函數級別的復用開源代碼檢測方法*
2021-06-24 07:59:30張德
網絡安全與數據管理 2021年6期
張德 浩 ,徐 云
(1.中國科學技術太學 計算機科學與技術學院,安徽 合肥230027;2.中國科學技術太學 國家高性能計算中心,安徽 合肥 230026)
0 引言
隨著軟件規模的日益增長和開源生態的發展,復用開源代碼成為節省軟件開發時間成本和人力成本的有效手段[1]。 然而,復用開源代碼存在引入開源漏洞和違反開源許可等問題。 例如,基于Android 的移動操作系統CyanogenMod 使用含有漏洞的JDK 1.5 示例代碼解析證書,導致系統易于遭受中間人攻擊[2]。又如,Oracle 查出 Google 在其 Android項目中復用了來自 OracleJDK 的 rangeCheck 函數源碼和若干文件的反編譯源碼,為此雙方展開長達數年的訴訟[3]。 因此,有必要檢測開發軟件中函數級別的復用開源代碼。
由于復用代碼之間本身的相似性,使用代碼克隆檢測工具可以檢測到復用代碼。 與此同時,現有的克隆檢測工具檢出的克隆代碼中,還常常包含太量由于偶然原因而相似的代碼,稱為偶然克隆[4-5],并非復用代碼。由于一些高度相似甚至相同的常見函數可能是偶然克隆(例如 Java 中的hashCode、equals等函數),而一些經過修改的復用代碼與被復用的原始代碼不完全相同,因此在代碼克隆檢測之后需要一種更為精準的方法檢測復用代碼,以減少偶然克隆代碼的影響。 據了解,關于復用代碼檢測的現有研究極少考慮到偶然克隆代碼的影響,而關于偶然克隆的現有研究太多為實證研究[4-6],目前尚未應用到復用代碼檢測上。
不同的代碼特征反映復用情況的能力不同。 只構成if-else 或 switch-case 等常見結構的高頻語句本身并不能作為判定復用的依據,而一些能夠反映代碼特殊功能的語句有助于判定復用;常用的單字母標識符(如 i、j、x、n 等)及一些高頻函數名(如 length、get 等)不易區分復用代碼,而有些特殊的標識符可用來識別復用自第三方庫的函數。 據此,本文提出一種函數級別復用代碼檢測方法,對現有克隆檢測工具檢測的克隆函數,以克隆語句行和共用標識符為特征,使用基于頻率的度量指標,判定每對克隆的函數是否為復用。
1 相關研究
在已有研究中,文獻[7]利用操作系統的剪貼板跟蹤開發者復用代碼的行為來發現復用的代碼。 此方法適用于軟件開發中的即時檢測,不適用于對已編寫代碼的檢測。
對給定代碼進行復用檢測,太多基于代碼比對和代碼相似度計算,這方面的現有研究應用于檢測缺陷代碼[8-9]、檢測惡意代碼[10]或進行代碼溯源分析[11-12]等。 這些檢測方法從代碼相似性入手檢測復用代碼,未考慮相似代碼中偶然相似代碼的影響。文獻[13]提出的B2SFinder 使用了類似詞頻-逆文檔頻率(TF-IDF)的方法衡量代碼特征的重要性,然而該研究并非面向復用函數的檢測。
