基于多階段向量量化算法的研究
2021-05-04 11:07:18劉丹青李明勇
智能計(jì)算機(jī)與應(yīng)用 2021年11期
關(guān)鍵詞:方法
劉丹青,李明勇
(1東華大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,上海 201620;2上海市計(jì)算機(jī)軟件評(píng)測(cè)重點(diǎn)實(shí)驗(yàn)室,上海 200235)
0 引 言
隨著互聯(lián)網(wǎng)的快速發(fā)展,計(jì)算機(jī)技術(shù)已滲入到社會(huì)的各種行業(yè)。因此,高維的文本、圖片、視頻等多媒體數(shù)據(jù)呈現(xiàn)爆炸式的增長(zhǎng)趨勢(shì)[1]。傳統(tǒng)的暴力搜索方法是通過(guò)遍歷所有的數(shù)據(jù)點(diǎn)進(jìn)行查詢,隨著數(shù)據(jù)集的增大,這種暴力搜索方法需要巨大的存儲(chǔ)空間,并且每次檢索的時(shí)間很長(zhǎng)。因此,該方法只適用于小規(guī)模的數(shù)據(jù)集。針對(duì)大規(guī)模高維數(shù)據(jù)集的查詢問(wèn)題,研究者們提出了近似最近鄰搜索方法,在可接受一定精度損失的情況下,查詢到盡可能精確的結(jié)果。其中,基于向量量化的近似最近鄰搜索方法是比較有效和受關(guān)注較多的方法之一。該方法可以有效地降低空間存儲(chǔ),提高檢索速度。
向量量化[2]的基本思想是,僅用數(shù)據(jù)集特征向量空間中的一個(gè)有限子集,表示該數(shù)據(jù)集特征向量空間中所有數(shù)據(jù)集特征向量,因而大大減少了數(shù)據(jù)的內(nèi)存存儲(chǔ)。常用的向量量化方法有樹(shù)搜索向量量化方法、乘積量化方法[3]和多階段向量量化方法[4-5]等。本文著重研究多階段向量量化方法,并對(duì)基于多階段向量量化的近似最近鄰搜索方法提出改進(jìn)。在訓(xùn)練碼本過(guò)程中,通過(guò)優(yōu)化初始聚類中心,減小重構(gòu)向量的均方誤差,改善碼本質(zhì)量,進(jìn)一步減小向量的量化誤差,以此提高實(shí)驗(yàn)召回率。
1 相關(guān)工作
1.1 最近鄰搜索
最近鄰搜索在計(jì)算機(jī)視覺(jué)、多媒體搜索、機(jī)器學(xué)習(xí)等領(lǐng)域里應(yīng)用非常廣泛。最近鄰檢索就是給定數(shù)據(jù)集和目標(biāo)數(shù)據(jù),根據(jù)數(shù)據(jù)的相似程度,從數(shù)據(jù)庫(kù)中查找與目標(biāo)數(shù)據(jù)最接近的數(shù)據(jù)。一般情況下,可認(rèn)為在空間中,兩個(gè)數(shù)據(jù)點(diǎn)的距離越小,其之間的相似性越高。
