一種結構信息增強的代碼修改自動轉換方法*
2021-05-23 06:11:56曹英魁孫澤宇鄒艷珍
軟件學報 2021年4期
曹英魁 ,孫澤宇 ,鄒艷珍 ,謝 冰
1(北京大學 信息科學技術學院,北京 100871)
2(高可信軟件技術教育部重點實驗室(北京大學),北京 100871)
1 引 言
在開發過程中,開發人員常常面臨著相似的代碼修改任務,而完成這些任務不僅需要耗費開發人員大量的時間和精力,同時,開發人員在完成重復的任務時又容易引入新的錯誤[1,2].得益于不同形式的版本控制系統,軟件項目的演化歷史得以完整地記錄下來.在這些演化歷史中,存在著豐富的代碼修改場景和修改方案[3-6].基于已有的相似代碼修改,研究人員開始關注于相似代碼自動轉換方法的研究,即:給定一組示例代碼修改,通過對修改示例的修改方式進行抽取和表示,并基于表示結果來實現對相似代碼的自動修改.
在早期工作中,代碼修改的自動轉換多是采用人工特征工程的方式[7-11],即人工地提出規則對修改示例中的修改方案的適配條件、修改過程和修改結果進行限定和說明.然而,這些規則的提出往往基于研究人員對特定語言的專家知識,并需要耗費大量的時間精力來總結、提煉.近來,采用基于機器學習的代碼轉換方法[12,13]不斷涌現出來.常見的做法是采用端到端的翻譯模式,將待修改的代碼“翻譯”為修改后的代碼.然而,現有的工作尚未對修改示例的結構信息充分加以使用.一方面,一些現有工作利用翻譯模型,直接將修改前的代碼“翻譯”為修改后的代碼.然而,在缺失修改示例信息的條件下,試圖訓練一個全局的翻譯模型來處理代碼轉換任務,無疑是十分困難的.另一方面,相比于自然語言,代碼內的信息存在著更為顯著的長程依賴.如圖1 所示,函數調用fis.close()中的變量名fis,與最初聲明的變量名為同一個變量.現有工作在采用時序模型對代碼信息建模時,由于兩處代碼間隔很遠,很難捕獲兩處變量間的依賴關系.