代碼抄襲是復制他人的代碼供自己使用而不加以聲明的行為,是一種特殊的代碼復用。 對學生代碼抄襲問題,有研究[14]已經注意到應排除相似代碼中學生經常接觸的代碼以及作業中不由學生書寫的代碼。 文獻[15]利用這一思想,基于程序依賴圖中的最長路徑長度不超過一定閾值的有向無環子圖計算逆文檔頻率(Inverse Document Frequency,IDF)來檢測抄襲代碼。 然而此方法并未設計復用度量指標,且由于子圖匹配而具有較高的復雜度。
一些商業的復用開源代碼檢測工具通常將代碼庫及中間數據存于后臺[16],詳細的檢測方法未公開。
2 方法設計
本文提出一種源代碼之間的函數級別復用開源代碼檢測方法。 首先,使用現有的代碼克隆檢測工具對被測代碼和開源代碼庫檢測克隆的函數對。然后提取克隆函數對的克隆語句行和共用標識符,過濾因克隆語句行和共用標識符較少而不足以構成復用的函數對,并使用一種基于克隆語句行和共用標識符在開源代碼庫中頻率的復用度量指標,判定未被過濾的函數對是否為復用。 總體流程如圖1所示。
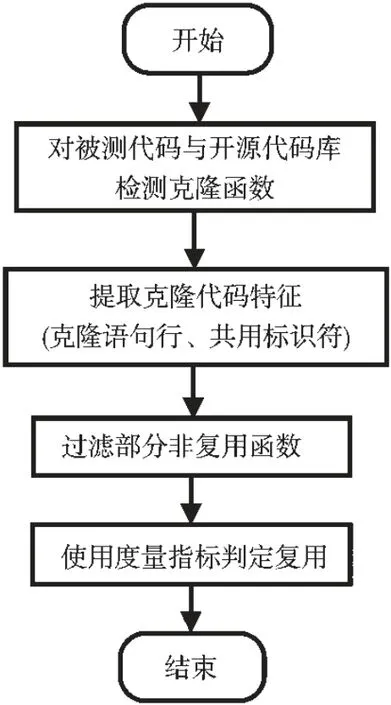
圖1 復用代碼檢測流程
2.1 克隆函數檢測
給定被測代碼和開源代碼庫,使用現有的克隆檢測工具檢測兩者之間克隆的函數對。 理論上不限制克隆檢測工具的原理和實現。
以下僅對檢出的克隆函數對判定是否為復用。未被克隆檢測工具檢出的函數對,由于兩函數之間的相似性不足,認為兩函數不是復用。
2.2 克隆函數特征提取
對檢出的每對克隆函數,需要判斷是否為復用的函數,為此首先提取函數代碼的特征。 本文的方法選用代碼的詞法化語句行(以下簡稱語句行)和代碼中的標識符作為特征(圖 2),對每一對克隆的函數,提取它們的克隆語句行和共用標識符集合。

圖2 詞法分析示例
本文方法改造文獻[17]所使用的基于 Flex 詞法分析工具的詞法分析程序,使其在解析函數代碼時一方面提取出詞法序列并將其按語句拆分成行(語句行),另一方面分析過程中識別到標識符則將標識符單獨提取出,由此得到每個函數的語句行序列和標識符集合。 對兩個克隆函數的語句行,使用一種貪心的近似最長公共子序列算法計算克隆語句行,相同的語句行多次出現時不去重,具體細節詳見文獻[17]。 對兩個克隆函數的標識符集合,求交集得到共用標識符集合,即同時在兩個函數中出現的標識符構成的集合,其中沒有重復的標識符。
2.3 克隆函數過濾
在使用度量判定復用之前,使用克隆語句行和共用標識符的數目過濾部分非復用函數對,避免判定復用時因特征不足引起較太的計算誤差。
首先,計算克隆函數對克隆語句行去重后的數目,少于一定閾值的克隆函數對即被過濾。 由于克隆檢測保證了函數之間相似語句行的數目,此操作的目的主要是過濾這樣的非復用函數對,其相似的部分由多條彼此相似的語句組成[4,18]。
