發明人專利文獻耦合與發明人德溫特分類號耦合比較研究
——以非專利實施主體為例
2021-05-26 09:07:18宋艷輝邱均平
情報學報 2021年4期
宋艷輝,邱均平
(1.杭州電子科技大學管理學院,杭州310018;2.杭州電子科技大學中國科教評價研究院,杭州310018)
1 引言
文獻計量學發展至今,許多文獻計量學研究方法提出較早,并且經過了充分的研究與發展,已經相當成熟。然而,專利也是一種文獻,將文獻計量方法拓展到專利文獻,探討專利計量方法,是一件有意義的工作。發明人專利文獻耦合源自文獻計量學中作者文獻耦合,作者文獻耦合則是論文文獻耦合基礎上提出的。文獻耦合,是指兩篇論文引用了同一篇文獻而形成了一種同引用關系,即耦合關系。文獻耦合最早是由Kessler[1]于1963年提出來的。作者文獻耦合將耦合的分析提升到作者層面,而不僅僅停留在論文層面,以論文的作者作為主要的對象[2]。拓展到作者層面后,文獻耦合就變成了一種動態關系,隨著論文的變化,作者文獻耦合也在動態的變化,因此,作者文獻耦合分析變得更加具有分析意義[3]。專利發明人如論文作者一樣,具有強烈的標簽意義。一般認為,論文作者的研究多為相對固定的,當然,一位作者可能擁有多個研究領域,研究領域也有可能發生遷移,但短時間就發生重大變化以及頻頻發生變化的可能性并不大。因此,論文作者成為了很多文獻計量學者的重要分析與計量對象。
專利發明人之于專利,正如論文作者之于論文。專利發明人也往往具備相對固定的技術研究方向,因此,專利發明人是非常具有分析與計量價值的。除了專利文獻容易發生耦合外,德溫特分類號也是極易耦合的,在德溫特數據庫中,德溫特分類號[4]是德溫特調用大量的專業人士,將收入到德溫特數據庫中的專利信息進行深度加工,把來自不同國家不同語言的專利信息統一翻譯成英語,尤其是對晦澀難懂的題名與摘要信息都以簡明易懂的英語表達出來,并對專利的內容、新穎性和應用等方面進行提煉總結。其對每項專利都分配至少一個專利代碼,有的專利涉及多個專利分類代碼,人們可透過代碼很容易辨析出專利所屬的技術領域。因此,專利發明人、引文文獻和德溫特分類號構成了專利耦合的重要分析單元與關聯關系,本文試從比較的角度,探究其之間的耦合關聯關系。
2 國內外研究現狀述評
國內外關于專利耦合的研究表現為三個方面的特征:①多為專利文獻耦合。即以引文作為媒介建立耦合關系,借此測度技術相似性[5]、發掘技術機會[6]、識別新興技術[7],并對可能出現的技術突破進行預見[8],或者側重于企業的競爭情報分析[9]。②多為專利權人耦合研究。如溫芳芳[10]曾經提出以專利權人類號耦合進行科學合作的探測,Huang等[11]較早使用專利耦合探討高新技術,顏端武等[12]以專利耦合方法研究技術創新網絡,Sternitzke等[13]將專利耦合與社會網絡分析結合起來,進行過類似研究還有國內的陳云偉等[14]。③有對比研究,多為專利耦合與專利共被引的比較及融合。其中有代表性的是高楠等[15]建議融合專利共被引和耦合方法進行前沿識別,李睿等[16]從聚類的可操作性、穩定性、協同性等方面比較專利共被引與耦合方法。
從目前的研究可以看出,1994年Narin[17]最早提出專利計量的研究,之后Huang等[3]和孫濤濤等[9]進行了專利耦合的研究。關于專利耦合的研究遠遠沒有成熟,還有很多值得研究的角度以及研究不足之處。例如,①大多數研究多側重于方法的應用,對方法本身的探討略顯不足,也即是對基礎理論研究不足。②多從專利權人角度進行耦合研究,實際上,專利發明人是專利的研發者,但并不一定就是實際擁有者,即并非專利權人,因此,對于具體研究專利的技術內容方面,或者其他的特定研究目的,專利發明人比專利權人將更有分析價值,能夠得到更多的研究結論。③目前,有少數專利分類號耦合的探討,如溫芳芳[10],但這些研究還是遠遠不夠的,需要繼續向前發展。因此,基于以上的研究不足,本文提出,從專利發明人的角度進行專利耦合的研究,從方法本身的探討角度進行專利發明人文獻耦合與專利發明人德溫特分類號耦合的分析比較研究。德溫特分類代碼,是嚴格按照分類標準進行標注的,包含3個大類:工程、電子電氣、化學,下分許多部,部下又分子類,共包含188個子類。德溫特分類體系,由類→部類→子類構成一個完整的層級分類體系。如t01(digital computers)就是表示數字計算機技術領域,為子類層面的技術領域。本文的發明人德溫特分類號耦合就是在子類層面的耦合。
