基于企業知識庫的智能問答技術與應用
2021-06-16 14:21:52張穎沈辰楠杜秀蘭閻曉強
電子技術與軟件工程 2021年5期
張穎 沈辰楠 杜秀蘭 閻曉強
(中國市政工程華北設計研究總院有限公司 天津市 300074)
1 前言
近年來,隨著企業管理水平不斷提升,員工對企業各規章制度和辦事流程不了解會使工作寸步難行。通過研究基于知識庫的智能問答相關技術,將企業的各個環節集成起來,共享信息和資源,同時利用現代的技術手段不斷提高生產效能和質量,增強企業的市場競爭力。
智能問答系統[1]的概念最早提出于20 世紀60年代,并在此后不斷發展。國外在智能問答系統領域取得了一系列研究成果,而國內問答系統的研究起步較晚,1970年后才開始基于漢語的中文問答系統的研究。近年來,智能問答系統取得了很大的發展和進步,已經有很多智能問答系統產品問世,然而這些領域都各自相對獨立并且采用了不同的方法,且這些方法都有著各自的瓶頸,所以如何根據企業自身情況尋找合適的理論和算法構建出符合企業實際需求的智能問答系統就變得尤為重要。企業智能問答系統的目標是提供一個及時解決員工各種需求問題的平臺,員工在日常工作中一旦不了解辦事流程或需要查詢任何資料,可以通過使用該問答系統及時得到解答。同時系統還需提供一個管理平臺供運營和管理人員使用,負責系統的日常維護和問題管理。本系統應具有較高的問題解決率和回答準確率,在智能問答部分,員工以自然語言的方式輸入問題時,系統應通過相關自然語言技術最大程度匹配到最佳答案,并為用戶推薦相關問題。
2 系統構建設計
2.1 系統整體架構
企業智能問答系統的目標是提供一個及時解決員工各種需求問題的平臺,員工在日常工作中一旦不了解辦事流程或需要查詢任何資料,可以通過使用該問答系統及時得到解答。同時系統還需提供一個管理平臺供運營和管理人員使用,負責系統的日常維護和問題管理。本系統應具有較高的問題解決率和回答準確率,在智能問答部分,員工以自然語言的方式輸入問題時,系統應通過相關自然語言技術最大程度匹配到最佳答案,并為用戶推薦相關問題。根據以上需求,智能問答系統整體設計架構如圖1 所示,該架構需解決的關鍵問題有如下三個,企業知識庫的構建、自然語言處理以及語義相似度匹配算法選取。
2.2 知識庫的建立
