基于車流徑路選擇偏好的鐵路車流運行徑路動態預測方法研究
2021-05-10 13:39:52張紅斌金福才
鐵路計算機應用 2021年4期
關鍵詞:信息
張紅斌,李 軍,金福才
(1. 北京經緯信息技術有限公司,北京 100081;2. 中國國家鐵路集團有限公司 調度指揮中心,北京 100844;3. 中國鐵道科學研究院集團有限公司 電子計算技術研究所,北京 100081)
提高日班計劃編制質量,是充分利用運輸能力,提升運輸組織效率,保障高質量完成運輸任務的重要手段,而準確的車流預測是編制高質量日班計劃的前提條件。
關于車流徑路的研究主要考慮路網運輸方案[1]、空車調整方案[2]等,在推算車流徑路時主要使用最短路徑、次短路徑或K 條最短路徑計算方法。目前,鐵路運輸徑路計算機處理系統是鐵路部門一個重要的車流徑路推算工具,為鐵路運輸計劃管理、車流組織、運費計算以及收入清算提供支持[3-5]。在實際運輸生產過程中,由于受到施工、通過能力、機車(車務組)分配、自然災害、事故等多種因素的影響,經常會發生車流迂回運輸[6]。在選擇車流迂回徑路時,需要考慮多種因素:迂回徑路的通過能力、迂回徑路的長度、迂回徑路上的牽引方式[7]等。若依據實際運輸需求、路網能力制約以及迂回運輸選擇條件等因素,對全路網貨運車流徑路建模和預測,無疑是一項十分復雜的任務。為此,考慮利用運輸信息集成平臺提供的貨運車流海量歷史軌跡和實時位置追蹤數據,提出一種基于車流徑路選擇偏好的鐵路車流運行徑路動態預測方法。
1 基于車流徑路選擇偏好的鐵路車流運行徑路動態預測方法
中國國家鐵路集團有限公司(簡稱:國鐵集團)于2013 年建成運輸信息集成平臺,實現對列車、車輛、貨物、機車、機車乘務員位置與狀態的實時掌握與動態追蹤[8];貨運列車在裝、卸、技術作業等關鍵環節均會產生報告信息,可以較為準確地掌握貨運列車動態信息,結合列車編組信息,以車號、起訖點、途徑站為線索,進而可獲得貨運車輛的動態運行軌跡。
1.1 車流徑路選擇偏好概念簡介
針對車流運行徑路歷史數據的統計,提出長期和近短期車流徑路選擇偏好的概念;其中,長期車流徑路選擇偏好是過去較長時間內貨運車流運行徑路的大概率選擇,反映長期貨物運輸運輸組織策略影響下,對貨運車流不同運行徑路的優先選擇;近短期車流徑路選擇偏好則是近短期內貨運車流運行徑路的大概率選擇,可反映車流受到現階段施工、線路運輸能力等因素影響,對貨運車流不同運行徑路的優先選擇,對于預測當前車流運行徑路具有較好的參考價值。在預測車流運行徑路時,優先使用近短期車流徑路選擇偏好,只有在近短期車流徑路選擇偏好數據缺失的情況下,才考慮采用長期車流徑路選擇偏好。
1.2 車流徑路選擇偏好參數統計方法