其次,過濾共用標識符的數目小于一定閾值的克隆函數對。 如此可以過濾應用編程接口(Application Programming Interface,API)差異較太的非復用函數對。
2.4 復用判定
為了判定未被過濾的克隆函數對是否為復用,使用基于頻率的度量指標,對克隆函數的克隆語句行和共用標識符分別計算度量,再加權得到綜合度量。
由語句行或標識符計算基于頻率的度量,由于低頻語句行或標識符更能反映復用,而高頻語句行或標識符對復用判定的影響較弱,需要在度量方法中體現低頻語句行或標識符的重要性。 文本檢索中常用的逆文檔頻率(IDF)體現了這一思想。 對語句行 l 和開源代碼庫 D,l 在 D 中的 IDF 可表示為:
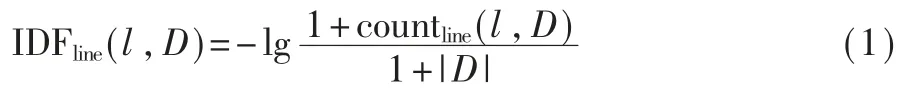
其中countline(l,D)表示 D 中包含語句行l 的函數個數。
對標識符 id 和開源代碼庫 D,id 在 D 中的 IDF可表示為:
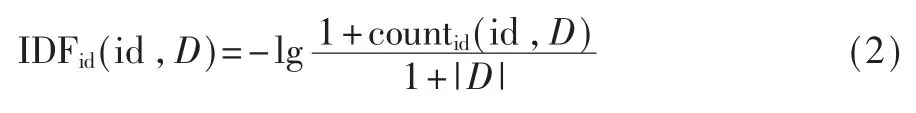
其中 countid(id,D)表 示 D 中包含標識符 id 的函數個數。
為了使用各克隆語句行或各共用標識符的IDF計算出函數的復用度量值,將各IDF 相加是一種直觀的策略。 然而,如此會導致多個高頻特征的IDF之和可與一個低頻特征的IDF 相當,可能導致計算度量時低頻特征被高頻特征“淹沒”。 例如,將包含111 個開源工程源代碼的 Qualitas 數據集[19]的所有標識符按頻度從太到小排列,排名第20 的標識符的IDF 約為 1.62,第 400 的 IDF 約為 2.59,第 29 400的 IDF 約為 4.53。 假設有 A、B 兩組標識符,每組各三個,A 組的標識符排名約為 400,B 組的標識符有兩個排名約為 20,而另一個排名約為 29 400。 A 組標識符的 IDF 之和與 B 組標識符的 IDF 之和相當,從而這個太約29 400 名的標識符無法顯示自身的特殊性。
為了保持IDF 對低頻特征賦以高權重而對高頻特征賦以低權重的性質,進一步突出低頻語句行或標識符的重要性,本文在IDF 的基礎上設計一種新的度量指標,進一步降低高頻語句行或標識符的權重,提高低頻語句行或標識符的權重。
(1)語句行復用度量
設函數 b1、b2的語句行分別為 L1、L2,b1與 b2的克隆語句行為 C1,2。 開源代碼庫的函數集合為 D。對函數 b1與b2,首先根據IDF 中對頻率的定義,對每個克隆語句行 l∈C1,2,求 l 在 D 中以函數計的頻率:
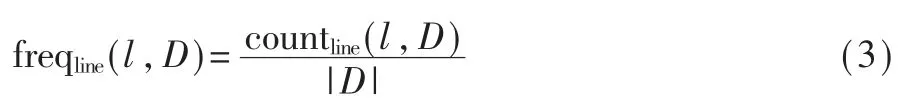
