潛變量機器學習方法在咖啡NIR定量分析中的應用
2021-05-11 07:22:06陳華舟許麗莉喬涵麗洪紹勇
光譜學與光譜分析 2021年5期
陳華舟,許麗莉,喬涵麗,洪紹勇
1.桂林理工大學理學院,廣西 桂林 541004 2.大數據處理與算法技術研究中心(桂林理工大學),廣西 桂林 541004 3.北部灣大學海洋學院,廣西 欽州 535011 4.廣州華商學院數據科學學院,廣東 廣州 511300
引 言
隨著生活質量的提高,食品的生產質量和品質安全直接關系到人們的健康,越來越多地受到人們的密切關注。咖啡是最流行的非酒精飲料之一,咖啡成分復雜,包含多種化合物,礦物質含量豐富,其中蛋白質是咖啡為人類提供能量的主要成分[1-3]。由于生長環境和加工方法的影響,不同種類的咖啡中的蛋白質含量存在一定差異,對于咖啡蛋白質含量的檢測已經有比較成熟的實驗室方法[4],然而化學檢測技術成本高、耗時長,需要化學試劑,容易造成污染,不能滿足當今社會快節奏的生活和高質量的檢測需要,同時,速溶咖啡粉末成品的制備和包裝過程中不可避免地添加了一些食品添加劑,這對于蛋白質成分的提純和檢測增加了復雜度。因此,尋求一種快速檢測技術來完成對咖啡蛋白質的檢測具有重要的社會意義。
隨著計算機和信息技術的發展,光譜快檢技術廣泛應用于農業、食品、生態環境、生物醫學等領域[5-7]。近紅外(NIR)光譜以其快速無損、無試劑、實時在線、多組分同時分析的特點得到相關行業認可[8-10]。而近紅外光譜的分析過程是多變量定標校正過程,需要結合化學計量學方法的研究和應用。近些年,NIR分析技術在食品行業的應用逐漸趨于成熟,利用近紅外光譜分析進行食品安全和品質檢測的精度要求越來越高,如多元回歸(MLR)、偏最小二乘法(PLS)等常規的線性分析方法已經不能滿足建模定標需求[11-12];大數據和智能計算技術的不斷更新,涌現出一系列非線性計量學分析方法,如支持向量機(SVM)、神經網絡(ANN)、極限學習機(ELM)等,用于NIR光譜建模,在定量分析方面取得良好的預測效果,能夠提高模型預測精度的同時還肯定了機器學習方法在NIR分析中的可行性[13-15]。
針對速溶咖啡粉末的蛋白質快速定量檢測的NIR光譜建模分析,提出利用SVM和ELM方法結合潛變量技術進行建模,討論兩種方法的參數優選和潛變量提取的聯合優化模式,結合簡單的建模前預處理,以達到提高NIR光譜分析精度的目的。與常用的PLS方法進行對比,驗證潛變量機器學習方法在近紅外定量分析中的應用優勢。
1 實驗部分
1.1 樣品采集與檢測
收集174份咖啡粉末樣品,采用常規食品蛋白質檢測技術(GB/T 5009.5—2003)測定每個樣品的蛋白質含量,作為NIR分析的參考化學值。所有樣品的蛋白質百分比含量最小值為46.55%,最大值為73.35%,平均值為60.00%,標準偏差值為4.97%。使用FOSS NIR Systems 5000光柵型光譜儀采集咖啡粉末樣本的近紅外光譜,以空氣作為背景,每測一個樣品伴隨著測量一次背景,用于光譜數據的基線校正。實驗環境溫度為(25±1) ℃,濕度為45%±1%RH的情況下,設置儀器內置光學系統對每個樣品(包括背景測量)自動掃描32次,波長范圍設置為1 000~2 500 nm,光譜分辨率為2 nm。光譜數據經過基線校正處理,消除光譜漂移影響,所得174個咖啡樣本的NIR光譜如圖1所示。
