基于K-means算法的互聯網有害信息挖掘模型構建
2021-06-16 16:43:04尚秋明
電子技術與軟件工程 2021年4期
關鍵詞:信息
尚秋明
(中國互聯網絡信息中心 北京市 100190)
當今時代人們多數通過互聯網進行聊天、交易等活動,信息技術的高速發展大大提高了信息傳遞效率,虛擬網絡中越來越多的有害信息不僅嚴重危害了網絡環境,擾亂了社會治安,還給網民帶來經濟損失。因此,對互聯網有害信息監管是當前亟需解決的問題。
隨著互聯網每時每刻產生的海量數據,傳統的監管方式在互聯網有害監管方面存在效能低下、管理松散、數據難以共享等難題。隨著大數據技術不斷出現,這一問題逐漸得到一定程度的解決。目前應用比較廣泛的數據挖掘算法主要有K-means、決策樹、Apriori等,其中K-means 算法運行效率高、實現容易被廣泛應用到數據挖掘中。本文就K-means 算法在互聯網違法信息監管中應用進行研究。
1 K-means算法
K-means 算法核心思想是將某些相似的數據進行分類后聚集在一起方法。該算法首先選取K 個中心點,然后計算每個中心點到各種聚類群體之間的聚類,重新分配中心點。采用迭代方法進行聚類中心劃分,直到中心點達到設置范圍,算法終止[1-2]。可用如下公式進行表達:

式中:xi表示第j 個簇類中第i 個數據;cj表示第j 個簇類中心點。
2 K-means算法在輿情監測管理中應用
輿情監管是互聯網有害信息管理重要內容。梁曉賀[3]研究了網絡微博輿情問題,提出了一種微博輿情主題發現超網絡模型及超邊相似算法,圖1 為該算法流程圖。
所設計的超邊相似度算法微博輿情監控模型中假設輿情主題中網絡模型共計N 條超邊,用符號相似度計算方法為:
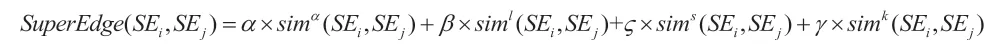

所設計的算法與K-means 算法融合后,通過仿真,結果表明所設計的算法在微博輿情監控中能夠很快識別。
王林[4]針對復雜的微博熱點問題,當前所使用的K-means 算法在初始中心選點存在難點問題,提出了一種基于MapReduce 的并行K-means 算法。該算法核心思想為使用MapReduce 中的map函數進行對象到聚類中心距離計算,該過程中需要重新標記聚類類別。Reduce 函數主要進行Map 函數的中間結果計算,并形成一個簇類中心。仿真結果表明所改進算法提高了K-means 算法精度,在輿情監測管理中有重要作用。
田世海[5]為提高輿情監管準確率,將K-means 算法與NRL 結合融合在一起形成新的算法。該算法核心思想是通過概率事件進行輿情監管。假設每個輿情監管事件中都包含兩個d 維向量,分別為表示節點作為其它相鄰節點的d 維向量。可用計算公式表示。使用概率計算方法得到輿情關注概率為:將K-means 算法應用到概率計算中得到,輿情事件分類為m 類,符號中心點用符號表示簇類劃分點數,每個簇類代表每個輿情事件,事件之間相似度可用符號表示。中心點平均值計算方法為:。仿真結果表明所設計的算法能夠較快明確分組數量,聚類效果好。
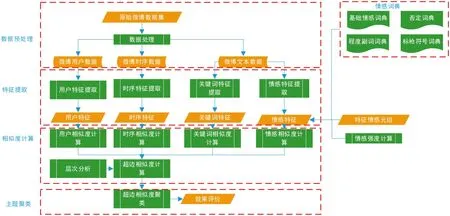
圖1:基于超邊相似度算法微博輿情監控算法
閆俊伢[6]對K-means 算法應用到輿情監管應用進行詳細分析,發現現有的K-means 算法在輿情挖掘中存在挖掘準確率和穩定性有待提升問題。為解決這一問題,提出了將遺傳算法與K-means 算法相結合。基于遺傳算法、K-means 算法相結合的聚類算法中使用浮點編碼規則進行編碼;使用均勻變異算子進行基因變異;適應度計算方法為,E 表示誤差平方和,b 為常數。
徐建國[7]將改進的K-means 算法應用到高校輿情監管中。當前K-means 算法容易存在局部最優問題,在傳統的聚類算法中增加了相似度計算方法重新選取新的簇類中心。仿真結果表明所設計的算法相比傳統的K-means 聚類算法性能提升了8%。陳艷紅[8]研究了K-means 算法在高校輿情監控中應用,提出了將剩余的樣本與中心點進行中心點選擇,仿真結果表明改進算法能夠提高算法性能。
謝修娟[9]針對當前K-means 算法初始聚類中心選取容易導致算法陷入局部最優問題,對K-means 算法進行改進。所設計的算法借用DBSCAN 密度算法進行改進。假定微博文檔集合符號初始聚類中心集合符號初始化聚類簇符號改進K-means 算法偽代碼為:

