面向深度神經網絡加速芯片的高效硬件優化策略
2021-06-24 09:41:24張經緯李國慶吳瑞霞曾曉洋
電子與信息學報 2021年6期
張 萌 張經緯* 李國慶 吳瑞霞 曾曉洋
①(東南大學電子學院國家專用集成電路系統工程技術研究中心 南京 210096)
②(復旦大學專用集成電路與系統國家重點實驗室 上海 200433)
1 引言
人工智能算法的理論研究相比于幾年前取得了突出的進步。因此,一部分研究人員開始將精力投在把人工智能算法特別是深度神經網絡(Deep Neural Networks, DNN)部署在各種硬件平臺上,包括中央處理器(Central Processing Unit, CPU)、圖形處理器(Graphics Processing Unit, GPU)、現場可編程門陣列(Field Programmable Gate Array,FPGA)、專用集成電路(Application Specific Integrated Circuit, ASIC)上[1,2]。這些基于硬件平臺而專門構建出來的神經網絡加速器被證明在應用于圖像分類[3]、目標檢測[4,5]和語音識別等方面有著很好的效果,而像無人機檢測、自動駕駛這類的強實時性的人工智能(Artificial Intelligence, AI)、物聯網應用不僅對網絡識別精度有較高要求,而且對網絡推理速度以及硬件平臺功耗同樣是嚴峻的挑戰。相比較基于性能優先的CPU/GPU這類通用處理器很難滿足功耗約束,FPGA和ASIC具有高能效、低功耗的特性成為當前邊緣AI應用方案的首選[6]。
但是想要基于低功耗硬件平臺,構建出符合要求的DNN加速器是非常有挑戰性的[7,8]。要求開發人員不僅了解AI算法,更加需要包括:(1)專用于低功耗平臺的DNN體系結構;(2)高效的內存管理方案;(3)并行可靠的工作流。整個任務嚴重依賴設計者跨越機器學習和集成電路設計的專業知識。設計過程中如果只實現AI算法卻不考慮硬件優化策略,就很難滿足邊緣計算方案低功耗和高實時性的嚴格要求。因此硬件優化策略具有較高的普適性和重要的研究價值。
為了解決以上諸多問題,本文提出用于DNN加速芯片設計的一系列高效率優化策略,并在FPGA上驗證性能,包括可堆疊共享計算引擎(Process Engine, PE)、可調的循環次數、通道增強和預加載工作流優化方法,利用有限的低功耗硬件資源獲得最好的性價比。