海平面聚類算法
2021-06-05 06:37:28馬杰,楊磊,徐建
智能計算機與應用 2021年4期
馬 杰,楊 磊,徐 建
(1江蘇師范大學 智慧教育學院(計算機科學與技術學院),江蘇 徐州221116;2中國礦業大學徐海學院 計算機系,江蘇 徐州221008)
0 引 言
本文算法不是一個獨立的聚類算法,是用來輔助其它聚類算法更好、更有效地聚類的輔助算法。與其它聚類算法結合使用,能有效地改善聚類算法的聚類效果。
1 問題的提出
有些算法聚類的結果與自然分類有出入,有些算法對某些情況不能正確的分類。比如:Affinity Propagation(AP)聚類算法,是基于數據點間的“信息傳遞”的一種聚類算法。算法的基本思想是:將全部樣本看作網絡節點,通過網絡中各條邊的消息傳遞 計算出各樣本的聚類中心。聚類過程中,共有兩種消息在各節點間傳遞,分別是吸引度(responsibility)和歸屬度(availability)。通過在點之間不斷地傳遞信息,最終選出代表元以完成聚類。AP算法通過迭代過程不斷更新每一個點的吸引度和歸屬度值,直到產生m個高質量的Exemplar(類似于質心),同時將其余的數據點分配到相應的聚類中。其特點如下:
(1)不需要制定最終聚類個數。
(2)將已有數據點作為最終的聚類中心,而不是新生成聚類中心。
(3)模型對數據的初始值不敏感,多次執行AP聚類算法,得到的結果是完全一樣的,即不需要進行隨機選取初值步驟。
(4)對初始相似度矩陣數據的對稱性沒有要求。
(5)與k中心聚類方法相比,其結果的平方差誤差較小,相比于K-means算法,魯棒性強、準確度較高,但算法復雜度高、運算消耗時間多。
在實際的使用中,AP有兩個重要參數:preference(定義聚類數量)和damping factor(控制算法的收斂效果)。
聚類就是個不斷迭代的過程,迭代的過程主要是更新兩個矩陣:
吸引度矩陣R:[r(i,k)]N×N
歸屬度矩陣A:[a(i,k)]N×N
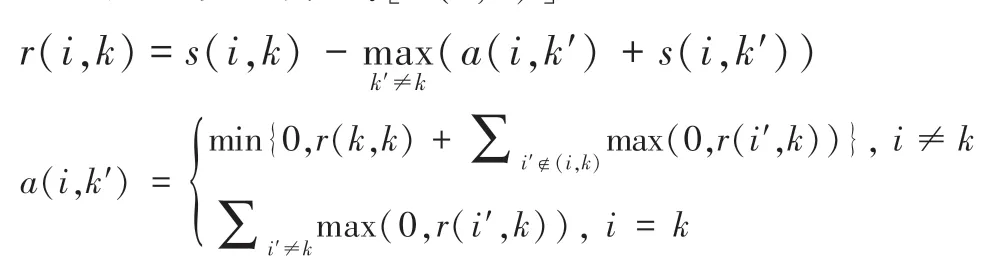
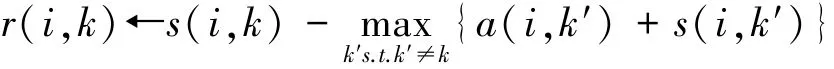
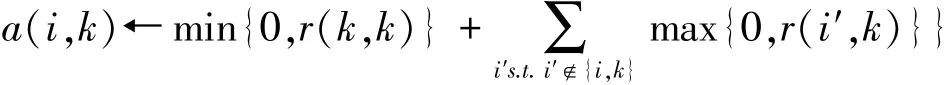
在不斷交替更新a和r值,達到一定的次數或收斂后,選取使得r(i,k)+a(i,k)最大的那個k作為i的代表元。其中s(i,k)表示similarity,可以翻譯為相似度或度量。是指點k作為點i的聚類中心的相似度,一般使用歐氏距離來計算。相似度值越大說明點與點的距離越近,這在幾乎所有的聚類分析中都是最基礎的量。
AP算法(參見參考文獻[1])是一個很好的聚類算法。但當有大類靠近小類時,往往會把大類的一些邊緣點錯分給小類。如對圖1中的數據,其AP算法的聚類結果如圖2所示。顯然,沒有分成左邊兩個小類,右邊一個大類。而是小類占了大類的幾個點。另外,還有一些算法(本文選定一種密度算法,本文稱MD算法)對有些數據不能正確的分開。如圖3的數據,右邊兩類中間有兩行點連接在一起,很多聚類算法就無法將這兩類分開。

