基于2T1MTJ單元的MRAM存算處理架構設計*
2021-05-08 06:10:08吳彩霞鄭志強唐慧琴王少昊
通信技術 2021年4期
吳彩霞,鄭志強,唐慧琴,胡 煒,王少昊
(福州大學晉江微電子研究院,福建 晉江 362200)
0 引言
當前主流的馮?諾依曼處理架構依賴總線進行處理器和存儲器之間的通信,難以應對新出現的數據密集型應用,面臨“內存墻”性能瓶頸[1]。近數據計算(Near Data Computing,NDC)和存算一體(Processing in-memory,PIM)的處理[2]改進了計算架構,可顯著提升處理器和存儲器之間的數據吞吐效率,在人工智能、圖像處理、物聯網計算等領域已顯現出良好的應用前景,有望解決上述“內存墻”問題[3]。近年來出現的非易失性存儲器(Non-Volatile Memory,NVM)具有斷電保存、高算力、低功耗、低成本等優勢,較以靜態隨機存儲器(Static Random Access Memory,SRAM)、動態隨機存儲器(Dynamic Random Access Memory,DRAM)為代表的傳統易失性存儲器更適用于PIM方案[4]。
新型NVM主要包括電阻性隨機存儲器(Resistive Random Access Memory,RRAM)、相變存儲器(Phase Change Memory,PCM)、磁性隨機存儲器(Magnetic Random Access Memory,MRAM)等,其中,MRAM具有體積小、功耗低、訪問速度快、近無限次讀/寫操作和抗輻射能力強等優點,具有廣闊的產業化前景[1]。基于MRAM的通用型PIM架構可在執行位邏輯運算的同時兼顧常規存儲功能。
與/或位邏輯運算操作是上述基于MRAM的通用型PIM架構的核心功能,根據其執行位置是否位于存儲陣列將PIM架構分為全后置式和部分前置式兩類,按照兩種運算的執行順序不同亦可區分為并行與串行兩類計算模式。在與/或運算的基礎上可進一步實現其他布爾邏輯運算和一位全加器功能。其運算方式取決于PIM架構所選用的存儲單元結構,常見的有1T1MTJ、2T2MTJ和2T1MTJ等[1,4-6]。1T1MTJ方案需要較大的存取晶體管尺寸保證寫可靠性,導致在對MTJ器件進行讀操作時存在較大的讀電流干擾。2T2MTJ[6]方案采用互補位單元結構,可提升位邏輯運算操作的正確率,但顯著增加了陣列面積與寫操作難度[6]。此外,2T1MT[4]方案雖提出采用2T1MTJ單元結構重構實現多位的加法計算[4],但該方案中的外圍控制電路設計較為復雜,且進行邏輯計算需要電壓脈沖,增加了設計難度。