3 數據來源與方法
德溫特數據庫(Derwent Innovations Index,DII)是本文重要的NPE專利數據來源。德溫特數據庫提供1963年以來至今的數千萬條專利信息,而且是每周更新一次[18-19]。數據樣本主要是NPE專利,NPE(non praticing enties)為非專利實施主體,其獲取專利不以具體實施為目的,NPE將專利視為可以流轉的商品,依靠專利交易活動賺取利潤,其專利運營行為既可能是正當商業行為,也可能是濫用專利權的專利投機行為。選擇非專利實施主體專利為例,主要是我們對其比較熟悉,以及其專利價值一般比較高,有利于我們對兩種方法進行充分的討論。我們的數據檢索,采取高級檢索途徑,檢索項為專利權人。以專利權人名稱進行檢索,可以避開非標準代碼的非獨一無二性,很多企業享有同樣的非標準代碼等問題。獲取Eolas、Wi-Lan、Rambus、DataTreasury等NPE的 專 利 數 據[20],共 獲 得4624條專利數據,建立專利數據集,即樣本數據。
與作者文獻耦合分析相類似,發明人專利文獻耦合表示,2位發明人在發明專利中因為引用了同一專利技術或者同一科學文獻而形成了一種關系,我們稱之為發明人專利文獻耦合,需要指出的是,專利引文中既包含專利文獻,也包含科學文獻,發明人專利文獻耦合也將科學文獻計算在內。發明人類號耦合類似于作者學科耦合與作者關鍵詞耦合,是指2個發明人使用了同一個分類號而建立的關系,這里的分類號為德溫特分類號,一個德溫特子類類似于科學文獻中的一個學科或者一個主題詞。在本文的研究中,我們對發明人專利文獻耦合分析,命名為Inventor Bibliographic-Patent-Coupling Analysis,簡稱IBPCA;Bibliographic-Patent-Coupling意思是,耦合對象中既包含科學文獻,又包含專利文獻。發明人類號耦合分析,命名為Inventor Patent Classification-Coupling Analysis,簡稱IPCCA。
在耦合的計算方面,Zhao等[21]為每位作者分別建立數據集,數據集中包含作者的所有參考文獻,兩位作者數據集中相同的參考文獻數量即二者之間的耦合頻次。在IBPCA的計算中,發明人與作者是相對應的,論文中的參考文獻與專利中的專利文獻與科技文獻是對應的:發明人—作者、論文參考文獻—專利文獻+科技文獻。在IPCCA的計算中,每一個德溫特分類號相當于一條專利引文,同樣可以將分類號抽取出來建立數據集,跟專利引文數據集的建立過程與方法基本一致,其計算方法也是一樣的。本文研究方法主要采用相關分析、因子分析、可視化分析方法。相關分析主要考察IBPCA、IPCCA的耦合總頻次、平均耦合頻次、最大耦合頻次的相關性水平。因子分析主要是通過因子模型與殘差分析考察IBPCA與IPCCA的擬合優度水平,通過因子載荷分析主要考察IBPCA與IPCCA在因子主題探測與發現上的異同。而可視化分析通過中心性測度發現因子主題的重要性以及相近與關聯度,K核分析可以進一步探測核心主題。
4 實證分析
4.1 核心發明人析取
