基于大數(shù)據(jù)Hadoop 的企業(yè)財(cái)務(wù)管理系統(tǒng)研究
2021-06-17 12:42:20婁德涵楊江海鄧海生
電子制作 2021年7期
關(guān)鍵詞:數(shù)據(jù)庫(kù)
婁德涵,楊江海,鄧海生
(西京學(xué)院,陜西西安,710123)
1 緒論
■1.1 研究背景和意義
在計(jì)算機(jī)網(wǎng)絡(luò)技術(shù)應(yīng)用于企業(yè)辦公初期時(shí),企業(yè)的財(cái)務(wù)管理都是通過手動(dòng)輸入等若干道流程進(jìn)行的,隨著現(xiàn)代社會(huì)高效率、高要求的節(jié)奏下,傳統(tǒng)的財(cái)務(wù)信息管理效率顯得十分低下。因此財(cái)務(wù)信息必須實(shí)現(xiàn)信息化、流程化管理,于是設(shè)計(jì)一種新的財(cái)務(wù)系統(tǒng)是至關(guān)重要的,企業(yè)財(cái)務(wù)管理系統(tǒng)就是一種能夠勝任企業(yè)各自財(cái)務(wù)管理需求的財(cái)務(wù)管理系統(tǒng)。
■1.2 國(guó)內(nèi)外研究現(xiàn)狀
當(dāng)前社會(huì)發(fā)展日新月異,人們追求創(chuàng)新的思想越發(fā)強(qiáng)烈,管理方式也隨之要?jiǎng)?chuàng)新,利用先進(jìn)技術(shù)轉(zhuǎn)變企業(yè)財(cái)務(wù)管理模式,提高企業(yè)財(cái)務(wù)管理效率進(jìn)入一個(gè)跨越式發(fā)展階段。由于系統(tǒng)平臺(tái)的演變、數(shù)據(jù)庫(kù)的升級(jí),通過數(shù)據(jù)庫(kù)系統(tǒng)的管理分析,向著功能豐富、分析能力強(qiáng)大、支持面廣的方向發(fā)展,演化成ERP 管理系統(tǒng)。財(cái)務(wù)軟件從開始到如今經(jīng)歷了5 個(gè)階段[1],如表1 所示。
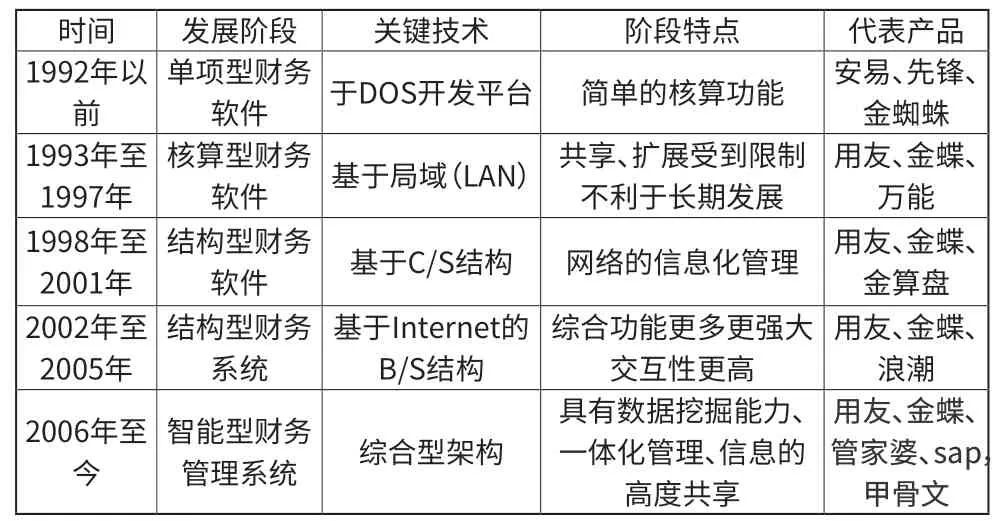
表1 國(guó)內(nèi)外財(cái)務(wù)系統(tǒng)發(fā)展階段
2 相關(guān)的理論及技術(shù)
■2.1 大數(shù)據(jù)特點(diǎn)
大數(shù)據(jù)主要有六大特點(diǎn):海量的容量、數(shù)據(jù)種類繁雜多樣、時(shí)效性高、可變性高、數(shù)據(jù)質(zhì)量高、尋求高質(zhì)量的價(jià)值。
■2.2 大數(shù)據(jù)相關(guān)技術(shù)
(1)Hadoop 生態(tài)系統(tǒng)