Input:微博數據Output:違法信息監督結果Step1:從數據庫中獲取微博文檔數據集b,根據初始類中心c,進行聚類劃分Step2:更新聚類中心,清空聚類中心,進行下一類操作Step3:重復Step1 和Step2,如果達到設置誤差函數,跳轉到Step4;否則跳轉到Step1 Step4:輸出監督結果。
研究結果表明所改進的K-means 算法具運行效率、準確性、穩定性指標等到提高。
張壽華[10]針對網絡輿情熱點話題監督提出了使用K-means 算法進行挖掘。所構建的輿情監測模型中,關鍵詞提取計算方法為:
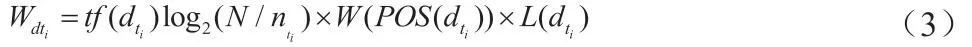
文檔聚類計算方法為:
(1)熱點新聞分析模型為:
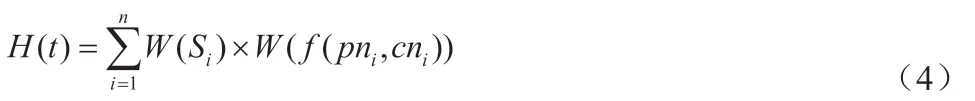
式中:H(t)表示新聞熱度值;n 表示新聞數量;W(Si)表示新聞網站權重;表示新聞參與評論權重;pni表示新聞參與人數;cni表示新聞評價人數。
(2)信息轉載模型為:
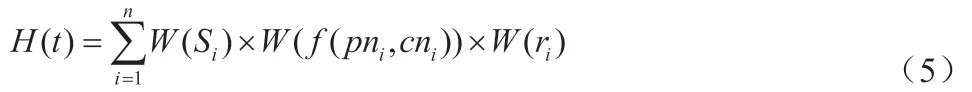
式中:H(t)表示話題論壇熱度值;n 表示話題數量;W(Si)表示話題的權重值;表示話題瀏覽次數和回復權重;pni表示話題參與人數;cni表示話題評價人數;W(ri)表示話題轉載次數權重。
應用結果表明所設計的基于K-means 算法的話題聚類方法能夠很好進行話題監管。
3 K-means算法在互聯網有害行為監管中應用
互聯網違法信息監管是當前重點研究課題。汪黎嘉[11]詳細研究了K-means 算法在網絡有害信息監管中應用,所設計的算法包括:
(1)網絡信息初步篩選,計算方法為:
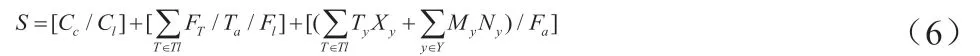
式中:S 表示互聯網信息可行度評價指標;Cc 表示信息變更次數;Cl 表示信息變更閥值;Ft 表示互聯網信息訪問次數;Tt 表示違法信息訪問時間。
呂飛[12]將改進K-means 算法應用到互聯網涉煙違法犯罪區域劃分研究。針對傳統的K-means 算法局部容易出現最優情況,提出了使用概率方法尋找質點。應用結果表明所設計的算法能夠準確識別煙草互聯網有害信息。
張玉峰[13]研究了有害信息的類型,包括色情信息、虛假信息、垃圾信息、網絡安全信息、文化侵略信息等。提出使用數據挖掘技術對有害信息挖掘。結果表明K-means 算法在有害信息分類中具有重要應用前景。
4 結語
本文詳細分析了K-means 算法在互聯網有害信息挖掘中應用。當前K-means 算法應用到輿情監管中發揮了重要作用,未來發展方向是結合大數據技術、神經網絡算法,能夠提高算法準確率。K-means算法應用到有害監管中具有重要作用,未來可發展到詐騙行為識別中。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