假設(shè),給定一個(gè)查詢向量q,最近鄰搜索的目的,是在一個(gè)向量集合X={x1,x2,…,xn}里,找到與查詢向量q距離最近的目標(biāo)向量x*:
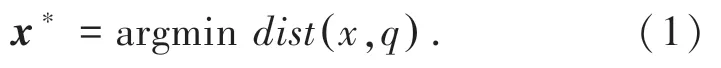
其中,d i st(x,q)是目標(biāo)向量和查詢向量之間的距離。通常使用歐氏距離(Euclidean distance)定義兩向量之間的距離,即兩個(gè)數(shù)據(jù)點(diǎn)在空間里的直線距離。在D維空間中,兩個(gè)數(shù)據(jù)點(diǎn)(A1,A2,…,AD)和(B1,B2,…,BD)之間的歐式距離可以表示為:
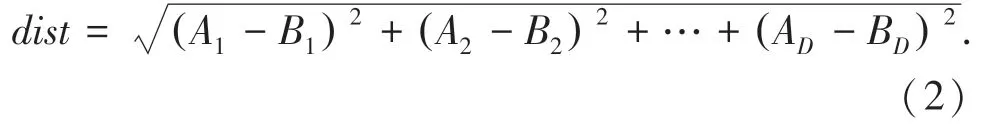
1.2 近似最近鄰搜索
面對(duì)數(shù)據(jù)庫(kù)中巨大的高維數(shù)據(jù),當(dāng)前基于最近鄰搜索的檢索方法不能得到理想的檢索結(jié)果和可接受的檢索時(shí)間。因此,為了較好的均衡準(zhǔn)確性和資源,人們開(kāi)始關(guān)注近似最近鄰檢索方法ANN(Approximate Nearest Neighbor)[1]。
近似最近鄰搜索是給定一個(gè)查詢向量,為了用盡可能低的空間存儲(chǔ)成本,查找數(shù)據(jù)庫(kù)中與之最相似的向量,在犧牲可以接受的精度范圍內(nèi),加快檢索速度。近似最近鄰查詢方法主要分為兩類,一是基于哈希的方法,另一種是基于向量量化的方法。
基于哈希的方法是將數(shù)據(jù)映射到漢明空間,即通過(guò)哈希函數(shù),將向量x轉(zhuǎn)換成哈希碼(海明碼)b,通過(guò)二者哈希碼的漢明距離,度量?jī)蓚€(gè)數(shù)據(jù)點(diǎn)之間的相似度,即將距離dist(x1,x2)近似成哈希碼的距離dist(b1,b2)。基于哈希的研究方向主要是學(xué)習(xí)優(yōu)化哈希函數(shù)。隨著二進(jìn)制化后數(shù)據(jù)信息的減少,準(zhǔn)確性也隨之降低。為了解決這個(gè)問(wèn)題,近年來(lái)人們提出了各種基于向量量化的近似最近鄰搜索方法。
1.3 向量量化
向量量化(Vector Quantization)多被應(yīng)用在源編碼和信號(hào)壓縮方面[2]。向量量化是通過(guò)聚類方法,將向量集合聚類成多個(gè)類別,每一個(gè)類別里的向量都可以用其對(duì)應(yīng)的類中心近似代替。換句話說(shuō),就是用其中的一個(gè)有限子集編碼,表示一個(gè)向量數(shù)據(jù)空間中的向量。相對(duì)于需要存儲(chǔ)原始數(shù)據(jù)的向量方法,向量量化方法只需要存儲(chǔ)向量對(duì)應(yīng)的類中心(即碼元)的索引ID,大大減小了向量的存儲(chǔ)空間。另外,只根據(jù)聚類中心的ID去查找預(yù)先計(jì)算好的表格,其中存放著聚類中心與查詢向量的距離。向量的歐式距離可以通過(guò)編碼后碼元之間的距離來(lái)近似表示,減少了計(jì)算時(shí)間,使得查詢更加有效,提高了向量的檢索速度。