①HDFS:一種分布式文件系統(tǒng),具有高容錯(cuò)性、高吞吐量等特點(diǎn),非常適合大規(guī)模數(shù)據(jù)集上的應(yīng)用。②MapReduce:一個(gè)計(jì)算系統(tǒng),將任務(wù)分為“Map(映射)”與“Reduce(規(guī)約)”階段,具有分布式并行處理的熱點(diǎn),因此能快速訪問數(shù)據(jù)。③Hbase:用于快速訪問NoSQL數(shù)據(jù)庫(kù)的工具。④Zookeeper:用于管理Hadoop 集群,協(xié)調(diào)分布式服務(wù)。⑤Pig:一個(gè)數(shù)據(jù)分析引擎,相當(dāng)于一個(gè)翻譯器,將Pig Latin 語(yǔ)句翻譯成MapReduce 程序 。⑥Hive:一個(gè)數(shù)據(jù)庫(kù)框架,可以將結(jié)構(gòu)化的數(shù)據(jù)文件轉(zhuǎn)化為數(shù)據(jù)庫(kù)表,并提供類SQL 查詢功能,將用戶編寫SQL 語(yǔ)句轉(zhuǎn)換為 MapReduce 任務(wù)運(yùn)行。⑦Sqoop:一個(gè)數(shù)據(jù)庫(kù)工具,主要用于NoSQL 數(shù)據(jù)與傳統(tǒng)的數(shù)據(jù)庫(kù)之間的數(shù)據(jù)交互。⑧Flume:一個(gè)日志收集系統(tǒng),具有高效率、高可靠性等特點(diǎn)。
(2)NoSQL
NoSQL為非關(guān)系型的數(shù)據(jù)庫(kù),它具有擴(kuò)展性高、容量大,高性能、可共享、靈活性高等優(yōu)點(diǎn),可以解決海量、復(fù)雜數(shù)據(jù)帶來的各種挑戰(zhàn),尤其是大數(shù)據(jù)應(yīng)用問題。
■2.3 數(shù)據(jù)挖掘
數(shù)據(jù)挖掘方法按照不同挖掘角度來分類,以下為幾種常見的數(shù)據(jù)挖掘方法。
關(guān)聯(lián)規(guī)則,反映一個(gè)事物與其他事物之間存在某種關(guān)聯(lián),通過這種關(guān)聯(lián)挖掘出有價(jià)值的數(shù)據(jù)項(xiàng)。
分類,通過算法找出數(shù)據(jù)庫(kù)中的數(shù)據(jù)對(duì)象中存在的特點(diǎn),然后按照規(guī)定特點(diǎn)進(jìn)行組合分類,將數(shù)據(jù)庫(kù)的數(shù)據(jù)分類到某個(gè)給定的類中,主要用于數(shù)據(jù)預(yù)測(cè)、特征分析。
聚類,將數(shù)據(jù)根據(jù)相似性進(jìn)行分類,同一類中的相似性盡可能大,不同的類中的相似性盡可能小。
回歸分析,將數(shù)據(jù)的屬性值因時(shí)間的變化而存在某種聯(lián)系,將其聯(lián)系的特征映射到實(shí)際預(yù)測(cè)的函數(shù)上,分析其數(shù)據(jù)間存在的關(guān)系,主要應(yīng)用于數(shù)據(jù)序列的特征預(yù)測(cè)與分析。
3 基于大數(shù)據(jù)的企業(yè)財(cái)務(wù)管理系統(tǒng)的設(shè)計(jì)分析
■3.1 總體技術(shù)架構(gòu)設(shè)計(jì)
