Hadoop2.0系統(tǒng)中的資源分配與動態(tài)監(jiān)控實踐
2021-06-16 14:21:52張博
電子技術(shù)與軟件工程 2021年5期
張博
(每銳軟件(上海)有限公司(Marin Software)上海市 200011)
1 引言
信息化社會中的信息爆炸引發(fā)了數(shù)據(jù)量的大幅增長。傳統(tǒng)數(shù)據(jù)處理器已經(jīng)很難快速高效地在經(jīng)濟實用的條件下完成數(shù)據(jù)實時運算。服務(wù)器聯(lián)同協(xié)作成為大規(guī)模數(shù)據(jù)處理的發(fā)展方向。在此背景之下,大數(shù)據(jù)運算平臺應(yīng)運而生,其中以Apache 基金會旗下的Hadoop 項目最為知名。得益于其開源特性,Hadoop 被許多大學(xué)、研究所與商業(yè)公司廣泛采用,在大數(shù)據(jù)領(lǐng)域已經(jīng)成為廣為接受的基準平臺。與此同時,為了方便使用者更簡便快捷的在Hadoop 平臺上實現(xiàn)分布式運算,許多分布式運算框架被研發(fā)與發(fā)行,其中Spark 以其突出的基于內(nèi)存存取的高性能運算,自推出之時,便成為了學(xué)術(shù)界與工業(yè)界重要的關(guān)注與應(yīng)用對象。
然而,大規(guī)模數(shù)據(jù)集所帶來的問題并不止于數(shù)據(jù)量的大幅增長,數(shù)據(jù)結(jié)構(gòu)的復(fù)雜性與差異性導(dǎo)致各個數(shù)據(jù)之間運算量差異亦十分明顯。直接的結(jié)果就是導(dǎo)致了Spark 工作集的多樣化。不同種類的Spark 工作,其生存周期與資源消耗各不相同。當大量多種類Spark工作同時出現(xiàn)在同一個Hadoop 平臺上時,運算資源的不當分配極易導(dǎo)致大量微型工作被阻塞,等待資源,直至超時。當數(shù)據(jù)量極大,例如運算峰值階段的平臺資源緊張時期,各個Spark 工作會因為資源爭搶,導(dǎo)致相互阻塞,數(shù)據(jù)運算因為各個Spark 工作均無法取得足夠資源而停頓,致使整個Hadoop 平臺產(chǎn)生系統(tǒng)死鎖,工作流停頓。
問題產(chǎn)生的根源是Spark 工作多樣性與單一的資源分配規(guī)則之間的矛盾。故而,在Hadoop 平臺搭配Spark 框架支持大規(guī)模數(shù)據(jù)運算的實踐中,Spark 工作集應(yīng)該被系統(tǒng)化分類,采用不同的分配原則,避免數(shù)據(jù)流高峰時刻因資源爭搶而導(dǎo)致的相互阻塞。此外,Hadoop 平臺資源高利用率階段出現(xiàn)性能下降是正常的反應(yīng),與工作流完全阻塞相比,兩者在短時間內(nèi)會呈現(xiàn)相同現(xiàn)象,而長時間的人工觀測在此情境下并不經(jīng)濟可取。因此,固定的監(jiān)控規(guī)則需要進行動態(tài)化改良,使其可以根據(jù)平臺負載量與工作流阻塞的特定現(xiàn)象自動調(diào)整監(jiān)控閾值,從而大幅降低監(jiān)控系統(tǒng)的誤報率,盡力削減非必要的運維成本。在大數(shù)據(jù)平臺運算資源的合理分配與動態(tài)監(jiān)控系統(tǒng)的配合之下,大數(shù)據(jù)平臺可以更加穩(wěn)定、健壯、高效的承受大規(guī)模多樣化Spark 工作流帶來的系統(tǒng)壓力。
本文后續(xù)篇章將主要分為幾個部分:Hadoop 平臺與Spark 框架的架構(gòu)介紹,工作流阻塞問題的生成機理,資源分配規(guī)則與動態(tài)監(jiān)控,與最終的經(jīng)驗總結(jié)。
2 系統(tǒng)架構(gòu)介紹
本章節(jié)將由兩個部分組成:
(1)Hadoop2.0/YARN 平臺與相關(guān)系統(tǒng)的架構(gòu)介紹;
(2)Spark 框架與各Spark 工作集種類的介紹。

圖1:Hadoop 2.0 架構(gòu)
作為被廣泛應(yīng)用的大數(shù)據(jù)平臺與分布式框架,Hadoop 與Spark其本身內(nèi)部的架構(gòu)缺陷并不會對使用者造成嚴重影響。然而當多套系統(tǒng)與框架需要協(xié)同工作、合并運行時,兩者結(jié)構(gòu)上的不同便會在極端條件下產(chǎn)生嚴重的負面影響。對于Hadoop 平臺與Spark 工作流內(nèi)部架構(gòu)與種類的理解將會成為重要的知識背景,在其幫助下,讀者會更加容易和有條理地理解這種協(xié)作系統(tǒng)下問題的產(chǎn)生根源。
2.1 Hadoop2.0/YARN平臺與相關(guān)系統(tǒng)的架構(gòu)介紹
