跨語(yǔ)種民航陸空通話語(yǔ)音識(shí)別模型研究
2021-05-14 03:57:44劉遠(yuǎn)慶郭曉靜張海剛楊金鋒
計(jì)算機(jī)應(yīng)用與軟件 2021年5期
關(guān)鍵詞:模型
劉遠(yuǎn)慶 郭曉靜 張海剛 楊金鋒
1(中國(guó)民航大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院 天津 300300) 2(深圳職業(yè)技術(shù)學(xué)院人工智能學(xué)院 廣東 深圳 518055)
0 引 言
陸空通話是飛行員與管制員在整個(gè)飛行過(guò)程中按照飛行程序進(jìn)行交流、溝通的語(yǔ)言,具有很強(qiáng)的專業(yè)性和情境性。在陸空通話過(guò)程中,由于通話內(nèi)容不正確、通話語(yǔ)言模糊等原因造成陸空通話錯(cuò)誤的情況時(shí)常發(fā)生[1-2]。而陸空通話錯(cuò)誤增大了飛行事故發(fā)生的概率,所以正確使用陸空通話用語(yǔ)進(jìn)行信息溝通,對(duì)航空器安全高效運(yùn)行有著至關(guān)重要的作用。民航陸空通話特點(diǎn)如下:(1) 語(yǔ)言標(biāo)準(zhǔn)規(guī)范,如:“對(duì)方呼號(hào)-己方呼號(hào)-內(nèi)容”;(2) 詞義固定、單一,如:stand-飛機(jī)停機(jī)位、departure-離場(chǎng);(3) 句式簡(jiǎn)短、緊湊,如:Cleared(to) touch and go(省略不定式符號(hào)to)。近幾年,隨著神經(jīng)網(wǎng)絡(luò)再度興起,深度學(xué)習(xí)在語(yǔ)音識(shí)別領(lǐng)域得到成功應(yīng)用,語(yǔ)音識(shí)別性能也得到大幅提升。文獻(xiàn)[3-4]分別將深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Network,DNN)和雙向長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(BiLSTM)用于解決日常對(duì)話的語(yǔ)音識(shí)別問(wèn)題。將語(yǔ)音識(shí)別技術(shù)應(yīng)用到陸空通話領(lǐng)域不僅可以用于管制員與飛行員的訓(xùn)練,減少民航通話語(yǔ)義表達(dá)錯(cuò)誤,還可以輔助管制員工作,提高工作效率。但是傳統(tǒng)語(yǔ)音識(shí)別的效果卻不盡人意,因此將深度學(xué)習(xí)應(yīng)用在民航陸空通話語(yǔ)音識(shí)別中以提升識(shí)別效果顯得尤為關(guān)鍵。
現(xiàn)在有很多語(yǔ)音識(shí)別技術(shù)已在民航陸空通話語(yǔ)音識(shí)別中應(yīng)用。例如:使用動(dòng)態(tài)時(shí)間規(guī)整算法來(lái)實(shí)現(xiàn)陸空通話的語(yǔ)音識(shí)別[5];利用基于混合高斯-隱馬爾可夫模型進(jìn)行英文陸空通話標(biāo)準(zhǔn)用語(yǔ)的關(guān)鍵詞識(shí)別[6];利用基于深度神經(jīng)網(wǎng)絡(luò)-隱馬爾可夫模型在專有的英文陸空通話語(yǔ)音數(shù)據(jù)庫(kù)上進(jìn)行實(shí)驗(yàn),并使詞錯(cuò)誤率下降到9.4%[7];將自動(dòng)語(yǔ)音識(shí)別技術(shù)應(yīng)用到空中交通管制領(lǐng)域構(gòu)建的封閉式跑道運(yùn)行預(yù)防裝置也取得一定成果[8]。