命名實體識別研究綜述
2021-05-28 06:03:48袁清波楊帆
現代計算機 2021年11期
袁清波,楊帆
(陸軍工程大學指揮控制工程學院,南京210007)
0 引言
隨著計算機和網絡通信技術的迅猛發展,互聯網上數據量呈爆炸性增長。這些數據產生渠道眾多,而大部分都是非結構化數據,給人們快速獲取有效信息帶來了較多困難。如何將這些非結構化數據轉換為結構化數據,以進行高效利用,是當前亟需解決的問題,也是信息抽取(Information Extraction,IE)研究的重要內容之一。命名實體識別(Named Entity Recognition,NER)作為知識圖譜構建過程中的關鍵技術,主要完成從非結構化數據中識別出預定義好的語義類型命名實體,目前廣泛應用于搜索引擎、智能推薦、機器翻譯和問答服務等領域。先前已有部分人員對命名實體識別的方法進行了相關綜述[1-2],但到目前為止已有一段時間,本文針對近幾年出現一些最新方法進行介紹。
1 產生與發展
近年來,一些重要國際競賽會議對命名實體識別技術的產生與發展起到了重要推動作用。這些會議主要有消息理解MUC 會議、自動內容抽取ACE 會議、文本分析TAC 會議以及語義評測SemEval 會議等。
MUC 會議由美國海軍海洋系統中心NOSC 發起,在美國國防部高級研究計劃局DARPA 的資助下,旨在對軍事文本信息進行自動分析評估,對命名實體識別技術的評測起到了重要作用。MUC 會議自1987 年開始到1998 年結束,共舉辦了七屆。MUC 會議定義的召回率(Recall)和精確率(Precision)兩個評價指標現已成為命名實體識別領域的評價標準。MUC 會議的舉辦對于命名實體識別的發展起到了極大的推動作用。
ACE 會議是由美國國家標準技術研究院NIST 組織的評測會議,其中的一項重要任務就是命名實體識別。ACE 會議自1999 年開始到2008 年結束,共舉辦了八屆。ACE 對MUC 定義的任務進行了細化,在語料的語種數量和數據規模都有所增加。ACE 會議主要涉及英語、阿拉伯語和漢語三種語言,主要包括實體檢測和跟蹤、關系檢測和表征、事件檢測與表征等三任任務。
TAC 會議是由NIST 組織的一系列評估研討會,旨在通過提供大量測試集,通用評估程序以及可共享其結果的論壇來鼓勵自然語言處理和相關應用的研究。TAC 由一組稱為“tracks”的任務集組成,每個任務集中于NLP 的特定子問題。命名實體識別的有關評估被歸為TAC 中的知識庫填充(Knowledge Base Population,KBP)評估任務中。KBP 評估從2009 年開始,每年舉辦一次,截至2019 年,已經舉辦了十一屆。
SemEval 會議是由國際計算語言學協會ACL 下的特殊興趣小組SIGLEX 組織的評估會議。該會議是由SensEval 詞義消歧評估系列會議發展而來的,后來又加入了語義角色標注、情感分析和命名實體識別等多項任務。SemEval 會議從1998 年開始舉辦第一屆,截至2019 年,已經成功舉辦了十三屆。
2 相關方法
命名實體識別方法發展至今,總體可以分為基于規則的方法和基于機器學習的方法[3],具體如圖1 所示。基于機器學習的方法按照對語料依賴程度分為兩類:有監督的命名實體識別和無監督的命名實體識別。基于深度學習的方法在命名實體識別任務中已成為當前研究的主要方向,取得的性能也在逐年提高。
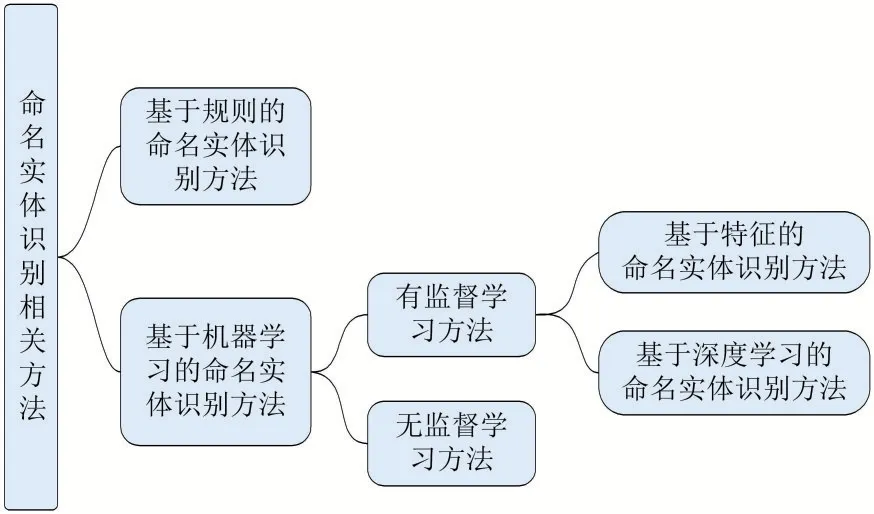
圖1 命名實體識別相關方法
2.1 基于規則的命名實體識別方法