本平臺中知識庫中的知識來源分為兩類:一類是通過各種途徑收集的日常工作中經常遇到的問題以及解決方案,這些問題和解決方案都是經過專業人員審核后歸入知識庫;另一類是日常工作中相關人員實時發布的消息、制度、新聞、附件、通知等,實時發布后即刻歸入知識庫。根據工作要求,這兩類知識分別存儲于不同的服務器,通過數據庫連通形成了跨服務器的方式將不同類型的知識以及不同出處的知識匯集在一起,形成多領域、多平臺的知識庫。
為了解決知識庫內容有限,不能包含工作中所有的問題,本平臺設計了一個開放性的人機對話窗口,使用者或者管理員可以隨時將遇到的問題輸入到平臺中,其他管理員(或專家)可以對提出的新問題進行解答和補充。由此可以增強本平臺的適應能力和學習能力,隨著時間的推移,知識庫中的知識會越來越豐富,不僅可以提高平臺解答問題的能力,對于以后數據的使用提供更多的可能性。
2.3 分詞算法的實現
中文分詞[2]是中文文本處理的一個基礎步驟,也是人-機自然語言交互的基礎模塊,在進行自然語言處理時,通常需要先進行分詞,Jieba 分詞是現在非常流行且開源的分詞器。Jieba 分詞算法首先將停用詞去掉,在通過基于前綴詞典實現高效的詞圖掃描,生成句子中漢字所有可能生成詞情況所構成的有向無環圖(DAG), 再采用了動態規劃查找最大概率路徑,找出基于詞頻的最大切分組合。本平臺所采用的Jieba 分詞原理如下:
2.3.1 去掉通用詞
Jieba 分詞自帶的h_stop_words.txt 中包含常用且無意義的詞,例如的、地、在。要、我以及一些特殊符號、數字等,用戶可以可根據自己的需求將一些常用寫無意義的詞放置到h_stop_words.txt中,即可在程序運行時將其去掉。
2.3.2 前綴詞典的構造
Jieba 分詞自帶dict.txt 詞典,這個詞典中包括詞條、詞條出現的次數和詞性。當程序運行的時候,它會加載統計詞典生成前綴詞典,它是在統計詞典中出現的每一個詞的每一個前綴提取出來,統計詞頻,如果某個前綴詞在統計詞典中沒有出現,詞頻統計為0,如果這個前綴詞已經統計過,則不再重復。
2.3.3 有向無環圖(DAG)
以每個字所在的位置為鍵值key,相應劃分的末尾位置構成的列表為value,基于以上構建的鍵值對,可以構成這個文本對應的有向無環圖,并在有向無環圖中找出概率最大的路徑,即每一個詞出現的概率等于該詞在前綴里的詞頻除以所有詞的詞頻之和。如果詞頻為0 或是不存在,當做詞頻為1 來處理,概率最大的詞為最終的分詞結果。
2.4 匹配算法的實現
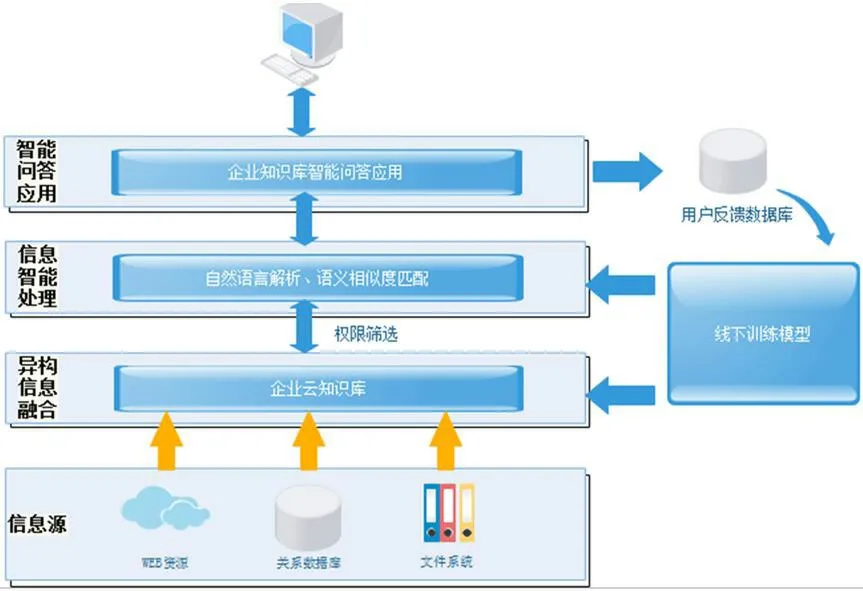
