基于改進DNN的糖尿病預(yù)測模型設(shè)計
2021-05-20 07:02:48林建君朱習(xí)軍
計算機工程與設(shè)計 2021年5期
李 儀,林建君,朱習(xí)軍
(青島科技大學(xué) 信息科學(xué)技術(shù)學(xué)院,山東 青島 266061)
0 引 言
近年來,許多研究者對糖尿病醫(yī)療數(shù)據(jù)進行了大量的研究,對于醫(yī)療結(jié)構(gòu)化數(shù)據(jù),使用了許多機器學(xué)習(xí)算法來構(gòu)建預(yù)測模型[1,2]。傳統(tǒng)的機器學(xué)習(xí)算法如K均值、決策樹、SVM、貝葉斯算法等,都對糖尿病結(jié)構(gòu)化數(shù)據(jù)進行了分析并構(gòu)造了糖尿病預(yù)測模型,取得了較好的效果[3-5]。除了傳統(tǒng)的算法外,研究者提出將深度學(xué)習(xí)應(yīng)用于結(jié)構(gòu)化醫(yī)療數(shù)據(jù)中,該研究者利用深度神經(jīng)網(wǎng)絡(luò)模型,構(gòu)建了糖尿病分類模型,也取得了良好的分類效果[6-8],這表明深度學(xué)習(xí)技術(shù)在處理結(jié)構(gòu)化醫(yī)療數(shù)據(jù)來預(yù)測疾病時的有效性。同時機器學(xué)習(xí)和深度學(xué)習(xí)的混合模型也逐漸得到應(yīng)用。機器學(xué)習(xí)和深度學(xué)習(xí)的混合,結(jié)合了其技能和優(yōu)勢,可以有效輔助醫(yī)生進行糖尿病預(yù)測診斷[9]。
利用深度學(xué)習(xí)進行結(jié)構(gòu)化醫(yī)療數(shù)據(jù)研究的方法不多,CNN、RNN等深度學(xué)習(xí)模型適用于非結(jié)構(gòu)化數(shù)據(jù),本文采用深度神經(jīng)網(wǎng)絡(luò)(deep neural networks,DNN)對結(jié)構(gòu)化數(shù)據(jù)進行研究,提出將深度神經(jīng)網(wǎng)絡(luò)與批歸一化(batch normalization,BN)層相結(jié)合,利用改進的DNN模型結(jié)合機器學(xué)習(xí)技術(shù),對結(jié)構(gòu)化糖尿病數(shù)據(jù)進行分析,并對該模型進行評估。
1 數(shù)據(jù)預(yù)處理
本文使用UCI公開提供的皮馬印第安人糖尿病數(shù)據(jù)集(PIMA indians diabetes data set,PIDD)進行實驗,該數(shù)據(jù)集由美國國立糖尿病、消化和腎臟疾病研究所提供。PIDD數(shù)據(jù)集包含768個樣本,有8個特征屬性和1個標(biāo)簽屬性,所有屬性都是數(shù)值型數(shù)據(jù),其中8個特征屬性見表1。

表1 數(shù)據(jù)集特征屬性
