基于BCP 的聯合委托學習模型及協議
2021-06-04 14:21:54高勝向康田有亮譚偉杰馮濤吳曉雪
通信學報 2021年5期
高勝,向康,田有亮,譚偉杰,馮濤,吳曉雪
(1.貴州大學計算機科學與技術學院公共大數據國家重點實驗室,貴州 貴陽 550025;2.中央財經大學信息學院,北京 100081;3.貴州大學密碼學與數據安全研究所,貴州 貴陽 550025;4.蘭州理工大學計算機與通信學院,甘肅 蘭州 730050;5.貴州省計量測試院,貴州 貴陽 550000)
1 引言
機器學習等相關技術的發展使大數據中的有利信息得以被挖掘和利用。在實際生活中,數據的分布并不是只存在于一個數據站點,而是多樣化地分布于多個數據站點。因此,數據共享[1-2]已成為數據挖掘等相關領域的研究熱點,而數據隱私泄露等安全問題是數據共享技術中的發展瓶頸。傳統的基于安全多方計算(SMC,secure multi-party computation)[3-4]的解決方案效率低下且可行性較差,無法真正實現對大數據[5]的處理。
在實際的數據特征學習過程中,對數據進行較復雜的分析、模型構造以及優化通常是比較困難的,導致客戶端背負著沉重的計算成本。甚至部分企業或用戶由于受限于自身對數據處理的能力而無法挖掘出有用的信息,只能依托于云服務[6-7]提供商進行特征提取和模型訓練。因此,基于傳統的委托計算思想引出數據多點分布時的數據外包挖掘方法具有重要的實際應用價值。本文將這種數據外包挖掘的方式命名為聯合委托學習,如圖1 所示。
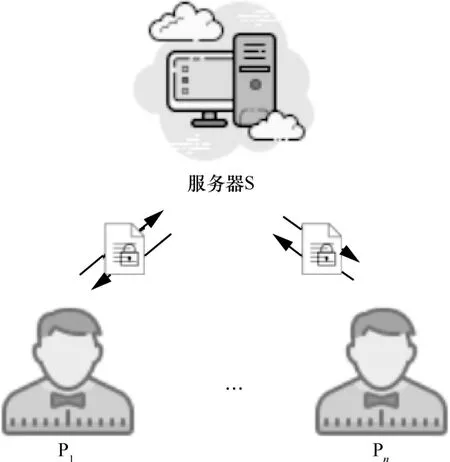
圖1 聯合委托學習
在數據多點分布時進行聯合委托學習需要考慮以下需求。
1) 在數據共享中,不僅要避免用戶隱私數據的泄露,而且必須保證加密后的數據滿足數據挖掘的條件。
2) 避免服務器從計算的中間結果推測出最終構建的模型信息。
3) 盡量將計算任務委托給云服務提供商,以降低客戶端的計算成本。
1.1 本文的貢獻
針對聯合委托學習中的安全性需求,本文的主要貢獻如下。
1) 基于傳統的委托計算思想提出了一種聯合委托學習模型,并針對決策樹的構造設計了一種基于虛假記錄的隱私保護方法(FRPPM,false-based records privacy protection method),該方法利用少量的虛假記錄擾亂最終構建的模型結構,增強了數據和模型結構的安全性。
2) 基于BCP(Bresson,Catalano,Pointcheval)同態加密算法分別設計了隱私保護委托點積算法(PPDDPA,privacy preserving delegation dot product algorithm)和隱私保護委托求熵算法(PPDEA,privacy preserving delegation entropy algorithm),降低了客戶端的隱私數據在數據共享中的泄露風險。
3) 針對數據垂直和水平分布的情況,根據上述2 種算法分別提出了對應的委托學習協議,降低了客戶端在數據挖掘中的計算成本。
1.2 相關工作
隱私保護數據挖掘技術[8-9]可分為基于數據擾動的方法和基于安全多方計算的方法。基于數據擾動方面,Agrawal 等[10]提出了用加入隨機噪聲的方法來進行隱私保護決策樹挖掘的方案。但此種加入隨機噪聲的方法過于簡單,Kargupta 等[11-12]對加入隨機噪聲方法的安全性提出了質疑,并基于隨機矩陣理論提出了從擾動后的數據估計真實數據的方法。Bu 等[13]給出了一種基于函數擾動的方法,該方法采用反函數變換方式來將擾動數據上的虛假決策樹還原為真實數據上的決策樹。
基于安全多方計算方面,Hamada 等[14]及Bost等[15]分別研究了可以應用于SMC 中的決策樹分類算法,在SMC 中向各參與方隱藏了輸入向量,但有關決策樹的信息被假定對各方公開。其中,Bost等[15]研究了使用同態加密通過決策樹對信息進行安全分類的方法。隨后,Wu 等[16]及Backes 等[17]各自將其擴展為一個隨機森林。此外,在與本文的工作相似的研究中,Ichikawa 等[18]提出了一種新穎的安全多方協議,同樣隱藏了輸入向量和輸出類以及樹的結構。Zheng 等[19]及Li 等[20]分別設計了基于云服務器的分類模型,可以保護樹模型和客戶數據隱的分類模型提高了系統的可伸縮性。特別地,Li 等[22]私。另外,Liu等[21]在此基礎上設計了支持離線服務針對數據的水平和垂直分布分別設計了外包隱私保護加權平均協議(OPPWAP,outsourced privacy preserving weighted average protocol)和外包安全集交叉協議(OSSIP,outsourced secure set intersection protocol),但不能保護訓練模型結構的安全性。