圖1:智能問答系統整體架構
本平臺采用的匹配算法是向量空間余弦相似度[3](Cosine Similarity)算法。向量空間余弦相似度計算是指將兩個不同的文本或語句映射到向量空間中,形成文本中文字和向量數據的映射關系,通過計算不同向量之間的差異大小來計算文本的相似度。具體方法如下:
(1)分詞
例如:
句子A:我今天要去電影院看電影;
句子B:我今天要去看電影;
通過上一節講解的Jieba 分詞方法,對句子A 和B 進行停用詞刪選及分詞,結果如下:
句子A:今天 去 電影院 看 電影
句子B:今天 去 看 電影
(2)列出所有詞
今天 去 電影院 看 電影
(3)計算詞頻
句子A:今天1 去1 電影院1 看1 電影1
句子B:今天1 去1 電影院0 看1 電影1
(4)寫出詞頻向量
句子A:[1 1 1 1 1]
句子B:[1 1 0 1 1]
(5)計算相似度
計算兩個向量的相似度是通過計算兩個向量的余弦值進行判斷。假設向量a(x1,y1)和向量b(x2,y2),則向量a 和向量b 的夾角余弦值計算公式為:
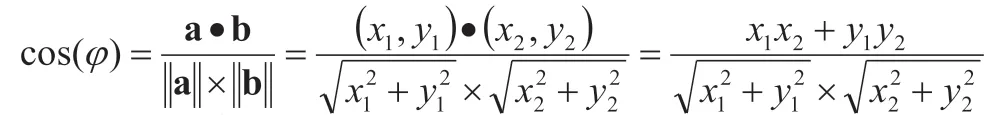
在根據相似度的值進行排序,并設定閾值,將大于閾值的10條信息顯示在界面上。
3 系統開發實現
3.1 開發工具及環境
通過軟件工程標準開發方案,采用基于MVC 設計模式的Struts2 Web 應用框架,以WebWork 為核心,采用攔截器的機制來處理用戶的請求。運用Tomcat 8.5 運行環境、基于MyEclipse 8.5 開發環境進行的系統開發,前端采用HTML5、JSP、JavaScript、jQuery 等開發語言,后端采用JAVA 語言進行開發,并將所有的數據存儲于SQL Server2008 數據庫中。
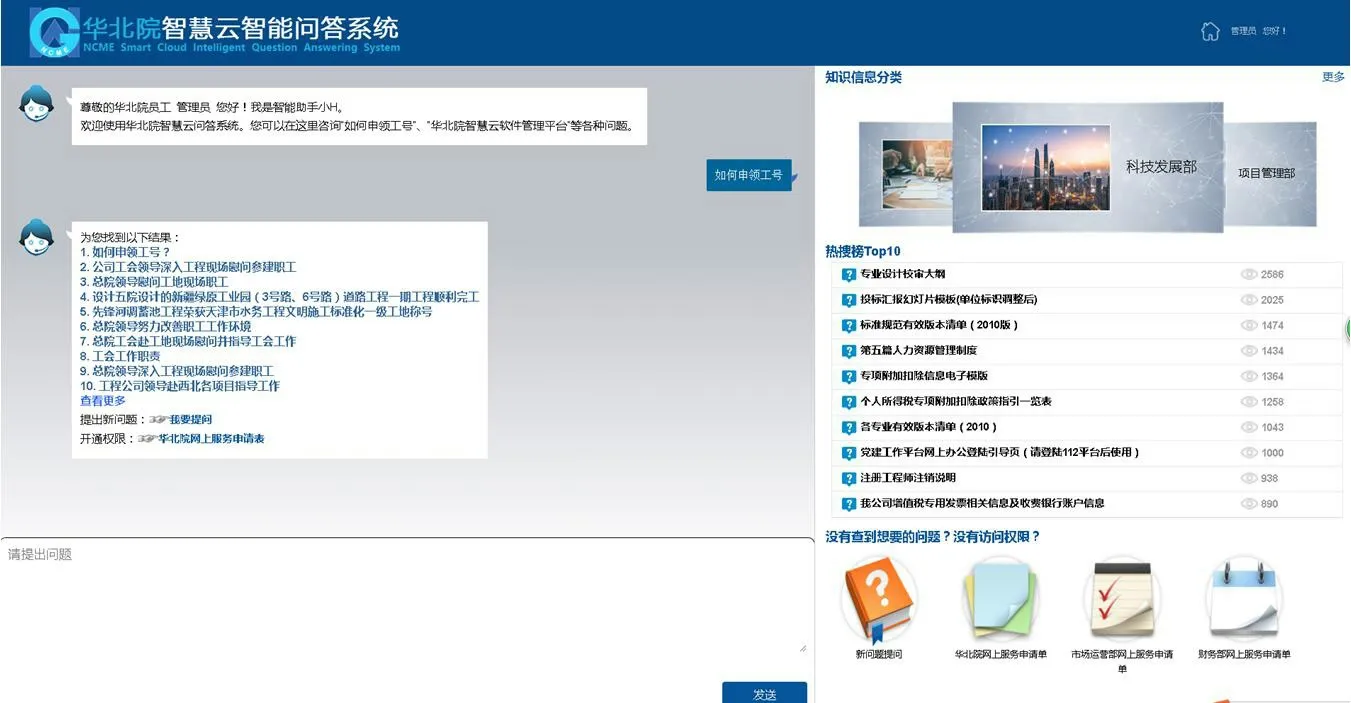
圖2:系統首頁圖
3.2 系統功能介紹
企業智能問答系統主要包括主界面、搜索查詢界面、信息分類界面以及其他附屬界面。
系統首頁為用戶進入系統后所看到的頁面,主要包括搜索查詢以及聊天窗口、知識分類相關鏈接、熱搜問題鏈接、常用網上服務鏈接等,系統首頁如圖2 所示。
用戶通過左側搜索查詢界面將想要提問的問題進行輸入,并將搜索出的相關信息顯示在此頁面,達到及時搜索及時顯示的目的,同時模擬了人-機的聊天模式。搜索查詢頁面主要包括提問窗口以及聊天界面兩部分。