自2013年推出Hadoop2.0 以來,Hadoop 平臺已經(jīng)擺脫了MapReduce 框架的束縛,從單一的HDFS+MapReduce 模式,變得更為開放與多元化。其中最大的改變,就是將工作調(diào)度元件從MapReduce 框架中分離出來,成為了獨立的Hadoop 構(gòu)件,被命名為YARN。基礎(chǔ)的Hadoop 架構(gòu)從此變成了三級結(jié)構(gòu)(如圖1 所示)。本段落將著重介紹工作調(diào)度與資源監(jiān)控構(gòu)件YARN 的內(nèi)部結(jié)構(gòu)與單/多租戶條件下的資源使用規(guī)則。
2.1.1 YARN 的系統(tǒng)結(jié)構(gòu)
作為Hadoop2.0 的核心構(gòu)件之一,YARN 的主要目的是實現(xiàn)跨服務(wù)器平臺的整體資源監(jiān)控與分布其上的工作調(diào)度,其監(jiān)控管理的主要資源類型是內(nèi)存。YARN 采取了經(jīng)典的主從式(Master-Slave)分布式結(jié)構(gòu)。這種結(jié)構(gòu)實現(xiàn)方法簡單明了,架構(gòu)清晰,算法簡明扼要。缺點亦十分明顯,主控節(jié)點的單點故障容易導(dǎo)致整個平臺癱瘓。然而,隨著多個版本的更新,Hadoop2.0 平臺已經(jīng)可以通過待機節(jié)點切換的高可用模式來規(guī)避單點故障,從而被業(yè)界所接受并將其放心地用于生產(chǎn)環(huán)境。
(1)從系統(tǒng)層級來看, 它由一個平臺級監(jiān)控中心ResourceManager(RM)和各個服務(wù)器各自獨有的托管代理模塊NodeManager(NM)構(gòu)成。通過這樣的架構(gòu),YARN 可以全面掌控整個平臺內(nèi)各個服務(wù)器的健康與資源消耗情況,并為工作調(diào)度提供了充足的信息支持。YARN 將整個平臺的資源視為一個整體,再根據(jù)客戶請求與配置,將資源切割為一個個獨立的資源塊分配給其進行數(shù)據(jù)處理。
(2)從客戶請求工作層級來看,每一個工作請求,都實際上由一組資源塊構(gòu)成。每個資源塊各包含(有且只有)一個模塊。在眾多模塊中,有一個為主控模塊(ApplicationMaster:AM),其余都是受其監(jiān)控管理的工作模塊(YarnChild:YC)。在客戶請求工作期間,這些資源塊統(tǒng)一由AM 監(jiān)控管理,不再受系統(tǒng)約束,直至請求完成,將它們歸還系統(tǒng)。
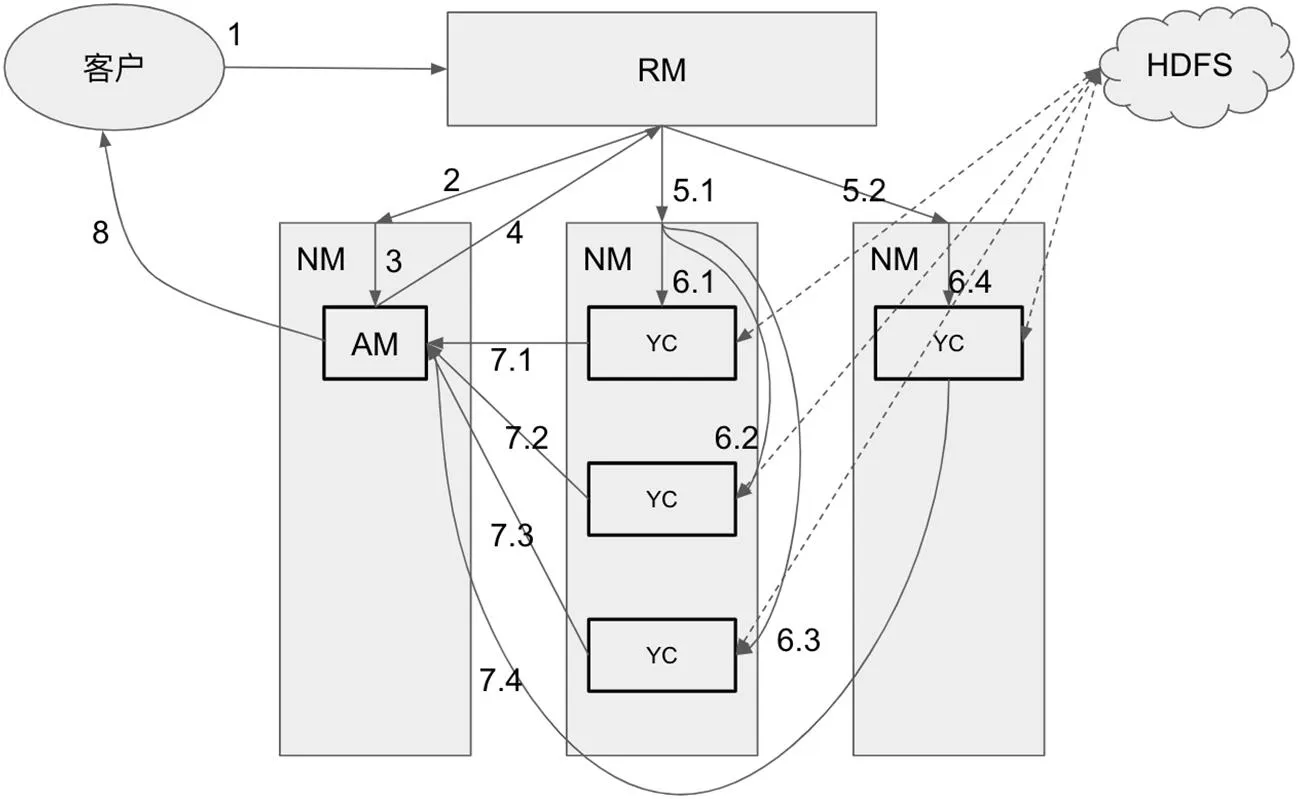
圖2:YARN 雙層分布式系統(tǒng)與客戶請求的生命周期
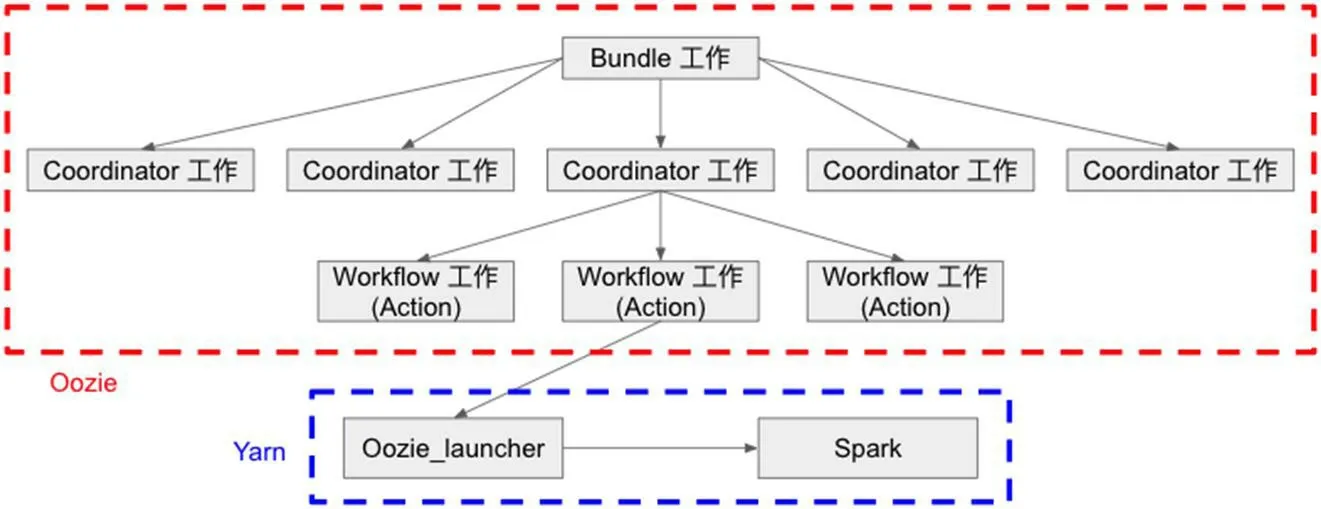
圖3:Oozie 工作層級與YARN 的邏輯關(guān)系
綜上所述,YARN 的內(nèi)部結(jié)構(gòu)其實是一個雙層主從式分布式系統(tǒng),其包含了系統(tǒng)級(RM+NM)與依賴其上的客戶請求工作級(AM+YC)兩部分,如圖2 所示。本文主旨所要討論的問題便與客戶請求工作層級密切相關(guān)。
2.1.2 YARN 中單/多租戶條件下的資源使用規(guī)則
YARN 中的資源使用規(guī)則主要由客戶請求中各資源塊的生命周期,既客戶請求的工作流程,所決定。其工作流程可以分為8 個階段(圖2,序號標示):
(1)客戶向RM 提交請求;
(2)RM 尋找空閑的NM;
(3)NM 在RM 的要求下,為客戶請求創(chuàng)建AM;
(4)基于對客戶請求的分析,AM 聯(lián)系RM,以取得用于數(shù)據(jù)處理的運算資源;
(5)依照AM 提出的要求,RM 尋找合適的NM;
(6)NM 根據(jù)RM 的要求,創(chuàng)建多個YC 以滿足AM 的需求;
(7)YC 完成數(shù)據(jù)處理,并將各自的結(jié)果返回給AM;
(8)AM 對收集到的分散結(jié)果進行總結(jié)合并,然后將最終結(jié)果返回客戶。
由此工作流程,YARN 中的資源使用規(guī)則可以被總結(jié)為以下幾點:
(1)被單租客客戶請求消耗的資源Rrequest,可分為RAM和RYC,其關(guān)系如公式1 所示(n 表示YC 的數(shù)量)。

(2)在多租戶多請求并行狀態(tài)下,YARN 集群的資源RYARN分配如公式2 所示,其中Ridle表示空閑資源,m 表示客戶請求的數(shù)量,n 表示YC 工作模塊的數(shù)量。
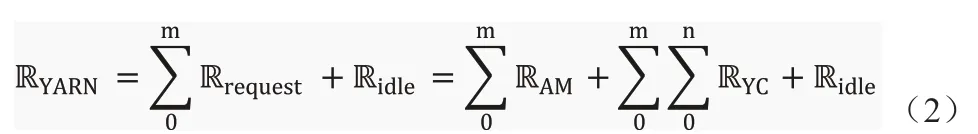
(3)每一個客戶請求,有且只有一個AM,而且其生命周期貫穿整個運算過程。
(4)YC才是數(shù)據(jù)處理的主要模塊,其數(shù)量n由AM的需求決定,生命周期亦不固定,只取決于各自的數(shù)據(jù)處理工作是否完成。
2.1.3 Oozie 的介紹與應(yīng)用
