云原生網(wǎng)絡的宏觀與微觀技術分析
2021-06-16 14:21:22湯聞達
電子技術與軟件工程 2021年5期
湯聞達
(中匯信息技術(上海)有限公司 上海市 201210)
1 背景
伴隨著容器技術的成熟與微服務理念的普及,業(yè)務彈性和敏捷交付的訴求催生了一系列云原生技術。云原生計算基金會(Cloud Native Computing Foundation, CNCF)對云原生做出了如下的定義:云原生技術有利于各組織在公有云、私有云和混合云等新型動態(tài)環(huán)境中,構(gòu)建和運行可彈性擴展的應用。云原生的代表技術包括容器、服務網(wǎng)格、微服務、不可變基礎設施和聲明式API。結(jié)合標準化自動化運維,云原生技術可幫助企業(yè)很方便地對容器化應用做出頻繁且可預測的變更。
事實上,數(shù)據(jù)中心資源無外乎計算、存儲和網(wǎng)絡。云原生與傳統(tǒng)架構(gòu)在承載業(yè)務應用的區(qū)別主要是在計算、存儲和網(wǎng)絡資源管理和編排調(diào)度方式上的差異,而針對這些差異的理解與消化直接影響了企業(yè)上云業(yè)務應用的運行質(zhì)量以及業(yè)務變更的靈活性。除此以外,對于那些采用本地部署(on-premises)云平臺的用戶,還涉及到數(shù)據(jù)中心基礎設施的建設與維護成本。
1.1 數(shù)據(jù)中心傳統(tǒng)網(wǎng)絡架構(gòu)與云原生的碰撞
宏觀上看,網(wǎng)絡資源作為數(shù)據(jù)傳輸?shù)母咚俟泛图~帶,可以數(shù)據(jù)中心網(wǎng)絡的構(gòu)建也無外乎由路由交換設備、服務器設備等實體硬件構(gòu)成,各類資源的可達性和能力優(yōu)勢完全依賴于數(shù)據(jù)中心的網(wǎng)絡拓撲結(jié)構(gòu)。
傳統(tǒng)數(shù)據(jù)中心主要承載的是南北向的網(wǎng)絡流量(即數(shù)據(jù)中心外到數(shù)據(jù)中心內(nèi)的流量,可以是外部流量到內(nèi)部服務器,也可以是內(nèi)部服務器到外部的流量)。相應的網(wǎng)絡架構(gòu)通常是三層結(jié)構(gòu)。思科(Cisco)稱之為:分級的互連網(wǎng)絡模型(Hierarchical Internetworking Model)。這個模型主要包含了以下三層:接入層(Access Layer)、匯聚層(Aggregation Layer)和核心層(Core Layer)[1]。接入層交換機通常位于數(shù)據(jù)中心機房內(nèi)的機架頂部,所以它們也被常常稱為ToR(Top of Rack)交換機,由于它們直接連接著實際的物理服務器,可以提供網(wǎng)絡接入的能力,所以叫做接入層交換機。匯聚交換機下連接入層交換機,用于提供防火墻策略執(zhí)行等能力。核心交換機一方面為流入整個數(shù)據(jù)中心的數(shù)據(jù)包提供高速轉(zhuǎn)發(fā)能力,另一方面下連多個匯聚層交換機并提供它們之間的連通性。
典型的數(shù)據(jù)中心三層網(wǎng)絡架構(gòu)如圖1 所示。