列車動態位置信息主要包括列車到達與出發報告,是由列車運輸途中重要節點站上報的列車到發信息。如圖1 所示,列車在始發站A、技術站B、C和終到站D,都會上報列車到發信息。結合列車編組信息,可以得到車輛運行動態信息,包含車號、始發站、當前站、終到站、貨物品類等信息項;匯總某個車輛的到發信息,以車號、起訖點、貨物品類為索引,即可以獲得該車輛的完整運行軌跡。

圖1 運輸信息集成平臺中車輛運行徑路構成示意
假設車流從始發站A 運行到終點站D,可有2條運行徑路:A—B—C—D 和A—B—E—D;利用車流長期歷史數據,對10 000 輛車輛運行徑路進行統計,發現其中80%車輛的走行徑路為A—B—C—D,20%車輛的走行徑路為A—B—E—D;利用車流近短期歷史數據,對100 輛車輛的走行徑路進行統計,發現其中60%車輛走行徑路為A—B—C—D,40%車輛走行徑路為A—B—E—D,可得到如表1 所示的車流徑路選擇偏好參數表。
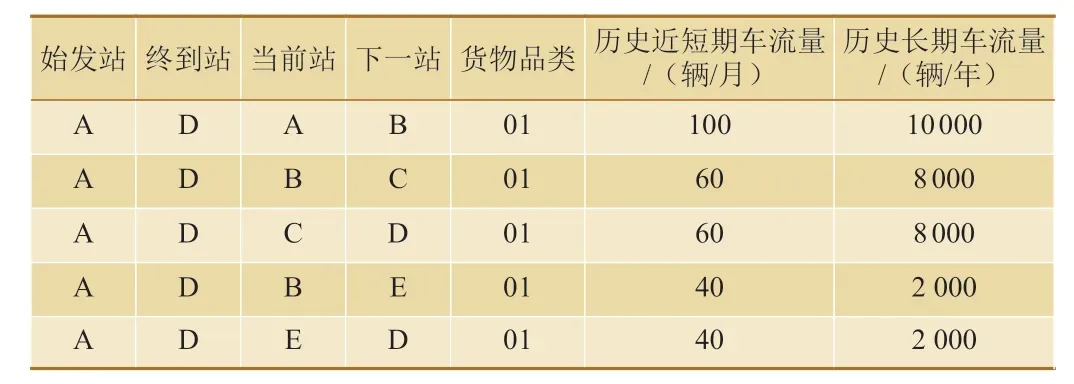
表1 車流徑路選擇偏好參數表
1.3 車流運行徑路動態預測算法
通過實時獲取運輸信息集成平臺提供列車到發報告信息,將其轉換成車輛運行動態信息,結合基于車流歷史數據生成的車流徑路選擇偏好參數表,設計貨運車流運行徑路動態預測方法,具體算法步驟如下:
(1)根據車輛的始發站、當前站、終到站和貨物品類信息,在車流徑路選擇偏好參數表中查找對應的車流徑路記錄;若查找不到對應的車流徑路記錄,則結束查找,使用默認的車流徑路計算方法確定車輛運行徑路;若找到,則轉到步驟(2);
(2)檢查所有查找到的車流徑路記錄中的近短期車流量數據項是否為空;若不為空,選擇近短期偏好概率最大的車流徑路記錄;若為空,則選擇長期偏好概率最大的車流徑路記錄;將所選擇車流徑路記錄中的下一站設置為預測站;
(3)判斷預測站是否為終到站,若是,則結束搜索;否則轉到步驟(4);
(4)將預測站設置為當前站,轉到步驟(1)。
2 車流徑路預測大數據應用環境與數據處理流程
2.1 車流徑路預測大數據應用環境
全路現有貨運車輛80 多萬輛,每日有50 多萬輛貨車的動態信息上報,日均上報數據量約為300 萬條,車輛歷史軌跡數據累計約為20 億條。為便于分析海量的車輛歷史軌跡信息,提高車流徑路預測應用的數據處理性能,搭建車流徑路預測大數據應用環境,其架構如圖2 所示。
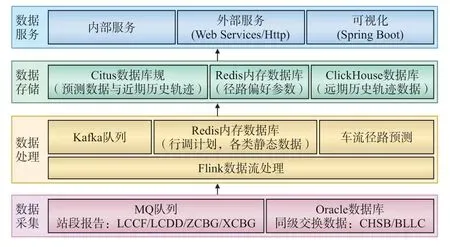
圖2 車流徑路預測大數據應用環境架構示意
數據采集層通過MQ 消息接收與數據庫同步2種方式獲取車輛最新動態信息,解析后寫入Kafka 消息隊列;數據處理層使用Flink 組件調用預測程序,動態預測車流徑路;數據存儲層使用Redis 數據庫存儲車流徑路選擇偏好參數表,Citus 數據庫存儲動態預測的車流徑路與近期車流軌跡歷史數據,Click-House 數據倉庫存儲較長時間之前的海量車流軌跡歷史數據;數據服務層基于WebServices/Http 等協議提供數據查詢和計算服務,使用SpringBoot 微服務架構實現數據可視化展示。