在早期的命名實體識別研究過程中,主要以基于規則的方法為主。基于規則的方法,主要由領域專家編寫制定規則,要求相對比較高。該方法首先由領域專家編寫一些簡單的規則,然后在語料庫中進行試驗,通過對錯誤的結果進行分析后而不斷改進規則,直到命名實體識別的效果達到滿意為止。在基于規則的方法中,比較常用的是基于詞典匹配的方法,通過字符串完全或部分匹配來完成命名實體識別,實現相對簡單且效率較高。基于詞典匹配的方法實現過程中,通常可以通過正向、逆向、雙向最長匹配,字典樹和AC 自動機等各種算法來進行實現。基于規則的命名實體識別方法的優點是無需提前對語料庫進行標注,在小規模語料庫上效果較好,且系統運行速度快;缺點就是編寫規則對人員個人水平要求較高,且系統移植性較差。一些著名的基于規則的NER 系統有LaSIE-Ⅱ、NetOwl、Facile、SAR、Fastus 和LTG 系統。
2.2 基于特征的命名實體識別方法
基于特征的命名實體識別方法屬于傳統機器學習中的有監督方法。該方法將命名實體識別當作是序列標注任務,具體算法模型需要利用標注好的語料進行訓練。基于特征的方法在識別命名實體過程中,通常包括以下幾個步驟:①標注語料,一般采用IOB(In?side-Outside-Beginning)或IO(Inside-Outside)標注體系對語料庫文本進行人工標注;②特征定義,通常選取當前詞、前一個詞、后一個詞、詞性等特征,其對命名實體識別的結果影響較大;③訓練模型,經常采用的模型主要有隱馬爾可夫模型(Hidden Markov Model,HMM)[4]和條件隨機場(Conditional Random Field,CRF)[5]。
2.3 基于深度學習的命名實體識別方法
基于深度學習的命名實體識別方法已成為當下研究的主流,而且取得了不錯的效果。與基于特征的NER方法相比,基于深度學習的NER 方法無需人工制定規則或者復雜的特征,易于從輸入語料中提取出隱藏的特征。在NER 任務中,常用的神經網絡主要有卷積神經網絡(Convolutional Neural Network,CNN)、循環神經網絡(Recurrent Neural Network,RNN)以及基于注意力機制(Attention Mechanism)的神經網絡。其中RNN 中的長短時記憶神經網絡(Long Shot-Term Memory Neural Net?work,LSTM)目前已經廣泛應用于NER 任務中。
Li 等人[6]在2020 年提出了一種典型的深度學習NER 總體架構,如圖2 所示。該架構主要分為三個部分:①輸入分布式表示(Distributed Representations),考慮了單詞和字符級別的嵌入,以及結合了在基于特征的方法中已經很有效的附加特征,如詞性標簽和地名詞典;②上下文編碼器(Context Encoder),使用CNN、RNN 或其他網絡捕獲上下文依賴關系;③標簽解碼器(Tag Decoder),主要用于預測輸入序列的標簽,也可以訓練用來檢測實體邊界。

圖2 深度學習NER總體架構
按照處理語言領域的不同,基于深度學習NER 方法可分為英文NER 方法、中文NER 方法及其他語種方法。英文及中文NER 常用方法如圖3 所示。
(1)英文NER 方法