2 預備知識
2.1 BCP 同態加密
BCP 同態加密算法是由Bresson、Catalano 和Pointcheval 于2003 年提出的,屬于同態密碼體制,具有以下性質。
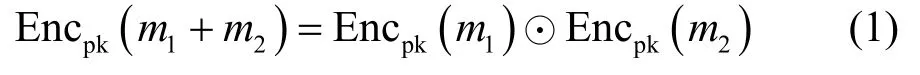
其中,m1和m2表示明文信息,⊙表示在同一公鑰下加密域中的算術乘法運算。BCP 同態加密算法的形式化描述包括以下4 個部分。
1) Setup(λ)。首先給定安全參數λ表示模數N的位長,再選定2 個不同的素數p'和q'分別計算p=2p'+1,q=2q'+1以及N=pq;隨后選擇表示在2[1,N]中所有與N2互質的數),并使最后得到公共參數pp=(N,k,g),主 密 鑰
3) Encpk(m)。明文m∈ZN,選擇隨機數,利用公鑰加密得到密文(A,B),其中A=grmodN2,B=gtr(1+mN)modN2。
4) Decsk(A,B)。利用私鑰sk=t解密,獲得明文。
2.2 數據的分布形式
通常數據的分布類型包括2 種情況:水平分布類型,即每個站點僅包含一部分元組,但每個元組都是完整的;垂直分布類型,即各個站點包含所有元組,但每個元組都不是完整的,僅包含一部分屬性。如表1 中前14 條記錄所示,為方便敘述,此處假設數據分布在站點P1和P2處。數據水平分布時,站點P1和P2分別包含部分完整的記錄,同時各站點都知道數據所對應的屬性名稱,即表1 中的第二行信息,但各個站點對其他站點所包含的具體數據一無所知。數據垂直分布時,站點P1和P2都包含所有記錄,但每條記錄都是不完整的,對于所有特征屬性而言站點P1只包含前2 個屬性的數據,站點P2只包含后2 個屬性的數據,但它們都包含標簽項數據,即表1 中的最后一列信息,同樣各個站點不愿意對其他站點透露自己所包含的具體數據。
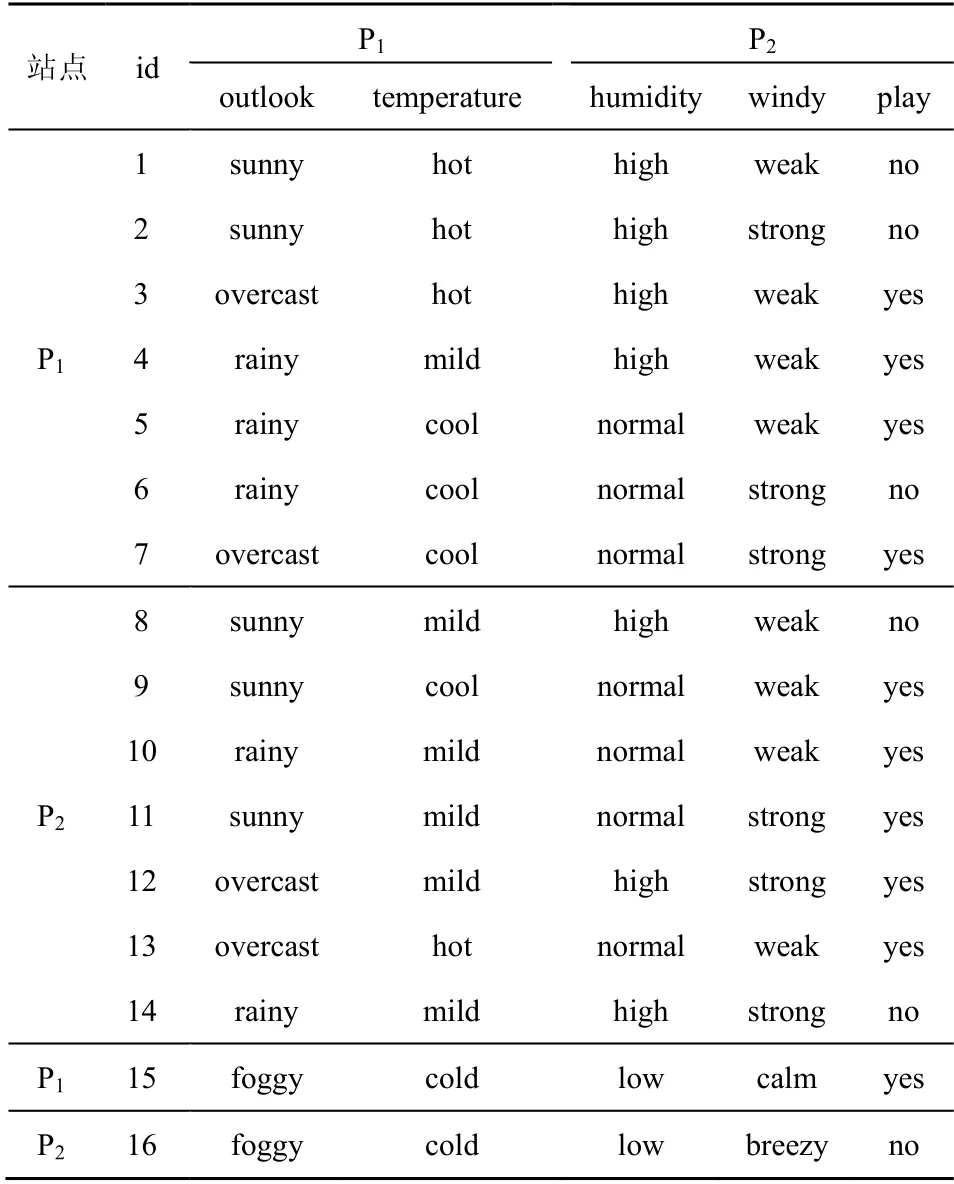
表1 數據集的分布形式
3 聯合委托學習模型
3.1 系統模型
聯合委托學習的系統模型框架如圖2 所示,系統模型包含2 個服務器和n個客戶端(用戶),并且相互之間采用安全信道連接。其中 S1是主服務器,S2是副服務器,分別由不同的服務提供商提供。首先,由 S2生成公共參數并發送給各客戶端,客戶端根據公共參數計算出各自的公私鑰對。其次,客戶端根據FRPPM 對各自的私有數據集進行擾動處理,并利用各自的公鑰對擾動后的數據統計信息進行加密。然后,將A、B這2 類密文分別發送給 S2和 S1進行計算,并由 S1綜合計算后返回結果。最后,各客戶端根據返回的結果構建同樣的決策樹模型。需要注意的是,無論數據垂直分布還是水平分布,本文在模型的構建過程中都以ID3[23]算法為例。為方便后續描述,假設總體數據集D分布在n個客戶端處,即D=D1∪D2∪…∪Dn,并且共有t條記錄、d個屬性和一個分類標簽項C,其中屬性集a={a1,a2,…,ad},且各屬性有U個可能的取值
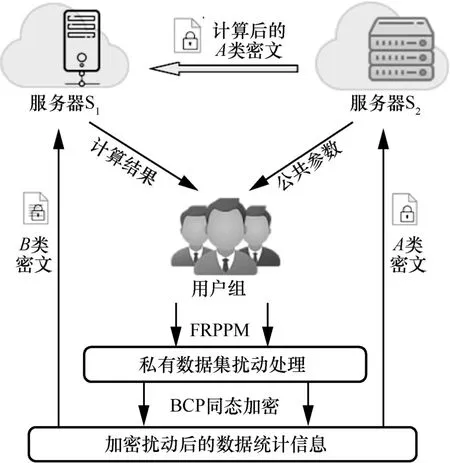
圖2 聯合委托學習的系統模型框架
3.2 安全模型
假設所有的參與者和服務器都是半誠實的并且不存在共謀行為,即服務器會認真完成客戶端的計算任務但對計算結果好奇,客戶端會誠實地提供自己的密文數據但同樣好奇其他客戶端的數據,并且服務器不具備數據集屬性名及其取值類別信息等先驗知識。
模型假設每個客戶端都有私有數據對(xi,yi),其中i=(1,2,…,n),客戶端之間不愿透露數據真實值但又希望利用其他人的數據計算最終結果R。
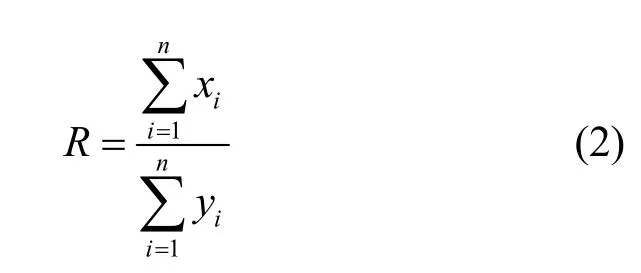
初始化階段。由服務器 S2生成公共參數pp=(N,k,g)并分發給每一個客戶端。各客戶端選擇隨機數生成各自的公鑰pki和私鑰ski,即
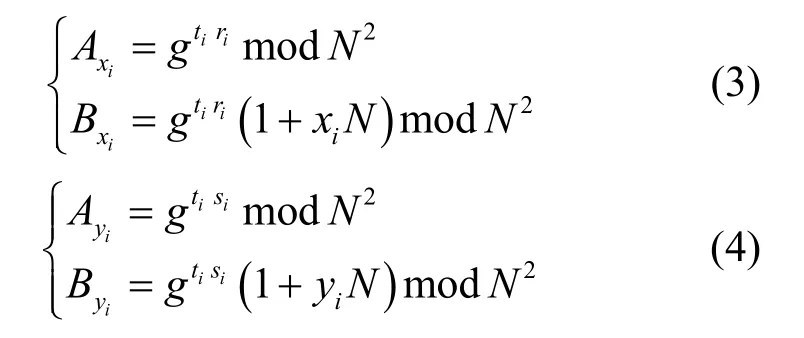

