一種基于NoC多核系統(tǒng)的矩陣乘法映射技術
2021-05-12 13:47:26王曉蕾袁子昂袁儒明
電子科技 2021年5期
關鍵詞:系統(tǒng)
汪 楊,王曉蕾,袁子昂,袁儒明
(合肥工業(yè)大學 電子科學與應用物理學院,安徽 合肥 230009)
矩陣乘法在數字信號處理、工程控制、神經網絡以及圖像處理等領域中有著重要的應用[1-2]。隨著待計算矩陣規(guī)模的不斷擴大,實現一個大規(guī)模且有較高運算性能的矩陣乘法器具有重大的工程意義。
脈動陣列算法[3]是將復雜的計算形成硬件結構的一般方法,其巧妙地將矩陣乘法自身良好的運算并行性和硬件的并行特性結合在一起,為后續(xù)研究利用硬件結構實現復雜的運算奠定了基礎。在FPGA上實現脈動陣列矩陣乘法已經取得了一些研究成果。在浮點矩陣乘法方面,文獻[4]在基于FPGA上實現了實時雙精度浮點矩陣乘法,在稠密矩陣乘法運算中獲得了較高的計算性能,并對稀疏矩陣進行了優(yōu)化處理。但針對大維度的矩陣乘法,上述方法的I/O帶寬成為制約性能的瓶頸。文獻[5]提出了一個基于FPGA的Systolic乘法,保留了脈動陣列的運算速度。但隨著矩陣規(guī)模的增大,該算法需要的運算資源和I/O帶寬成比例增長,限制了該設計的可擴展性,導致實用性較低。
上述研究雖然在特定規(guī)模下的矩陣乘法中獲得了優(yōu)越的加速性能,但隨著矩陣規(guī)模的變化,上述方案的性能優(yōu)勢難以體現,對不同維度的矩陣乘法通用性不高。另一方面,脈動陣列需要一個全局時鐘來控制全部的運算節(jié)點,必然會存在大量的時鐘偏移(Clock-Skew)問題[6-8]。隨著集成電路制造工藝的迅速發(fā)展,特征尺寸越來越小,工作頻率不斷提高,時鐘偏移和連線延時對設計工作具有重大影響,甚至會導致整個設計系統(tǒng)出現問題。