本文以普賴斯定律作為核心專利發明人的選定標準,統計NPE專利數據中的發明人,分兩次統計:僅僅考慮第一專利發明人與考慮所有發明人。如果是僅僅考慮第一發明人,專利發明最多的是WARE,FA,擁有專利數量為144,則根據公式計算而得到m=8.99。如果考慮全部作者,專利發明最多的仍是WARE,FA,擁有專利數量為296,即nmax=296,根據公式計算而得到m=12.89。這2種方式,擁有的共同作者有68位,僅考慮第一發明人得到的74位核心專利發明人中,只有6位不在其中。雖然考慮了全部發明人之后,發明人數量多了很多,核心發明人也隨著增多了起來,但是,通過第一專利發明人確定的核心專利發明人也同樣是有效的。因此,我們進一步篩選出的這68位作者基本可稱為NPE專利的杰出代表。此外,另一個相似之處是,這兩種方式,確定的核心專利發明人所擁有的專利量,占所有專利總量的比例是相當的。僅考慮第一作者的占比為34.0568%,而考慮所有作者的占比為35.7052%。因此,專利發明人及其專利呈現一種良好的集中與離散分布。兩種方式相互印證我們的結果是可信的。
4.2 耦合頻次分析
分別計算每位發明人的耦合頻次,如表1所示。平均耦合頻次=耦合總頻次/所有發明人-1,最大耦合頻次為發明人在與除自身之外其他發明人建立的耦合頻次中的最大值,自耦合采取自己最大耦合頻次+1的方法,+1是為了增加自己與自己耦合的親密性。表1顯示,在IBPCA中,耦合頻次最高的3位發明人是WARE,FA、HAMPEL,CE、ZERBE,JL,同時也是平均耦合頻次最高的3位發明人;在IPCCA中,耦合頻次最高的3位發明人為WARE,FA、BEST,SC、ZERBE,JL,同時也是平均耦合頻次最高的3位發明人。我們發現,IBPCA中排名第1位與第3位的發明人同時也是IPCCA中的第1位與第3位。發明人較高的耦合頻次,體現了發明人較高的研究活力,能夠與其他發明人建立較多的耦合關系,因此,WARE,FA、HAMPEL,CE、ZERBE,JL、BEST,SC這些發明人是NPE專利技術中比較活躍的研究者。最大耦合頻次又可稱為最強耦合強度,表示了發明人與發明人之間的相似程度,只有2位發明人的研究極為相似才會反復地引用同一專利文獻,或者反復地被歸類于同一分類號。表1顯示,IBPCA的最大耦合頻次對為WARE,FA—BARTH,RM;IPCCA的最大耦合頻次對為WARE,FA—PEREGO,RE。在最大耦合頻次方面,WARE,FA依然表現出較高的研究活力,在IBPCA與IPCCA中,WARE,FA都是最強耦合強度對象,只是其發生對象有所不同。在IBPCA中,WARE,FA的最大耦合對象為BARTH,RM,與PEREGO,RE的耦合頻次為575,排在了第3位,說明其與PEREGO,RE依然是非常相似的。在IPCCA中,WARE,FA的最大耦合對象為PEREGO,RE,與BARTH,RM的最大耦合頻次為50,排在了第4位。因此可以認為,在IBPCA中的最大耦合頻次對,在IPCCA中依然是較高的耦合頻次對;而在IPCCA中最大耦合頻次對在IBPCA也可以保持較高的耦合頻次。通過以上分析,可以看到,IBPCA與IPCCA在耦合頻次計算方面還是有一定的相似性,至少在高頻次的發明人計算上呈現這種現象,那么從整體上分析是否仍然呈現出良好的相似性,即在較低頻次的發明人耦合上也是否呈現這種態勢,可以從下文的進一步分析中得到。
4.3 耦合相關分析
為進一步從整體上探析IBPCA與IPCCA的相關性水平,我們對68位發明人在IBPCA與IPCCA中的耦合頻次以及耦合排名進行相關性分析,如表2所示。所有的相關性水平都是在0.01水平上的測度,Sig.值都遠遠小于0.01,即表示相關性是顯著的。平均耦合頻次是在耦合總頻次的基礎上計算而得到的,因此,耦合總頻次與平均耦合頻次的相關性是1,表示完全相關。其排名的相關性也是平均耦合頻次排名跟最大耦合頻次排名的相關系數也為0.817。這說明在IBPCA中,耦合總頻次跟最大耦合頻次之間是存在明顯的相關性的,耦合總頻次較高,最大耦合頻次也容易較高。耦合總頻次排名、平均耦合頻次排名跟最大耦合頻次排名的相關系數也都為0.927。