標(biāo)簽屬性值為0和1,其中0代表未患有糖尿病,1代表患有糖尿病。通過統(tǒng)計分析,標(biāo)簽值為0的樣本個數(shù)為500個,標(biāo)簽值為1的樣本個數(shù)為268個,分布情況如圖1所示。
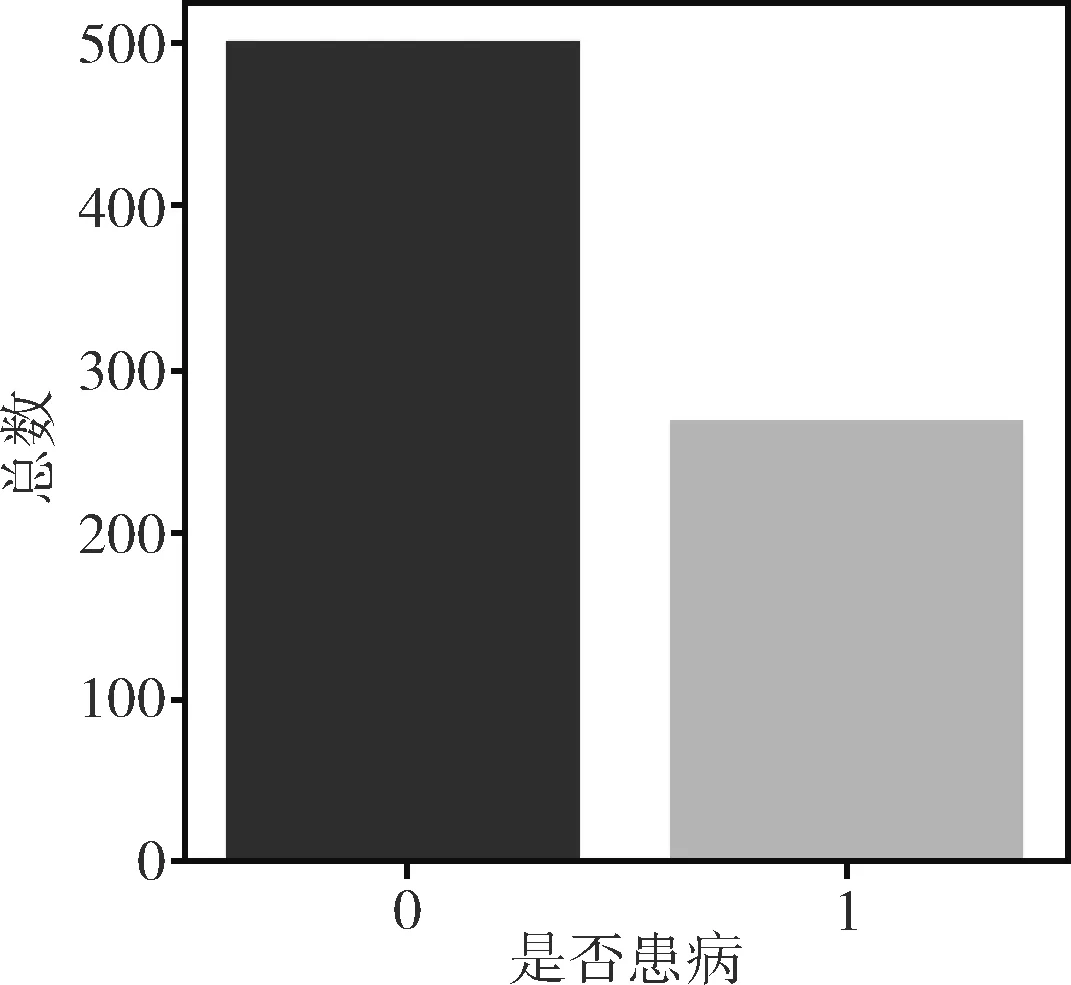
圖1 數(shù)據(jù)集標(biāo)簽分布
本文對數(shù)據(jù)進行預(yù)處理主要包括兩個方面:缺失值處理、數(shù)據(jù)標(biāo)準(zhǔn)化。
(1)缺失值處理常用方法包含刪除法、插補法。刪除法主要用于刪除缺失數(shù)據(jù),適用于樣本數(shù)據(jù)量大的情況。插補法利用缺失值變量的均值、中位數(shù)或眾數(shù)來填充變量中的缺失值。
PIDD數(shù)據(jù)集包含大量為零的數(shù)值,如舒張壓為零、胰島素含量為零、體重指數(shù)為零等,這些零值是沒有意義的,需要進行缺失值處理。因為該數(shù)據(jù)集數(shù)據(jù)量不大,本文采用均值插補方法進行缺失值填充。將原始數(shù)據(jù)集分為糖尿病組和非糖尿病組,計算每組各屬性的平均值,然后用各屬性平均值代替其缺失值,同時對于異常值,也用平均值代替。將處理后的數(shù)據(jù)集合成一個新的數(shù)據(jù)集用于后續(xù)建模。
(2)數(shù)據(jù)標(biāo)準(zhǔn)化是將原始數(shù)據(jù)按比例縮放,使之落入特定區(qū)間,去除數(shù)據(jù)的單位限制,對其進行無量綱化處理,本文采用區(qū)間縮放法進行標(biāo)準(zhǔn)化,將不同屬性列的數(shù)據(jù)轉(zhuǎn)換為同一量綱,將數(shù)據(jù)映射到[0,1]區(qū)間上,常見的有min-max方法,可利用python sklearn模塊中的StandardScaler()、MinMaxScaler()等函數(shù)進行計算,計算公式如下
(1)
其中,max是樣本屬性最大值,min是樣本屬性最小值。
2 特征選擇
2.1 特征關(guān)聯(lián)性分析
對數(shù)據(jù)集的特征進行處理,分析特征之間的關(guān)聯(lián)程度,使用python pandas包中的corr函數(shù)計算特征之間的皮爾遜相關(guān)系數(shù),相關(guān)系數(shù)趨向于1時,表明兩者關(guān)聯(lián)程度大;相關(guān)系數(shù)為0時,表明兩者相互獨立。通過熱力圖的形式展示各特征的關(guān)聯(lián)情況,如圖2所示。圖中橫軸和縱軸特征之間的顏色越淺表明特征之間相關(guān)系數(shù)越小,其關(guān)聯(lián)程度越小;顏色越深表明特征之間相關(guān)系數(shù)越大,其關(guān)聯(lián)程度越大。對圖1進行分析可以得出,該數(shù)據(jù)集中大部分特征之間的相關(guān)程度較弱,說明大部分?jǐn)?shù)據(jù)之間冗余較小。但是個別特征之間的顏色較深,如Age(年齡)和Pregnancies(懷孕次數(shù)),代表這兩個特征之間相關(guān)程度較大,存在冗余。對于關(guān)聯(lián)程度較強的特征需要進一步判斷其對預(yù)測結(jié)果的貢獻程度,再進行處理。
