基于Q 學習的無人機輔助WSN 數據采集軌跡規劃
2021-04-29 03:21:14蔣寶慶陳宏濱
計算機工程 2021年4期
關鍵詞:規劃
蔣寶慶,陳宏濱
(桂林電子科技大學信息與通信學院,廣西桂林 541004)
0 概述
無線傳感器網絡(Wireless Sensor Network,WSN)是傳感器、計算機、無線通信及微系統等技術發展融合的產物[1],是物聯網的基礎技術之一[2],其由大量廉價微型傳感節點組成,通過使用相互連接的智能傳感器來感知和監控環境。無線傳感器網絡應用范圍廣泛,包括環境監測、工業監測、交通監測等各個方面。由于傳感器的大數據環境和大規模無線傳感器網絡的出現,因此亟需新的節能數據采集技術。目前,無線傳感器網絡的數據采集方法主要集中在移動數據采集器和匯聚技術方面。隨著智能城市、智能家居等概念的提出,無線傳感器網絡被認為是智能環境的核心技術。無線傳感器網絡能夠以智能通信的方式交互建立一個智能網絡,從而產生一個能夠處理用戶隨機需求的應用系統。傳統的無線傳感器網絡結構大多由靜態節點組成,這些節點密集地分布在傳感器區域內。近年來,人們提出了多種基于移動收集器的無線傳感器網絡結構,利用移動性來解決無線傳感器網絡中的數據收集問題,其中,無人機(Unmanned Aerial Vehicle,UAV)具有高機動性、靈活、可達視距點和成本低等特點。由于下一代無線通信領域將網絡部署從地面轉移到空中,因此無人機被廣泛用作匯聚節點與基站之間的通信樞紐[3]。
然而,無線傳感器網絡的移動性也帶來了靜態無線傳感器網絡中不存在的一些問題。文獻[4]指出其面臨的挑戰有感知偵查、喚醒-休眠機制、傳輸可靠性和移動控制,其中,移動控制指的是當移動收集器的運動可控制時,必須設計訪問網絡節點的策略,因此,必須定義移動節點的路徑和停留時間,使網絡性能達到最高。一般而言,軌跡規劃分為兩類:一類是靜態軌跡規劃,針對不隨時間變化的軌跡;另一類是動態軌跡規劃,指為滿足數據采集的某些特定條件(例如實時性),能夠隨時間變化而改變自己下一步軌跡的規劃。
本文根據無線傳感器網絡的移動性,提出非連續無人機軌跡規劃算法Q-TDUD。考慮無人機輔助無線傳感器網絡數據采集的場景,通過相關工作的對比,針對數據采集中各節點數據率隨機的問題建立相應的延時模型和能耗模型。在此基礎上,結合Q 學習算法設置合適的獎勵制度并對場景中的無人機進行迭代訓練,使其能夠智能地根據場景狀態的變化做出相應的軌跡調整。
1 相關工作