NoC(Network on Chip)作為一種全新的片上系統(tǒng)設計方法[9-14],不僅克服了單一時鐘頻率同步全局芯片工作方式帶來的種種制約問題,還可以通網絡靈活地構建多種運算結構,克服了固定運算結構中提高特定規(guī)模矩陣乘法性能的局限性,具有較好的適應性和擴展性。本文研究在有限的I/O帶寬資源約束下,對不同維度的矩陣乘法運算進行任務調度及資源分配,充分利用了NoC通信并行性和多核系統(tǒng)計算并行性,提高了矩陣乘法的計算效率。
1 矩陣乘法分析
常采用的并行矩陣乘算法有旋轉矩陣元素(Cannon)算法、復制矩陣元素(DNS)算法,以及采用流水線(脈動陣列)算法。Cannon算法源于空間對準思想,需要預先在運算節(jié)點中分配好數據,此過程處理難度較大,不易于實現。DNS算法是面向立方體的處理器結構,其結構難以表示。脈動陣列算法結構簡單且分布規(guī)則,數據按照流水線的形式直接輸入到節(jié)點中,更易于設計實現[15]。
給定兩個矩陣A和B,矩陣C=A·B表示二者的積,如式(1)和式(2)所示。
(1)
(2)
這些方程的空間表示如圖1所示。

圖1 矩陣乘法的三維空間圖
脈動算法源于時間對準思想。首先,對矩陣的行列向量進行分配,將數據輸入到運算節(jié)點中,計算的結果進行本地緩存,并作為下一次計算的中間值,用于計算的數據傳入相鄰的運算節(jié)點中執(zhí)行運算,直至該向量運算結束。由圖1可以看出,矩陣A的行向量(a11,a12,a13)、(a21,a22,a23)、(a31,a32,a33)分別進入i軸方向的運算節(jié)點,矩陣B的列向量(b11,b12,b13)、(b21,b22,b23)、(b31,b32,b33)分別進入j軸方向的運算節(jié)點,通過k軸方向上的節(jié)點運算后得到結果矩陣C,簡化的依賴圖如圖2所示。
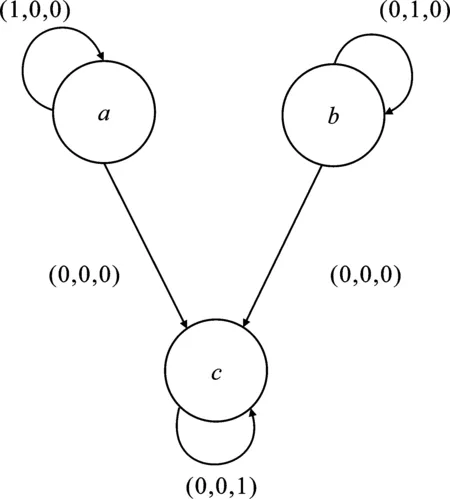
圖2 矩陣乘法的依賴圖
由圖2可知,迭代的標準輸出形式可以表示為式(3)。
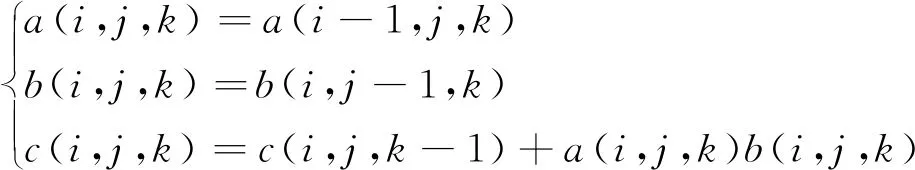
(3)
