基于多網(wǎng)絡(luò)級聯(lián)預(yù)測的異常行為識別方法研究
2021-06-11 03:12:50趙鑫,陳平
測試技術(shù)學(xué)報 2021年3期
趙 鑫,陳 平
(中北大學(xué) 信息探測與處理山西省重點實驗室,山西 太原 030051)
0 引 言
人員異常行為檢測在機(jī)器人視覺、 智能監(jiān)控、 公共安全等領(lǐng)域的運用日趨普遍[1]. 異常行為是指相對于歷史軌跡發(fā)生偏離的運動目標(biāo). 如何在復(fù)雜的視頻中自動檢測識別異常行為是近年來智能視頻處理的研究熱點.
目前,國內(nèi)外學(xué)者主要根據(jù)不同場景中不同的異常行為識別任務(wù),提出了多種不同的檢測方法. 已有的異常行為分析方法大致可以分為以下4類: ① 基于時空特征的模式分析方法,針對視頻序列在時空維度提取特征判斷行為類別[2],該類方法依賴于圖片信息提取的視覺運動特征[3],存在輸入信息冗余、 模型自適應(yīng)能力差等缺點,并且對人類行為的刻畫能力有限,局限于若干種簡單的單人行為,不易擴(kuò)展到多人間的復(fù)雜行為. ② 基于運動軌跡的方法,通過位置匹配和目標(biāo)關(guān)聯(lián)來提取運動軌跡,構(gòu)建網(wǎng)絡(luò)對目標(biāo)軌跡的速度、 加速度、 軌跡長度等信息進(jìn)行訓(xùn)練[4]. 該類方法主要對軌跡數(shù)據(jù)建模,然而,由于圖片中的目標(biāo)之間存在重疊、 遮擋等問題,難以精確跟蹤目標(biāo)軌跡. ③ 基于行為預(yù)測分析方法,通過構(gòu)建預(yù)測未來時間段內(nèi)人類行為的網(wǎng)絡(luò)模型,對人員在運動時可能觸發(fā)危險的行為發(fā)出及時警告[5-9]. 目前,人類行為視頻預(yù)測方法是在像素空間中遞歸生成未來幀來進(jìn)行行為判斷[10],但預(yù)測模型缺乏視覺特征與真實運動事件語義的可解釋性,且預(yù)測效果容易受預(yù)測容量和環(huán)境因素影響. ④ 基于人體骨架姿態(tài)預(yù)測的方法,采用目標(biāo)檢測和人體模型提取圖片中人體骨架,利用骨架隨時間的變化來描述行為[11-12]. 基于骨架預(yù)測的方法強(qiáng)調(diào)異常行為的可預(yù)測性,采用預(yù)測人體骨架運動軌跡的方式,但骨架關(guān)鍵點提取不準(zhǔn)確時,會直接影響異常預(yù)測結(jié)果.
人員異常行為識別是集成目標(biāo)檢測、 目標(biāo)跟蹤、 行為預(yù)測等多個模塊的智能識別系統(tǒng),單個神經(jīng)網(wǎng)絡(luò)不能直接用于異常的識別和判斷,而單獨運用較深的網(wǎng)絡(luò)會使計算處理速度較慢,研究人員提出了使用多網(wǎng)絡(luò)級聯(lián)的思想,應(yīng)用于異常行為識別[13-15]. 通過級聯(lián)神經(jīng)網(wǎng)絡(luò)模塊逐級細(xì)化人員特征,構(gòu)建行為規(guī)則模型對視頻中人員異常進(jìn)行判斷. 但是基于多網(wǎng)絡(luò)級聯(lián)的檢測識別效果,仍取決于各個模塊的檢測效果與精度. 在場景復(fù)雜、 多目標(biāo)遮擋的人員異常行為分析中,現(xiàn)有的多網(wǎng)絡(luò)級聯(lián)的識別方法在識別精度和魯棒性上存在局限性.