本文基于2T1MTJ單元結構,提出一種通用型PIM宏架構。在不顯著增加存儲陣列面積的同時,可通過配置實現常規MRAM存儲、并行PIM與串行PIM工作。該PIM方案除了采用2T1MTJ單元結構將與/或位運算控制前置于存儲陣列,結合讀取電路后端還可實現邏輯非(NOT)、與(AND)、與非(NAND)、或(OR)、或非(NOR)、異或(XOR)、一位全加器(ADD)和移位/循環(SHIFT/ROTATE)操作,并且對提出的PIM宏架構設計進行了存算功能驗證與性能分析。
1 基于2T1MTJ的PIM架構設計
1.1 2T1MTJ 存儲陣列
自旋轉移磁矩MRAM(Spin Transfer Torque MRAM,STT-MRAM)的數據存儲功能是通過其存儲單元中的磁隧道結(Magnetic Tunnel Junctions,MTJ)器件實現的。MTJ器件是由釘扎層、隧道勢壘層和自由層組成的雙端器件,如圖1(a)所示。當自由層的磁矩方向與釘扎層一致時,MTJ器件呈現低阻態(平行態)RP,常將其定義為二進制符號“0”;當自由層的磁矩方向與釘扎層相反時,MTJ器件轉變為高阻態(反平行態)RAP,可定義為符號“1”。高低阻態之間的隧道磁阻比(Tunnel Magnetoresistnce Ratio,TMR)定義為TMR=(RAP-RP)/RP,根據材料和溫度的不同,TMR的范圍在10%與400%之間不等[1]。過低的TMR將導致讀取或位邏輯運算的錯誤率上升。
STT-MRAM中典型的存儲單元結構為1T1MTJ結構,即由一個MTJ器件和一個選擇晶體管組成。可通過驅動電路控制位線(Bit Line,BL)、字線(Word Line,WL)和源極線(Source Line,SL)的電壓實現對單元中MTJ器件寫入和讀取操作。在把二進制數據寫入MTJ存儲單元時,只需改變流經MTJ器件的電流方向即可更改其自由層的磁矩方向,實現對磁阻態的控制,具體電流方向如圖1(b)所示。
本文提出的通用型PIM宏架構由2T1MTJ存儲陣列、陣列控制電路和邏輯運算電路三部分構成,如圖1(c)所示。在2T1MTJ存儲陣列中,每個存儲單元由兩個控制晶體管和一個MTJ器件構成,其中控制晶體管分別由兩行字線(WL與CWL)控制實現部分前置式與、或位邏輯運算。單元的MTJ一端連接一列BL,另一端則由每兩個臨近2T1MTJ單元共用一列SL。
1.2 陣列控制電路
本文提出的PIM架構中,位邏輯運算與常規MRAM功能擁有相同陣列控制電路,主要包括行譯碼器、列譯碼器、字線驅動電路和讀寫驅動電路。其中行解碼器、列解碼器以及字線驅動電路用于地址總線的控制,陣列電路外圍還添加了邏輯電路和控制電路模塊輔助實現位邏輯運算功能。控制電路負責實現PIM架構的模式控制,邏輯電路模塊實現在PIM模式下的位邏輯運算、一位全加器和移位/循環功能。