用于矩陣運算的脈動陣列主要分為一維、二維脈動陣列結構,如圖3所示。
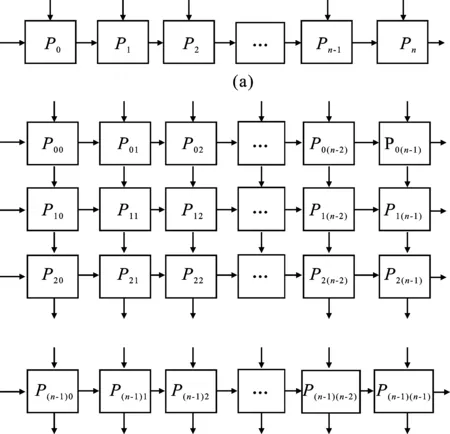
圖3 脈動陣列結構圖
一維線性陣列可在固定的存儲帶寬下實現矩陣乘法的加速運算[16],通過提高運算資源來滿足性能需求。相比于一維陣列,二維脈動陣列需要更高的I/O帶寬資源,通過增加運算并行度來獲得良好的加速性能[17]。結合脈動陣列算法,本文在多核系統(tǒng)中針對不同維度的矩陣乘法實現了多種有效的映射方案,既滿足了對不同維度矩陣乘法運算的適應性,又保留了脈動陣列算法卓越的運算性能。
2 基于NoC多核系統(tǒng)
基于NoC多核系統(tǒng)是一種可編程的多核處理系統(tǒng),主要面向復雜度高、數據帶寬要求大的計算密集型應用,如圖4所示。
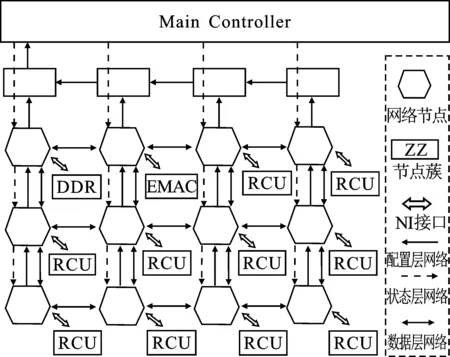
圖4 NoC多核系統(tǒng)的結構框圖
系統(tǒng)中主要包括主控制器(Main Controller)、NoC網絡節(jié)點,其節(jié)點中掛載了可重構運算單元(Reconfigurable Calculate Unit,RCU)以及外圍存儲器。NoC網絡是整個系統(tǒng)數據傳輸樞紐,主要負責網絡節(jié)點間的數據傳送。主控制器通過片上網絡實現了對節(jié)點中運算單元的控制管理,保證了系統(tǒng)高效的數據通信效率。
RCU是一種可重構的計算單元,也是整個多核系統(tǒng)的核心運算單元,支持IEEE 754標準的32位單精度浮點運算能力。在不同配置信息下,RCU可以完成多種規(guī)則的單精度浮點運算,包括加、減及乘累加等運算。RCU結構如圖5所示。
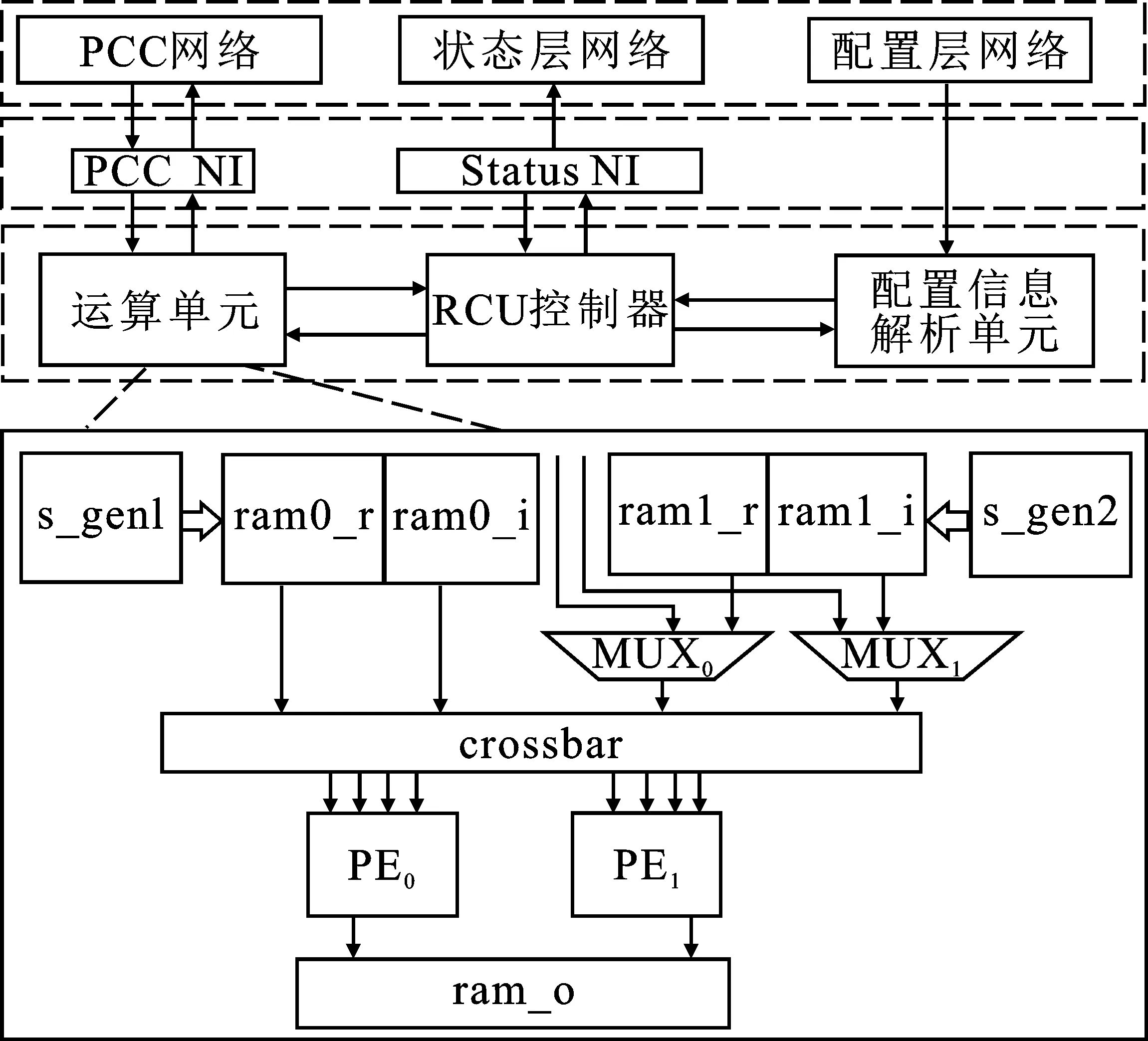
圖5 RCU結構圖
