制信號(hào)IN4,輸出有三根數(shù)據(jù)線,分別是32bits位寬的OUT1和OUT2,以及1bits位寬的輸出控制信號(hào)線。Opcode輸入控制PE功能與外部線連接。其中具有LSU功能,能夠訪問(wèn)片上存儲(chǔ)的PE單元分布在陣列四周。

圖2 卷積窗口3*3數(shù)據(jù)流(a)權(quán)重參數(shù)(b)輸入特征圖數(shù)據(jù)(c)卷積部分和
1.1 陣列路由層次結(jié)構(gòu)
目前的CGRA架構(gòu)設(shè)計(jì)中,往往會(huì)在mesh結(jié)構(gòu)的基礎(chǔ)上,擴(kuò)展PE的互連能力[4][5],使得PE能夠與不相鄰的PE進(jìn)行數(shù)據(jù)傳輸,從而使PE陣列更適合流式處理以達(dá)到更高的吞吐率。
本文所搭建的粗粒度可重構(gòu)架構(gòu)中,處理單元陣列尺寸為8*8,陣列由64個(gè)異構(gòu)處理單元組成。陣列邊沿的PE可以與之橫向或者縱向距離為3以內(nèi)的PE進(jìn)行單周期的數(shù)據(jù)傳輸,并能夠與其距離為7的PE進(jìn)行單周期數(shù)據(jù)傳輸。
1.2 陣列存儲(chǔ)層次結(jié)構(gòu)
目前針對(duì)神經(jīng)網(wǎng)絡(luò)這類(lèi)數(shù)據(jù)密集型和計(jì)算密集型的應(yīng)用,往往會(huì)給每個(gè)PE配備一個(gè)單獨(dú)的存儲(chǔ)塊[3]用于存儲(chǔ)頻繁使用的操作數(shù)或者存儲(chǔ)臨時(shí)數(shù)據(jù),以降低花費(fèi)在訪問(wèn)外部存儲(chǔ)中的時(shí)間。通用目的架構(gòu)為了在各個(gè)應(yīng)用場(chǎng)景達(dá)到最高的平均能效,往往不會(huì)單獨(dú)為每個(gè)PE配置較大的存儲(chǔ)空間,替代的則是小型用于少量局部數(shù)據(jù)存儲(chǔ)的LR(local register),本文所用架構(gòu)的局部寄存器為每個(gè)PE提供了深度為16,位寬為32bits的可利用空間。
8*8的陣列結(jié)構(gòu)被分為了四塊,每一塊配備了深度為8的,可供16個(gè)PE同時(shí)訪問(wèn)的區(qū)域寄存器,以實(shí)現(xiàn)區(qū)域性的數(shù)據(jù)傳輸。另外,所搭建的架構(gòu)提供了可供陣列上所有PE訪問(wèn)的8個(gè)全局寄存器。
2 數(shù)據(jù)流設(shè)計(jì)
2.1 陣列卷積設(shè)計(jì)
卷積所實(shí)現(xiàn)的功能類(lèi)似于濾波操作,通過(guò)Nout個(gè)大小為w* h * Nin的三維卷積核W,在輸入特征圖I上以固定步長(zhǎng)的滑窗操作遍歷整個(gè)輸入特征圖,每次滑窗操作會(huì)將卷積核各個(gè)位置的權(quán)重與其在特征圖中的數(shù)據(jù)相乘,再將所有乘數(shù)相加得到輸出特征圖A中的一個(gè)數(shù)據(jù),過(guò)程可表示為:

公式中?代表一次二維卷積操作,B為偏置。目前主要的卷積窗口尺寸分別為3*3、5*5以及7*7,因此主要針對(duì)這三種卷積窗進(jìn)行映射數(shù)據(jù)流設(shè)計(jì)。