2.2 車流運行徑路預測數據處理流程
車流運行徑路預測的數據處理流程如圖3 所示,其中,黃色部分為車流徑路選擇偏好參數更新流程,其余部分為車流運行徑路動態預測流程。
對車流徑路選擇偏好參數的動態更新,是通過將存儲在運輸信息集成平臺Oracle 數據庫中的車流歷史數據定期同步到分布式實時分析數據庫Citus,再調用車流徑路選擇偏好參數計算程序定期更新該參數表;該參數表保存在內存數據庫集群Redis 中,便于車流運行徑路動態預測程序快速讀取表中的參數。
在車流運行徑路動態預測流程中,從運輸集成平臺的MQ 隊列中實時讀取最新的車流裝、卸和到發信息,轉存到Kafka 消息隊列集群中;使用Flink流式處理技術,解析Kafka 隊列中的最新車流信息,通過Nginx 負載均衡(目的是為了防止并發調用Redis 時造成阻塞),讀取存儲在Redis 中的車流徑路選擇偏好參數表,生成預測的貨車運行徑路;最后,將預測結果存儲到數據倉庫ClickHouse 中,以供應用查詢。
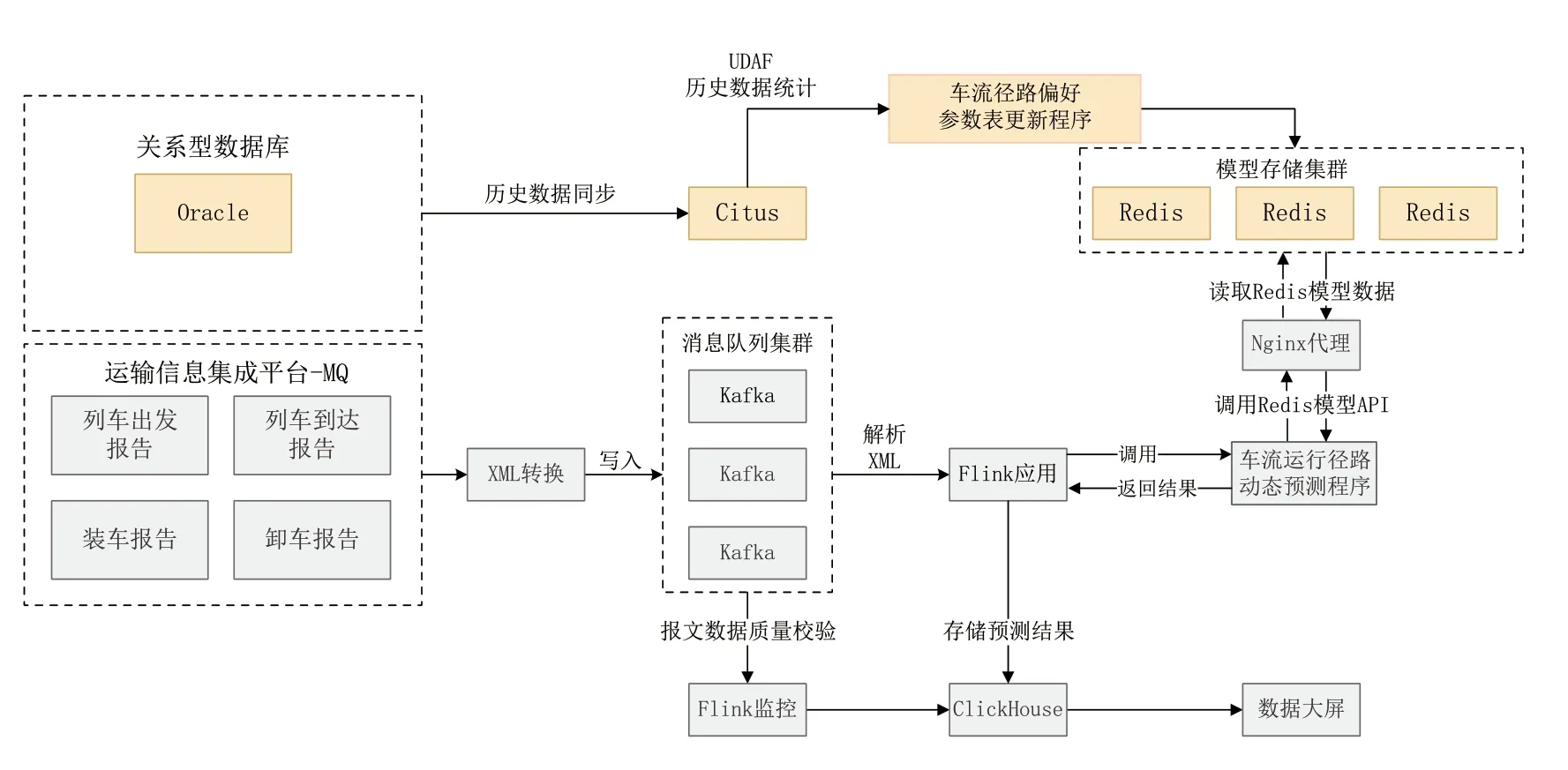
圖3 車流運行徑路預測數據處理流程
2.2.1 車流徑路選擇偏好參數更新流程
(1)車流歷史數據存儲在關系型數據庫Oracle 中,每天定時將前一天的數據同步到分布式實時分析數據庫Citus 中。
(2)利用自定義聚合函數(UDAF,User-Defined Aggregation Funcation),對同步過來的新增歷史數據進行整合處理,包括車流運行徑路合并、到發報告合并等。
(3)運行車流徑路選擇偏好參數計算程序,完成車流徑路選擇偏好參數的更新計算,并用重新計算的參數更新Redis 集群中存儲的車流徑路選擇偏好參數表,更新頻次為每天1 次。
2.2.2 車流運行徑路動態預測算法流程
(1)實時獲取車流動態信息,包括列車出發報告、列車到達報告、裝車報告、卸車報告、車號識別等(通過MQ 以XML 格式接入到車流運行徑路實時預測系統的Kafka 消息隊列中)。
(2)實時計算Flink 程序通過解析Kafka 中的XML 數據獲取獲取車輛的始發站、當前站、終到站和貨物品類等關鍵信息,調用車流運行徑路動態預測程序,具體的算法流程參見圖4,通過Nginx 負載均衡,調用Redis 模型接口,返回貨車運行徑路的預測結果。
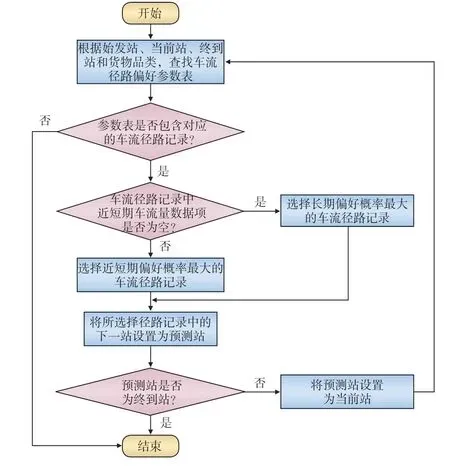
圖4 車流運行徑路動態預測算法流程