Fig.1 Long dependency among variable names圖1 變量名間的長程依賴
針對上述問題,本文提出了一種利用結構信息增強代碼轉換的方法ExpTrans.一方面,給定修改示例,方法將修改前和修改后的代碼解析為抽象語法樹,并尋找其節點間的對應關系.基于節點間的對應關系,方法采用圖的形式來表示給定的示例代碼修改,以增強模型對代碼修改中的結構信息的捕獲能力;另一方面,方法通過將圖卷積網絡和Transformer 架構[14]有效地結合來增強模型對代碼間的依賴信息,尤其是長程依賴關系的捕獲能力.
方法整體上遵循encoder-decoder 的架構設計.其中,編碼器分別對待修改代碼、修改示例代碼以及中間信息進行建模;解碼器依據編碼器的編碼結果,預測轉換后的代碼.為了保證方法產生的代碼的可編譯性,方法在預測修改后的代碼時,借鑒了Yin 和Sun 等人的工作[15,16],以預測指令序列的方式來產生代碼.所謂指令,形如α→β1β2…,其所代表的含義是在代碼的抽象語法樹中的類型為α的節點上,插入子節點,類型分別為β1、β2….具體地,在產生代碼的過程中,方法將維持一棵表示中間結果的抽象語法樹,并基于預測的下一條指令,對當前最左的待擴展的節點進行擴充,直至所有的非葉子節點被擴展完畢,所生成的抽象語法樹所對應的代碼即為轉換后的代碼.
為了驗證方法的有效性,本文在兩個數據集上進行了對比實驗.第1 個數據集是Yin 等人對外開放的111 724個C#代碼修改[13].實驗結果表明,對比Yin 的工作(基于深度學習)[13],本文方法在準確率上有11.8%~30.8%的提升.第2 個數據集是從GitHub 上收集整理的6 組Java 語言典型的相似代碼修改.在該數據集上,分別將本文方法、GenPat 方法[17](基于人工規則)和ARES 方法[10](基于人工規則)用于自動修改這些代碼實例.實驗結果表明,在每組數據中,均有實例被ExpTrans 正確修改,并且在一組數據上的實例全部被ExpTrans 正確修改.相比于GenPat 和ARES 方法的結果,ExpTrans 的結果在準確率和正確修改的實例的數量上,均有大幅度提升.
本文的貢獻主要表現在:(1) 提出了一種基于圖的代碼修改表示方法.相比采用單詞序列的表示方式,圖結構能夠更加準確地表示代碼修改過程,增強了方法對代碼修改中結構信息的捕獲能力.(2) 提出了一種基于Transformer 架構的結構信息增強的代碼修改自動轉換方法.該方法采用特殊的copy 指令顯式地表示代碼間廣泛存在的變量聲明與使用的依賴關系,增加了模型對代碼中長程依賴信息的捕獲能力.(3) 本文在兩個數據集上開展了對比實驗并將數據全部公開(https://github.com/caoyingkui/ExpTrans).相比于現有的機器學習方法,本文方法ExpTrans 在準確率上提升了11.8%~30.8%.對比基于人工規則的方法,在修改實例的準確率和正確修改的實例數量上均有顯著提升.
本文第2 節介紹已有的相關工作.第3 節介紹基于預測指令序列的代碼產生方式,以及本文方法的整體框架.第4 節介紹本文方法的具體實現細節.第5 節介紹為了驗證方法有效性而開展的實驗以及實驗設置和實驗結果.最后,第6 節對本文工作進行總結.
2 相關工作
如前所述,本文的相關工作分為兩類:一類是基于人工特征的方法,另一類是基于深度學習的代碼修改自動轉換方法.
2.1 基于人工特征的方法
該類工作的主要思路是:基于人工提煉的規則,從給定的修改示例中,抽取一個代碼轉換“腳本”,以對示例中的修改條件、修改模式和修改過程進行說明和約束,并可以按照腳本中所約定的方式自動地適配到符合條件的代碼區域并完成代碼轉換.在現有的工作中,這種腳本呈現出代碼編輯序列[7]、模板[8]和特定領域語言(DSL)[11]等多種形式.
在Meng 等人提出的SYDIT 中,利用一組編輯操作序列來表示代碼轉換的過程[7].序列中的編輯操作共包含4 種類型:增加、刪除、修改和移動一個AST 節點,同時利用通配符等方式編輯操作中的類型、位置信息以進行泛化.例如,!config.inValid()被表示為!v2.m5().按照順序依次執行該序列中的操作,即可將代碼修改為修改后的代碼.LASE 是Meng 等人提出的另外一種代碼轉換方法,并依舊利用一組編輯操作序列來表示示例代碼中的代碼轉換[9].與SYDIT 不同,LASE 是從多個相似修改示例中抽取代碼轉換.
此外,還有一些現有工作采用模板的形式來表示修改示例中的修改模式.如Andersen 等人提出的方法spdiff[8],該方法從修改示例中抽取一個單詞替換補丁(term replacement patch)用于刻畫示例中的代碼修改方法,并將一組修改示例中最長的公共子補丁作為該組示例代碼修改中的代碼轉換.針對LASE 在表示代碼修改模式時,無法準確地識別代碼語句移動等問題,Dotzler 等人提出方法ARSE.ARSE 同樣是一種基于多示例的代碼轉換方法[10].然而,與LASE 不同,ARSE 以模板的方式來表示修改示例中的修改模式.Jiang 等人提出的方法GENPAT 是一種從單一修改示例中抽取代碼轉換的方法[17].在該方法中,代碼轉換最終以樹形結構的形式加以表示.在該結構中,每一個節點的信息包括節點ID 和一組屬性值.同時,GENPAT 的表示結果中還包含一組操作,其中的每一個操作為一個元組〈id,id'〉,id 和id'分別代表了修改前、后代碼的AST 中的一個節點并存在對應關系,即節點id 發生修改后變為節點id'.
在Rolim 等人提出的REFAZER 中,定義了一種特殊的DSL(領域特定語言)[11].其主要功能是定義對代碼AST 的操作,以及對符合特定修改的AST 的條件及發生修改的位置和修改類型進行限定.因此,該代碼生成任務的目標為:一段基于該DSL 的代碼.該代碼的輸入為一段修改前的代碼,輸出為修改后的一段代碼.
2.2 基于深度學習的方法
該類工作的主要思路是:給定待修改的代碼,利用機器學習模型預測修改后的代碼.Tufano 等人提出了基于翻譯模型完成代碼轉化方法[12].具體地,給定一段待修改的代碼作為模型的輸入,并利用翻譯模型直接預測一個token 序列,作為轉換后的代碼.同時,該方法也探索了翻譯模型適合何種類型的代碼轉化場景.例如,缺陷修改、代碼重構.代碼作為一種高度結構化的文本,其功能和可編譯性嚴格依賴于代碼具體的token 序列和token 間的相互位置關系.然而,以預測token 序列方式進行工作的翻譯模型,無法從方法層面上保證模型的輸出結果是可編譯的.為了克服這一問題,在Yin 等人提出的方法中,以預測指令序列的方式來生成代碼,從而能夠保證模型輸出代碼的語法正確性[15].基于此工作機制,Yin 等人提出一種基于學習的代碼轉換模型[13].該模型的輸入,除一段待修改的代碼外,同時輸入一個修改示例的修改前、后的代碼,即通過學習修改示例中的代碼轉換方式,來指導待修改的代碼轉換過程.
綜上,Yin 等人提出的方法是目前現有工作中與本文最為相關的方法.在Yin 等人的方法中,利用了LSTM 時序模型用于處理代碼的文本信息.然而,相比于自然語言,代碼存在更為顯著的長程依賴關系,然而有研究表明,時序模型在處理信息長程依賴時效果并不佳[14].因此,克服代碼的信息長程依賴挑戰,是提出本文方法的一個主要的動機.
3 方法框架
為了保證方法生成代碼的可編譯性,本文借鑒了Yin 等人的工作[15],采用以預測指令序列的方式來生成代碼,而非單詞序列.同時,方法在代碼指令集合中,增設了特殊的copy 指令,以顯式地刻畫代碼中變量間的依賴關系.在介紹方法框架之前,本節首先詳細介紹方法中基于預測指令序列的代碼產生方式.
代碼指令.在本文中,所謂指令,指的是形如α→β1β2…的產生式.其中,α為非終結符,βi為終結符或非終結符.在代碼的抽象語法樹上,每個非葉子節點均對應一條指令α→β1β2…,其中,α為該節點的語法類型,βi為其子節點的語法類型(或單詞).
指令集的獲取.給定一棵代碼抽象語法樹,假定其中某個節點v的語法類型為α,節點v共有n個子節點,且其語法類型(或單詞)分別為β1,…,βn,則依據節點v,可獲取指令r:α→β1…βn.按照由上到下、從左至右的順序依次遍歷抽象語法樹的所有非葉子節點,即可獲取相應的代碼指令序列.同時,通過遍歷已有數據集中代碼的抽象語法樹,即可獲取指令集{r1,…,rN}.
在代碼中,由于開發人員可以采用任何合法的變量名、字符串等,導致代碼中存在比自然語言更為顯著的OOV(out of vocabulary)問題.因此方法對出現在指令中的單詞進行限制和預處理,從而避免所獲取的指令集的規模過于龐大,不利于方法進行建模.具體地,在獲取指令之前,本文統計了在給定數據集中的代碼中出現的所有變量名、字符串、數字常量、字符常量及其出現的次數,只有當出現次數超過閾值的單詞,才會將其保留.當代碼中某個單詞出現次數低于閾值時,本文方法將采用形如type_id 的形式進行替換,其中,type 表示該單詞對應的類型,即變量名、字符串、數字常量或字符常量,id 為其編號.通過這樣的處理,能夠保證所獲取的指令規模在有限的范圍內.