因此,針對該問題,基于多網(wǎng)絡(luò)級聯(lián)思想,重點圍繞復(fù)雜場景下多目標(biāo)跟蹤與行為識別,分析改進(jìn)級聯(lián)網(wǎng)絡(luò)中各個網(wǎng)絡(luò)模塊的實現(xiàn)途徑. 主要采用實例分割模型檢測人體位置,提取人體骨架關(guān)鍵點作為行為語義特征,輔助理解人類行為信息,并通過運動分解獲得運動特征. 在預(yù)測過程中,以目標(biāo)檢測框和關(guān)鍵點坐標(biāo)信息作為中間特征,同時利用全局和局部預(yù)測網(wǎng)絡(luò)來捕捉不同分量的人體運動信息,從而實現(xiàn)多目標(biāo)下高質(zhì)量的行為預(yù)測和識別.
1 骨架關(guān)鍵點提取與跟蹤
1.1 基于Mask RCNN的骨架關(guān)鍵點提取模型
異常行為識別主要研究視頻人員的行為,使用人體骨架關(guān)鍵點作為行為特征,利用骨架關(guān)鍵點坐標(biāo)表示人體整個結(jié)構(gòu)以及肢體結(jié)構(gòu)間的關(guān)系,可精確反映人體運動變化并表示對應(yīng)的行為狀態(tài). 本文基于上海交通大學(xué)盧策吾團(tuán)隊提出的自頂向下的骨架關(guān)鍵點檢測算法Alpha Pose[16],使用通用實例分割架構(gòu)Mask RCNN[17]用作人體檢測,其不僅能輸出目標(biāo)的具體類別和目標(biāo)框,也可以在保證檢測速度的情況下,對場景復(fù)雜、 多目標(biāo)遮擋下的人體進(jìn)行精確分割,網(wǎng)絡(luò)結(jié)構(gòu)如圖1 所示.
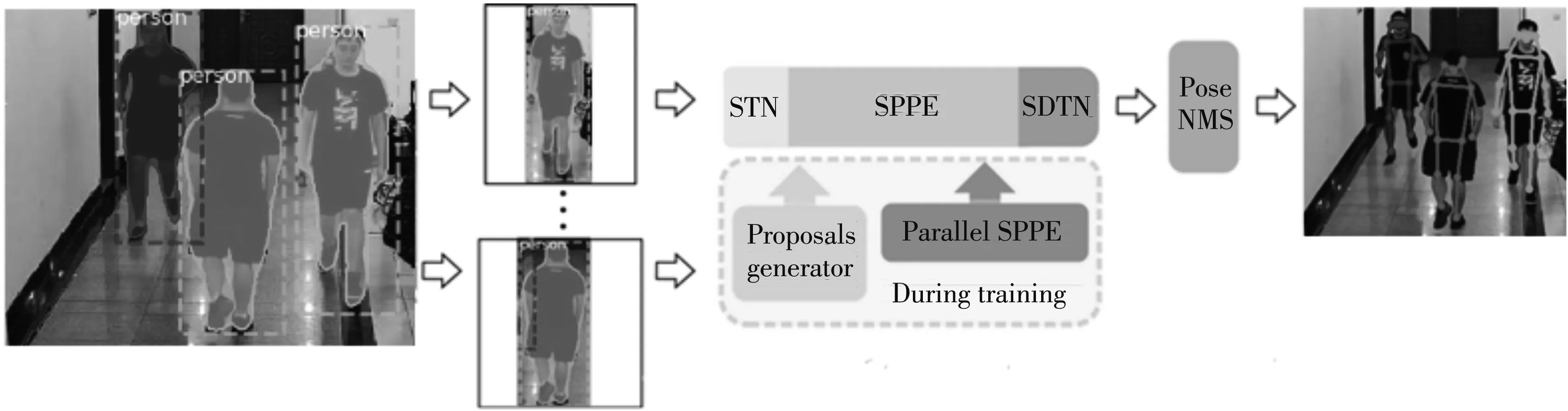
圖1 骨架關(guān)鍵點提取網(wǎng)絡(luò)結(jié)構(gòu)
骨架關(guān)鍵點檢測的基本步驟: ① 采取Mask RCNN作為人體檢測網(wǎng)絡(luò),提取圖像中的候選框和可視化掩膜. ② 使用空間變換網(wǎng)絡(luò)(Spatial Transformer Networks,STN)對人體檢測候選框進(jìn)行空間變換,提取出高質(zhì)量的單人區(qū)域. 然后使用單人姿態(tài)檢測(Singal Person Pose Estimation, SPPE)對得到的單人區(qū)域進(jìn)行骨架關(guān)鍵點檢測,并將檢測結(jié)果映射到原圖中. ③ 利用參數(shù)化姿態(tài)非最大抑制(Parametric Pose Non-Maximum Suppression,Pose NMS)來消除檢測器產(chǎn)生的冗余骨架. 另外,空間反變換網(wǎng)絡(luò)(Spatial De-Transformer Network, SDTN)為STN的逆變換,用于反向修正骨架關(guān)鍵點,姿態(tài)引導(dǎo)區(qū)域框生成器(Pose-Guided Proposals Generator, PGPG)的作用是來增強(qiáng)訓(xùn)練樣本,作用于目標(biāo)檢測和SPPE的訓(xùn)練,提高訓(xùn)練的精度. 如圖2 所示,將人體結(jié)構(gòu)簡化為17個人體骨架關(guān)鍵點坐標(biāo)的模型. 人體骨架關(guān)鍵點標(biāo)注信息以COCO數(shù)據(jù)集形式存儲.