對(duì)于3*3尺寸的卷積操作,每次計(jì)算實(shí)際上需要18個(gè)獨(dú)立的操作數(shù),主要使用到的計(jì)算為乘加運(yùn)算,完成一個(gè)卷積結(jié)果的輸出需要9次乘法和8次加法。在映射方案中,考慮到18個(gè)操作數(shù)中的權(quán)重所占的9個(gè)操作數(shù)可以重復(fù)利用,這部分操作數(shù)則預(yù)先通過(guò)配置放到了每個(gè)PE獨(dú)有的Local Register中,待遍歷完輸入特征圖之后再更新,這使得每次運(yùn)算需要的新操作數(shù)從18個(gè)降低為9個(gè)。圖2(a)為更新各個(gè)PE的Local register的更新路徑,由綠色線條表示。模擬卷積操作的滑動(dòng)窗口的滑動(dòng)狀態(tài),可以發(fā)現(xiàn)相鄰兩次滑動(dòng)窗口中有6個(gè)數(shù)可重復(fù)利用,應(yīng)用到PE陣列中,設(shè)計(jì)方案使用脈動(dòng)陣列的方式來(lái)模擬滑動(dòng)窗口的滑動(dòng)過(guò)程,在傳遞單次乘法計(jì)算結(jié)果的同時(shí)通過(guò)OUT2輸出接口傳遞IN1的輸入數(shù)據(jù),這種數(shù)據(jù)傳輸方式,只需要逐周期傳入輸入特征圖的3行數(shù)據(jù),將前幾個(gè)周期傳入的輸入數(shù)據(jù)繼續(xù)保留在陣列中傳輸,待流水線填充完成則可以將單個(gè)卷積結(jié)果所需要的新數(shù)據(jù)降低到3個(gè)。計(jì)算模式如圖2所示,計(jì)算結(jié)果從左至右傳遞,原始計(jì)算操作數(shù)從上至下傳遞,紅色線條為計(jì)算結(jié)果輸出路徑,藍(lán)色線條為原始操作數(shù)通過(guò)脈動(dòng)陣列傳輸?shù)穆窂健?/p>
輸出的3個(gè)部分和使用額外的兩個(gè)PE做加法完成整個(gè)二維卷積窗口的計(jì)算結(jié)果,但脈動(dòng)陣列的處理方式下,這3個(gè)結(jié)果之間相隔5個(gè)周期,無(wú)法通過(guò)簡(jiǎn)單的路由完成周期對(duì)齊。為解決這個(gè)問(wèn)題,設(shè)計(jì)了通過(guò)LR加上一個(gè)簡(jiǎn)單路由功能PE可以完成5周期的緩沖PE。
這種計(jì)算模式下,數(shù)據(jù)的初始填充間隔周期為56個(gè)周期,流水線填充完畢后,每個(gè)周期可輸出一個(gè)卷積計(jì)算結(jié)果。并且將訪存帶寬需求縮小為原有需求的1/6,可以大幅度降低訪存功耗,PE利用率達(dá)98.4%,有效計(jì)算PE占比達(dá)70%。5*5和7*7卷積窗口的數(shù)據(jù)流設(shè)計(jì)思路與上述類(lèi)似。
2.2 陣列池化設(shè)計(jì)
池化層實(shí)質(zhì)為一個(gè)下采樣層,目的是降低特征圖的尺寸以實(shí)現(xiàn)特征圖的主要特征提取,并同時(shí)簡(jiǎn)化網(wǎng)絡(luò)計(jì)算復(fù)雜度。常用的池化算子包括最大值池化和均值池化,池化操作將輸入特征圖分為多個(gè)K*K大小的區(qū)域,將其中的最大值或者區(qū)域內(nèi)數(shù)據(jù)均值作為輸出。
陣列數(shù)據(jù)流設(shè)計(jì)如圖3所示為2*2池化,圖中黑色線條表示傳入的數(shù)據(jù)流,紅色線條表示通過(guò)減法PE得到的單比特控制信號(hào),用于select功能PE選擇數(shù)據(jù)輸出。通過(guò)使用可供片上協(xié)處理器控制的全局寄存器控制功能單元每個(gè)功能的迭代次數(shù)可以完成同一配置在不同尺度輸入特征圖上的共用,可大幅度減少讀取配置所需的訪存時(shí)間和功耗。

圖3 陣列池化數(shù)據(jù)流