文獻(xiàn)[9-10]在將語(yǔ)音識(shí)別技術(shù)應(yīng)用到民航陸空通話的基礎(chǔ)上,又加入了雷達(dá)信息進(jìn)行輔助,不僅提高了空中交通管理的效率,而且減少了管制員的工作量和飛機(jī)的油耗。文獻(xiàn)[11]則使用迭代半監(jiān)督的方法在空中交通管制領(lǐng)域構(gòu)建語(yǔ)音識(shí)別系統(tǒng),該方法利用有限的轉(zhuǎn)錄數(shù)據(jù)和大量未轉(zhuǎn)錄數(shù)據(jù)進(jìn)行模型訓(xùn)練,得到較好的效果。文獻(xiàn)[12]對(duì)比了不同的模型在陸空通話語(yǔ)音識(shí)別和呼號(hào)識(shí)別這兩個(gè)任務(wù)中的性能,其中使用隱馬爾可夫-多層感知機(jī)的模型效果最好,詞錯(cuò)誤率降至7.62%。文獻(xiàn)[13]提出了基于雙向長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)-端到端的民航陸空通話語(yǔ)音識(shí)別方法,用于英文陸空通話的語(yǔ)音識(shí)別,使詞錯(cuò)誤率降至5.53%。當(dāng)前大部分民航陸空通話語(yǔ)音識(shí)別都是針對(duì)單語(yǔ)進(jìn)行的,但是在國(guó)內(nèi),一名管制員在工作期間會(huì)和不同的航班(國(guó)際、國(guó)內(nèi))進(jìn)行交流,那么所用的語(yǔ)言就會(huì)涉及到英文和中文,所以有必要構(gòu)建一種跨語(yǔ)種民航陸空通話語(yǔ)音識(shí)別方法。針對(duì)于跨語(yǔ)種語(yǔ)音識(shí)別的研究方法總結(jié)如下:一種方法是利用語(yǔ)種識(shí)別系統(tǒng)[14]先對(duì)輸入的語(yǔ)音進(jìn)行語(yǔ)種判別,之后根據(jù)語(yǔ)種判別結(jié)果選擇對(duì)應(yīng)的單語(yǔ)語(yǔ)音識(shí)別系統(tǒng)進(jìn)行識(shí)別,但是其識(shí)別準(zhǔn)確率依賴于前端的語(yǔ)言識(shí)別的準(zhǔn)確率;另一種方法是建立多語(yǔ)言共享音素庫(kù),構(gòu)建方法有很多,例如利用巴氏系數(shù)距離[15]和聲學(xué)似然[16]等。
本文將注意力集中在民航領(lǐng)域的跨語(yǔ)種(中文、英文)陸空通話語(yǔ)音識(shí)別上,根據(jù)中英文陸空通話語(yǔ)言特點(diǎn),提出一種基于深度學(xué)習(xí)的跨語(yǔ)種民航陸空通話語(yǔ)音識(shí)別方法。在構(gòu)建聲學(xué)模型時(shí),由于卷積的不變性[17]可以克服語(yǔ)音信號(hào)本身的多樣性,所以在DNN中引入卷積神經(jīng)網(wǎng)絡(luò)CNN構(gòu)成卷積深度神經(jīng)網(wǎng)絡(luò)CDNN,其中CNN主要對(duì)聲學(xué)特征進(jìn)行加工和處理,使其能更好地被用于DNN的分類。最終,將卷積深度神經(jīng)網(wǎng)絡(luò)與隱馬爾可夫模型結(jié)合構(gòu)建共享隱層的跨語(yǔ)種聲學(xué)模型。本文利用中文(聲韻母音素標(biāo)注)和英文(CMU音素標(biāo)注)音素直接融合的方法構(gòu)建中英文混合語(yǔ)言模型;為了減少總的音素?cái)?shù)量、降低識(shí)別復(fù)雜度,將基于卡內(nèi)基梅隆大學(xué)(Carnegie Mellon University,CMU)標(biāo)準(zhǔn)音素表建立的英文音素映射為T(mén)IMIT標(biāo)準(zhǔn)音素,使它與中文音素進(jìn)行融合重新構(gòu)建語(yǔ)言模型,同時(shí)在提取聲學(xué)特征時(shí)加入低幀率用于縮短訓(xùn)練解碼時(shí)間。實(shí)驗(yàn)結(jié)果表明,基于CDNN-HMM聲學(xué)模型音素先映射再融合的方法得到的效果較好。在此基礎(chǔ)上,通過(guò)加入低幀率有效降低了訓(xùn)練解碼時(shí)間,而且使得詞錯(cuò)誤率進(jìn)一步下降。