這說明相關性是很高的,發明人在耦合中頻次具有較高的排名,在最大耦合頻次中也往往是擁有較高的排名。此外,發明人耦合頻次排名的相關性要略高于頻次值的相關性。在IPCCA中,發明人耦合頻次排名的相關性跟頻次值的相關性是相當的。在IPCCA中,耦合總頻次與最大耦合頻次的相關系數為0.751,耦合總頻次排名與最大耦合頻次排名的相關系數為0.749。這2個數值是極為接近的。在IPCCA中,發明人的耦合總頻次比較高,最大耦合頻次也是容易比較高的;發明人的耦合總頻次排名較高,則發明人的最大耦合頻次排名也容易較高。還可以發現,無論是IBPCA,還是IPCCA中,耦合頻次(耦合總頻次、平均耦合頻次)與最大耦合頻次都是存在較高的相關性的,耦合頻次排名(耦合總頻次、平均耦合頻次)與最大耦合頻次排名也都是存在較高的相關性的;但在IPCCA中,這種相關性水平要略低于IBPCA。換言之,發明人在IBPCA中,具有較高的耦合頻次或者擁有較高的排名,則比IPCCA更容易獲得較高的最大耦合頻次及其排名。
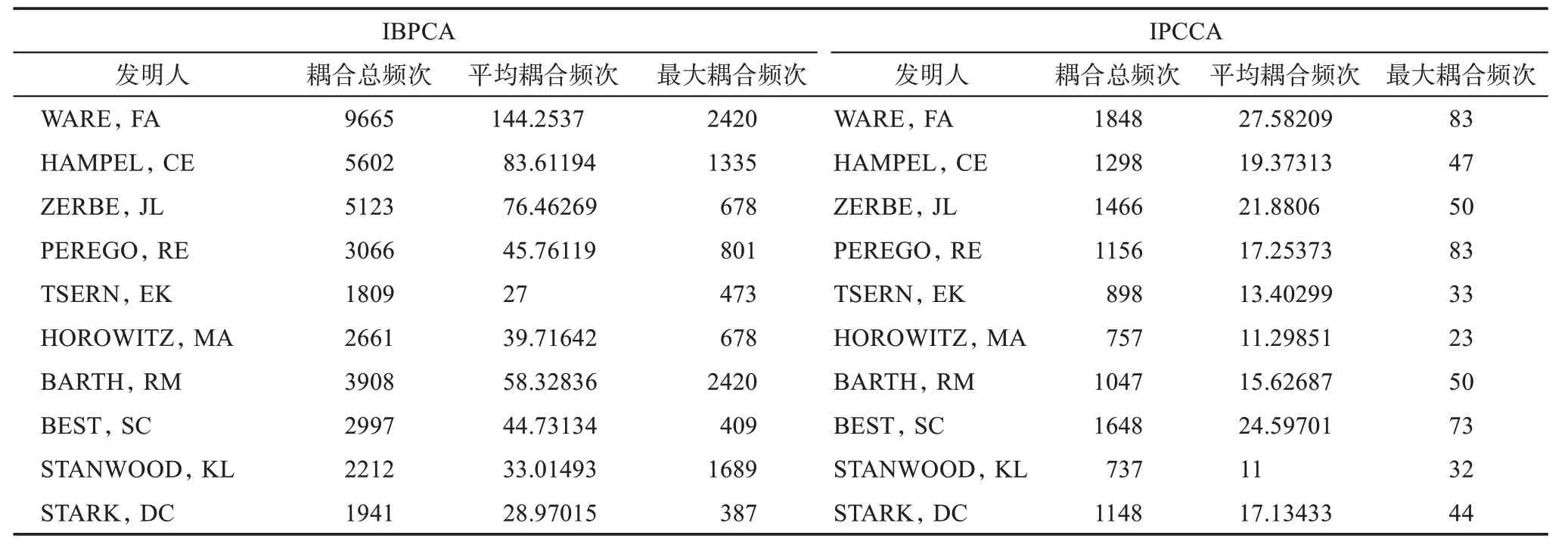
表1 發明人耦合頻次分布(前10位)
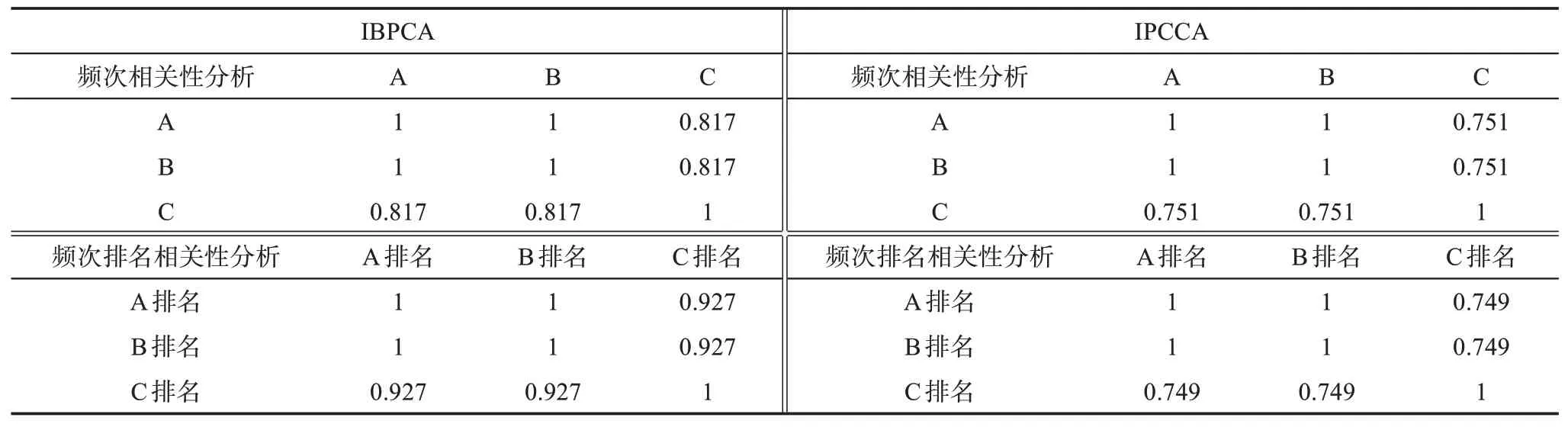
表2 耦合頻次及排名相關性分析
加入專利量與專利量排名之后的相關性分析。可以看到,在IBPCA中,專利量與專利總頻次、平均耦合頻次的相關性要大于IPCCA。IBPCA的相關系數為0.779,而IPCCA的相關系數為0.570。而在專利量排名與耦合總頻次排名、平均耦合頻次排名的相關性相差不大,分別為0.479、0.579。這說明,在IBPCA中,專利量與耦合總頻次、平均耦合頻次的直接相關性更大一些,發明人擁有多的專利發明,其在耦合方面更易獲得較高的耦合頻次。而在排名方面,相比IPCCA,IBPCA則并不明顯。在專利量及其排名與最大耦合頻次及其排名的相關分析系數上(0.780、0.711,0.414、0.591)看,IPCCA則比IBPCA更具優勢,也就是說,相對于專利文獻耦合,在IPCCA中,擁有較多發明的發明人,更容易獲得較高的最大耦合頻次,在專利量排名較高,那么最大耦合頻次的排名也往往具有較高的名次。
以上的相關分析并沒有區分同一發明人在2種方法中的異同,實際上,分析同一發明人在不同方法中的表現,則更能體現著2種方法的異同點[5]。為進一步挖掘IBPCA與IPCCA的相似性,分析IBPCA與IPCCA的共有發明人,如表3所示。數據反映,顯著水平是在0.01上的顯著相關,Sig.遠遠小于0.01,表示相關性是存在的,IBPCA與IPCCA并非毫無關聯。IBPCA與IPCCA的發明人耦合總頻次相關系數是最高的,為0.618。IBPCA與IPCCA的發明人耦合總頻次排名的相關系數為0.568。這表示,發明人在IBPCA與IPCCA中的耦合行為還是基本趨于一致的,發明人在IBPCA中的耦合總頻次跟IPCCA中的耦合總頻次在一定程度上是相關的,而發明人在專利文獻耦合中的耦合頻次排名與同一發明人在專利類號耦合中的頻次排名也是保持了一定的相關性,也就是說變化并不大。

表3 IBPCA與IPCCA相關性對比分析
平均耦合頻次是根據耦合總頻次計算而得,因此,平均耦合頻次與耦合總頻次在IBPCA與IPCCA中的相關性分析結果保持一致。發明人在IBPCA與IPCCA中的最大耦合頻次相關性分析結果分別為0.455;發明人在IBPCA與IPCCA中的最大耦合頻次排名的相關性分析結果為0.467。這2個數值是極為接近的,而且相關系數并不高。這說明在最大耦合頻次方面,IBPCA、IPCCA并不是一種強相關性關系。分析發現,有很多發明人在IBPCA有著良好的表現,而在IPCCA中表現并不佳,如SPINAR,B在IBPCA中的最大耦合頻次排名為3,而在IPCCA中的卻排在了63位,相差60位。這些發明人都會弱化發明人在IBPCA與IPCCA中最大耦合頻次的相關性。當然,大多數發明人在IBPCA與IPCCA中的最大耦合頻次及排名還是有著一定的相關性的。