圖1 AP算法數據準備 Fig.1 AP algorithm data preparation
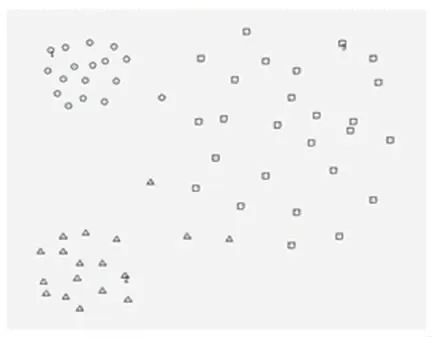
圖2 AP算法分類結果Fig.2 AP algorithm classificationresults
2 問題分析
由上述分析可以看出,問題都出在類的邊緣點上。AP算法的問題是大類的幾個邊緣點離大類的中心點過遠,而離靠近其小類中心點更近。另外一些算法無法將圖3右邊兩個類分開,是因為靠近兩個類的共同邊緣的點連接在了一起。

圖3 MD算法數據準備Fig.3 MD algorithm data preparation
3 解決方法
如果能把這些出問題的邊緣點先0拿掉(拿掉的點最后還要歸類到分好的類中)再進行分類,就不會有上面的問題了。那么,一個問題是解決如何區分邊緣點,其二是如何將拿掉的點歸類。
首先,對每個點定義一個密度函數,使得類的邊緣點的密度小,越靠近中心的點密度越大,這樣就解決了第一個問題。再定義每個點的歸屬點為離此點最近的密度大于自己的點,這樣第二個問題就解決了。判斷邊緣點時,不是直接用密度函數的密度值判斷,而是用傳導歸屬點數(既A點到其歸屬點B點,B點再到其歸屬點C點,等等,一直傳導下去所經歷的點叫A點的傳導歸屬點,這個過程叫傳導歸屬。而傳導歸屬數是所有能傳導歸屬到此點的點的個數),傳導歸屬點數越小越邊緣,反之越中心。引進一個參數k,傳導歸屬數小于其則為邊緣點。先剔除邊緣點,然后根據某聚類算法聚類,最后將邊緣點傳導歸屬到已分好的類中。
本文定義密度函數:
(1)此點密度為,此點到所有點的距離的倒數之和。
(2)數據的個數為n,每一點為其它各點打分。離此點最遠的點得1分,次遠點得2分,以此類推。最近的點得n-1分。定義每個點得密度為此點得分的總和。
第一個密度函數要求數據先要剔除相同的數據點。
4 應用效果
本算法與AP算法結合(以下密度函數均選擇第一種),采用聚類圖1的數據,選擇K為2,邊緣點如圖4所示(方形空心為邊緣點),聚類結果如圖5所示。本文算法與MD算法結合,采用聚類圖3的數據,選擇k為3,邊緣點如圖6所示(圓形空心為邊緣點),聚類結果如圖7所示。
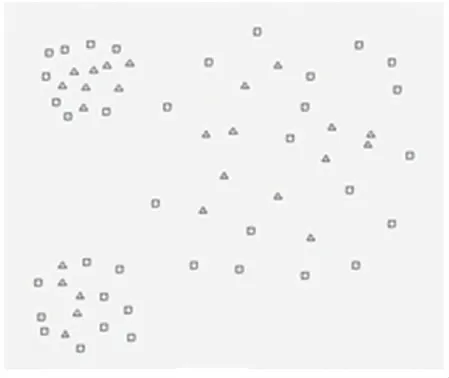
圖4 AP算法結合海平面算法的邊緣圖Fig.4 Edge map of AP algorithm combined with sea level algorithm
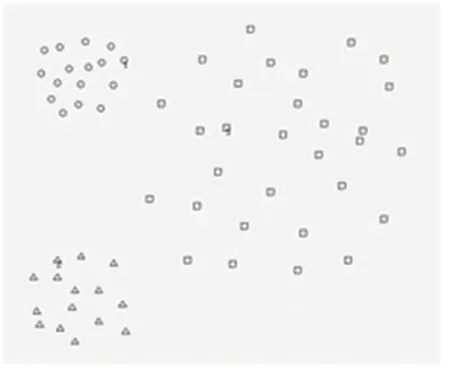
圖5 AP算法結合海平面算法結果Fig.5 Results of AP algorithm combined with sea level algorithm

圖6 MD算法結合海平面算法的邊緣圖Fig.6 Edge map of MD algorithm combined with sea level algorithm

圖7 MD算法結合海平面算法的結果圖Fig.7 Result chart of MD algorithm combined with sea level algorithm
5 結束語
本算法之所以叫海平面聚類算法,是因為k參數相當于設置海平面,邊緣點都淹沒在海水里,只對陸地進行聚類,因此得名。本算法與其它聚類算法結合可以明顯改善聚類結果,經實驗證明,本算法是有效的。