按OSI(Open System Interconnection)七層參考模型,通常情況下的匯聚交換機是數(shù)據(jù)鏈路層和網(wǎng)絡層的分界點,匯聚交換機以下的是數(shù)據(jù)鏈路層,以上是網(wǎng)絡層。匯聚交換機和接入交換機之間通常為了防止數(shù)據(jù)鏈路層環(huán)路或廣播風暴破壞網(wǎng)絡等問題,運行著生成樹協(xié)議(Spanning Tree Protocol,STP)。STP 使得對于一個VLAN 網(wǎng)絡只有一個匯聚層交換機可用,其他的匯聚層交換機僅在出現(xiàn)故障時才被使用(上圖中紅色虛線表示備份線路),也就是說匯聚層是一個“主備”的高可用模式[2],其余網(wǎng)絡設備的能力沒有被充分利用。通過應用TRILL(Transparent Interconnection of Lots of Links,多鏈路透明互聯(lián))技術,在數(shù)據(jù)鏈路層引入IS-IS(Intermediate System-to-Intermediate System,中間系統(tǒng)到中間系統(tǒng))這樣的可運行于鏈路層的路由協(xié)議,可將數(shù)據(jù)鏈路層的簡單靈活和網(wǎng)絡層的穩(wěn)定可靠相結(jié)合,實現(xiàn)針對已知單播數(shù)據(jù)包轉(zhuǎn)發(fā)的等價多路徑負載分擔,從而規(guī)避應用STP 所產(chǎn)生的帶寬利用率低等問題[3]。
目前已有大量數(shù)據(jù)中心中在使用這種三層網(wǎng)絡架構(gòu),這樣的架構(gòu)可以很方便地支持數(shù)據(jù)中心南北向流量。但是近年來伴隨著互聯(lián)網(wǎng)業(yè)務的迅猛增長和日趨完善的應用微服務改造,數(shù)據(jù)中心虛擬化要求著更高的東西向流量(數(shù)據(jù)中心內(nèi)的服務器之間的流量),甚至跨數(shù)據(jù)中心流量。據(jù)一份來自思科的網(wǎng)絡分析報告描述,預計到2021年末,東西向流量將占數(shù)據(jù)中心總流量72%,遠超南北向流量(15%),數(shù)據(jù)中心間流量(14%)[4]。
需要指出的是,盡管上述傳統(tǒng)三層網(wǎng)絡架構(gòu)也能夠支持東西向流量,但是效率并不高(即便采用TRILL 技術),這主要體現(xiàn)在一旦發(fā)生網(wǎng)絡層的東西向流量傳輸需求,都必須經(jīng)過核心交換機完成轉(zhuǎn)發(fā),這不僅浪費了寶貴的核心交換機資源,多層轉(zhuǎn)發(fā)也增加了傳輸延時。
1.2 云原生數(shù)據(jù)中心網(wǎng)絡架構(gòu)特征
云原生對于數(shù)據(jù)中心網(wǎng)絡的需求,可以分別從基礎設施平臺以及業(yè)務需求兩方面來進行分析。從基礎設施平臺方面來看,整個平臺正在向分布式彈性化的方向發(fā)展,其在承載上層應用有關性能、可擴展性與可靠性方面都有對應的保障要求,并且各個微服務間的通信流量均衡與故障應對(如服務降級、熔斷、限流)等均需交由平臺進行處理。從業(yè)務需求方面來看,傳統(tǒng)單體應用正在向微服務架構(gòu)進行演進,以充分利用平臺的彈性可擴展能力,這種將計算與存儲分離的方式對網(wǎng)絡資源的調(diào)配要求更高。
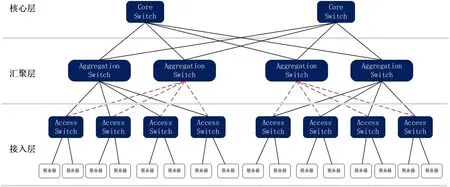
圖1:典型數(shù)據(jù)中心三層網(wǎng)絡架構(gòu)
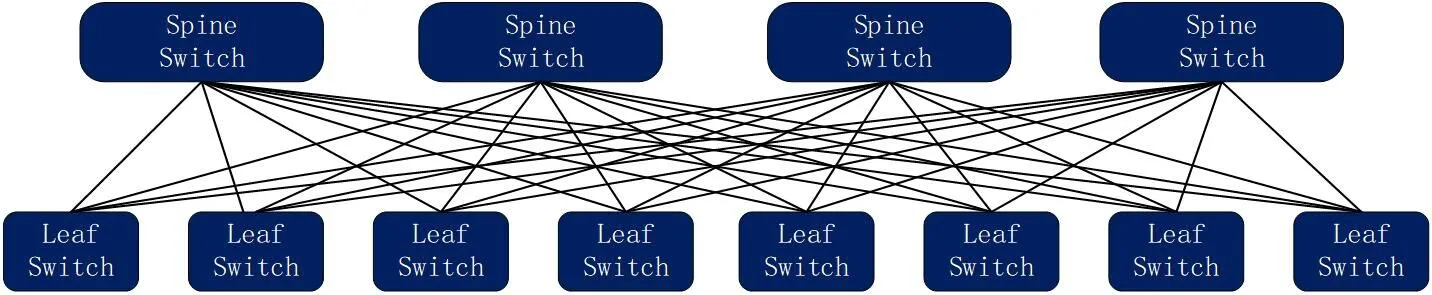
圖2:Spine-Leaf 網(wǎng)絡拓撲