1 卷積深度神經(jīng)網(wǎng)絡(luò)基本原理
通常情況下,語(yǔ)音識(shí)別都是基于時(shí)頻分析后的語(yǔ)音譜完成的,其中語(yǔ)音時(shí)頻譜是具有結(jié)構(gòu)特點(diǎn)的。要想提高語(yǔ)音識(shí)別率,就需要克服語(yǔ)音信號(hào)所面臨多樣性,包括說(shuō)話人的多樣性(說(shuō)話人自身、說(shuō)話人間)、環(huán)境的多樣性等。基于以上考慮,本文將卷積神經(jīng)網(wǎng)絡(luò)(CNN)引入到深度神經(jīng)網(wǎng)絡(luò)(DNN)中共同構(gòu)成卷積深度神經(jīng)網(wǎng)絡(luò)(CDNN),其結(jié)構(gòu)如圖1所示,以此來(lái)建立中英文民航陸空通話聲學(xué)模型。CNN主要用來(lái)處理聲學(xué)特征,利用其在時(shí)間和空間上的平移不變性卷積來(lái)克服語(yǔ)音信號(hào)本身的多樣性。CNN在語(yǔ)音識(shí)別任務(wù)中可以使用一維模型或者二維模型,由于一維模型能很好地適應(yīng)語(yǔ)音的一維特性,而二維模型的網(wǎng)絡(luò)過(guò)于復(fù)雜,因此本文在構(gòu)建聲學(xué)模型時(shí)選取一維模型。DNN則是用來(lái)對(duì)音素進(jìn)行分類,因?yàn)镈NN能夠?qū)⑻卣饔成涞姜?dú)立空間,所以DNN強(qiáng)大的分類能力能準(zhǔn)確將語(yǔ)音的聲學(xué)特征分類到相應(yīng)的HMM狀態(tài)。
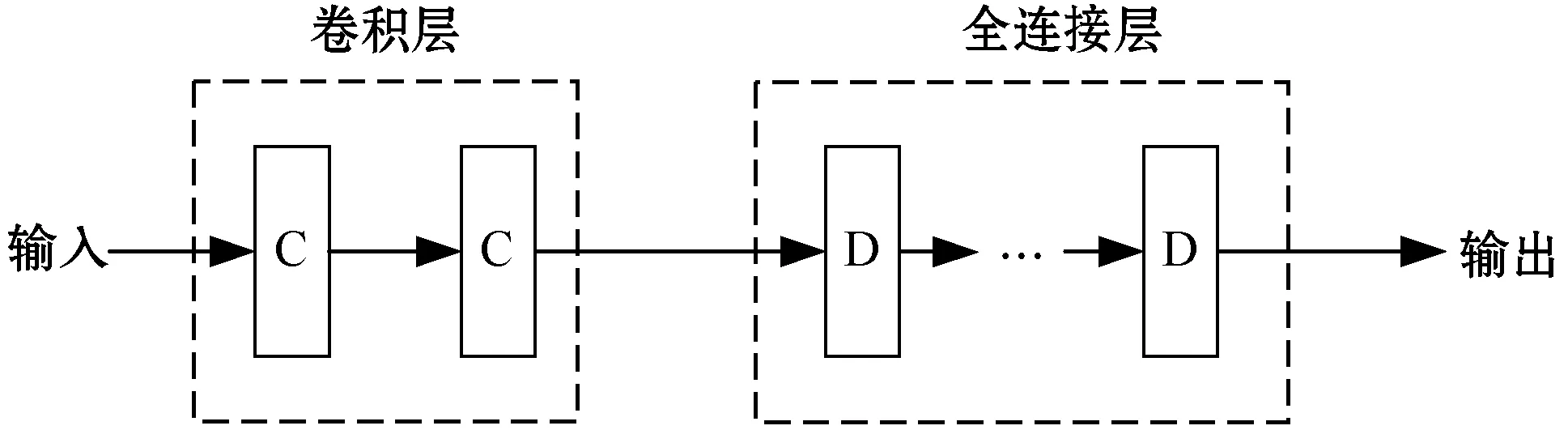
圖1 CDNN結(jié)構(gòu)
CNN[18]拋開(kāi)輸入、輸出層不談,其主體包括卷積層和池化(采樣)層,卷積層通過(guò)卷積核在時(shí)間軸上移動(dòng)對(duì)輸入的語(yǔ)音信號(hào)進(jìn)行聲學(xué)特征提取,這樣一方面可以適應(yīng)語(yǔ)音信號(hào)的時(shí)變的特點(diǎn),另一方面保留了頻帶的相關(guān)性,對(duì)識(shí)別性能的提高有很大幫助。對(duì)給定一系列聲學(xué)特征值X,卷積層將X與k個(gè)濾波器{Wi}進(jìn)行卷積,得到的激活特征映射:
Hi=sigmoid(Wi*X+bi)i=1,2,…,k
(1)
式中:符號(hào)*表示卷積運(yùn)算;Wi表示權(quán)值矩陣;bi表示偏置參數(shù)。對(duì)于該模型中的所有卷積運(yùn)算,卷積步幅選擇為1,最后得到的特征作為DNN的輸入向量。
池化層是對(duì)卷積層提取出的特征進(jìn)行降維,一方面使特征圖變小,簡(jiǎn)化網(wǎng)絡(luò)計(jì)算復(fù)雜度;另一方面進(jìn)行特征壓縮,提取主要特征,減小過(guò)擬合,同時(shí)提高模型的容錯(cuò)性。池化方法有最大池化和平均池化,本文選擇在語(yǔ)音識(shí)別中普遍使用的最大池化。
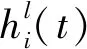