本文所提硬件優化策略:(1)基于SkyNet網絡模型應用,設計出SEUer A型加速器,其精度和功耗都要優于iSmart3-SkyNet(the 1st place in the DAC’2019-SDC)[9];(2)基于SkrSkr-SkyNet(the 2nd place in the DAC’2020-SDC)[10]應用優化出了SEUer B型加速器,最終分數會超過UltraNet(the 1st place in the DAC’2020-SDC)。本文的主要貢獻如下:
(1)提出一種可堆疊共享PE用于組裝成并行度靈活的卷積計算模塊,可以獨立且高效率地完成逐點卷積(PointWise Convolution, PWC)計算和深度可分離卷積(DepthWise Convolution, DWC)計算,并且采用了行緩沖區結構解決PWC單次讀取特征圖的限制。
(2)針對可堆疊共享PE提出了循環次數可調,可根據網絡層數自動優化計算模塊中循環次數,提高計算的效率。
(3)通道增強的方法不僅可以大幅度增強圖片輸入層的并行度,還可以增加與外部存儲器的通信帶寬。
(4)預加載工作流可以更好地協同處理系統(Processing System, PS)與可編程邏輯(Programmable Logic, PL),從而加速整個系統,降低系統的延遲和功耗。
本文其余安排如下:第2節介紹專用于低功耗平臺的SkyNet的網絡結構以及存在的問題,然后使用Roofline模型[11]分析基于SkyNet網絡設計出的iSmart3-SkyNet加速器的性能瓶頸;第3節針對這些問題給出對應的優化策略;第4節將討論我們為低功耗平臺提出的優化策略的實驗結果;第5節給出結論。
2 SkyNet網絡模型及其加速器問題分析
2.1 專注于低功耗目標檢測的SkyNet模型
SkyNet是一個冠軍模型,它被設計出來專門用于嵌入式邊緣設備的目標檢測和追蹤任務[9]。可以為低功耗嵌入式系統提供可靠的推理精度的同時滿足實時響應這類的低延時要求。SkyNet采用自下而上的DNN設計方法[12],將3×3深度卷積層、1×1點卷積層、批量歸一化的組合層和ReLU6組合成捆綁包(bundle)。將捆綁包反復堆疊形成如表1所示的網絡結構。表1所示的超參數(包括網絡通道數和池化層的位置)是通過使用實際硬件進行神經網絡搜索而獲得的最佳解決方案。從硬件執行效率角度考慮,SkyNet網絡比自上而下設計的卷積神經網絡(Convolutional Neural Network, CNN)更有效[13]。