NoC系統(tǒng)可以支持多種工作模式:流、存儲和脈動工作模式。圖6為流模式的結構圖,結構中兩條路徑route1、route2分別執(zhí)行雙目運算和單目運算。route1執(zhí)行xin的數據傳遞,待xin存入PE(Processing Element)后,yin直接流入PE進行計算,得到計算結果z=z+xin·yin。route2中xin不參與計算,流入PE的值為空值(NULL)。先執(zhí)行route1,并釋放route1執(zhí)行route2,寄存在PE中的xin作為源數據與新數據yin進行計算,有效提高了數據xin的復用度。
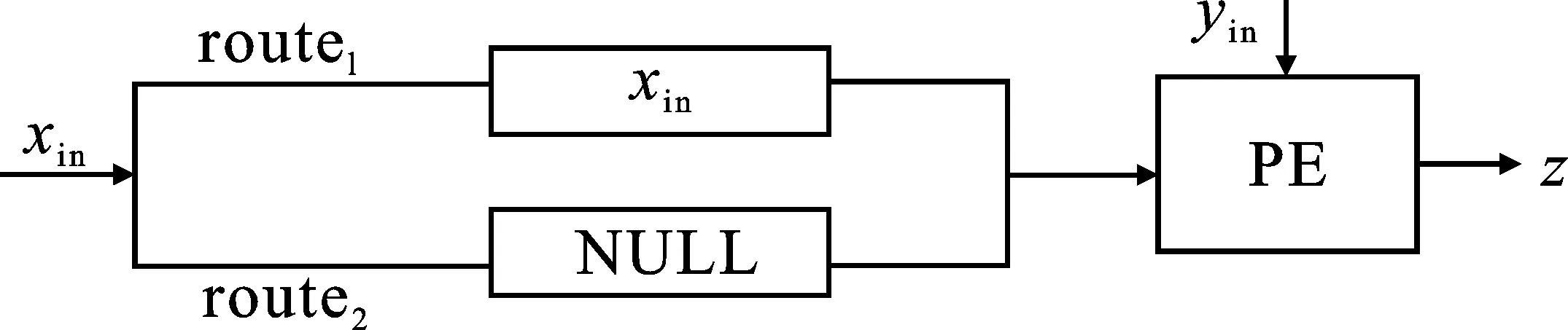
圖6 流模式結構圖
脈動模式利用了傳統(tǒng)脈動算法中數據的流動方式,如圖7所示。PE中計算結果z0、z1可以由式(4)表示。
(4)
計算完成后,z0和z1存儲在PE中作為下一次計算的中間結果,x0、x1和y0、y1分別流入相鄰節(jié)點,并以流水線形式進行傳遞。整個運算陣列可以同步工作,不僅提高了運算并行性,還獲得了較高的數據吞吐量。在有限的I/O帶寬下,為了保持系統(tǒng)的運算速度與I/O帶寬之間的平衡,脈動工作模式較適用于節(jié)點數較少的運算陣列。
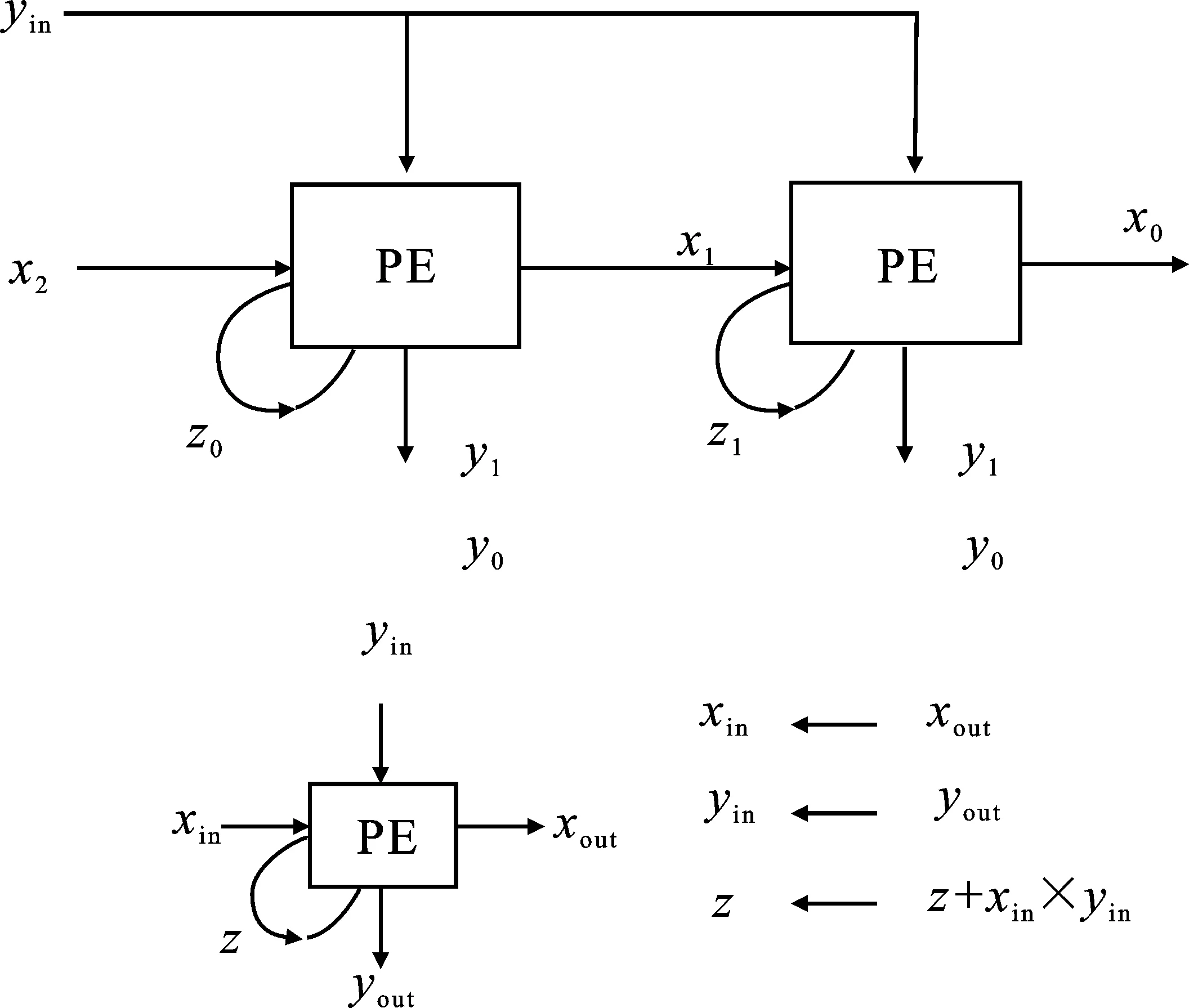
圖7 脈動模式結構圖
存儲模式中數據在運算節(jié)點中緩存,通過特殊的地址控制規(guī)則對數據進行讀寫控制,規(guī)則如圖8所示。

圖8 存儲模式運算規(guī)則
具體代碼如下:
輸入:矩陣v;矩陣s。
輸出:矩陣積h=v·s。
begin
for u=0 to N-1 do
for p=0 to N-1 do
h(u,p)=v(u)×s(p)
end for
end for
end
其中,u、p分別代表ram0中矩陣v行向量和ram1中矩陣s列向量的序列號;N為總向量個數。
該模式下數據可以實現完全復用,提高了數據復用性,減少了重復數據傳輸帶來的周期消耗及I/O帶寬占用率,并降低了數據傳輸周期占總運算周期的比值,可以有效提高系統(tǒng)的計算速度。