(2)
式中:σ(·)是sigmoid函數(shù)。以上元素是下一層l+1的輸入,觀測(cè)向量輸入到最底層l=0。
對(duì)于CD-DNN-HMM[21],頂層L是一個(gè)針對(duì)于每個(gè)上下文相關(guān)音素狀態(tài)的softmax函數(shù):
(3)
DNN可以使用預(yù)訓(xùn)練進(jìn)行初始化,預(yù)訓(xùn)練是在受限玻爾茲曼機(jī)RBM[22]上使用對(duì)比散度算法進(jìn)行初始化。同時(shí)也可以使用隨機(jī)初始化的方法,頂層權(quán)重通常是隨機(jī)初始化的,初始化完成后,使用反向傳播算法的微調(diào)過(guò)程來(lái)更新所有DNN參數(shù)。損失函數(shù)選擇交叉熵函數(shù),如式(4)所示,其中:q(t)為時(shí)刻t時(shí)的期望輸出。
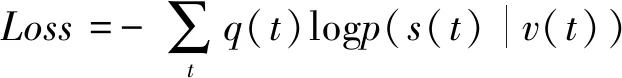
(4)
2 基于CDNN-HMM的跨語(yǔ)種陸空通話聲學(xué)模型
2.1 低幀率
訓(xùn)練中英文民航陸空通話混合聲學(xué)模型時(shí),首先要對(duì)語(yǔ)音數(shù)據(jù)集進(jìn)行一系列的處理,例如分幀加窗,它是將時(shí)變語(yǔ)音信號(hào)處理成短時(shí)平穩(wěn)信號(hào),用于之后的特征提取。之所以這樣處理是因?yàn)檎Z(yǔ)音信號(hào)是時(shí)變非平穩(wěn)信號(hào),平穩(wěn)信號(hào)的相關(guān)的處理方法對(duì)于它并不適用。但是語(yǔ)音信號(hào)屬于短時(shí)平穩(wěn)信號(hào),一般認(rèn)為10~30 ms內(nèi)語(yǔ)音信號(hào)的特性是基本不變的,或者變化很慢[23]。因此需要將語(yǔ)音信號(hào)切分為極短的片段,這些片段稱為語(yǔ)音幀,幀長(zhǎng)一般為10~30 ms,本文最初幀長(zhǎng)取25 ms,幀移為10 ms,從而有15 ms的重疊。通過(guò)這種方式來(lái)防止幀與幀之間丟失重要的信息。
分幀是利用一個(gè)窗函數(shù)來(lái)實(shí)現(xiàn)。為了減少信息的泄露,所以在加窗時(shí)選擇主瓣寬度窄、旁瓣衰減大的窗函數(shù)(漢明窗):
(5)
對(duì)于一段語(yǔ)音進(jìn)行加窗操作時(shí)設(shè)置的參數(shù)包括幀長(zhǎng)、幀移以及重疊時(shí)間,它們之間關(guān)系:重疊=幀長(zhǎng)-幀移。為了縮短訓(xùn)練和解碼的時(shí)間,本文在提取聲學(xué)特征之前加入低幀率,原理如圖2所示。
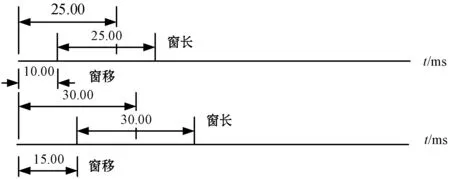
圖2 低幀率原理圖
一幀的幀長(zhǎng)25 ms,幀移10 ms,幀與幀之間有15 ms的重疊,然后再對(duì)每幀加窗處理。本文所講的低幀率就是在分幀時(shí)將幀長(zhǎng)和幀移都延長(zhǎng),將幀長(zhǎng)設(shè)置為30 ms、幀移15 ms,讓幀與幀之間仍有15 ms的重疊。
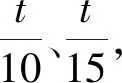
由上述可知,當(dāng)幀移取較大值時(shí),幀數(shù)會(huì)減少,相應(yīng)的幀率降低,所以本文所講的低幀率就是通過(guò)增加幀移的值來(lái)減少幀數(shù),從而通過(guò)降低幀率來(lái)加快訓(xùn)練速度和解碼速度。
2.2 聲學(xué)模型訓(xùn)練