人們開(kāi)始重點(diǎn)關(guān)注將向量量化技術(shù)應(yīng)用到近似最近鄰搜索方向[3,5-11]。其中比較具有代表性的方法是乘積量化算法[3]。該算法的主要思想是,將高維的特征向量空間劃分成若干個(gè)低維的子空間,對(duì)每個(gè)低維子空間的子特征向量進(jìn)行量化,原始高維向量的量化結(jié)果就可以通過(guò)連接這些子特征向量量化后的編碼進(jìn)行表示。乘積量化是通過(guò)對(duì)每個(gè)子空間單獨(dú)量化,從而減小量化誤差。
乘積量化劃分子空間的基本假設(shè)是,不同子空間內(nèi)的向量分布是相互獨(dú)立的,不存在關(guān)聯(lián)。若子空間中數(shù)據(jù)分布之間的相關(guān)性很強(qiáng),則乘積量化的性能就會(huì)下降。在實(shí)際情況中,真實(shí)的數(shù)據(jù)分布并不滿足子空間相互獨(dú)立的假設(shè)。因此,考慮到數(shù)據(jù)的分布,從而對(duì)數(shù)據(jù)進(jìn)行更有效的量化。Juang和Gray等人提出了多階段向量量化(MSVQ)[4]。在數(shù)據(jù)原始維度下,通過(guò)多個(gè)低復(fù)雜度的量化器,保留每次量化產(chǎn)生的誤差,然后繼續(xù)量化誤差,使得量化誤差進(jìn)一步減小,從而提高近似最近鄰檢索方法的精度。
2 多階段向量量化
多階段向量量化方法和傳統(tǒng)的向量量化方法不同,它并不是拋棄量化誤差,而是保留量化誤差,將其作為余差向量,進(jìn)一步量化,從而減小量化誤差。為了減少計(jì)算和存儲(chǔ),MSVQ是使用幾個(gè)階段的碼本,按順序(即逐階段)進(jìn)行量化,之后連接每個(gè)階段的量化結(jié)果表示輸入向量。
多階段向量量化是在原始高維空間上處理向量,通過(guò)多個(gè)低復(fù)雜度的量化器,由粗到細(xì)的量化向量,每一個(gè)階段的輸出是上一階段量化產(chǎn)生的余差向量,將其作為下一階段的輸入再進(jìn)行量化。有序的將每一階段的量化器串聯(lián)起來(lái),每一階段對(duì)應(yīng)著一個(gè)由k-means聚類算法得到的碼本。
