基于深度神經(jīng)網(wǎng)絡的中國移動營業(yè)廳人流量統(tǒng)計研究
2021-06-07 04:50:33陳樂丁戈肖忠良
現(xiàn)代信息科技 2021年24期
陳樂 丁戈 肖忠良

摘 ?要:文章提出深度神經(jīng)網(wǎng)絡的方法,將分治策略引入到人流量統(tǒng)計問題中。這個方法以VGG16作為特征編碼網(wǎng)絡,UNet作為解碼網(wǎng)絡,將人流量統(tǒng)計變成一個可拆解的任務。在統(tǒng)計圖片上人數(shù)時,總可以把圖片分解成多個子區(qū)域,使得每個區(qū)域的人流量計數(shù)都是在之前訓練集上所見過的人數(shù)類別。然后再把每個子區(qū)域上面的人數(shù)加起來,就是統(tǒng)計結果。在對廣州某個中國移動營業(yè)廳的人流量統(tǒng)計的實驗中,預測的速度能達到實時監(jiān)測的速度和高精確度。
關鍵詞:分治策略;人流量統(tǒng)計;深度神經(jīng)網(wǎng)絡;VGG16;UNet
中圖分類號:TP18 ? ? ? ?文獻標識碼:A文章編號:2096-4706(2021)24-0084-05
Abstract: In this paper, the method of deep neural network is proposed, and the divide and conquer strategy is introduced into the problem of people flow statistics. This method takes VGG16 as the feature coding network ?and UNet as decoding network, which turns the people flow statistics into a detachable task. When counting the number of people on the pictures, we can always decompose the picture into multiple sub-regions, so that the people flow count in each area is the number of people seen on the previous training set. Then add up the number of people in each sub-region, which is the result of statistics. In the experiment of people flow statistics in a China mobile business hall in Guangzhou, the predicted speed can reach real-time monitoring speed, and has high accuracy.
Keywords: divide and conquer strategy; people flow statistics; deep neural network; VGG16; UNet
0 ?引 ?言