輸出階段。服務器 S1將最終計算結果R返回給每一個客戶端。
4 基于虛假記錄的隱私保護方法
本節針對決策樹的構造提出了一種新的隱私保護方法。該方法類似于數據擾動的方法,但與之不同的是客戶端不在原始數據中做擾動操作,而是添加完整的虛假記錄來達到擾動效果。
以表1 中的數據為例,前14 條記錄是真實的數據,最后2 條是添加的虛假記錄。換句話說,在原始數據屬性outlook 的取值情況中并沒有foggy類型,同樣其他屬性也都沒有對應的cold、low、calm以及breezy 的取值類型。簡而言之,最后2 條記錄是虛構的,其目的在于通過添加虛假記錄的方式來生成干擾樹枝,使服務器無法辨認決策樹分支的真實性。
以ID3 算法為例,表1 中的數據可以生成如圖3所示的決策樹T'。

圖3 具有干擾分支的決策樹T '
圖3 中,虛線框中的分支就是生成的干擾分支,當所有節點以及分支信息處于加密狀態時,服務器是很難猜測或分辨分支的真實性的,而客戶端解密后通過后剪枝的方式剪掉虛假的分支可以輕松獲得真實決策樹T。
在添加虛假記錄進行擾動時,有以下兩點是需要注意的。
1) 由于ID3 算法的核心是以屬性的信息增益大小來確定決策樹各節點的劃分屬性的,因此,在添加虛假記錄后要保證真實數據中原本信息增益最高的屬性仍保持最高。例如,在表1 的真實數據中,屬性outlook 的信息增益最大,當加入虛假記錄后仍要保證屬性outlook 的信息增益最大,否則就破壞了真實決策樹的結構,根節點不再是屬性outlook,也就是說,降低了決策樹模型的分類精度。
2) 添加虛假記錄的方法在提高安全的同時,也由于增加虛假數據集D'導致挖掘計算量增大。因此本文限定添加的虛假數據集為原真實數據集的2%~15%,當增加的計算量在可接受的范圍內時,客戶端應盡量增加更多根節點可能取值的虛假類別以提高決策樹的安全性,這一點將在后續的安全性分析章節進行具體介紹。另外,n個客戶端在聯合委托學習之前可以通過協商確定添加的虛假數據集D'或由某一個客戶端設定虛假數據集分發給其他客戶端。當數據垂直分布時,各客戶端也應將數據集D'垂直分割,因此各客戶端添加的記錄數為|D'|;當數據水平分布時,則每個客戶端添加的數據量為
5 聯合委托學習協議
根據第3 節和第4 節提出的聯合委托學習模型及基于虛假記錄的隱私保護方法,可以設計以下數據在不同分布形式時的委托學習協議。
5.1 數據垂直分布的委托學習協議
當數據垂直分布時,各客戶端雖然包含的記錄信息不完整,但可以使用布爾化向量表示數據在各屬性上的取值情況。例如,在表1 中,P1使用向量表示所有記錄在屬性 outlook 上取值為sunny 的情況
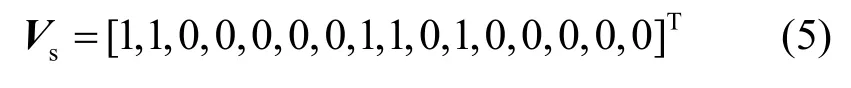
其中,“1”表示該記錄在屬性outlook 上取值為sunny,“0”表示取其他值。同理,P2可以表示所有記錄在屬性humidity 上取值為high 的情況
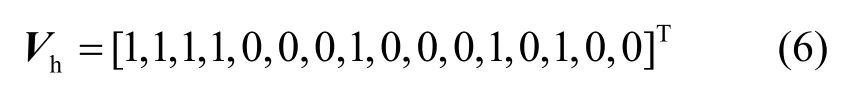
盡管P1和P2之間都不愿透露各自的數據信息,但可以通過向量點積來獲得同時滿足在屬性outlook 和humidity 上分別取值為sunny 和high 的記錄數。其中,求解點積的過程可以看作第3.2 節安全模型中假設的一部分,如
根據以上描述,各客戶端可以將各自的私有向量加密后發送給服務器,由服務器代理進行點積運算,具體如算法1 所示。
算法1隱私保護委托點積算法
輸入每個客戶端分別輸入各自(t+|D'|)維的隱私向量Vi
輸出結果R
1) 服務器 S2采用BCP 同態加密算法生成公共參數pp 并分發給各客戶端。
3) 各客戶端利用各自的公鑰對向量Vi中每一個元素進行加密,得到密文向量對并將分別發送給服務器 S2和 S1。
4) 服務器 S2接收到各方發送的向量后做如下計算。
令j=1,中的第
j個元素vi,j計算,將vj加入向量VA中,j=j+1},最后將向量VA發送給服務器 S1。
5) 服務器 S1接收到各客戶端及服務器 S2發送的向量后做如下計算。
令j=1,R=0,while(j≤t+|D'|) do {取及VA中第j個元素vi,j及vj計算
if(m≤ 1)令m=0,else 令m=1,R=R+m,
j=j+1}
6) 服務器 S1將結果R返回給各客戶端。
根據上述算法,可以設計數據垂直分布時的聯合委托學習協議,具體介紹如下。
1) 各客戶端利用自身的數據計算出數據集D的信息熵