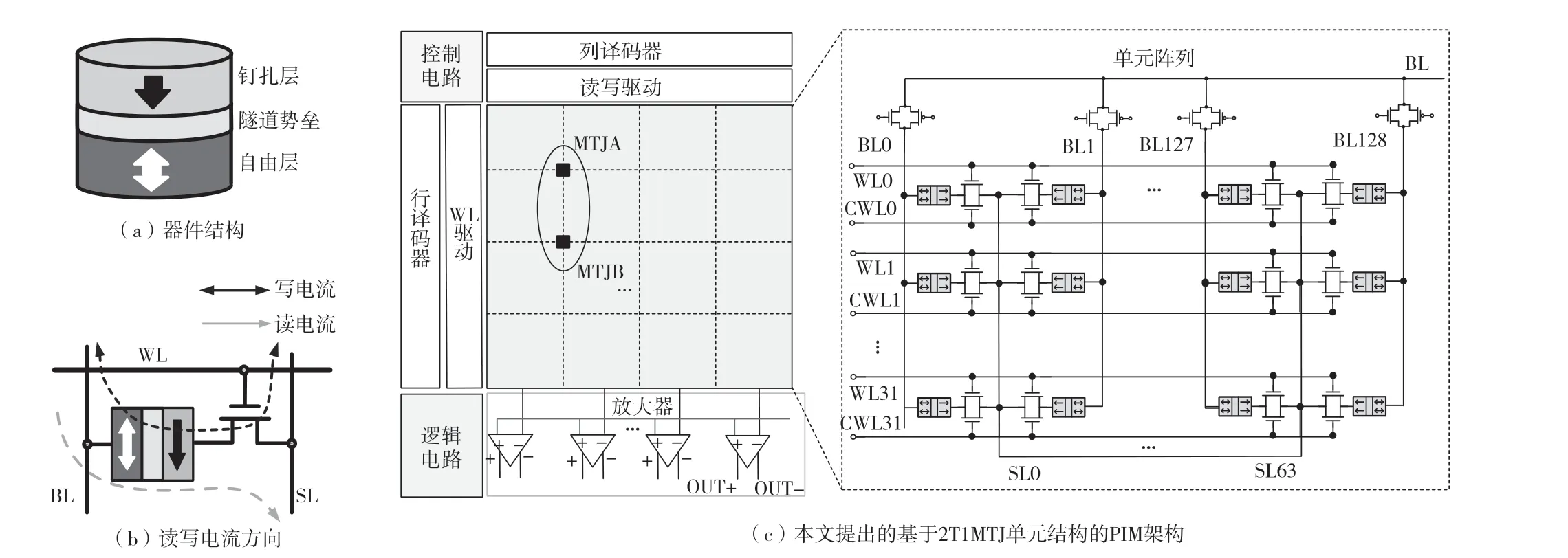
圖1 MTJ特性
控制電路的系統結構框架如圖2所示。電路根據輸入操作數(命令和地址信號)輸出相應的控制信號,主要分為3個子模塊:mram_ctrl、mram_work和mram_pim。mram_ctrl模塊負責完成系統的上電穩定、初始化配置、命令解析以及指令狀態控制;mram_work模塊根據相應的工作模式控制地址信號;mram_pim模塊根據具體的工作狀態控制預充電電流型靈敏放大器(Pre-charge Current Sensing Amplifier,PCSA)、讀寫驅動電路以及邏輯電路。
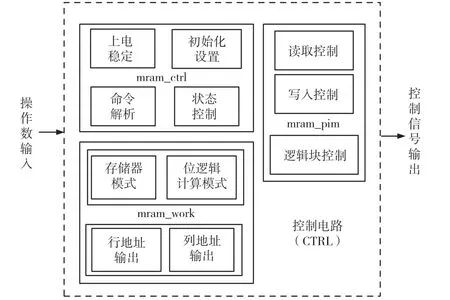
圖2 MRAM的控制電路架構
1.3 常規存儲模式
基于2T1MTJ單元的PIM宏架構可在常規存儲和串行PIM、并行PIM模式下工作。相應地,需要在架構的每個子陣列中均分別配置獨立的讀取參考單元和獨立的邏輯運算參考單元。
在常規存儲模式下,對2T1MTJ存儲單元的讀寫操作均為單值操作。在執行寫操作時,需要同時選通WL和CWL,保證為MTJ器件提供足夠的寫入電流,讀寫驅動電路則負責控制寫入電流的方向,實現邏輯寫“1”和“0”的功能。在執行讀取操作時,只需選通WL打開單個存取晶體管以實現低讀取電流。在讀取電路部分,SA將從BL輸入的讀電流和從讀取參考流入的參考電流進行比較,在輸出端OUT-(或OUT+)輸出高(或低)電平,如圖1(c)所示。自此完成了常規存儲模式下邏輯“1”或邏輯“0”的讀取操作。
1.4 PIM模式下的布爾運算和全加器設計
PIM模式寫操作與常規存儲模式下完全相同。本文提出的PIM宏架構能夠對存儲陣列中同一列的兩個操作數[(如圖1(c)中的MTJA和MTJB)]實現位布爾邏輯運算和一位全加器計算,如表1所示(省略了NOR、NAND和XNOR運算),其中設定進位輸入CIN=1。邏輯運算電路可分3個模塊實現上述功能:讀取電路模塊、組合邏輯模塊和全加器邏輯模塊。
讀取電路模塊可實現NOT、OR/NOR和AND/NAND的功能。除NOT運算結果直接在讀取操作時SA的OUT+端口得出外(OUT-為讀出的MTJ數據)。提出的PIM架構將OR/AND位運算操作前置于2T1MTJ存儲陣列中,具體配置方式為:同時打開同一列BL中的MTJA和MTJB單元,流經兩個單元的總電流Ib1將沿著BL流入SA的一端。此時需調用相應的邏輯運算參考單元,SA會將Ib1與從邏輯運算參考單元流入的電流Iref進行比較,進而得出位邏輯運算結果。按執行OR/AND位邏輯運算的執行順序不同,這里將讀取電路分為并行PIM和串行PIM兩種計算模式,如圖3(a)、圖3(b)所示。布爾邏輯運算與全加器功能真值表,如表1所示。