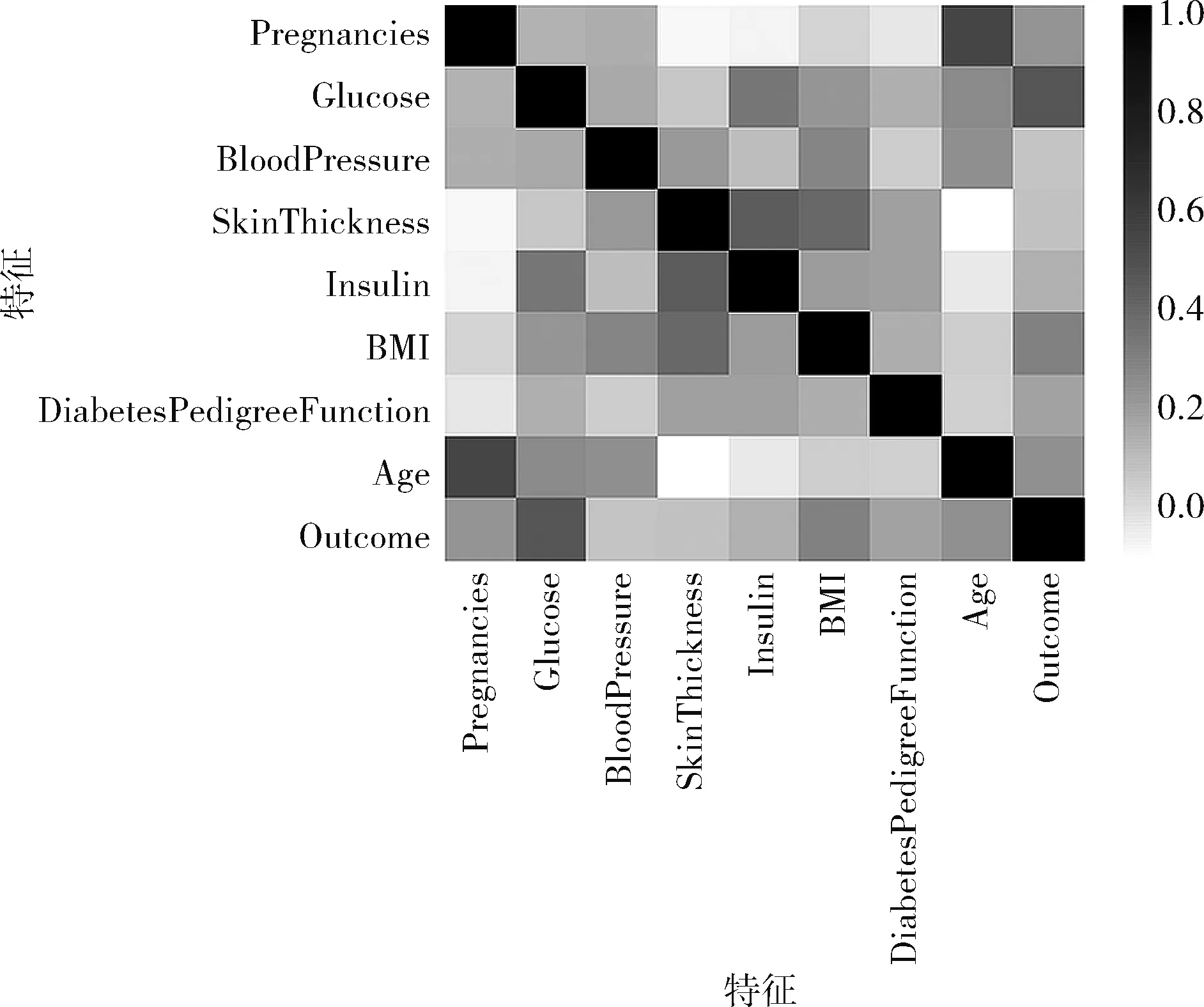
圖2 特征關(guān)聯(lián)性分析
2.2 特征選擇算法
根據(jù)特征關(guān)聯(lián)性分析,得到個別特征之間存在一定的冗余,說明數(shù)據(jù)集中有的特征對實驗的實現(xiàn)沒有作用,需要篩選出有用的特征。特征選擇就是從數(shù)據(jù)集所有特征中除去冗余的特征,選擇最優(yōu)特征的過程。特征選擇可以把高維數(shù)的特征轉(zhuǎn)化為低維數(shù)的特征,經(jīng)過處理后的特征作為模型的輸入,可以提高模型的穩(wěn)定性和準(zhǔn)確率。
XGBoost算法是GBDT(gradient boosting decision tree)算法的改進,以CART樹為組合,負(fù)梯度為學(xué)習(xí)策略的一種基于boost的集成學(xué)習(xí)算法。具有高效率、高準(zhǔn)確率、高并發(fā)的優(yōu)點,在分類、回歸、特征選擇等方面得到廣泛應(yīng)用。在特征選擇方面,XGBoost算法可以通過計算特征的重要性對特征進行選擇,特征重要性表示特征在構(gòu)建提升樹起的作用。如果一個特征在所有樹中作為劃分屬性的次數(shù)越多,表明該特征越重要,由算法中評判特征重要程度指標(biāo)weight表示。通過計算特征和預(yù)測結(jié)果之間的關(guān)聯(lián)性,得到每個特征對預(yù)測結(jié)果的影響權(quán)重,以此得到每個特征的重要性,并對特征重要性進行排序[10,11]。
本文運用XGBoost算法對PIDD數(shù)據(jù)集中8個屬性進行特征選擇,輸出每個特征對預(yù)測結(jié)果的影響程度,并輸出影響程度的排名即特征重要性排名。實驗結(jié)果如圖3所示,通過圖示可得Glucose(血糖值)、DiabetesPedigreeFunction(糖尿病譜系功能)、BMI(體重)、Age(年齡)、BloodPressure(舒張壓)、SkinThickness(皮脂厚度)、Pregnancies(懷孕次數(shù))、Insulin(胰島素含量)對預(yù)測結(jié)果影響程度依次減小。本文實驗選擇得分最多的前五名,Glucose(血糖值)、DiabetesPedigreeFunction(糖尿病譜系功能)、BMI(體重)、Age(年齡)、BloodPressure(舒張壓)為重要特征,組成特征子集用于模型的訓(xùn)練。
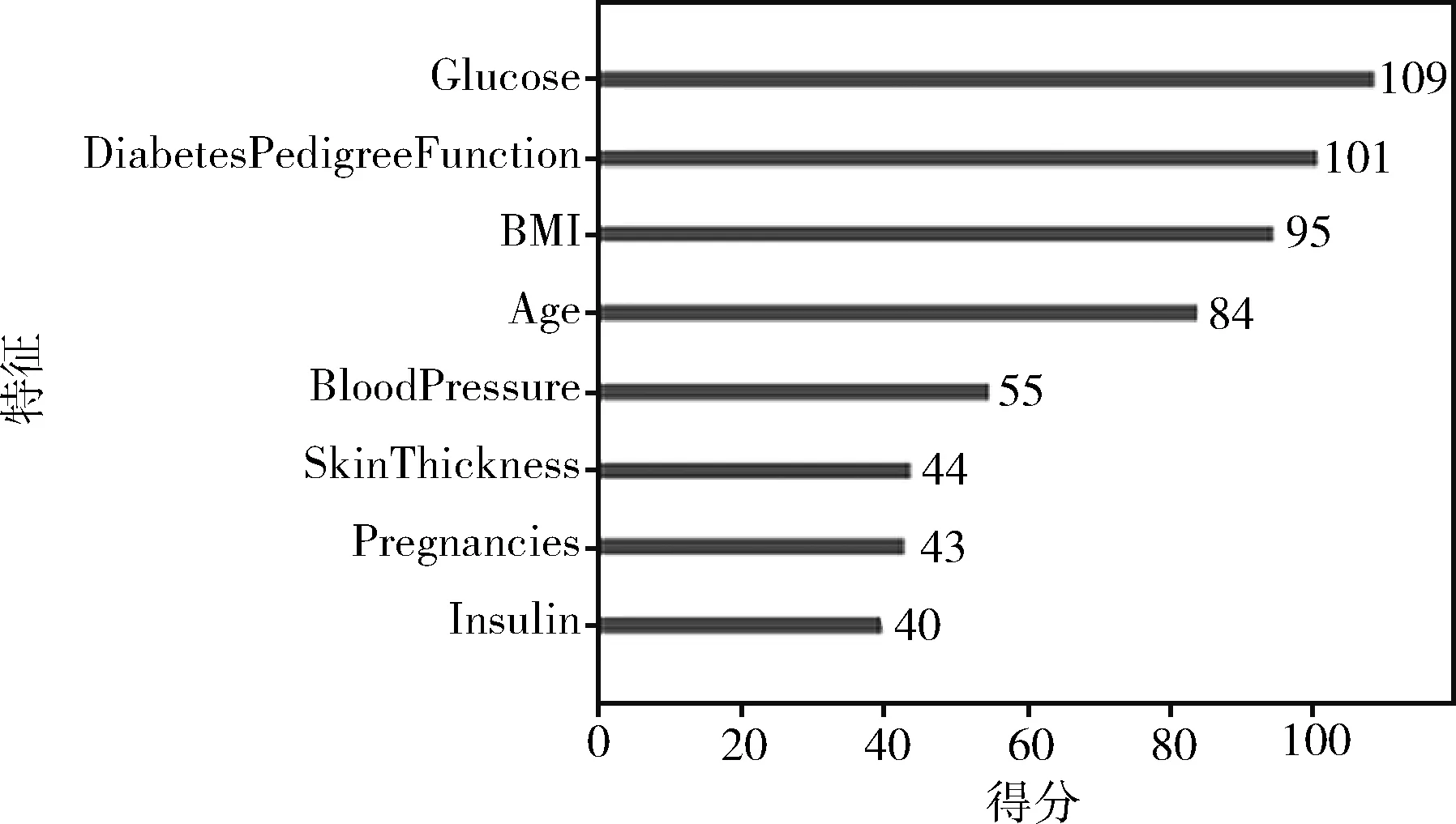
圖3 特征影響程度排名
3 模型設(shè)計
3.1 模型體系結(jié)構(gòu)