截止2021年6月底,中國移動客戶達到9.46億戶,線下營業(yè)廳遍布中國的每個大大小小的城市。5G套餐客戶達到2.51億戶,穩(wěn)居三大運營商之首[1]。面對如此龐大的客戶群體,營業(yè)廳員工在多用戶咨詢和辦理業(yè)務繁忙的時候,難免會出現(xiàn)服務不周到,工作效率下降的情況。而且在新冠疫情的影響下,每個營業(yè)廳的人數(shù)也要得到相應的控制。而且客戶能得到精確的每個營業(yè)廳的人數(shù),能幫助他們選擇人數(shù)相對較少的營業(yè)廳辦理業(yè)務。在提高中國移動的員工服務質(zhì)量和精準控制營業(yè)廳人數(shù)來更好的進行防疫工作的壓力之下,本文章提出了一種基于神經(jīng)網(wǎng)絡和分治策略的精準和實時的人流量統(tǒng)計的方法。首先,該方法需要先訓練一個可以計數(shù)0到10個人的深度神經(jīng)網(wǎng)絡模型。然后再利用判別器來判斷該子區(qū)域是否需要繼續(xù)進行切割,若子區(qū)域的人數(shù)大于10人的時候需要繼續(xù)切割。最后合并不同的子區(qū)域的結果[2]。該預測網(wǎng)絡的整體結構是以VGG16作為特征編碼器的主干網(wǎng)絡,參考UNet作為解碼器,一個計數(shù)分類器,一個劃分判別器。網(wǎng)絡結構的各個部分各司其職,相互作用,提高了模型的預測速度和準確率。
1 ?人流量統(tǒng)計算法
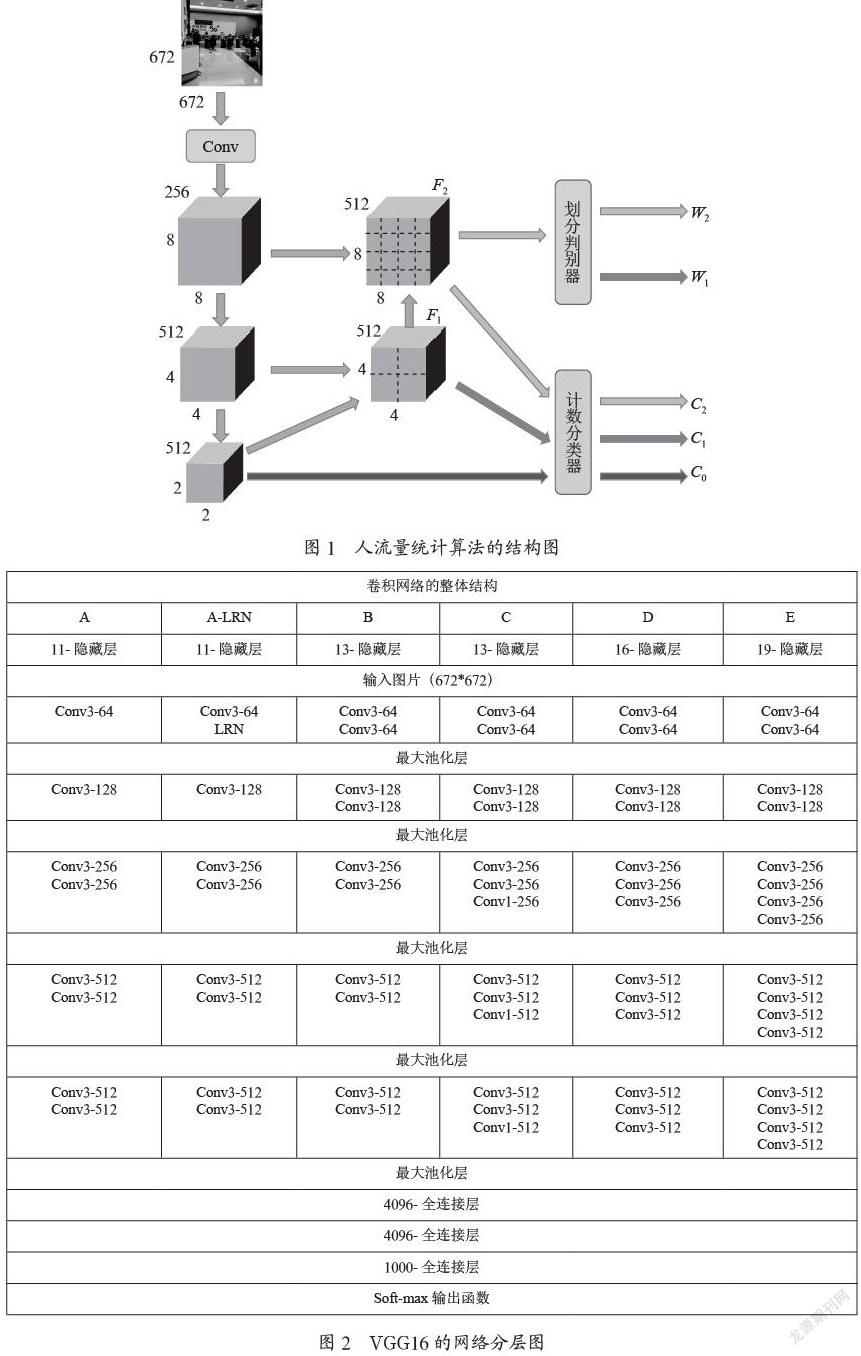
1.1 ?人流量統(tǒng)計算法的結構圖
算法的整體結構如圖1所示,由一個VGG16特征編碼器,一個UNet型的解碼器,一個計數(shù)分類器和一個劃分判別器構成的。左邊的Conv3,Conv4和Conv5是參考VGG16的網(wǎng)絡進行的下采樣卷積操作。中間有格子劃分的F2和F1是通過上采樣得到的。F1是通過F0上采樣的得到的,F(xiàn)2是通過F1上采樣得到的,它們的步長都是2。這個部分是參考UNet型的解碼器得到的。F1和F2劃分出來的區(qū)域就是子區(qū)域。這時劃分判別器就需要判斷是否要繼續(xù)進行上采樣,讓子區(qū)域劃分得更加小來滿足子區(qū)域人數(shù)小于10的要求。W1和W2的值就只有(0,1),來判斷是否需要繼續(xù)進行“錯誤!未找到索引項。”上采樣。最后再把特征圖中的每個子區(qū)域讓訓練好的計數(shù)分類器來判斷里面有多少人,是屬于(0,10)中的哪一個類別,得到C0,C1和C2[3]。
1.2 ?VGG16的特征編碼器
圖2是原先的VGG16的網(wǎng)絡結構層圖。由圖結構可知,總共有13個卷積層和3個全連接層。其中的池化部分都是用了max pooling,激活函數(shù)是用了ReLU函數(shù)。卷積核的大小都是3×3的[4]。文章人流量統(tǒng)計算法中的結構,就是去掉了VGG16中所有全連接層,Conv5就是上圖結構中除了全連接層中的最后的輸出特征圖,也就是原圖中的輸入圖片下采樣32倍得到的輸出特征圖。Conv5的結果直接通過計數(shù)分類器,預測出C0。C0就是當前整體圖片的預測輸出結果,也相當于由普通的VGG16網(wǎng)絡預測得到的結果。
1.3 ?UNet的解碼器
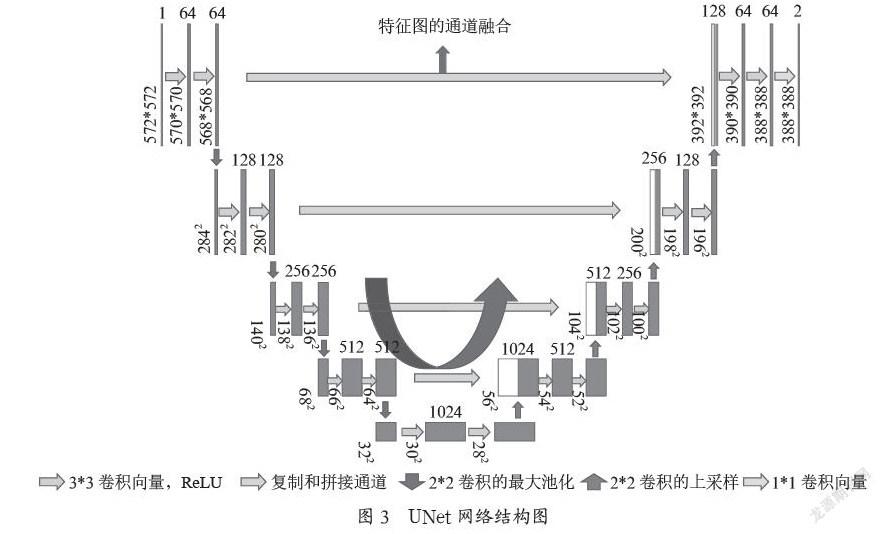
圖3就是UNet網(wǎng)絡的整個網(wǎng)絡結構圖,這個網(wǎng)絡的左半部分是由兩個3×3的卷積層和兩個最大池化層,步長為2組成的,激活函數(shù)是ReLU函數(shù)[5]。左邊結構每進行一次下采樣,通道數(shù)都會乘以2。這個網(wǎng)絡的右半部分是由一個2×2的上采樣卷積,激活函數(shù)是ReLU函數(shù)。右邊的網(wǎng)絡通道,是由左邊對應的特征圖通道和經(jīng)過上采樣得到的特征圖通道疊加的,最后得到的特征圖,有一半包含了左邊對應特征圖的信息。因為這個池化的方式是最大池化,所以一定程度上進行下采樣,都會損失了很多圖片中的信息。這里的通道融合的方式,能將淺層低維度的特征圖和在深層高維度的特征圖的信息進行融合,讓最終的特征圖中蘊含著更加豐富的圖片信息,讓圖像的預測更加的全面和準確。