本文使用的聲學(xué)特征包括Filter-Bank(FBank)和梅爾倒譜系數(shù)(MFCC)。MFCC是在FBank的基礎(chǔ)上又做了一步離散余弦變換,對(duì)FBank進(jìn)行去相關(guān)和壓縮處理。
CDNN聲學(xué)模型訓(xùn)練流程如圖3所示。首先用經(jīng)過(guò)倒譜均值歸一化(CMVN)處理的MFCC特征訓(xùn)練單音素模型,即標(biāo)簽到語(yǔ)音的映射,它是針對(duì)每個(gè)音素分別建立HMM;然后基于單音系統(tǒng)構(gòu)造三音素模型,并在此基礎(chǔ)上對(duì)特征進(jìn)行線性判別分析(Linear Discriminant Analysis,LDA)、最大似然線性變換(Maximum Likelihood Linear Transform,MLLT)和說(shuō)話人自適應(yīng)變換(Speaker Adaptation Transform,SAT);最終利用經(jīng)過(guò)變換的特征和GMM-HMM模型生成的狀態(tài)對(duì)齊訓(xùn)練CDNN。
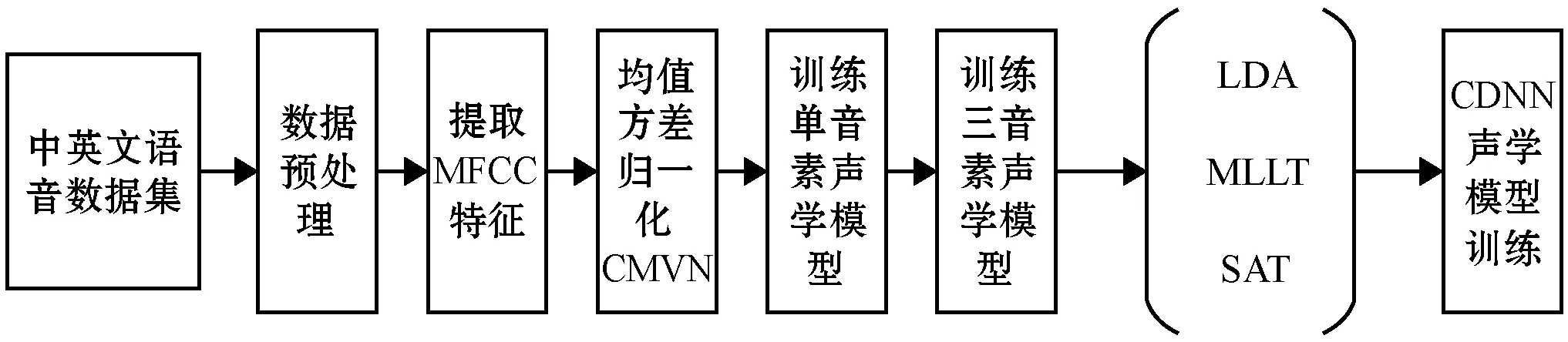
圖3 CDNN聲學(xué)模型訓(xùn)練流程
訓(xùn)練CDNN-HMM之前首先需要用混合高斯-隱馬爾可夫模型(GMM-HMM)將各個(gè)狀態(tài)進(jìn)行強(qiáng)制對(duì)齊,GMM-HMM的輸入為39維(標(biāo)準(zhǔn)的13維MFCC加上一階和二階差分參數(shù))聲學(xué)特征,在訓(xùn)練HMM模型的參數(shù)時(shí),每次要求輸入到HMM中的數(shù)據(jù)是一個(gè)觀測(cè)值序列。此時(shí)每個(gè)狀態(tài)對(duì)應(yīng)的觀測(cè)值為39維的向量,因?yàn)橄蛄恐性氐娜≈凳沁B續(xù)的,所以需要用多維密度函數(shù)來(lái)模擬。陸空通話語(yǔ)音識(shí)別任務(wù)中,用提前標(biāo)注好的訓(xùn)練樣本對(duì)每個(gè)音素建立一個(gè)HMM模型,建立模型時(shí)分別用EM算法和Baum-Welch算法訓(xùn)練出GMM-HMM的所有參數(shù),這些參數(shù)包括初始狀態(tài)的概率向量、狀態(tài)之間的轉(zhuǎn)移矩陣、每個(gè)狀態(tài)對(duì)應(yīng)的觀測(cè)矩陣。
基于GMM-HMM訓(xùn)練的CDNN-HMM聲學(xué)模型的輸入特征是40維FBank,相鄰的幀由11幀窗口(每側(cè)5個(gè)窗口)連接而成。為了便于CNN對(duì)聲學(xué)特征進(jìn)行進(jìn)一步的處理,本文將輸入特征變成一維向量,具體的步驟是將提取的聲學(xué)特征參數(shù)按照幀的順序排列(首尾相連),例如將11幀40維FBank首尾連接,構(gòu)成1×440的一維向量作為CNN的輸入。用于處理聲學(xué)特征的CNN包括兩個(gè)卷積層和一個(gè)池化層,兩個(gè)卷積層的卷積核大小分別為11×8和128×4,卷積步幅均為1;池化層池化大小、步幅均為3,最后輸出2 048維向量作為DNN的輸入。DNN的架構(gòu)由4個(gè)隱藏層組成,每個(gè)層由1 024個(gè)單元組成,輸出層由3 613個(gè)單元組成。DNN模型用交叉熵準(zhǔn)則進(jìn)行訓(xùn)練,使用隨機(jī)梯度下降算法來(lái)執(zhí)行優(yōu)化,將最小批量處理大小設(shè)定為256幀,初始學(xué)習(xí)率設(shè)定為0.008。其框架如圖4所示。

圖4 CDNN-HMM框架