多數從靜態軌跡規劃角度出發設計的無人機飛行策略未考慮無人機自身能耗與飛行軌跡之間的關系,因此,本文主要關注動態軌跡規劃方面的研究。文獻[5]證明了無論是速度最大化還是能耗最小化的軌跡規劃都不是最優的方案,一般而言,軌跡規劃需要在這兩個目標之間達到最佳的平衡。文獻[6]提出空對地無線通信的基本能量權衡問題,推導出無人機和地面終端的能量消耗表達式,得到了兩者之間權衡后的最優地面終端發射功率和無人機軌跡。文獻[7]聯合優化傳感器節點喚醒機制和無人機軌跡規劃機制,在最小化所有傳感器節點最大能耗的同時確保每個傳感器數據的可靠傳輸。文獻[8]研究無人機對傳感器進行充電的軌跡規劃問題,討論總能量最大化引起的遠近公平問題,進而提出一種最優航跡驅動的連續式盤旋航跡方法。文獻[9]研究無人機組播系統,提出一種基于虛擬基站布局的新概念和凸優化的路徑設計方法。
上述工作均為連續式的無人機軌跡規劃研究,即在無人機執行任務之前計算出飛行軌跡,按照該軌跡規劃結果連續式飛行直至任務結束。然而,連續式無人機的飛行軌跡規劃無法滿足實際應用場景中數據收集的可靠性和有效性要求。只有當無人機進入匯聚節點感知范圍且匯聚節點完成數據匯集時,無人機才對匯聚節點進行感知,這會造成不必要的能量消耗及數據采集延遲。對此,一些研究者提出非連續無人機軌跡規劃。文獻[10]針對單無人機給多地面用戶進行充電的問題,提出一種基于遺傳算法的非連續飛行方案,迭代搜索出最優懸停點并優化相應的懸停時間。文獻[11]運用機器學習領域的相關知識,利用認知代理在無線傳感器網絡中建立基于學習、推理和信息共享的主動學習決策,使無人機能夠在多個約束中智能地選擇執行懸停或者飛行策略,得到非連續無人機飛行軌跡。文獻[12]提出一種改進的多無人機Q 學習算法來解決分散的無人機軌跡規劃問題,同時計算使用嵌套馬爾科夫鏈得到的有效數據傳輸概率。文獻[13]研究用戶端信息(如位置、發射功率、信道參數等)無法訪問情況下的上行速率之和最大化問題,將該問題描述為一個馬爾科夫決策過程(Markov Decision Process,MDP),通過無模型強化學習來解決,同時由實驗結果表明,無人機能在未知用戶側信息和信道參數的情況下,根據所學習的軌跡對地面用戶進行智能跟蹤。
為優化無人機的能耗及無線傳感器網絡的數據采集效率,上述工作主要從無人機的飛行能耗和懸停能耗以及數據傳輸的信道分配來進行問題建模,但沒有考慮到負責接收和發送數據的匯聚節點存在匯聚完成時間不一致及數據量大小不一致的問題,忽略了實際應用中節點數據產生速率隨機性的影響。在進行無人機軌跡規劃時,懸停點順序及懸停時間應得到進一步優化。由于強化學習中的Q 學習具有單步獎勵機制和離線學習等特點,其能將懸停動作加入無人機動作集中,通過一定次數的迭代得到最優飛行策略,優化懸停點順序和懸停時間,因此對于合理規劃無人機軌跡、保證有效數據率較高且提高能量效率的問題,可以結合強化學習理論進行分析。