Oozie 是Hadoop 2.0 大數(shù)據(jù)平臺生態(tài)環(huán)境中的一個附屬構(gòu)件,同屬Apache 基金會旗下。其主旨是幫助使用者實現(xiàn)大規(guī)模Hadoop工作流的順序調(diào)度。通過應(yīng)用有向無環(huán)圖(DAG)算法,Oozie可以實現(xiàn)Hadoop 工作流中復(fù)雜邏輯關(guān)系的編排。在Oozie 中,工作流分為三個層級:Bundle 工作級,Coordinator 工作級,和Workflow 工作級(如圖3 所示)。其中,只有workflow 工作級和YARN 有交互關(guān)系,Bundle 和Coordinator 兩個級別都只是一個邏輯層級存在于Oozie 中,既Bundle 工作和Coordinator 工作最終都會落實到子Workflow 工作中,并由其最后在YARN 中實現(xiàn)。
在使用Oozie 編排Spark 工作流時,Workflow 工作會先在YARN 中啟動一個MapReduce 工作,其被命名為Oozie_launcher。Oozie_launcher 是相關(guān)Spark 工作在YARN 中的母進程,它將依據(jù)Oozie 中的設(shè)定與配置實時監(jiān)控Spark 工作的進度并保證其始終遵循Oozie 的邏輯順序運行;在Spark 工作因意外中止時,亦由Oozie_launcher 負責(zé)其錯誤信息的收集與工作的重啟。
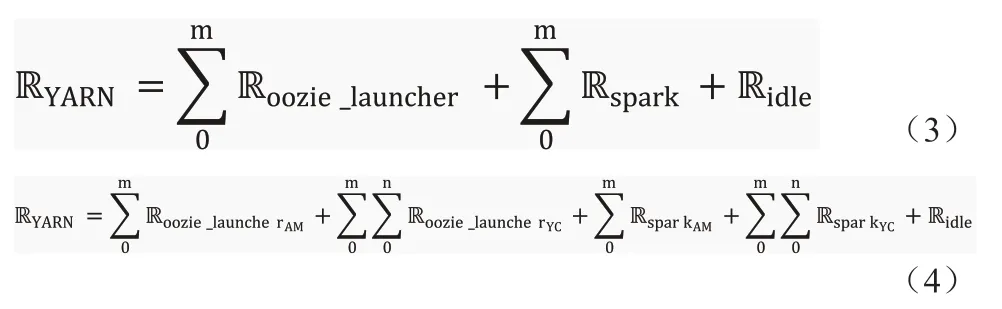
得益于Oozie 的協(xié)作,使用者可以批量管理并行工作,并實現(xiàn)工作流間復(fù)雜的邏輯運行關(guān)系。然而,這種架構(gòu)的劣勢也很明顯。除了Spark 工作流外,Oozie 會為每個Spark 工作都另外創(chuàng)建一個MapReduce 工作,這就使工作流在數(shù)量上翻升了一倍,其資源使用分布如公式3 與公式4 所示。在處理大型數(shù)據(jù)集的工作流中,既∑0mRspark遠遠大于∑0mRoozie_launcher時,這樣的負面影響并不明顯;但在中小微型數(shù)據(jù)集工作流中時),非工作模塊的資源占比r(公式(5)所示)會大幅上升,當Hadoop 平臺遇到足夠大規(guī)模的工作流負載時,平臺的運算與資源壓力將會變得更加巨大,為系統(tǒng)死鎖埋下隱患。

2.2 Spark框架與各Spark工作集種類的介紹
由圖1 可知,Hadoop2.0 不僅支持 MapReduce,Spark 也成為可用框架之一。在對于運算性能有要求的情境下,Spark 成為了更受歡迎的選項而被廣泛應(yīng)用在測試與生產(chǎn)環(huán)境中。Spark 框架在結(jié)構(gòu)上完全遵守YARN 的客戶請求工作層級架構(gòu),采用主從分布式結(jié)構(gòu)。一個運行的Spark 工作由一個主控模塊SparkAM和一組受其監(jiān)控的工作模塊SparkYC組成,其資源消耗亦符合公式1 所示。
Spark 工作的原生種類大體可分為兩種:流式數(shù)據(jù)作業(yè)模式與存儲式數(shù)據(jù)作業(yè)模式
(1)流式數(shù)據(jù)作業(yè)模式:此種模式下的Spark 工作是一種長期運行的微服務(wù)類工作,它們長期運行于Hadoop 集群上,實時于內(nèi)存中處理網(wǎng)絡(luò)上傳輸來的流式數(shù)據(jù),并將最終結(jié)果存于HDFS 以備后用或?qū)崟r反饋給客戶。
(2)存儲式數(shù)據(jù)作業(yè)模式:此類Spark 工作的處理對象并非網(wǎng)絡(luò)實時傳輸?shù)牧魇綌?shù)據(jù),而是HDFS 中的預(yù)存數(shù)據(jù)。這類工作的工作原理與MapReduce 類似,但得益于純內(nèi)存間數(shù)據(jù)運算與傳輸,相較于MapReduce 工作中Map 與Reduce 任務(wù)之間shuffle 階段的落磁盤操作,其性能更為強大。其早期版本與Hadoop1.0 系統(tǒng)的性能對比中,就有近100 倍[1]的性能優(yōu)勢。
Spark 框架的兩種工作模式搭配上Oozie 的編排服務(wù),便可以衍生出了多種工作種類。在互聯(lián)網(wǎng)企業(yè)中,使用較多的工作種類主要包含以下四種:
(1)流式數(shù)據(jù)工作:此類工作主要便是針對網(wǎng)絡(luò)中傳輸?shù)牧魇綌?shù)據(jù),是典型的資源密集型工作種類。其特點為,長時間運行,資源消耗量大且穩(wěn)定,不會輕易釋放占有的運算資源。
(2)微型存儲式數(shù)據(jù)工作:微型存儲式數(shù)據(jù)工作大多是基于事件而誘發(fā)的微小型工作。單個工作資源用量小,運行時間短,相較于大數(shù)據(jù)平臺,幾乎可以忽略不計。但此類工作往往成群出現(xiàn),且數(shù)量極大,非常容易在Hadoop 平臺中造成短時間內(nèi)負載高峰。然而,在平臺負載出現(xiàn)擁堵時,此類工作群的出現(xiàn),會大幅加劇資源的爭搶力度。平臺擁堵大都由工作量的提升而引起,此時工作群的數(shù)量也大概率會出現(xiàn)提升,資源使用總量相較平時也會增加,可用資源在現(xiàn)有運行工作間的爭搶力度,既平臺擁堵程度,會出現(xiàn)驟增。同時,由于各個工作均無法獲得足夠的運算資源,導(dǎo)致運行時間加長,使得平臺的擁堵時段亦被延長。此外,由于其巨大的工作數(shù)量,一旦出現(xiàn)此情況,平臺的等待工作數(shù)量與等待時間,都會大幅增長。