表1 布爾邏輯運算與全加器功能真值表
(1)并行PIM采用全后置模式,讀取電路需并行配置一對SA用于分別執行OR和AND位邏輯運算,如圖3(a)所示。相應地,需要為該SA配置一對邏輯運算參考單元,分別提供不同的參考電流(Iref1和Iref2)。值得注意的是,由于Ib1需要同時輸入一對SA來實現并行運算,因此需要加入電流鏡以提升電路穩定性。
(2)串行PIM模式下,OR/AND位邏輯運算可部分前置于存儲陣列中,即先同時選通MTJA和MTJB單元的WL和CWL實現AND運算,再單獨選通WL實現OR運算。如圖3(b)所示,讀取電路先將AND結果通過鎖存器保存,再連同在第二次計算中得到的NOR結果一起輸入下一級模塊。因此,串行PIM模式下讀取電路僅需配置一個SA和一個固定的邏輯運算參考單元,SA和參考單元數量較并行PIM方案減半。
組合邏輯模塊可由NOR和AND的運算結果得到XOR與XNOR的位邏輯運算結果。
全加器邏輯模塊可以實現一位全加器的計算功能,即輸入XOR、AND和CIN,得到A、B相加的和(SUM)與進位輸出(COUT)。
1.5 移位/循環功能
本文以32×128存儲陣列對PIM架構進行性能評估,該陣列被劃分為8個32×16大小的子陣列。子陣列共享地址總線,即一個地址同時選中8個子列陣中對應的單元,因此使用5~32的行譯碼器和4~16的列譯碼器。并且每個子陣列均擁有獨立的SA、參考單元和讀寫驅動電路,因此上述32×128陣列除可以實現對8位數據的并行讀寫操作與邏輯運算,還可以在SA輸出端實現對該組8位數據的SHIFT和ROTATE操作。如圖4(a)所示,主要考慮向右的操作,Di(i=0,…,7)為數據輸入,Qi為相應輸出,由Si控制實現移位/循環i+1位的操作,Ei控制實現SHIFT和ROTATE兩種邏輯操作。圖4(b)顯示了這兩種邏輯功能的具體操作,在向右移位時最高位補“0”。
2 功能實現
本文結合中芯國際55 nm工藝、數字標準工藝庫與p-MTJ緊湊模型[7]對上述模擬和數字設計進行了混合仿真,并通過對硬件描述語言代碼的綜合分析評估了提出的PIM宏架構系統性能。本文采用的p-MTJ緊湊模型默認設置溫度T=300 K,TMR=150%。綜合考慮p-MTJ模型和PCSA的充放電特性[8],再將邏輯控制電路時鐘頻率設定在100 MHz,通過設置可令提出的PIM宏架構在接到操作命令后的3個時鐘周期內正確實施寫操作、常規讀取、AND/OR位邏輯運算功能。
