基于二級(jí)并行架構(gòu)的顆粒全息圖快速重建方法
2021-05-10 05:51:14浦世亮金其文陳曉鋒吳學(xué)成
激光技術(shù) 2021年6期
浦世亮,金其文,陳曉鋒,毛 慧,吳學(xué)成*
(1.杭州海康威視數(shù)字技術(shù)股份有限公司,杭州 310051;2.浙江大學(xué) 能源清潔利用國(guó)家重點(diǎn)實(shí)驗(yàn)室,杭州 310027)
引 言
全息術(shù)作為一種3維照像技術(shù),自發(fā)明以來(lái)經(jīng)過(guò)記錄介質(zhì)的更新?lián)Q代,由光學(xué)全息發(fā)展為數(shù)字全息,并廣泛地應(yīng)用在流場(chǎng)和顆粒場(chǎng)測(cè)量領(lǐng)域[1-2]。數(shù)字全息技術(shù)測(cè)量顆粒場(chǎng)的優(yōu)勢(shì)在于可同時(shí)測(cè)量3維空間中的顆粒位置、形貌、粒徑參量,結(jié)合粒子圖像/軌跡測(cè)速(particle image/trackingvelocimetry,PIV/PTV)還可進(jìn)一步測(cè)量速度、旋轉(zhuǎn)等參量。然而數(shù)字全息技術(shù)的重建過(guò)程需要大量的計(jì)算時(shí)間,全息圖數(shù)量越多、分辨率越高、重建截面越多,計(jì)算耗時(shí)也迅速增加。這限制了全息技術(shù)應(yīng)用于工業(yè)過(guò)程中顆粒場(chǎng)實(shí)時(shí)在線監(jiān)測(cè)[3]。
為了提高全息重建的速度,國(guó)內(nèi)外的研究人員已經(jīng)開(kāi)展了相關(guān)的研究工作。加快重建速度一般可以從兩方面著手:一方面是采用性能更強(qiáng)的計(jì)算硬件,比如采用圖形處理單元(graphics processing unit,GPU)[4-7]和大規(guī)模可編程門陣列(field-programmable gate array,FPGA)[8];另一方面是優(yōu)化重建算法和并行架構(gòu),比如采用多線程編譯框架(open multi-processing,OpenMP)。其中,GPU技術(shù)由于具有開(kāi)發(fā)過(guò)程更為簡(jiǎn)單和可移植性更強(qiáng)的優(yōu)點(diǎn)[9],已經(jīng)被廣泛使用,一般需要搭配NVIDIA顯卡的統(tǒng)一計(jì)算設(shè)備架構(gòu)(compute unified device architecture,CUDA)[10]。
快速傅里葉變換(fast Fourier transform,FFT)是全息重建中的主要耗時(shí)算法,MASUDA等人[8]設(shè)計(jì)的全息PTV系統(tǒng),F(xiàn)FT 由FPGA芯片完成,對(duì)于256×256的全息圖,重建100個(gè)截面的時(shí)間為266ms。ZHANG等人[11]比較了CPU和GPU進(jìn)行全息重建的計(jì)算性能,使用OpenMP多線程技術(shù)進(jìn)行算法優(yōu)化,重建速度顯著增加。YAMAMOTO等人[12]發(fā)展了一種用于高速全息3維成像的專用計(jì)算機(jī),包括4個(gè)計(jì)算模塊,重建速度相比于普通計(jì)算機(jī)提高了68倍。ZHU等人[7]基于GPU并行技術(shù),開(kāi)發(fā)了數(shù)字全息實(shí)時(shí)再現(xiàn)系統(tǒng),每秒平均可以處理20張分辨率為512×512的全息圖。MA等人[13]將OpenMP應(yīng)用于數(shù)字全息3維重構(gòu),比較了不同并行方法的加速效果,證明了OpenMP可有效提高全息重建速度。