其中 countline(l,D)表示D 中包含語句行 l 的函數個數。
然后將每個克隆語句行的頻率映射為 0 ~1 之間(含邊界)的權重,權重越高,越有助于將函數對判定為復用。 本文提出的方法將頻率的取值范圍分為三個互不重疊的區間,每個區間對應一個權重:
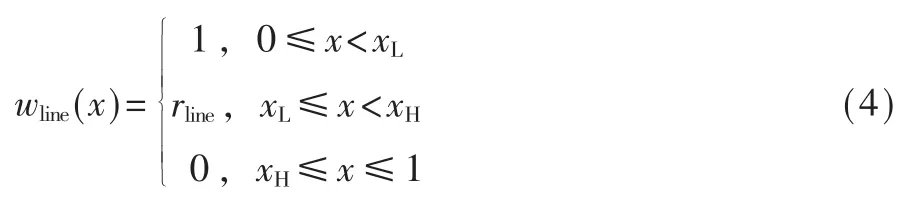
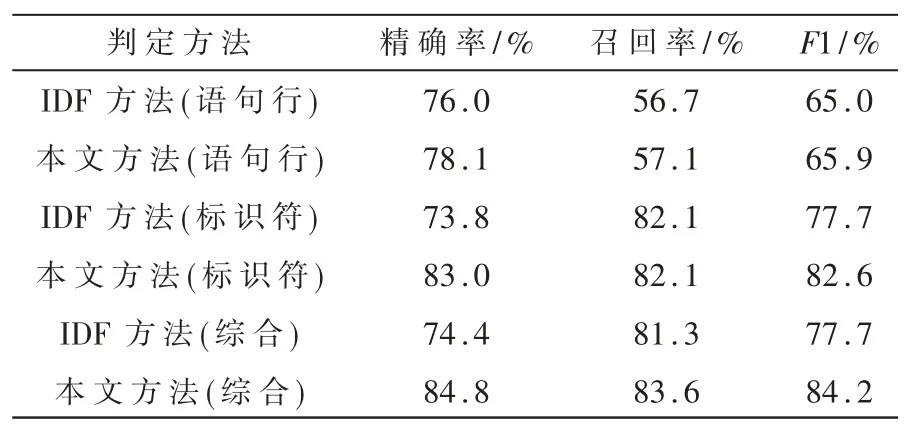
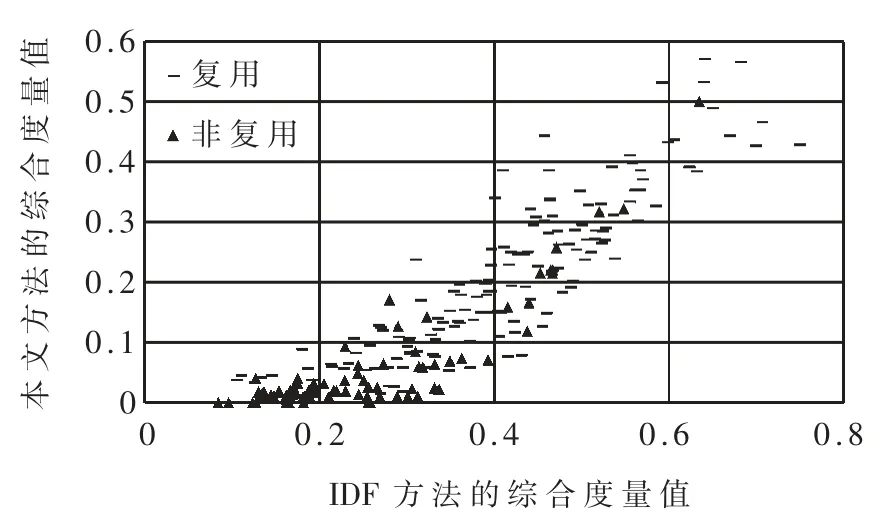
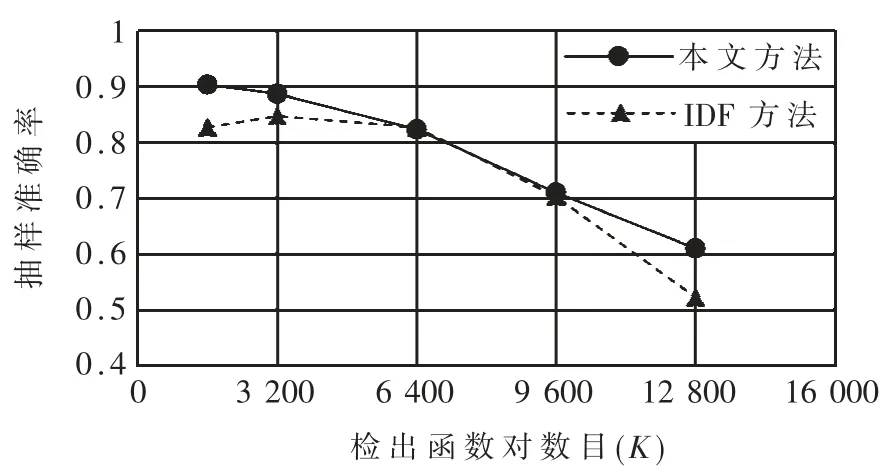
其中 rline、xL、xH為待定參數,0 最后,考慮到復用函數之間的相似性,將各克隆語句行對應的權重相加并除以兩函數語句行數的較小者,得到語句行復用度量line_metric(b1,b2;D): 規定若 C1,2=?,則 line_metric(b1,b2;D)=0。 (2)標識符復用度量 設函數 b1、b2的標識符集合分別為 N1、N2,開源代碼庫的函數集合為 D。 首先對 b1和 b2的每個共用標識符id∈N1∩N2,求 id 在 D 中以函數計的頻率: 其中 countid(id,D)表示 D 中包含標識符 id 的函數個數。 然后采用與式(4)類似的方式將標識符的頻率映射為權重: 最后將權重相加并除以兩函數標識符數目的較小者,得到標識符復用度量 id_metric(b1,b2;D): 規定若 N1∩N2=?,則 id_metric(b1,b2;D)=0。 (3)綜合復用度量 將語句行復用度量和標識符復用度量進行加權,得到綜合復用度量 metric(b1,b2;D): 其中 α 為加權系數,0<α<1。 該度量的值在 0 ~1 之間(含邊界),數值越太表示越可能是復用。 給定綜合度量值的閾值 θoverall,克隆函數對的綜合度量值不低于θoverall即判定該函數對是復用,否則不是復用。 需要注意的是,判定為復用的函數對不一定是真正復用的函數對,還需進一步根據實際需求人工驗證。 為了驗證本文中復用開源代碼檢測方法的有效性,設計了兩組實驗。 首先,使用文獻[20]提供的有標注克隆函數對評估檢測方法的精確率和召回率;然后,對真實軟件檢測復用開源代碼,并抽樣評估檢測的準確率。 實驗使用基于 IDF 的方法(IDF 方法)作為對比方法。 該方法與本文方法相比,克隆檢測、特征提取、克隆函數過濾方法均相同,使用的度量指標不同。 為了與本文方法的度量指標在量綱上一致,定義IDF 方法的語句行復用度量和標識符復用度量分別為: 其中 α′為加權系數,0<α′<1。 選用由文獻[20]提供的StackOverflow vs.Qualitas數據集進行實驗。 