基于高光譜成像技術的大米溯源研究
2021-05-07 09:55:04羅浩東劉翠玲孫曉榮吳靜珠
中國釀造 2021年4期
關鍵詞:模型
羅浩東,劉翠玲*,孫曉榮,吳靜珠
(北京工商大學 人工智能學院 食品安全大數據技術北京市重點實驗室,北京 100048)
中國是世界大米生產和消費的大國之一,大米是中國主要的糧食產物之一。中國大米產地繁多,不同產地的大米口感、營養價值及品質均具有明顯差異[1-2]。隨著人們生活水平的不斷提高,人們對大米的產地以及品質越來越重視。由于大米因外觀及品質方面難以用肉眼檢測,一些不法商販將劣質大米混入其中,以次充好,牟取暴利,使得大米摻假問題日益嚴重[3]。傳統的檢測方法(如感官識別、近紅外光譜等)均有一定劣勢和不足。如感官識別受到主觀因素影響,檢測結果的準確性和穩定性并不高。近紅外光譜法需要對大米進行研磨粉碎[4-5],使得進行檢測的大米樣本不能進行后續的使用[6]。
高光譜成像技術結合了近紅外光譜和數字成像技術,具有高速、無損、精度高的特點,使樣本避免被破壞,被廣泛應用于食品檢測領域[7-9]。PEREZ-RODRIGUEZ M等[10]利用基于支持向量機(support vector machine,SVM)的預測模型,建立了一種簡單、快速、高效的火花放電激光誘導擊穿光譜方法。對四個水稻品種(古里、IRGA424、普伊特和塔伊姆)的72個樣品進行分析,得到了按植物品種鑒別水稻樣品的最佳模型。該模型在試驗樣本中的正確預測率達到了96.4%。JI M等[11]基于高光譜成像技術建立的最小二乘支持向量機模型對豬肉中的不飽和脂肪酸包括單不飽和脂肪酸和多不飽和脂肪酸進行了檢測,并繪制了單不飽和脂肪酸和多不飽和脂肪酸含量的彩色圖,取得了良好的實驗結果。吳寶婷等[12]利用高光譜技術對靈武棗發酵過程中pH值和總酸含量進行了定量分析,結合競爭性自適應加權算法(competitive adaptive reweighting sampling,CARS)和遺傳算法(genetic algorithm,GA)進行特征波段的篩選,進而建立偏最小二乘定量分析模型。結果表明,高光譜技術可以對靈武棗發酵過程中pH值和總酸含量進行定量預測。可見,高光譜成像技術已經廣泛應用于食品檢測的各個領域,而大米產地溯源領域的報道并不是很多。
王璐[13]采用隨機方法對大米樣品進行訓練集和測試集的劃分,根據訓練集中樣本大米的平均光譜建立了最小二乘支持向量機(least squares support veotor maohine,LS-SVM)分類模型。選取正交信號校正法(orthogonal signal correction,OSC)作為光譜預處理方法,并利用連續投影算法(successive projections algorithm,SPA)提取特征波段建立大米產地分類模型,分類結果為95.36%。