基于視角轉(zhuǎn)換的多視角步態(tài)識(shí)別方法
2021-06-18 07:32:12瞿斌杰孫韶媛SamahManssor趙國(guó)順
計(jì)算機(jī)工程 2021年6期
瞿斌杰,孫韶媛,Samah A.F.Manssor,趙國(guó)順
(1.東華大學(xué)信息科學(xué)與技術(shù)學(xué)院,上海 201620;2.東華大學(xué)數(shù)字化紡織服裝技術(shù)教育部工程研究中心,上海 201620)
0 概述
生物識(shí)別技術(shù)通過(guò)計(jì)算機(jī)與光學(xué)、聲學(xué)、生物傳感器及生物統(tǒng)計(jì)學(xué)原理等高科技手段密切結(jié)合,利用人體固有的生理特性和行為特征來(lái)進(jìn)行個(gè)人身份的鑒定。當(dāng)前諸如面部、虹膜、指紋和簽名之類的生物識(shí)別技術(shù)已廣泛用于身份認(rèn)證。這些生物識(shí)別技術(shù)的局限性在于需要被測(cè)者的配合來(lái)獲取特征信息。步態(tài)是一種重要的生物特征,它克服了上述限制,在不受控制的情況下無(wú)需對(duì)象合作,攝像機(jī)可以很容易地在遠(yuǎn)距離捕獲目標(biāo)并采集信息[1]。目前步態(tài)識(shí)別方法主要分為基于模型的方法和基于外觀的方法。
基于模型的方法試圖建立模型以從視頻序列重建人體的基礎(chǔ)結(jié)構(gòu)。文獻(xiàn)[2]通過(guò)構(gòu)建身體結(jié)構(gòu)模型來(lái)完成步態(tài)識(shí)別,文獻(xiàn)[3]從多個(gè)相機(jī)重建的3D步態(tài)數(shù)據(jù)進(jìn)行識(shí)別。3D 數(shù)據(jù)比2D 數(shù)據(jù)能夠傳遞更多的信息,但采集成本高限制了其應(yīng)用。
基于外觀的方法將步態(tài)圖像序列作為輸入。此類方法首先從視頻序列中提取二進(jìn)制輪廓序列,然后用多種方法將步態(tài)輪廓序列處理成單張的步態(tài)特征圖,如步態(tài)能量圖像(Gait Energy Image,GEI)[4]即是廣泛使用的一種步態(tài)特征,其通過(guò)在整個(gè)步態(tài)周期上平均輪廓序列獲得,GEI 包含了步態(tài)周期的空間信息。此外,還有其他步態(tài)特征,如運(yùn)動(dòng)歷史圖像(Motion History Image,MHI)[5]。受MHI 的啟發(fā),文獻(xiàn)[6]提出了運(yùn)動(dòng)剪影圖像來(lái)嵌入步態(tài)剪影的時(shí)空信息,文獻(xiàn)[7]提出了用于步態(tài)識(shí)別的步態(tài)流圖像。
盡管目前基于深度學(xué)習(xí)的步態(tài)識(shí)別算法已經(jīng)取得了一些成果,但是步態(tài)識(shí)別面臨著諸多挑戰(zhàn),如視角的變換、著裝變化和攜帶物等。在視角的變換方面[8],由于一般攝像頭均為固定狀態(tài),當(dāng)行人由不同的方向進(jìn)入攝像采集區(qū)域時(shí),會(huì)造成多視角下目標(biāo)姿態(tài)不同的問(wèn)題。針對(duì)這種視角變化問(wèn)題,文獻(xiàn)[9]將來(lái)自不同視角的樣本表示為在原對(duì)應(yīng)視圖下的線性組合,通過(guò)提取特征表示系數(shù)進(jìn)行分類,文獻(xiàn)[10]提取一種基于均值的視角不變步態(tài)特征方法,并基于形狀距離測(cè)量步態(tài)相似性。文獻(xiàn)[11]提出了基于頻域特性和視圖轉(zhuǎn)換的模型。在此基礎(chǔ)上,文獻(xiàn)[12]進(jìn)一步應(yīng)用線性判別分析簡(jiǎn)化計(jì)算。因此,構(gòu)造視角轉(zhuǎn)換模型可以在較小代價(jià)下實(shí)現(xiàn)精度較高的識(shí)別效果。在著裝變化方面,人的著裝在很大程度上會(huì)改變?nèi)梭w的輪廓,尤其在著裝較厚或者衣物較長(zhǎng)的情況下,會(huì)對(duì)人體姿態(tài)形成遮擋,影響步態(tài)的識(shí)別效果。在攜帶物方面,在前景分離的過(guò)程中,人所攜帶的物品極有可能被當(dāng)作人體的一部分而被提取出來(lái),從而影響步態(tài)特征的準(zhǔn)確性。若該行人在其他時(shí)刻未攜帶物品或攜帶其他物品,則較難實(shí)現(xiàn)精確識(shí)別。
本文提出一種基于視角轉(zhuǎn)換的步態(tài)識(shí)別方法。通過(guò)VTM-GAN 網(wǎng)絡(luò)將不同視角下的步態(tài)特征統(tǒng)一轉(zhuǎn)換至90°狀態(tài)下,即目標(biāo)運(yùn)動(dòng)方向與拍攝方向呈垂直狀態(tài),采用視角轉(zhuǎn)換后的步態(tài)數(shù)據(jù)構(gòu)建步態(tài)正負(fù)樣本對(duì),擴(kuò)充用于網(wǎng)絡(luò)訓(xùn)練的數(shù)據(jù)來(lái)增加模型的泛化能力,將時(shí)空雙流卷積神經(jīng)網(wǎng)絡(luò)作為步態(tài)識(shí)別網(wǎng)絡(luò),并在CASIA-B 數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn)驗(yàn)證。
1 步態(tài)數(shù)據(jù)預(yù)處理
良好的步態(tài)序列預(yù)處理可以提升實(shí)驗(yàn)效果,因此將原始步態(tài)序列中的圖像經(jīng)過(guò)混合高斯模型背景差分[13]、形態(tài)學(xué)處理以及尺寸歸一化等操作后能夠得到質(zhì)量較高的步態(tài)二值圖。
基于混合高斯模型的背景差分法是一種較常用的背景減除算法,該算法認(rèn)為像素間顏色互不相關(guān),對(duì)每一像素點(diǎn)的處理都是獨(dú)立的。通過(guò)對(duì)每個(gè)背景像素點(diǎn)建立2 個(gè)~3 個(gè)高斯模型后分別進(jìn)行前背景匹配,得到背景圖象后進(jìn)行差分運(yùn)算得到步態(tài)前景圖。
通過(guò)背景差分后得到的步態(tài)二值圖往往存在較多的空洞以及噪聲,因此,引入圖像形態(tài)學(xué)處理中的開(kāi)運(yùn)算[14],即先腐蝕再膨脹來(lái)消除噪聲以提高步態(tài)輪廓的質(zhì)量,開(kāi)運(yùn)算數(shù)學(xué)表達(dá)式如式(1)所示:

其中,A表示待處理圖像,B表示開(kāi)運(yùn)算所定義的結(jié)構(gòu)體用以遍歷圖像。
經(jīng)過(guò)前兩步得到的步態(tài)二值圖中,目標(biāo)位置及大小往往因?yàn)榕臄z角度以及目標(biāo)位置的改變不盡相同,所以采用步態(tài)尺寸歸一化得到步態(tài)二值圖序列。將每個(gè)歸一化后的輪廓圖B表示為:

其中,(x,y)表示步態(tài)圖左上角坐標(biāo),w和h分別表示為歸一化后二值圖的寬度和高度,實(shí)驗(yàn)中為了減少因縮放尺度給圖像質(zhì)量帶來(lái)的影響,將歸一化二值圖的寬高比例設(shè)置為1,即w=h=240。歸一化二值圖的高度為目標(biāo)的高度,再對(duì)每個(gè)目標(biāo)的中心(Gx,Gy)進(jìn)行計(jì)算,其中x的計(jì)算如式(3)所示:

對(duì)步態(tài)二值圖進(jìn)行平均化相加操作來(lái)獲取GEI,其定義如式(4)所示:
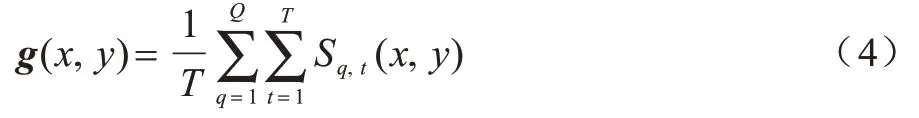
其中,g(x,y)為步態(tài)能量圖,Sq,t(x,y)表示在第q個(gè)步態(tài)序列中時(shí)刻t的步態(tài)剪影圖中坐標(biāo)為(x,y)的像素值。
對(duì)于CGI 的合成,本文參考了文獻(xiàn)[15]提出的方法,在GEI 基礎(chǔ)上,通過(guò)該方法將步態(tài)二值圖序列根據(jù)三通道RGB 色彩的映射,來(lái)保留GEI 圖像中損失的時(shí)間信息。
2 網(wǎng)絡(luò)架構(gòu)及參數(shù)配置
本文主要以VTM-GAN 網(wǎng)絡(luò)作為視角轉(zhuǎn)換網(wǎng)絡(luò),以時(shí)空雙流卷積神經(jīng)網(wǎng)絡(luò)作為步態(tài)識(shí)別網(wǎng)絡(luò),步態(tài)視角轉(zhuǎn)換網(wǎng)絡(luò)VTM-GAN 基于Cycle-GAN 網(wǎng)絡(luò)[16],將不同視角下 的GEI 轉(zhuǎn)換成90°狀態(tài)下 的GEI,從而構(gòu)建擴(kuò)充的正負(fù)數(shù)據(jù)樣本對(duì)。時(shí)空雙流卷積神經(jīng)網(wǎng)絡(luò)同時(shí)保留時(shí)間空間信息,通過(guò)距離度量判斷同時(shí)輸入的樣本是否來(lái)源于同一個(gè)目標(biāo)。
2.1 VTM-GAN 網(wǎng)絡(luò)
VTM-GAN 網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。VTM-GAN 網(wǎng)絡(luò)具有2 個(gè)輸入端,本質(zhì)上是2 個(gè)鏡像對(duì)稱的GAN 網(wǎng)絡(luò),共有2 個(gè)G1生成器、2 個(gè)G2生成器及2 個(gè)鑒別器,在每一對(duì)生成器間共享權(quán)值且采用跳躍鏈接技術(shù)。該網(wǎng)絡(luò)思想是源于Cycle-GAN 網(wǎng)絡(luò),在網(wǎng)絡(luò)中有兩個(gè)數(shù)據(jù)域A和B,該網(wǎng)絡(luò)從域A獲取輸入圖像并傳遞到第一個(gè)生成器G1,完成從域A至域B圖像的轉(zhuǎn)換。然后新生成的圖像被傳遞到另一個(gè)生成器G2,再完成從域B到域A圖像的轉(zhuǎn)換,其目的是在原始域A轉(zhuǎn)換回圖像A'。輸出A'必須與原始輸入圖像相似,用來(lái)定義非配對(duì)數(shù)據(jù)集中原來(lái)不存在的映射。
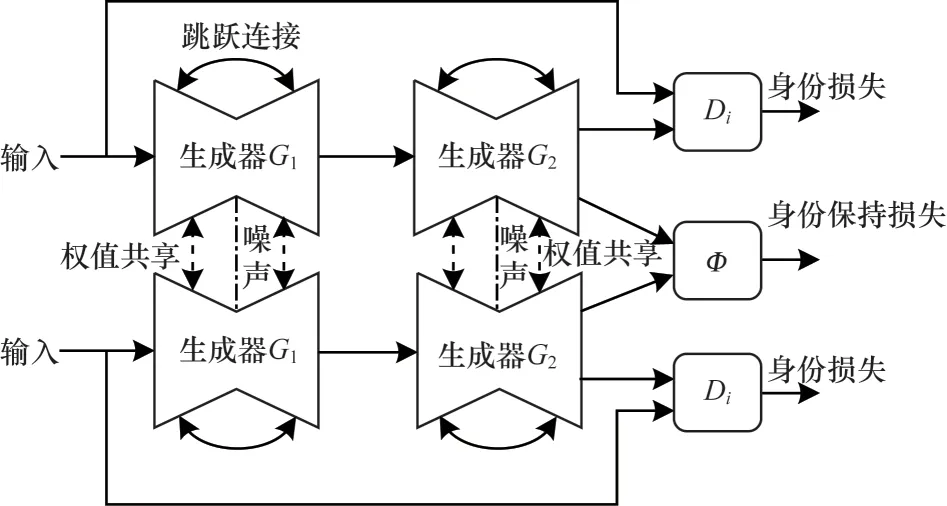
圖1 VTM-GAN 網(wǎng)絡(luò)結(jié)構(gòu)Fig.1 Network structure of VTM-GAN
該網(wǎng)絡(luò)的損失函數(shù)主要由對(duì)抗損失、身份損失、身份保持損失、循環(huán)一致性損失以及分類損失組成。網(wǎng)絡(luò)的對(duì)抗損失主要由兩部分組成,對(duì)于映射A→B和它對(duì)應(yīng)的判別器DB,損失函數(shù)可以定義為:

同理,對(duì)于映射B→A和它對(duì)應(yīng)的判別器DA,損失函數(shù)可以定義為:

當(dāng)網(wǎng)絡(luò)優(yōu)化時(shí),對(duì)于生成器G1即去最小化目標(biāo)函數(shù)式(5),而對(duì)于鑒別器即去最大化目標(biāo)函數(shù)式(5),如式(7)所示:

對(duì)于生成器G2就是去最小化目標(biāo)函數(shù)式(6),而對(duì)于鑒別器就是去最大化目標(biāo)函數(shù)式(6),如式(8)所示:

因?yàn)橛成銰1完全可將所有域A中的圖像轉(zhuǎn)換成域B中同一張圖像,從而導(dǎo)致?lián)p失無(wú)效化,所以引入循環(huán)一致性損失同時(shí)學(xué)習(xí)G1和G2兩個(gè)映射,并要求G2(G1(a))≈a以及G1(G2(b))≈b,該損失如式(9)所示:
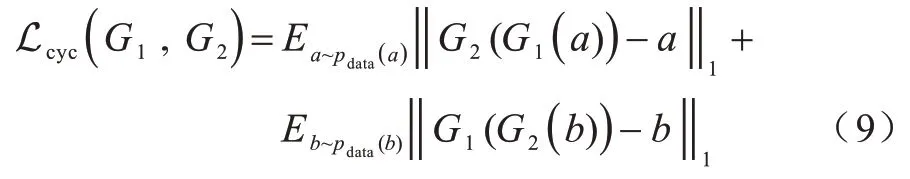
綜上所述,可得網(wǎng)絡(luò)總損失如式(10)所示:
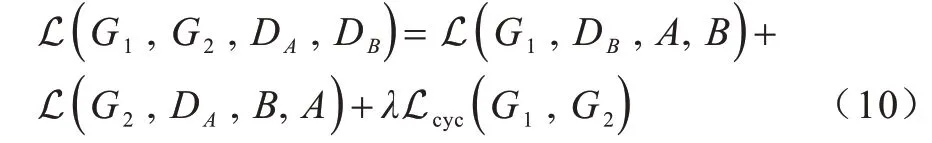
其中,λ用于調(diào)節(jié)循環(huán)一致性損失在總損失中的比重。
生成器是負(fù)責(zé)域A到域B的圖像的生成,輸入一個(gè)域B的圖片生成域B的圖片b',用于計(jì)算b'與輸入b的損失稱為身份損失,而身份保持損失的作用是不僅希望生成的GEI 看上去像同一個(gè)人,而且能夠保持原有的身份信息,因此引入分類損失,并使分類器與生成器進(jìn)行競(jìng)爭(zhēng),與鑒別器進(jìn)行協(xié)作,將真實(shí)圖片與生成的圖片作為輸入,然后預(yù)測(cè)它們的標(biāo)簽,希望兩者間預(yù)測(cè)得到的是同樣的標(biāo)簽,并且使生成的特征盡可能地靠近真實(shí)的特征。
基于以上的思想,將步態(tài)數(shù)據(jù)庫(kù)中不同視角、不同狀態(tài)風(fēng)格下的步態(tài)特征圖統(tǒng)一轉(zhuǎn)換為90°狀態(tài)下正常行走風(fēng)格的步態(tài)特征圖,從而完成對(duì)步態(tài)數(shù)據(jù)庫(kù)樣本的擴(kuò)充并且消除了多視角對(duì)于步態(tài)識(shí)別的影響[17],如圖2 所示,其中,NM 表示正常狀態(tài),BG 表示背包狀態(tài),CL 表示穿外套狀態(tài)。
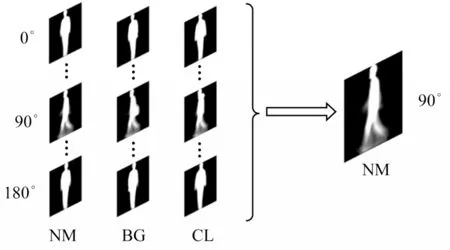
圖2 視角轉(zhuǎn)換示意圖Fig.2 Schematic diagram of view transformation
表1 所示為網(wǎng)絡(luò)生成器的具體參數(shù),其中,輸入尺寸為240 像素×240 像素×1 通道。采用的Unet 網(wǎng)絡(luò)結(jié)構(gòu)由編碼器及解碼器兩部分構(gòu)成,并且在第4 層編碼器之后之間引入[?1,1)范圍內(nèi)遵循均勻分布的噪聲,反卷積層的第一層設(shè)置Dropout 大小為0.5。跳躍連接將d1 與e3、d2 與e2、d3 與e1 進(jìn)行合并。
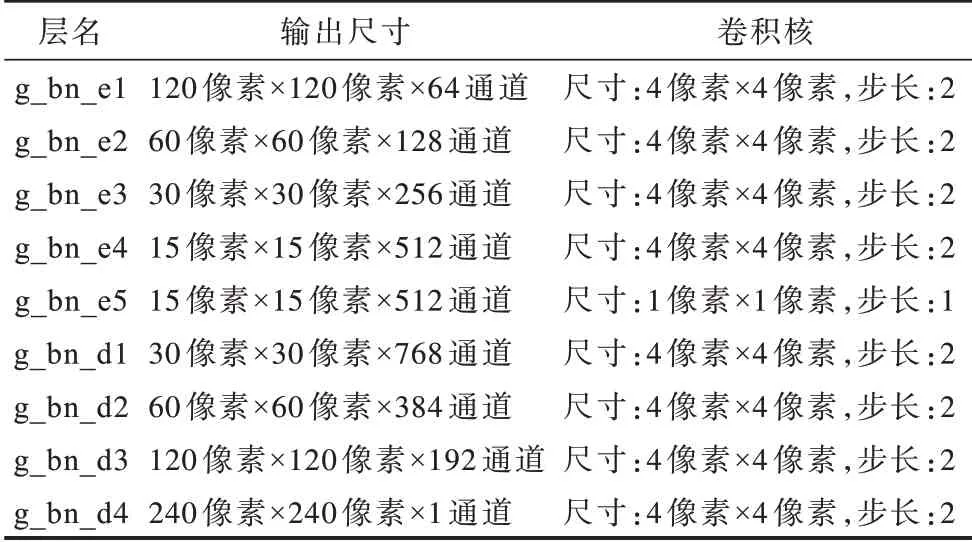
表1 生成器參數(shù)Table 1 Generator parameters
表2 所示為網(wǎng)絡(luò)鑒別器參數(shù),其中輸入尺寸為240 像素×240 像素×1 通道。對(duì)輸入圖像進(jìn)行特征提取,然后確定該輸入是否屬于某特定類別,鑒別器最后一層卷積層通過(guò)產(chǎn)生一維輸出來(lái)完成鑒別。