本文模型體系結(jié)構(gòu)主要包括數(shù)據(jù)預(yù)處理、特征選擇,搭建改進的DNN模型-BNDNN模型,并進行訓(xùn)練,將測試數(shù)據(jù)集輸入訓(xùn)練好的模型用于預(yù)測,最后進行模型性能評估,模型體系結(jié)構(gòu)如圖4所示。

圖4 模型體系結(jié)構(gòu)
3.2 DNN網(wǎng)絡(luò)結(jié)構(gòu)
深度神經(jīng)網(wǎng)絡(luò)(deep neural networks,DNN)為包含多個隱藏層的神經(jīng)網(wǎng)絡(luò),有時也叫多層感知機。感知機模型由若干個輸入和一個輸出組成,輸入和輸出之間為線性關(guān)系,如圖5所示。
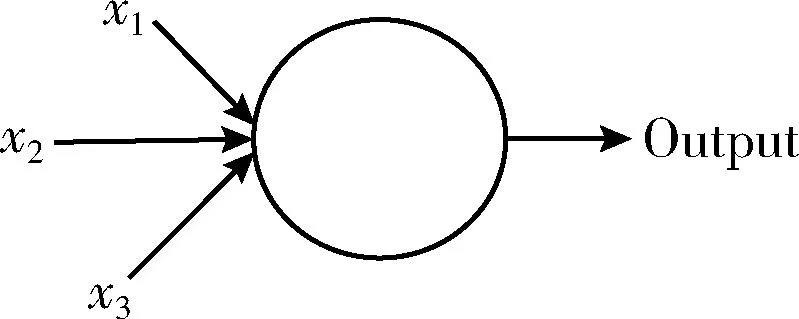
圖5 感知機模型
計算得到中間輸出結(jié)果
(2)
中間輸出通過神經(jīng)元激活函數(shù),得到分類結(jié)果。感知機模型只能進行二元分類,無法用于復(fù)雜的非線性模型,因此神經(jīng)網(wǎng)絡(luò)在感知機模型基礎(chǔ)上進行了擴展。增加隱藏層,增強了模型的計算能力,提高了模型的復(fù)雜度;增加輸出層神經(jīng)元個數(shù),以此增加輸出,可以應(yīng)用于多分類、回歸等問題;增加激活函數(shù),如Sigmoid、tanx、softmax、ReLU函數(shù)等,不同的激活函數(shù)可以增強神經(jīng)網(wǎng)絡(luò)的表達(dá)能力。
DNN神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)如圖6所示,包含1個輸入層、1個輸出層和n個隱藏層,層與層之間神經(jīng)元為全連接。DNN分為前向傳播和反向傳播。對數(shù)據(jù)進行預(yù)處理后,進行前向傳播,將數(shù)據(jù)從輸入層輸入經(jīng)過n個隱藏層得到計算結(jié)果最后傳入輸出層,利用輸出層得到的結(jié)果與期望結(jié)果進行比較得到誤差,反向傳播通過梯度下降將誤差從輸出層經(jīng)過隱藏層傳入輸入層,這一過程為一輪神經(jīng)網(wǎng)絡(luò)的訓(xùn)練[12]。
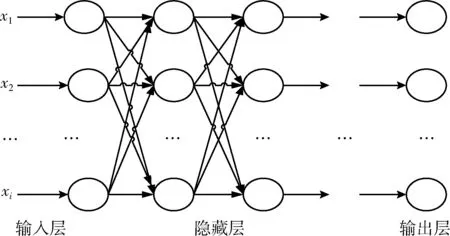
圖6 DNN網(wǎng)絡(luò)結(jié)構(gòu)
3.3 批歸一化
DNN的輸入在進行非線性變換前,隨著網(wǎng)絡(luò)層數(shù)的增加,在訓(xùn)練過程中其分布會逐漸往非線性函數(shù)取值區(qū)間的上下限靠近,會導(dǎo)致梯度消失,優(yōu)化函數(shù)越來越容易陷入局部最優(yōu)解,這些問題的出現(xiàn)使得模型訓(xùn)練速度變慢,準(zhǔn)確率降低。批歸一化BN層在神經(jīng)網(wǎng)絡(luò)層中進行預(yù)處理操作,將每個神經(jīng)網(wǎng)絡(luò)層的輸出結(jié)果進行歸一化處理后再進入下一層,將每層神經(jīng)網(wǎng)絡(luò)的輸入值分布重新拉回標(biāo)準(zhǔn)正態(tài)分布,使其落在激活函數(shù)的敏感區(qū)間。