2.3 多陣列協(xié)同工作
由于片外存儲(chǔ)數(shù)據(jù)的讀寫(xiě)為數(shù)據(jù)密集型應(yīng)用的瓶頸所在,CGRA的計(jì)算資源和片上存儲(chǔ)大小及數(shù)據(jù)帶寬的不匹配問(wèn)題往往是限制架構(gòu)性能的關(guān)鍵,數(shù)據(jù)帶寬并不能像計(jì)算資源一樣通過(guò)堆疊提高,而片上存儲(chǔ)的增大會(huì)提高芯片功耗。通過(guò)多陣列協(xié)同工作,利用合理的片上數(shù)據(jù)復(fù)用,平衡片外存儲(chǔ)訪問(wèn)與計(jì)算時(shí)間,可以最大化釋放陣列處理單元的計(jì)算能力。
如圖4所示,相鄰的兩個(gè)PEA之間可以共用一個(gè)片上存儲(chǔ)塊,將初始計(jì)算操作數(shù)依次寫(xiě)入各個(gè)片上存儲(chǔ)的同時(shí),依次啟動(dòng)各個(gè)陣列進(jìn)行計(jì)算,使各個(gè)陣列之間形成一個(gè)廣義的流水線,計(jì)算結(jié)果通過(guò)SM1輸出。各個(gè)存儲(chǔ)塊分別有16個(gè)bank可同時(shí)被陣列上的訪存單元讀寫(xiě),通過(guò)地址增加方式的改變,可將片上存儲(chǔ)以8個(gè)bank分為兩組,兩個(gè)PEA陣列在同一時(shí)刻分別訪問(wèn)一組,以乒乓模式對(duì)兩組存儲(chǔ)進(jìn)行讀寫(xiě),可保證在兩個(gè)陣列同時(shí)運(yùn)行時(shí)陣列之間不發(fā)生訪存沖突。

圖4 多陣列協(xié)同工作
3 實(shí)驗(yàn)結(jié)果與分析
為了驗(yàn)證所設(shè)計(jì)數(shù)據(jù)流的性能,本文在VCS上搭建了上述通用粗粒度可重構(gòu)架構(gòu)的RTL仿真環(huán)境。
通過(guò)將64*64尺寸的特征圖分別進(jìn)行3*3卷積、5*5卷積、7*7卷積以及池化窗口2*2的最大值池化,比較在CGRA平臺(tái)和使用Intel Core i5-8500型號(hào)CPU平臺(tái)的運(yùn)行時(shí)間,具體運(yùn)行結(jié)果如表1,發(fā)現(xiàn)針對(duì)各個(gè)尺寸的卷積,CGRA架構(gòu)相對(duì)于CPU架構(gòu)的平均加速比可達(dá)732倍,其中3*3卷積窗口使用了4個(gè)不同的卷積核,因此CPU時(shí)間為單個(gè)卷積核的4倍。對(duì)于2*2池化窗口的最大值池化操作,加速比也可達(dá)412倍。
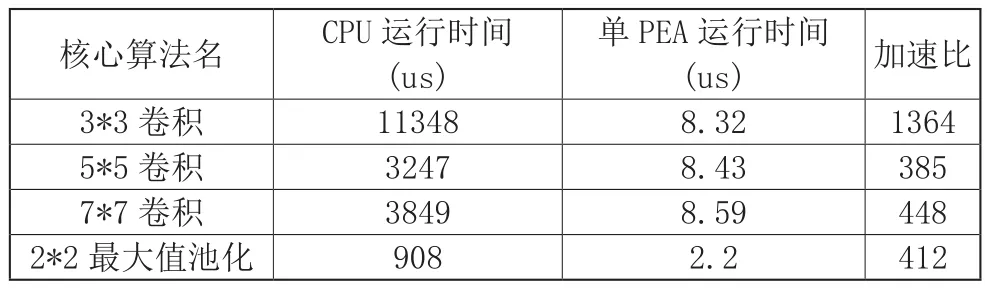
表1 核心算法在單PEA和CPU的運(yùn)行性能比較
在Pytorch平臺(tái)載入AlexNet模型預(yù)訓(xùn)練權(quán)重后,通過(guò)量化將浮點(diǎn)數(shù)轉(zhuǎn)為32bits定點(diǎn)數(shù)據(jù),將AlexNet各個(gè)尺寸的卷積層通過(guò)上一節(jié)描述的方式映射到整個(gè)CGRA中,由于神經(jīng)網(wǎng)絡(luò)類(lèi)應(yīng)用對(duì)片上存儲(chǔ)需求較高,為了驗(yàn)證陣列數(shù)據(jù)流的極限性能,仿真過(guò)程中將片上存儲(chǔ)限制放寬,預(yù)設(shè)了足夠放置所有權(quán)重和中間數(shù)據(jù)的存儲(chǔ)空間。在500MHz的時(shí)鐘頻率下,峰值計(jì)算性能可達(dá)379.11GOP/s,平均計(jì)算性能可達(dá)238.37GOP/s。