(3)編排預(yù)設(shè)工作:此類工作本身也屬于存儲式數(shù)據(jù)工作,其資源使用量一般小于流式數(shù)據(jù)工作,但遠高于微型工作。與前兩者的最大區(qū)別在于,在Oozie 的編排服務(wù)輔助下,它可以根據(jù)用戶的需求,預(yù)設(shè)工作時段。既不需要長期運行于平臺上占用資源;也并非完全基于事件,不可預(yù)控;而是將一個預(yù)設(shè)時間段內(nèi)的請求積累起來,定時啟動一個工作將其批次處理。而其缺點相較于流式數(shù)據(jù)工作也十分明顯,客戶的請求不會被馬上處理,結(jié)果并非實時反饋。此外,當一個時間段內(nèi)工作量積累過多,無法按時完成時,會造成工作積壓延后,延遲后續(xù)時段工作的運行。
(4)資源池工作:此類工作與編排預(yù)設(shè)工作類似。其區(qū)別在于,編排預(yù)設(shè)工作直接處理數(shù)據(jù)或是客戶請求;而資源池工作會根據(jù)時段內(nèi)積累的工作量,觸發(fā)一系列子工作,并將工作切割分配給它們,所以資源池工作并非只有一個工作被定期重啟,而是一組工作群。其優(yōu)點十分明顯,既工作子集的規(guī)模會隨時段內(nèi)工作量的變化而變化;但其運算結(jié)果亦并非實時數(shù)據(jù),且并行子工作群使得實現(xiàn)難度大幅上升。
本章節(jié)就Hadoop2.0 系統(tǒng)的架構(gòu)與Spark 框架中的工作種類進行了解釋說明。下一章節(jié)會就系統(tǒng)資源的不當分配,在平臺資源緊張時期,大概率造成系統(tǒng)死鎖這一問題的產(chǎn)生機理進行分析與說明。
3 系統(tǒng)死鎖的原理分析
本章節(jié)將會對多樣化Spark 工作集在Hadoop2.0 平臺上,于平臺高負載資源緊張時,極易出現(xiàn)的兩種系統(tǒng)死鎖問題及其產(chǎn)生機理進行系統(tǒng)地分析說明。這兩種系統(tǒng)死鎖分別為:
(1)Oozie/YARN 死鎖;
(2)AM/YC 死鎖。
3.1 Oozie/YARN死鎖
根據(jù)2.1.3 章節(jié)的介紹可知,Oozie 會為每一個運行于Hadoop2.0 平臺上的Spark 工作創(chuàng)建一個監(jiān)控程序Oozie_launcher。Oozie_launcher 作為Oozie 啟動的監(jiān)控程序,Spark 工作其本質(zhì)是由Oozie_launcher 啟動的子工作。這其中有幾個特征非常重要:
(1)Oozie_launcher 必定先于Spark 工作被啟動;
(2)Oozie_launcher 啟動后,才會與YARN 商榷以獲取新資源,用以啟動Spark 工作。倘若此時平臺空閑資源不足,Oozie_launcher 無法獲取足夠資源,則Spark 工作無法被啟動。此時,Oozie_launcher 會一直與YARN 保持通信,等待分配資源;
(3)Oozie_launcher 會一直保持運行狀態(tài),并在整個Spark 工作的生命周期期間對其進行持續(xù)的監(jiān)控。其只有確保Spark 工作結(jié)束后,才會結(jié)束,并釋放被自己占用的資源。
由公式(3)已知,在Oozie 參與編排的Spark 工作流于Hadoop2.0 平臺上運行時,其系統(tǒng)總資源RYARN是由Oozie_launcher占用的總資源∑0mRoozie_launcher,Spark 工作群占用的總資源∑0mRspark,與系統(tǒng)空閑資源Ridle三個部分構(gòu)成。當平臺遇到一個巨大的負載高峰時,Oozie 會于極短時間內(nèi)啟動大量Oozie_launcher,占用大量系統(tǒng)資源。當Ridle小于Rspark時,公式(3)可演化為公式(6)。

當公式6 所描述的現(xiàn)象在Hadoop2.0 平臺中出現(xiàn)時,根據(jù)之前介紹的特征2 可知,Oozie_launcher 會一直保持運行狀態(tài),等待其他工作結(jié)束并釋放資源,而后平臺為其分配空閑資源以啟動相關(guān)的Spark 工作。然而由特征3 亦可知,任何Oozie_launcher 都不會在相關(guān)Spark 工作結(jié)束前,釋放資源。于是,在此情況下,Oozie/YARN 死鎖生成:所有Oozie_launcher 都在等待其他Oozie_launcher 結(jié)束并釋放資源來啟動自有Spark 工作,但任一Oozie_launcher 都不會在自有Spark 工作結(jié)束前釋放資源。
3.2 AM/YC死鎖
除了Oozie/YARN 死鎖這種情況外,還存在另外一種死鎖現(xiàn)象,既AM/YC 死鎖。顧名思義,這是發(fā)生在每個工作的AM 與YC 模塊之間因資源爭搶而發(fā)生的死鎖現(xiàn)象。