其中,K表示數據集D中分類標簽項可能取值的類別數,pk表示第k個類別的樣本所占的比例,k={1,2,…,K}。
2) 各客戶端計算出各自所具有的屬性信息增益大小,以此來共同確定信息增益最大的屬性并作為決策樹的根節點。

其中,Du表示在第u個分支中包含的D中所有在屬性ai上取值為的樣本集,u={1,2,…,U}。
3) 各客戶端共同協商決定添加虛假記錄的數量以及虛假數據的具體值,并將數據集D和D'布爾化,用布爾型向量表示所有記錄在某一個屬性上的取值情況。
4) 由當前劃分(只有一個節點時指根節點)屬性所屬的客戶端計算出各分支的信息熵并發送給其他客戶端。若某分支的信息熵為零,則直接標記該分支為葉子節點,否則共同委托服務器計算該分支的其他信息,以便選取該分支的劃分屬性。
5) 各客戶端將各自的私有向量加密后發送給服務器,并由服務器返回計算結果。
6) 各客戶端根據結果R計算出各屬性的信息增益并確定信息增益最大的屬性為該分支節點。再返回到步驟4),以類似的方式遞歸地構造樹的其他節點。
下面,以表1 中的數據為例,說明上述協議的具體執行過程。
1) 由于站點P1和P2都擁有標簽項數據和不完整的記錄數據,因此各客戶端可以利用自身的數據計算出數據集D的信息熵
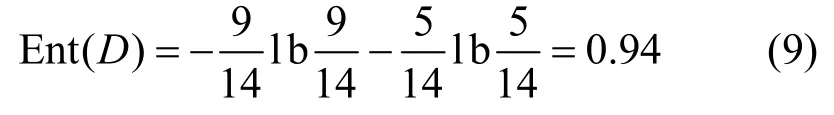
2) 站點P1和P2也可以計算出各自所具有的屬性信息增益大小,并發布給其他客戶端。