Huang 等人[7]在2015 年提出了一系列基于LSTM的序列標注模型,包括LSTM、雙向LSTM(BI-LSTM)、帶有條件隨機場(CRF)的LSTM(LSTM-CRF)以及帶有CRF 層的雙向LSTM(BI-LSTM-CRF),并比較了上述模型在NLP 標記數據集上的性能。首次將BI-LSTMCRF 模型應用到了NLP 基準序列標記數據集中,并證明該模型可以有效地利用過去和未來的輸入特征和句子級別的標記信息。Ma 等人[8]在2016 年提出了一種結合雙向LSTM、CNN 和CRF 的端到端序列標記模型,是一個真正的端到端模型,不依賴于特定任務的資源、特征工程或數據預處理。Rei 等人[9]在2016 年提出了基于注意力機制的詞向量和字符級向量組合方法用于序列標注任務中。該方法認為命名實體識別除了需要詞向量,還需要詞中的字符級特征向量。在RNN-CRF模型基礎上,采用注意力機制對詞向量和字符級特征向量進行拼接。Lample 等人[10]在2016 年提出了LSTM-CRF 命名實體識別模型,該模型依賴于兩個關于單詞的信息源:基于字符的單詞表示主要從有監督的語料庫中學習得到;無監督單詞表示主要從無注釋的語料庫中學習得到。Li 等人[11]在2019 年提出了一種基于機器閱讀理解(Machine Reading Comprehension,MRC)的框架代替序列標注模型統一處理嵌套與非嵌套命名實體識別問題。該方法適用于非嵌套和嵌套兩種類型的NER。相比序列標注方法,該方法簡單直觀,可遷移性強。通過實驗表明,基于MRC 的方法能夠讓問題編碼一些先驗語義知識,從而能夠在小數據集下、遷移學習下表現更好。Yan 等人[12]在2019 年提出了TENER 模型。該模型是在原始Transformer 基礎上針對NER 任務進行的改進,采用經過改進的Transformer編碼器來對字符級特征和單詞級特征建模。

圖3 基于深度學習英文及中文NER常用方法
(2)中文NER 方法
Zhang 等人[13]在2018 年針對中文NER 提出了一種網格結構的LSTM 模型(Lattice LSTM)。該模型相對基于字符(character-based)的方法,能夠充分利用單詞和詞序信息;相比基于詞(word-based)的方法,不會因為分詞錯誤影響識別結果。該模型的核心思想是通過網格LSTM 表示句子中的單詞,將潛在的詞匯信息融合到基于字符的LSTM-CRF 中。Cao 等人[14]在2018 年針對中文NER 提出了一種新穎的對抗性轉移學習模型(BiLSTM+CRF+adv+self-attention)。作者認為中文分詞(Chinese Word Segmentation,CWS)和中文NER 任務有很多地方很相像,也有很多不同。于是提出了對抗遷移學習模型,以充分利用兩者共同的邊界信息,同時也防止中文分詞特有的特征對中文NER 任務造成影響;同時還將自注意力機制引入到模型中,以來捕捉句子中長距離的依賴性和語法信息。Zhu 等人[15]在2019 年針對中文NER 提出了一種基于注意力機制的卷積神經網絡模型(CAN)。該模型由一個具有局部注意力層的基于字符的卷積神經網絡(CNN)和一個具有全局自我注意力層的門控遞歸單元(GRU)組成,用于從相鄰的字符和句子上下文中獲取信息。Ma 等人[16]在2020 年提出了一個簡單而有效的中文NER 方法Soft?Lexicon(LSTM),可以將詞匯信息整合到字符表示中。該方法避免了設計復雜的序列建模結構,對于任何神經網絡模型,只需對字符表示層進行細微調整,就可以引入詞典信息。同時,該方法還可以很容易地與BERT等預訓練模型相結合。Li 等人[17]在2020 年提出了一種適用于中文NER 的FLAT 模型(Flat-Lattice Trans?former),是在Zhang 等人[13]Lattice 模型基礎上進行的改進。為解決傳統Lattice 模型計算效率低下、引入詞匯信息有損的這兩個問題,FLAT 基于Transformer 結構進行了兩大改進:一是對每一個字符和詞匯都構建兩個頭部位置編碼和尾部位置編碼,將Lattice 結構轉化為平面結構;二是引入相對位置編碼,以提升Transformer 的位置感知和方向感知。FLAT 模型不去設計或改變原生編碼結構,設計巧妙的位置向量就融合了詞匯信息,既做到了信息無損,又大大加快了推斷速度。