王靖會等[14]采集了吉林省梅河口市水稻主產區及松原、大安、輝南等其他水稻產區共990個大米樣本的高光譜圖像作為研究對象,利用多元散射校正(multiple scattering correction,MSC)處理方法對光譜進行了預處理。采用了多層感知機(multilayer perceptron,MLP)、極限學習機(extreme learning ma chine,ELM)與在線序列極限學習機(online sequence extreme learning machine,OS-ELM)算法,分別基于全波段高光譜數據建立產地溯源模型。實驗結果表明,OS-ELM模型分類效果最好,可以準確的進行大米產地的溯源。市場上大米產地來源極多,造成東北大米摻假問題嚴重。東北大米來源于多個產地,品種不一,不同產地的東北大米也存在著形態、成分組成等差異。再加上高光譜數據信息量豐富,但一些相關性不強的光譜信息會影響預測模型的準確性,容易造成信息冗余,這就為應用高光譜技術建立大米產地溯源造成了干擾和困難[15-16]。
本研分以大米產地的溯源為出發點,使用高光譜成像技術,以來源于5種東北和5種非東北的大米作為樣本集,對大米的產地進行溯源研究。通過主成分分析法(principal component analysis,PCA)進行主成分提取,實現高光譜數據降維,避免信息冗余[17-18]。采用SVM建立大米產地溯源模型,旨在對市場中流通的大米產地進行快速、準確的判別。
1 材料與方法
1.1 材料與試劑
黑龍江長粒香、吉林稻花香、圓粒香以及遼寧小町米(2種):北京古船米業有限公司;江蘇長粒香、小町米、河北小町米、安徽小町米以及浙江圓粒香:浙江農業科學院。
1.2 儀器與設備
SISUCHEMA-SWIR高光譜成像系統:芬蘭SPECIM公司。
1.3 方法
1.3.1 大米高光譜技術路線及操作要點
預熱→調距→調參→掃描
預熱:開啟高光譜成像系統預熱30 min以上。
調距:調整載物臺的距離,確保激光可以穿過大米樣品。調整鏡頭與大米樣品的距離,確保所有大米樣品進入高光譜成像系統掃描范圍。
調參:經過調整參數,確保大米樣品像素最清晰。將采集過程中的曝光時間設為3.8 μs,幀率為50 Hz。
將100顆同一產地的大米樣本放于板上以便高光譜儀器進行掃描。
1.3.2 感興趣區域的提取
感興趣區域提取就是將大米樣本的高光譜圖像中的目標區域進行提取,因每個像素點的光譜信息不同,目標區域的大小、位置都會對實驗數據造成影響。使用ENVI4.8按照大米樣本的輪廓,手動提取感興趣區域,并將感興趣區域內所有像素點的平均光譜作為大米樣本的光譜信息,最后得到10種大米的高光譜數據。