因此選擇屬性outlook 為根節點。
3) 雖然P1和P2可以在不透露具體數據的情況下共同確定根節點,但余下的所有分支節點必須利用整個數據集信息計算才能確定。因此在確定根節點后,P1和P2需要將各自數據的統計信息委托給服務器進行整合計算,為了保證數據以及模型的安全,首先P1和P2需要共同協商決定添加虛假記錄并將數據集布爾化。
4) 由P1計算outlook 屬性劃分的4 個分支的信息熵,其中包括foggy 分支。例如,式(12)計算的sunny 分支不為零,因此該分支下的節點為非葉子節點。
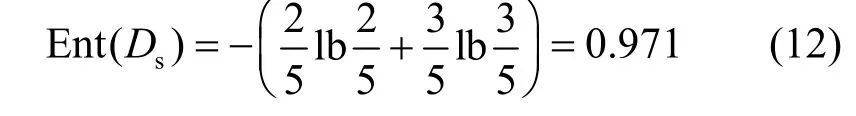
P1將Ent(Ds)發送給P2,并聯合P2將各自數據的統計信息發送給服務器計算其余3 個屬性在該分支下的信息增益情況。例如計算humidity 屬性的信息增益值。用Ds_h和Ds_n分別表示當屬性outlook 取sunny、屬性humidity 取high 和normal時的樣本集,則

其中,Ds_h_y和Ds_h_n分別表示當屬性outlook 及humidity 取值為sunny 和high 時,標簽項play 取值為yes 和no 的樣本集。同理,Ds_n_y和Ds_n_n也分別表示對應的樣本集。
5) 在計算各屬性的信息增益過程中,各站點需要知道當前分支的樣本數等數據信息,但由于各站點之間不愿透露自己的數據樣本信息,因此通過第三方服務器進行代理計算。例如,若站點P2想要知道在sunny 分支中的樣本數,則可以聯合站點P1分別將向量V和Vs加密后發送給服務器,讓其代理計算出在sunny 分支中的樣本數|Ds|=Vs?V,并返回給站點P2。其中,向量V是(t+|D'|)維的通用向量,其所有元素都為1。
類似地,站點P1使用向量
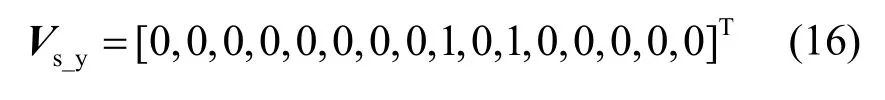
表示所有記錄在屬性outlook 及標簽項play 上的取值情況,其中“1”表示該條記錄同時滿足在屬性outlook 及標簽項play 上分別取值為sunny 和yes,“0”表示不滿足。同理,向量Vs_n表示所有記錄在屬性outlook 及標簽項上分別取值sunny 和no 的情況。在站點P2的數據中,向量Vh表示所有記錄在humidity 屬性上取值為high 的情況,向量Vn表示所有記錄在humidity 屬性上取值為normal 的情況。站點P1和P2分別將

加密后發送給服務器,可以得到對應的計算結果。
6) 站點P1和P2收到服務器返回的結果后,各自可以計算出相同的humidity 屬性信息增益數據。再返回到步驟4),以相同的方式,站點P1和P2可以計算出余下2 個屬性的信息增益大小,并選擇信息增益最大的屬性作為sunny 分支下的劃分節點。以類似的方式遞歸地構造樹的其他節點,最后站點P1和P2都可以構造出圖3 中完整的決策樹T',經過剪掉虛假的分支后獲得真正的決策樹T。
5.2 數據水平分布的委托學習協議
與數據垂直分布的情況不同,數據水平分布時各客戶端無法根據自身的數據計算出總體數據的信息熵和各屬性的信息增益,只能委托服務器作為中間節點進行代理計算。
根據式(7)可以看出,計算總體數據的信息熵需要各客戶端提供各自數據的統計信息,即
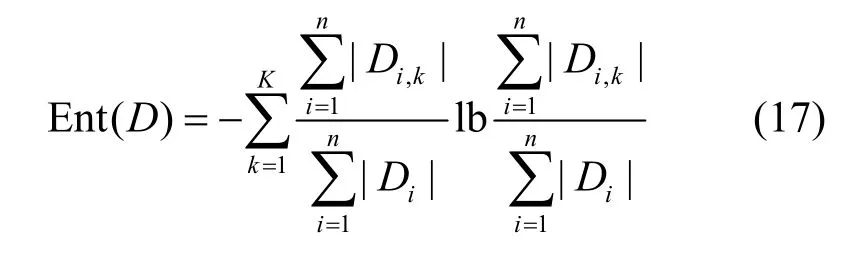
其中,Di,k表示在第i個客戶端的數據中屬于第k類樣本的數據集。式(17)同樣可以看作第3.2 節中安全模型的假設形式
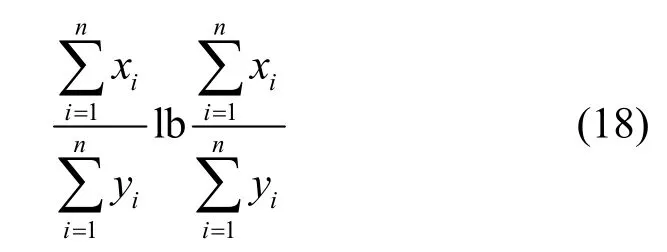
假設各客戶端使用向量
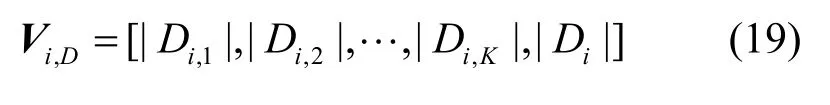
表示該客戶端的數據所屬類別的統計信息,其中,|Di|表示該客戶端具有的數據量;使用向量