此外,本文在指令集中額外增設了一類特殊的copy 指令.在代碼中,變量聲明和使用之間隱含著明確的依賴關系.本文利用增設的copy 指令,顯示地標記變量聲明與使用間的這種依賴關系.如在圖1 中,語句“fis.close();”中的變量名fis 是由語句“FileInputStream fis=new FileInputStream(new File(dir));”聲明得來.因此,方法在解析fis.close();時,采用copy 指令,以標記該變量名fis由復制之前定義的fis而得來.采用copy 指令主要有兩方面的優勢:一方面,顯式地標記出變量間依賴關系的方式,有利于增強后續模型對變量間的依賴關系的捕獲能力.另一方面,copy 指令的復制變量的范圍,是代碼已定義的變量名集合.因此,方法在后續的預測過程中,所面臨的預測空間即為代碼已定義的變量名集合.相比于整個單詞空間,copy 指令縮小了在預測變量名時的預測空間,從而能夠提升方法的準確率.
預測指令序列的代碼產生方式.圖2 展示了基于指令序列[r1,…,r7]生成代碼“fis.close();”的過程.給定圖2(a)的指令序列,方法首先初始一個只有根節點的抽象語法樹,其類型為Statement.基于第1 條指令,即Statement→ExpressionStatement,方法為根節點插入一個類型為ExpressionStatement 的子節點.如圖2(b)所示,當完成前3 條指令后,當前的抽象語法樹最下層將含有2 個待擴展的節點,分別是Expression 和SimpleName.由于“.”“(”和“)”已經是終結符,因此在后續過程中,方法將不會對它們進行擴展.此時,方法將利用下一條指令r4來擴展最左邊的待擴展的節點(非終結符),即左側的Expression 節點.按照上述方式,最終將產生一棵完整的抽象語法樹.按照從左至右的方式,獲取所有的葉子節點內容,即為所生成的代碼.
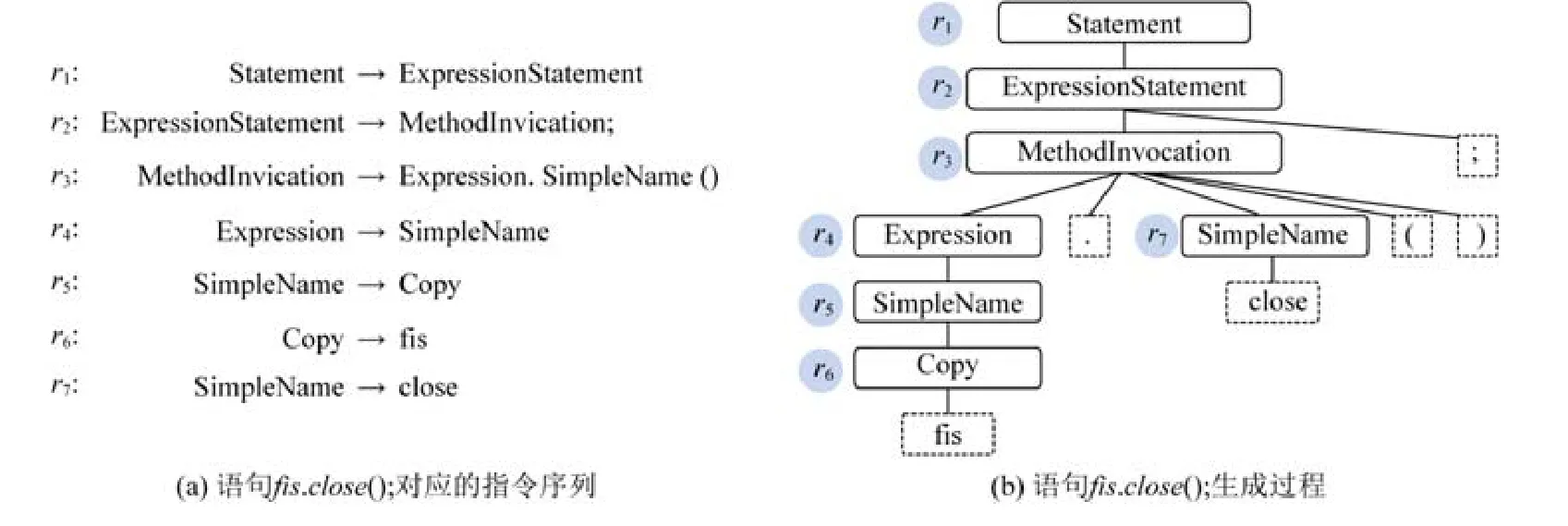
Fig.2 The rule sequences and generation of fis.close();圖2 語句fis.close();對應的指令序列和生成過程
基于上述方式,本文將以預測指令序列的方式,實現代碼修改的自動轉換.方法的輸入為x和xΔ→yΔ,其中,x為待修改的代碼,xΔ→yΔ表示一個修改示例(xΔ和yΔ分別為修改前、后的代碼).最終的輸出為表示代碼轉換后的結果.在生成代碼的過程中,方法將維持一棵表示中間結果的抽象語法樹.通過預測下一條指令,并基于該指令對當前的抽象語法樹最左邊待擴展的節點進行擴展,直至生成最終的代碼.本文將生成代碼的概率形式化地表示為
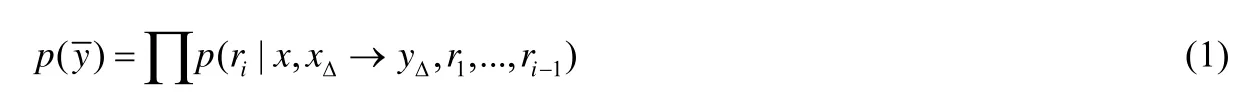
其中,r1,…,ri為產生的指令序列.
圖3 展示了本文方法ExpTrans 的整體框架.
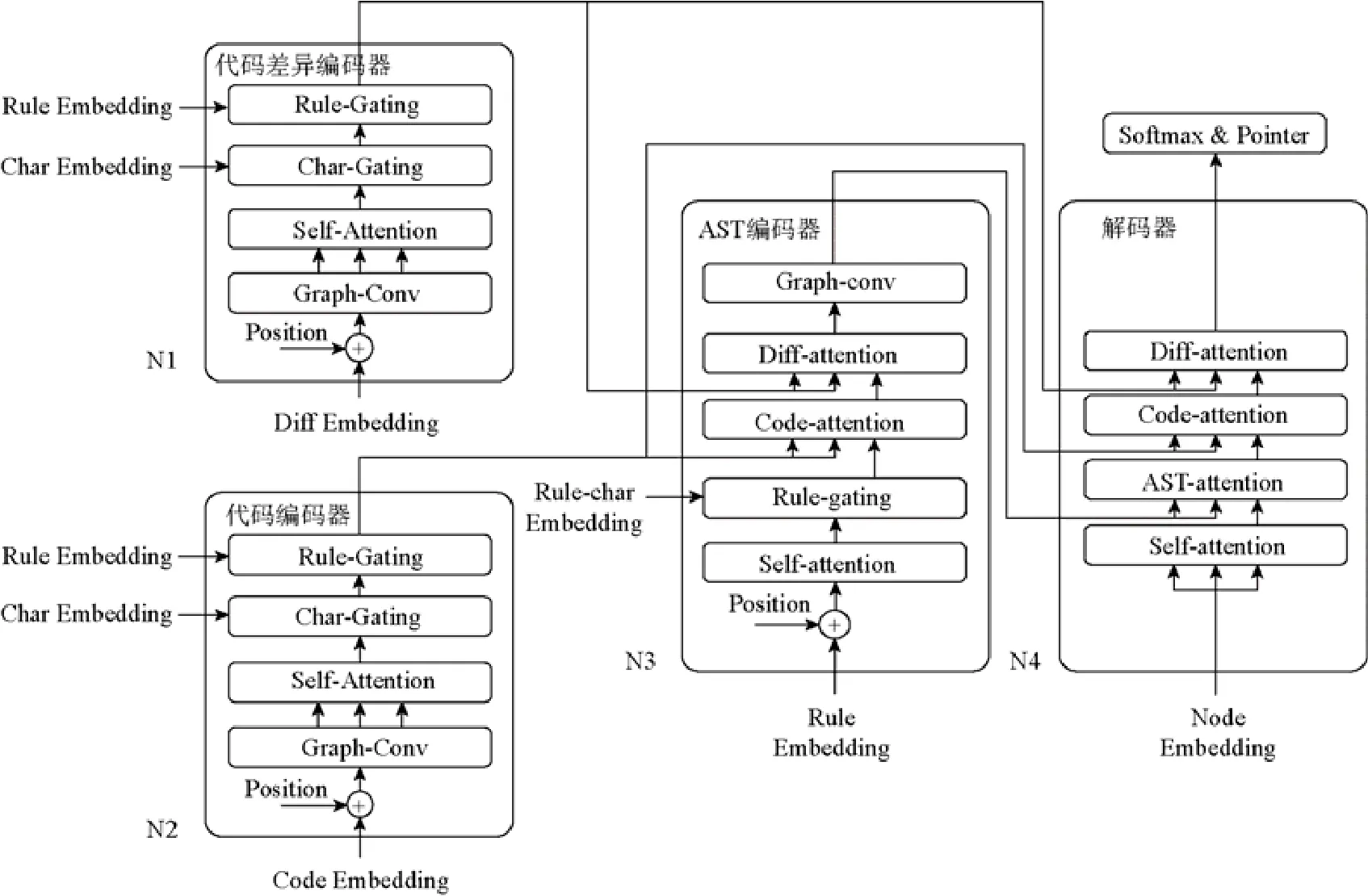
Fig.3 The neural network of ExpTrans圖3 ExpTrans 的網絡結構
方法整體上遵從encoder-decoder 的架構模式,主要包含4 個模塊:代碼差異編碼器、代碼編碼器、AST 編碼器和解碼器.這4 個子模塊均采用了Transformer 的多塊(block)架構[14],即每一個子模塊均由多個結構相同的塊組成.例如,在代碼差異編碼器中,每一個塊均由相同的網絡結構組成,包含Graph-conv 層、Self-attention 層、Char-gating 層和Rule-gating 層,并且按照前一塊的輸出為后一塊的輸入的方式進行連接.在每一個塊的內部結構中,采用殘差連接的方式[18],將相鄰的網絡層(如Graph-conv 層與Self-attention 層之間)進行連接.需要注意的是,圖3 只展示了每個模塊的一個塊.4 個模塊的主要功能如下.
代碼差異編碼器.方法利用該模塊,對輸入的修改示例xΔ→yΔ的信息進行建模.
代碼編碼器.方法利用該模塊,對輸入的待修改代碼x的信息進行建模.
AST 編碼器.在生成代碼時,方法需要維持一棵表示中間狀態的抽象語法樹.方法利用該模塊對該抽象語法樹的信息進行建模,以期在預測代碼指令時,能夠提供語法樹的全局信息.
解碼器.在生成代碼時,解碼器將依據已生成的抽象語法樹中待擴展的節點,預測一下指令.具體地,方法以待擴展的節點信息作為查詢,輸入解碼器.基于輸入的查詢,解碼器采用注意力機制來結合代碼編碼器、代碼差異編碼器和AST 編碼器的建模信息.然后根據解碼器的輸出,方法結合softmax 和指針網絡[19]以預測下一條指令.
4 本文方法
給定待修改代碼x以及修改示例xΔ→yΔ,方法的目標是實現代碼轉換其中,為轉換后的代碼.本節將介紹ExpTrans 中不同模塊的具體實現.
4.1 代碼差異編碼器
方法利用代碼差異編碼器,對修改示例xΔ→yΔ的修改方式、代碼結構信息進行建模.基于xΔ→yΔ,分別將修改前、后代碼xΔ和yΔ表示為抽象語法樹的形式.按照由上到下、從左至右的順序,獲取兩棵語法樹所對應的節點序列然后將兩個序列合并成同一個序列并統一地記為其中,L為方法預設的最大長度,前L(ori)個節點為修改前的節點序列,隨后L(mod)個節點為修改后的節點.當修改前、后的節點序列長度小于L時,方法利用特殊的占位符號〈EMPTY〉進行擴充.代碼差異編碼器將修改示例xΔ→yΔ建模為節點序列[v1,…,vL],代碼差異編碼器的輸出為其中,為節點vi的表示向量,H表示空間緯度(在方法中設定為128).
4.1.1 代碼差異的圖表示
修改示例xΔ→yΔ,以修改前、后代碼分離的形式存在,采用單獨對xΔ和yΔ進行建模的方式,將損失修改前、后代碼間的關聯關系及結構信息.為了更加精確地表示xΔ→yΔ中所蘊含的代碼修改方式,本文將xΔ→yΔ表示為一個統一的圖G=〈V,E〉,其中,節點集合V包含xΔ和yΔ所對應的抽象語法樹節點的集合,E為節點間的連邊集合.
為了建立xΔ和yΔ節點間的連邊關系,本文利用工具GumTree[20]來獲取代碼修改前、后節點的對應關系.GumTree 是一種基于代碼抽象語法樹的代碼差異抽取工具.在工作時,GumTree 首先獲取修改前、后的代碼xΔ和yΔ所對應的抽象語法樹treex和treey.然后按照自底向上的順序,對比treex和treey節點間的類型信息和文本信息,并據此計算節點的相似度,從而獲取treex和treey節點間的最佳匹配關系,并據此能夠準確地推導出代碼的修改過程.
在本文中,當節點vj與節點vi間存在連邊,且由vj指向vi時,我們稱節點vj為節點vi的父節點.進一步地,vj的父節點為vi的祖父節點.結合工具GumTree 的結果,當節點vi和vj滿足下列3 種關系之一時,則建立一條由vj指向vi的連邊,并將該邊加入集合E中.
(1) 節點vi和vj均為treex上的節點,且vj為vi的父節點.
(2) 節點vi和vj均為treey上的節點,且vj為vi的父節點.
(3) 節點vi為treey上的節點,vj為treex上的節點,并且在GumTree 的結果中,vi和vj存在對應關系.
基于集合E,可以構造節點間的鄰接矩陣M,當vj為vi的父節點時,M[i][j]=1;否則,M[i][j]=0.例如,現將代碼“fis.close();”修改為“inputFile.close();”,圖4 給出了采用圖結構表示本處代碼修改的過程和結果.如圖4(a)所示,首先將修改前、后的代碼表示為抽象語法樹的形式(這里,省略了‘.’‘(’等符號以方便展示).基于獲取的抽象語法樹,利用GumTree 來獲取修改前、后代碼抽象語法樹節點間的對應關系.在圖4(a)中,節點ni與in'表示兩個節點存在對應關系.最終,該處代碼修改的圖結構被表示為圖4(b)所示的鄰接矩陣.
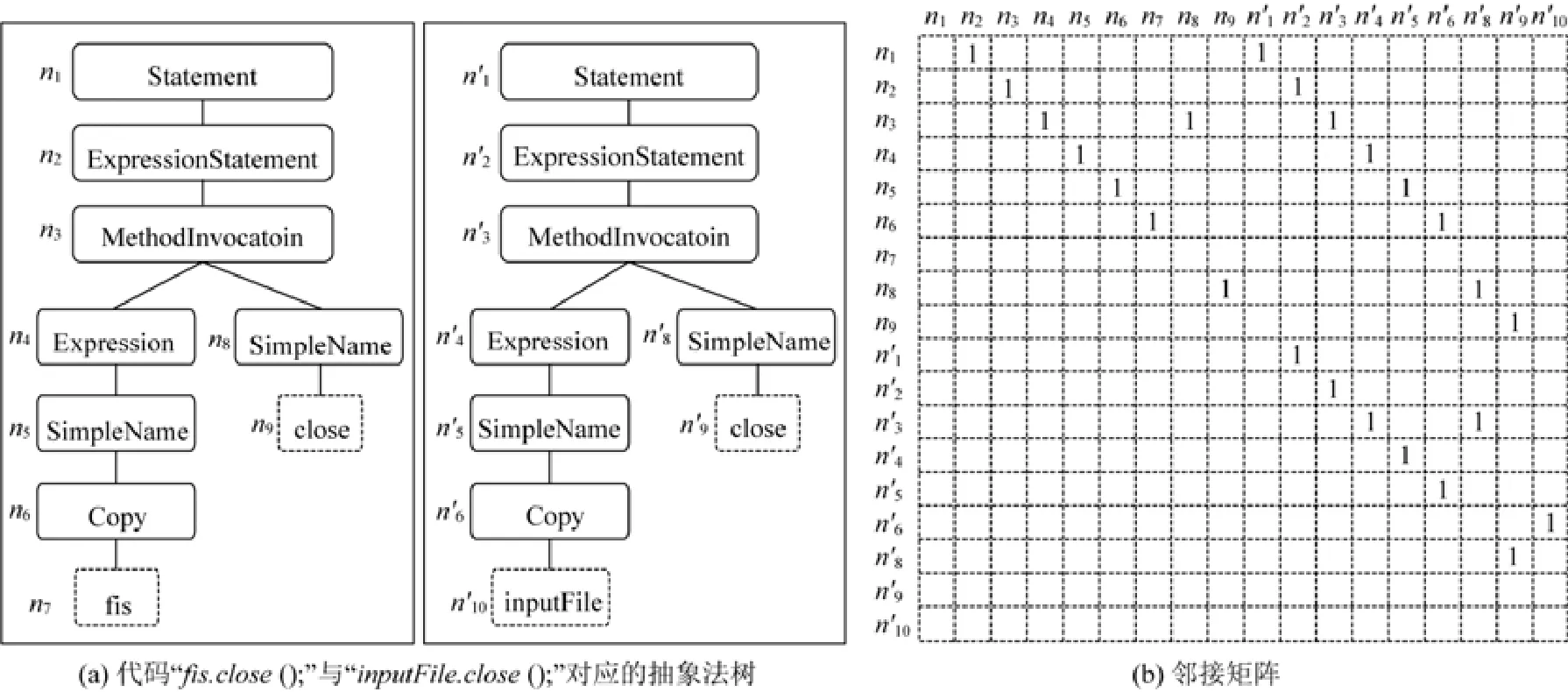
Fig.4 The illustration of construction of code change adjacent matrix圖4 代碼差異鄰接矩陣建立過程示意圖
4.1.2 編碼信息的抽取
在計算Y(diff)之前,方法首先獲取每個節點不同方面的初始信息.
節點的單詞信息.在代碼的抽象語法樹中,每個非葉子節點均有相應的語法類型,每個葉子節點則對應代碼中的一個單詞.基于圖G的節點序列V,可以得到單詞序列[w1,…,wL].當vi為非葉子節點時,wi為節點對應的語法類型;當vi為葉子節點時,wi為節點對應的單詞.通過embedding 方式,為每個單詞wi初始一個表示向量節點序列[v1,…,vL]對應的單詞信息為
節點單詞字符信息.有些語義相似的單詞存在相同的字符序列.例如,同一詞根派生的不同類型的單詞.而上述將單詞作為整體進行信息編碼的方式,將丟棄單詞的字符信息.為了在節點表示向量中引入單詞的字符信息,本文借鑒了Sun 等人對單詞的字符信息進行編碼的方法[16].具體地,基于獲取的單詞序列,將每個單詞wi切分為字符序列[ci,1,…,ci,L′],其中,L′為模型預設的單詞最大長度.類似地,利用embedding 方式為每個字符ci,j初始一個表示向量并利用全連接層,按照公式(2)的方式,計算單詞wi的字符表示向量