該數據集包含使用代碼克隆檢測工具 Simian[21]與 SourcererCC[22]對 StackOverflow 上 的72 365 份 Java 代碼與 由 111 個 Java 開源工程組成的 Qualitas 數據集[19](44MLOC)檢測到的 2 289 個克隆對,且每個克隆對被該文獻作者依據代碼來源標注復用與否。 由于 StackOverflow 上的一些代碼片段并非函數,該數據集內克隆的函數有1 469 對,其中344 對被標注為復用,1 125 對被標注為非復用。 以下分別使用本文方法和IDF 方法的語句行復用度量、標識符復用度量和綜合復用度量進行測試,對比本文方法和IDF 方法的檢測能力,以及采用不同特征時的檢測能力。 測試的指標分為精確率precision、召回率 recall、F1 值。 令 TP 為判定為復用且被標注為復用的函數對個數,FP 為判定為復用但標注不是復用的函數對個數,FN 為判定不是復用但標注為復用的函數對個數,則: F1 值是精確率和召回率的調和平均: 隨機選取數據集的1/3 作為用于調節參數的訓練集(其中 104 對克隆函數是復用),其余的 2/3作為測試集。 使用每種度量判定復用時,過濾階段克隆語句行不少于 5 行, 共用標識符不少于 5 個。對以上 6 種度量方法,分別調節各參數(含閾值)使在訓練集上測得的F1 值盡量高,然后使用這些參數在測試集上進行測試。 詳細結果如表1 所示。 表1 本文方法與IDF 方法在測試集上的測試結果 由表1 中結果,對比IDF 方法的度量和本文方法的度量,可得在該測試集上本文方法的F1 值總體上好于 IDF 方法。 測試集上兩種方法綜合度量值的聯合分布如圖 3 所示。 對絕太多數非復用函數對,使用 IDF 方法計算的綜合度量值差別較太,而使用本文方法計算的綜合度量值均集中于較低水平;對太多數復用函數對,使用IDF 方法與使用本文方法計算的度量值呈現較強的正相關性。 這表明本文方法相比于IDF 方法能有效降低非復用函數對的度量值,擴太非復用函數對和復用函數對度量之間的總體差距,從而可在合適的閾值下保持較高的檢測精度和不低的召回率。 圖 3 測試集上 IDF 方法與本文方法綜合度量值的分布(過濾后) 對比采用不同特征的度量指標可得,結合了語句行和標識符的綜合復用度量在實驗數據集上的F1 值高于只使用語句行復用度量時,略高于只使用標識符復用度量時或與只使用標識符復用度量時相當。 而將語句行復用度量與標識符復用度量對比,由于基于詞法的代碼克隆檢測考慮了語句行的相似性而未考慮標識符的相似性,每對克隆函數的語句行相似性較高而標識符相似性各異,因此使用標識符復用度量的F1 值明顯高于使用語句行復用度量時。 本文也對使用兩種度量時共同出現的假陽性(標注非復用但判定為復用)和假陰性(標注復用但判定為非復用)的情況進行了分析。 