CNN網絡的圖像輸入通道一般為3個光學三原色(Red Green Blue, RGB)或4個三原色加不透明參數(Red Green Blue Alpha, RGBA),因此很難在固定計算通道的PE上提高淺層網絡的計算效率[14,15]。例如,表1最后兩列反映了iSmart3-SkyNet理論計算量占比跟實際硬件延時占比差異,在第1個捆綁包中,雖然SkyNet的輸入層是3,但在理論計算中第1層的PWC的輸入層卻是32,DWC的輸出層卻是64而不是48。因為加速器中計算模塊輸入輸出通道固定,iSmart-SkyNet的輸入并行度為16,輸出并行度為32。在計算第1層時,即便通道當中存在無效數據,它在輸入輸出通道維度依舊各自循環兩次,也因此在表格中第1個、第2個捆綁包的計算量之和為34.48%;而實際加上異構計算平臺的計算耗時,僅僅第1個捆綁包的延時就占了整體時間的33.90%,實際延時相比較計算量,增加了69%。在這種情況下,第1個、第2個捆綁包的延時占到整個系統延時的1/2。因此考慮到帶寬限制等諸多現實因素,提高淺層網絡的計算效率,使得延時與計算量一致是非常困難的。
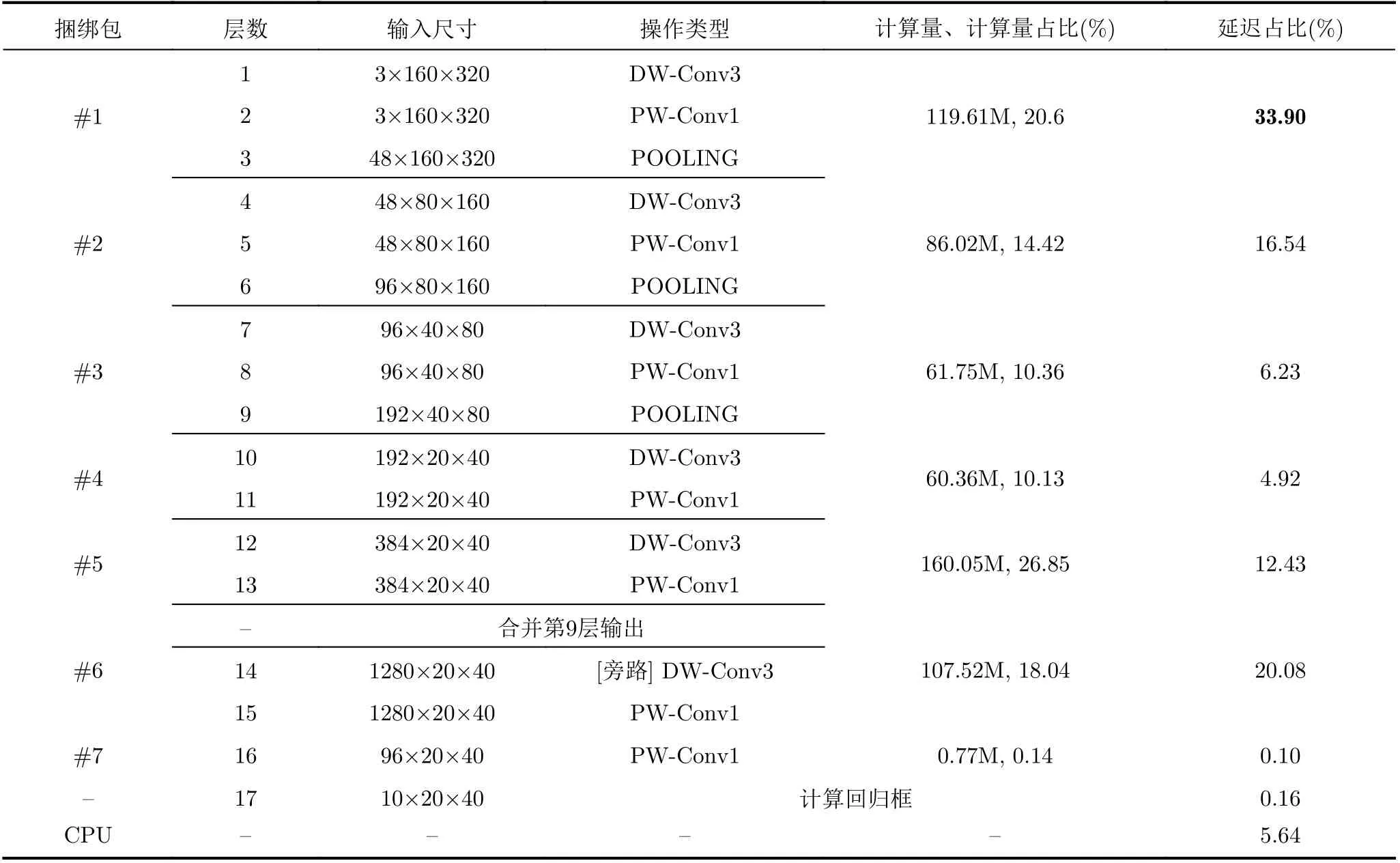
表1 SkyNet的體系結構和每個捆綁包的推理速度表格
2.2 Roofline模型
計算和通信是系統吞吐量優化中的兩個主要限制。加州大學洛杉磯分校叢京生教授團隊[11]的Roofline性能模型,反映了系統性能與片外內存流量的關系,更重要的是,突出了硬件平臺的峰值性能與神經網絡模型之間的相關性。式(1)描述了Roofline模型,PP是系統中所有可用計算資源提供的浮點吞吐量,也稱為計算屋頂。B是內存帶寬(Memory Bandwidth, BW),而CC代表計算與通信之比(Computing To Communication, CTC)是每個片上存儲器流量的操作。加速器的實際計算性能不能超過計算屋頂和計算與通信比率×內存帶寬的最小值。在第1種情況下,可達到的性能受到處理器可提供的最大計算資源限制;第2種情況則可達到的性能受到內存帶寬的限制,并且無法充分利用計算資源
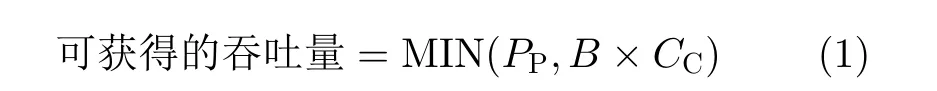
對于不同類型卷積以及不同循環展開的相同卷積,加速器計算通信比公式都是不一樣的。對于深度可分離卷積,計算通信比如式(2)所示
對于逐點卷積的計算通信比如式(4)和式(5)所示,其中出現的參數量的含義與式(2)和式(3)的一致

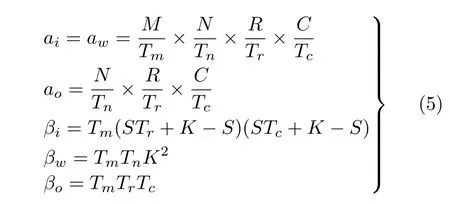