3 實(shí) 驗(yàn)
本文所有的實(shí)驗(yàn)都是在Linux系統(tǒng)下安裝的Kaldi[24]語(yǔ)音識(shí)別平臺(tái)上完成的。硬件配置如下:CPU為Inter酷睿i7-5690八核處理器,主頻3.3 GHz,內(nèi)存32 GB,搭配顯卡GTX 1070。
語(yǔ)音識(shí)別的評(píng)價(jià)指標(biāo)常選用詞錯(cuò)誤率(Word Error Rate,WER),為了使識(shí)別出來(lái)的詞序列和標(biāo)準(zhǔn)的詞序列之間保持一致,需要進(jìn)行替換(Ci)、刪除(Cd)、插入(Cs)某些詞,將這些詞的總數(shù)除以標(biāo)準(zhǔn)詞序列中詞的總數(shù)C從而得到用百分比表示的詞錯(cuò)誤率:
(6)
3.1 民航陸空通話數(shù)據(jù)集
實(shí)驗(yàn)所用的數(shù)據(jù)集是根據(jù)民航陸空通話標(biāo)準(zhǔn)建立的。該語(yǔ)料庫(kù)由空管專業(yè)人員與一線管制員共同錄制,包含飛行各個(gè)階段的民航陸空通話語(yǔ)音,并標(biāo)注出語(yǔ)音的文本序列和音素信息。
如表1所示,中英文民航陸空通話數(shù)據(jù)集共有音頻文件27 700條、57小時(shí)、說(shuō)話人31名,其中:中文數(shù)據(jù)集包含13 400條(說(shuō)話人21)音頻文件,27小時(shí);英文數(shù)據(jù)集包含14 300條(說(shuō)話人11)音頻文件,30小時(shí)。此數(shù)據(jù)集包括訓(xùn)練集、測(cè)試集、開(kāi)發(fā)集,分別占總數(shù)據(jù)集的80%、13%、7%,并且各個(gè)數(shù)據(jù)集中均包含男性和女性錄制的陸空通話音頻文件。

表1 中英文陸空通話數(shù)據(jù)集
3.2 卷積神經(jīng)網(wǎng)絡(luò)模型選擇
卷積神經(jīng)網(wǎng)絡(luò)在圖像處理任務(wù)中表現(xiàn)十分出色,但是將其應(yīng)用到語(yǔ)音識(shí)別任務(wù)中就需要根據(jù)實(shí)際情況認(rèn)真考慮分析。針對(duì)語(yǔ)音識(shí)別的卷積神經(jīng)網(wǎng)絡(luò)可以選擇一維卷積和二維卷積,為了驗(yàn)證哪種卷積更適合于民航陸空通話語(yǔ)音識(shí)別任務(wù),本文進(jìn)行了對(duì)比實(shí)驗(yàn)。實(shí)驗(yàn)分別使用相同層數(shù)(卷積層+池化層+卷積層)的一維卷積(1D-CNN)和二維卷積(2D-CNN)對(duì)上文提到的民航陸空通話語(yǔ)音的聲學(xué)特征進(jìn)行處理,處理后的聲學(xué)特征在相同配置的深度神經(jīng)網(wǎng)絡(luò)上進(jìn)行訓(xùn)練識(shí)別,識(shí)別結(jié)果如表2所示。
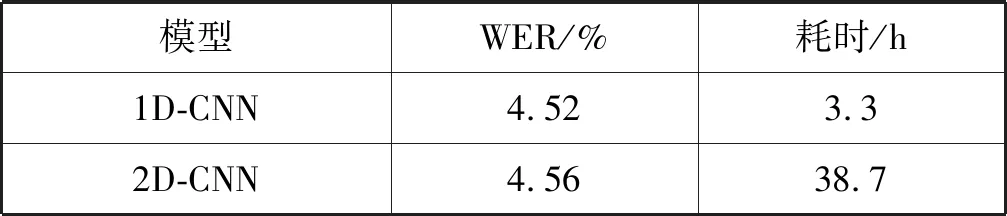
表2 兩種卷積神經(jīng)網(wǎng)絡(luò)對(duì)比
可以看出,一維卷積神經(jīng)網(wǎng)絡(luò)比二維卷積神經(jīng)網(wǎng)絡(luò)在民航陸空通話語(yǔ)音識(shí)別任務(wù)中表現(xiàn)要好,這主要因?yàn)槠湓跁r(shí)間軸上對(duì)語(yǔ)音信號(hào)進(jìn)行卷積時(shí)保留了語(yǔ)音信號(hào)的時(shí)變性和頻帶的相關(guān)性。而在訓(xùn)練解碼耗時(shí)方面,由于一維卷積神經(jīng)網(wǎng)絡(luò)的模型復(fù)雜程度較低,因此其表現(xiàn)明顯好于二維卷積。所以在訓(xùn)練CDNN時(shí),選擇1D-CNN來(lái)對(duì)聲學(xué)特征進(jìn)行處理,然后輸入到DNN網(wǎng)絡(luò)中進(jìn)行訓(xùn)練。