1.3.3 大米檢測圖像的校正
由于高光譜采集樣本數據時光源強度不均勻以及攝像頭中暗電流存在,會對圖像采集產生較大的噪聲,導致光譜信息不準確[19]。為了對圖像進行修正,消除噪聲的影響,必須對原始的高光譜采集數據進行黑白板校正[20]。高光譜圖像的黑白板校正利用(1-1)在ENVI4.8中處理完成。

式中:Rc為相對反射率圖像;R0為原始反射率圖像;RW為白色參考圖像;RB為黑色參考圖像。
一是“好教育進行時”促進了各區、各校對好教育的思考,各區、各校、個人都對好教育有自己的理解和追求,對好學校、好校長、好教師、好學生也有了更新、更深的思考,這種教育觀、學校觀、教師觀、學生觀、質量觀的更新,對教育的改革創新意義重大。
1.3.4 數據集劃分
在Matlbe2016環境下進行樣本集的劃分,采用X-Y距離樣本集算法,將大米樣本分為測試集和訓練集,測試集和訓練集比例為4∶1,其中800個大米作為測試集,剩下的200個大米作為訓練集。
2 結果與分析
2.1 主成分分析法和變量相關性分析
計算變量間相關性,畫出各波段對應的相關系數曲線圖,結果如圖1所示。由圖1可知,波段之間的吸光度值基本在0.8以上,對全波段進行主成分降維。
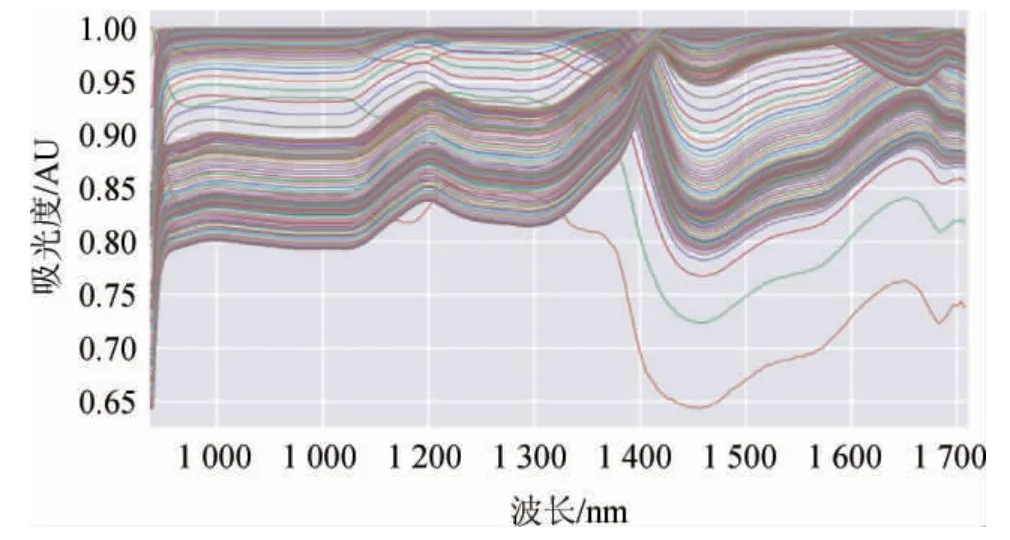
圖1 相關系數曲線圖Fig.1 Curve graph of correlation coefficient
2.2 全波段主成分分析
PCA是一種非監督模式識別算法,可以降低高光譜數據的維數,提高模型工作效率,同時增強大米相關信息并降低干擾信號。全波段成分的方差貢獻率如表1所示。由表1可知,當4個主成分時,主成分累計方差貢獻率達到99.9%,因此選取第4 個主成分作為特征。

表1 主成分分析貢獻率統計結果Table 1 Statistics results of contribution rate of principal component analysis
2.3 預測模型的建立與結果
SVM是一種以結構風險最小化的學習型算法。其優勢是實現數據的降維,克服了傳統機器學習的維數災難問題[21]。在小樣本數據集中的分類具有顯著優勢。SVM的中心思想是構造支持向量機Xi和輸入層Xn之間的內積核。K(X,Xn)為核函數,能產生重要作用的是懲罰參數c。
本次建模使用了線性函數(linear)和高斯函數(radial),核函數是線性函數時,當C=0.011時,準確率為78%。核函數是高斯函數(radial)時,準確率最大值為57%,比線性函數小,因此選擇線性函數最優參數進行建模。