本文考慮節點數據產生速率的隨機性以及非連續無人機輔助數據采集的應用場景,提出一種基于Q 學習的非連續無人機軌跡規劃算法Q-TDUD。在建立匯聚節點時,利用基于距離的K-means 算法對網絡中節點分簇并確定匯聚節點,根據傳感器網絡中單個節點在周期內的數據速率改變概率以及單位數據量和單位距離轉發數據的延遲時間,構建匯聚節點的延遲差異模型。在規劃非連續無人機軌跡時,將無人機軌跡設計整體細分為離散馬爾科夫過程[14],并應用強化學習[15]中的Q 學習算法來優化無人機的飛行軌跡。在無線傳感器網絡數據收集過程中,將無人機的位置和運動方向作為強化學習中的狀態集和動作集。在每次執行某個策略后,收到的匯聚節點的反饋將被用作更新Q 表的即時獎勵,通過獎勵對Q 表進行更新,從而確定無人機在每個狀態的下一步策略。重復該過程直至找到最佳飛行軌跡。不同于現有多數無人機輔助數據采集的軌跡規劃研究,本文考慮各簇規模不一致導致相應匯聚節點匯聚完成時間不一致的情況,設置延遲容忍時間來約束無人機數據采集任務的完成效率,提出非連續無人機軌跡規劃問題,并利用Q 學習中的獎勵機制設置兩種獎勵方式,使無人機能夠智能地選擇自己的懸停狀態或飛行狀態,將傳統的連續式無人機飛行軌跡規劃轉換為非連續的軌跡規劃。
2 系統模型
2.1 延時模型
無線傳感器網絡由大量傳感器節點和少量執行器節點構成,其應用涵蓋廣泛,從工業過程的自動化到系統的通風量和溫度控制等均有所涉及[16]。在無線傳感器網絡中,傳感器節點負責從物理世界收集信息,執行器節點負責根據信息做出獨立的判斷,并執行相應的任務[17-19],傳感器節點一旦部署完成,不再移動或者改變。
本文將n個靜態傳感器節點X={x1,x2,…,xn}隨機均勻地部署在大小為W的網絡范圍內,初始化單個節點的數據生成速率為Va。無人機有能量損耗速度快、自身儲能小和工作時長短等缺點,若遍歷網絡中的每一個節點進行數據采集,則采集時間過長,會出現部分節點的緩存區數據溢出或無人機自身能耗不足導致任務終止等情況。因此,本文將節點組織成簇,在簇中選出匯聚節點負責接收簇內各節點的數據并與無人機進行數據交互,以提高網絡的擴展性和節點能量的利用率。此處使用K-means 聚類算法[20]對隨機均勻分布的節點進行分簇,得到包含k個簇的集合C={c1,c2,…,ck},其中每個簇的簇成員個數為cn(k),匯聚節點位置表示為,k∈{1,2,…,m},匯聚節點的最大緩存數據量為Dmax。圖1 為傳感器網絡節點數量為30、分簇個數為4 時的節點分簇示意圖,將各簇分別用4 種不同的顏色表示(彩色效果見《計算機工程》官網HTML 版),其中,黑色點表示匯聚節點,是距離各簇質心最近的節點。
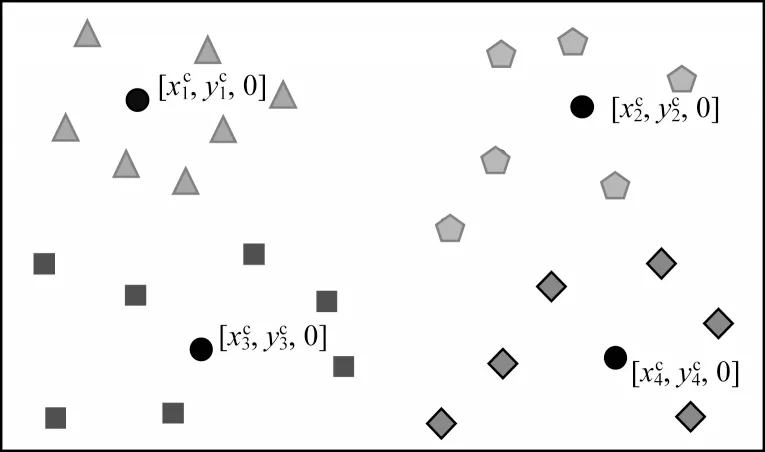
圖1 K-means 分簇結果(k=4,n=30)Fig.1 K-means clustering result(k=4,n=30)