圖2 人體關(guān)鍵點模型Fig.2 Human body key point model
1.2 基于稀疏光流的骨架關(guān)鍵點跟蹤網(wǎng)絡(luò)
在固定相機(jī)監(jiān)控場景下,行人的移動速度也較為緩慢,在高幀率相機(jī)的采樣下,人體運動時位置坐標(biāo)信息連續(xù)性強(qiáng),不易出現(xiàn)人體動作行為的瞬態(tài)變化. 為了跟蹤人體的運動情況,本文采用融合稀疏光流的骨架關(guān)鍵點跟蹤方法. 稀疏光流是對指定關(guān)鍵點進(jìn)行跟蹤,基于亮度恒定假設(shè)、 相鄰幀關(guān)鍵點小范圍運動假設(shè)、 空間一致假設(shè),計算運動物體在像素平面上的瞬時速度,跟蹤運動目標(biāo)在連續(xù)圖片中的位置.
根據(jù)1.1中骨架提取模型,依次輸出人員骨架關(guān)鍵點坐標(biāo)和目標(biāo)矩形框坐標(biāo)信息,以人員中心為原點將人體檢測的感興趣區(qū)域(region of interest, ROI)擴(kuò)大20%,確保放大的邊界框為關(guān)鍵點在下一幀的可能區(qū)域.
使用Lucas-Kanade算法計算關(guān)鍵點坐標(biāo)的光流,當(dāng)dt足夠短時,依據(jù)光流恒定原則,關(guān)鍵點的變化保持不變,即
G(x+dx,y+dy,t+dt)=G(x,y,t),
(1)
式中:G(·)表示不同時刻的骨架關(guān)鍵點;x,y分別表示骨架關(guān)鍵點的坐標(biāo);t表示時刻; dt表示運動時間; dx,dy分別表示dt足夠短時的坐標(biāo)變化量.
由于相鄰幀時間足夠短,使得物體運動較小,則
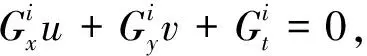
(2)
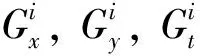
建立光流方程,使用最小二乘法,可得光流的近似解
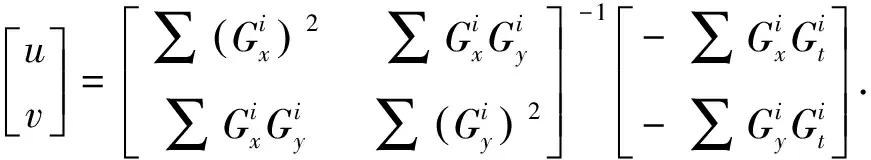
(3)
通過光流可生成關(guān)鍵點從起始位置到當(dāng)前位置時的坐標(biāo)
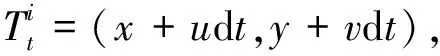
(4)
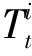
比較稀疏光流生成的骨架關(guān)鍵點是否會落入可能區(qū)域內(nèi),對于檢測和跟蹤一致的每個關(guān)鍵點,標(biāo)定為1分,否則標(biāo)定出0.