右側信息分類部分包括了各個部門的門戶網站以及各個部門發布的相關信息,用戶可在此部分快速瀏覽到各個部門發布的相關信息,幫助用戶更加快速的了解各部門發布的制度、規范等。知識信息分類包括各部門門戶網站平臺入口鏈接以及知識信息匯總界面兩部分
為方便用戶進行權限申請等其他操作,本平臺將一些工作中常用的表單連接放在此處。用戶可通過右側常用鏈接進行新問題的提問以及公司內部網上權限的申請。
3.3 系統創新點
(1)自然語言處理與應用領域相結合。該項目應用于市政設計企業,知識庫內容不僅涵蓋了企業日常管理中關于財務、人事、物資、質量、經營、檔案等相關內容,還包含了生產設計中關于給水排水、熱力、暖通、海綿城市等市政行業專業領域內容,具有鮮明行業特色,將行業特色詞匯加入自然語言處理過程中,大大提高系統的實用性。
(2)平臺知識庫構建與云概念相結合。該系統并非獨立平臺,是依托于企業已有的管理平臺而使用,智能管控范圍不僅限于平臺本地知識庫,可跨服務器跨平臺獲取企業所積累的相關知識信息,豐富全面,避免重復錄入,同時可在平臺間跳轉獲取答案,靈活直觀。
4 結束語
隨著企業管理水平的不斷提升,員工對企業各規章制度和辦事流程不了解會使工作寸步難行,本文通過Javaweb 技術、Jieba 分詞方法和余弦相似度方法搭建智能問答系統,將企業的各種規章制度、辦事流程、新聞、相關專業知識等信息集成在一個系統中,并通過數據庫連通的方法將不同服務器中的數據進行整合,形成多領域、多平臺的知識庫。并打造智能人-機界面,用戶在前端界面輸入自然語言,智能問答系統可通過界面中的智能助手同樣以自然語言的形式將匹配度高的答案顯示在界面中,并提供多種常用鏈接入口,提高用戶的辦公效率,加強企業的信息化發展,降低管理者的工作負擔。
猜你喜歡
當代陜西(2020年13期)2020-08-24 08:22:02
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
制造技術與機床(2017年5期)2018-01-19 02:49:17
商用汽車(2016年11期)2016-12-19 01:20:16
濰坊學院學報(2016年2期)2016-12-01 13:00:11
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