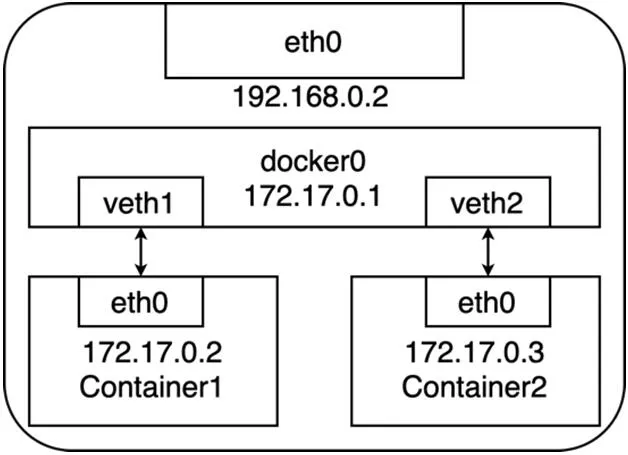
圖3:宿主機docker0 網(wǎng)橋網(wǎng)絡拓撲示意
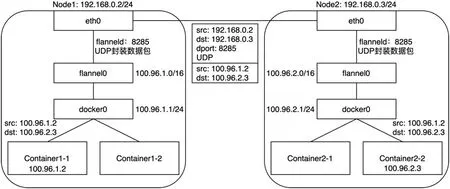
圖4:兩個宿主機上容器基于Flannel UDP 模式的通信過程
從業(yè)界實踐上來看,一種基于Clos 網(wǎng)絡模型的扁平化網(wǎng)絡架構(gòu)Spine-Leaf 可以為數(shù)據(jù)中心提供高帶寬、低延遲、非阻塞的端到端連接。并且,它能夠在性能、高可用等方面為上述需求的滿足提供一定的支撐作用。圖2 是一個典型的兩級Spine-Leaf 網(wǎng)絡拓撲。
在以上的兩級Clos[5]拓撲中,每個低層級的交換機(Leaf)都會連接到每個高層級的交換機(Spine)。與三層網(wǎng)絡架構(gòu)類似,這里Leaf 層由接入交換機組成,用于連接服務器等設備。Spine 層負責將所有的Leaf 連接起來,這里每個Leaf 都會連接到每個Spine。任意一個Spine 發(fā)生故障,都不會影響到整個網(wǎng)絡的正常運轉(zhuǎn),且吞吐性能只會有輕微的下降。與三層網(wǎng)絡架構(gòu)不同的是,Leaf 交換機與Spine 交換機間的網(wǎng)絡流量都是網(wǎng)絡層以上的流量,因此可充分利用到網(wǎng)絡層等價多路徑路由特性,實現(xiàn)網(wǎng)絡鏈路的負載均衡。同時,在任意Leaf-Spine 鏈路發(fā)生故障時,實現(xiàn)快速切換。在上述基礎上,網(wǎng)絡擴容與接入資源的擴容只需對應增加一個Spine 交換機和Leaf 交換機即可,這樣可很方便解決鏈路擁塞問題,且實現(xiàn)了無阻塞的網(wǎng)絡架構(gòu)。
在Spine-Leaf 架構(gòu)中,任意一個服務器到另一個服務器的連接,都會經(jīng)過相同數(shù)量的設備(除非這兩個服務器在同一Leaf 下面)。因為一個數(shù)據(jù)包只需要經(jīng)過一個Spine 和另一個Leaf 就可以到達目的地,這就使得整個網(wǎng)絡中任意的端到端連接延遲是可預測的。因此,當數(shù)據(jù)中心的物理設備間通過Spine-Leaf 網(wǎng)絡架構(gòu)互聯(lián)后,即可較為高效地處理數(shù)據(jù)中心的東西向網(wǎng)絡流量,并同時保證低的、可預測的網(wǎng)絡間延遲,從而為部署于物理機器上的各個應用容器提供靈活、高性能的通信。
2 云原生容器網(wǎng)絡的需求與實現(xiàn)
云原生架構(gòu)以容器和Kubernetes 為核心調(diào)度組件構(gòu)建了一整套微服務生態(tài)系統(tǒng)。愛因斯坦曾經(jīng)說過:“如果沒有界定范疇和一般概念,思考就像在真空中呼吸,是不可能的。”容器技術的大規(guī)模靈活運用同樣離不開底層宿主機間網(wǎng)絡性能的支撐。云原生容器網(wǎng)絡立足于前文描述的數(shù)據(jù)中心網(wǎng)絡架構(gòu),聚焦于微觀的技術實現(xiàn),目的是為泛在的容器提供堅實的網(wǎng)絡通信基礎。
2.1 容器網(wǎng)絡的需求
盡管運行于宿主機上的容器可以直接使用宿主機網(wǎng)絡棧,從而為容器提供良好的網(wǎng)絡性能,但這樣做會不可避免地引入共享網(wǎng)絡資源的問題,比如端口沖突等。和虛擬機的使用類似,大多數(shù)情況下都希望容器能擁有獨占的網(wǎng)絡資源。但在擁有獨占網(wǎng)絡資源后,依然面臨兩個問題:一是各個容器間如何進行有效通信?二是容器和其他非容器應用(宿主機、非宿主機等)如何通信?