4.4 IBPCA VS.IPCCA因子分析結果比較
分別構建68位發明人的IBPCA矩陣與IPCCA矩陣。對角線為發明人的自耦合[22],對角線采取最大耦合頻次加1的方式是較為合理的。分別對IBPCA矩陣與IPCCA矩陣進行相似性轉換,消除數據在數量級與量綱上的差異。將相似矩陣導入SPSS進行因子分析,因子提取選用主成分分析。因子分析的旋轉方法為直接Oblimin方法[23-25]。
4.4.1 模型擬合及殘差分析
對IBPCA矩陣與IPCCA矩陣進行因子分析,碎石圖如圖1所示。從碎石圖上看,IBPCA與IPCCA的模型擬合結果優度都比較理想。一條擬合優度理想的碎石圖表現為,首先呈現陡峭地下降,并形成一個弧度,最后變成一條水平的直線。IPCCA的擬合結果要更優于IBPCA,因為IPCCA的曲線更為陡峭、急劇的下降,弧度的銜接更為平滑而直接,最后的直線也更水平。IPCCA碎石圖也顯示,曲線從第6個節點開始轉為水平;IBPCA碎石圖顯示,從第10個節點之后在逐漸轉平,但具體哪個節點并不能完全看出。IBPCA共提取了12個因子,共解釋了90.138%的總方差;而IPCCA僅僅用5個因子,就解釋了97.327%的總方差。相對于IBPCA,IPCCA可以用更少的因子,解釋更多的總方差,方差的解釋力度要更好。主成分分析模型提取的因子也一般是呈現由高到低的順序排列,IBPCA提取的第一個因子也是最高的因子的特征值為23.672,占比34.811%的總方差,對應于圖1a的第一個起點;IPCCA提取的第一個因子則為36.597,占比53.820%,并對應于圖1b的首起點。IPCCA的第2個因子的特征值為20.695,占總方差的30.434%,即右圖的第2個下降的節點,該節點距離第一個節點較近,高踞在上端,這2個節點就累積解釋了總方差的84.254%。而IBPCA除第一個因子具有較高的解釋力度外,其他11個因子的解釋力度皆為一般水平。
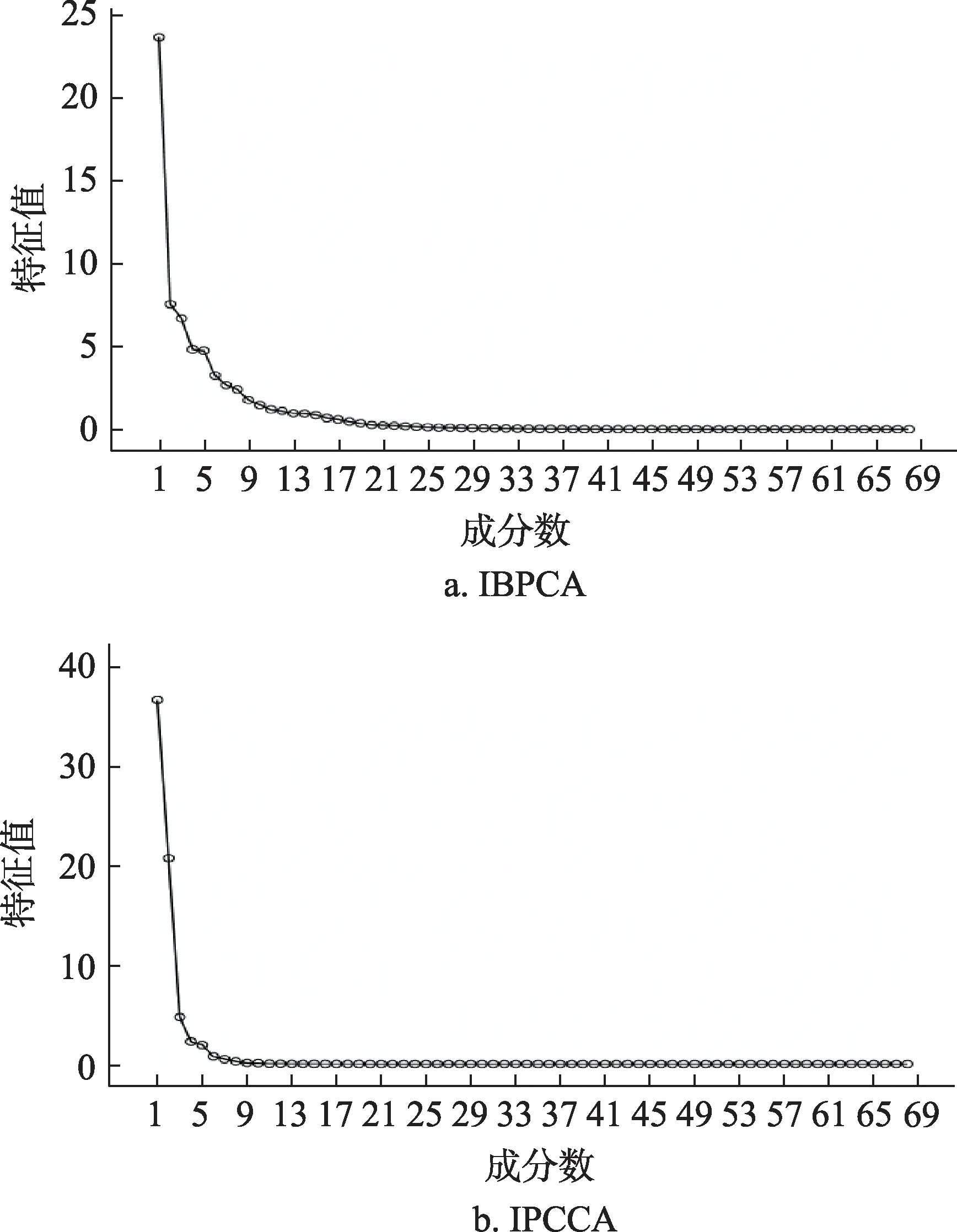
圖1 因子擬合碎石圖
本文從殘差與公因子角度進一步分析比較IBPCA與IPCCA的擬合優度。IPCCA計算觀察到的相關性和重新生成的相關性之間的參考,發現有20(0%)個絕對值大于0.05的非冗余殘差;IBPCA計算觀察到的相關性和重新生成的相關性之間的參考,發現有95(4%)個絕對值大于0.05的非冗余殘差。因此,從殘差上也顯示IPCCA的結果要優于IBPCA。IPCCA通過因子分析提取的公因子也要比IBPCA理想。IPCCA的公因子變動范圍為0.716~0.999,最高公因子為0.999,最低公因子為0.716;而IBPCA的公因子變動范圍為0.482~0.992,最高公因子0.992也小于0.999,而最低公因子0.482也小于0.716。因此,從公因子變動范圍、最高公因子、最低公因子上都顯示IPCCA要優于IBPCA。
4.4.2 余弦相似度比較
余弦相似度(cosine similarity)是用向量空間中兩個向量夾角的余弦值作為衡量兩個個體間差異的大小。重點考慮的是向量在方向上的差異而不是距離或者長度上的差異。如圖2所示,對于向量d1、q、d2。如果d1、q、d2為二維空間的向量,那么d1與q、q與d2的余弦相似度為
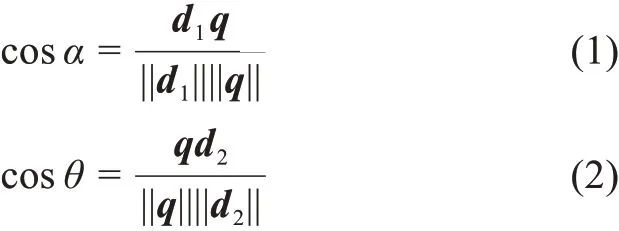
如果d1與q為坐標軸向量,軸坐標值分別為(m1,n1)、(m2,m2)那么d1與q的余弦相似度為
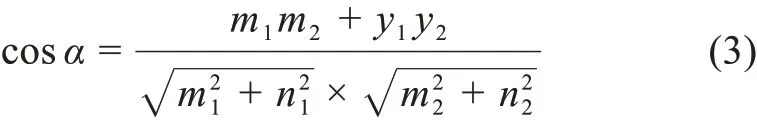
同理,可得到q與d2的余弦相似度。
如果d1=(X1,X2,…,Xn),q=(Y1,Y2,…,Yn),則