表2 鑒別器參數(shù)Table 2 Discriminator parameters
2.2 時(shí)空雙流卷積神經(jīng)網(wǎng)絡(luò)
時(shí)空雙流卷積神經(jīng)網(wǎng)絡(luò)具有左右兩側(cè)輸入端,網(wǎng)絡(luò)的左右兩側(cè)具有相同結(jié)構(gòu)和參數(shù),兩側(cè)輸入的樣本對(duì)可以通過(guò)模仿減法運(yùn)算來(lái)得到一對(duì)特征的差別,隨后可以通過(guò)兩者的差別進(jìn)而得到樣本間的相似度。其主要思想是通過(guò)一個(gè)函數(shù)將輸入映射到目標(biāo)空間,在目標(biāo)空間基于距離度量的歐式距離來(lái)對(duì)比相似度。在分別計(jì)算每對(duì)樣本差值之前,只使用線性投影,這是由卷積核在最底卷積階段實(shí)現(xiàn)的,即在網(wǎng)絡(luò)底層進(jìn)行特征的融合,能夠在輸入端減少數(shù)據(jù)復(fù)雜度,進(jìn)而能夠一定程度地減少網(wǎng)絡(luò)復(fù)雜度,更易于計(jì)算。一對(duì)卷積核可接受兩個(gè)輸入,可以看作權(quán)重比較器。在每個(gè)空間位置,首先分別對(duì)其兩個(gè)輸入的局部區(qū)域重新加權(quán),然后將這些加權(quán)后的項(xiàng)相加來(lái)模擬減法。在底層融合之后的深層卷積層可以從樣本對(duì)之間的差異中學(xué)習(xí)更多復(fù)雜信息。
在網(wǎng)絡(luò)的頂層設(shè)置一個(gè)Softmax 二分類器來(lái)判斷輸入樣本對(duì)是否為同一目標(biāo),利用邏輯回歸損失對(duì)整個(gè)網(wǎng)絡(luò)進(jìn)行訓(xùn)練。該預(yù)測(cè)器可用式(11)表示:

其中,x和xi為輸入樣本對(duì),?將x和xi映射到同一空間,與此同時(shí),φ計(jì)算兩個(gè)輸入的權(quán)值差,η作為預(yù)測(cè)器來(lái)預(yù)測(cè)最終的相似度,?可由一層或多層卷積層和全連接層組成,φ必須有兩個(gè)輸入并且可由一個(gè)卷積層或全連接層構(gòu)成,預(yù)測(cè)器η由全連接層和Softmax層構(gòu)成,Si為預(yù)測(cè)器。
該網(wǎng)絡(luò)在訓(xùn)練階段最小化來(lái)自相同類別的一對(duì)樣本的損失函數(shù)值,最大化來(lái)自不同類別的一對(duì)樣本的損失函數(shù)值。給定一組映射函數(shù)Gw(X),其中參數(shù)w為共享參數(shù)向量,目的是尋找一組參數(shù)w,使得當(dāng)X1和X2屬于同一類別時(shí),相似性度量較小,且最小化損失函數(shù)。當(dāng)屬于不同類別時(shí),相似性度量較大,且最大化損失函數(shù)。其中,X1和X2是網(wǎng)絡(luò)的一組輸入圖像,Y為輸入組的一個(gè)0,1 標(biāo)簽,如果輸入為同一個(gè)人,即一組正對(duì),那么Y=0,否則Y=1,相似性度量公式如式(12)所示:

綜上,該網(wǎng)絡(luò)可以用式(13)簡(jiǎn)明地表示為:
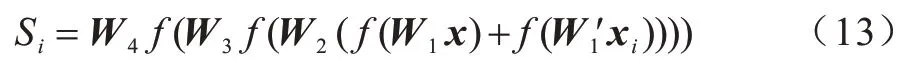
其中,Wl和分別代表了一對(duì)樣本第l層的權(quán)值,f為非線性激活函數(shù),本文采用Relu 作為非線性激活函數(shù)。
網(wǎng)絡(luò)結(jié)構(gòu)及各層參數(shù)設(shè)置如圖3 和表3 所示,在表3 中,輸入尺寸為240 像素×240 像素×2 通道。因?yàn)槭菍?duì)稱的網(wǎng)絡(luò),所以左右兩側(cè)網(wǎng)絡(luò)參數(shù)相同網(wǎng)絡(luò)中的N 為批歸一化技術(shù),網(wǎng)絡(luò)中的D 為Dropout 技術(shù),通過(guò)減少每次訓(xùn)練時(shí)的參數(shù)量,提高了模型準(zhǔn)確率,增強(qiáng)了模型的泛化能力。