(3)將預測結果數據和報文數據質量校驗數據存儲在數據倉庫ClickHouse 中,以服務形式提供數據訪問及數據可視化展示。
3 預測效果評價
該預測方法已在武清數據中心應用,迄今為止車流徑路選擇偏好參數表已累計生成1500 萬條記錄,每日增量約為2 萬條,可以覆蓋全路大多數車流運行徑路。為了評價本文提出鐵路車流運行徑路動態預測方法的效果,定義預測命中率和準確率2 個統計指標。
預測命中是指可根據車輛當前位置準確預測車輛即將到達的下一個車站,命中率H用于衡量單次徑路預測的結果準確性,其計算公式為:

式中,T表示統計時間范圍,Pt表示某預測時段t內完成車輛下一站預測的頻次,Rt表示此預測時段t內準確地完成下一站預測的頻次。
預測準確性是指車輛從始發站到終到站的運行徑路上的所有車站都能被準確地預測,準確率K用于衡量車輛全程徑路預測的準確性,其計算公式為:

式中,T表示統計時間范圍,Dt表示某預測時段t內所有終到車輛的輛數,Ωt表示這些終到車輛中全程運行徑路預測均正確的輛數。
在目前的實際應用中,全路每天大約有16 萬輛車到達終到站,發生約300 萬次車輛運行徑路更新。根據2020 年11 月的數據統計,預測命中率為83%,準確率為72%,基本達到實用水平。
圖5 展示了新豐鎮—城廂某品類車流的長期徑路選擇偏好,可以看出:從新豐鎮出發,車流以92%概率直接運行到安康東;車流在安康東會以59%較大概率一站運行至廣元西。在車流運行過程中,如果系統動態檢測到某車輛運行至達州,那么該車輛的后續運行徑路就會根據預測結果,動態修正為“達州—廣安—內江”方向。
4 結束語
利用運輸信息集成平臺提供的海量車流運行軌跡歷史數據,提出一種簡單易行的鐵路車流運行徑路動態預測方法;通過對長期和近短期車流運行軌跡歷史數據的統計,生成車流徑路選擇偏好參數,可等效反映路網中多種復雜因素對于車流徑路的影響;基于車流徑路選擇偏好參數,結合貨運車輛實時位置跟蹤信息,動態預測貨運車輛運行徑路;搭建大數據應用環境,完成預測程序的開發與部署,采用命中率和準確率2 項指標,對該方法的準確性和實用性進行評價,結果表明:預測結果準確性較高,具有較為滿意的實用價值。
目前,車流徑路選擇偏好參數表可以覆蓋全路92%車流運行徑路,但存在部分徑路找不到終到站或者出現回路,從而導致車流徑路搜索失敗,這類錯誤與運輸信息集成平臺的數據質量有關。后續需要進一步研究如何對參數表數據進行修正,如將終到站數據缺失的記錄用臨近站近似替換填充,對出現回路的徑路進行甄別并剔除折返通路,提高車流徑路選擇偏好參數表的覆蓋范圍和準確性,進而提高車流運行徑路動態預測的準確性和效率。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