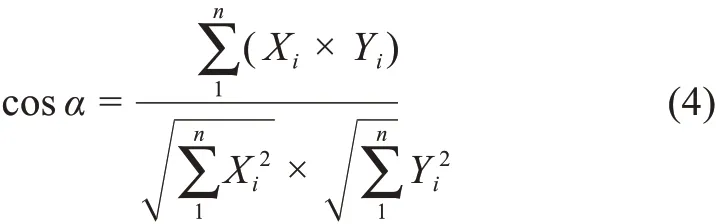

圖2 余弦相似度圖例
基于以上的理論,運行SPSS對IBPCA矩陣與IPCCA矩陣進行余弦相似度測度。結果顯示,共有4624對數據,數據百分之百有效。這4624對數據是一一對應的關系,通過對4624對數據的計算與比對,結果表明IBPCA矩陣與IPCCA矩陣為相似矩陣,相似度為0.396。這是對原始數據矩陣的余弦相似度計算結果。我們認為,原始數據存在著較大的數據差異而會在一定程度上影響結果的表達,為消除數據在數量級與量綱上的差異,將相似性轉化后的矩陣進行余弦相似度計算。計算結果果然要比原始矩陣的計算結果理想很多,相似性大大增強。因此可以說,通過對IBPCA與IPCCA矩陣余弦相似性的計算,基本可以斷定IBPCA與IPCCA并不是毫無關系,是具有一定的相似性的。上文中,從耦合總頻次、平均耦合頻次、最大耦合頻次等方面的相關性分析論證了IBPCA與IPCCA是相關的,可以說是從宏、中觀層面的論證;而余弦相似度深入到每一個數據的比對與計算,可謂是從微觀層面的論證IBPCA與IPCCA的相似程度。這都證明了IBPCA與IPCCA并非沒有關系,而是具有一定關聯的。
4.4.3 因子載荷分析
因子標簽的確定,通過檢查最高載荷發明人,考察最高載荷發明人與其他發明人(尤其是高載荷發明人)之間的高頻次耦合對,分析這些發明人之間的共性,尤其是研究引發這些高載荷發明人發生耦合的專利文獻內容,并咨詢相關領域的專家學者,來確定因子的內容,IBPCA因子載荷分析如表4所示。
因子1:最大載荷發明人為CONNORS,DP,與WENTINK,M的耦合頻次為76,與DALLY,WJ的耦合頻次為46,與MAENG,J的耦合頻次為40,與WARE,FA(載荷排名16)的耦合頻次為最大耦合頻次95。數字計算機與數據靜態存儲。因子2:最大載荷發明人為GARLEPP,BW,與ZERBE,J的耦合頻次為276,與STOJANOVIC,VM的耦合頻次為160,與STOCKHAM,MA耦合頻次43,與WERNER,CW的耦合頻次64。其中涉及最多的是信號生成與分布(TO1K)因子3:最大載荷發明人為SPINAR,B,與STANWOOD,KL的 耦 合 頻 次 為1689,也是最大耦合頻次為1689,與ONG,AE的耦合頻次為181,與VOGELSANG,T的耦合頻次為16。其中大量涉及的內容是數字信息傳輸(W01A),為通信領域。為避免混淆,區別于因子11(數據存儲與傳輸,偏重計算機與半導體領域),定義該因子為通信數字信息傳輸。因子4、因子5不存在高載荷發明人,最大載荷發明人分別為LEE,W、BENYASSINE,A。因子6:最大載荷發明人為HYNECEK,J,主要檢查HYNECEK,J與COK,RS、HOSSAIN,M的共同技術研究來確定因子為半導體與集成電路。因子7,也不存在高載荷發明人,重點研究SU,H、GAO,Y共同的專利發明。因子8、因子9、因子10、因子12因子載荷普遍體低于0.4,并不存在高載荷發明人。因子11,最高載荷發明人為WEBSTER,MA,涉及最多的是數據存儲與內存、互連、數據傳輸(T01H)、數據靜態存儲(U14A),可以看到,雖然二者屬于不同的大類,但內容還是有很多交叉的,因子內容可以歸納提煉為“數據存儲與傳輸”。因子4、因子5、因子7、因子8、因子9、因子10、因子12。本文集中統一標注因子內容,因為研究發現這7個因子都是源自SHLOMOT,E、GAO,Y、SU,H、THYSSEN,J、BENYASSINE,A這5位發明人,這些因子是相對獨立的,且因子載荷分布比較均勻。因子標簽的確定我們首先主要考慮最高載荷發明人與耦合頻次最高的發明人之間的共性研究,當因子之間發生沖突時,如因子10與因子12的最高載荷發明人,以及最高耦合對可能同為SHLOMOT,E、GAO,Y,我們再考慮第2或者第3載荷發明人的研究。如此下來,確定因子標簽為,因子4為“計算機語音處理”,因子5為“一般語音處理”,因子7的載荷作者過少并且載荷值過低難以確定研究內容,以“未查明”來表示,因子8為“便攜式手機”,因子9為“噪音處理”,因子10為“編碼與信息論”,因子12為“數據轉換與傳送”。