3.3 CMU映射為T(mén)IMIT對(duì)英文語(yǔ)料進(jìn)行標(biāo)注
本文所用語(yǔ)言模型是3-Gram中英文陸空通話語(yǔ)言模型,此語(yǔ)言模型是使用SRILM工具生成統(tǒng)計(jì)語(yǔ)言模型。訓(xùn)練步驟:首先將已有的中英文陸空通話文本語(yǔ)料讀入到SRILM中生成n-gram計(jì)數(shù)文件,然后用生成的計(jì)數(shù)文件訓(xùn)練語(yǔ)言模型,語(yǔ)言模型為ARPA格式文件,其中包括一、二、三元詞的總數(shù)及其出現(xiàn)的概率。用于中英文陸空通話語(yǔ)音識(shí)別的字典中共有1 118個(gè)詞,包含中文詞匯467個(gè)、英文詞匯653個(gè),每個(gè)詞都是用對(duì)應(yīng)語(yǔ)種的音素進(jìn)行標(biāo)注。
標(biāo)注的目的就是為了將由句子分成的各個(gè)詞進(jìn)一步劃分為更小的狀態(tài)(音素),這樣可以在音素級(jí)別對(duì)語(yǔ)音進(jìn)行識(shí)別。對(duì)于中文而言,通常采用聲母、韻母以及音調(diào)對(duì)涉及到的字詞進(jìn)行標(biāo)注。對(duì)于英文的音素標(biāo)注,則可以選擇CMU或TIMIT兩種標(biāo)準(zhǔn)音素表進(jìn)行標(biāo)注。針對(duì)民航陸空通話,初步嘗試中文應(yīng)用聲韻母標(biāo)注,英文使用CMU進(jìn)行標(biāo)注,然后將二者進(jìn)行融合共同構(gòu)建混合語(yǔ)言模型,用于最終的中英文民航陸空通話語(yǔ)音識(shí)別,結(jié)果如表3所示。
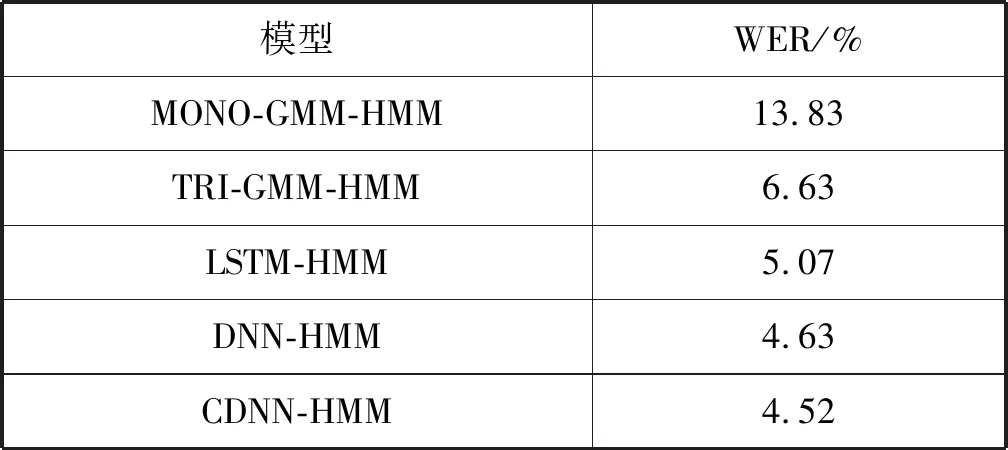
表3 CMU標(biāo)注中英文語(yǔ)音識(shí)別結(jié)果
可以看出,考慮上下文信息的三音素混合高斯隱馬爾可夫模型(TRI-GMM-HMM)比單音素混合高斯隱馬爾可夫模型(MONO-GMM-HMM)的詞錯(cuò)誤率減少了7.2百分點(diǎn);從實(shí)驗(yàn)結(jié)果可知擅長(zhǎng)對(duì)時(shí)序序列建模的長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(LSTM)在陸空通話領(lǐng)域表現(xiàn)并不突出,主要是因?yàn)殛懣胀ㄔ挼奶厥鈶?yīng)用場(chǎng)合要求對(duì)話盡可能簡(jiǎn)短、緊湊,這就使得LSTM的優(yōu)勢(shì)發(fā)揮不了很大的作用;加入卷積的深度神經(jīng)網(wǎng)絡(luò)模型(CDNN-HMM)詞錯(cuò)誤率進(jìn)一步降低了2.11百分點(diǎn),而且比不加卷積的深度神經(jīng)網(wǎng)絡(luò)模型(DNN-HMM)在識(shí)別性能上有了進(jìn)一步提高。
在此基礎(chǔ)上,將英文采用的CMU標(biāo)注映射為T(mén)IMIT進(jìn)行標(biāo)注,映射方法如圖5所示,CMU標(biāo)準(zhǔn)音素表和TIMIT標(biāo)準(zhǔn)音素表中對(duì)應(yīng)英文的音標(biāo)相同,但是表現(xiàn)形式不同,TIMIT標(biāo)準(zhǔn)音素表的形式與中文標(biāo)注的聲韻母比較相近,所以融合之后比之前音素的個(gè)數(shù)少了17個(gè)。

