一種基于CTPN網絡的文檔圖像標題檢測算法
2021-06-16 14:21:48郝聚濤段靜文陳超陳鴻龍
電子技術與軟件工程 2021年5期
郝聚濤 段靜文 陳超 陳鴻龍
(1.上海電機學院電子信息學院 上海市 201306 2.上海思賢信息技術有限公司 上海市 200233)
隨著互聯網技術的發展創新,辦公也逐漸進入了信息化時代,紙質文檔數字化由于其便于存儲和傳輸已被廣泛應用。但是,大中型的企業由于文檔數量龐大,陷于難以梳理的困境。對大量以圖像或者pdf 格式存儲的文檔,進行管理需要能夠智能化進行文檔的組織和歸流,方便用戶按照類型進行查找,有效提高工作效率。
文檔圖像的版面分析是文檔信息處理系統的重要組成部分,以及復雜文檔OCR(Optical Character Recognition)必不可少的環節,它是實現紙質文檔數字化的重要環節。文檔版面分析是一個將文檔圖像分解成不同區域塊并且進行文本、圖像、表格和數學公式等分類的過程。版面分析在信息檢索、機器翻譯、光學字符識別以及從文檔中提取結構化數據都有著廣泛應用。
版面分析包含三個主要步驟:
(1)檢測感興趣的文檔塊;
(2)提取特征;
(3)對文檔塊進行分類。
傳統的自頂向下、自底向上和混合的塊檢測方法被用于文檔塊的分割。然后,使用基于塊、基于像素或基于連接組件的技術從塊中提取特征。最后引入機器學習算法來分類文檔塊。
近年來,深度學習在文檔布局分類中得到了廣泛的研究。Kang將CNN 引入到使用自定義網絡進行文檔分類的任務中與傳統的基于特征的方法相比,顯著降低了錯誤率。
本文中的標題檢測就是對文檔進行邏輯版面分析的一種特定應用,首先將文檔圖像分割幾何區域,進行文本行識別。然后對文本行進行語義類別劃分,劃分為標題和非標題。對標題文本區域進行OCR 識別,為后續進行文檔自動分類和檢索提供支持。
1 標題識別模型
1.1 模型整體結構
本文提出的文本圖像標題檢測模型主要由三個部分組成,第一部分為文本檢測模塊(Connectionist Text Proposal Network,CTPN),即對輸入的文本圖像(Text images)進行文本塊的檢測,獲取圖像中文本的位置信息;第二個部分是特征設計(Feature design),對得到的文本塊位置信息進行特征設計,轉化為分類器所需要的特征向量;第三個部分是分類器,對文本圖像中的每個文本塊進行分類,判斷該本塊是否屬于標題,最后得到輸入文本圖像的標題概率分布。
1.2 文本行檢測
CTPN(Connectionist Text Proposal Network)認為預測文本的縱向位置(邊框的上下邊界)比橫向位置(邊框的左右邊界)更容易,因此CPTN 的基本想法就是去預測文本的縱向位置,水平方向的位置不做預測。由此提出了一個縱向錨點(vertical anchor)的方法,該方法與Faster RCNN 中的錨點類似,但不同的是,縱向錨點的寬度都是固定的16 個像素大小。而高度則從11 像素到273 像素變化,總共10個錨點。 同時,同一文本線上不同字符可以互相利用上下文,將長短期記憶網絡(Long Short-Term Memory LSTM)引入到了網絡里面,并且和卷積神經網絡無縫對接,發揮LSTM 的記憶作用,根據前后的錨點序列來提取這種相互之間的關系特征,輸出給全連接層,給每個錨點打分,最后用文本行構造法,將錨點連接起來,得到文本行。這兩大亮點使得CTPN 在文本行檢測的精確度方面有了很大的提升。
1.3 特征構建以及符號說明
標題與正文在排版以及字體大小等方面往往存在差別,可以利用這種差異性構建標題識別模型特征向量。只考慮圖像的文本信息,任何一張文本圖像都是由若干個文本塊組成,假設該文本圖像共有n 個文本塊,以第i 個文本塊text_block_i 為例闡述標題識別模型特征向量的構建。該文本塊上邊界離文本圖像上邊界的距離為vti,離文本圖像下邊界的距離為vbi;文本塊左邊界離文本圖像左邊界的距離為hli;文本塊右邊界離文本圖像右邊界的距離為hri;文本塊的高度為fi;第i 文本塊之上和之下分別存在的文本塊數量為m 和k,且m+k+1=n;該文本塊的特征向量為:

表1:文本圖像001_1.jpg 生成的訓練集