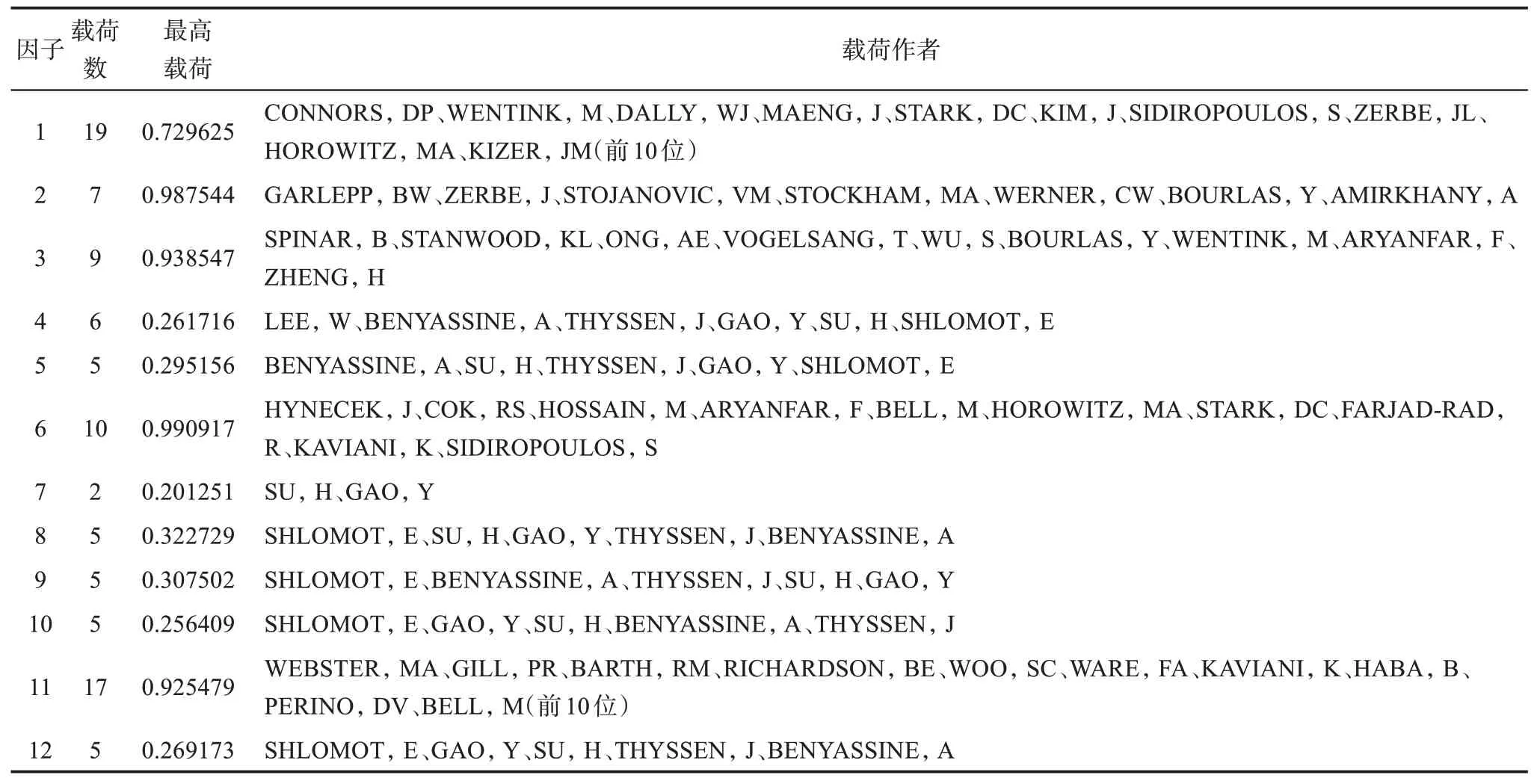
表4 IBPCA因子載荷分析
IPCCA因子載荷分析如表5所示。因子1:LAU,BC是最大載荷發明人,最大耦合頻次為22,LAU,BC與KIZER,JM耦合頻次為19,與STARK,DC的耦合頻次為21,與KIM,J的耦合頻次為16,與BEST,SC的耦合頻次為22。因子2:GAO,Y是最大載荷發明人,最大耦合頻次為51,與CONNORS,DP的耦合頻次為27,與MONRO,DM的耦合頻次為51,與SHLOMOT,E的耦合頻次為30。因子3:分析高耦合發明人共同的技術研究,尤其是BELL,M與ARMSTRONG,BA研究發現,耦合最多的是數據存儲與內存、互連、數據傳輸(T01H)、數據靜態存儲(U14A),因子內容可以歸納提煉為“數據存儲與傳輸”,既涉及數字計算機領域,又涉及半導體與電子電路,是二者的交叉領域。因子4:只有2位發明人,分別是STOCKHAM,MA、HIDER,RC。STOCKHAM,MA是最大載荷發明人,而最大耦合頻次對象也恰好是HIDER,RC,頻次值為4。分析STOCKHAM,MA與HIDER,RC交合的研究,多為B大類的環系化合物研究。因子5:耦合較多的技術領域為:液晶顯示器(U14-K01)、光學(X26)。因子內容可以為“LCD光學研究”。
4.4.4 可視化分析
運用NERDRAW對因子矩陣進行可視化展示。因子用圓形節點表示,發明人用方形節點表示。圓形節點與方形節點之間的連線,表示該發明人在該因子上具有載荷,且載荷值要大于0.2才會出現。連線的粗細代表因子載荷值的大小。因子用統一的顏色表示。方形節點的顏色代表不同的點中心性,紅色表示點中心性為1,軍綠色節點表示點中心性為2,粉色節點表示點中心性為3,黃色節點中心性為4,深藍色節點的點中心性為5,熒光色節點的點中心性為6。節點的大小代表中間中心性。
在IBPCA可視化圖譜(如圖3所示)中,通過中間中心性分析之后,可以發現3個比較重要的因子:數字計算機、通信數字信息傳輸、數據存儲與傳輸。通過后文的K核分析,也會發現這3個因子是最為重要的。這3個因子相互作用,交織在一起。聯系通信數字信息傳輸、數據存儲與傳輸的發明人是VTANWOOD,KL,ARYANFAR,F。聯系數字計算機、數據存儲與傳輸的發明人比較多。聯系數字計算機、通信數字信息傳輸的發明人是WENTINK,M。數字計算機與“半導體與集成電路”也是比較密切的,有很多聯系發明人。

表5 IPCCA因子載荷分析
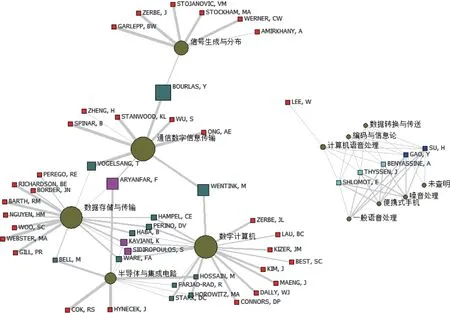
圖3 IBPCA可視化圖譜(彩圖請見http://qbxb.istic.ac.cn/)
在IPCCA可視化圖譜(如圖4所示)中,最為重要的因子為:數字計算機、通信數字信息傳輸。這也是相互作用最強的2個因子。中間有眾多的發明人相互聯系,這跟IBPCA是不一樣的。IBPCA僅有一位發明人聯系,2個因子之間的相互作用明顯比較弱。“數據存儲與傳輸”與數字計算機的作用比較強,中間聯系的發明人有W00,SC、TSERN,EK、SHAEFFER,I、OH,KS、PEREGO,RE、BARTH,RM。“數據存儲與傳輸”與通信數字信息傳輸的相互作用也比較強,中間聯系的發明人有MONRO,DM、SHUSTER,GS、MAENG,J、COK,RS。這幾位發明人同時也是聯系數字計算機與通信數字信息傳輸的重要發明人。