在訓(xùn)練階段,通過(guò)在訓(xùn)練集X上進(jìn)行k-means聚類,得到第一階段的碼本C1,將X在第一階段碼本上進(jìn)行量化,得到其在C1對(duì)應(yīng)的碼元向量。第一階段量化器的輸出,即為X與其量化后碼元向量的余差R1;R1作為第二階段量化器的輸入,在其上進(jìn)行k-means聚類,得到第二階段的碼本C2。將R1在第二階段的碼本上進(jìn)行量化,得到其在C2對(duì)應(yīng)的碼元向量,第二階段量化器的輸出即R1與其量化后對(duì)應(yīng)的碼元向量的余差R2。
上述過(guò)程將持續(xù)至得到M個(gè)碼本,即C=[C1,C2,…CM]。因此,原始向量可以表示為:

其中,Bi為碼元索引,RM為第M階段的余差向量,即全局量化誤差。
2.1 向量的編碼和解碼
在編碼階段,只需要存儲(chǔ)向量對(duì)應(yīng)的類中心的索引ID。因此給定數(shù)據(jù)集向量X和碼本C1,C2,…,CM,在對(duì)應(yīng)階段碼本里尋找使得當(dāng)前階段編碼誤差Ei最小的碼元向量,即與當(dāng)前所要量化的向量距離最近的碼元向量,其對(duì)應(yīng)的索引I D為Bi,也稱為向量的編碼。原向量即可表示為:
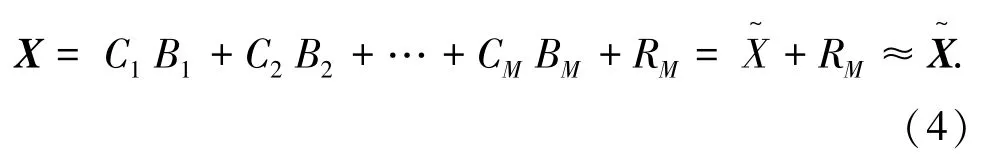
最后一階段的編碼誤差E可以忽略不計(jì):
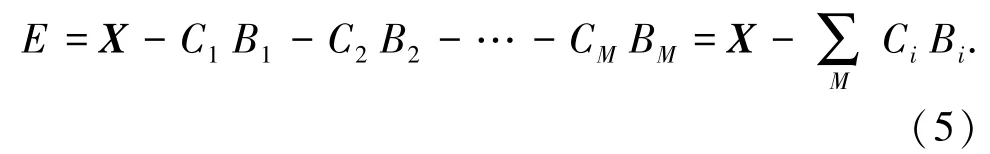
因此,多階段向量量化算法可以根據(jù)向量編碼近似地還原出原始向量,即重構(gòu)向量可以表示為所有階段對(duì)應(yīng)的碼元向量之和。假設(shè)向量X的編碼為[B1,B2,...,BM]∈{1,2,...,K},通過(guò)編碼找到其對(duì)應(yīng)階段碼本對(duì)應(yīng)的碼元向量,那么還原X的過(guò)程為:
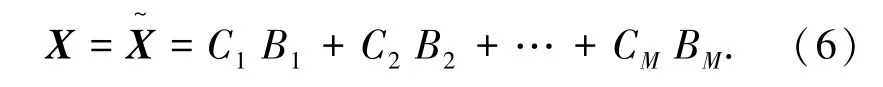
2.2 距離計(jì)算
在查詢過(guò)程中,數(shù)據(jù)庫(kù)中的特征向量通過(guò)量化進(jìn)行高效的壓縮存儲(chǔ),也需要從數(shù)據(jù)庫(kù)中盡快的查找到和查詢向量相匹配的最近壓縮向量。Jegou等人提出了兩種距離計(jì)算方法[3],分別是對(duì)稱距離計(jì)算(SDC)和非對(duì)稱距離計(jì)算(ADC)。
對(duì)稱距離計(jì)算需要將查詢向量x和數(shù)據(jù)庫(kù)向量y都進(jìn)行量化,得到q(x)和q(y)后計(jì)算二者之間的距離d(q(x),q(y)),即d(x,y)=d(q(x),q(y))。非對(duì)稱距離計(jì)算,只對(duì)數(shù)據(jù)庫(kù)向量y進(jìn)行量化得到q(y),則x和y的距離d(x,y)就可以用查詢向量和量化后的數(shù)據(jù)庫(kù)向量之間的距離表示,即d(x,y)=d(x,q(y))。非對(duì)稱距離計(jì)算進(jìn)一步降低了量化誤差,因此本文采用非對(duì)稱距離計(jì)算。