為了滿足數(shù)字全息技術(shù)在工業(yè)應(yīng)用過(guò)程中的實(shí)時(shí)性需求,快速獲取3維顆粒場(chǎng)信息,本文中提出了一種基于OpenMP圖片級(jí)并行和基于CUDA像素級(jí)并行的二級(jí)并行架構(gòu)。以小波重建方法為例,分析了小波重建的計(jì)算流程,在此基礎(chǔ)上提出了計(jì)算流程改進(jìn)、并行計(jì)算思路和二級(jí)并行實(shí)現(xiàn)方式。以煤粉顆粒全息圖為實(shí)驗(yàn)對(duì)象,測(cè)試了二級(jí)并行架構(gòu)的重建準(zhǔn)確性和加速性能。
1 理論基礎(chǔ)與并行實(shí)現(xiàn)
數(shù)字同軸全息3維顆粒場(chǎng)測(cè)量主要包括顆粒全息圖的記錄和數(shù)值重建兩個(gè)過(guò)程。在全息記錄過(guò)程中,一束平行激光照射顆粒場(chǎng),一部分光由顆粒散射作為物光,另一部分未經(jīng)散射的光作為參考光,物光與參考光干涉后,由數(shù)字相機(jī)記錄形成顆粒全息圖。數(shù)字全息重建是指用計(jì)算機(jī)模擬光的傳播,采用全息重建算法獲得全息圖中的3維顆粒場(chǎng)信息。菲涅耳積分重建、角譜重建、分?jǐn)?shù)傅里葉變換重建和小波重建是常見(jiàn)的全息重建方法。小波重建具有全息重建圖像信噪比高和圖像背景均勻的優(yōu)點(diǎn),本文中利用小波重建方法進(jìn)行全息重建提取顆粒信息[14],并對(duì)基于小波重建的并行設(shè)計(jì)進(jìn)行分析介紹。根據(jù)小波母函數(shù)Ψ0(x,y)=sin(x2+y2),構(gòu)造小波函數(shù):
(1)
式中,a為尺度參量,與重建距離有關(guān),其表達(dá)式為:
(2)
式中,λ是激光波長(zhǎng)。
對(duì)構(gòu)造的小波函數(shù)進(jìn)行適當(dāng)調(diào)整,引入高斯窗函數(shù)exp[-(x2+y2)/(a2σ2)]使小波函數(shù)在偏離中心點(diǎn)處的值迅速趨于零,同時(shí)引入一個(gè)調(diào)零參量K,使其均值為零,K(σ)的表達(dá)式為:
(3)
式中,σ為窗函數(shù)帶寬因子,代表窗函數(shù)的寬度,依賴于全息圖采樣特性,其表達(dá)式為:
(4)
式中,N和δ分別為相機(jī)分辨率和像素尺寸,ε為一個(gè)數(shù)值極小的常數(shù)。最終得到校正的小波函數(shù)可表示為:
Ψ(x,y)=
(5)
全息圖Iholo(x,y)重建圖像的光強(qiáng)I(x,y,z)可以表示為:
I(x,y,z)=

(6)
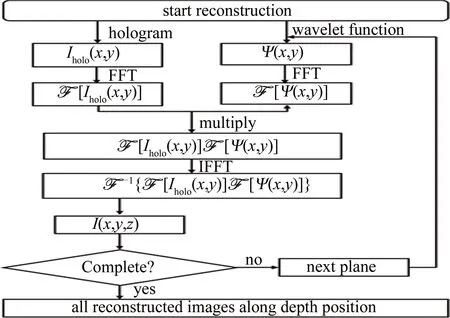
Fig.1 Flow chart of reconstruction with wavelet method