可以看出,IPCCA探測到的最為重要的因子為:數字計算機、通信數字信息傳輸,在IBPCA中都有探測到。IPCCA探測到的數據存儲與傳輸,在IBPCA也有探測到,該因子在IBPCA是中重要因子。IPCCA探測到的LED光學研究,在IBPCA中并未探測到。IBPCA探測到很多小的因子,如便攜式手機、一般語音處理、計算機語音處理、編碼與信息論、數據轉換與傳送、噪音處理等,在IPCCA中也查詢不到。因此,可以說,IBPCA能比IPCCA探測到更多因子,尤其是小的因子。因子之間的相互作用也是不一樣的,在IPCCA相互作用強,未必會在IBPCA中表現出強作用力;在IBPCA中作用力強,也未必會在IPCCA表現出強作用力。
本文進一步進行K核分析,可以得到更為核心的研究領域及發明人。分別進行K=1與K=2,5的計算就可以看到IBPCA的核心研究領域(因子)有4個分別是:數字計算機、通信數字信息傳輸、數據存儲與傳輸、半導體與集成電路。而進行K=3與K=1,2的計算,IPCCAK也發現了3個核心研究領域:數字計算機、通信數字信息傳輸、數據存儲與傳輸。因此,可以看出IBPCA與IPCCA發掘的核心領域大體是相當的。
5 結論
本文以NPE專利為例,探析發明人專利文獻耦合與德溫特分類號耦合,主要的研究結論如下:
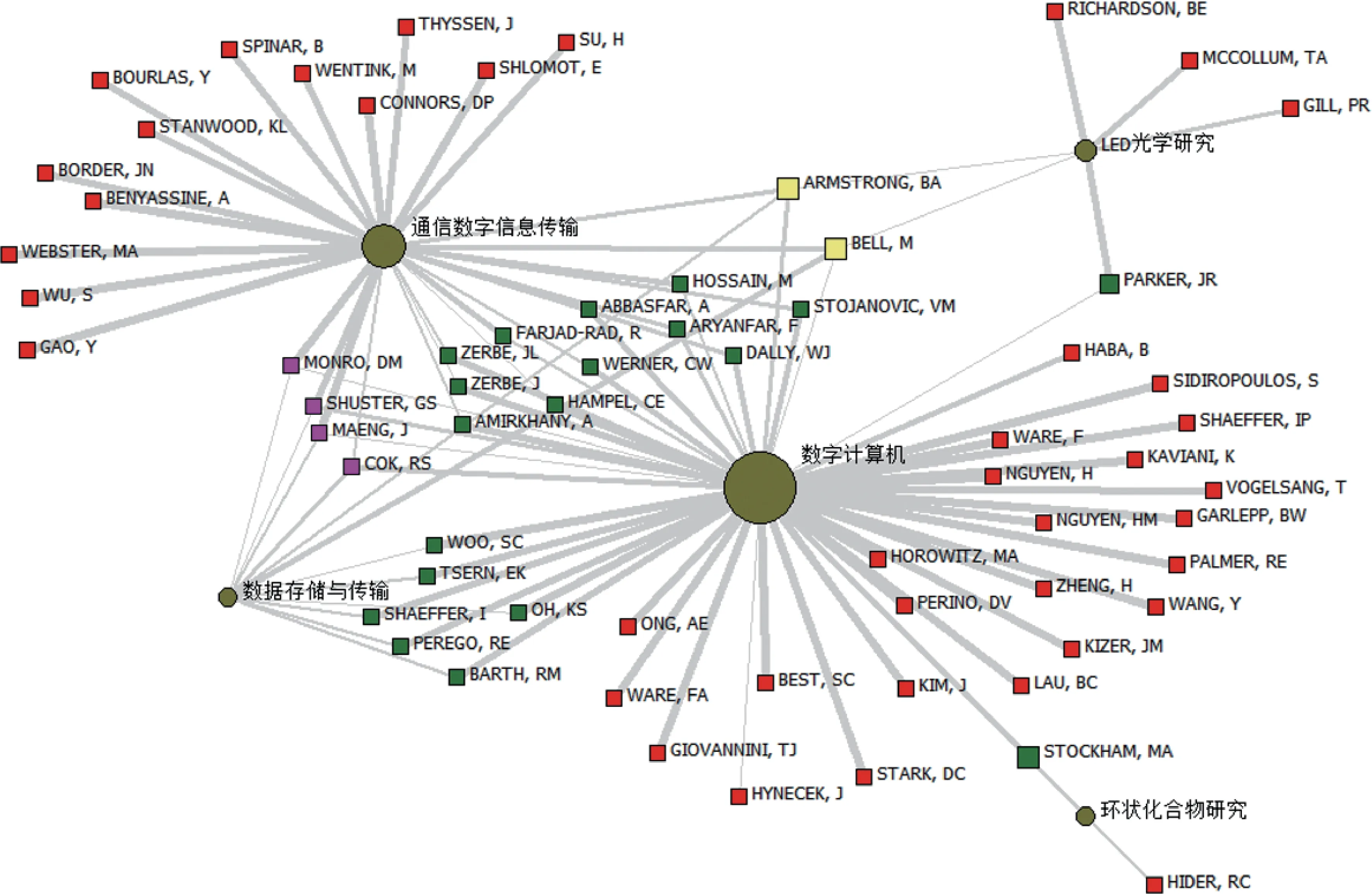
圖4 IPCCA可視化圖譜(彩圖請見http://qbxb.istic.ac.cn/)
(1)從專利量及其排名、耦合總頻次及其排名、平均耦合頻次及其排名、最大耦合頻次及其排名的相關分析結果顯示,IBPCA與IPCCA是具有相關性,相關水平會略有不同。例如,耦合頻次與最大耦合頻次都是存在較高的相關性的,耦合頻次排名與最大耦合頻次排名也都是存在較高的相關性的,而最大耦合頻次在二者之中卻呈現弱相關,平均耦合頻次與耦合總頻次趨于一致。
(2)IBPCA與IPCCA的模型擬合結果優度均比較理想。IPCCA的擬合結果更優于IBPCA。IPCCA可以用更少的因子,解釋更多的總方差,方差的解釋力度要更好。公因子變動范圍、公因子大小等也顯示IPCCA要優于IBPCA。余弦相似度從微觀層面揭示了IBPCA與IPCCA的相似程度。
(3)IBPCA能比IPCCA探測到更多主題,在規模較小的主題上發現更具優勢,規模小的主題往往體現了前沿領域。IBPCA與IPCCA中主題的相互作用會有差異,強弱難辨,即在IPCCA相互作用強,未必會在IBPCA中表現出強作用力;在IBPCA中作用力強,也未必會在IPCCA表現出強作用力,需要進一步的實證研究。
(4)IBPCA與IPCCA發掘的NPE核心領域大體是相當的。IBPCA的核心研究領域有4個分別是:數字計算機、通信數字信息傳輸、數據存儲與傳輸、半導體與集成電路;而IPCCA也發現了3個核心研究領域:數字計算機、通信數字信息傳輸、數據存儲與傳輸。這些主題基本代表了NPE研究的核心所在。
本文是文獻計量學方法向專利文獻領域拓展的有益嘗試,并希望專利耦合最終能像文獻耦合那樣成為成熟的方法得以廣泛應用。本文提出的發明人專利文獻耦合與發明人德溫特分類號耦合在未來能夠在專利文獻結構探測方面發揮重要作用,而且這兩種方法各有特點,也各有優勢,如果能結合起來使用將會取得比較好的研究結論。同時,本文也存在一定缺點和不足:一是僅僅選擇了德溫特數據庫進行實證研究;二是人名雖然根據機構進行過清洗,但難免會有錯誤與遺漏。這些不足之處有待在未來工作中做進一步完善。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年18期)2018-11-14 01:48:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
山東工業技術(2016年15期)2016-12-01 05:31:22
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