圖3 時(shí)空雙流卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)Fig.3 Structure of spatial-temporal double flow convolutional neural network
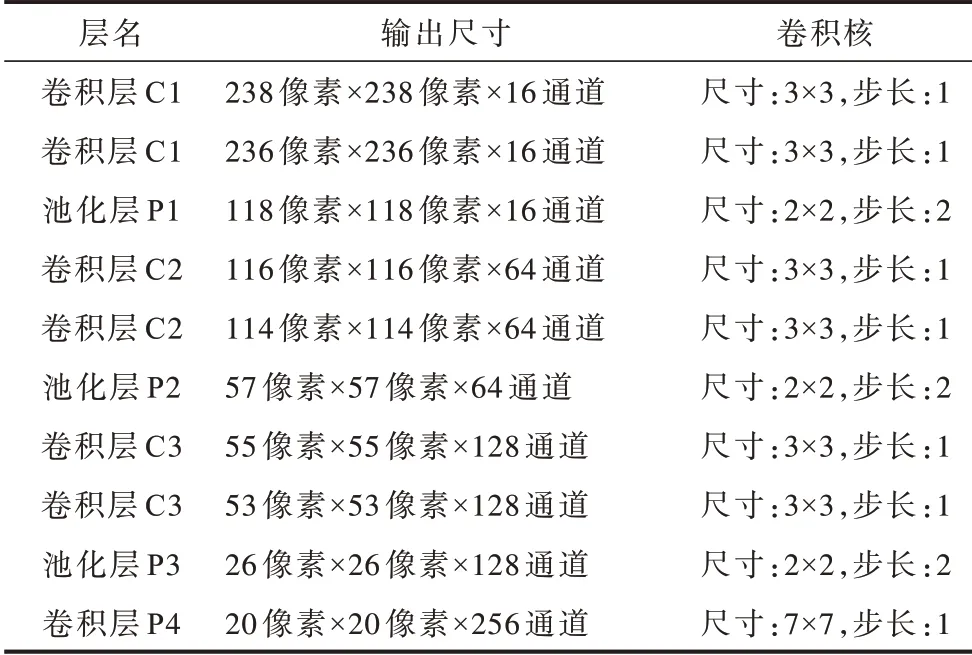
表3 網(wǎng)絡(luò)參數(shù)設(shè)置Table 3 Setting of network parameters
3 實(shí)驗(yàn)結(jié)果與分析
本文采用CASIA-B[17]數(shù)據(jù)集作為實(shí)驗(yàn)數(shù)據(jù),該數(shù)據(jù)集是一個(gè)大規(guī)模、多視角的步態(tài)庫(kù),其中共有124 個(gè)人,每個(gè)人有11 個(gè)視角(0o,18o,36o,…,180o),并在普通條件(NM)、穿大衣(CL)以及攜帶包裹(BG)這3 種行走條件下采集。實(shí)驗(yàn)的具體流程依次為步態(tài)圖像預(yù)處理、GEI 及CGI 的合成、VTM-GAN網(wǎng)絡(luò)視角轉(zhuǎn)換、步態(tài)樣本對(duì)構(gòu)建、時(shí)空雙流卷積神經(jīng)的網(wǎng)絡(luò)訓(xùn)練,最后通過(guò)測(cè)試得到各視角下的準(zhǔn)確率。
本文算法使用PyTorch1.4框架,實(shí)驗(yàn)的軟硬件配置如下:CPU為Intel i5-6600,內(nèi)存為8 GB,GPU為NVIDIA GTX 1060,操作系統(tǒng)為Windows10,CUDA為9.2。
3.1 數(shù)據(jù)預(yù)處理結(jié)果
圖4 所示為實(shí)驗(yàn)得到的各角度不同狀態(tài)下CASIA-B 的GEI,其能很好地表現(xiàn)步態(tài)的速度、形態(tài)等特征。

圖4 不同角度及狀態(tài)下的步態(tài)能量圖Fig.4 Gait energy diagrams at different angles and states
圖5 所示為將步態(tài)二值圖序列通過(guò)RGB 三通道色彩映射后得到的CGI 圖像,通過(guò)色彩映射保留了步態(tài)序列的時(shí)間信息。

圖5 CGI 圖像示例Fig.5 Examples of CGI image
3.2 視角轉(zhuǎn)換及樣本擴(kuò)充
圖6 所示為通過(guò)視角轉(zhuǎn)換后的到的計(jì)時(shí)步態(tài)圖像(CGI)步態(tài)樣本。圖7 所示為將不同視角下、不同行走狀態(tài)下的步態(tài)能量圖像(GEI),通過(guò)VTM-GAN網(wǎng)絡(luò)轉(zhuǎn)換成90°狀態(tài)下的結(jié)果示例,圖中每3 列為一組,每一列分別包含輸入步態(tài)、實(shí)際步態(tài)和正常視圖中的合成步態(tài)。