本文針對不同維度的矩陣在多種映射方案中靈活運用上述系統(tǒng)的工作模式,提高了矩陣乘法在陣列結構中的運算效率。
3 算法映射
基于NoC多核系統(tǒng)可實現多種運算結構,具有良好的靈活性。本設計分別以I/O帶寬和運算資源為設計導向,提出了多種映射算法。
3.1 基于I/O帶寬的矩陣乘法
在有限的I/O帶寬資源下,確定系統(tǒng)中最大帶寬通道的數量,通道數量的計算式如式(5)所示。其中,Q表示最大帶寬通道數量;W表示數據位寬;D表示最大可支持帶寬;f表示工作頻率。該算法通過對不同陣列結構進行合理的帶寬分配來提高計算并行度和帶寬利用率,如圖9所示。

(5)
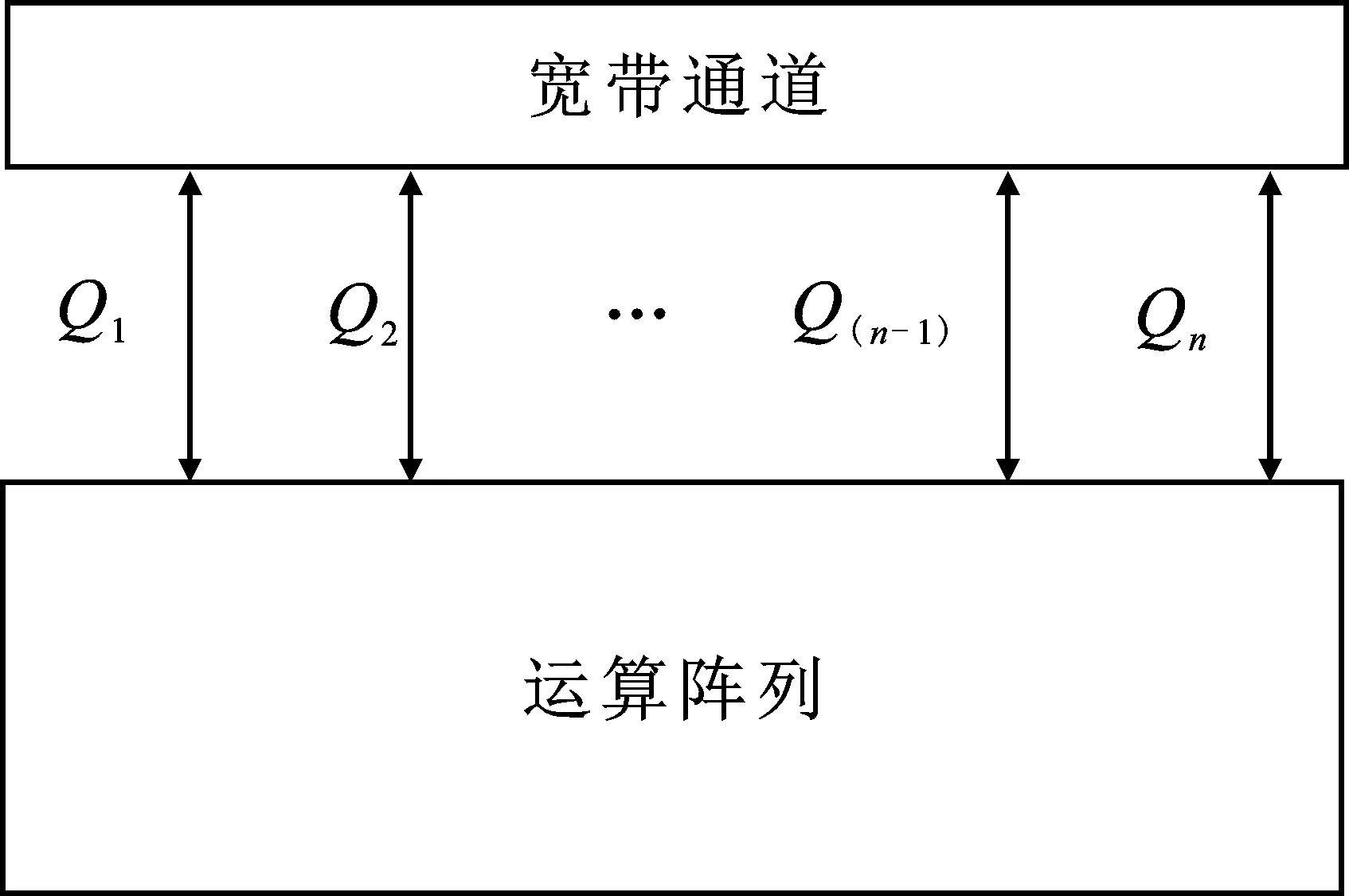
圖9 基于I/O帶寬的結構示意圖
本設計中外圍存儲接口的數據帶寬通道最大可以支持8路并發(fā),基于有限的I/O帶寬提出了以下幾種映射方案。
方案1該方案采用4×4的運算陣列,如圖10所示。
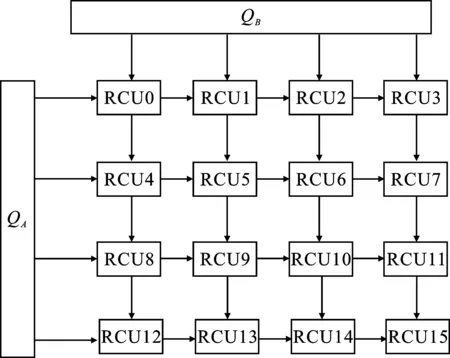
圖10 映射方案1
在該陣列中,QA、QB通道分別負責矩陣A和B的數據傳輸,并通過脈動傳輸方式在陣列中執(zhí)行計算。數據在流經陣列的交叉計算節(jié)點時實現多次復用,充分保留了脈動陣列高度并行流水的運算形式。計算的結果在RCU內部存儲器中緩存,每個RCU可存儲2 k點的結果數據。可以看出,方案1中的運算陣列最大可支持32 k點數據緩存,緩解了數據回寫引起的帶寬負擔。但當矩陣維度大于128時,本地數據緩存空間不足,需要額外的帶寬用于數據回寫,導致乘法器中的計算單元出現空閑狀態(tài),影響系統(tǒng)整體的計算性能。
方案2在方案1的基礎上進行折疊、展開,得到方案2,其結構如圖11所示。
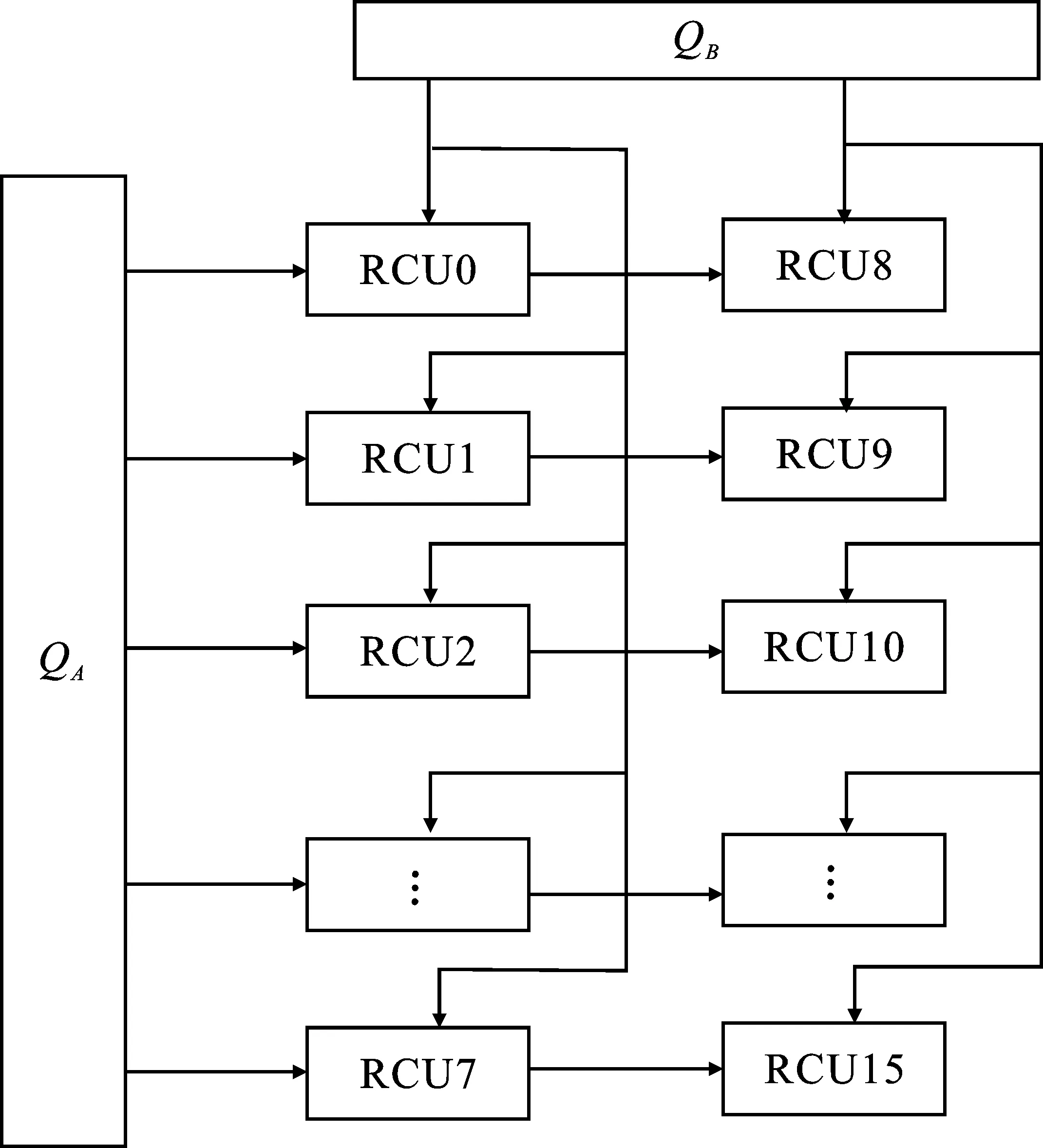
圖11 映射方案2