Pod 是Kubernetes 的原子,是構(gòu)建應用程序的最小可部署對象。單個Pod 代表集群中正在運行的工作負載,其一般封裝一個或多個容器(比如基于Docker 運行時的容器)。
Kubernetes 使用了一種“IP-per-Pod”網(wǎng)絡模型:它為每一個Pod 分配了一個IP 地址,Pod 內(nèi)部的容器共享同一個網(wǎng)絡空間(相同的網(wǎng)絡設備和IP),且一個Pod 的IP 地址并不會隨著Pod 中的一個容器的起停而改變。
Kubernetes 中的網(wǎng)絡要解決的核心問題就是為每臺容器宿主機的進行IP 地址網(wǎng)段的劃分,以及容器IP 地址的分配。主要概括為:
(1)每個Pod 擁有集群內(nèi)唯一的IP 地址
(2)不同宿主機節(jié)點的容器IP 地址劃分不會重復
(3)宿主機節(jié)點的不同Pod 可以互相通信
(4)不同宿主機節(jié)點的Pod 可以與跨節(jié)點的主機互相通信
Kubernetes 提出了針對Pod 的網(wǎng)絡模型,但是并沒有提供具體實現(xiàn)細節(jié)。因此,任何滿足Kubernetes 網(wǎng)絡模型接口的都可視作一種有效的容器網(wǎng)絡技術實現(xiàn)。容器網(wǎng)絡插件則是針對Pod 的網(wǎng)絡模型,通過不同的方法,實現(xiàn)不同宿主機上的容器通信目標。
2.2 主流網(wǎng)絡插件解決方案
2.2.1 虛擬化協(xié)議棧
虛擬化協(xié)議棧主要目的在于從一臺物理主機中分離出多個TCP/IP 協(xié)議棧進行資源隔離使用。Network Namespace 是實現(xiàn)網(wǎng)絡虛擬化的重要功能,網(wǎng)絡空間有獨自的網(wǎng)絡棧信息,路由表,防火墻策略等。采用Network Namespace 網(wǎng)絡虛擬化技術后,容器進程就能使用自己 Network Namespace 里的協(xié)議棧,即:擁有屬于自己的 IP 地址和端口。
2.2.2 虛擬化網(wǎng)橋
在采用NetworkNamespace+Veth 技術后,容器即擁有了自身獨立的IP 地址和端口。但當宿主機啟動多個容器時,一個顯而易見的問題就是:各個被Network Namespace 隔離的容器進程如何進行端到端交互?如若讓眾多容器采用基于Veth 技術的“網(wǎng)線”的Container-to-Container Mesh 全互聯(lián)實現(xiàn),這顯然是較為“臃腫”的。
可以把每一個容器看做一臺主機,那么它們的聯(lián)通需求即是實現(xiàn)多臺主機之間的通信,通過網(wǎng)橋即可實現(xiàn)這樣的虛擬交換功能。具體來說,通過將網(wǎng)橋的每個端口都用Veth 連接對應的容器NetworkNamespace,然后根據(jù) MAC 地址學習來將數(shù)據(jù)包轉(zhuǎn)發(fā)到網(wǎng)橋的不同端口上,從而可實現(xiàn)一個宿主機內(nèi)部的不同容器通信需求。
以Docker 為例,它會在宿主機上創(chuàng)建一個名為 docker0 的網(wǎng)橋,然后所有的容器都借助于這個網(wǎng)橋進行通信[6]。圖3 展示了在一臺宿主機上基于docker0 網(wǎng)橋的容器網(wǎng)絡拓撲。