圖6 CGI 視角轉(zhuǎn)換后結(jié)果Fig.6 Result of CGI after view transformation

圖7 GEI 視角轉(zhuǎn)換后結(jié)果Fig.7 Results of GEI after view transformation
為衡量該視角轉(zhuǎn)換網(wǎng)絡(luò)的準(zhǔn)確性,本文采用余弦相似度來(lái)判斷參考圖像與合成圖像的相似度,余弦相似度公示如式(14)所示:
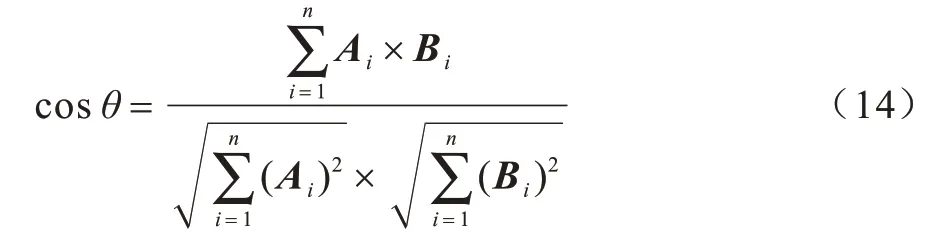
其中,Ai、Bi分別代表參考圖像與合成圖像。如果合成圖像與參考圖像通過(guò)式(14)計(jì)算所得結(jié)果越接近1,那么兩圖就越接近,即合成GEI 的信息保留程度就越高。
如圖8 所示,通過(guò)計(jì)算參考步態(tài)以及合成步態(tài)的余弦相似度,發(fā)現(xiàn)兩者的相似度總體在98.5%以上,因?yàn)閺?°及180°轉(zhuǎn)換至90°的視角跨度較大,所以相似度有所下降。
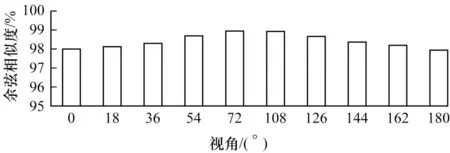
圖8 視角轉(zhuǎn)換后合成步態(tài)與參考步態(tài)的余弦相似度Fig.8 Cosine similarity between the synthesized gaits and the reference gaits after the view transformation
在視角轉(zhuǎn)換前,一共擁有124×10=1 240 個(gè)側(cè)視圖下的步態(tài)樣本,而將CASIA-B 的124 個(gè)目標(biāo)的GEI 以及CGI 樣本全部經(jīng)過(guò)視角轉(zhuǎn)換后,每種共有124×10×11=13 640 個(gè)側(cè)視圖下的樣本,視角轉(zhuǎn)換突破了原數(shù)據(jù)庫(kù)多視角上的限制,大大擴(kuò)充了可訓(xùn)練的步態(tài)樣本數(shù)量。本文使用CASIA-B 中的NM01-NM04、CL01、BG01 序列作為訓(xùn)練集,即124×6×11=8 184 個(gè)特征來(lái)構(gòu)建正負(fù)樣本對(duì)用于時(shí)空雙流卷積神經(jīng)網(wǎng)絡(luò)的訓(xùn)練,每個(gè)目標(biāo)包含了6×11=66 個(gè)側(cè)視圖下的GEI 及CGI,任選同一目標(biāo)的兩個(gè)GEI 及兩個(gè)CGI構(gòu)成一組正樣本對(duì),則共可構(gòu)成對(duì),即2 145 對(duì)。因此,對(duì)于124 個(gè)目標(biāo),總共可以構(gòu)成265 980 對(duì)正樣本對(duì)。同樣,隨機(jī)選取某一目標(biāo)的一個(gè)GEI 及一個(gè)CGI,再選取其他目標(biāo)的某一個(gè)GEI 及某一個(gè)CGI 來(lái)構(gòu)建負(fù)樣本對(duì)。本文構(gòu)建的正負(fù)樣本對(duì)都為265 980 對(duì),即各占總樣本對(duì)的一半。通過(guò)這種樣本構(gòu)建方法,網(wǎng)絡(luò)訓(xùn)練過(guò)程中的樣本量成倍增加,緩解了模型因數(shù)據(jù)量較少而產(chǎn)生過(guò)擬合問(wèn)題。