節點指令信息.在抽象語法樹中,每個非葉子節點vi均對應一條指令其中,α(i)為節點vi對應的語法類型,所有β(i)均為節點vi的子節點的語法類型或單詞.采用類似公式(2)的方式,方法為每條指令ri:計算表示向量此外,葉子節點所對應的指令,統一采用特殊指令〈EMPTY_RULE〉進行替代.據此,節點序列[v1,…,vL]對應的節點指令信息為
位置信息.在Transformer 的架構中,方法將時序數據(例如代碼的節點序列的表示向量)打包成一個向量矩陣,以使得模型能夠并行訓練.但這樣的處理方式會丟失數據的位置(時序)信息.因此,需要額外添加數據的位置信息.在本文中,采用Dehghani 的工作做法[21],利用下列公式人為地構造每個節點的位置信息:
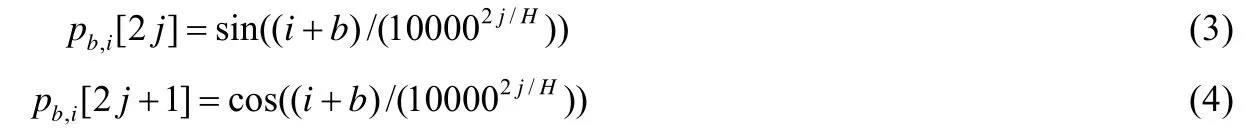
4.1.3 代碼差異編碼器的網絡結構
Graph-conv 層.在將xΔ→yΔ表示為節點序列后,模型將無法捕獲節點間的結構信息.因此本文方法利用一層圖卷積層來實現在每個節點的表示向量中引入代碼的結構信息.
基于構造的圖G=〈V,E〉和鄰接矩陣M,假定當前節點的表示向量矩陣F=[f1;…;fL],方法將按照公式(5)計算每個節點的父節點的表示向量:

在卷積時,方法預設了卷積窗口K,并按照如下方式進行卷積:
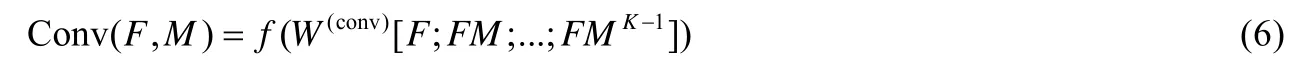
其中,W(conv)為卷積參數,f為Rule 激活函數.
該層的輸入為節點的表示向量和節點的位置信息之和,即I=[xb,1+pb,1;…;xb,L+pb,L],該層的輸出為

其中,當b=1 時(即為第1 個塊),xb,i表示對應節點的單詞信息(即);而對于其他塊,xb,i則為前一塊的輸出.
Self-attention 層.該層采用了Transformer 中的self-attention 注意力機制[14],以捕獲代碼間的長程依賴關系.
在Transformer 中,注意力機制被表述為將查詢Q、鍵值對K和V映射到輸出的過程,其中,Q、K和V均為向量矩陣.輸出為對V中分量加權求和的結果.而V中每個value 相應的權重將依據Q與相應的關鍵字K的匹配程度給出,其加權求和的結果為
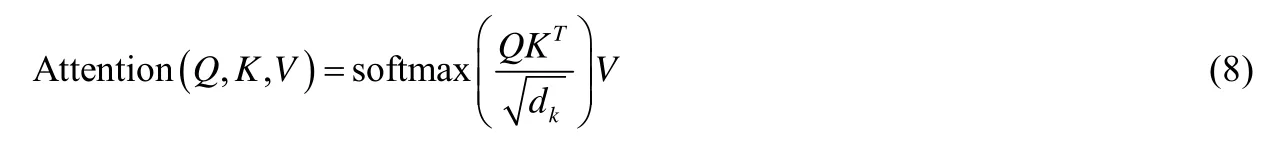
其中,dk為縮放因子.同時,Transformer 采用multi-head attention 機制,使得模型能夠從不同的表示空間的角度來注意到不同位置的信息,即:
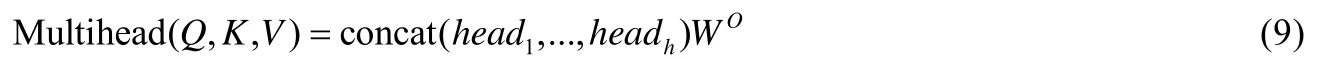
特別地,當Q、K和V相同時,即形如Multihead(Q,Q,Q)的形式,則被稱為self-attention.該層實現了selfattention 注意力機制,該層的輸出為
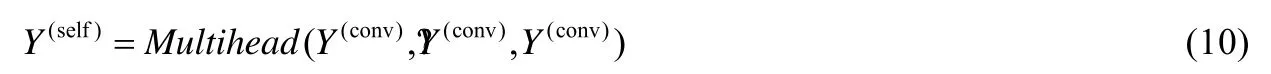
Char-gating 層.在該層之前,節點序列被表示為向量矩陣Y(self),為了在節點vi的表示向量中引入字符信息方法在該層中采用門機制,使得節點的表示向量矩陣更新為Y(self)和Y(char)的加權和.
門(gating)機制的目的在于對不同表示空間的表示結果進行綜合,形成最終的表示向量.給定表示向量f1和f2,門機制的目標是將f1和f2進行加權求和,獲取綜合f1和f2后的表示向量f(gate).其中,f1和f2的權重按照下列公式進行計算:
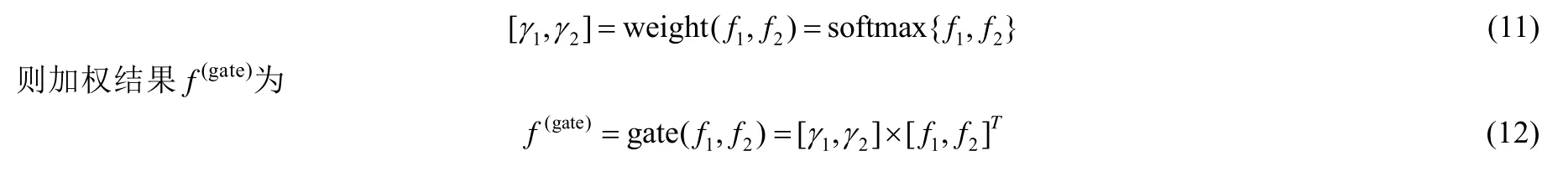
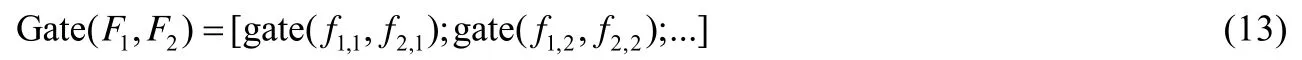
為了保證Y(self)依舊為加權后的結果的信息主體,方法首先基于Y(self)通過線性變換的方式獲取控制向量C(self).然后按照下列公式來計算Y(self)和Y(char)的加權結果作為該層的輸出:

Rule-gating 層.類似地,該層同樣采用門機制,使得在節點的表示向量中融合指令字符信息Y(rule),該層的輸出為
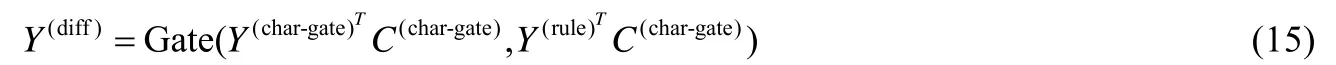
其中,C(char)為通過Y(char-gate)線性變換得來的控制向量.
最終,代碼差異編碼器的輸出為Y(diff).
4.2 代碼編碼器
代碼編碼器的作用是為了實現對待修改代碼x的信息建模.如圖3 所示,代碼編碼器和差異編碼器的網絡結構是一致的,只是在獲取該層的輸入方式上有所不同.
給定待修改代碼x,通過將其解析為抽象語法樹treex,并按照由上到下、從左至右的方式,獲取節點序列V(x)=基于treex,構造圖G(x)=〈V,E〉,其中,V=V(x),E為treex中節點的連邊集合.此外,方法同樣為G(x)構造其節點間的鄰接矩陣M(x).
代碼編碼器采用與代碼差異編碼器中相同的數據預處理方式來獲取節點序列V(x)對應的單詞信息、節點單詞字符信息、節點指令信息和位置信息.然后,信息依次經過Graph-conv 層、Self-attention 層、Char-gating層和Rule-gating 層,并記代碼編碼器的最終輸出為Y(x).
4.3 AST編碼器
本文方法在產生代碼的過程中,需要維持一個由已產生指令序列生成的抽象語法樹.方法以當前抽象語法樹的最左非葉子節點(待擴展節點)為查詢,預測下一條指令,并利用預測的指令對該節點進行擴充.因此,需要對產生代碼過程中的抽象語法樹的信息進行編碼,以在預測下一條指令時,能夠為模型提供抽象語法樹的全局視圖.在AST 編碼器中,方法利用已產生的指令序列[r1,…,rp]來表示已產生的抽象語法樹.AST 編碼器的目標則是:將指令序列最終表示為其中,為指令ri的表示向量,P為方法預設的最大指令序列長度.
4.3.1 編碼信息的提取
指令的初始向量.利用embedding 方式,為每條指令r初始一條表示向量因此給定指令序列[r1,…,rR],通過查表的方式,獲取指令序列的初始表示向量矩陣
指令的符號信息.在形如α→β1β2…的指令表示形式中,符號α和βi對于表達指令的語義信息十分重要.例如,當待擴展的節點的類型為Statement 時,則下一條預測的指令的非終結符α必須同樣為Statement,以保證代碼的合法性.然而,上述將指令作為整體進行編碼的方式,將忽略指令涉及的符號信息.為了在指令的表示向量中引入指令符號序列的信息,本文采用了Sun 的工作方式[16].具體地,給定指令ri:α→β1β2…,α及所有的βj均為標準單詞集中的一個單詞.通過查表的方式,可以獲取每個單詞對應的表示向量α(w)或類似公式(2),利用全連接層,以α(w)和所有作為輸入,并將輸出記為最后,再次利用全連接層實現如下的編碼方式:

其中,W(rule)為網絡參數.指令序列[r1,...,rp]對應的符號信息為
位置信息.本文方法同樣利用公式(3)和公式(4)來計算指令序列的位置信息其中,為第b個塊中的第i條指令的位置信息.
4.3.2 AST 編碼器的網絡結構
Self-attention 層.方法利用一層Self-attention 層來捕獲指令間的依賴關系.該層結構和代碼差異編碼器中的Self-attention 層的結構是一致的.該層輸入為指令表示向量與位置信息之和,即該層的輸出為

當b=1 時(即為第1 塊),rb,i表示指令ri的初始向量(即);而在其他塊中,rb,i為前一塊的輸出.
Rule-gating 層.如上文所述,指令的符號信息對于表示指令的語義十分重要,因此,本文方法同樣利用門機制來實現對指令符號信息的獲取.與之前的gating 層相似,首先基于R(self)獲取控制變量矩陣C(r-self),然后按照下列公式進行計算:
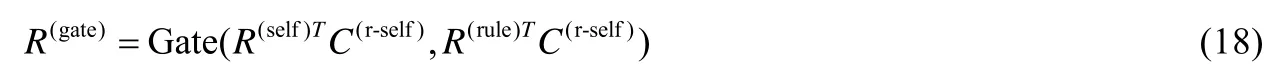
Code-attention 層.代碼轉換需要依據待修改代碼x進行轉換,因此在后續的代碼指令預測過程中,模型需要獲取待修改代碼的信息.本文方法利用該層來實現在指令序列的編碼結果中,引入待修改代碼x的信息(Y(x)).該層的輸出為

Diff-attention 層.針對代碼x進行修改時,所修改的方式依賴于給定修改示例xΔ→yΔ.因此,在后續的代碼指令預測過程中,模型需要修改示例的差異信息.本文方法利用該層來實現在指令序列的編碼結果中,引入xΔ→yΔ的信息(Y(diff)).該層的輸出為

Graph-conv 層.由已生成的代碼指令可以構造出局部的抽象語法樹,而預測的指令均會對應特定的節點,因此,指令(節點)間存在有意義的結構關系.然而,以指令序列的形式表示已生成的抽象語法樹,將會遺失指令間的結構信息.因此,本文方法采用一層圖卷積層,利用代碼的抽象語法樹的結構信息來增強指令的編碼信息.
依據指令對應節點的鄰接關系,可以獲得一個指令間的鄰接矩陣Mp*p.當M[i][j]=1 時,表示指令rj(對應的節點)為指令ri(對應的節點)的父節點.基于此,該層的輸出為

最終AST 編碼器的輸出為R(ast).
4.4 解碼器
解碼器以當前待擴展的非葉子節點為輸入,即Q(d)=[q1;…;qR],其中,qi為每個待擴展節點的表示向量.由于解碼器仍然遵循多塊的設計,因此在第1 塊中,qi為節點對應的語法類型或單詞信息;而在其他塊中,qi則為上一個塊的輸出.解碼器的目標是生成查詢矩陣其中,為第i個節點相應的查詢向量,方法將依據預測第i條指令.解碼器首先利用Self-attention 層來獲取待擴展節點間的依賴關系.然后,數據流將依次經過AST-attention 層、Code-attention 層和Diff-attention 層,分別用于獲取抽象語法樹、待修改代碼和修改示例的信息.具體地:
Self-attention 層.在上述查詢矩陣中,每個查詢分量qi均代表抽象語法樹中的一個待擴展的節點的信息.在代碼的抽象語法樹中,不同節點彼此間存在不同程度的依賴關系,因此,我們利用一層Self-attention 層來捕獲查詢間(即節點間)的依賴關系,該層的輸出為

Ast-attention 層.本文方法利用該層實現利用已產生的抽象語法樹的信息(即Y(ast))增強查詢信息.在該層中,Q=D(self),K=Y(ast),V=Y(ast),輸出為

Code-attention 層.本文方法利用該層實現待修改代碼x的信息(即Y(x))增強查詢信息.在該層中,Q=D(ast),K=Y(x),V=Y(xt).輸出為

Diff-attention 層.本文方法利用該層實現利用修改示例xΔ→yΔ的信息(即Y(diff))增強查詢信息.在該層中,Q=D(x),K=Y(diff),V=Y(diff),輸出為
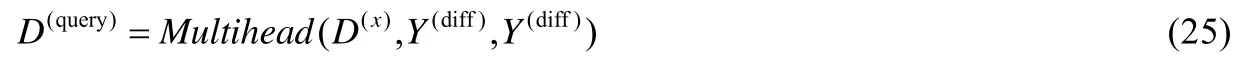
最終,解碼器的輸出為D(query).
4.5 指令預測
在預測下一條指令時,模型的預測范圍將來自于兩種類型的指令.首先,在我們處理數據時,獲取了標準數據指令集R={r1,r2,…,rN},該指令集能夠滿足正常的代碼生成需要.然而,在代碼中變量名定義和使用存在依賴關系.為了捕獲這種依賴關系,方法增設了指令copy(n),表示復制已產生指令中第n條指令中的變量名.在預測第i條指令時,除了計算指令rj的概率p(rj)以外,方法還將依據指針網絡計算p(copy(t))的概率.因此,最終的第i條指令預測結果需要從指令rj和copy(t)中進行選擇.本文將采用下列公式所示的門機制來對兩種類型的指令進行篩選:

其中,g表示當前預測指令屬于R的概率,亦即指令為copy 的概率為1-g.最終預測的指令為op=argmaxopp(op).
其中,本文將按照公式(27),計算下一條指令為rj的概率p(rj):

在預測第i條指令時,copy 指令所復制的變量名來自于前i-1 條指令中聲明的變量,因此,本文方法將按照下列公式來計算p(copy(t)):
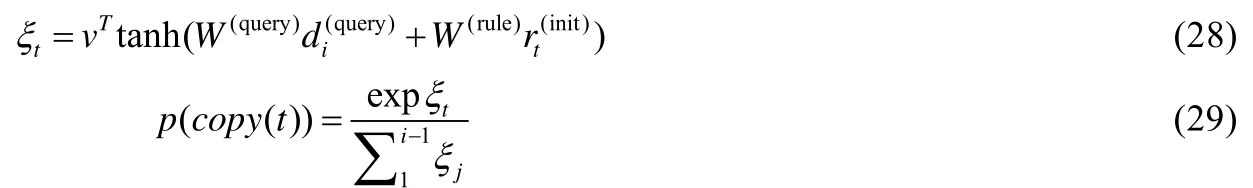
其中,1≤t≤i–1,為已產生的第t條指令的表示向量,W(query)和W(rule)為網絡參數.
5 方法驗證
本文開展了兩個實驗,分別將本文方法與現有的基于深度學習的方法以及基于人工規則的方法進行對比,以驗證方法的有效性.
5.1 實驗1
該實驗通過與現有的基于深度學習的方法進行對比,以驗證本文方法的有效性.
(1) 數據集.該實驗在Yin 等人的數據集[13]上來驗證本文方法的有效性.在Yin 等人的工作中,他們從Github上收集了54 個C#開源項目,然后從這些軟件項目的提交歷史中抽取并篩選出111 724 處C#代碼修改,其中,91372/10176/10176 條數據分別用于訓練/驗證/測試.在該數據集中,數據示例均可表示為〈xi,yi〉的形式,其中,xi為修改前的代碼,yi為修改后的代碼.依據實例〈xi,yi〉,將其轉換為數據〈xi,xi→yi,yi〉的形式,并按照模型輸入要求進行預處理.具體地,首先將xi和yi解析為抽象語法樹的形式,并按照由上至下、從左到右的順序,獲取節點序列此外,依據yi對應的抽象語法樹,獲取指令序列[r1,…,rR].其中,修改前的代碼節點序列作為代碼編碼器的輸入,長度為L(ori);將修改前、后代碼的節點序列進行拼接,作為代碼差異編碼器的輸入,長度為L(ori)+L(mod);指令序列作為模型預測目標,長度為P.表1 列出了該數據集中數據的4 種長度的分布情況.如表中第2 行所示,92.2%的實例的長度L(ori)小于100,7.7%的實例的長度L(ori)處于101~200 之間,0.1%的實例的長度L(ori)處于201~300 之間,最大長度為239.此外,本文對預處理后的數據中所包含的單詞進行統計,共發現2 931 個獨有單詞,其中最大字符長度為70,且80.3%的單詞的字符長度少于20 個.
(2) 對比方法.Yin 等人的工作是目前與本文工作最為相關的最新工作[13].在該工作中,作者通過表示示例代碼中的修改方式,并用于指導代碼轉換.在該工作中,作者還嘗試利用不同的方式來表示代碼和修改示例,并驗證不同模型的組合的方法效果.
(3) 參數設置.為了獲取較優的Transformer 架構的塊數設置,方法分別將塊數設為4、6 和8,且實驗結果表明,當塊數為6 時,模型效果最佳(具體結果見表3).因此,方法最終將代碼差異編碼器、代碼編碼器、AST 編碼器和解碼器的塊數(即N1/N2/N3/N4)設為6.此外,如表1 所示,由于所有的代碼長度都小于300,且超過98%的代碼差異長度小于300,因此代碼差異編碼器和代碼編碼器的最大輸入長度L被設定為300.同時,所有數據實例的指令長度均小于200,且最大長度為185,因此,模型允許最大的指令長度P被設定為200.此外,還有超過80%的單詞的字符≤20,且最大長度為70,因此,方法將模型允許單詞的最大長度L'設定為20,意在保證該值能夠覆蓋到大多數單詞的同時,避免引入過多的占位符而影響模型效果.
(4) 實驗過程.在與Yin 等人的方法進行對比時,本文沿用了他們的實驗設置,并利用其數據集的訓練集和驗證集來訓練本文方法.然后,利用測試集來測試本文方法,即方法是否能夠將修改前的代碼xi正確地轉換為yi.
(5) 評估標準.本文主要采用準確率來量化方法的效果.給定一條數據〈x,xΔ→yΔ,y〉,其中,x為修改前的代碼,xΔ→yΔ為修改示例,y為修改后的代碼.若方法的預測結果與y完全相同,則稱x被正確地修改.本文將方法的準確率定義為