同時降低了對神經(jīng)網(wǎng)絡(luò)參數(shù)初始化的要求,增強了網(wǎng)絡(luò)層之間的獨立性,增大反向傳播的梯度,因此可以有效地避免梯度消失等現(xiàn)象,與Dropout相同可以防止過擬合現(xiàn)象,加快了網(wǎng)絡(luò)訓(xùn)練,提高模型的準(zhǔn)確度[13]。BN算法流程如下所述:
輸入:數(shù)據(jù)x1…xm
輸出:(1)計算每一個訓(xùn)練批次數(shù)據(jù)的均值μβ
(3)
(4)
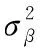
(5)
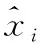
(6)
(5)數(shù)據(jù)完成批歸一化操作后進入下一個網(wǎng)絡(luò)層。
z=g(wx+b)
(7)
DNN引入BN層時,其作用于非線性激活函數(shù)之前,如式(8)所示
z=g(BN(wx+b))
(8)
3.4 Adam優(yōu)化算法
Adam(adaptive moment estimation)算法通過計算梯度的一階矩估計和二階矩估計對不同參數(shù)學(xué)習(xí)率的取值進行調(diào)整,Adam算法是一種替代隨機梯度下降的優(yōu)化算法[14]。Adam的每一次迭代,學(xué)習(xí)率都被限制在一個大致的范圍,使得參數(shù)平穩(wěn),解決學(xué)習(xí)率消失、稀疏梯度、噪聲等問題。Adam算法更新公式如下
(9)
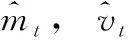
(10)
(11)
β1和β2為常數(shù),mt為對梯度的一階矩估計,vt為對梯度的二階矩估計。mt、vt的更新如下,其中g(shù)t為一階導(dǎo)
mt=β1×mt-1+(1-β1)×gt
(12)
(13)
3.5 L2正則化
若數(shù)據(jù)量較少、網(wǎng)絡(luò)參數(shù)權(quán)重過大時,在網(wǎng)絡(luò)訓(xùn)練過程中會存在訓(xùn)練過度產(chǎn)生過擬合現(xiàn)象,可以通過正則化方法對網(wǎng)絡(luò)模型參數(shù)設(shè)定先驗,防止模型過擬合。L2正則化方法為在損失函數(shù)中增加一個正則化項,對權(quán)重參數(shù)進行影響,如以下公式所示
(14)
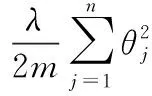
3.6 DNN模型的改進