該結構為雙陣列結構,主要分為task1、task2兩個任務過程。task1如下:QB通道以廣播的數據傳輸形式向兩列運算單元發(fā)送矩陣B的列向量元素,待數據傳輸完成后,釋放QB通道,執(zhí)行task2。task2為:QA通道發(fā)送矩陣A的行向量元素,并采用存儲模式在RCU節(jié)點中完成向量乘運算,得到的計算結果在本地緩存,直至完成矩陣的所有運算,輸出結果矩陣。
在處理階數不大于64的矩陣乘法時,相比于方案1,方案2中數據的分配控制相對簡單,并且可以實現數據的完全復用,有效地減少重復數據傳輸次數,降低了運算節(jié)點的閑置率。當矩陣維度處于64~128之間時,矩陣B通道的傳輸次數增加,但并不影響整個結構的并行運算形式。當維度大于128時,本地空間不足導致陣列單元的閑置率增大,系統(tǒng)的運算性能受到影響。
3.2 基于運算資源的矩陣乘法
方案3隨著矩陣規(guī)模的進一步增大,僅僅利用有限的I/O帶寬來提高矩陣乘法的運算速度是不夠的。在具有充足的運算資源下,上述兩種映射方案由于受到I/O帶寬的限制,運算資源將成為大維度矩陣乘法運算的瓶頸。為了提高運算結構的可擴展性,系統(tǒng)采用固定帶寬數量為Qs(Qs=QA+QB+QC=3)的線性陣列結構。該結構可以將NoC系統(tǒng)中掛載的所有計算節(jié)點連接在一起,并且不受I/O帶寬的影響,如圖12所示。
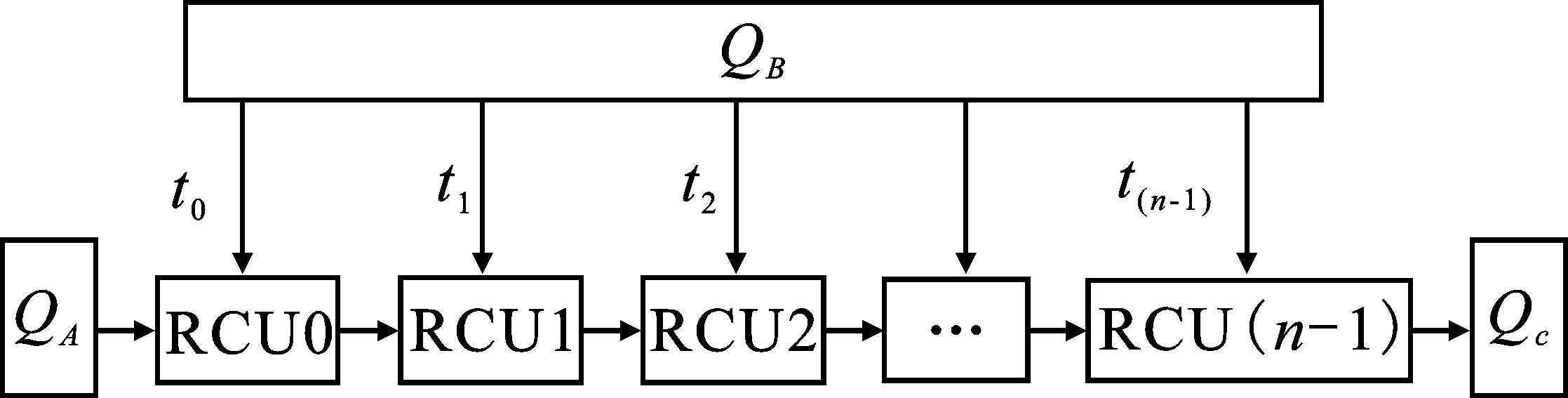
圖12 映射方案3
在該方案中,QA通道通過線性陣列傳遞矩陣A的數據,QB通道采用單通道的分時傳遞方式。t0時刻,完成第n=0個RCU節(jié)點的數據傳送;t1時刻,完成第n=1個RCU節(jié)點的數據傳輸,此時第n=0個RCU節(jié)點中通過流工作模式與流經該節(jié)點的數據進行計算;tn時刻,其中tn=t(n-1)+1,結束第n-1個RCU節(jié)點的數據傳輸,并重新向第n=0個RCU節(jié)點發(fā)送數據。這種傳輸方式提高了運算結構的可擴展性,保證數據的高效復用和并行流水的運算機制。同時,針對大維度的矩陣乘法,可以在更低的I/O帶寬要求下調度當前系統(tǒng)中所有的運算資源,相比方案1和方案2,該方案預留了數據結果的回寫通道Qc,解決了大維度矩陣運算中由于I/O帶寬、存儲空間不足而導致的運算節(jié)點的閑置問題,能夠有效提高大規(guī)模矩陣乘法的運算速度。