下面,給出多個客戶端委托服務器代理計算的具體算法,如算法2 所示。
算法2隱私保護委托求熵算法
輸入每個客戶端{Pi|1≤i≤n}分別輸入各自的隱私向量Vi,D、Vi,j以及向量組
輸出以第j個屬性劃分的信息增益Gain(D,aj)


根據算法2,可以設計如下數據水平分布的聯合委托學習協議。
1) 各客戶端以向量的形式表示自身數據所屬類別信息。經過各自公鑰加密后將A、B兩類密文分別發送給服務器 S2和 S1,計算得到整體數據集(或分支包含的子數據集)的信息熵。
2) 類似地,各客戶端以向量Vi,j和的形式表示數據在第j個屬性上的取值情況。通過委托服務器進行代理計算,可以獲得所有屬性的信息增益數據,將信息增益最大的屬性作為節點(當前沒有節點時作為根節點)屬性。
3) 確定根節點后,各客戶端協商確定添加虛假記錄的數量|D'|及具體數據值,并且每一個客戶端添加的虛假記錄數都為
4) 返回執行步驟1),客戶端采用同樣的方式發送虛假的統計信息委托服務器計算根節點下各分支的信息熵。若某分支的信息熵為零,即表示該分支所包含的樣本屬于同一類別,則客戶端直接標記該分支為此類別的葉子節點。否則執行步驟2),委托服務器計算出該分支下的所有屬性信息增益,選擇信息增益最大的屬性作為該分支的節點屬性。
5) 反復執行步驟1)和步驟2),以類似的方式遞歸地構造樹的其他節點。
6 安全性及性能分析
6.1 安全性分析
本節從客戶端的數據與最終構建的決策樹模型2 個方面分析本文所提出的隱私保護委托算法和學習協議的安全性。
1) 當服務器 S2不能同時獲得數據的密文A和B時,客戶端的數據是安全的。
證明服務器 S2利用主密鑰MK=(p',q')解密的過程如下。
①利用客戶端的公鑰計算出對應的私鑰。
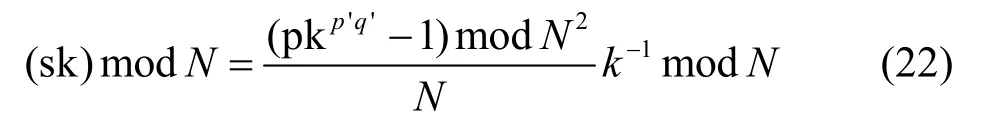
其中,k?1表示k模N的逆。
②利用密文A計算出客戶端在加密過程中選擇的隨機數r。

③令δ表 示p'q'模N的 逆,并 且γ=(sk ?r)modN,則明文為
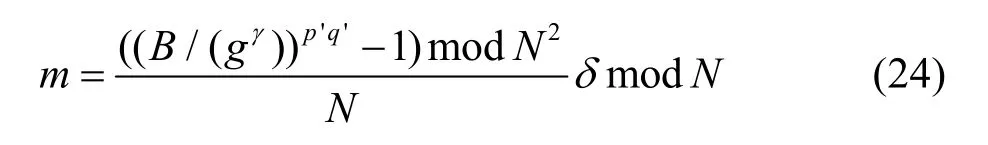
從上述解密過程可以看出,當服務器 S2利用主密鑰解密時,必須同時具有密文(A,B)才能獲得明文m,但在本文所設計的安全模型中,各客戶端是將其密文A和B分別發送給不同的服務器做求和運算,并最終由服務器 S1計算出構建決策樹模型的中間結果。因此當服務器 S1和 S2之間不存在共謀行為時,任何一個服務器都不會具備解密數據的基本條件。綜上所述,客戶端的數據是安全的。
2) 當數據集的屬性個數d等基本參數足夠大時,最終構建的決策樹模型是安全的,即服務器不能從中間結果推測出真正的模型。
證明在數據垂直分布的情況中,隱私保護委托點積算法只要求服務器對布爾化后的向量做內積運算,因此服務器并不了解數據的真實意義和計算目的,所以,很難猜測出有關決策樹模型的任何信息。而在數據水平分布的情況中,服務器 S1根據計算信息熵和信息增益的結果,可以構造出如圖4所示的空模型框架。

圖4 決策樹空模型框架
為方便描述,假設客戶端在添加虛假記錄的過程中,將根節點屬性的取值類別增加了l個可能的虛假取值,并且最終構建的決策樹模型有e個非葉子節點、f個中間葉子節點和h個底層葉子節點。首先,服務器能夠正確匹配所有非葉子節點對應的節點屬性的概率可以表示為
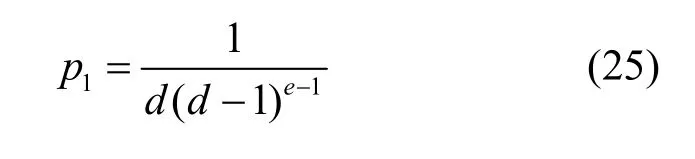
其次,服務器能正確匹配所有葉子節點對應的類別信息的概率可表示為