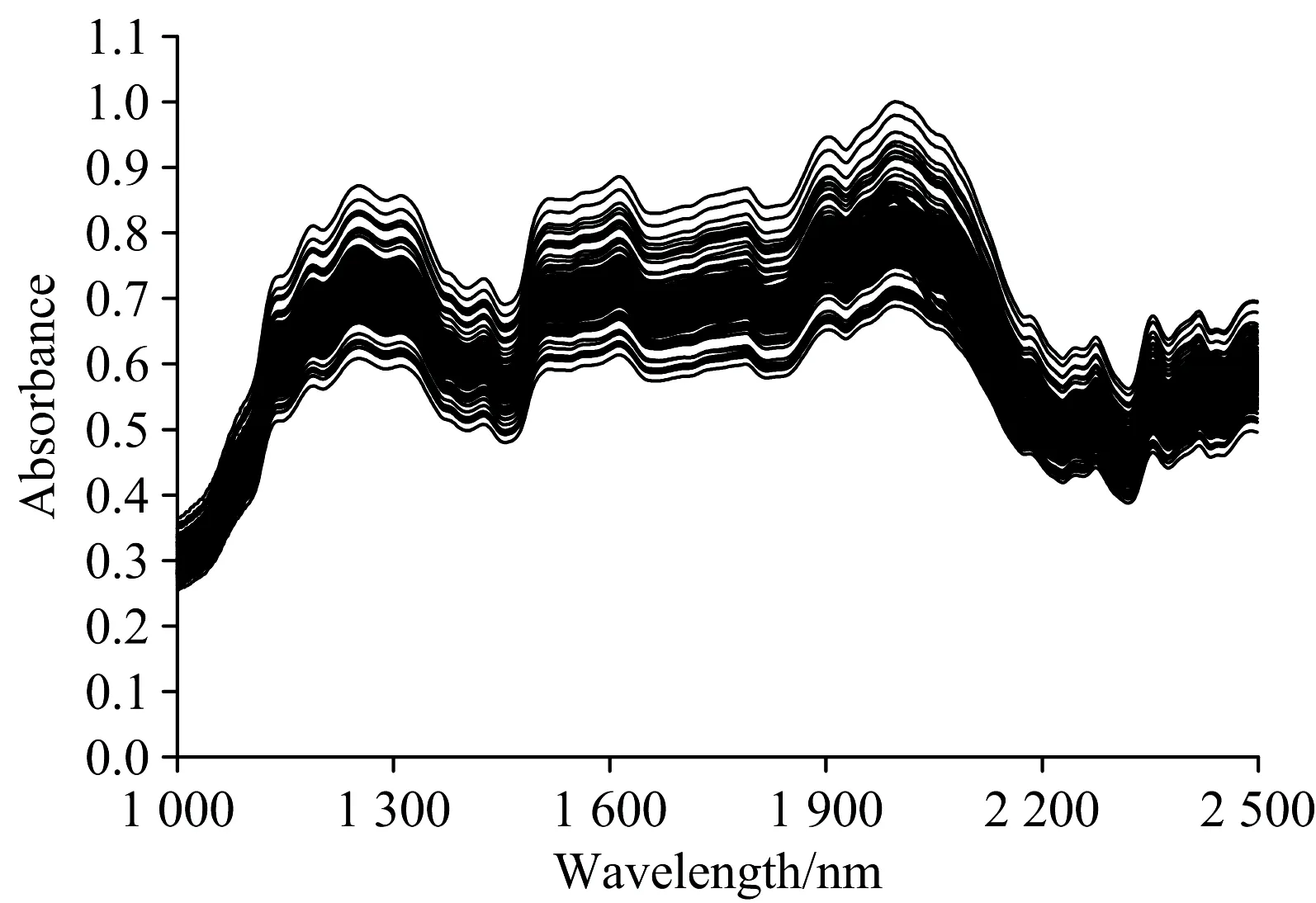
圖1 174個咖啡粉末樣本的NIR光譜Fig.1 NIR spectra of 174 coffee powder samples
1.2 潛變量機器學習方法
采用SVM和ELM兩種機器學習方法,結合潛變量分析技術,對174個咖啡蛋白質的NIR光譜快速檢測進行建模優化。潛變量是通過分析光譜數據的信號分布情況,提取出來的包含特定待測成分信息最大的綜合變量[16]。潛變量分析常用的方法有因子分析(FA)、主成分分析(PCA)、隱馬爾可夫模型(HMM)等;本工作利用PCA算法思想提取潛變量,并將潛變量提取過程與SVM和ELM進行聯合優化,形成操作方便的新型數據優化分析模型。
(1)潛變量支持向量機(LV-SVM)模型
LV-SVM的基本思路是采用PCA潛變量技術,將原光譜數據X通過潛變量提取形成光譜特征的潛變量特征數據LX,進一步利用非線性映射核函數將潛變量LX映射到一個更高維的特征變量空間,使得原來變量之間的非線性對應關系轉換成高維空間中的線性關系;加入松弛變量ξ,在特征空間中基于線性最優化理論構建目標函數,
s.t.f=wTφ(lxj)+b+ξj,
lxj∈LX,j=1,2,…,p
其中γ為正則化參數,ξj為松弛變量,lxj為潛變量矩陣LX的向量元素,b為偏差因子。此為凸二次規劃問題,可用Lagrange乘子法求解,經整理可以得到LV-SVM算法針對NIR光譜定量分析的預測模型為
其中yi為樣本待測成分含量,αj是Lagrange乘子,lxj為潛變量變換之后的特征光譜,bi為基線校正偏差。
(2)潛變量極限學習機(LV-ELM)模型
ELM算法是基于單一隱藏層的反饋式神經網絡(SLFN)權值優化理論提出的一種機器學習方法,它可以為SLFN系統提供更優化的模型訓練機制,以便更快速地確定最佳優化權值和最小訓練誤差,使其具有更好的泛化應用能力[17-18]。LV-ELM的基本思想是將PCA提取的潛變量(LX)作為SLFN的輸入變量,執行ELM算法過程,構建潛變量極限學習機模型,使得反饋式神經網絡極限學習的模式完全作用于待測成分特征的光譜數據。
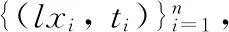
其中aj∈Rn和bj∈R(1,2,…,k)表示第j個隱含節點的學習參數,βj∈Rp表示隱含層的第j個節點到輸出層的連接權值,g(aj,bj,lxi)表示第j個隱含節點輸出值與輸入樣本特征變量lxi之間的關系。
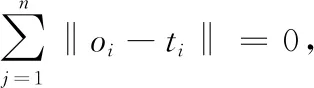