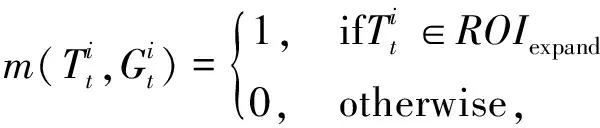
(5)
式中:ROIexpand表示擴(kuò)大的感興趣區(qū)域;m表示匹配分?jǐn)?shù).
將前后幀的骨架坐標(biāo)以及骨架匹配分?jǐn)?shù)聯(lián)立成為效益矩陣,利用匈牙利算法[18]對前后幀的關(guān)鍵點進(jìn)行指派,按照空間一致性和姿勢一致性約束條件進(jìn)行篩選,得到匹配成功的目標(biāo)關(guān)鍵點. 逐幀更新骨架關(guān)鍵點,完成對視頻流中的人體骨架姿態(tài)跟蹤.
2 異常行為識別方法
2.1 人體運動分解
在監(jiān)控視頻中,人體骨架運動變化取決于位置和姿態(tài)的變化. 人體與監(jiān)控攝像頭的距離會導(dǎo)致個體運動狀態(tài)的差異,對于近場的人體,運動主要受局部姿態(tài)因素的影響. 在遠(yuǎn)場情況下,運動由全局運動支配. 現(xiàn)有的分解方法僅利用了人體關(guān)鍵點所表征的全局運動模式信息,而忽略了它背后所蘊(yùn)含的人體局部區(qū)域的細(xì)節(jié)外觀信息,而局部信息的缺失導(dǎo)致預(yù)測和重建人員在行為細(xì)節(jié)上存在一定的困難.
在1.2節(jié)中跟蹤骨架關(guān)鍵點坐標(biāo)的基礎(chǔ)上,將人體的骨架運動分解為“全局”分量和“局部”分量兩部分. 全局分量為目標(biāo)人體的絕對位置,包括有關(guān)人體邊界框的坐標(biāo),剛性運動的信息等; 局部分量為骨架關(guān)節(jié)點相對于邊界框的位置,用于描述骨架的內(nèi)部形變. 上述分解過程由公式(6)來描述.
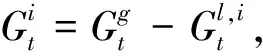
(6)
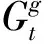
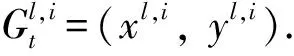
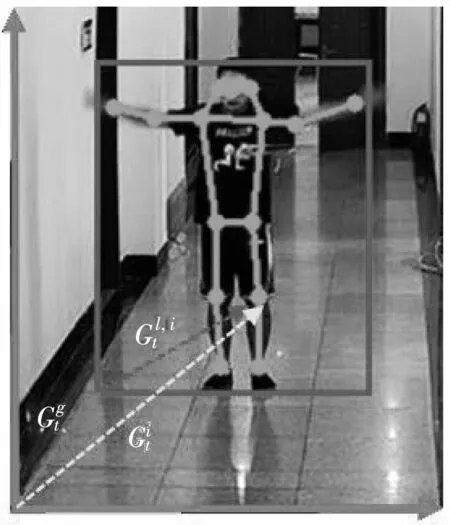
圖3 人體運動分解模型Fig.3 Human body motion decomposition model
xl,i=xi-xg;yl,i=yi-yg,
(7)
式中:xg,yg表示人體邊界框左下角的坐標(biāo);xi,yi代表第i個關(guān)鍵點在相應(yīng)分量的坐標(biāo).