(6) 實驗結果.表2 展示了與Yin 等人方法對比后的實驗結果.從實驗結果來看,較之Yin 等人提出的不同的模型,本文方法在準確率上提升了11.8%~30.8%.在Yin 等人的工作方法中,他們采用了兩個不同的子模塊分別用于編碼待修改代碼的信息和修改示例的信息.同時,他們還嘗試了兩種不同思路以對信息進行建模,即基于單詞序列的方式和基于圖結構的方式,并探索了信息建模方式的不同組合的實際效果.僅從Yin 等人的工作結果來看,基于單詞序列模型(如Seq2Seq-Seq)的結果要比基于圖結構模型(如Graph2Tree-Graph)的結果更優.導致這種結果的原因在于實驗數據的特殊性.由于模型輸入的修改示例包含了待修改代碼的修改結果信息,反而更有利于基于單詞序列的模型預測修改結果.
反觀本文方法ExpTrans 的結果,若單獨與Yin 工作中的基于圖結構的模型進行對比,ExpTrans 在準確率上提升了23.4%,這表明,ExpTrans 采用圖的形式來表示修改示例,并結合卷積神經網絡的方式,能夠有效增強模型對代碼的結構信息的捕獲能力,從而使得方法的準確率有了大幅度的提升.與Yin 等人基于單詞序列的方法進行對比,ExpTrans 同樣具有至少11.8%的提升.這些實驗結果表明,本文方法是有效的.
此外,在模型ExpTrans 中,Transformer 架構的塊數、copy 指令和模型的不同模塊對代碼轉換效果均有一定程度的影響.因此,基于ExpTrans,本文通過修改模型的架構或參數設置,產生了不同的變體,以此探究上述因素在ExpTrans 轉換代碼過程中的有效性.表3 列出這些變體的具體設置及實驗結果.
首先,為了尋求模型中Transformer 架構層數較優的設置,本文借鑒了Vaswani 等人的工作[14],先后將模型的層數設置為4、6 和8,具體的實驗結果如表3 中(A)行所示.從結果可以看出,當層數設置為4 時,方法的準確率為67.37%,較之層數為6 時,下降4.08%.當層數設置為8 時,準確率為64.37%.鑒于上述結果,最終將ExpTrans中Transformer 的層數設置為6 層.
同時,為了驗證copy 指令的有效性,本文再次將ExpTrans 應用于Yin 等人提供的數據集上.所不同的是,在處理該數據集時,取消了copy 指令.具體的實驗結果如表3 中(B)行所示.如結果顯示,當指令集中不含copy 指令時,模型的準確下降為60.12%,該結果表明,增設的copy 指令能夠有效地提升模型對代碼間長程依賴的捕獲能力,并提升方法的準確性.
最后,本文通過分別刪除模型中的代碼差異編碼器以及代碼差異編碼器和代碼編碼器中的圖卷積層,來驗證它們的必要性.具體結果如表3 中(C)行所示.當刪除代碼差異編碼器時,方法的準確率驟降為6.36%.該實驗結果充分說明,在代碼自動轉換時,給定一個或一組實例修改的必要性,同時也說明了ExpTrans 中的代碼差異編碼器的有效性.另外,當分別刪除代碼差異編碼器和代碼編碼器中圖卷積層后,模型的準確率分別下降為68.01%和65.69%.在取消圖卷積層的情況下,模型實際處理輸入數據的效果等同于處理線性的單詞序列,失去了代碼自身的結構信息.這些結果表明,本文方法采用圖卷積的方式能夠有效地捕獲代碼的結構信息,并增強模型的轉換能力,提升模型效果.

Table 1 Data length distribution in the first experiment表1 實驗1 中數據長度分布

Table 2 The comprative results with the work of Yin,et al表2 與Yin 等人方法的對比實驗結果

Table 3 Performances of different variations on ExpTrans表3 ExpTrans 的不同變體及實驗結果
5.2 實驗2
該實驗通過與現有的基于人工規則的方法進行對比,來驗證本文方法的有效性.
1) 數據集.由于所對比的基于人工規則的方法是針對Java 語言的,因此我們又收集了Java 語言的代碼修改數據集.在收集該數據之前,我們查閱了Java 語言在不同版本上新增的功能,選出其中5 種并總結了可能導致的修改模式.表4 列出了所選出的Java 功能和相應的修改模式.基于每種功能,構造相應的查詢語句,并在Github上搜索相關的commit.依據搜索結果,人工地為每個查詢篩選出10 個具有相應修改模式的代碼修改,即為相似代碼修改.
2) 對比方法.在本實驗中,對比了兩種基于人工特征的代碼轉換方法GenPat 和ARES.
(1) GenPat[17].該方法是一種基于單示例的代碼轉換方法,其通過將給定的單個修改示例解析為抽象語法樹,對抽象語法樹上的特定節點的屬性進行了泛化或限制,并標注抽象語法樹的節點的變化過程.在代碼轉換時,GenPat 將根據抽取的抽象語法樹進行代碼匹配,并利用標注的節點的變化過程對代碼進行轉換.
(2) ARES[10].該方法是一種基于多示例的代碼轉換方法,其利用模板來表示修改示例中的修改模式.在模板中保留了修改示例中的共有部分,而采用通配符的形式對不同的部分進行泛化.在代碼轉換時,ARES 將依據抽取的模版對代碼進行匹配,并利用模版所刻畫的修改結果模式,對匹配成功的代碼進行修改.