系統(tǒng)的總體架構(gòu)分為三層:大數(shù)據(jù)并行分析層、大數(shù)據(jù)并行處理層、數(shù)據(jù)存儲(chǔ)層,大數(shù)據(jù)并行處理層解決快速和時(shí)效性要求,大數(shù)據(jù)分析層分析數(shù)據(jù)提取價(jià)值,數(shù)據(jù)存儲(chǔ)層存儲(chǔ)海量復(fù)雜類型數(shù)據(jù)[2]。總體技術(shù)框架如圖1 所示。
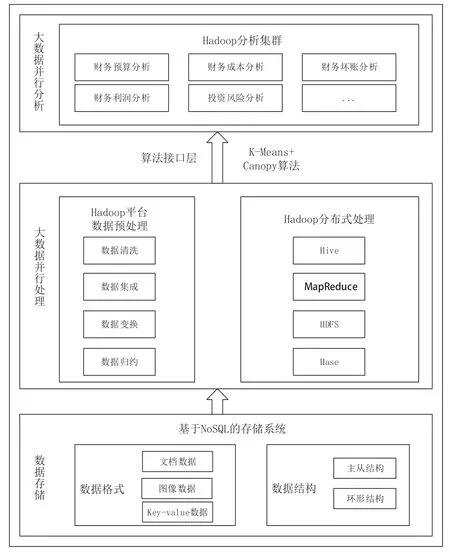
圖1 總體技術(shù)架構(gòu)圖
■3.2 數(shù)據(jù)存儲(chǔ)結(jié)構(gòu)設(shè)計(jì)
NoSQL 分為兩種結(jié)構(gòu),主從結(jié)構(gòu)和環(huán)形結(jié)構(gòu)。主從結(jié)構(gòu)的優(yōu)點(diǎn)為結(jié)構(gòu)簡(jiǎn)單、可控性好、低負(fù)載,缺點(diǎn)為主節(jié)點(diǎn)易成為瓶頸。環(huán)形結(jié)構(gòu)優(yōu)點(diǎn)為無(wú)主節(jié)點(diǎn)、各節(jié)點(diǎn)自協(xié)調(diào)性好,擴(kuò)展性高、負(fù)載均衡性好,缺點(diǎn)為結(jié)構(gòu)復(fù)雜、可控性差、范圍查詢較差。在企業(yè)財(cái)務(wù)系統(tǒng)中,應(yīng)綜合考慮兩者的優(yōu)缺點(diǎn),根據(jù)企業(yè)規(guī)模合理做出選擇。在對(duì)企業(yè)財(cái)務(wù)現(xiàn)狀分析以及大數(shù)據(jù)研究的基礎(chǔ)上,設(shè)計(jì)了新的財(cái)務(wù)大數(shù)據(jù)預(yù)處理模型,建立了以Hadoop 生態(tài)和NoSQL 存儲(chǔ)系統(tǒng)為核心的財(cái)務(wù)數(shù)據(jù)預(yù)處理平臺(tái)。

圖2 NoSQL 存儲(chǔ)流程圖
4 基于大數(shù)據(jù)企業(yè)財(cái)務(wù)管理系統(tǒng)關(guān)鍵性算法研究
■4.1 基于K-MEANS 的數(shù)據(jù)分析算法
K-means 算法的基本思想為,事先設(shè)定一個(gè)參數(shù)k,即將數(shù)據(jù)分為k 類且隨機(jī)選擇的初始聚類中心也為k 個(gè),計(jì)算每個(gè)元素到k 個(gè)聚類中心的距離,將距離最短的那個(gè)元素歸為其聚類中心一類中。當(dāng)所有元素都分配到所屬的類中,所有聚類中心將重新計(jì)算,重復(fù)以上步驟,直到聚類準(zhǔn)則函數(shù)收斂為止[3]。
■4.2 基于Canopy 的數(shù)據(jù)分析算法