將此峰值性能與現(xiàn)有的卷積神經(jīng)網(wǎng)絡(luò)FPGA加速器做比較,其中FPGA[6]工作時(shí)鐘為100MHz,F(xiàn)PGA型號(hào)為Virtex-7 VX485T,F(xiàn)PGA[7]的工作時(shí)鐘評(píng)論為156MHz,型號(hào)為Virtex-7 VX690T,F(xiàn)PGA[8]工作頻率為150MHz。可以看到針對(duì)AlexNet網(wǎng)絡(luò)模型,CGRA的計(jì)算性能相比于FPGA加速器處于劣勢(shì),這是由于CGRA在計(jì)算過(guò)程中需要更換配置達(dá)到重構(gòu)以切換數(shù)據(jù)地址以及權(quán)重,這個(gè)過(guò)程需要消耗額外的時(shí)間,并且重新提取權(quán)重進(jìn)入陣列之后,流水線需要重新填充。
計(jì)算性能上的劣勢(shì)除了重構(gòu)時(shí)間造成,還由片上計(jì)算資源決定,若將FPGA的DSP個(gè)數(shù)與CGRA的PE個(gè)數(shù)做等效處理,那么從單個(gè)計(jì)算單元的執(zhí)行效率來(lái)看,CGRA比FPGA更高,并且CGRA擁有動(dòng)態(tài)可重構(gòu)的特性。因此,在CGRA的片上存儲(chǔ)資源足夠大的情況下,相比于FPGA實(shí)現(xiàn),本文的數(shù)據(jù)流映射方式使CGRA的計(jì)算單元能夠得到更有效的利用。
4 結(jié)語(yǔ)
本文針對(duì)神經(jīng)網(wǎng)絡(luò)類(lèi)應(yīng)用核心算法特點(diǎn),結(jié)合脈動(dòng)陣列的思想在通用粗粒度可重構(gòu)架構(gòu)的處理單元互連特性下,設(shè)計(jì)了一套高效的映射數(shù)據(jù)流,設(shè)計(jì)方案在配置文件層提供了處理器參數(shù)控制接口,在不更換配置文件的情況下適用于不同輸入特征尺寸圖像,并可作為映射模板嵌入到大型網(wǎng)絡(luò)應(yīng)用映射流程中。本文搭建了通用粗粒度可重構(gòu)架構(gòu)的RTL仿真環(huán)境,在該環(huán)境下針對(duì)神經(jīng)網(wǎng)絡(luò)核心算法進(jìn)行仿真和性能評(píng)估,驗(yàn)證了數(shù)據(jù)流方案的高效性,通過(guò)比較相同算法在CPU平臺(tái)和仿真平臺(tái)的運(yùn)行時(shí)間,結(jié)果顯示所設(shè)計(jì)的數(shù)據(jù)流可以達(dá)到平均652倍的應(yīng)用加速比。在片上存儲(chǔ)資源足夠的情況下,本文的數(shù)據(jù)流設(shè)計(jì)使得計(jì)算單元的執(zhí)行效率高于FPGA實(shí)現(xiàn)方式。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
現(xiàn)代裝飾(2020年7期)2020-07-27 01:27:42
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
流行色(2020年1期)2020-04-28 11:16:38
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
藝術(shù)啟蒙(2018年7期)2018-08-23 09:14:18
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