2.2 基于GRU單元的骨架關(guān)鍵點重建和預(yù)測
本文使用門控循環(huán)單元(GRU)組成雙循環(huán)遞歸編解碼器模型,解決循環(huán)神經(jīng)網(wǎng)絡(luò)中參數(shù)隨時間反向傳播時發(fā)生梯度消失的問題,并且該模型結(jié)構(gòu)簡單、 計算量較少,可應(yīng)用于提取視頻運動信息和時間特征.
雙循環(huán)遞歸編解碼器模型由編碼器、 重建解碼器和預(yù)測解碼器組成,其中,全局分量和局部分量的軌跡信息輸入到兩個交互的分支,其中一個分支用于學(xué)習(xí)目標(biāo)全局分量下軌跡特征的時間關(guān)聯(lián)性,另一個分支用于學(xué)習(xí)目標(biāo)局部分量下軌跡特征的時間關(guān)聯(lián)性,網(wǎng)絡(luò)結(jié)構(gòu)如圖4 所示.
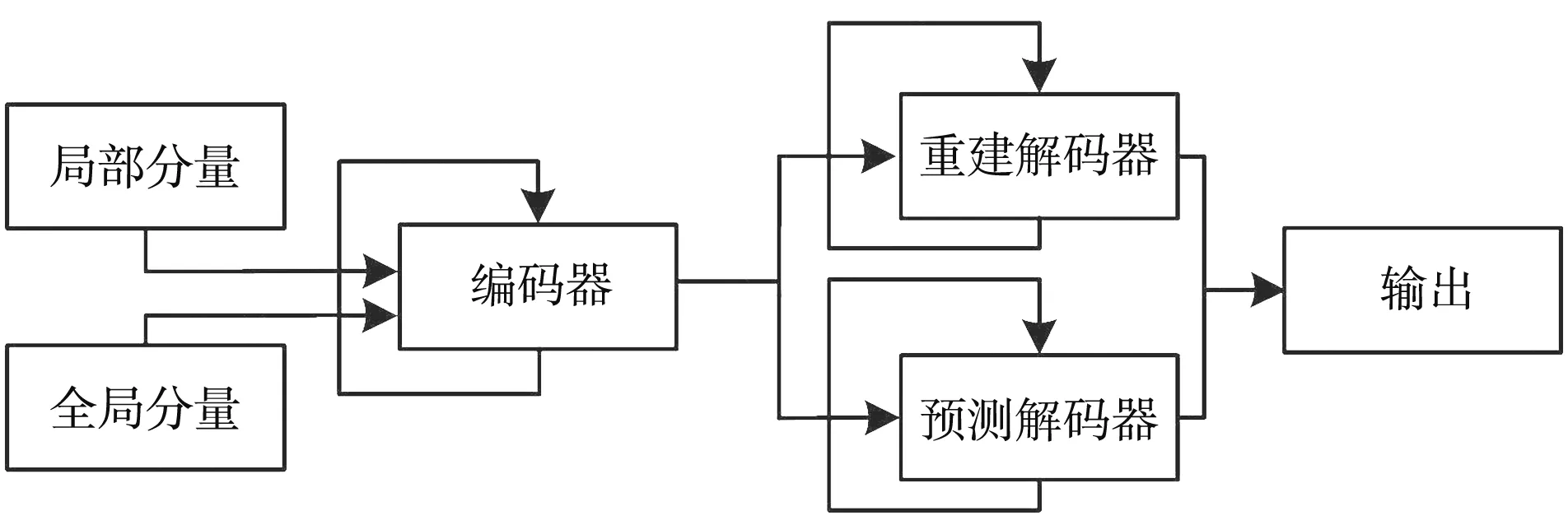
圖4 雙向遞歸編解碼網(wǎng)絡(luò)結(jié)構(gòu)Fig.4 Two-way recursive encoding and decodingnetwork structure
使用滑動窗口策略從人體骨架軌跡中提取片段,編碼器過程中設(shè)置GRU的隱狀態(tài)為空,通過跨分支信息傳遞機(jī)制傳遞各分量下的參數(shù)信息,學(xué)習(xí)各分量單獨組件下的動態(tài)坐標(biāo)信息. 解碼過程時設(shè)置GRU的隱狀態(tài)與編碼器輸出相同,使用重建解碼器對學(xué)習(xí)的人體骨架坐標(biāo)進(jìn)行重建,預(yù)測解碼器預(yù)測其未來幀的動態(tài)骨架信息. 編碼器輸入長度為6幀,重建解碼器和預(yù)測解碼器的長度為6幀. 輸出真實骨架關(guān)鍵點坐標(biāo)距離與預(yù)測骨架信息的損失誤差為
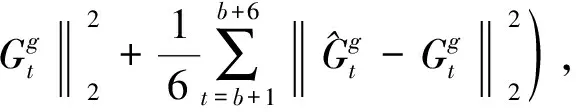
(8)
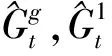
收集骨架異常得分: 經(jīng)過訓(xùn)練的模型預(yù)測人體在未來時間尺度上的姿勢軌跡. 使用表決機(jī)制計算預(yù)測誤差
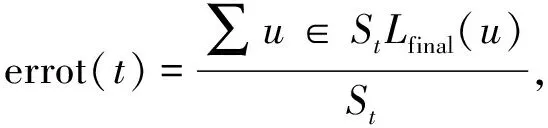
(9)
式中:St表示從重建和預(yù)測中包含的已解碼段的集合. 對于每段姿態(tài)軌跡,在測試期間將與閾值進(jìn)行比較. 如果超過閾值,則將時刻t標(biāo)記為異常.