2.2.3 虛擬化路由
事實上,Docker 通過Veth 虛擬網(wǎng)絡設備以及Linux bridge 實現(xiàn)了同一臺主機上的容器網(wǎng)絡通信,在容器向外部網(wǎng)絡通信的部分可通過宿主機的Netfilter/iptables 進行NAT 實現(xiàn),但跨主機間的容器互訪依然存在阻礙。跨主機容器通信所需要解決的問題即不同宿主機上網(wǎng)橋間的聯(lián)通性問題,目前主要有如下兩個方向?qū)ι鲜鰡栴}進行解決。
方向一:在底層網(wǎng)絡設備中默認加入容器IP 地址的管理,需要感知容器實體的存在,一般依靠結(jié)合SDN 設備進行實現(xiàn)。
方向二:不修改底層網(wǎng)絡設備配置,而是復用既有的Underlay平面網(wǎng)絡,以Overlay 或通過自動化生成主機路由的方式解決容器跨主機通信,主要表現(xiàn)形式如下:
2.3 兩組患者心理狀態(tài)對比 干預前,兩組患者SAS、SDS評分比較,差異無統(tǒng)計學意義(P>0.05)。干預后,觀察組患者評分低于對照組,(P<0.05)。見表3。
(1)Overlay,通過隧道機制把容器發(fā)出的數(shù)據(jù)包封裝在通過宿主機網(wǎng)絡的數(shù)據(jù)包中,并復用既有的Underlay 網(wǎng)絡傳輸?shù)侥繕酥鳈C,目標主機再拆包轉(zhuǎn)發(fā)給對應的容器中。Overlay 隧道如VXLAN、IPIP 等,目前使用Overlay 技術的主流容器網(wǎng)絡有Flannel、Weave 等。
(2)Routing,通過動態(tài)修改宿主機的路由表信息,把宿主機當作容器的網(wǎng)關,調(diào)整路由規(guī)則轉(zhuǎn)發(fā)到指定的主機,達到容器間的網(wǎng)絡層互通。目前通過路由技術實現(xiàn)容器跨主機通信的網(wǎng)絡有Flannel host-gw、Calico BGP 等。
本文接下來以同時兼顧Overlay 與Routing 的Flannel 解決方案描述容器的跨主機通信機制。
Flannel 的設計分為兩個方面,一個是容器IP 的分配機制,另一個是容器間的通訊機制。Flannel 提供了一種全局的網(wǎng)絡地址分配機制,并使用外置的etcd 數(shù)據(jù)庫來存儲網(wǎng)段和節(jié)點之間的映射關系,F(xiàn)lannel 通過配置各個節(jié)點上的容器只能在分配到當前節(jié)點的網(wǎng)段里選擇IP 地址,從而實現(xiàn)IP 地址分配的全局唯一性。
在容器間通訊的具體實現(xiàn)上,F(xiàn)lannel 利用各種backend 例如UDP,VXLAN,host-gw 等等,通過不同手段實現(xiàn)跨主機轉(zhuǎn)發(fā)容器間的網(wǎng)絡流量,完成容器間的跨主機路由通信。
Flannel 的UDP backend 方案里會在每臺宿主機上生成flannel0設備,它是一個TUN 設備。TUN 設備可以在操作系統(tǒng)內(nèi)核態(tài)和用戶態(tài)應用程序之間數(shù)據(jù)。當內(nèi)核將一個數(shù)據(jù)包發(fā)送給flannel0 設備之后,flannel0 就會把這個數(shù)據(jù)包交給創(chuàng)建這個設備的應用程序進行處理,這里就是flannel 的守護進程——flanneld。而如果 flanneld 進程向 flannel0 設備發(fā)送了一個數(shù)據(jù)包,那么這個數(shù)據(jù)包就會根據(jù)宿主機的路由表進行處理。