Canopy 算法是一種專門處理海量多樣化數(shù)據(jù)的聚類算法,因其不需要事先設(shè)定聚類參數(shù),通常用Canopy 算法對(duì)數(shù)據(jù)進(jìn)行初步處理,達(dá)到數(shù)據(jù)“粗”聚類效果,再運(yùn)用其他算法對(duì)數(shù)據(jù)進(jìn)一步處理。Canopy 算法思想為[4]:
①隨機(jī)兩個(gè)閾值T1、T2(T1<T2)作為參考值,初始化聚類中心為數(shù)據(jù)集中任意元素,其他元素到聚類中心的距離小于T2,則將其元素與聚類中心歸為一類。
②在距離大于T2 的元素中,任意選擇一個(gè)作為新的聚類中心,重復(fù)步驟1,當(dāng)存在元素曾屬于某個(gè)類時(shí)且距離小于其某個(gè)類中T1 時(shí),則排除改元素。
③重復(fù)以上步驟,直到數(shù)據(jù)集為空。
■4.3 基 于Map-Reduce 的Canopy+K-means 算法研究
K-means 算法雖然效率高,聚類參數(shù)的隨機(jī)性與初始聚類中心的不確定性是K-means 算法的兩個(gè)缺點(diǎn),因此會(huì)導(dǎo)致聚類最優(yōu)值不穩(wěn)定。為了提高聚類效果的穩(wěn)定性與準(zhǔn)確性,提出了Canopy+K-means 算法[5]。利用Canopy 算法對(duì)數(shù)據(jù)粗處理,處理后的數(shù)據(jù)作為K-means 的初始數(shù)據(jù),可以解決K-means 存在的問題,提高了K-means 算法的效率。為了提高Canopy+K-means 算法的工作效率,采用與Hadoop 生態(tài)Map-Reduce 框架相結(jié)合,多服務(wù)器部署提高進(jìn)一步提高算法的時(shí)效性,也是企業(yè)財(cái)務(wù)管理系統(tǒng)的核心。執(zhí)行過程主要為兩個(gè)階段:
①Canopy 聚類階段:map 過程將數(shù)據(jù)集分組,對(duì)每個(gè)組分別利用Canopy 算法聚類,得到多個(gè)Canopy 聚類。Reduce 過程將多個(gè)Canopy 中心合并為一組,重新進(jìn)行Canopy 聚類得到新的Canopy 中心。
②K-means 聚類階段:Canopy 中心作為K-means 初始化聚類中心,Map-Reduce 中的一次任務(wù)就是K-means一次迭代。Map-Reduce 中Map 函數(shù)記錄每次樣本元素到聚類中心得距離與每次聚類結(jié)果,再通過Reduce 函數(shù)來重新計(jì)算。重復(fù)步驟,直到聚類結(jié)果最為收斂、最為穩(wěn)定,執(zhí)行流程如圖3 所示。
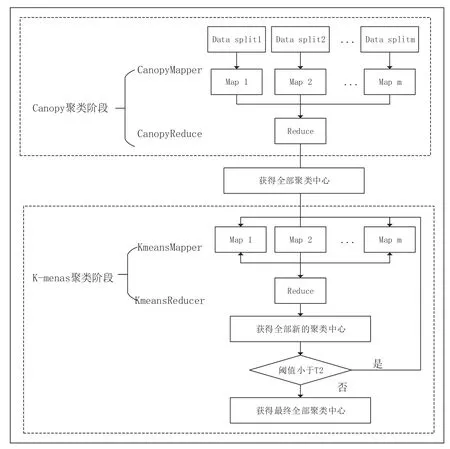
圖3 系統(tǒng)算法執(zhí)行流程圖
5 實(shí)驗(yàn)
為了驗(yàn)證基于Hadoop 改進(jìn)的Canopy+K-means算法的有效性,本文選取兩個(gè)數(shù)據(jù)集,與傳統(tǒng)的Canopy+K-means、K-means 算法進(jìn)行對(duì)比,并基于DB、SC、AMI 等聚類評(píng)價(jià)指標(biāo)評(píng)價(jià)聚類效果[6]。