1.4 ?劃分判別器和計數(shù)分類器
劃分判別器是用來判斷經(jīng)過特征通道融合的特征圖是否需要繼續(xù)進行上采樣操作。圖中F1的特征圖就是把64×64像素的原圖分為了四個子區(qū)間,每個子區(qū)間對應著16×16,但是它的感受野是整張原圖。如果這個子區(qū)間的人數(shù)大于10的話,則劃分判別器會讓該特征圖繼續(xù)進行步長為2的上采樣操作,直到子區(qū)間人數(shù)小于10為止[6]。劃分判別器由一個2×2的平均池化層(步長為2),一個512個通道的1×1卷積和一個1個1×1輸出卷積構成的,最后通過一個sigmoid函數(shù)輸出0或者1。
計數(shù)分類器是一個21個類別的訓練好的分類器,區(qū)間范圍是0到10,間隔是0.5。該分類器是Resnet50,通過對21個類別的2 000張圖片進行訓練得到的具有權重的模型。如圖2,F(xiàn)1特征圖所示,里面有4個區(qū)間,這4個子區(qū)間分別作為輸入,輸入給計數(shù)分類器進行預測。最后將四個子區(qū)間的預測結果相加,向下取整即為最終的輸出結果。
1.5 ?人流量統(tǒng)計算法的損失函數(shù)
這是人流量統(tǒng)計算法的損失函數(shù):,由兩個部分組合而成。左邊部分是多個交叉熵損失函數(shù),是用來監(jiān)督在對子區(qū)域人數(shù)統(tǒng)計的不同級別的分類問題。右邊部分是用來監(jiān)督最終劃分輸出的函數(shù)。該網(wǎng)絡可以支持多任務網(wǎng)絡的訓練方式,所以才有一個關于N次的求和[7]。
2 ?模型算法實驗
2.1 ?中國移動營業(yè)廳采集數(shù)據(jù)
歷時兩個星期,在廣州天府路中國移動營業(yè)廳用手機采集圖片。采集方式是在營業(yè)時間段,每隔半個小時在營業(yè)廳的各個角度采集若干張含有人群信息的圖片。然后總共采集了大概200張左右的有效圖片,人數(shù)范圍在10~70人左右。最后在網(wǎng)上開源的ShanghaiTech的數(shù)據(jù)集中融入了100張左右的圖片,組成了最后400張左右的數(shù)據(jù)集,部分圖片如圖4所示。
2.2 ?生成人群熱力圖的標簽方式
人群流量的標簽方式一般有兩種,一種是對人頭進行檢測框的標記,另外一種是直接對圖片生成熱力圖,如圖5所示。對于采集到的數(shù)據(jù)集,需要標記它們的真實標簽即圖片中的真實人數(shù)。標簽方式是生成人群熱力圖,然后人群流量統(tǒng)計就變成了對熱力圖的積分計算,甚至可以計算每平方米的人數(shù)和聚集程度,來判斷相應的需求[8]。原圖上的標注方式是,在人頭所在的像素點上標記一個紅點,然后再根據(jù)紅點生成相應的人群熱力圖[9]。
2.3 ?訓練網(wǎng)絡
本文采用深度神經(jīng)網(wǎng)絡的方法來預測中國移動營業(yè)廳的真實實時人數(shù)。采用將原圖區(qū)域進行劃分成若干個子區(qū)域,再在子區(qū)域進行預測人數(shù)的方式來預測真實人數(shù)。該方法訓練網(wǎng)絡的步驟如下:步驟一:數(shù)據(jù)預處理,對采集好的圖片進行降噪和除去黑白噪點的操作。使得圖片更加的平滑,過濾掉無效信息的圖片。步驟二:數(shù)據(jù)增強,因為采集的數(shù)據(jù)不是特別的充足,所以對圖片進行隨機裁剪和翻轉的操作增強數(shù)據(jù)集的數(shù)量。步驟三:根據(jù)標記好的紅點,生成每一張圖片的人群密度熱力圖。步驟四:模型訓練,把數(shù)據(jù)集按照8:1:1的比例,將數(shù)據(jù)集分為訓練集、驗證集和測試集。隨機初始化網(wǎng)絡中的所有參數(shù),batch size設置為64,把每一批的數(shù)據(jù)集喂給模型進行正向傳播和反向傳播進行參數(shù)的更新。訓練次數(shù)設置為100,最后選取訓練了至少50次的損失函數(shù)值最小的模型為最佳的訓練模型。