全息重建是在深度方向進(jìn)行切分,得到一系列不同深度z處的重建圖像。計(jì)算過(guò)程中有些變量與z有關(guān),如a和σ,有些變量與z無(wú)關(guān),如(x2+y2),對(duì)于與z無(wú)關(guān)的變量可作為局部變量保存,避免多次計(jì)算。全息圖的重建過(guò)程具有二級(jí)特征,第1級(jí)為重建截面之間的獨(dú)立性,第2級(jí)為像素點(diǎn)之間的獨(dú)立性,因?yàn)橹亟ń孛嬷g和像素點(diǎn)之間沒(méi)有數(shù)據(jù)的交換,得到結(jié)果像素的計(jì)算過(guò)程對(duì)于每個(gè)像素是獨(dú)立的。這使得并行計(jì)算非常適用于全息圖的快速重建,而且是“圖片級(jí)+像素級(jí)”的二級(jí)并行,二級(jí)并行架構(gòu)的具體實(shí)現(xiàn)如圖 2所示。利用OpenMP實(shí)現(xiàn)圖片級(jí)并行,利用CUDA實(shí)現(xiàn)像素級(jí)并行。除了用于單張全息圖的并行重建,當(dāng)面對(duì)海量的全息圖數(shù)據(jù)而這些全息圖重建參量一致時(shí),可以將每個(gè)重建截面的F[Ψ(x,y)]作為局部變量保存,同樣可以避免重復(fù)計(jì)算,加快批處理速度。
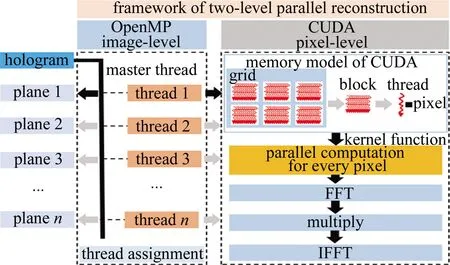
Fig.2 Framework of two-level parallel reconstruction
OpenMP是一個(gè)應(yīng)用程序接口(application programming interface,API),用于在多個(gè)處理器上編寫(xiě)并行程序?qū)崿F(xiàn)多線程之間的并行計(jì)算、內(nèi)存共享和負(fù)載分配。OpenMP使用最頻繁的編譯指導(dǎo)語(yǔ)句為#pragma omp parallel for[子語(yǔ)句],用OpenMP實(shí)現(xiàn)圖片級(jí)并行的主要代碼如圖3所示。主程序中firstprivate(z)表示重建深度z為私有變量,變量image為全息圖的傅里葉變換F[Iholo(x,y)],為公有變量。CUDA并行架構(gòu)程序包括主機(jī)端和設(shè)備端兩部分,分別在GPU和CPU上執(zhí)行,主要流程是顯存申請(qǐng)(cudaMalloc)、數(shù)據(jù)拷貝(cudaMemcpy)、數(shù)據(jù)運(yùn)算、數(shù)據(jù)拷貝。數(shù)據(jù)運(yùn)算由核函數(shù)在GPU上運(yùn)行,采用__global__ static void function進(jìn)行函數(shù)定義,再用function函數(shù)可設(shè)置線程塊和線程數(shù)量。此外CUDA中有針對(duì)傅里葉變換的專用函數(shù)CUFFT,可直接調(diào)用。本文中針對(duì)小波重建編寫(xiě)的一些子函數(shù)及其功能如圖3所示。

Fig.3 Some codes for OpenMP and CUDA
2 實(shí)驗(yàn)與結(jié)果
2.1 實(shí)驗(yàn)裝置
本文中采用煤粉顆粒全息圖作為實(shí)驗(yàn)對(duì)象,測(cè)試二級(jí)并行架構(gòu)的準(zhǔn)確性和加速效果。實(shí)驗(yàn)裝置如圖4所示。采用同軸數(shù)字全息系統(tǒng)記錄煤粉顆粒流的全息圖。激光器發(fā)出的激光束經(jīng)過(guò)光強(qiáng)衰減、濾波、擴(kuò)束、準(zhǔn)直后照射煤粉顆粒場(chǎng),CCD相機(jī)記錄煤粉顆粒全息圖,其中激光器波長(zhǎng)為532nm,相機(jī)像素大小為5.5μm、分辨率可調(diào)。高性能工作站用于重建煤粉顆粒全息圖,工作站配備了2塊驍龍?zhí)幚砥?Intel Xeon E5-2680 v4)和4塊英偉達(dá)顯卡(NVIDIA Tesla P100)。實(shí)驗(yàn)中獲得了一系列不同分辨率的煤粉顆粒全息圖。