Hβ=T
其中H={hij=g(aj,bj,lxi)}為隱含層的輸出矩陣,β=(β1,β2,…,βk)為輸出權重矩陣,T=(t1,t2,…,tn)為目標輸出矩陣。于是,SLFN系統方程轉化為線性模型,則輸出權重可通過最小二乘法來確定,即可以得到β的估計值為
其中H-1為H的廣義逆矩陣。利用ELM優化估計的值來預測樣本待測成分的含量。
1.3 數據劃分與模型評價指標
咖啡蛋白質定量檢測的NIR建模采用定標—驗證—測試的模式進行,將全部174個樣本按照大約2∶1∶1的比例隨機劃分為定標集、驗證集和測試集,其中定標集樣本用于構建定量模型,驗證樣本用于對定標模型進行對比驗證和參數優選,然后將優化模型應用于測試集樣本進行模型評價。經過劃分之后的三個樣本集的統計數據如表1所示。
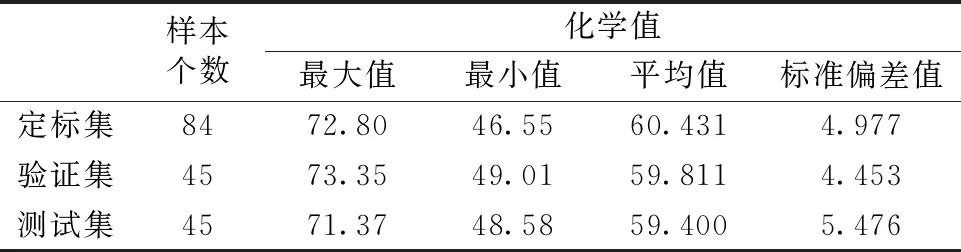
表1 定標集、驗證集和測試集樣本的咖啡蛋白質含量基本統計數據Table 1 The statistic data of coffee protein content for the calibrating, validating and testing sets
模型評價體系包括對驗證集樣品的評價和對預測集樣品的評價,評價指標有均方根偏差(RMSE)和相關系數(r),通過以下公式計算
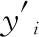
2 結果與討論
分別采用LV-SVM和LV-ELM兩種方法對咖啡粉末的NIR光譜建模,定量預測蛋白質含量,有利于人們選擇咖啡蛋白能量的攝取。針對84個定標集樣本建立LV-SVM模型進行訓練,首先基于全譜段數據提取潛變量信息,由于不同潛變量個數將影響建模效果,調試前30個潛變量,結合SVM學習過程進行聯合優化,設置正則化參數的調整范圍為γ=1,2,…,20,將每一個參數組合所對應的模型應用于45個驗證集樣本蛋白質含量的預測,通過比較不同潛變量個數(LV)、不同正則化參數(γ)取值,依據模型評價指標(RMSEV)確定建模優化參數。雙參數調試的LV-SVM建模驗證結果如圖2所示,其中圖2(a)為雙參數聯合調試任一參數組合的預測偏差,圖2(b)和圖2(c)分別為該預測結果分別對應r和LV兩個變量方向的最小預測偏差投影。依圖2可以選擇優化的r為14,LV為15,對應LV-SVM模型的優化RMSEV為6.797,對應的RV為0.877。
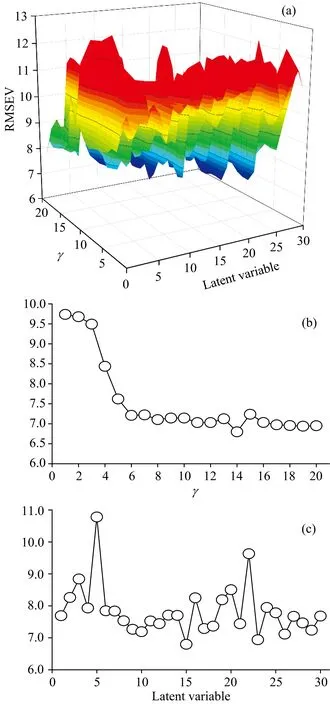
圖2 LV-SVM定標驗證模型的RMSEV優選Fig.2 The optimization of RMSEV for the LV-SVM calibration models