為解決DNN網(wǎng)絡(luò)模型易出現(xiàn)的局部最優(yōu)解、梯度消失等現(xiàn)象,本文對普通DNN網(wǎng)絡(luò)結(jié)構(gòu)進行了改進,增加了BN層構(gòu)建BNDNN模型,BNDNN網(wǎng)絡(luò)結(jié)構(gòu)如圖7所示。該模型構(gòu)造了5個全連接層,包含3個隱藏層,1個輸入層,1個輸出層。從輸入層到輸出層神經(jīng)元個數(shù)分別為70、20、20、5、1,在輸入層后和輸出層前增加了BN層。本文采用的糖尿病數(shù)據(jù)集中每個特征均為數(shù)值型數(shù)據(jù),經(jīng)過數(shù)據(jù)預(yù)處理和特征選擇后,形成6維的標(biāo)準(zhǔn)化數(shù)據(jù)集,將數(shù)據(jù)輸入到BNDNN模型,其中輸入數(shù)據(jù)為5維,代表數(shù)據(jù)集中的5個特征。數(shù)據(jù)從輸入層經(jīng)過全連接層進入BN層時,BN層經(jīng)過計算使得數(shù)據(jù)重新分布在[0,1]之間,對數(shù)據(jù)進行變換重構(gòu),再傳入下一層,提高了模型的準(zhǔn)確率。
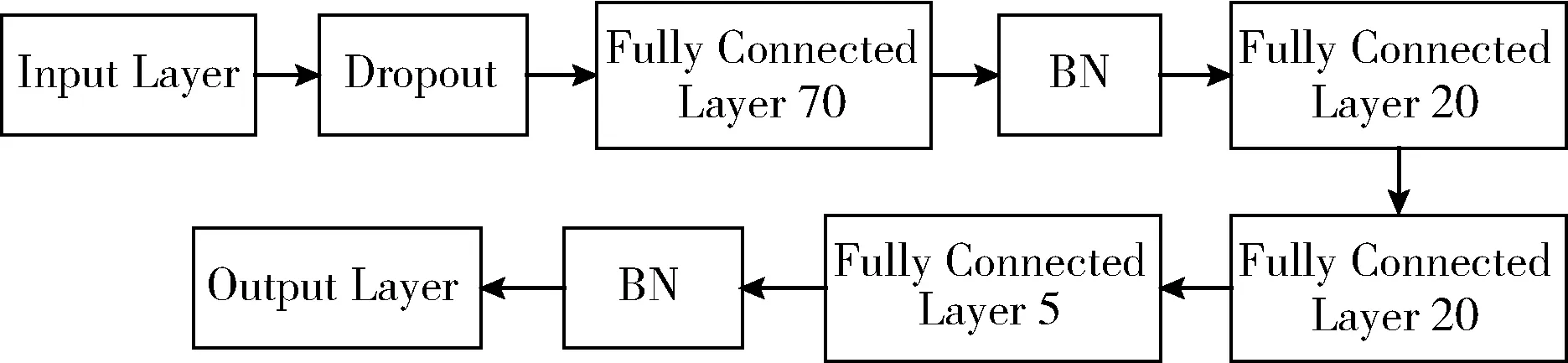
圖7 BNDNN網(wǎng)絡(luò)結(jié)構(gòu)
訓(xùn)練網(wǎng)絡(luò)模型,配置多個參數(shù)并進行優(yōu)化:
(1)采用Adam優(yōu)化算法,設(shè)置參數(shù)學(xué)習(xí)率為0.001。
(2)經(jīng)過多次實驗進行準(zhǔn)確率對比,設(shè)置迭代次數(shù)參數(shù)Epoch為100次。
(3)隱藏層激活函數(shù)選擇ReLU函數(shù),輸出層激活函數(shù)選擇Sigmoid函數(shù)。
(4)增加Dropout層,使神經(jīng)網(wǎng)絡(luò)每次訓(xùn)練時隨機忽略一部分神經(jīng)元,這樣會使神經(jīng)網(wǎng)絡(luò)對某個神經(jīng)元的權(quán)重變化不敏感,增加了泛化能力,減少過擬合。Dropout參數(shù)默認(rèn)值設(shè)為0.2。
(5)在dense層中添加正則項,L2參數(shù)設(shè)置為0.01。
4 實驗結(jié)果與分析
本文對PIDD數(shù)據(jù)集進行缺失值處理,數(shù)據(jù)標(biāo)準(zhǔn)化等一系列數(shù)據(jù)預(yù)處理操作后,利用XGBoost算法進行特征選擇,篩選出重要性比較高的5個特征屬性,即Glucose(血糖值)、DiabetesPedigreeFunction(糖尿病譜系功能)、BMI(體重)、Age(年齡)、BloodPressure(舒張壓),將其作為新的輸入數(shù)據(jù)。采用Keras框架搭建BNDNN模型用于進行糖尿病預(yù)測。將數(shù)據(jù)集按照8∶2的比例分為訓(xùn)練集和測試集,訓(xùn)練集樣本數(shù)為615,測試集樣本數(shù)為153。通過對訓(xùn)練集進行交叉驗證,并根據(jù)模型評價指標(biāo)調(diào)整網(wǎng)絡(luò)參數(shù)來訓(xùn)練網(wǎng)絡(luò)模型,在測試集上評估訓(xùn)練好的模型準(zhǔn)確率。
4.1 評價指標(biāo)