Fig.4 Experimental setup
2.2 重建準(zhǔn)確性驗(yàn)證
在二級(jí)并行架構(gòu)重建準(zhǔn)確性的驗(yàn)證中,比較了并行算法與單線程算法重建不同分辨率的煤粉顆粒全息圖的差異。圖5a為分辨率為1000×1000的煤粉顆粒全息圖;圖5b為單線程重建結(jié)果;圖5c為并行重建結(jié)果。重建深度z范圍為9cm至10cm,重建截面間隔為1mm。

Fig.5 Reconstructed images of coal powder hologram with different calculation method
計(jì)算圖5b和圖5c對(duì)應(yīng)位置的像素值的方差,作為重建準(zhǔn)確性的判別依據(jù)。計(jì)算得到圖5中二級(jí)并行與單線程重建結(jié)果圖的方差S=0.078,由于像素值的大小在0~255之間,所以可以基本認(rèn)為圖5b和圖5c是一致的。分別處理多張不同分辨率和重建參量的全息圖,計(jì)算兩種重建算法的結(jié)果方差,結(jié)果如表1所示。表中,zmin為重建深度的最小值,zmax為重建深度的最大值,interval為重建間隔,variance為方差計(jì)算結(jié)果,隨著全息圖分辨率的增加,方差逐漸增大,但都小于0.1,表明不同方法重建圖差別極小。結(jié)果說(shuō)明基于二級(jí)并行架構(gòu)的全息重建程序與單線程全息重建程序在重建結(jié)果上是基本一致的,證明了二級(jí)并行架構(gòu)的重建準(zhǔn)確性。

Table 1 Comparisonofreconstructionresultsbetweensinglethreadandtwo-level parallel
2.3 重建加速效果對(duì)比
在二級(jí)并行架構(gòu)重建加速效果的驗(yàn)證中,首先同時(shí)使用單線程重建算法、二級(jí)并行架構(gòu)重建算法以及單線程調(diào)用CUDA的并行算法重建了從100×100~5000×5000的6種不同分辨率的全息圖,重建截面數(shù)都為40。3種方法計(jì)算耗時(shí)以及加速比(speedup ratio)如圖6所示。speedup ratio 1為單線程耗時(shí)與單線程調(diào)用CUDA耗時(shí)的比值,speedup ratio 2為單線程耗時(shí)與二級(jí)并行耗時(shí)的比值。如圖6所示,重建低分辨率的全息圖時(shí),二級(jí)并行架構(gòu)的加速效果不明顯,主要是因?yàn)橛?jì)算量小,單線程重建程序也有足夠的計(jì)算能力在短時(shí)間內(nèi)處理完成,而并行計(jì)算能力沒(méi)有充分體現(xiàn)出來(lái)。當(dāng)全息圖分辨率增大時(shí),重建耗時(shí)明顯減少。對(duì)于100×100,200×200,500×500,1000×1000,2000×2000和5000×5000的全息圖,二級(jí)并行架構(gòu)的加速比分別達(dá)到了22.8倍、30.7倍、36.1倍、42.7倍和48.3倍,充分顯示了其并行加速能力。全息圖的分辨率增大到1000×1000時(shí),加速比的增加開(kāi)始變得緩慢。這主要是由于一個(gè)重建截面的內(nèi)存動(dòng)態(tài)申請(qǐng)過(guò)程不能通過(guò)并行處理來(lái)加速,因此動(dòng)態(tài)申請(qǐng)內(nèi)存所消耗的時(shí)間占了很大的比例,加速比的增加也就逐漸平緩。