3.3 時(shí)空雙流卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練及測(cè)試方式
時(shí)空雙流卷積神經(jīng)網(wǎng)絡(luò)采用Adam 進(jìn)行優(yōu)化,設(shè)置初始學(xué)習(xí)率為0.000 1,訓(xùn)練過(guò)程中采用自適應(yīng)方式調(diào)節(jié)各個(gè)參數(shù)的學(xué)習(xí)率。用二分類交叉熵?fù)p失作為模型的目標(biāo)函數(shù)訓(xùn)練網(wǎng)絡(luò),訓(xùn)練集由數(shù)量相同的正負(fù)樣本對(duì)構(gòu)成,Mini-Batch 尺寸為128,每訓(xùn)練一個(gè)Mini-Batch進(jìn)行一次網(wǎng)絡(luò)的權(quán)值更新,損失函數(shù)如式(15)所示:

其中,L(y,y)為二分類交叉熵?fù)p失函數(shù),y和y分別為預(yù)測(cè)值與真實(shí)值。
在訓(xùn)練中,每5 000 次對(duì)模型進(jìn)行一次測(cè)試得到如圖9 所示的訓(xùn)練準(zhǔn)確率及損失變化曲線,時(shí)空雙流卷積神經(jīng)網(wǎng)絡(luò)經(jīng)過(guò)將近1 600K 次迭代后,網(wǎng)絡(luò)損失函數(shù)和訓(xùn)練準(zhǔn)確率逐漸開(kāi)始趨于穩(wěn)定,表明模型已經(jīng)趨于穩(wěn)定。
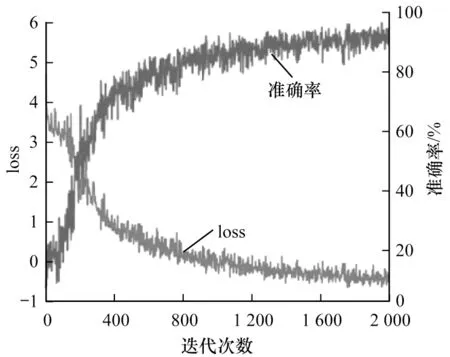
圖9 網(wǎng)絡(luò)損失及訓(xùn)練準(zhǔn)確率變化曲線Fig.9 Network loss and training accuracy curves
對(duì)網(wǎng)絡(luò)進(jìn)行測(cè)試時(shí),分別采用CASIA-B 中NM05-NM06、CL02、BG03 序列中的每個(gè)視角下的GEI作為測(cè)試集。首先將待測(cè)試樣本利用VTM-GAN網(wǎng)絡(luò)進(jìn)行視角轉(zhuǎn)換至側(cè)視狀態(tài)下,此時(shí)一共可以得到124×11×4=5 456 個(gè)測(cè)試GEI。然后隨機(jī)在某類樣本中選擇一個(gè)作為基樣本,將待測(cè)樣本與基樣本構(gòu)成一組樣本對(duì)輸入至訓(xùn)練好的時(shí)空雙流卷積神經(jīng)網(wǎng)絡(luò)中,如圖10 所示,最終得到NM、BG 和CL 各狀態(tài)下各視角的平均準(zhǔn)確率分別為94.4%、92.5% 和90.5%。