3 ?模型預測結果分析
3.1 ?中國移動營業(yè)廳數(shù)據(jù)集的標簽人數(shù)分布
從經(jīng)歷半個月左右的時間在中國移動營業(yè)廳收集到的數(shù)據(jù),圖6可見,營業(yè)廳大部分的人流數(shù)量集中在20人到60人。有時候比較繁忙的時候能達到100人左右。由于這種人數(shù),所以訓練分類網(wǎng)絡的時候,把子區(qū)域的人群計數(shù)分類定為了0-10人的范圍。
3.2 ?損失函數(shù)和預測效果評估
人流量統(tǒng)計模型的損失函數(shù)由分類的交叉熵損失和回歸函數(shù)共同組成,所以選用最小二乘法的梯度下降訓練方法。損失函數(shù)一般是用來測試訓練模型的時候真實值和預測值的差異的,一般來說損失函數(shù)的值越低,模型的預測效果越好。但是一般來說會選擇驗證集中,真實值和預測值最小的模型作為最終的模型參數(shù)輸出[10]。圖7就是訓練模型時候的損失函數(shù)和準確率。
在測試集中測試模型性能的方法是平均絕對誤差,即真實值和預測值的差值的絕對值和的平均值。平均絕對誤差的公式:[11]。在測試集上的結果是,平均絕對誤差:0.27即每次預測只差了0.27個人數(shù)的統(tǒng)計。結果的準確率(誤差少于1)為98.87%。從結果上來看,模型預測的準確度還是十分可觀的。而且模型在一秒鐘內(nèi)可以預測大概30張到40張的圖片,滿足的實時監(jiān)測的需求。
4 ?結 ?論
本文提出一種基于分治策略,將原圖分割成若干個子區(qū)域進行區(qū)域計數(shù)的人流量統(tǒng)計的深度神經(jīng)網(wǎng)絡模型。該網(wǎng)絡模型參考了傳統(tǒng)神經(jīng)網(wǎng)絡VGG16作為特征提取的主干網(wǎng)絡和UNet網(wǎng)絡作為解碼器。在測試和預測真實的中國移動營業(yè)廳時,模型的人數(shù)準確率基本保障不會出現(xiàn)錯誤而且能達到實時更新營業(yè)廳人數(shù)的效果。這很好的滿足的讓營業(yè)廳的營業(yè)員精準定位服務,而且能讓客戶根據(jù)每個營業(yè)廳的實時人數(shù)來選擇人數(shù)更少的營業(yè)廳辦理業(yè)務。在疫情管控營業(yè)廳的實時人數(shù)時,可以起到監(jiān)督和監(jiān)控的作用。
參考文獻:
[1] 中國移動.營運數(shù)據(jù) [EB/OL].[2021-09-25].https://www.chinamobileltd.com/sc/ir/operation_q.php.
[2] SAM D B,SAJJAN N N,BABU R V,et al. Divide and Grow:Capturing Huge Diversity in Crowd Images with Incrementally Growing CNN [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.IEEE:Salt Lake City,2018:3618-3626.
[3] BADRINARAYANAN V,KENDALL A,CIPOLLA R. SegNet:A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation [J/OL].arXiv:1511.00561 [cs.CV].(2015-11-02).https://arxiv.org/abs/1511.00561.