使用交叉驗證評估模型的泛化能力。K-fold交叉驗證是將數(shù)據(jù)集分成K組,將K-1組子集作為訓(xùn)練集,剩下的子集作為測試集,進行K次訓(xùn)練和測試,將K次測試結(jié)果的平均值作為最終結(jié)果。
在醫(yī)學(xué)診斷中,通常利用以下常用指標(biāo)評估模型:
準(zhǔn)確率(Accuracy):表示分類器做出正確預(yù)測的樣本個數(shù)與樣本總數(shù)的比率[15]
(15)
其中,TP為真陽性、TN為真陰性、FP為假陽性、FN為假陰性。如果數(shù)據(jù)集中樣本標(biāo)簽為正,并且分類器預(yù)測這個樣本標(biāo)簽也為正時,稱其為真陽性;如果數(shù)據(jù)集中樣本標(biāo)簽為負(fù),預(yù)測也為負(fù)時,稱其為真陰性;如果數(shù)據(jù)集中樣本標(biāo)簽為正,但分類器預(yù)測為負(fù),稱其為假陰性;如果數(shù)據(jù)集中樣本標(biāo)簽為負(fù),分類器預(yù)測為正時,稱其為假陽性。
靈敏度(Sensitivity)即召回率(recall):表示陽性病例正確分類為陽性與所有陽性病例的比率
(16)
特異度(Specificity):表示陰性病例正確分類為陰性與所有陰性病例的比率
(17)
精準(zhǔn)率(Precision):表示陽性病例正確分類為陽性與所有預(yù)測為陽性病例的比率
(18)
F1值表示精確值和召回率的調(diào)和均值
(19)
ROC曲線:接受者操作特征曲線,縱坐標(biāo)為靈敏度(Sensitivity),橫坐標(biāo)為特異度(Specificity),當(dāng)曲線向坐標(biāo)軸左上角靠近時表明模型準(zhǔn)確度越高[16]。AUC表示ROC曲線下的面積,AUC值越大表明模型性能越穩(wěn)定,利用這兩個指標(biāo)可以用來衡量模型的分類性能。
4.2 實驗結(jié)果分析
本文利用10倍交叉驗證對模型進行訓(xùn)練和評估,經(jīng)過100次迭代測試集準(zhǔn)確率基本穩(wěn)定在80%左右,實驗結(jié)果如圖8所示,表明該模型對糖尿病的診斷預(yù)測是可行的。
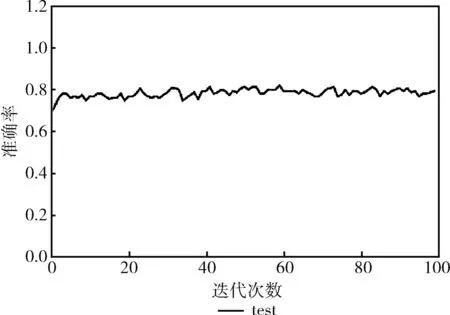
圖8 預(yù)測結(jié)果
為了驗證模型的有效性,將XGBoost-BNDNN模型與其它傳統(tǒng)機器學(xué)習(xí)算法決策樹(DT)、隨機森林(RF)以及利用PCA進行特征選擇的PCA-DNN模型和XGBoost-DNN模型進行對比,實驗結(jié)果見表2。
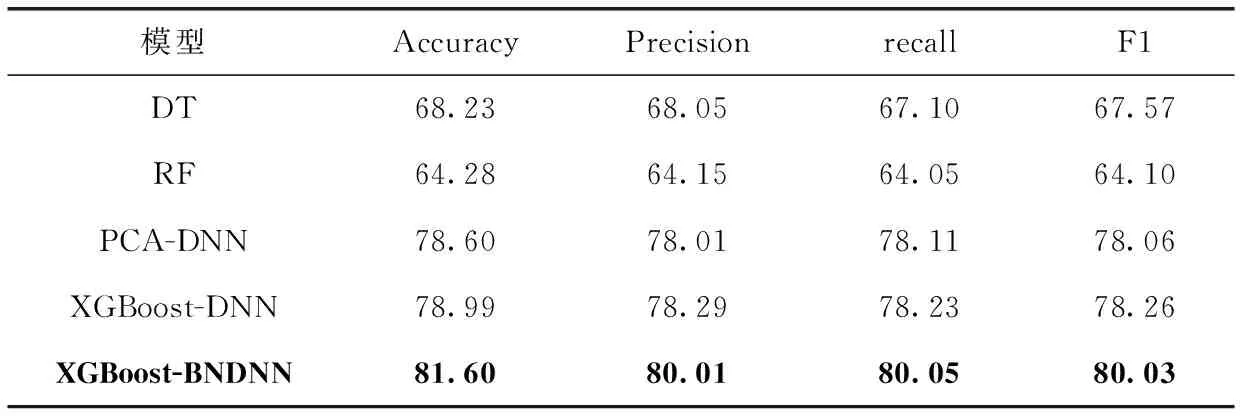
表2 不同模型分類準(zhǔn)確率/%
從實驗結(jié)果可以看出,在準(zhǔn)確率方面,XGBoost-BNDNN模型準(zhǔn)確率為81.60%,比DT提高了13.37%,比