由公式4 可知,在多租戶條件下工作層級粒度中,平臺總資源RYARN由Oozie_launcher 的AM和YC分別消耗的總資源以及Spark 工作的AM 和YC 分別消耗的總資源外加空閑資源Ridle,五個部分構(gòu)成。其中,由公式(5)可知,Oozie_launcher 工 作與Spark 工作的AM 部分都不會涉及到真實的數(shù)據(jù)處理,而只負責(zé)相關(guān)工作系統(tǒng)級與工作內(nèi)的監(jiān)控與調(diào)度;只有Spark 工作的YC 模塊會在Hadoop2.0 平臺上并行地處理客戶的實際請求。
由圖2 的工作啟動流程中可知,每個工作的AM 模塊都是第一個被啟動的,而后由AM 來啟動、監(jiān)控YC 模塊,分配作業(yè),并在YC 模塊結(jié)束后收集整合結(jié)果,既AM 模塊的生命周期會覆蓋整個工作流程(所有YC 模塊的生命周期)。當平臺遇到一個巨大的負載高峰時,在所有Oozie_launcher 啟動后,部分Spark 工作的AM模塊也被創(chuàng)建出來,而后,平臺的空閑資源不足以讓任何Spark 工作啟動任一YC 模塊時,AM/YC 死鎖便出現(xiàn)了。Oozie_launcher在等待Spark 工作結(jié)束,Spark 工作的AM 模塊在等待YC 模塊結(jié)束并返回結(jié)果;然而YC 模塊因空閑資源不足,只能等待Oozie_launcher 和Spark 工作的AM 模塊釋放資源,才能夠得以啟動。此情況如公式(7)所示。

其實YARN 中提供了一系列參數(shù)(例如AMFairShare),以控制AM 模塊的資源消耗量,為YC 模塊留出足夠資源余量以避免此種死鎖現(xiàn)象。在種類單一的Hadoop 工作流中,這一機制運行良好,幾乎完美地規(guī)避了AM/YC 死鎖現(xiàn)象。然而如2.2 章節(jié)中所展示,在Oozie 參與的Spark 工作流中,工作種類并不單一,甚至許多種類間的資源消耗與運行模式差異極大。這就使得AMFairShare 這類簡單的資源劃分規(guī)則,無法有效阻止AM/YC 死鎖以及與之類似的現(xiàn)象在復(fù)雜多樣性高負載工作流運行期間頻繁出現(xiàn)。
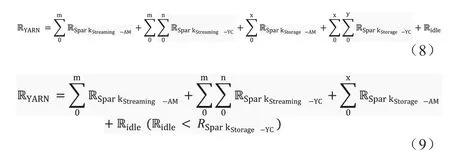
假設(shè)一個Spark 工作流中包含流式數(shù)據(jù)(SparkStreaming)與微型存儲式數(shù)據(jù)(SparkStorage)兩種工作類型(為了簡化案例,此例中的所有Oozie_launcher 工作均被剔除)。那么正常情況下,Hadoop2.0平臺的資源消耗應(yīng)當如公式8 所示。可是通常流式數(shù)據(jù)工作資源消耗量極大,即便在所有AM 模塊的資源消耗總量依然小于AMFairShare 設(shè)定的閾值時,整個平臺的空閑資源可能已經(jīng)無法為微型存儲式數(shù)據(jù)工作的YC 模塊提供足夠資源,如公式(9)所示。由于流式數(shù)據(jù)工作會長期運行并占用資源,這就導(dǎo)致與其伴生的微型存儲式數(shù)據(jù)工作流只要數(shù)量強度達到一定范圍,AM/YC 死鎖現(xiàn)象便會出現(xiàn)。而Oozie_launcher 工作的加入,只會使問題更為嚴峻。
以上所闡述的兩種死鎖問題,都是(1)運行中的工作/模塊等待尚未啟動的工作/模塊返回結(jié)果才可以結(jié)束,(2)而未啟動工作/模塊等待運行中的工作/模塊釋放資源才可以啟動,這兩者相互沖突而造成的系統(tǒng)死鎖。其本質(zhì)上相同,都是整體平臺缺乏對資源的合理科學(xué)分配而引起的混亂資源爭搶行為所導(dǎo)致的結(jié)果。此類問題在平臺空閑或非繁忙時段不會產(chǎn)生任何影響,但在平臺高負載時段,卻極有可能導(dǎo)致整個平臺系統(tǒng)死鎖,運算服務(wù)中止。此外,因為系統(tǒng)死鎖的產(chǎn)生原因并非Hadoop 平臺構(gòu)件問題導(dǎo)致,也非Spark 框架內(nèi)部缺陷引起,這就使得系統(tǒng)死鎖發(fā)生時,所有系統(tǒng)部件與工作日志都顯示正常,與平臺實際工作狀態(tài)不符。
以下兩個章節(jié)將重點講解用以解決此問題的按隊列分配資源原理,以及依托第三方監(jiān)控軟件Nagios 及其腳本插件所實現(xiàn)的動態(tài)監(jiān)控。經(jīng)長時間應(yīng)用得以證明,正確有效的資源管理可以大幅降低系統(tǒng)死鎖的發(fā)生概率。即便在系統(tǒng)死鎖發(fā)生初期,得益于對YARN資源隊列的動態(tài)監(jiān)控,系統(tǒng)本身也可以正確有效地預(yù)警此類問題。
4 Hadoop2.0/YARN平臺的資源分列分配
由第三章節(jié)的論述可知,Hadoop2.0 大數(shù)據(jù)集平臺在面對多樣性大規(guī)模Spark 工作流負載時,極易產(chǎn)生系統(tǒng)死鎖。而產(chǎn)生的核心本質(zhì)就是平臺運算資源在各種Spark 工作間的不合理分配,導(dǎo)致資源爭搶,進而產(chǎn)生系統(tǒng)死鎖。本文中所指出的資源不合理分配行為包含兩點:
(1)所有種類的Spark 工作被推送入同一運行隊列,并未按照特定規(guī)則分類管理;
(2)在可用資源劃分上也只是簡單劃分為兩部分,并不能有效保證在各種情況下運算資源對特定工作/模塊的可用性。
Spark 工作流的隊列分類規(guī)則主要按照其工作種類劃分制定,但是平臺運算資源在各個工作流分列的分配原則卻必須依照其工作性質(zhì)與重要程度決定。
4.1 Spark各類型工作重要程度分析
此小節(jié)將主要依據(jù)各類Spark 工作的實時性與工作量來分析其重要程度并排序。
(1)最重要的工作類型便是流式數(shù)據(jù)工作(SparkStreaming)。此類工作資源消耗量極大且長久,主要因為它們需要實時處理網(wǎng)絡(luò)中傳輸?shù)牧魇綌?shù)據(jù),并在服務(wù)質(zhì)量限定的范圍內(nèi)盡快給出結(jié)果。此類工作大多可被視為長效運行于Hadoop 平臺上的微服務(wù),為內(nèi)部其他構(gòu)件甚至外部客戶提供穩(wěn)定高效的運算服務(wù)。在此情況下,YARN 需要優(yōu)先滿足此類工作的資源需求。
(2)編排預(yù)設(shè)工作(SparkOrchestration)與資源池工作(SparkThread-pool)的重要程度僅次于流式數(shù)據(jù)工作。這兩類工作的本質(zhì),都是將預(yù)設(shè)時間段內(nèi)的工作量積累起來,于事先設(shè)定好的時間節(jié)點啟動一個大型或一組微型工作進行集體處理,所以實時性遜于流式數(shù)據(jù)工作,甚至弱于微型存儲式數(shù)據(jù)工作。然而,由于此二類工作的負載積累模式,每次工作啟動時平臺都已經(jīng)堆積了數(shù)量相當可觀的待處理請求或數(shù)據(jù)。而且鑒于盡量降低平臺資源爭搶,提高資源利用率的考量,預(yù)設(shè)時段的設(shè)定往往會在安全閾值范圍內(nèi)盡可能貼近服務(wù)質(zhì)量下限。這些特性就導(dǎo)致此類工作啟動時,YARN 必須盡快安排其開始運行,并在不影響高優(yōu)先級工作服務(wù)質(zhì)量的前提下,盡量滿足其資源需求。
(3)微型存儲式數(shù)據(jù)工作(SparkStorage),此類工作本質(zhì)上也是實時運算。然而,由于其資源需求量通常極小且運行時間往往很短,在數(shù)量龐大的情況下也可以實現(xiàn)快速迭代。除極端情況下,純粹此類工作組成的高負載峰值并不會發(fā)生擁堵。故將此類工作置于獨立工作隊列內(nèi)并保證其擁有少量的固定資源以使用,其造成系統(tǒng)死鎖的概率幾乎為零。因此,與其他種類的Spark 工作相比,此類工作的重要性最低。
綜上所述,四大類Spark 工作的重要性I 排序如下所示:

4.2 Hadoop2.0/YARN中的資源隊列分配規(guī)則
大規(guī)模多種類混合Spark 工作流在單一資源隊列中很容易于高負載資源緊張時期遭遇系統(tǒng)死鎖威脅。因此,此類復(fù)雜工作流在Hadoop2.0 平臺上運行時,需要被拆開剝離,不同種類的工作分流至適當隊列中去以避免潛在威脅。同時,在Hadoop2.0/YARN 中,提出了資源彈性[2]的概念。一個隊列的資源被分為穩(wěn)定資源(Steady Fair Share)與瞬時資源(Instantaneous Fair Share)兩類。這兩類資源并無實際聯(lián)系。其中穩(wěn)定資源是一個隊列獨有且不容侵占的,是經(jīng)由YARN 配置的固定值。瞬時資源則會根據(jù)整個平臺的資源總量與隊列的數(shù)量和權(quán)重而實時產(chǎn)生相應(yīng)變化,隊列數(shù)量越多,權(quán)重越大,所得瞬時資源便會越多,但是瞬時資源在特定條件下可以被其他隊列占用,既當某隊列資源使用率接近滿負荷時,如果其他隊列的瞬時資源多余穩(wěn)定資源且相對空閑,那么此隊列可以超負荷占用其他隊列的瞬時資源。然而,當穩(wěn)定資源大于瞬時資源時,此隊列的資源彈性消失,既任何情況下,此隊列的資源不可被其他隊列占用。
根據(jù)上一章節(jié)的分析,Spark 工作依據(jù)種類劃分的重要程度有三個等級,故而隊列規(guī)則的制定與其相對應(yīng),亦有三個種類:
4.2.1 擁有足量資源的專有隊列
此類隊列專供流式數(shù)據(jù)工作使用,并根據(jù)用戶的配置為其預(yù)留足夠的運算資源。當YARN 發(fā)現(xiàn)流式數(shù)據(jù)工作被提交后,此類工作的所有組件都會被調(diào)度在此隊列之內(nèi)。此隊列所擁有的穩(wěn)定資源總量應(yīng)與所有流式數(shù)據(jù)工作的資源需求總量相當。這種隊列設(shè)置有兩點優(yōu)勢:
(1)在任何情況下,都能優(yōu)先保證流式數(shù)據(jù)工作的資源需求以滿足其服務(wù)質(zhì)量的要求;
(2)這種資源強制劃分會使此類隊列的穩(wěn)定資源大于瞬時資源,有效降低了其他隊列在資源規(guī)劃調(diào)控階段對于此隊列彈性資源的依賴。
4.2.2 專有隊列