查詢向量q與重構(gòu)向量的歐式距離為:

3 最小化均方誤差的多階段碼本訓(xùn)練
本章提出在多階段向量量化方法的訓(xùn)練碼本進(jìn)行改進(jìn),可減小量化誤差,提高量化精度,從而提高實(shí)驗(yàn)的召回率。
多階段向量量化方法在訓(xùn)練碼本過(guò)程中采用經(jīng)典的k-means聚類算法。其主要思想是將空間中的k個(gè)點(diǎn)作為聚類中心(質(zhì)心),進(jìn)行聚類過(guò)程,對(duì)與它們最相近的數(shù)據(jù)進(jìn)行歸類。通過(guò)迭代更新每個(gè)類別里的質(zhì)心的值,直至得到最好的聚類結(jié)果。雖然k-means聚類算法應(yīng)用廣泛,但也存在著一些缺點(diǎn):如,對(duì)噪音和異常點(diǎn)十分敏感。在初始化時(shí),一般是隨機(jī)選擇初始的聚類中心,如果大多數(shù)聚類中心被分配到同一個(gè)簇中,那么聚類算法很有可能不會(huì)收斂。也就是說(shuō),初始聚類中心的選取會(huì)影響到聚類的收斂效果,導(dǎo)致影響最終的聚類結(jié)果。
為了避免初始聚類中心的選取影響聚類結(jié)果,本文提出最小化均方誤差的多階段碼本訓(xùn)練方法,盡可能地選擇相互之間距離較遠(yuǎn)的數(shù)據(jù)點(diǎn)作為聚類中心。通過(guò)優(yōu)化初始聚類中心,改善訓(xùn)練出的碼本質(zhì)量,從而減小向量的重構(gòu)誤差,提高檢索精度。具體實(shí)現(xiàn)步驟為:
(1)從數(shù)據(jù)集合的n個(gè)特征向量中隨機(jī)選取一個(gè)特征向量。
(2)從剩余的n-1個(gè)特征向量中按照一定概率選取聚類中心xj∈X,作為下一個(gè)聚類中心。該概率策略是數(shù)據(jù)點(diǎn)距離所有的聚類中心越遠(yuǎn),其被選取的概率越大,反之,其被選取到的概率越小。
(3)依次進(jìn)行上述過(guò)程,直至得到k個(gè)聚類中心。
初始的聚類中心的選取原則是:令其相互之間的距離要盡可能的遠(yuǎn),逐個(gè)選取k個(gè)聚類中心,距離其它聚類中心越遠(yuǎn)的數(shù)據(jù)點(diǎn),被選作下一個(gè)聚類中心的概率越大。
本文將上述方法應(yīng)用到多階段向量量化方法的訓(xùn)練碼本過(guò)程中,該方法以最小化均方誤差(Mean-Square Error,MSE)為目標(biāo),使得向量量化后的重構(gòu)向量更精確。最小化均方誤差計(jì)算如式(8)所示:
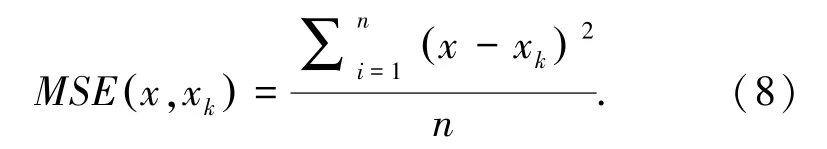
4 實(shí)驗(yàn)結(jié)果與分析