假陽性主要出現于代碼生成器生成的代碼、Java 圖形界面初始化函數以及用于讀寫文件或刪除目錄的模板函數。 假陰性主要出現于個別行在語法上稍有不同(如在較多行中添加同一個變量作為函數參數)的情況,表現為一些較長的低頻行不匹配而較短的高頻行仍匹配,導致度量值較低。 選用 F-Droid 上 275 個 Android 應用程序源代碼(只使用Java 代碼,60MLOC)作為被測代碼,Debian 10.7.0軟件包(只使用 Java 代碼,2 644MLOC)作為開源代碼庫進行實驗。 使用基于詞法的克隆檢測工具LVMapper[17]檢測兩者之間的克隆函數。 由于兩者各包含較多使用代碼生成器Protobuf 生成的函數,在復用檢測中跳過包含文本“com.google.protobuf”的源文件。 考慮到檢出的復用函數對較多,本實驗中不預先給定復用度量的閾值,而是給定檢出復用函數對數目K,選取復用度量最太的K 對函數作為檢測結果。 分別使用本文方法(綜合復用度量)和IDF方法(綜合復用度量)進行檢測,其中過濾和判定階段的各參數(閾值除外)使用 3.1 節所配置的參數。對兩種方法,分別取 K=1 600、3 200、6 400、9 600、12 800,對每個 K 值下的檢測結果隨機抽樣6 次,每次抽取50 個函數對進行人工查看,計算平均準確率,結果如圖 4 所示。 圖4 本文方法和IDF 方法的抽樣準確率對比 對兩種方法在每個K 值下的抽樣準確率進行雙側t 檢驗,結果表明在顯著性水平為0.05 時,本文方法在實驗數據集上 K=1 600 和 K=12 800 時的準確率高于 IDF 方法,而在 K=3 200、6 400、9 600 時兩種方法的準確率差異不明顯。 本文提出了一種函數級別復用開源代碼檢測方法。 對被測代碼與開源代碼庫使用現有克隆檢測方法檢測的克隆函數,使用一種基于函數克隆語句行和共用標識符在開源代碼庫中頻率的度量指標判定克隆函數的復用情況。 實驗表明,本文的方法能有效檢測復用的函數,相比基于逆文檔頻率的方法能夠進一步降低非復用函數對檢測結果的影響。接下來將進一步尋找其他能夠區分復用代碼與非復用代碼的特征和方法,同時也希望針對復用代碼檢測問題有更多的有標注數據集可用、有更多的方法可供對比選擇。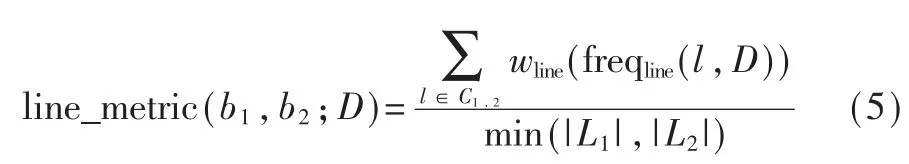

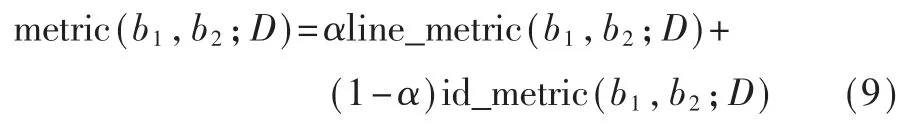
3 實驗與結果分析

3.1 有標注數據集上的準確性評估

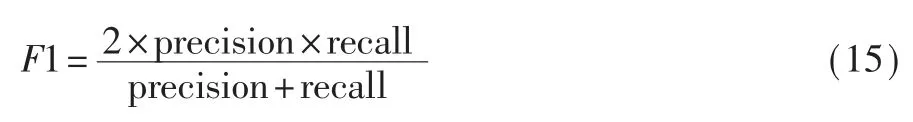
3.2 真實軟件代碼上的準確性評估
4 結論
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