此類隊列主要應(yīng)對編排預(yù)設(shè)工作和資源池工作。專有隊列的優(yōu)勢在于,獨立的隊列就會有獨立的穩(wěn)定資源被預(yù)留下來。當工作被觸發(fā)時,這些穩(wěn)定資源可以確保Oozie_launcher 與Spark 工作的正常啟動。在平臺資源空閑時,此類隊列中的工作可以通過Hadoop2.0 的資源彈性機制通過獲取其他同類隊列的瞬時資源以滿足自身需求;而當平臺出現(xiàn)高負載資源緊張狀況時,此類隊列中工作的啟動行為亦不會受到負面影響,同時盡可能維持工作的運行而不會出現(xiàn)長時間吊起等待的阻塞現(xiàn)象。
4.2.3 共享隊列
此類隊列專供微型存儲式數(shù)據(jù)工作。根據(jù)微型存儲式數(shù)據(jù)工作的特點,此類隊列會包含兩個子隊列,分別為Oozie_launcher 專有隊列與Spark 專用隊列。顧名思義,在此類工作流到來時,其Oozie_launcher 工作與附屬的Spark 工作會運行在各自的專有隊列中,從而有效防止了這兩類工作之間的資源爭搶。與此同時,對于每種工作單獨而言,又被轉(zhuǎn)化為了單種類單隊列問題,Hadoop 系統(tǒng)默認的資源分割機制可以完美避免AM/YC 死鎖問題。
通過如上的隊列資源管理規(guī)則,當Oozie 參與編排的復(fù)雜大規(guī)模Spark 工作流運行于Hadoop2.0 平臺上時,系統(tǒng)潛在的死鎖問題被專有隊列與種類篩選分離機制轉(zhuǎn)化為一組簡單的單種類單隊列問題,從而得以被Hadoop 系統(tǒng)的原生安全機制覆蓋。
5 基于Nagios及其腳本的動態(tài)監(jiān)控
作為一個開發(fā)社區(qū)極為活躍的開源監(jiān)控軟件,Nagios 為監(jiān)控腳本提供了充足的定制化空間。相對于其他固定規(guī)則的監(jiān)控軟件(例如Cloudera[3]),擁有動態(tài)閾值的自定義監(jiān)控腳本在Nagios 上更容易實現(xiàn)。因為Hadoop 平臺的資源被劃分為不同的子隊列,且工作流亦被分配至相應(yīng)隊列,這個動態(tài)監(jiān)控腳本將基于子隊列監(jiān)控,而非整個Hadoop 平臺的總隊列。
動態(tài)監(jiān)控腳本包含兩個部分:
5.1 隊列阻塞預(yù)警
監(jiān)控系統(tǒng)死鎖需要拉取大量平臺數(shù)據(jù),包含每個隊列中等待工作數(shù)量,此隊列支持的每個運行工作中AM 與YC 模塊的運行狀態(tài)與數(shù)量等。這會對Hadoop 平臺造成額外的工作負擔(dān),進而影響平臺性能,而且頻繁的監(jiān)控數(shù)據(jù)篩選累加也會對Nagios 本身提出很高的性能要求。故而應(yīng)盡量降低系統(tǒng)死鎖的檢測頻率。根據(jù)章節(jié)三的介紹可知,系統(tǒng)死鎖只會于平臺資源緊張時發(fā)生。因此,隊列阻塞預(yù)警被引入動態(tài)監(jiān)控腳本,既當隊列于資源緊張時期發(fā)生阻塞時,Nagios 才會對當前隊列進行死鎖檢測;否則跳過。根據(jù)當前隊列中等待的工作數(shù)量Ncurrent,Nagios 將實時地計算出一個當前預(yù)警閾值Tcurrent,其與基準閾值Tbaseline的關(guān)系由Ncurrent與基準等待數(shù)量Nbaseline決定,如公式(10)所示。當任一等待工作的滯留時間長于Tcurrent時,Nagios 便會向運維人員預(yù)警隊列阻塞。而Tcurrent的意義在于,在高負載時期,使用者可以容忍有限度的工作超時現(xiàn)象。

5.2 基于隊列的死鎖預(yù)警
當確認隊列出現(xiàn)阻塞現(xiàn)象后,Nagios 會開始對當前隊列進行系統(tǒng)死鎖檢測。這里使用的預(yù)警閾值為Tbaseline,既在符合死鎖特征的條件下,只要有超時等待的工作/模塊,即示警。檢測規(guī)則步驟如下:
(1)Oozie/YARN 死鎖檢測:
1.是否有Spark 工作處于等待狀態(tài);
2.若是,是否有Spark 工作處于工作狀態(tài);
3.若否,是否存在任一等待狀態(tài)的Spark 工作,其滯留時間長于Tbaseline;
4.若是,隊列可能出現(xiàn)Oozie/YARN 死鎖,Nagios 發(fā)出預(yù)警。
(2)AM/YC 死鎖
1.是否每個運行工作都只有一個模塊處于運行狀態(tài)(只有AM運行);
2.若是,是否存在任一等待狀態(tài)的模塊,其滯留時間長于Tbaseline;
3.若是,隊列可能出現(xiàn)AM/YC 死鎖,Nagios 發(fā)出預(yù)警。
基于如上腳本,Nagios 可以持續(xù)對Hadoop 平臺每個隊列的阻塞狀態(tài)與系統(tǒng)死鎖進行持續(xù)監(jiān)控和預(yù)警,并盡可能避免大幅增加平臺系統(tǒng)的運算負擔(dān)。
6 基于Hadoop2.0大數(shù)據(jù)平臺的MarinOne系統(tǒng)實踐