最后,服務器能正確剪掉虛假分支的概率可以表示為

因此,服務器能正確獲得完整的決策樹模型的概率為
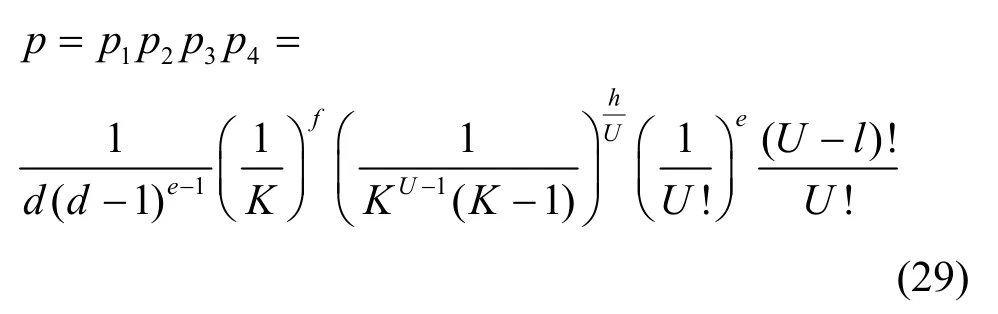
根據式(29)可知,當數據集的屬性個數d等基本參數以及根節點屬性可能的虛假取值數l足夠大時,服務器能猜測模型的概率p是可以忽略的,同時也說明了當增加虛假記錄的數量在可接受的范圍時,l的值越大越能提高模型的安全性。
另外,值得注意的是,上述服務器能夠正確獲得完整決策樹的概率p是基于服務器了解數據集基本信息的情況下才成立的。即只有當服務器知道該數據集有哪些具體的屬性名及各屬性可能的取值時,才能了解該數據集的用途并對模型框架進行匹配和猜測。然而在本文提出的算法中,客戶端并未透露任何關于數據集的基本信息,因此進一步降低了服務器根據中間計算結果對模型進行推測的概率。
綜上所述,本文提出的聯合委托學習協議構建的決策樹模型是安全的。
6.2 性能分析
本節通過對比客戶端與服務器的時間開銷來評估本文所提出的算法和協議的性能。實驗測試中使用Python 實現了PPDDPA 和PPDEA,建立了安全參數λ為1 024 的BCP 密碼系統,并在Ubuntu 18.04(CPU主頻為2.6 GHz,型號為Core i5-3230M,內存為4 GB)的設備上進行了測試。為了避免網絡時延的影響,本文在同一設備上模擬所有客戶端和服務器。
首先,對PPDDPA 和PPDEA 的性能進行了測試,設定每個客戶端的隱私向量是1 000 維,相當于數據集的記錄數為1 000,特征屬性個數d>500。如圖5 所示,在PPDDPA 的性能測試中可以看出,兩服務器的時間花銷總和及各參與的客戶端的時間花銷幾乎不隨著客戶端的數量增加而增加,這表明PPDDPA 的性能幾乎不受客戶端數量的影響。其實在該算法的執行過程中也可以看出這一點,每當該算法執行一次時,不管客戶端的數量是多少,實際上只有2 個客戶端參與其中并只對各自的向量進行加密操作,同時服務器也只對2 個向量做點乘運算。

圖5 PPDDPA 性能測試
在PPDEA 的測試中,每個客戶端都有1 000 條數據記錄,因此每一個客戶端都會參與其中,從圖6可以看出,服務器的時間花銷隨著客戶端數量的增加而顯著增加,而各客戶端的時間花銷幾乎不受影響。同樣也可以從該算法的執行過程看出,各客戶端僅執行向量加密操作,而服務器的計算量隨著客戶端數量的增加而增大。綜上所述,本文提出的算法不僅適用于少量客戶端聯合委托學習的情況,而且在大量客戶端參與時也能保證各客戶端的數據加密成本不隨客戶端數量的增加而增大。