Table 4 The corresponding query sentences and change patterns of different Java features表4 不同Java 功能對應的查詢語句和修改模式
3) 實驗過程.在該實驗中,本文按照搜集的6 組相似代碼修改分別進行實驗.具體地,給定一組相似修改集合P={p1,…,p10},其中,代碼修改pi=〈xi,yi〉,xi為修改前的代碼,yi為修改后的代碼.為了訓練本文方法,我們基于集合P,進行了如下方式的構造:
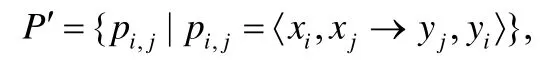
其中,1≤i,j≤10,pi,j所代表的含義是利用pj的修改模式對代碼xi進行修改,并且按照如下方式將P'分為:
訓練集:{pi,j},1≤i≤10,1≤j≤8;
驗證集:{pi,j},1≤i≤10,j=9;
測試集:{pi,j},1≤i≤10,j=10.
在實驗時,分別利用3 種方法對測試集中的實例進行修改.由于ARES 是一種基于多示例的代碼轉換方法,因此,我們將P作為一組相似代碼變更提供給ARES,以供ARES 抽取所需的代碼修改模式.
參數設置.在該實驗中,本文方法中的模型參數沿用了實驗1 中的參數設置.
實驗結果.我們將方法的輸出結果分為4 種.
○ 表示方法無法從給定的修改示例中抽取出統一的修改模式,導致方法無輸出.
表5 中展示了方法在6 組數據上的對比實驗結果.結果表明,ExpTrans 要明顯優于其他兩種對比方法.ExpTrans 在所有組別上,均有正確的修改示例,尤其是在第2 組數據上,ExpTrans 能夠將全部的代碼實例修改成功.我們人工檢查了ExpTrans 修改錯誤的實例,發現這些錯誤實例主要發生在預測同一個函數的多個參數時.其可能的原因是,ExpTrans 在預測函數的參數時,缺乏參數的序列位置信息,從而導致錯誤的預測結果.例如,一個預期結果為byteBufferReadCheck(in,buf,11);,而ExpTrans 的預測結果為byteBufferReadCheck(in,11,11);,其中,11為錯誤預測的參數.
進一步地,我們檢查了GenPat 和ARES 的輸出結果,以探究導致兩種方法結果不理想的原因.
方法GenPat 失效的原因在于:(1) 方法依賴于待修改的代碼與修改示例代碼的結構和語法類型的相似性.例如,“return new Double(0.0);”→“return new Double.valueOf(0.0);”中的修改方式,由于語法類型不同,導致無法用于修改代碼“val=new Double(0.0);”.而在本實驗所獲取的數據中,無法保證相似的代碼修改具有相似的結構和語法特征.因此,導致GenPat 從示例中抽取的修改模式無法適配于待修改的代碼(類型).(2) GenPat 需要利用代碼中變量的定義信息.然而,由于獲取代碼修改時,只抽取了發生修改的代碼片段,因而無法保證抽取的代碼修改中同時包含所有涉及的變量的定義.由于GenPat 無法獲取足夠的信息,因此在將抽取的模式匹配待修改的代碼時,產生錯誤匹配,從而導致錯誤修改(類型?).
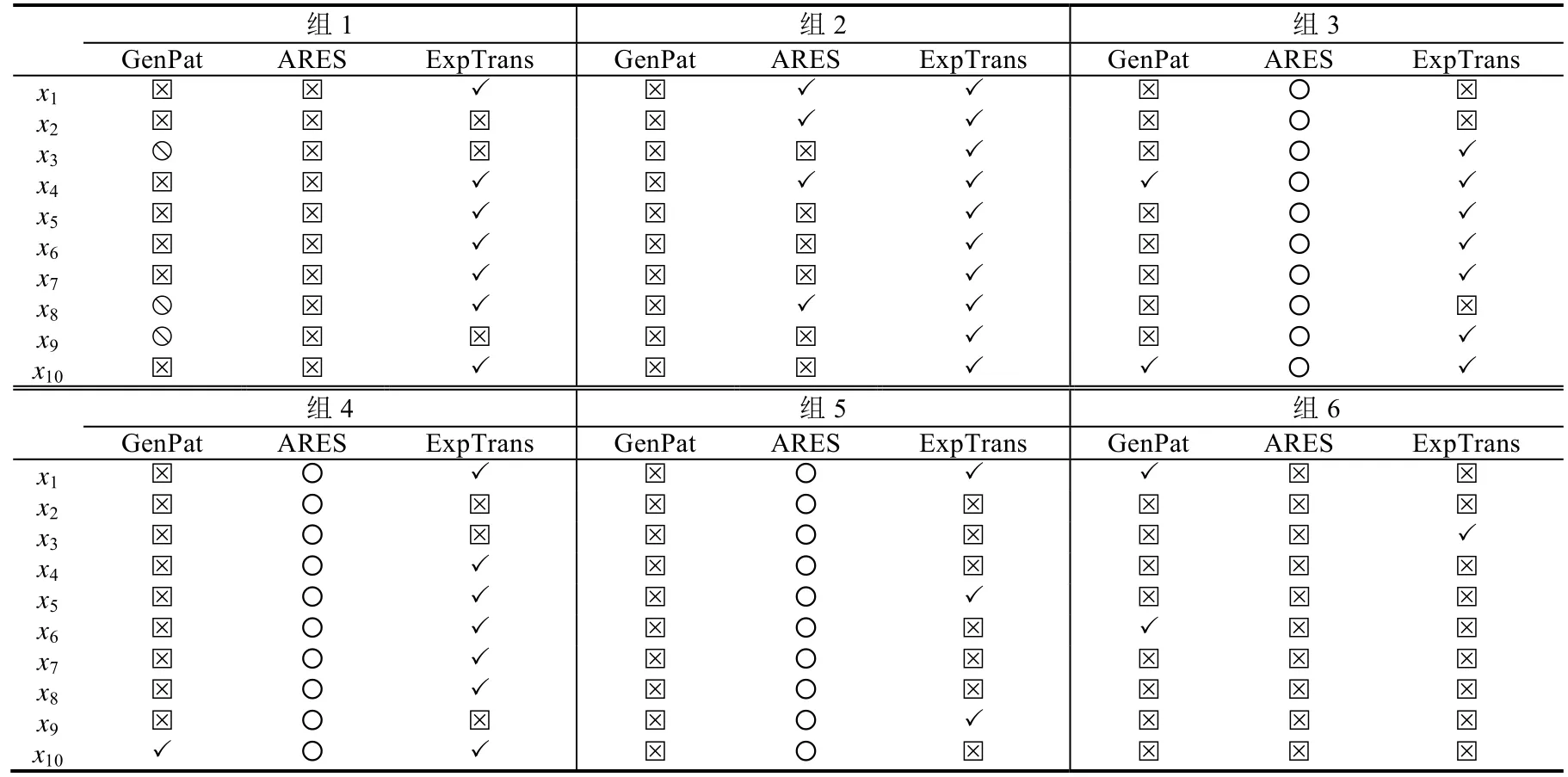
Table 5 The comprative results with GenPat and ARES表5 ExpTrans 方法與GenPat 和ARES 方法的對比實驗結果
由于ARES 方法是一種基于多示例的代碼轉換方法,因此,當給定一組相似代碼修改示例時,ARES 需要對修改示例中的不同部分進行泛化,以使其表示的修改模式能夠擬合給定的修改示例.然而,當給定的修改示例的修改語義相似但結構不同時,容易導致方法無法抽取出統一的修改模式.例如,在實驗中我們發現,ARES 無法從組別2、4、6 的數據中抽取統一的修改模式,因此也無法完成對相應代碼的修改(類型○).此外,還有一些錯誤實例是因為ARES 在抽取的模式中,保留了修改示例所特有的變量名.因此,在將抽取的模式適配到待修改的代碼時,所修改的結果中引入了這些變量名,導致修改失敗(類型?).
5.3 討 論
方法適用范圍.在本文方法中,我們針對輸入的待修改代碼x和修改示例xΔ→yΔ,預設了最大長度.當代碼長度超過預設長度時,超過預設長度的代碼內容將被截取.這在一定程度上影響了方法能夠使用的代碼修改場景.但在一些頻繁發生的相似修改任務中,例如API 版本遷移,所修改的代碼往往是局部的、簡短的,因此,方法預設最大的長度并不會嚴重制約本文方法的實用性.盡管如此,在未來的工作中,我們仍需嘗試提出不同的網絡模型以降低修改代碼長度對方法的影響.
數據規模.在收集Java 數據時,依賴于人工對搜索結果的篩選,這限制了本文收集數據的規模和效率,也一定程度地制約了挖掘方法更大的潛力.在未來的工作中,我們將嘗試利用自動化的方式來大規模地收集數據,盡量在降低人力代價的情況下,提升方法的效果.
6 總結
在本文中,我們提出了一種基于深度學習的代碼轉換方法.通過采用圖形式來表示修改示例,并結合卷積網絡和Transformer架構,增加了方法捕獲代碼結構信息的能力.實驗結果表明,我們的方法比現有的基于深度學習和基于人工規則的方法,其效果有著較為明顯的提升.針對可能影響方法有效性的因素,我們將在未來的工作中,通過提出優化模型和自動化的數據收集方法,來降低這些因素對方法的影響.
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
機電信息(2014年27期)2014-02-27 15:53:56
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
海外英語(2006年8期)2006-09-28 08:49:00