單線程調(diào)用CUDA的重建耗時(shí)結(jié)果也證明了全息圖分辨率增大時(shí)動(dòng)態(tài)申請(qǐng)內(nèi)存的耗時(shí)會(huì)大大增加,分辨率大于1000×1000后,單線程調(diào)用CUDA的加速比迅速下降。在實(shí)際工程應(yīng)用中,例如工業(yè)粉體粒度的在線監(jiān)測(cè),往往要求數(shù)字全息技術(shù)的結(jié)果反饋時(shí)間在分鐘級(jí),假設(shè)全息圖分辨率為1000×1000,每張全息圖捕捉的顆粒數(shù)目為1000。60000顆顆粒能夠具有充分的代表性,那么至少需要處理60張全息圖。如果要在2min內(nèi)反饋結(jié)果,則一張全息圖的處理時(shí)間要少于2s,而本文中采用的并行架構(gòu)處理時(shí)間為1.41s,能夠滿足要求。
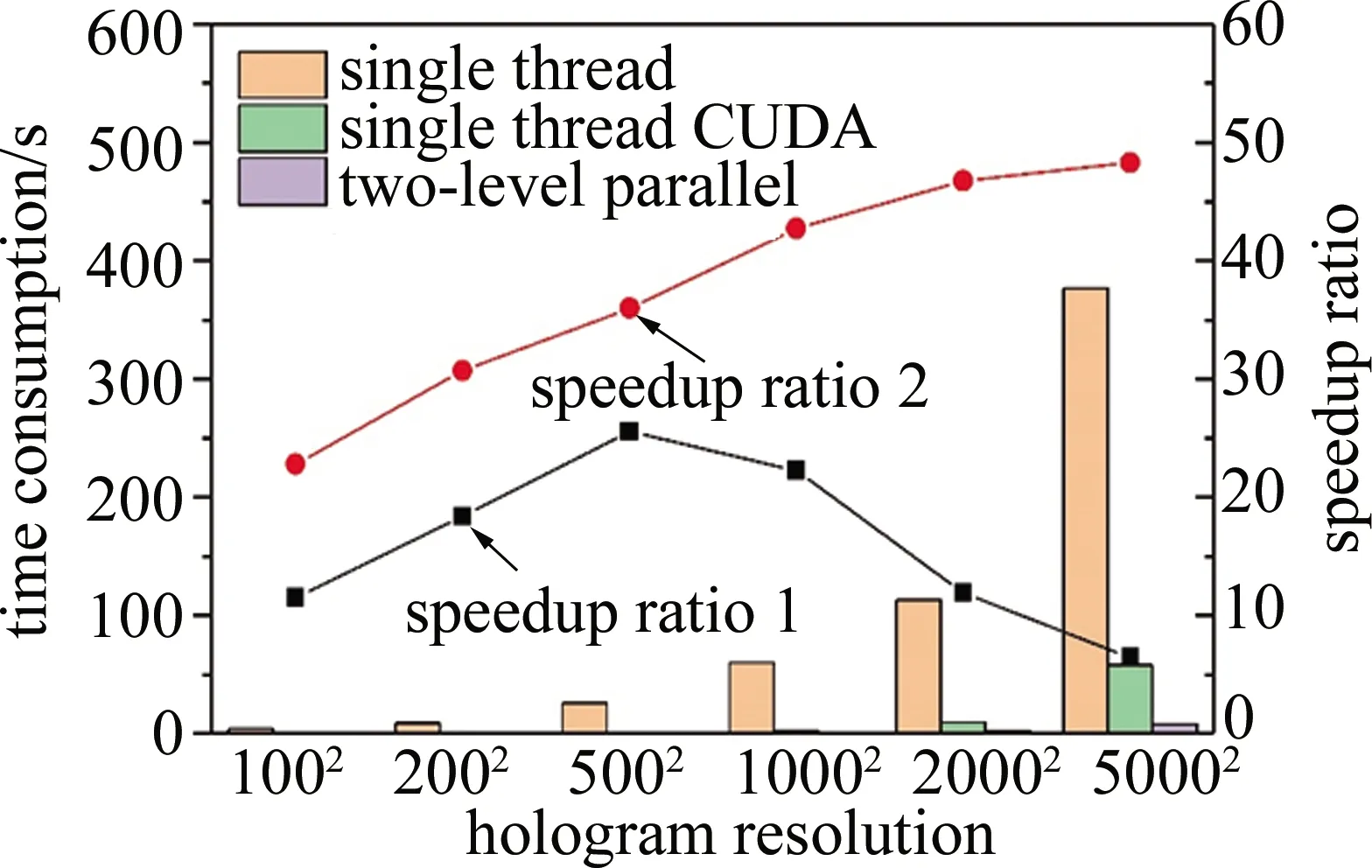
Fig.6 Time consumption of the three methods for holograms with different resolution
其次,選擇分辨率為1000×1000的全息圖,測(cè)試3種算法在重建截面數(shù)目不同時(shí)的計(jì)算耗時(shí)和加速比,結(jié)果如圖7所示。隨著重建截面的增多,單線程重建耗時(shí)急劇增加。二級(jí)并行算法的加速效果受限于線程數(shù)量,重建截面較少時(shí),計(jì)算耗時(shí)主要來(lái)源于線程通信,重建截面數(shù)目影響較小,隨著重建截面數(shù)目的增加,線程趨于滿負(fù)荷狀態(tài),此時(shí)二級(jí)并行算法的計(jì)算耗時(shí)隨之也會(huì)有較大的增加。而對(duì)于單線程調(diào)用CUDA,加速比都在20左右,重建截面數(shù)大于200后略有下降,這說(shuō)明CUDA的并行效果穩(wěn)定,單線程調(diào)用CUDA的重建耗時(shí)與單純單線程的重建耗時(shí)為近似線性的關(guān)系。以上不同分辨率和不同截面數(shù)下的實(shí)驗(yàn)結(jié)果表明,采用二級(jí)并行架構(gòu)重建全息圖,當(dāng)分辨率過(guò)大或重建截面過(guò)多時(shí),加速效果會(huì)受到內(nèi)存申請(qǐng)和線程通信的限制,在實(shí)際應(yīng)用過(guò)程中應(yīng)加以考慮。

Fig.7 Time consumption of the three methods for reconstruction with different plane numbers
3 結(jié) 論
提出了一種基于二級(jí)并行架構(gòu)的顆粒全息圖快速重建方法,該架構(gòu)結(jié)合了OpenMP多線程技術(shù)和CUDA技術(shù),利用OpenMP實(shí)現(xiàn)圖片級(jí)并行,利用CUDA實(shí)現(xiàn)像素級(jí)并行。以煤粉顆粒全息圖為實(shí)驗(yàn)對(duì)象,驗(yàn)證了二級(jí)并行架構(gòu)全息重建的準(zhǔn)確性和加速效果。結(jié)果表明二級(jí)并行架構(gòu)在保證了重建準(zhǔn)確性的同時(shí),可極大提高重建速度。對(duì)于分辨率為5000×5000的全息圖,可實(shí)現(xiàn)48.3倍的加速比。但隨著全息圖分辨率增大,加速比的增加會(huì)趨于平緩;隨著重建截面的增多,加速比則趨于穩(wěn)定。