圖5 CMU到TIMIT音素映射過(guò)程
實(shí)驗(yàn)結(jié)果如表4所示。在使用TIMIT標(biāo)準(zhǔn)進(jìn)行標(biāo)注時(shí),由于MONO-GMM-HMM模型只考慮單個(gè)音素,沒(méi)有考慮協(xié)同發(fā)音效應(yīng)即上下文音素會(huì)對(duì)當(dāng)前的中心音素發(fā)音有影響,所以效果提升不明顯。而TRI-GMM-HMM模型、DNN-HMM模型和CDNN-HMM模型的識(shí)別效果均比使用CMU標(biāo)注時(shí)的效果好。由CMU映射到TIMIT之后,再與中文音素進(jìn)行融合重構(gòu)語(yǔ)言模型的識(shí)別方法,音素?cái)?shù)量的減少使得音素彼此之間的影響降低,識(shí)別解碼復(fù)雜程度降低,詞錯(cuò)誤率也有所下降。
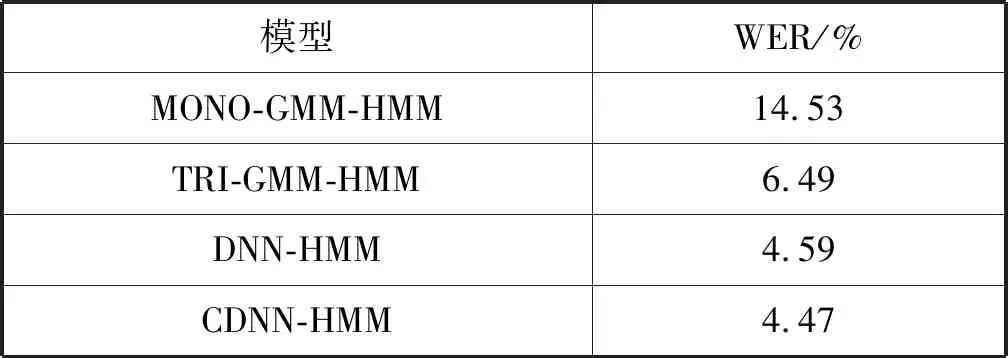
表4 TIMIT標(biāo)注中英文語(yǔ)音識(shí)別結(jié)果
3.4 低幀率實(shí)驗(yàn)
在聲學(xué)模型的訓(xùn)練過(guò)程中,將本文提出的低幀率加入其中,得到的實(shí)驗(yàn)結(jié)果如表5所示。

表5 低幀率(LFR)實(shí)驗(yàn)結(jié)果
可以看出,加入LFR以后,相似幀數(shù)量減少,使得不同音素對(duì)應(yīng)幀之間的區(qū)分性增大,從而減小了計(jì)算量,進(jìn)一步提高了識(shí)別性能。除此之外,LFR也縮短了訓(xùn)練和解碼的時(shí)間。
本文將基于CDNN模型的實(shí)驗(yàn)結(jié)果進(jìn)行了一個(gè)簡(jiǎn)單的對(duì)比,可以明顯看出用TIMIT標(biāo)注的識(shí)別結(jié)果要比CMU標(biāo)注識(shí)別的結(jié)果好;而加入LFR后,TIMIT標(biāo)注的效果依然表現(xiàn)良好,不過(guò)在耗時(shí)方面稍顯遜色。但是從整體上看,加入LFR確實(shí)將訓(xùn)練解碼時(shí)間縮小,而且性能也有所提升。
4 結(jié) 語(yǔ)
本文根據(jù)民航中英文陸空通話語(yǔ)言特點(diǎn),提出了基于卷積深度神經(jīng)網(wǎng)絡(luò)模型的跨語(yǔ)種陸空通話語(yǔ)音識(shí)別方法。對(duì)不同卷積模型的實(shí)驗(yàn)結(jié)果分析發(fā)現(xiàn),一維卷積模型更適合陸空通話語(yǔ)音識(shí)別任務(wù),加入卷積的深度神經(jīng)網(wǎng)絡(luò)聲學(xué)模型(CDNN)比單純的DNN-HMM模型性能更好。從實(shí)驗(yàn)結(jié)果來(lái)看,在已有的中英文民航陸空通話語(yǔ)料庫(kù)上,采取不同的標(biāo)注形式(CMU/TIMIT)構(gòu)建的語(yǔ)言模型對(duì)識(shí)別性能有影響,TIMIT標(biāo)注形式適用于跨語(yǔ)種民航陸空通話語(yǔ)音識(shí)別。LFR思想的加入,不僅有效地降低了詞錯(cuò)誤率,而且也縮短了模型訓(xùn)練解碼的時(shí)間。最終使用CDNN-HMM模型,結(jié)合詞典以及語(yǔ)言模型實(shí)現(xiàn)了跨語(yǔ)種民航陸空通話語(yǔ)音識(shí)別,將詞錯(cuò)誤率降至4.28%。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