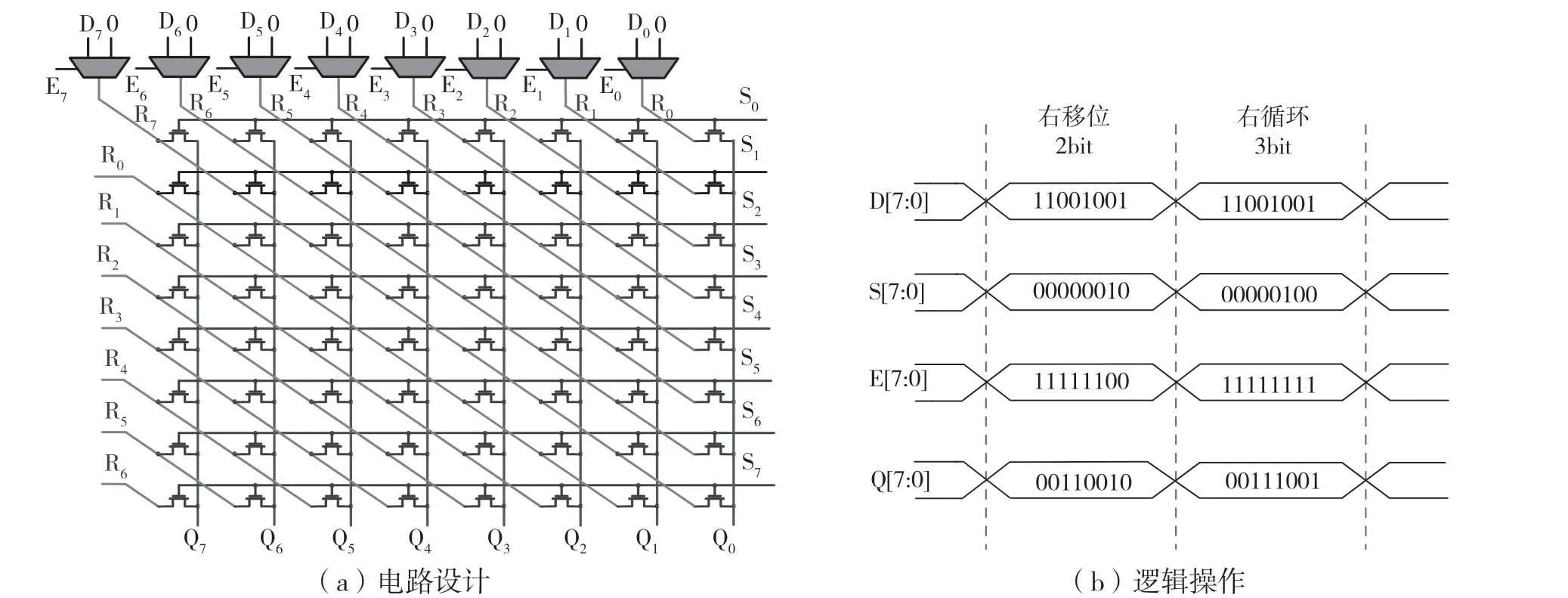
圖4 右移位/循環操作
2.1 常規存儲功能
工作在常規存儲模式下,2T1MTJ PIM架構讀寫操作的仿真結果如圖5(a)所示。當放大器使能信號SA_EN為高電平時,存儲器執行讀取操作,其中SA的預充電動作在讀時間的第一個時鐘周期內完成。在第1次進行讀操作時,假定對象2T1MTJ單元中的MTJ器件為高阻態(對應二進制符號SMTJ=1),則OUT-輸出端VOUT_為高電平。當寫入使能信號WR_ENB為低電平時,存儲器可執行寫入操作。由于指令為寫入“0”,電路對2T1MTJ單元施加反向電流,令MTJ器件成功轉變為低阻態(SMTJ=0)即完成寫“0”操作。隨后,再對該2T1MTJ單元執行一次讀操作,得到輸出VOUT_為低電平。最后,對該2T1MTJ單元執行一次寫“1”操作和一次讀取操作。由圖可知,在100 MHz系統的時鐘頻率下,本設計可在接到操作命令后的3個周期內完成上述常規存儲模式的讀寫功能。
2.2 位邏輯運算功能和全加器運算
位邏輯計算是執行同一列BL中任意兩個操作數(二進制符號記為SA和SB)之間按位邏輯計算。圖5(b)展示了串行PIM方案對不同的輸入操作數執行OR、AND和ADD運算的仿真結果。用于驗證的輸入操作數按輸入順序依次為(SA=1,SB=1),(SA=1,SB=0)和(SA=0,SB=0)。以輸入操作數(SA=1,SB=1)為例,在執行位OR運算時,輸出VOR/AND為高電平,在執行位AND運算時,輸出VOR/AND也為高電平。隨后,讀取電路模塊將OR和AND運算結果輸出至組合邏輯模塊得到XOR運算輸出VXOR為低電平。最后,當ADD計算設置進位輸入為高電平(CIN=1)時,在全加器邏輯模塊SUM的輸出VSUM和VOUT輸出VC均為高電平。上述結果表明,在100 MHz時鐘頻率下,本設計可在接到操作命令后的3個周期內完成對兩個輸入操作數的OR、AND位邏輯運算,串行方案在第二次計算時完成一位全加器運算。
3 結果分析與比較
表2比較了基于1T1MTJ[1,5]、2T2MTJ[6]單元和本文提出的基于2T1MTJ單元的PIM架構。
上述PIM架構方案的陣列版圖面積主要由MTJ器件所需寫操作電流決定。假設存儲陣列中的MTJ器件完全相同,考慮到寫電流的要求,2T2MTJ方案和1T1MTJ方案中的單元存取晶體管尺寸應相當。因此2T2MTJ單元面積應為1T1MTJ單元的2倍。2T1MTJ方案在執行寫操作時同時開啟兩個存取晶體管,因此可認為雙管尺寸與兩指結構1T1MTJ單管尺寸相當。