圖6 PPDEA 性能測試
其次,利用急性肝功能衰竭疾病預測數據集對本文提出的協議與OPPC4.5[22]協議進行了對比測試。由于該數據集只包含29 個特征屬性,因此設定參與的客戶端數量最大為29,并且插入的虛假記錄數為200條。如圖7 所示,當數據垂直分布時,在本文所提出的協議中由于客戶端需要提前計算出整體數據集的信息熵并布爾化數據集,因此計算成本略高于OPPC4.5 協議,但從整體來看客戶端與服務器對模型訓練的總成本略低于OPPC4.5 協議。從圖8 中可以看出,當數據水平分布時,在本文所提出的協議中客戶端的計算成本顯著低于OPPC4.5 協議,因為模型訓練的計算過程幾乎完全由服務器處理,客戶端僅需對數據進行統計和加密操作。因此也說明當數據水平分布時,客戶端的計算負擔得到了顯著改善。
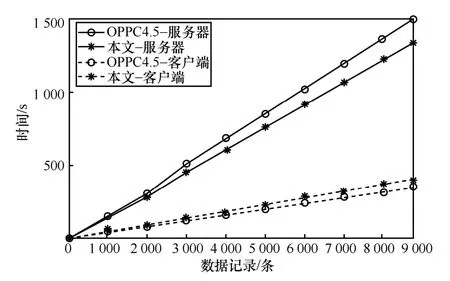
圖7 數據垂直分布的協議性能測試
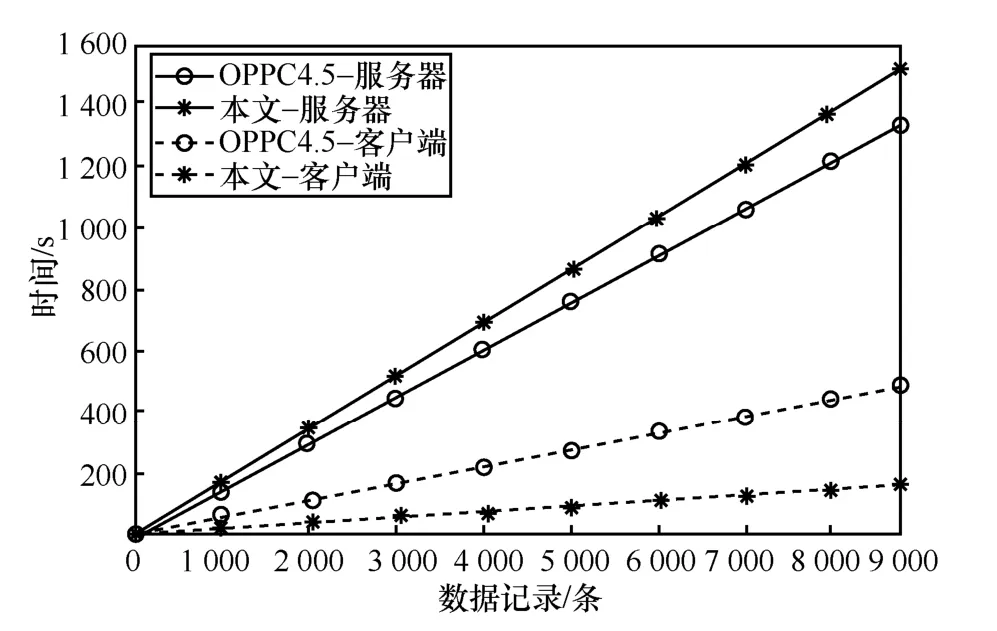
圖8 數據水平分布的協議性能測試
最后,以表1 中的數據對本文提出的基于虛假記錄的隱私保護方法進行了測試。如圖9 所示,無論數據分布情況如何,客戶端最終都可以構建正確的決策樹模型T。而在服務器側,當數據垂直分布時,兩服務器都得不到任何關于模型的信息。當數據水平分布時,只有服務器S1可以推測出如圖10 所示的模型框架,且僅能使用不確定的信息(字母)代替節點和分支的信息。對于機器學習模型訓練而言,學習的過程就是對模型參數的調參過程,而沒有參數的模型是毫無價值的。通常隱私保護的決策樹挖掘方法均使用隱藏節點名稱達到保密的目的,本文在此基礎上增加了虛假分支的方法(圖10 中A 節點下的分支中(a,c,d)必有一個分支是虛假的)以此來擾動決策樹模型結構,進一步提升了決策樹模型的安全性。
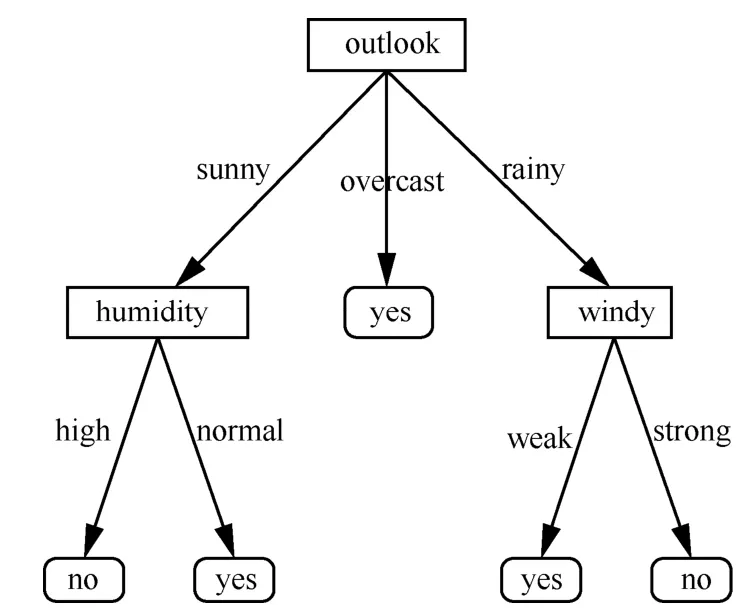
圖9 客戶端最終獲得的模型T
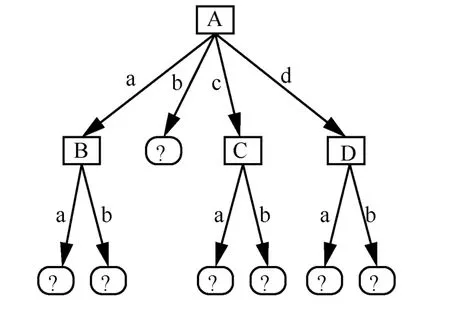
圖10 S1 可推測的虛假模型框架
7 結束語
為降低用戶隱私數據在數據共享過程中的泄露風險,同時減少客戶端在數據挖掘過程中的計算成本,本文基于傳統的委托計算思想和BCP 同態加密算法提出了一種聯合委托學習模型,該模型采用雙服務器分別計算客戶端的部分密文信息的方式來降低數據共享中的隱私泄露風險。進一步地,針對決策樹的安全構造,提出了一種基于虛假記錄的隱私保護方法,該方法利用少量的虛假記錄改變了數據統計的真實結果,并對決策樹的模型結構進行擾動,避免了服務器獲得真實的中間計算結果和最終訓練的模型結構。另外,分別對數據垂直分布和水平分布的情況設計了隱私保護委托算法及聯合委托學習協議,在保證數據安全共享的同時降低了客戶端的計算成本。最后,通過實驗測試結果表明,在聯合委托學習過程中,各客戶端的數據加密成本不隨客戶端數量的增加而增大,并且最終獲得的模型與真實數據構建的模型具有一致性,即最終挖掘得到的模型準確度沒有任何損失,而服務器很難推測和匹配出真實的模型結構。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