在iSmart3-SkyNet中,DWC和PWC分別由不同的計算引擎計算。DWC和PWC的Roofline模型的說明如圖1所示。對于DWC的Roofline模型的圖示如圖1(a)所示,第1層可獲得的性能非常低,這受到帶寬的限制。因此,捆綁包#1的等待時間百分比大于捆綁包#1的浮點操作次數(Floating Point of OPeration, FLOP)。此外,計算上限僅約為6.88 GFLOPS,這受計算資源的限制,因為PWC計算引擎占用了最多的計算資源。圖1(b)顯示了PWC層的Roofline模型,所有層的可達到的性能都達到了計算上限110 GFLOPS。但是,計算能力不高。此外,DWC和PWC由不同的計算引擎計算。換句話說,當PWC引擎工作時,DWC引擎是自由的,反之亦然。計算資源的利用率不高。在第1層中,輸入通道為3,但是iSmart3-SkyNet計算32個通道。冗余計算會增加推理延遲。這些問題在其他用于輕量級目標檢測網絡的加速器中也存在。為了解決這些問題,提出了幾種方法,這些方法在第3節介紹。

圖1 iSmart3-SkyNet加速器上的SkyNet Roofline模型分析
3 優化策略
本節首先介紹高效優化策略下的加速器總體架構,該架構可專用于低功耗平臺。以專用于低功耗平臺的網絡SkyNet為例,經問題分析,可堆疊共享PE、通道增強、循環次數可調、預加載工作流優化方法依次被提出。這樣,基于低功耗平臺有限的硬件資源,可充分發揮并行計算優勢,實現更加高效的邊緣計算。
3.1 系統整體結構
系統的整體架構如圖2所示,架構基于異構結構,包含了可編程邏輯(Progarmmable Logic,PL)和高性能處理系統(Processing System, PS)。PL由4個模塊組成:內存判決模塊通過高性能總線接口(Advanced eXtensible Interface, AXI)直接訪問外部存儲器以及調度雙倍的數據緩沖區形成乒乓結構,最大化利用片上存儲器;多個可堆疊共享計算引擎(Process Engine, PE)堆疊成為計算模塊來處理PWC和DWC計算;池化激活模塊完成池化與激活計算;控制模塊被設計用來控制PL邏輯和時序,保證每個模塊在正確的時刻被正確地重用。PS采用了多進程優化,以提高圖像預處理和后處理的計算速度。

圖2 系統-計算模塊-線性緩沖區結構示意圖
加速器開始工作時,圖像和權重被存儲在外部存儲器中。PS做圖像預處理的同時,向PL發出啟動信號。PL中的控制模塊接收啟動信號后,控制內存判決模塊通過AXI4接口從外部存儲器中讀取權重和圖像并存儲到相應的緩沖區中,接著控制模塊按照網絡模型順序依次重復調用計算模塊和池化激活模塊,最后內存判決模塊將結果輸出給PS做后處理完成所有任務。