本文仿真比較了基于上述三種單元的PIM架構的寫性能。由于2T2MTJ方案在寫入時需要操作兩個MTJ,因此在相同的寫入電壓和寫入時間下存儲單元內的寫能耗是1T1MTJ和2T1MTJ方案的兩倍,且寫入正確率最低。此外,由于2T1MTJ方案拆分存取管減小了寄生電阻電容,提高了響應速度和電流,因此寫入正確率略高于版圖面積相同的1T1MTJ方案。
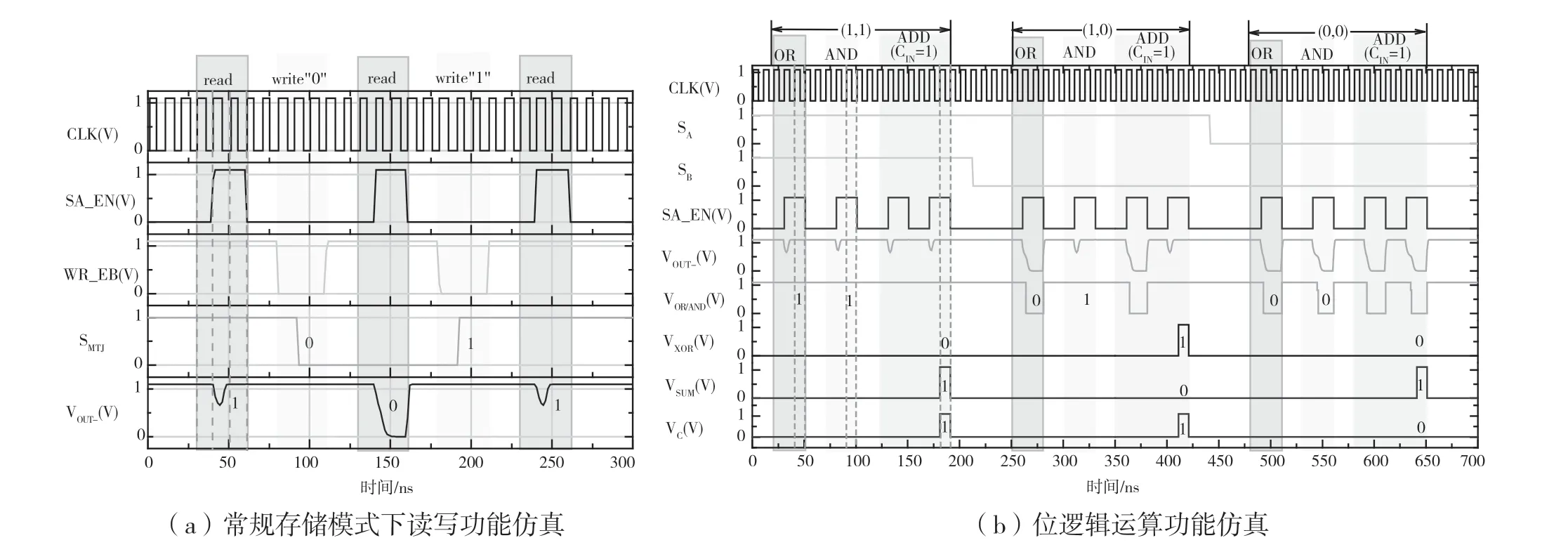
圖5 功能實現

表2 基于1T1MTJ、2T2MTJ和2T1MTJ單元的PIM架構比較
讀取操作時,在1T1MTJ方案和2T1MTJ方案的電路結構中,SA需配置參考單元(等效電阻Req)對經BL流入的讀電流進行讀取或位邏輯運算。采用互補結構的2T2MTJ方案在讀取時無須配置參考單元,但需要根據互補的兩組單元進行讀取。因此,在常規存儲讀操作過程中,1T1MTJ和2T1MTJ方案在實際讀操作中開啟晶體管和讀取MTJ的數量與2T2MTJ方案相當。相較而言,2T1MTJ方案僅需開啟單管且單管面積為1T1MTJ方案單管面積的一半,因此可有效減小讀電流干擾及避免誤寫操作。
在串行位邏輯運算模式下,3種結構除需要操作擬讀取的存儲單元外,1T1MTJ和2T1MTJ方案還需操作運算參考單元,2T2MTJ方案還需操作存儲陣列中的邏輯控制位。因此,1T1MTJ所需開啟晶體管和讀取MTJ的數量均為2T2MTJ方案的一半。2T1MTJ方案由于采用部分前置AND/OR運算模式,晶體管和讀取MTJ的數量介于1T1MTJ和2T2MTJ方案之間。在并行位邏輯運算模式下,2T1MTJ方案的工作模式與1T1MTJ方案相同且具有與常規存儲模式相同的陣列讀寫優勢。由于2T2MTJ無法實現并行計算,因此本文不在表2中做對比。
4 結論
本文提出了一種基于新型2T1MTJ存儲單元結構的通用型PIM宏架構,可在常規存儲模式、并行PIM模式與串行PIM模式下工作,在PIM模式下可實現布爾邏輯運算、全加器、移位/循環操作等功能,有助于解決“內存墻”問題,實現存內計算在人工智能和邊緣計算等領域的應用。數模混合仿真結果表明,該方案在100 MHz時鐘頻率下執行一組位寫入操作或者與/或位邏輯計算操作的時間均為3個周期。較基于1T1MTJ單元的PIM方案而言,該架構不僅不增加陣列面積,還可顯著提升寫操作可靠性和位邏輯運算正確率。此外,該架構的寫入功耗、寫入正確率和版圖面積均優于基于2T2MTJ單元的PIM方案,是實現基于MRAM的高密度、低功耗、高可靠性的PIM方案的可行技術路線。