RF提高了17.32%,比PCA-DNN模型提高了3%,比XGBoost-DNN模型提高了2.61%;在精準(zhǔn)率方面,XGBoost-BNDNN模型精確率為80.01%,比DT提高了11.96%,比RF提高了15.86%,比PCA-DNN模型提高了2%,比XGBoost-DNN模型提高了1.72%;在召回率方面,XGBoost-DNN模型召回率為80.05%,比DT提高了12.95%,比RF提高了16%,比PCA-DNN模型提高了1.94%,比XGBoost-DNN模型提高了1.82%;在F1值方面,XGBoost-BNDNN模型F1值為80.03%,比DT提高了12.46%,比RF提高了15.93%,比PCA-DNN模型提高了1.97%,比XGBoost-DNN模型提高了1.77%。表明增加BN層對模型性能的提高是有效的。
為了更進一步對比不同模型的性能,對其進行ROC曲線比較,結(jié)果如圖9所示。從圖9可以看出,XGBoost-BNDNN模型的ROC曲線最靠近坐標(biāo)軸左上方,ROC曲線下的面積最大,表明其AUC值最大,同時從表3可以得到驗證,XGBoost-BNDNN模型AUC值為0.822,與其它模型相比值最大。表明該模型具有更好的預(yù)測效果,可以對糖尿病進行有效的預(yù)測來輔助醫(yī)生進行診斷。
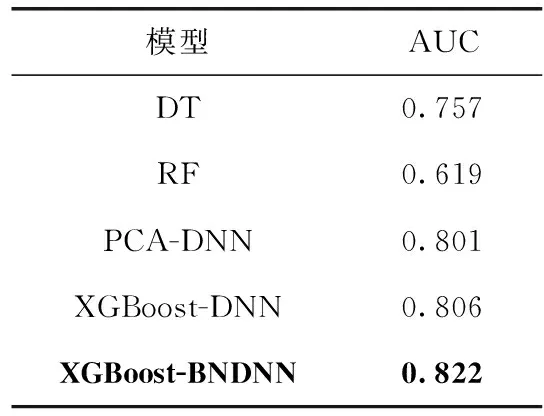
表3 不同模型AUC
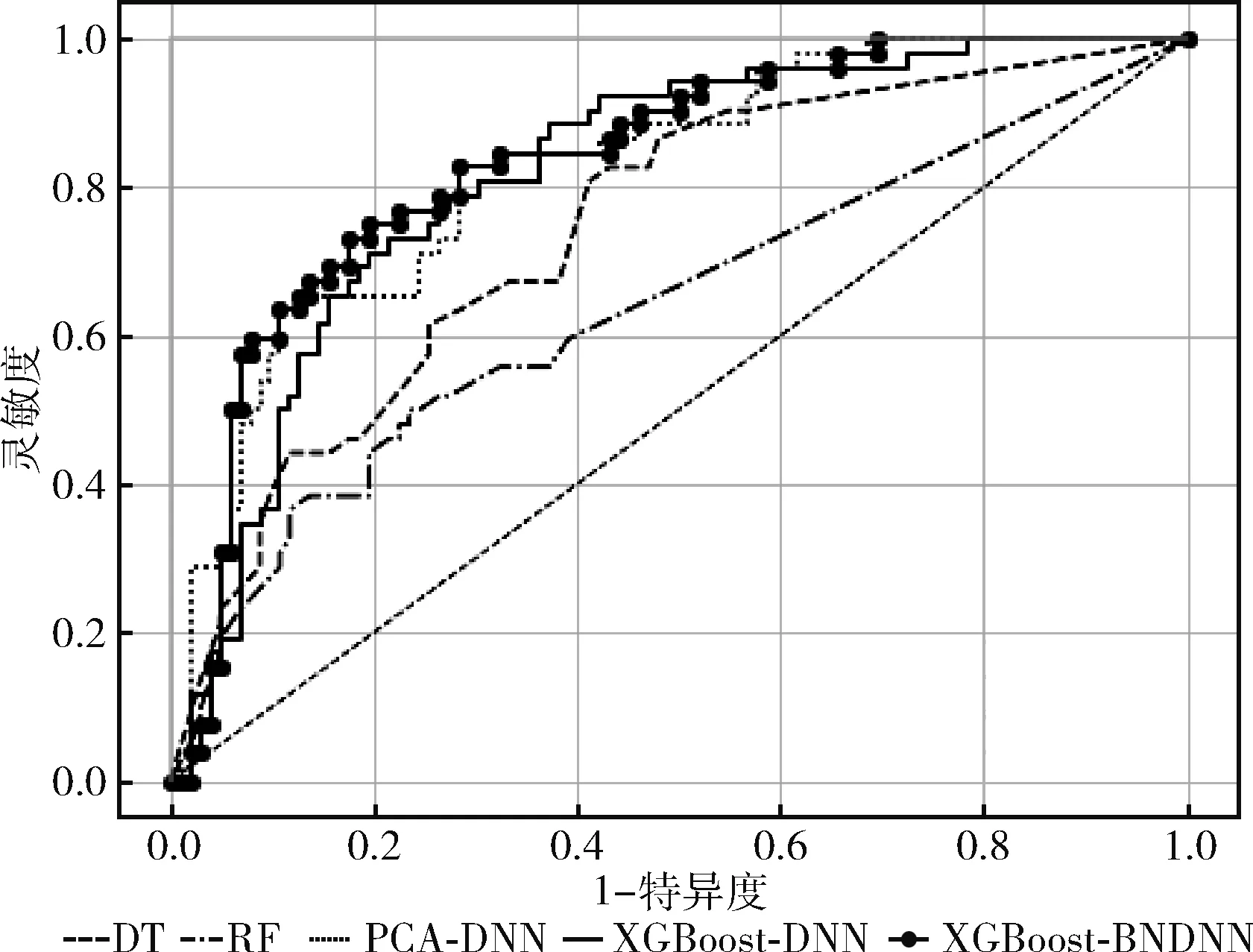
圖9 各個分類模型ROC曲線
5 結(jié)束語
本文圍繞糖尿病預(yù)測問題,對糖尿病結(jié)構(gòu)化數(shù)據(jù)進行處理,運用XGBoost算法進行特征選擇,提出對DNN進行改進,構(gòu)建XGBoost-BNDNN模型用于糖尿病的預(yù)測。該
模型在普通DNN網(wǎng)絡(luò)結(jié)構(gòu)上增加了BN層,可以有效防止梯度消失、訓(xùn)練速度慢等現(xiàn)象,提高模型準(zhǔn)確率。增加Adam優(yōu)化算法、Dropout層、L2正則化對BNDNN模型進行優(yōu)化。通過10倍交叉驗證以及各種評價指標(biāo)評估該模型,驗證了模型的優(yōu)越性。由于本文使用的數(shù)據(jù)集數(shù)量少,特征維數(shù)低,不能保證該模型適應(yīng)大數(shù)據(jù)、特征維數(shù)高的情況。針對這一問題,下一步將使用大數(shù)據(jù)集對模型進行優(yōu)化,以取得更高的準(zhǔn)確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2022年5期)2022-08-24 02:35:42
中老年保健(2022年1期)2022-08-17 06:14:56
中老年保健(2021年5期)2021-08-24 07:07:20
中老年保健(2021年11期)2021-08-22 03:15:16
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