3.2 可堆疊共享PE
由于有限的硬件資源,并且PWC計算引擎占用了大多數計算資源[16],因此DWC計算引擎的峰值性能非常低。本文提出一種可堆疊的共享PE,以提高DWC計算引擎的峰值性能。幾個這樣的PE被組裝并堆疊到一個大型計算模塊中。PWC和DWC操作都共享此計算模塊。這意味著在整個任務中只有一個這樣的計算模塊就可以完成PWC和3×3 的DWC。
如圖2(b)所示,共享PE由9個DSP組成,因此可以在1個時鐘周期內完成3×3 DWC計算。受雙端口塊隨機存取存儲器(dual-port Block Random Access Memory, BRAM)功能的限制,1個時鐘周期內最多可以讀取兩個像素。為了解決這個問題,共享PE利用BRAM和DWC計算引擎之間的行緩沖區。如圖2(c)所示,紅色特征圖的像素被存儲在行緩沖區中,而滑動窗口的像素被用于當前計算。在每個時鐘周期,窗口中的像素都會移動,新的像素會從行緩沖區中移入,而舊的像素會從窗口中彈出,以便可以展開內核,并且可以映射特征圖的9個像素1個時鐘周期內即可輕松獲得。
對于SkyNet,選擇32個共享PE堆疊到計算模塊中,并且在計算PWC時,將展開18個輸入通道和16個輸出通道。16/18輸入通道用于傳輸數據,其他兩個通道的值為0。在計算DWC時,所有通道都用于傳輸數據,并且計算速度將比訪問外部存儲器更快,并且會觸及加速器的存儲墻。
3.3 循環次數可調
從表1可以看出,SkyNet的前兩層實際耗時比理論上花費更多的時間。淺網絡層的通道很少,圖像輸入通道通常只有3(RGB)或4(RGBA)。具有固定輸入和輸出通道尺寸的計算引擎將在處理淺層網絡時導致某些通道的計算資源空閑,并且其他循環將導致額外的系統延遲。具有不變循環計數的計算模塊不能完美地應用于淺層網絡。因此,本文提出循環計數可調節的優化方法。
可調節的循環計數方法建立在可堆疊共享PE基礎上。通過提供的參數變量[輸入通道并行度(Channel Input, CI)],可以自由地堆疊到計算模塊中,它根據不同的層自動調節循環計數,以達到最小功耗和最低延遲。例如,iSmart3-SkyNet的輸入通道并行度為16。在計算PWC的第1層時,在輸入通道尺寸上循環了兩次,而第2個循環為無效計算。最終iSmart3-SkyNet第1層中超過90%的計算資源處于空閑狀態,這也導致更長的延遲和更多的功耗。如果iSmart3-SkyNet使用可調節的循環計數優化,則可以基于不同的層調節循環計數。在計算第1個PWC層時,輸入通道尺寸將僅循環1次,而不是原始的兩倍。即使圖像輸入通道尺寸僅循環1次,仍然有13/16 DSP處于空閑狀態,第1個PWC層的這種無用計算可以通過3.4節描述的通道增強優化來解決。