4 實驗和結果分析
本實驗在Xilinx公司Virtex7系列XC7V2000T FPGA芯片上進行原型驗證。RCU內部PE單元的浮點乘法器和加法器使用Xilinx公司提供的Floating Point IP核實現。本設計中所使用的FPGA開發(fā)環(huán)境和仿真環(huán)境為Xilinx Vivado 2018.3及MentorGraphics Modelsim SE-64 10.2c。
4.1 系統(tǒng)的峰值計算性能
理想情況下,系統(tǒng)中RCU單元每個周期可以完成1次單精度浮點乘法和1次單精度浮點加法操作。系統(tǒng)的計算性能可由式(6)得出
PERFpeak= 2×(P×f)
(6)
式中,PERFpeak表示矩陣乘法器的峰值計算性能(每秒百萬次浮點操作);P為RCU節(jié)點的個數;f為矩陣乘法器工作的時鐘頻率。各映射方案的FPGA內部資源使用情況如表1所示,該乘法器在未作優(yōu)化的情況下工作頻率為158.7 MHz。由此可以得出該系統(tǒng)的峰值計算性能可以達到5 078 MFLOPS。

表1 FPGA內部資源消耗表
4.2 系統(tǒng)對不同規(guī)模下矩陣乘法的性能分析
表2為系統(tǒng)中在不同規(guī)模下矩陣乘法的運算周期,為了方便對比,脈動陣列中由16個運算單元組成的4×4陣列。

表2 不同矩陣乘法的運算周期
由表2中的實驗結果可以看出,當矩陣階數不大于128時,方案3的運算消耗的周期數最大,高于方案1和方案2的周期數。當階數大于128的矩陣乘法時,方案3的運算周期消耗最小,并逐漸與脈動陣列的運算周期相近。
為了方便對實驗結果的進一步分析,以不同映射方案的運算并行度更直觀地表示系統(tǒng)的運算性能,其中并行度定義計算式為