利用LV-ELM模型針對定標集樣本進行訓練,基于全譜數據提取潛變量LX,調試潛變量數量為1,2,…,30,結合ELM的學習優化過程,設置SLFN網絡的隱含層節點數量可變,調試取值為k∈{5,10,15,20,25,30,35,40,45,50},通過反饋式迭代確定各個隱含節點的參數,利用最小二乘回歸計算SLFN隱含層至輸出層的權值β,進而完成對驗證集樣本的蛋白質含量預測。通過比較不同潛變量個數(LV)、不同隱含層節點個數(K)的取值,依據RMSEV確定建模優化參數。雙參數調試的LV-ELM建模驗證結果如圖3所示,其中圖3(a)為雙參數聯合調試任一參數組合的預測偏差,圖3(b)和圖3(c)分別為該預測結果分別對應K和LV兩個變量方向的最小預測偏差投影。依圖3可以選擇優化的K為40,LV為18,對應LV-ELM模型的優化RMSEV為6.118,對應的RV為0.908。
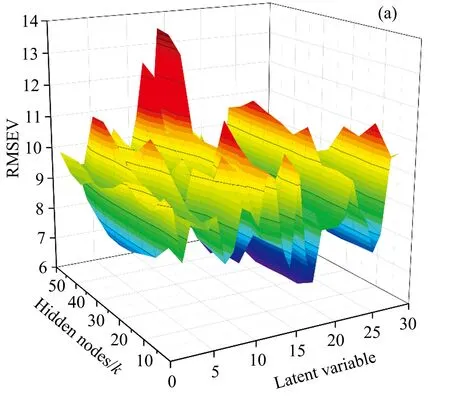
圖3 LV-ELM定標驗證模型的RMSEV優選Fig.3 The optimization of RMSEV for the LV-ELM calibration models
利用上述定標和驗證過程得到的最優建模參數,即15個潛變量、正則化參數為14的LV-SVM模型和18潛變量、40個隱含層節點的LV-ELM模型,分別對測試集的45個咖啡樣本的蛋白質含量進行預測,計算對應的RMSET和RT,所得結果列于表2中;同時將常規PLS定標的優化模型預測結果也列于表中進行比較。對比可知,LV-SVM和LV-ELM方法在咖啡蛋白的NIR光譜快速定量分析中能夠取得比常規PLS方法更優的預測精度,且LV-ELM模型取得相對于LV-SVM模型更好的預測結果。經過定標—驗證—測試結果可知,潛變量提取結合機器學習的方法在近紅外定量分析中具有一定的應用優勢,比常規的線性建模方法更有應用前景。
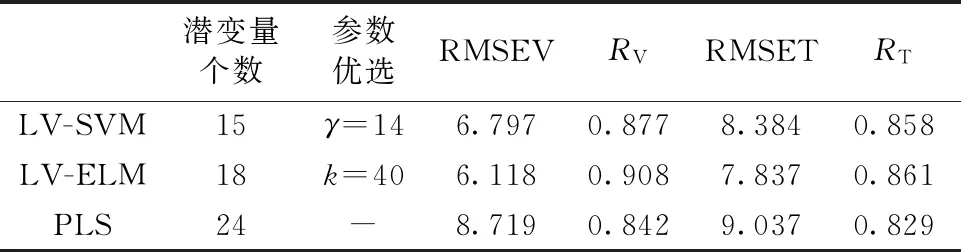
表2 LV-SVM,LV-ELM和PLS方法對咖啡蛋白質的NIR建模預測結果Table 2 The NIR model prediction results for coffee protein based on the LV-SVM, LV-ELM and PLS methods
3 結 論
采用NIR光譜快速檢測技術實現對速溶咖啡樣本中蛋白質含量的定量檢測,在建模方法上采用潛變量結合機器學習的聯合優化方法,建立LV-SVM和LV-ELM定標預測模型,形成SVM或ELM關鍵參數和潛變量優選的雙參數聯合調試模式,使建模預測偏差結果形成三維隨動優選結構。該方法能夠在實現變量降維的同時優選建模參數,對咖啡蛋白質的定量分析取得良好的預測效果,經過定標—驗證—測試三個環節的建模對比,該方法普遍優于常規PLS的建模預測。結果表明,潛變量結合機器學習聯合參數優化方法能夠為NIR快速檢測技術提供良好的建模分析手段,有望推廣應用于其他類型的咖啡樣本進行快速品質鑒定。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