3.4 通道增強
由表1分析,相比較于第2層網絡,第1層網絡硬件延時遠遠大于計算量,占整個系統延時的1/3。這是因為在像SkyNet這樣的CNN中,第1層圖片的輸入通道只有3個(RGB)。即使使用了循環次數可調優化,iSmart3-SkyNet的第1層PWC的通道利用率并不高,DSP的利用效率僅為3/16。為了解決這一問題,通道增強優化被提出。方法如圖3所示,先將特征圖以像素單位裁剪,并以RGB的順序在通道維度上重新排列。從低位開始一直排列到高位。下一輪從上一輪結束的像素開始,重復以上操作直至最后一個像素點。如此使得處理后的特征圖的通道展寬,提高了第1層的計算并行性。

圖3 通道增強流程說明圖
本文提出的通道增強不同于傳統通道增強技術[17]。通道增強優化不僅提高了圖片輸入層的計算并行性,還大大提高了與外部存儲器的傳輸帶寬。例如在iSmart3-SkyNet中,傳輸圖像的AXI4的數據位寬只有8位,在Skrskr-SkyNet中傳輸圖像的AXI4的數據位寬度為32位,但只有24位有效。而在使用了通道增強優化的SkrSkr-SkyNet,用于傳輸圖像的AXI4總線數據寬度為128位并且沒有原先的無效數據。因此傳輸圖像的帶寬大大提升,訪問存儲器的次數減少,系統延時和功耗也隨之減少。
3.5 預加載工作流
當前可用于計算CNN的工作流程如下:獲取圖像(picture)、對該圖像進行預處理、將處理后的圖像復制到DDR存儲器進行存儲、在加速器上計算DNN模型以及后處理,如圖4(a)所示,盡管DNN是在PL上并行計算的,但其工作受到串行工作流程的限制,并且必須等待上一幅圖像的后處理完成,才能對DNN進行預處理。將處理后的圖像復制到DDR內存中,然后才能開始工作。此串行工作流程效率低下。一般的并行工作流程如圖4(b)所示。與串行工作流程相比,在并行工作流程中,PL正在執行DNN計算,而PS也在預處理下一張圖片。但是,PL仍處于空閑狀態。因此,提出了預加載工作流程。如圖4(c)所示,在計算圖像的第1層之后,PS將預處理的下一個圖像復制到DDR以替換舊圖像。由于PL幾乎始終處于工作狀態,因此預加載工作流程的效率高于圖4(b)。