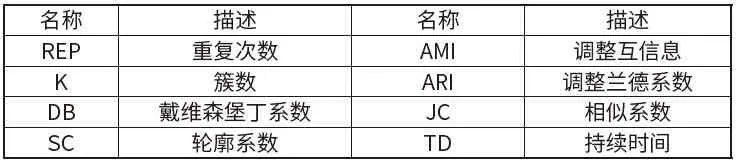
表2 聚類評(píng)價(jià)指標(biāo)
從表3 和表4 可以看出,無(wú)論是DB、SC、AMI、ARI還是JC、TD,Canopy+K-means 算法的聚類效果要明顯優(yōu)于K-means 算法。K-means 算法需要事先設(shè)定參數(shù)k,而優(yōu)化后的算法無(wú)需事先設(shè)定k 值,但卻可以得到更好的初始聚類中心點(diǎn),從而得到更真實(shí)的聚類結(jié)果,并且與Hadoop 相結(jié)合的Canopy+K-means 聚類效果更優(yōu)于傳統(tǒng)Canopy+K-means 算法。

表3 設(shè)定K-means簇?cái)?shù)為5時(shí)聚類效果評(píng)價(jià)
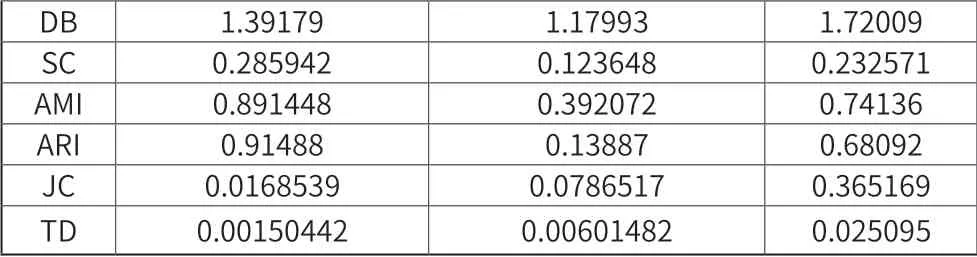
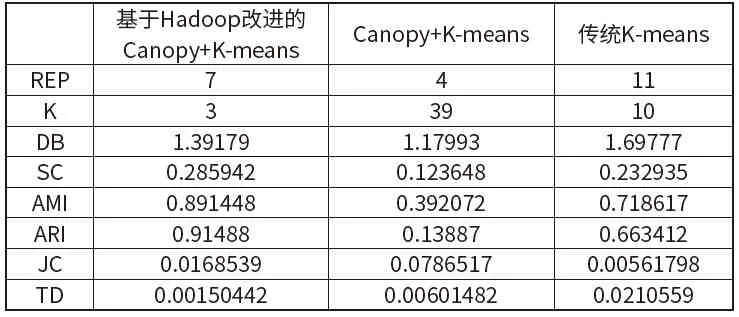
表4 設(shè)定K-means簇?cái)?shù)為10時(shí)聚類效果評(píng)價(jià)
6 結(jié)論
本文針對(duì)傳統(tǒng)K-means 算法在聚類時(shí)需事先設(shè)定確定參數(shù)k 和無(wú)法確定初始聚類中心的問題,通過 Canopy 算法對(duì)K-means 算法進(jìn)行優(yōu)化并與大數(shù)據(jù)平臺(tái)Hadoop 結(jié)合,將其應(yīng)用于企業(yè)財(cái)務(wù)管理系統(tǒng)中;闡述了Canopy、K-means與Canopy+K-means 算法思想,以及基于Hadoop 中Map-Reduce 框架下的聚類步驟,并通過實(shí)驗(yàn)分析了基于該算法進(jìn)行財(cái)務(wù)信息聚類,相較于傳統(tǒng)K-means有更好的聚類效果。
猜你喜歡
財(cái)經(jīng)(2017年15期)2017-07-03 22:40:49
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
華東師范大學(xué)學(xué)報(bào)(自然科學(xué)版)(2017年1期)2017-02-27 13:41:08
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
財(cái)經(jīng)(2015年3期)2015-06-09 17:41:31
財(cái)經(jīng)(2014年21期)2014-08-18 01:50:18
財(cái)經(jīng)(2014年6期)2014-03-12 08:28:19
財(cái)經(jīng)(2013年6期)2013-04-29 17:59:30