在簇成員向匯聚節點進行數據轉發的路由選擇上,本文考慮分級多跳路由的方式[21]。分級多跳路由的核心思想是劃分節點之間的優先級,首先計算出簇成員節點到匯聚節點的距離,然后根據其距離將簇成員節點由近及遠劃分為3 個等級。數據轉發規則為節點數據只能由較遠的低級節點發送給較近的高級節點,不可跨級上傳。簇內路由的系統模型如圖2 所示,圖中心的黑色點為該簇的匯聚節點,淺灰色點為一級轉發節點,深灰色點為二級中間節點,白色點為三級邊緣節點。當開始數據匯集時,簇成員節點通過多跳的方式將數據轉發至匯聚節點進行數據匯集。
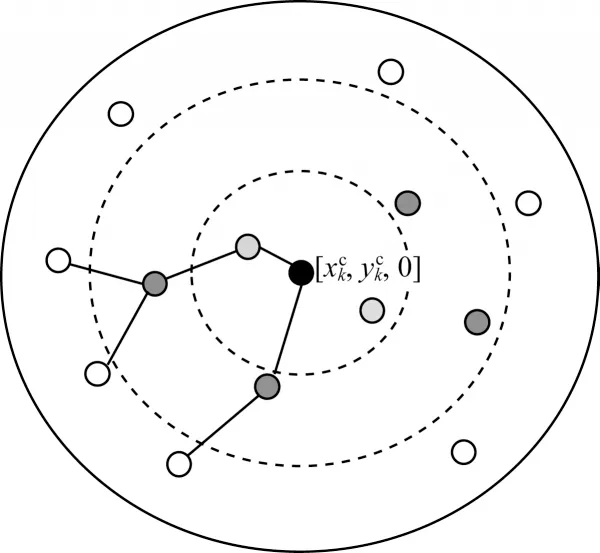
圖2 簇內路由Fig.2 Routing within the cluster
對于傳感器節點而言,需要考慮采集數據量和能量消耗之間的折中。處于網絡區域邊緣的節點只需要將收集的數據發送給移動采集器,能量消耗相對較少,而靠近匯聚中心的節點同時還需要為邊緣節點轉發數據,消耗的能量較多。因此,邊緣節點必須對采集到的數據進行一定的壓縮和融合處理后再發送給下一跳節點。數據融合機制減少了需要傳輸的數據量,能夠減輕網絡的傳輸擁塞,降低數據的傳輸延遲,在一定程度上提高網絡收集數據的整體效率。用Dk表示匯聚周期Tv內匯聚節點的數據量,用Pn表示節點的數據產生速率在一個匯聚周期Tv內發生改變的概率,用Pc表示邊緣節點的數據融合率,則根據文獻[21]中對簇頭節點匯集數據量的計算方式,在匯聚周期Tv內各簇的數據量為:

在實際應用中,人們希望無人機的單次采集效率最大化。考慮到無線傳感器節點監測環境的不確定性以及無人機能耗特性的約束,需要設置匯聚節點的最小數據量大小,使得當匯聚節點只有在匯聚數據量大小達到規定時,無人機才將此匯聚節點考慮至軌跡規劃內,若匯聚節點在時隙t未達到最小數據量,則產生匯聚延時。本文通過設立延時機制來提高無人機的單次采集效率。用Ds表示匯聚節點最小數據量,若改變量為?Va,則Va+?Va∈[Vamin,Vamax],其中,Vamin為節點最小數據產生速率,Vamax為節點最大數據產生速率。此時可以計算得到匯聚節點的延時為:
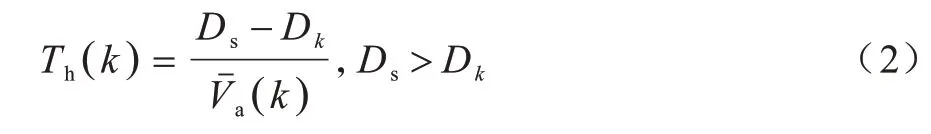
(k)為簇k的平均數據生成率,表示為:
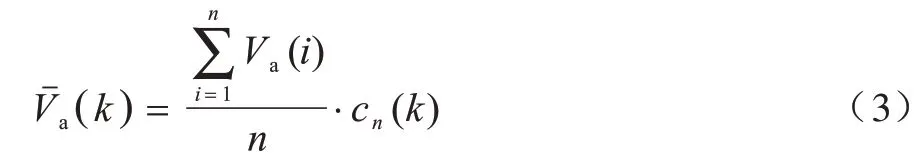
2.2 能耗模型
考慮到在節點度、最大時間延遲等條件相同的情況下,移動采集器的軌跡長度與傳感器網絡中節點的總跳數成反比[22],若聯合考慮無人機與傳感器網絡的總能耗,當改變網絡拓撲使傳感器網絡節點之間數據傳輸達到最小時,會一定程度忽略無人機的路徑復雜度,使無人機飛行能耗增加,從而系統中的能耗無法達到最優。因此,本文主要考慮無人機的能耗。