(7)
式中,Ep表示并行度;Sp表示加速比;Ts表示串行算法的計算時間;Tq表示在q個運算節(jié)點下的計算時間;q表示計算節(jié)點個數。各映射方案的計算并行度如表3所示。
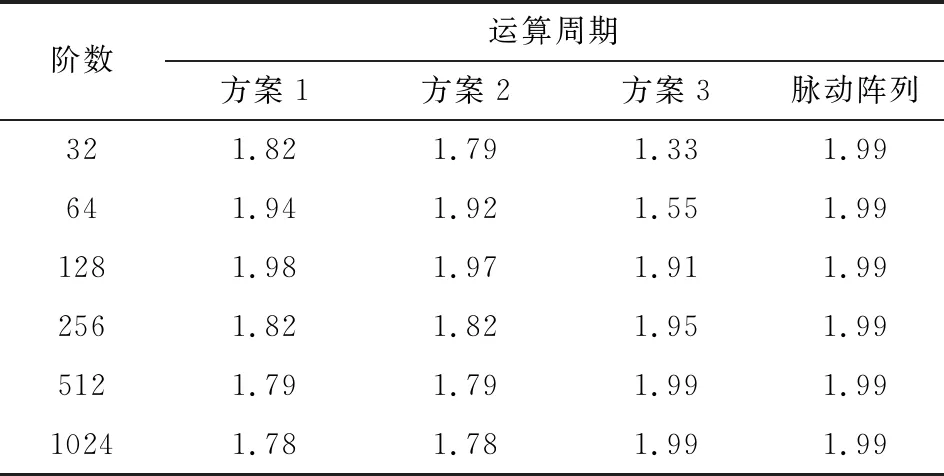
表3 不同映射方案的運算并行度
由表3可知,矩陣階數小于128時,方案1和方案2的運算并行度高于方案3,并逐漸趨近于脈動陣列的運算并行度。當矩陣階數大于128時,方案1和方案2的運算并行度不斷下降。而隨著矩陣維度的不斷增大,方案3運算并行度不斷提高,最終達到脈動陣列的運算并行度,并保持不變。
可以總結出,在處理規(guī)模相對較小的矩陣乘法時,方案1和方案2高度并行的數據傳輸和運算形式有效提高了矩陣乘法的運算速度,并獲得了較高的運算并行度。但隨著矩陣規(guī)模增大,方案1、方案2中存儲容量和帶寬資源達到上限,數據回傳周期占總運算周期的比例越來越大,導致運算速度受到限制,并行度也隨之降低。此時方案2的數據傳輸周期占總周期的比例會越來越小,運算節(jié)點的閑置率最低,并保持高度并行全流水的運算形式,從而獲得了良好的運算性能。
5 結束語
本文通過對矩陣乘法硬件加速常規(guī)算法的分析,設計了一種基于NoC多核系統(tǒng)的矩陣乘法器,并在Xilinx XC7V2000T FPGA上進行了實現。該矩陣乘法器不僅可以利用系統(tǒng)可重構性針對具體的性能需求靈活地改變運算結構,提高矩陣乘法器的通用性和可擴展性,還保留了脈動陣列算法中高度并行的運算形式,取得良好的運算性能。系統(tǒng)整體的運算性能仍有較大的提升空間。為了獲得更高的并行度和運算速度,可以增加存儲資源、I/O帶寬以及運算節(jié)點個數,也可以進一步改善和增強RCU的運算性能,提出更高效的映射算法來提升矩陣乘法的運算速度。
猜你喜歡
工業(yè)設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