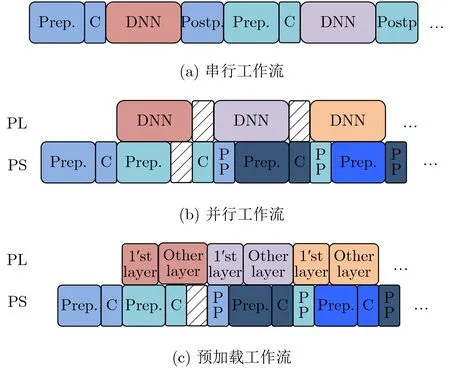
圖4 3種工作流比較圖
值得一提的是,其中PS上的預處理速度一般都要快于PL上DNN的計算速度。而要想做到這一點,需要對PS做多進程優化。以多個進程對攝像頭采集的照片同時預處理,然后將圖像放入隊列并等待存入DDR中。PL在計算完DNN之后會將結果存入另一個隊列,PS也會以多進程優化確保后處理時間快于DNN第1層的計算時間。如此一來,系統的關鍵路徑在PL處,且PL的效率接近100%。
4 實驗結果分析
根據第3節提出的優化方法優化iSmart3-SkyNet加速器后,優化后的DWC層的Roofline模型如圖5(a)所示。可以看出,與原始Roofline模型相比,第1層DWC的性能不再比其他DWC層的性能更弱,因為通道增強優化增加了帶寬。由于共享計算資源,DWC的計算能力從原來的6.88 GFLOPS增加到172.8 GFLOPS。它使所有DWC層從計算限制變為內存限制,使得可達到的性能得到了顯著提高。PWC的Roofline模型如圖5(b)所示。優化的PWC計算屋頂從原來的110 GFLOPS增加到307.2 GFLOPS。計算屋頂的增加導致該層的一部分從計算限制更改為內存限制,使得每層可獲得的性能都比iSmart3-SkyNet高。
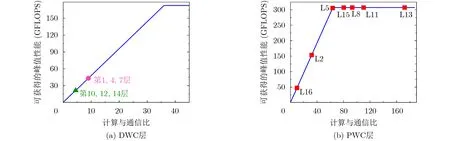
圖5 優化后加速器上的SkyNet Roofline模型分析
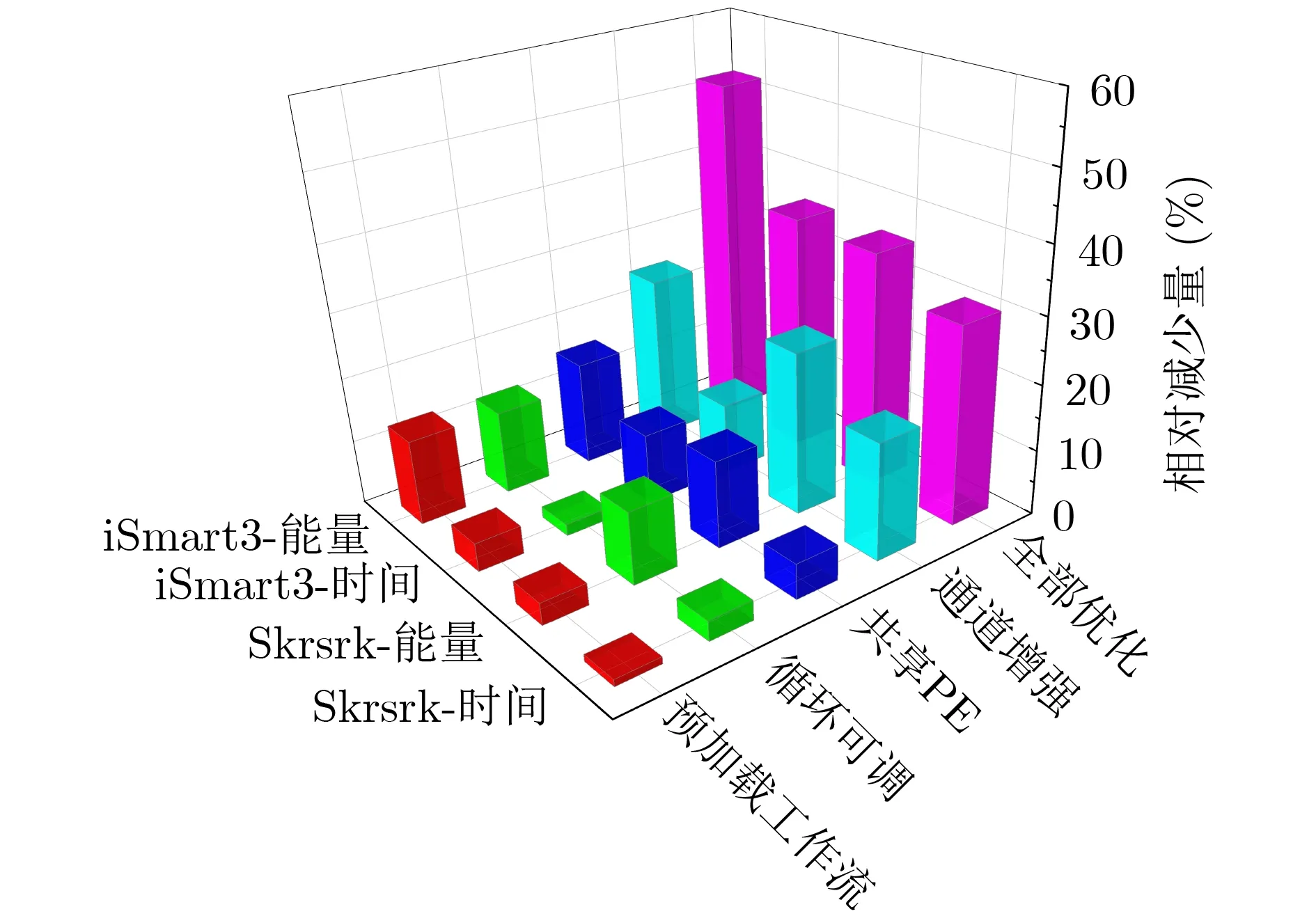
圖6 iSmart3和Skrskr加速優化前后性能對比
為了更好地說明本文優化方法在低功耗目標檢測方面的性能改進,分別選擇了iSmart3-SkyNet和SkrSkr-SkyNet作為基準模型。本文iSmart3-SkyNet和Skrskr-SkyNet中提出的方法的有效性如圖6所示,其中它們的性能(包括延遲和能量)被標準化為1。與iSmart3-SkyNet和SkrSkr-SkyNet相比,使用預加載的工作流方法處理1000幅圖像,分別可以將運行時間減少約4.44%和1.11%,并將能耗分別減少13.27%和3.45%。當處理的圖像數量增加時,預加載工作流程可以減少更多的運行時間和能耗。對于iSmart3和Skrskr,可調節循環次數方法的運行時間分別減少了1.78%和3.10%,能耗分別減少了12.92%和11.29%。考慮到可調節循環計數僅應用于前兩個PWC層,因此更改為合適的網絡模型將獲得更顯著的效果。