如圖3 所示,無線傳感器網絡中的匯聚節點負責接收和處理從子節點多跳上傳來的數據,無人機在空中作為一個移動采集器對地面上k個匯聚節點進行數據采集。
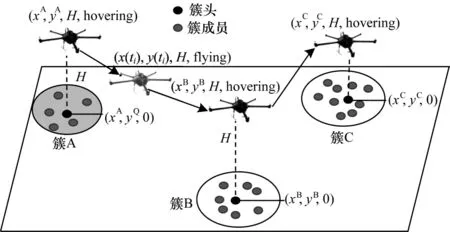
圖3 無人機采集無線傳感器網絡數據的場景Fig.3 A scene where UAVs collect data in WSN
將無人機采集數據的總過程分為T個時隙,以便于迭代推導。假設無人機以恒定速度VUAV飛行在固定高度H上空。每個時隙無人機的位置為U={U1,U2,…,UT}。其中,Ut=[xu(t) ,yu(t) ,H]。由于無人機的計算能耗與飛行能耗相比較小,因此可忽略不計。另一方面,本文將無人機完成收集所有匯聚節點數據的任務作為一輪。在每一輪開始時,各匯聚節點的匯聚延時會隨著各簇成員節點數據生成速率的更新而更新,因此,在每輪無人機開始采集數據到完成采集的過程中,各匯聚節點的數據量大小是固定的。又因為無人機只有進入匯聚節點的感知范圍r時才會與該節點進行數據傳輸,保證了通信信道較大的穩定性和較小的差異性,所以本文忽略無人機與各匯聚節點之間的數據傳輸能耗。因此,在保證無人機采集效率的同時提高無人機的能量效率,是優化軌跡性能的關鍵。設ph為無人機的懸停功率,d(t)為一個時間間隙內無人機飛行距離,則無人機懸停能耗Eh和飛行能耗Ef表示為:
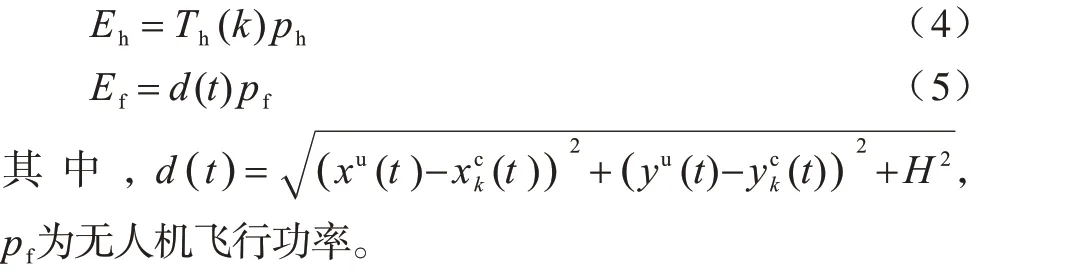
由于無人機在飛行過程中加入了懸停策略,會出現某些匯聚節點數據匯集完成但是無人機尚未進入其采集范圍的現象,這使得匯聚節點進入等待時間易造成數據丟失及緩存溢出的情況,從而無人機后續的數據采集將變得毫無意義,因此有必要設置一個等待時間閾值來約束等待時間過長的情況。根據傳感器緩沖內存限制及數據匯集的實時性要求,本文規定當無人機在時隙t內與匯聚節點k進行數據采集時,若匯聚節點k的等待時間Tw(k)≤γ,則無人機采集的數據為有效數據,Tw(k)=Th(k) -t。若不在此等待閾值范圍內,則將此數據稱為無效數據。等待閾值γ定義為:
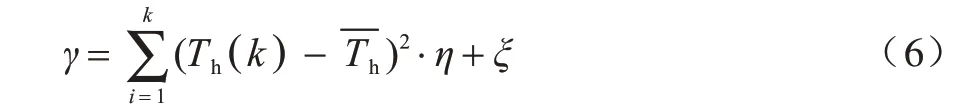
其中,為平均延遲時間,η、ξ為常數參數。
3 Q-TDUD 算法描述
在無人機軌跡規劃中,無人機的能量消耗及通信質量等問題始終是研究者的關注重點。上節已求解出無人機的飛行能耗和懸停能耗,下節將解決在保證無人機與傳感器之間上行鏈路傳輸穩定的同時使無人機整體能耗最小的問題。本文考慮每架無人機的效用為其任務成功采集有效數據總量,因此,可以通過設計非連續無人機的軌跡來最大化有效數據總量。
本節將給出非連續無人機的軌跡規劃,最大化總傳輸速率和能量消耗的比值。考慮速度的約束,將其建模為如下最優化問題:
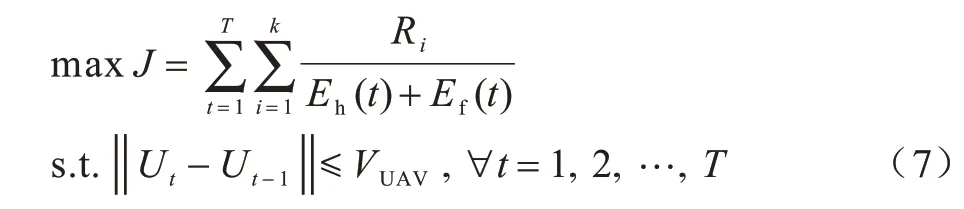
Ri表示CN(i)的傳輸速率,如式(8)所示:
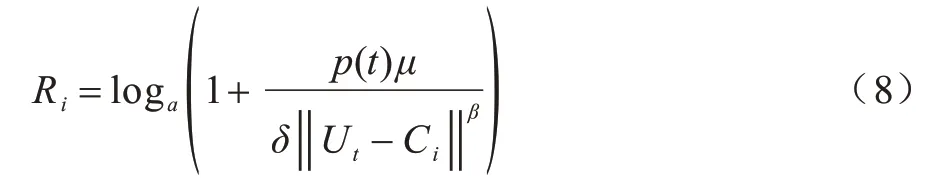
其中,μ表示信道增益,β表示距離衰減,Ci表示匯聚節點所在位置,δ表示信道噪聲功率。
由于優化問題是非凸的,全局最優軌跡很難找到,并且在無人機未知匯聚節點位置信息的情況下,只有在多次執行采集操作后才能觀察到能耗及有效數據的收集情況,因此本文基于強化學習確定無人機每個狀態的動作執行策略來解決式(7)所示的問題。Q 學習算法是強化學習中基于值函數的算法,對任何有限的馬爾科夫決策過程,Q 學習都可以找到一種最優策略。Q 學習涉及一個代理(agent)、一組狀態S以及一組動作A。通過在環境中執行動作使得代理從一個狀態轉移到另一個狀態,在特定狀態下執行動作會提供獎勵。簡單來說,Q(s,a) 為某一時刻s狀態下(s∈S),采取動作a(a∈A) 能夠獲得的獎勵期望。環境會根據代理選擇的動作反饋相應的獎勵r,因此,Q-TDUD 算法的主要設計思想是以狀態s與動作a構建成一張Q 表來存儲Q值,最后根據Q值來選取能夠獲得最大獎勵的動作。在非連續無人機軌跡規劃中,將無人機在各時隙的位置信息設置為Q 學習中的狀態集,再將懸停態加入無人機的動作集之中,構建一個關于無人機當前位置狀態和動作的Q 表。在算法的迭代過程中,環境根據下一個狀態s,中選取的最大Q(s,,a,) 值乘以獎勵衰變系數,再加上真實獎勵值計算得到Q的現實值Q,(s,a):

其中,γ為獎勵性衰變系數,γ越接近1 代表它越有遠見會著重考慮后續狀態的價值。當γ接近0 時會著重考慮當前的利益影響,r為當前行為獎勵,Q(s,,a,)為下一狀態中的最大Q值。
根據以上推導可以對Q值進行計算,即對Q 表進行更新。假設學習率為α,采用時間差分的方法進行更新,則更新后的Q值為:
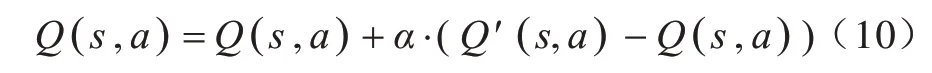
Q 學習的最大目標是求出累計獎勵最大策略的期望。接下來需要明確學習環境、狀態集、動作集、獎勵設置以及Q 表的更新過程[23]。
1)環境。單架無人機從固定起點飛行,向通信半徑范圍內的節點廣播數據包。在每個周期開始時,匯聚節點更新其數據量大小及數據匯集完成時間。無人機的位置為強化學習的狀態集,行為為動作集。在每輪采集開始時,無人機對地面匯聚節點的位置未知,但可通過接受各匯聚節點的反饋來獲取每個行為的好壞。
2)狀態集S={g1,g2,…,gx}。根據文獻[24]中的網格法使無人機的位置狀態離散化。將無人機需要采集的網絡區域劃分為x個網格{g1,g2,…,gx}。文獻[25]指出:網格粒度越小,節點位置及無人機狀態表示會越精確,但同時會占用大量的存儲空間,算法的搜索范圍將按指數增大;網格粒度太大,規劃的軌跡會很不精確。因此,此處的x與傳感區域大小及VUAV如式(11)所示:

其中,W為傳感區域大小,λ為常數參數。在每次無人機改變位置狀態后將對其位置進行判定,劃分到所屬的狀態集,以便于Q 表的更新。
4)獎勵。獎勵機制分為懸停優先和非懸停優先兩種情況。第1 種是懸停優先的情況,忽略無人機與匯聚節點進行數據采集所耗費的時間,若當前位置狀態下無人機到延時最小的匯聚節點的飛行時間小于該節點的延遲時間時,即tf<minTk,無人機動作獎勵為懸停優先,其中,tf為無人機到最小延時節點的預估時間,當δ=1 時懸停動作獎勵為r=rh,其他動作獎勵為0。第2 種是非懸停優先的情況,若tf≥minTk,不滿足第1 種獎勵情況,則為非懸停優先。兩種情況的獎勵設置為:

當δ=0 時,使當下無人機狀態的各匯聚節點完成時間序列{T1(t),T2(t),…,Tl(t)},根據文獻[26]方法進行歸一化處理得到{s1(t),s2(t),…,sl(t)},便于獎勵的計算。筆者希望無人機朝著延時最小的節點且傳輸數據較大的方向飛行,因此:

當選擇的動作a 使無人機與簇頭i的距離減小時,τ=1。
Q-TDUD 算法的偽代碼如算法1 所示。其中:第1 行初始化了無人機的位置、地面靜態節點的位置以及動作集和Q 表;第2 行~第3 行規定了無人機的總采集輪數,每輪開始前要更新無人機的位置坐標和匯聚節點的延時;第4 行對無人機是否對所有的匯聚節點執行完采集任務的判定,若還有節點尚未采集則程序仍然往下執行,S是每次循環開始時程序根據無人機當下位置坐標判斷得到的狀態集中的狀態;第5 行進行動作選擇。為使結果更具非偶然性,在確定選擇動作的策略時設置一個冒險概率ξ,這樣代理有一定機會不遵從Q 表中當前狀態的動作最大值來選擇動作,而是從剩余動作中隨機選擇一個動作執行,有效避免了代理陷入某個動作并反復執行所帶來的時間浪費;第6 行~第12 行是對Q 表的更新。在獎勵計算方面,根據上述的兩種獎勵機制,首先計算出當前tf與minTk的大小比較情況。若tf<minTk,進入第1 種懸停優先獎勵模式,此時的無人機如果執行的不是懸停動作,則獎勵為0;若tf≥minTk,則獎勵進入非懸停優先模式,如果此時無人機執行的不是最佳動作則無法獲得最大獎勵。算法第12 行將當前狀態的最大Q值動作的選擇策略設置為1,使下一輪代理在進行動作選擇時在不冒險的情況下得到最大Q值的動作選擇策略。
算法1Q-TDUD 算法

4 仿真與結果分析