3 技術(shù)路線圖
本文采用如圖5 所示的多網(wǎng)絡(luò)級聯(lián)預(yù)測的異常行為識別網(wǎng)絡(luò),采用Mask-RCNN模型提取人體位置,利用提取骨架與稀疏光流相結(jié)合,完成視頻中人體骨架的跟蹤,通過運動分解,精確描述人體全局運動信息和局部區(qū)域細(xì)節(jié)信息,在預(yù)測過程中以目標(biāo)檢測框和關(guān)鍵點坐標(biāo)信息作為中間特征,同時利用全局和局部預(yù)測網(wǎng)絡(luò)來捕捉不同分量的人體運動信息,從而實現(xiàn)多目標(biāo)下高質(zhì)量的行為預(yù)測和識別.
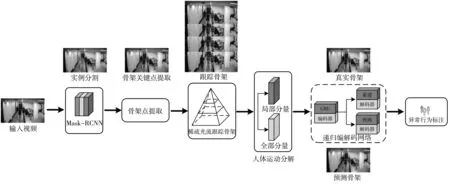
圖5 網(wǎng)絡(luò)結(jié)構(gòu)圖
4 實驗分析與評價
4.1 實驗環(huán)境及數(shù)據(jù)集
本文的實驗環(huán)境為: windows 10; 處理器為Intel(R)Core(TM) i7-6700 CPU @ 3.4 GHz; 內(nèi)存32 G; 顯卡為GTX1080; 編程環(huán)境為python3.7; 開發(fā)工具為PyCharm 2018; 使用TensorFlow框架進(jìn)行網(wǎng)絡(luò)搭建、 訓(xùn)練和測試.
為了驗證所提算法的可靠性及泛化能力,本文分別在實驗室自建模擬場景數(shù)據(jù)集以及ShanghaiTech Campus公開數(shù)據(jù)集[19]進(jìn)行訓(xùn)練和測試. 公開數(shù)據(jù)集結(jié)合了上海科技大學(xué)校園13個不同場景的視頻信息,包含330個訓(xùn)練視頻和107個測試視頻,視頻分辨率為856×480,包括摔倒、 推打、 追逐、 騎行、 翻越欄桿等多種行為. 數(shù)據(jù)實例如圖6 的所示.

圖6 ShanghaiTech Campus數(shù)據(jù)集
自建樣本數(shù)據(jù)使用布置于室內(nèi)的DS-IPC-B12H槍式攝像機(jī)采集,相機(jī)焦距為8 mm,具備720P/1080高清廣角畫面功能,多臺攝像機(jī)分布式安裝于實驗樓內(nèi)側(cè)走廊,走廊長約25 m,監(jiān)控攝像機(jī)與人員平均距離約7 m. 攝像機(jī)及安裝位置如圖7 所示.