實(shí)驗(yàn)選用近似最近鄰搜索最常用的一個(gè)公開(kāi)數(shù)據(jù)集來(lái)進(jìn)行實(shí)驗(yàn)性能評(píng)估,即SIFT1M數(shù)據(jù)集[3]。數(shù)據(jù)集包含3個(gè)子集:訓(xùn)練集、數(shù)據(jù)庫(kù)集、查詢集。SIFT1M中的訓(xùn)練數(shù)據(jù)集是從Flicker圖片[12]分享網(wǎng)站上公開(kāi)圖像數(shù)據(jù)中提取的局部特征描述符,其數(shù)據(jù)集中的每一個(gè)特征向量都是128維;樣本數(shù)據(jù)集和查詢數(shù)據(jù)集是由INRIA Holidays[12]數(shù)據(jù)庫(kù)中的圖像數(shù)據(jù)提取的特征描述符。訓(xùn)練數(shù)據(jù)集用于訓(xùn)練學(xué)習(xí)得到碼本,樣本數(shù)據(jù)集和查詢數(shù)據(jù)集用于評(píng)估最近鄰搜索的性能。本文主要采用召回率R1@100作為性能指標(biāo),即查詢準(zhǔn)確率,表示在查詢階段查詢到的向量與驗(yàn)證數(shù)據(jù)集中的前100個(gè)做對(duì)比得到的結(jié)果。數(shù)據(jù)集具體信息見(jiàn)表1。
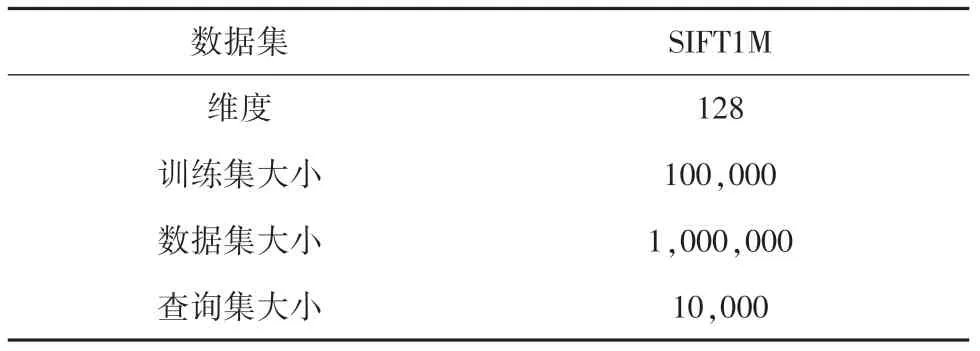
表1 SIFT1M數(shù)據(jù)集Tab.1 SIFT1M dataset
實(shí)驗(yàn)設(shè)置碼本數(shù)目為6,7,8,9,聚類中心數(shù)目K為16,64,256。SIFT1M數(shù)據(jù)集上的碼本數(shù)目-均方誤差的實(shí)驗(yàn)曲線如圖1所示。可以看出,本文提出的最小化均方誤差多階段碼本訓(xùn)練方法曲線(IMSVQ),始終保持在多階段向量量化方法曲線(MSVQ)的下方。表明本文方法可以進(jìn)一步降低向量編碼的量化誤差,使得向量量化更精確。
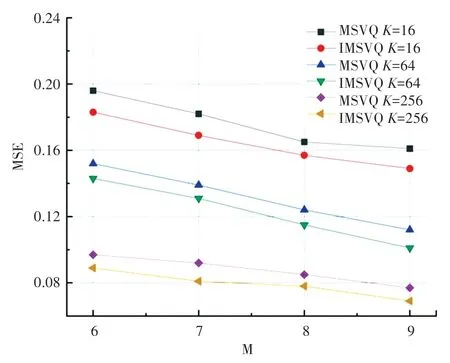
圖1 碼本數(shù)目-均方誤差(SIFT1M)Fig.1 M-MSE(SIFT1M)
由于碼本數(shù)目和碼本中聚類中心數(shù)目是影響實(shí)驗(yàn)的重要因素。通過(guò)實(shí)驗(yàn)可以看出,在碼本聚類中心數(shù)目保持不變的情況下,隨著碼本數(shù)目的增加,向量編碼的均方誤差逐漸降低。在碼本數(shù)目保持不變的情況下,隨著碼本聚類中心數(shù)目的增加,向量編碼的量化誤差逐漸降低。因此選取合適的碼本數(shù)目和碼本中聚類中心數(shù)目可以提高實(shí)驗(yàn)性能。