2.4 基于無監督的命名實體識別方法
無監督學習的一個典型方法是聚類。基于聚類的NER 系統基于上下文相似性從聚類組中提取命名實體。無監督NER 的關鍵思想是:詞法資源、詞匯模式和在大型語料庫上計算的統計信息可以用來推斷命名實體的提及。Michael 等人[18]在1999 年提出使用未標記示例來解決命名實體分類問題,提出了兩種無監督的命名實體分類算法。該方法表明使用未標記的數據可以將對監管的要求減少到僅7 個簡單的“種子”規則。同時,利用數據的自然冗余性,名稱的拼寫和出現的上下文都足以確定命名實體類型。Nadeau 等人[19]在2006 年提出了一個無監督的地名索引建立和命名實體歧義解決系統。該系統解決了該領域中經常討論的兩個主要限制:一是系統不需要人工干預,例如手動標記訓練數據或創建地名索引;二是系統可以處理三種以上的經典命名實體類型(人、位置和組織)。此外,Zhang 等人[20]在2013 年提出了一種無監督的從生物醫學文本中提取命名實體的方法。他們的模型采用術語、語料庫統計(如反向文檔頻率和上下文向量)和淺層句法知識(如名詞短語組塊),而不是監督。在兩個主流生物醫學數據集上的實驗證明了它們的無監督方法的有效性和可推廣性。
3 評價指標
在命名實體識別任務評測過程中,國際上的評價指標主要有準確率(Precision)、召回率(Recall)、F 值(F Measure)。
(1)準確率
準確率又稱為查準率,是針對識別結果而言的,它表示的是識別結果樣本中有多少是對的。把正確的識別結果記為TP(True Positive),錯誤的識別結果記為FP(False Positive)。其計算公示為:

(2)召回率
召回率又稱為查全率,是針對原來的樣本而言的,它表示的是原來的樣本中有多少被正確識別了。把正確的識別結果記為TP,錯誤的識別結果記為FN(False Negative)。其計算公示為:

(3)F 值
對于命名實體識別來說,準確率和召回率兩個指標有時候會出現相互矛盾的情況,二者實際上為互補關系。這樣就需要綜合考慮它們,最常見的方法就是F 值,又稱為F Score。其計算公示為:

其中β是用來平衡準確率和召回率在F 值計算中的權重。在關系抽取任務中,一般β取1,認為兩個指標一樣重要。此時F 值計算公式為:

4 結語
本文首先對命名實體識別的產生與發展進行了簡要介紹;其次對命名實體識別的相關方法進行了總結和梳理,重點是目前研究較熱的深度學習方法;最后對命名實體識別的評價指標進行說明。從深度學習方法中可以看出,BiLSTM-CRF 模型是當前基于深度學習的NER 方法中最常見的模型。NER 系統的成功很大程度上取決于其輸入表示,集成或微調預訓練的語言模型嵌入向量正成為深度學習NER 的新的發展方向。利用這些語言模型嵌入向量時,可以顯著提高性能。另外,當在大型語料庫上對Transformer 進行預訓練時,顯示出Transformer 編碼器會比LSTM 更有效。命名實體識別作為一個開放性的熱門話題,有待于更多研究者們進一步深入的研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