圖7 攝像機(jī)及安裝位置
自建樣本數(shù)據(jù)為模擬行人異常可疑行為,主要有摔倒、 聚集、 劇烈運動、 奔跑等行為,每段序列中各動作按一定順序多次出現(xiàn). 圖8為自建數(shù)據(jù)集實例,共計200組動作序列,其中訓(xùn)練集150組,測試集50組.

圖8 自建樣本數(shù)據(jù)
4.2 公開數(shù)據(jù)集
使用本文方法對公開數(shù)據(jù)集中測試視頻進(jìn)行實驗,在異常行為可視化的同時,屏蔽與人員無關(guān)的背景,采用熱圖的方式呈現(xiàn)圖片,異常分?jǐn)?shù)較高使用深色表示異常人員,異常分?jǐn)?shù)較低時采用淺色表示. 引入?yún)?shù)AUC和AP作為評價標(biāo)準(zhǔn),AUC定義為接收者操作特征曲線(Receiver Operating Characteristic ,ROC)下與坐標(biāo)軸圍成的面積,其值小于等于1,AUC值越大說明檢測越好. AP定義為精確召回曲線(Precision-Recall,PR)下與坐標(biāo)軸圍成的面積,是召回率與精確度的一種統(tǒng)一化平均,AP值越接近1,表示檢測效果越好.
針對ShanghaiTech Campus數(shù)據(jù)集,去除與人類行為無關(guān)的異常行為,為了直觀地顯示異常行為檢測效果,對比本文方法與其他算法在異常情況發(fā)生時和非異常情況的效果,實驗結(jié)果如圖9 和圖10 所示.

圖9 不同算法非異常情況比較Fig.9 Comparison of non-abnormal situations ofdifferent algorithms

圖10 不同算法異常情況識別結(jié)果Fig.10 Recognition results of abnormal conditions ofdifferent algorithms
圖9 中(a)~(c)為使用Morais R方法測試,正常人員在場景中被人員遮擋時,提取骨架具有與正常下半身“相似”的移動模式,預(yù)測網(wǎng)絡(luò)補(bǔ)充上半身肢體坐標(biāo)點,導(dǎo)致局部分量下坐標(biāo)信息發(fā)生異常,從而對于正常行為誤報警; 圖9 中(e)~(f)為本文方法,消除非異常標(biāo)注.
圖10 為公開數(shù)據(jù)集中異常情況標(biāo)注結(jié)果,通過融合實例分割的方法,提取人體關(guān)鍵點,并調(diào)整編碼器輸入圖片為6張,使用滑動窗口算法,從連續(xù)圖片中提取人體骨架軌跡信息,輸入網(wǎng)絡(luò)進(jìn)行判斷. 圖10 中(a)~(c)為使用Morais R方法測試; 圖10 中(e)~(f)為本文方法,消除非異常標(biāo)注,可以更有效地預(yù)測動態(tài)骨架信息且保留細(xì)節(jié)信息,提供了更好的視覺性能.
表 1 為本文方法在ShanghaiTech Campus數(shù)據(jù)集與現(xiàn)有技術(shù)的性能比較. Liu和Conv-AE等基于圖像的方法所構(gòu)建的模型會因為關(guān)注圖像的背景、 光線等信息,造成輸入信息的過分冗余,具有較大的局限性. Rodrigues使用提取人體姿態(tài)信息表征人體的整體運動模型,使提取的特征更加精細(xì),使得指標(biāo)有所提升. 本文算法獲得了更為優(yōu)越的識別效果,AUC達(dá)到了0.774 2,AP達(dá)到0.702 7,由于精確提取人體關(guān)鍵點,并作為行為語義特征,避免了場景中圖像的背景、 光線等不相關(guān)噪聲信息的干擾. 并將運動動態(tài)信息分解,能夠精確描述人體關(guān)節(jié)點內(nèi)部的異常行為,可對更加復(fù)雜的行為進(jìn)行識別.