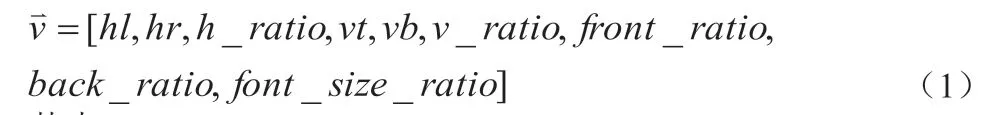
其中hl=hli,hr=hri,h_ratio=hli/hri,vt=vti,vb=vbi,v_ratio=vti/vbi,front_ratio=m/n,back_ratio=k/n,
2 實驗評估
2.1 數據集描述
以文本圖像001_1.jpg 為例(見表1),該圖像存在8 個文本塊,可以生成8 個訓練樣本,其中 用于說明該文本塊是否屬于標題,如果是標題則為1,反之為0,每張圖片生成的訓練樣本數目取決于該圖片文本塊數量。這里選取了300 張文本圖像,生成9647 個樣本,其中正負樣本比例為1:13。考慮到實際情況下,同樣式下不同圖像的文本塊的相對位置會存在一定程度的左右偏移或者上下偏移;利用該特性,通過對每個特征變量引入偏移量 ,其中 ,生成偽樣本,使得正負樣本比例為1:1,得到最終樣本數目為18617,訓練集和測試集比例為7:3。
2.2 模型比較和實施
將樣本數據輸入給模型進行訓練前,需要將其進行歸一化或者標準化預處理,從而消除各特征量綱的影響。本文對訓練數據特征預處理采用python 的sklearn 模塊的StandardScaler 方法。選取sklearn 自帶的7 種主流分類算法,即隨機森林(Random Forest,RF)、支持向量機(Support Vector Machine,SVM)、邏輯回歸(Logistics Regression,LR)、梯度提升決策樹(Gradient Boosting Decision Tree,GBDT)、輕量梯度提升機(Light Gradient Boosting Machine,LGBM)、自適應提升(Adaptive boosting,AdaBoost)、 極 端 梯 度 提 升(Extreme Gradient Boosting,XGBoost),分別作為本文的標題二分類分類模型,分類器參數均采用sklearn 默認值。
如表2 所示,各分類器均具有較優性能,其原因是本文涉及到的文本標題特征較為鮮明,即標題所處位置、大小和非標題文本存在交大差異,使得整個檢測場景變的簡單,而事實上這是一個在文檔中普遍存在的合理的現象。本文最終選取RF 作為文本圖像的標題檢測分類器。
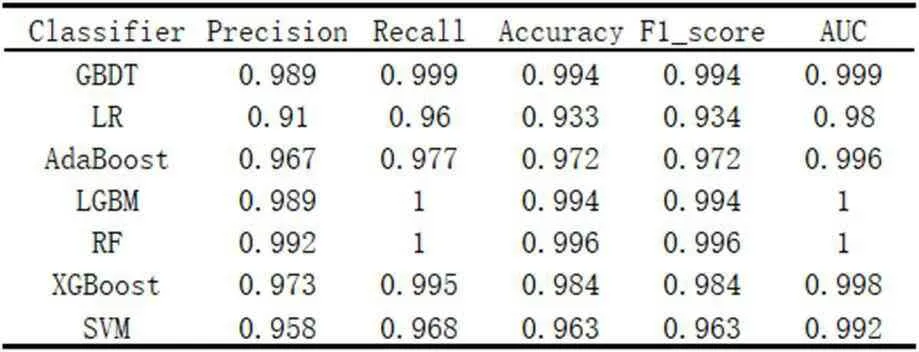
表2:分類器性能
2.3 特征重要性分析
對數據進行StandardScaler 預處理,采用RF 分類器進行訓練,同時對樣本的各個特征進行重要性排序,可知文本塊所在的上下位置信息對該文本塊為標題的貢獻較大,特別的,該文本塊上方存在的文本塊數量與總文本塊數量比率貢獻最大,這個也是合理的,常見文檔中,標題一般出現在第一行或者前幾行。
2.4 效果展示與壞例分析
為了更好說明本文所提出的文本圖像標題檢測方法的有效性,從網絡上隨機下載了1000 份文本圖像,標題檢測準確率~96%,驗證該算法具有強魯棒性。同時,本方法也存在一定局限性,例如對豎直、干擾嚴重的標題檢測失效。
3 總結
本文提出一種基于CTPN 的文本圖像標題檢算方法,首先檢測文本圖像中文本塊,將每個文本塊位置信息轉化為標題檢測模型所需的特征向量,并形成訓練樣本集,利用RF 分類器學習樣本分布,再利用訓練好的RF 分類器參數對未知文本圖像的標題進行檢測。傳統基于規則的文本圖像標題檢測算法存在因為規則覆蓋率有限導致算法泛化能 力差的問題。本文所提出的方法,結合了神經網絡和隨機森林分類器,算法泛化能力強,同時在給定樣本分布下,訓練得到分類器的精準率、召回率、F 值、準確率均接近于1,說明本文提出的標題檢測算法具有較優的性能,可用于一般場景下文本圖像標題檢測。雖然該方法能較好的自動檢測文本圖像的標題,但是當文本標題周圍存在較強或者手寫字與打印字體識別置信度差異,構建新特征,進一步提高標題檢測算法的魯棒性和性能,這都是值得進一步開展研究的。干擾,例如手寫字或者文本標題以垂直樣式出現,該方法準確率下降,因此后續可以考慮引入字符串語義信息。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
小學教學參考(2015年20期)2016-01-15 08:44:38