[4] HE K M,ZHANG X Y,REN S Q,et al. Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification [J/OL].arXiv:1502.01852 [cs.CV].(2015-02-06).https://arxiv.org/abs/1502.01852.
[5] SIMONYAN K,ZISSERMAN A. Very Deep Convolutional Networks for Large-Scale Image Recognition [J/OL].arXiv:1409.1556 [cs.CV].(2014-09-04).https://arxiv.org/abs/1409.1556.
[6] LEMPITSKY C,ZISSERMAN A. Learning To count objects in images [C]//NIPS10:Proceedings of the 23rd International Conference on Neural Information Processing Systems.Red Hook:Curran Associates,2010:1324-1332.
[7] LI R B,XIAN K,SHEN C H,et al. Deep attention-based classification network for robust depth prediction [J/OL].arXiv:1807.03959 [cs.CV].(2018-07-11).https://arxiv.org/abs/1807.03959.
[8] NIU Z X,ZHOU M,WANG L,et al. Ordinal Regression with Multiple Output CNN for Age Estimation [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:4920-4928.
[9] GIRSHICK R. Fast R-CNN [C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago:IEEE,2015:1440-1448.
[10] IDREES H,TAYYAB M,ATHREY K,et al. Composition Loss for Counting,Density Map Estimation and Localization in Dense Crowds [J/OL].arXiv:1808.01050 [cs.CV].(2018-08-02).https://arxiv.org/abs/1808.01050.
[11] MASKA M,ULMAN V,SVOBODA D,et al. A benchmark for comparison of cell tracking algorithms [J].Bioinformatics,2014,30(11):1609-1617.
作者簡介:陳樂(1982—),男,漢族,重慶人,項目總監(jiān),碩士研究生,研究方向:AIOps、業(yè)務支撐系統(tǒng)運營支撐;丁戈(1995—),男,漢族,廣東廣州人,項目經(jīng)理,碩士研究生,研究方向:AIOps算法;肖忠良(1986—),男,漢族,廣東廣州人,項目經(jīng)理,碩士研究生,研究方向:AIOps、業(yè)務支撐系統(tǒng)運營支撐。