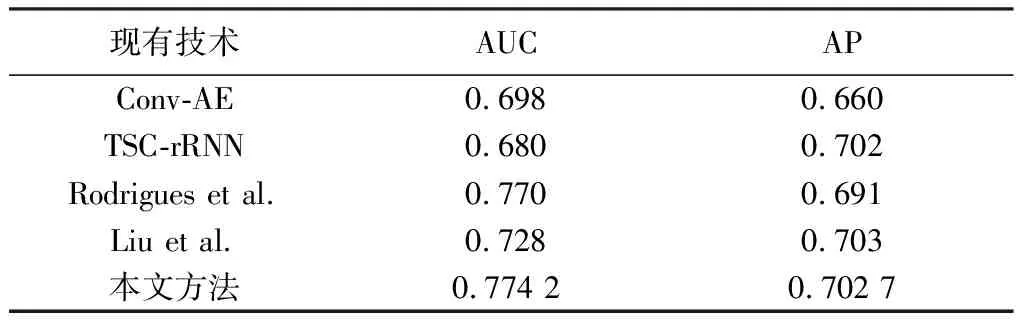
表 1 公開數(shù)據(jù)集下現(xiàn)有技術(shù)的性能比較Tab.1 Performance comparison of existing technologiesunder public datasets
4.3 自建樣本數(shù)據(jù)
使用ShanghaiTech Campus數(shù)據(jù)集預(yù)訓(xùn)練網(wǎng)絡(luò)模型,將模型遷移學(xué)習(xí)到自建數(shù)據(jù)集上并調(diào)整網(wǎng)絡(luò). 異常行為檢測結(jié)果如圖11 所示,圖11(a)表示輸入圖片中人員揮舞手掌、 異常行進(jìn)、 劇烈運動、 摔倒?fàn)顟B(tài); 圖11(b)為重建骨架圖,可以看出人員在異常行為發(fā)生時的真實骨架狀態(tài); 圖11(c) 為人員預(yù)測骨架和重建骨架的圖示,收集骨架異常分?jǐn)?shù)進(jìn)行判斷異常; 圖11(d)為異常行為可視化標(biāo)注.

圖11 自建數(shù)據(jù)集異常行為檢測結(jié)果
將自建測試集中50組視頻分解為圖像幀,共計樣本6 727幀,選擇其中異常事件的3 851幀圖像測試,異常跳躍樣本數(shù)為478,摔倒樣本數(shù)為1 531,劇烈運動樣本數(shù)為596,原地異常樣本數(shù)為457,加速奔跑樣本數(shù)為789. 異常檢測結(jié)果如表 2 所示.

表 2 自建數(shù)據(jù)異常行為檢測結(jié)果Tab.2 Self-built data abnormal behavior detection results
5 結(jié)束語
本文針對人員在正常運動具有規(guī)律性且異常事件和違規(guī)操作具有連續(xù)性的問題,提出了多網(wǎng)絡(luò)級聯(lián)異常行為預(yù)測分析方法,不同于傳統(tǒng)端到端異常行為檢測的方法,使用實例分割模型提取目標(biāo)位置,提取骨架關(guān)鍵點作為行為特征,利用提取骨架與稀疏光流相結(jié)合,完成視頻中骨骼的跟蹤,通過雙向遞歸編解碼網(wǎng)絡(luò)預(yù)測動態(tài)骨架信息,將骨架異常分?jǐn)?shù)與閾值對比判斷行為異常. 在ShanghaiTech Campus公開數(shù)據(jù)集和自建數(shù)據(jù)集進(jìn)行實驗,實驗結(jié)果表明,本文模型在不同場景、 不同異常行為下都有較高的檢測精度.
猜你喜歡
中學(xué)生數(shù)理化·中考版(2022年12期)2022-02-16 07:36:56
今日農(nóng)業(yè)(2021年8期)2021-11-28 05:07:50
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
中國衛(wèi)生(2014年2期)2014-11-12 13:00:16
語文知識(2014年7期)2014-02-28 22:00:26