圖10 NM、BG 及CL 狀態(tài)下平均測(cè)試準(zhǔn)確率Fig.10 Average test accuracy in NM,BG and CL states
將本文方法與文獻(xiàn)[18]提出的基于3DCNN 方法、文獻(xiàn)[19]提出的Deterministic Learning 方法以及文獻(xiàn)[7]提出的SST-MSCI 方法進(jìn)行比較,如圖11所示,本文方法在視角為0°時(shí)識(shí)別準(zhǔn)確率略低于SST-MSCI 方法,但是在剩余的視角下,識(shí)別準(zhǔn)確率均高于其他幾種算法。此外,將本文方法與文獻(xiàn)[20]提出的GaitGAN 方法進(jìn)行了對(duì)比,該方法在NM 狀態(tài)下識(shí)別準(zhǔn)確率達(dá)到了98.75%,但在BG 以及CL 狀態(tài)下本文方法均高于GaitGAN 算法在這兩種狀態(tài)下的識(shí)別準(zhǔn)確率。
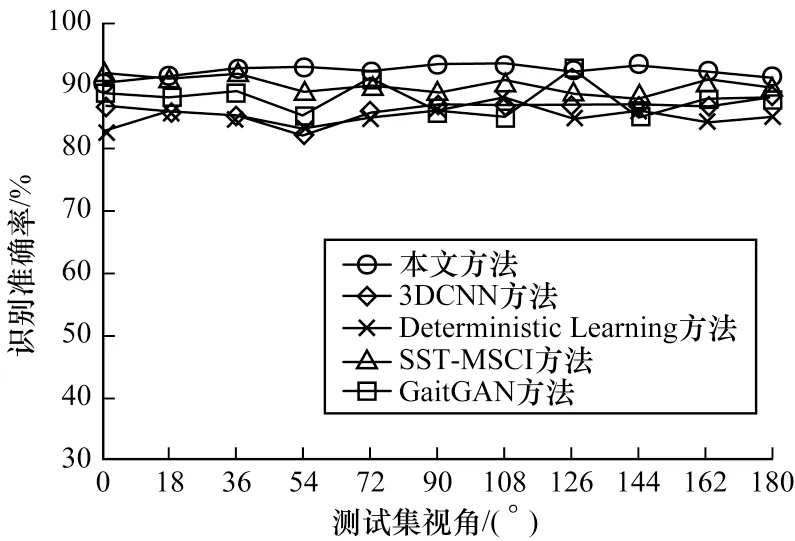
圖11 不同方法識(shí)別準(zhǔn)確率的對(duì)比Fig.11 Comparison of recognition accuracy of different methods
4 結(jié)束語(yǔ)
本文采用基于視角轉(zhuǎn)換的方法進(jìn)行步態(tài)識(shí)別研究,針對(duì)目前步態(tài)識(shí)別中多視角、缺少對(duì)步態(tài)時(shí)間信息的利用以及數(shù)據(jù)量較少等問(wèn)題,結(jié)合VTM-GAN網(wǎng)絡(luò)將不同視角下的步態(tài)樣本統(tǒng)一轉(zhuǎn)換至保留步態(tài)信息最豐富的90°狀態(tài)下,從而構(gòu)建擴(kuò)充的步態(tài)樣本對(duì)訓(xùn)練時(shí)空雙流卷積神經(jīng)網(wǎng)絡(luò)。實(shí)驗(yàn)結(jié)果表明,與3DCNN、Deterministic Learning 等步態(tài)識(shí)別方法相比,本文方法在各角度下步態(tài)識(shí)別準(zhǔn)確率有所提升,驗(yàn)證了基于視角轉(zhuǎn)換方法的有效性。但是針對(duì)多視角狀態(tài)下的步態(tài)識(shí)別仍需改進(jìn),如研究更精準(zhǔn)的行人檢測(cè)模型來(lái)獲取精確的步態(tài)數(shù)據(jù),并結(jié)合多種生物特征的優(yōu)點(diǎn)研究特征融合識(shí)別算法。