在R-4.0.2上進行實驗建模分析。將來自東北大米的黑龍江長粒香、吉林稻花香、圓粒香以及遼寧小町米歸為一類(ALL)。非東北大米有:江蘇長粒香(SU01)、江蘇小町米(FX17APC)、河北小町米(HBTS)、安徽小町米(HUI)以及浙江圓粒香(ZJ01)。訓練集實驗結果如表2所示。由表2可知,使用訓練集中的800個大米樣品高光譜數據進行模型的建立,除江蘇長粒香外,其他種類大米的訓練集預測準確率達到了98%以上。
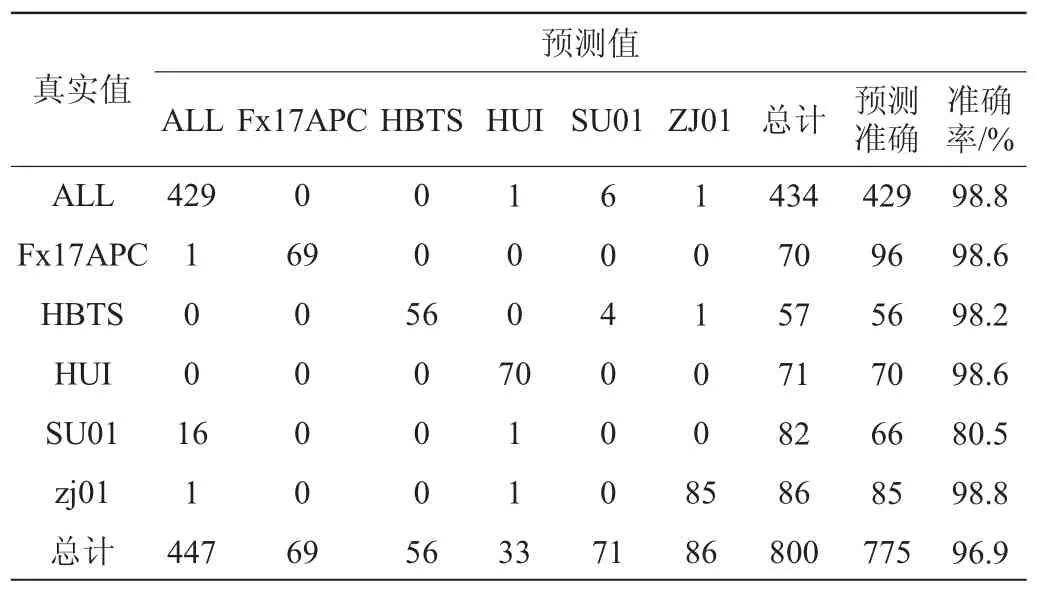
表2 大米產地溯源訓練集結果Table 2 Result of the training set of rice origin traceability
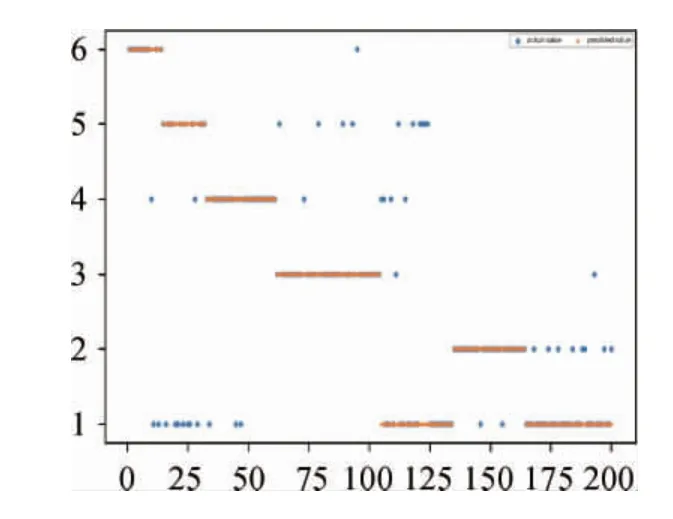
圖2 測試集的結果Fig.2 Result of test set

表3 大米產地溯源測試結果Table 3 Result of rice origin traceability test
由表3可知,江蘇小町米(FX17APC)的判斷準確率最高,達到了93.3%。河北小町米(HBTS)、安徽小町米(HUI)以及浙江圓粒香(ZJ01)判斷準確率在80%左右,而江蘇長粒香(SU01)的預測準確率偏低,江蘇長粒香的高光譜信息和東北地區大米樣品高光譜信息較為接近,使得模型預測結果產生偏差。整體大米溯源預測模型準確率為79%,結果表明高光譜成像技術可以用于大米產地的溯源。
3 結論
采用主成分分析法前幾個主成分就已經包含了樣品大部分信息,因此比較前幾個主成分的貢獻率,其中第4主成分累計方差貢獻率為99.9%,故采用第4主成分建立大米產地溯源模型。
SVM的中心思想是構造支持向量機內積核。能夠對核函數產生重要作用的是懲罰參數c。c表示的是對誤差的寬容度,c值越高,說明對誤差容忍度越小,過高容易出現過擬合現象。c值過低,容易出現欠擬合的情況。因此c值過大過小都會影響最終模型預測結果。當采用線性函數時,c=0.011時,準確率為78%時,最終模型預測結果較好。
采用主成分分析法(PCA)對高光譜數據的主成分進行了提取,并結合支持向量機(SVM)建立了大米產地溯源預測模型。以提取的第4主成分建立的模型質量有所優化。不僅降低了建模的復雜程度,解決了光譜信息冗余問題,并且提高了模型預測效率,預測準確性以及穩定性。通過預測結果可以發現,高光譜信息較為相近的大米溯源會有一定誤差,有待進一步數據處理進行大米產地溯源判斷。實驗結果表明,高光譜成像技術可以實現對大米產地溯源的快速、準確預測,在大米產地溯源具有廣闊的應用前景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