MarinOne 是Marin Software(每銳軟件)公司推出的新一代數(shù)碼廣告平臺系統(tǒng),其基于Hadoop2.0 大數(shù)據(jù)平臺、微服務(wù)框架與虛擬化技術(shù)為客戶提供更直觀與專業(yè)的數(shù)據(jù)展示與廣告建議。在公司內(nèi)部測試平臺QA2 上經(jīng)過檢驗,證明此動態(tài)監(jiān)控與資源分列配置不會對系統(tǒng)造成任何負面影響后,生產(chǎn)環(huán)境的Hadoop 平臺得以應(yīng)用如上更改。此Hadoop平臺的YARN部分由200臺大型服務(wù)器構(gòu)成,總共擁有37.37 TB 的內(nèi)存資源,長期保持大約130 個工作同時運行,最多時會有超過230 個工作并行運行,其最高內(nèi)存資源利用率超過91%。
在應(yīng)用本文介紹的內(nèi)存資源隊列分配規(guī)則與動態(tài)監(jiān)控之前,平臺一旦出現(xiàn)高負載就會發(fā)生阻塞現(xiàn)象,耗費大量人力與時間成本后可以斷定基本是由系統(tǒng)死鎖引發(fā)。在應(yīng)用這項技術(shù)后,僅2020年一年間,Nagios 成功預(yù)警隊列阻塞143 次,系統(tǒng)死鎖26 次。系統(tǒng)死鎖的發(fā)生概率降低了81.8%,僅剩約18.2%。其他的系統(tǒng)阻塞大都是由于工作流過于巨大而導(dǎo)致等待時間過長所觸發(fā),期間系統(tǒng)并未死鎖,但是阻塞的成功預(yù)警也使人工干預(yù)得以及時介入,從而避免了系統(tǒng)服務(wù)質(zhì)量的下降。
7 相關(guān)工作
作為被廣為接受的大數(shù)據(jù)運算平臺,學(xué)術(shù)界與工業(yè)界已經(jīng)圍繞Hadoop2.0 系統(tǒng)進行了非常多的相關(guān)研究與改良工作。例如AROMA[4]和FMEM[5]都主張在Hadoop 系統(tǒng)之上嵌套一層新的自動化系統(tǒng)以實現(xiàn)平臺資源的合理配置,Gunther[6]更是將遺傳基因算法引入系統(tǒng)監(jiān)控與資源管理中。Filip K?ikava 等與本人也曾于15-16年發(fā)表文章[7-8]展示了基于內(nèi)存監(jiān)控的自適應(yīng)配置優(yōu)化工具。Gil Jae Lee 等也發(fā)表多篇文章[9-10]提出了基于CPU 運算資源的Hadoop系統(tǒng)優(yōu)化建議。Jenn-Wei[11]也提出了新的依據(jù)工作重要性與預(yù)設(shè)截止時間等相關(guān)屬性進行資源分配管理的調(diào)度器。但這些研究的應(yīng)用環(huán)境相對苛刻,穩(wěn)定性與可行性并未得到業(yè)界的深入驗證,并不適合在短時間內(nèi)應(yīng)用于生產(chǎn)環(huán)境。相反,基于Hadoop 已經(jīng)提供的調(diào)配接口與成熟的監(jiān)控軟件,本文所論述的資源配置方法與動態(tài)監(jiān)控腳本擁有可靠的穩(wěn)定性與可行性,這一點也在Marin 的生產(chǎn)平臺上已經(jīng)得以驗證。
8 總結(jié)
本文系統(tǒng)化地介紹了Hadoop2.0 系統(tǒng)中由于復(fù)雜大規(guī)模Spark工作流引發(fā)的系統(tǒng)死鎖與其生成機理。并據(jù)此提出了切實可行的大數(shù)據(jù)平臺資源分配規(guī)則,既依據(jù)Spark 工作種類與重要程度將平臺整體資源劃分為不同類型隊列的分配原則。再輔以基于Nagios 系統(tǒng)的動態(tài)監(jiān)控腳本,運維團隊可以對平臺系統(tǒng)阻塞與死鎖進行實時監(jiān)控及快速準確的反應(yīng)排查。最終使系統(tǒng)的可靠性與基于此大數(shù)據(jù)平臺的服務(wù)質(zhì)量都得到切實保證。相較于其他已有資源管理方式與研究,本文介紹的系統(tǒng)資源分配規(guī)則與動態(tài)監(jiān)控實現(xiàn)相對簡單,對應(yīng)用環(huán)境沒有特殊要求,現(xiàn)均已應(yīng)用于Marin Software(每銳軟件)的實際生產(chǎn)環(huán)境(MarinOne)并得到了良好反饋。
猜你喜歡
江蘇安全生產(chǎn)(2023年1期)2023-02-08 05:58:38
工業(yè)設(shè)計(2022年8期)2022-09-09 07:43:20
吉林廣播電視大學(xué)學(xué)報(2021年4期)2022-01-14 02:35:48
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
作文成功之路·小學(xué)版(2020年5期)2020-06-11 12:48:26
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
小天使·一年級語數(shù)英綜合(2018年11期)2018-11-23 09:47:26
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