圖4 展示了兩個宿主機上容器的通信過程。
所以,事實上Flannel UDP 模式即是在不同宿主機上的兩個容器之間打通了一條Overlay“隧道”,它使得任意兩個容器可直接透明地進行IP 通信,且無需考慮容器和宿主機在網(wǎng)絡中的位置。考慮到該模式采用了flannel0 這個TUN 設備,它在數(shù)據(jù)包傳輸過程中頻繁存在用戶態(tài)與內(nèi)核態(tài)的數(shù)據(jù)拷貝,性能較差,因此基于VXLAN(Virtual Extensible LAN)的模式應運而生,它可以完全在內(nèi)核態(tài)實現(xiàn)上述封裝和解封裝的工作。
Routing 的形式主要體現(xiàn)在flannel 的host-gw 模式。在實際運作中,host-gw 工作模式就是將每個宿主機承載的flannel 子網(wǎng)的“下一跳”設置成了該子網(wǎng)對應的宿主機的 IP 地址。具體來說,hostgw 模式通過在宿主機上添加一個路由規(guī)則:<目的容器IP 地址段> via <網(wǎng)關的IP 地址> dev eth0。而這個路由規(guī)則的更新則是通過在各個宿主機上部署代理進程動態(tài)地將容器網(wǎng)絡的變化信息“翻譯”為到主機的路由表信息,從而實現(xiàn)在所有的宿主機上都擁有整個容器網(wǎng)絡的路由信息。
由于host-gw 模式完全是依靠宿主機的路由機制,因此它的效率與虛擬機直接的通信相差無幾。但這種網(wǎng)絡方案得以正常工作的核心,是為每個容器的IP 地址,找到它所對應的,“下一跳”的網(wǎng)關。所以說,F(xiàn)lannel host-gw 模式必須要求集群宿主機之間在數(shù)據(jù)鏈路層之間是連通的,這也限制了集群的規(guī)模。不僅如此,大規(guī)模的路由表查詢也會進一步影響容器網(wǎng)絡的性能。因此,host-gw 模式在宿主機本身存在跨網(wǎng)段情況下的實現(xiàn)有一定的局限性。
為了同時兼顧性能和支持宿主機跨網(wǎng)段,可為flannel 的VXLAN 指定DirectRouting 參數(shù),當兩個容器所在宿主機節(jié)點在同一個網(wǎng)段中時,可直接通過物理網(wǎng)卡的網(wǎng)關路由轉(zhuǎn)發(fā),而不用額外對數(shù)據(jù)包進行隧道封裝。當且僅當所在宿主機跨網(wǎng)段時,才使用VXLAN 模式。
3 總結(jié)與展望
數(shù)據(jù)中心網(wǎng)絡在云計算基礎設施中具有關鍵地位,其性能的高低一定程度上影響著企業(yè)云計算的服務質(zhì)量。以容器、微服務、Kubernetes為主要核心的云原生架構(gòu),是當下設計具有彈性、可擴展、高可用業(yè)務系統(tǒng)架構(gòu)的主要聚焦點。由于該架構(gòu)中的實施往往伴隨著數(shù)據(jù)中心東西向網(wǎng)絡帶寬的高要求,因此,其涉及的有關網(wǎng)絡拓撲、資源規(guī)劃和分配方式等需要配合以云原生的方式演進與適應,從而為“應用系統(tǒng)上云”的工作打下堅實基礎。