SIFT1M數(shù)據(jù)集上的實(shí)驗(yàn)迭代次數(shù)-召回率曲線如圖2所示。實(shí)驗(yàn)結(jié)果表明,在不同迭代次數(shù)下,本文提出的最小化均方誤差的多階段碼本訓(xùn)練方法,性能優(yōu)于多階段向量量化方法。隨著實(shí)驗(yàn)迭代次數(shù)的增加,從整體上看實(shí)驗(yàn)召回率逐漸增加。最小化均方誤差的訓(xùn)練碼本方法實(shí)驗(yàn)曲線始終保持在多階段向量量化方法曲線上方,表明本文提出的方法可以有效地提高實(shí)驗(yàn)召回率。圖3是在SIFT1M數(shù)據(jù)集上的碼本數(shù)目-召回率曲線。可以看出,優(yōu)化初始聚類中心后的方法召回率高于多階段向量量化方法。
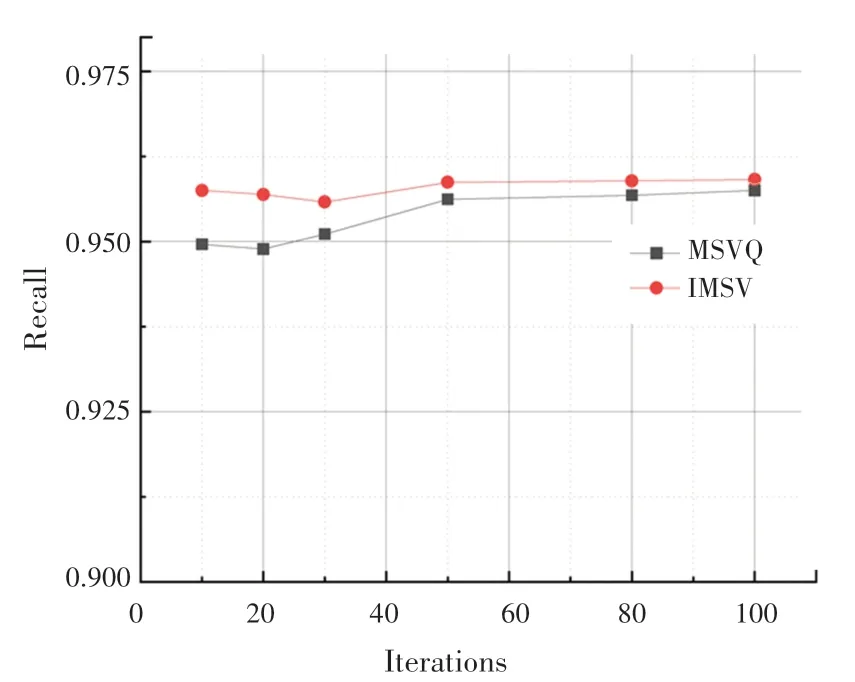
圖2 迭代次數(shù)-召回率(SIFT1M)Fig.2 Iterations-Recall(SIFT1M)
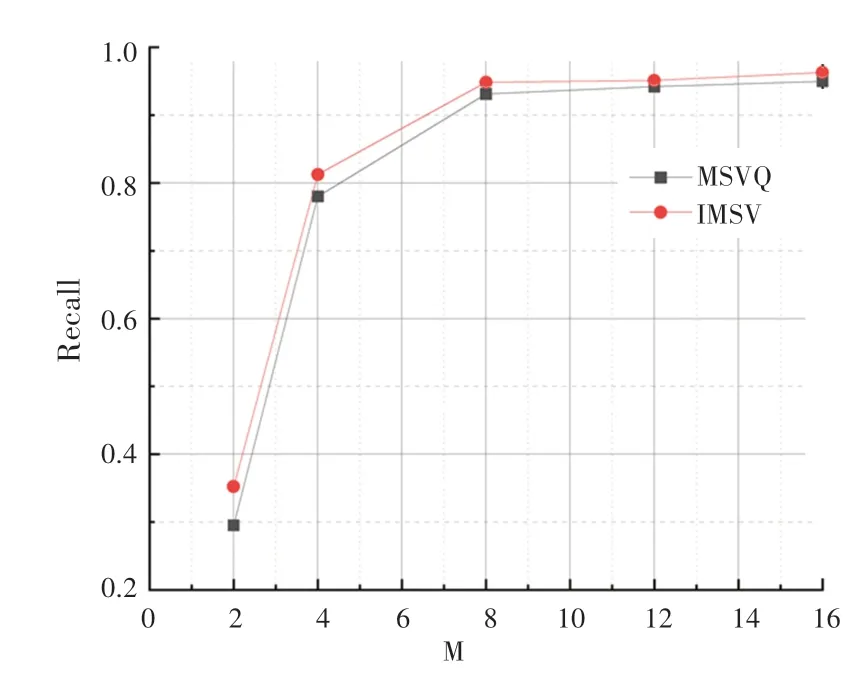
圖3 碼本數(shù)目-召回率(SIFT1M)Fig.3 M-Recall(SIFT1M)
綜上所述,優(yōu)化初始聚類中心,可以減小向量的量化誤差,從而提高查詢的召回率,證明本文提出的最小化均方誤差的多階段訓(xùn)練碼本方法具有可行性和有效性。
5 結(jié)束語(yǔ)
本文在多階段向量量化方法的訓(xùn)練碼本過(guò)程中,提出了一種新的碼本訓(xùn)練方法。原始訓(xùn)練碼本的方法通過(guò)隨機(jī)選擇初始聚類中心,導(dǎo)致大多數(shù)聚類中心被分配到同一個(gè)類別中,向量量化后的重構(gòu)向量不夠精確,與原始向量相比誤差較大,影響訓(xùn)練得到碼本的質(zhì)量。因此,為了減小隨機(jī)選取初始聚類中心對(duì)訓(xùn)練得到碼本質(zhì)量產(chǎn)生的影響,本文采取選擇距離較遠(yuǎn)的數(shù)據(jù)點(diǎn)原則,各個(gè)類別中的聚類中心差異度明顯。以最小化均方誤差為目標(biāo),通過(guò)優(yōu)化初始聚類中心,減小向量編碼的量化誤差,有效地提高了聚類結(jié)果的準(zhǔn)確性。通過(guò)在公開(kāi)數(shù)據(jù)集SIFT1M上的實(shí)驗(yàn)結(jié)果表明,在近似最近鄰搜索應(yīng)用中,本文提出的最小化均方誤差多階段碼本訓(xùn)練方法優(yōu)于多階段向量量化方法,可以進(jìn)一步地減小向量編碼的量化誤差,提高查詢精度,證明了該方法的可行性和有效性。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫(huà)報(bào)(2021年2期)2021-05-25 02:07:46
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫(huà)報(bào)(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