對于iSmart3,可堆疊共享PE減少了10.87%的運行時間和16.07%的能耗。對于Skrskr,可堆疊共享PE減少了5.49%的運行時間和13.55%的能量。由于內存的限制,運行時間的減少并不重要。但是,由于減少了計算資源的消耗,因此能源的節省非常重要。通道增強方法具有最大的改進,可以減少Skrskr和iSmart3的運行時間10.85%和17.98%。它們的功耗降低了約1/4。通道增強不僅可以提高硬件資源的利用率,而且可以大大提高加載圖像的帶寬。將所有優化方法應用于SkrSkr,運行時間縮短了30.29%,能耗降低了35.49%。iSmart3的改進更加明顯,運行時間縮短了35.98%,能耗降低了52.06%。
與之前的DAC-SDC目標檢測加速器相比,結果如表2所示。與iSmart3- SkyNet相比,Skrskr-SkyNet使用了更有效的量化,這也使得Skrskr的GOPS/W值為iSmart3的2.24倍,準確率也因為DWC使用了線性緩沖區從0.716增加到0.731。根據第3節所述的優化策略,可以在不改變量化方法的情況下對每個加速器進行進一步優化。基于iSmart3改進的SEUer A型不僅由于行緩沖區使精度提升到0.724,GOPS/W和Energy/Picture還分別優化了1.85倍和2.14倍。基于Skrskr改進的SEUer B型幀率從52.429提高到78.576,功耗降低了近1/2。此外,SEUer B型的GOPS/W和Energy/Picture分別比Skrskr增加了1.5倍和1.9倍。
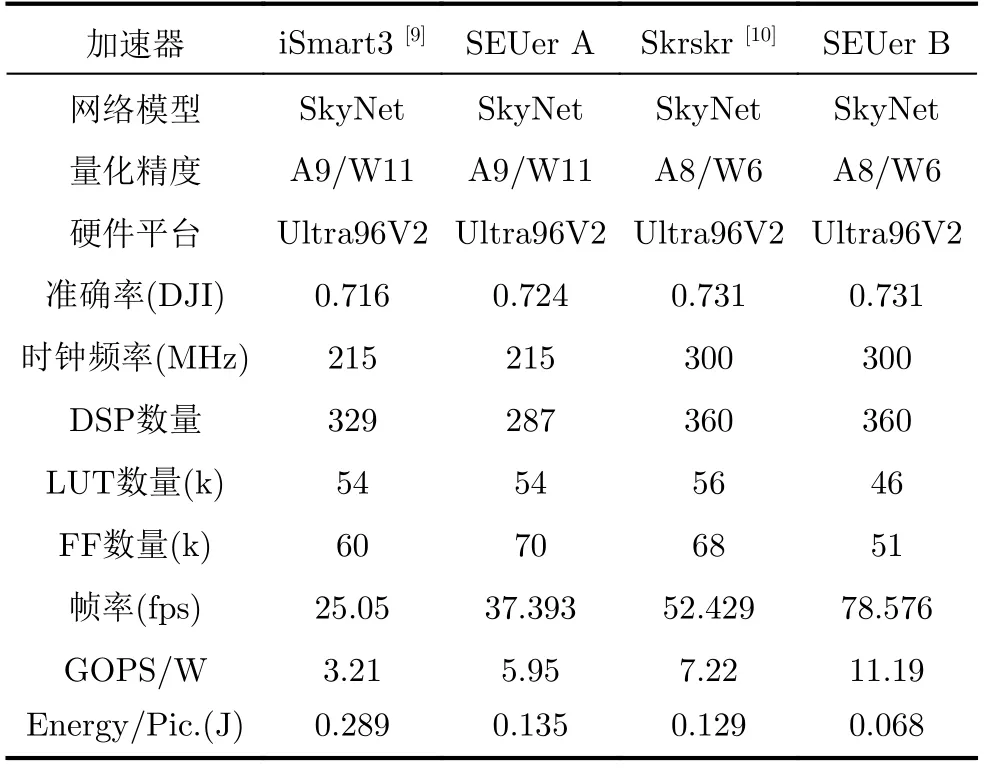
表2 優化策略效果對比
5 結束語
本文利用Roofline模型對深度可分離卷積進行分析,然后面向低功耗目標檢測提出了DNN加速芯片的優化策略,包括可堆疊共享PE、可調節循環次數、通道增強和預加載工作流等優化措施,通過選擇iSmart3-SkyNet和Skrskr-SkyNet作為基礎網絡,FPGA驗證效果顯著。對于iSmart3-SkyNet,本文提出的方法可以增加精度并提高能效;對于Skrskr-SkyNet,本文基于提出的優化策略所設計的加速器以78.576 fps的速度和0.068 J/圖像的速度進行計算,性能超過2020年DAC低功耗目標檢測國際頂尖競賽第1名UltraNet,目前在此類目標檢測加速器設計領域處于較為領先地位。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