本節將對比基于強化學習的無人機軌跡規劃的性能仿真結果,包括任務完成時間、有效數據率、有效數據收集以及有效數據和能耗之比。首先設置一個W=100 m×100 m 的正方形區域,在其中隨機均勻分布300 個節點,節點的分布情況及分簇多跳結果如圖4 和圖5 所示(彩色效果見《計算機工程》官網HTML 版)。圖4 中的黑色點為各簇的簇頭節點,圖5 展示了簇內節點的分級情況以及數據的多跳傳輸過程,圖中右下角圖案為六角星、右三角形、五角星的點分別為文獻[21]中簇內分級算法計算所得的三級、二級、一級節點,黑色的線段表示不同級別節點之間的數據傳輸路徑。
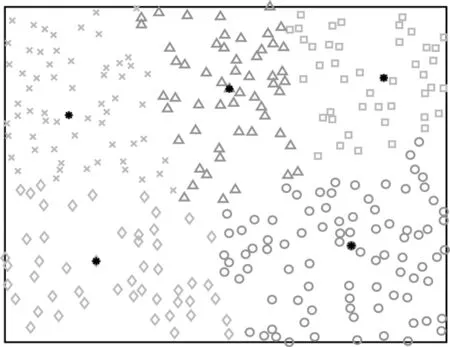
圖4 K-means 分簇結果Fig.4 K-means clustering result
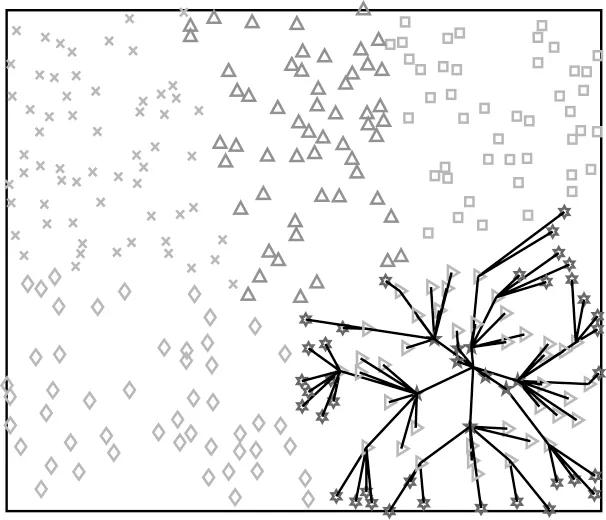
圖5 簇內節點分簇多跳結果Fig.5 Grading and multiple hops result within a cluster
基于上述網絡結構,設置節點初始數據產生速率Va=10bit/s,Vamin=5bit/s,Vamax=50bit/s。節點數據速率改變概率Pa=0.9,數據融合率Pc=0.8。Ds=5×104bit,Tv=3 s。無人機的初始位置為[50,50,H],H=5 m,懸停功率ph=50 w,飛行功率pf=75 w,飛行速率VUAV=6 m/s。延時模型參數為η=0.01,ξ=3,=1。
針對上文無線傳感器網絡節點部署,將Q-TDUD算法參數設置為ξ=0.2,β=2,p(t)=5 w,λ=0.057,ρ=0.3,學習率α=0.01,獎勵衰減系數γ=0.9,并與連續式最小旅行商軌跡規劃算法(TSP-continues)[27-28]、非連續最小旅行商算法(TSP)、連續式下一跳最短路徑規劃算法(NJS-continues)以及非連續下一跳最短路徑規劃算法(NJS)進行比較,Matlab 仿真結果如圖6~圖9 所示。TSP 方案的主要原理是先將網絡中的節點按照K-means 方法進行分簇并找到簇頭,簇成員節點按照前文介紹的文獻[21]簇內多跳方法將數據傳至簇頭,再用文獻[27]中蟻群求解TSP 問題的算法找出無人機經過全部簇頭的最優軌跡。NJS方案中的簇頭選取與簇內節點數據的多跳傳輸部分與Q-TDUD 一致,在無人機軌跡規劃上,簇頭節點將根據已被采集和未被采集兩種狀態分為兩個集合,在每輪采集中無人機基于當前的簇頭位置與未被采集集合的簇頭節點計算歐氏距離,距離最小的當選為無人機執行下一個采集任務的位置。TSP 與NJS方案又分為連續式和非連續式:連續式指的是無人機沒有懸停機制,若進入匯聚節點感知區域內但匯聚節點并沒有達到匯聚完成狀態時,無人機會繼續按照計劃軌跡行駛,直至將所有數據采集完畢;非連續是指當無人機按照計算出的軌跡行進至某個匯聚節點感知區域內時,若該節點尚未達到匯聚完成狀態,無人機會開啟懸停機制,懸停在感知區域內直到采集完該節點數據才執行下一個任務。
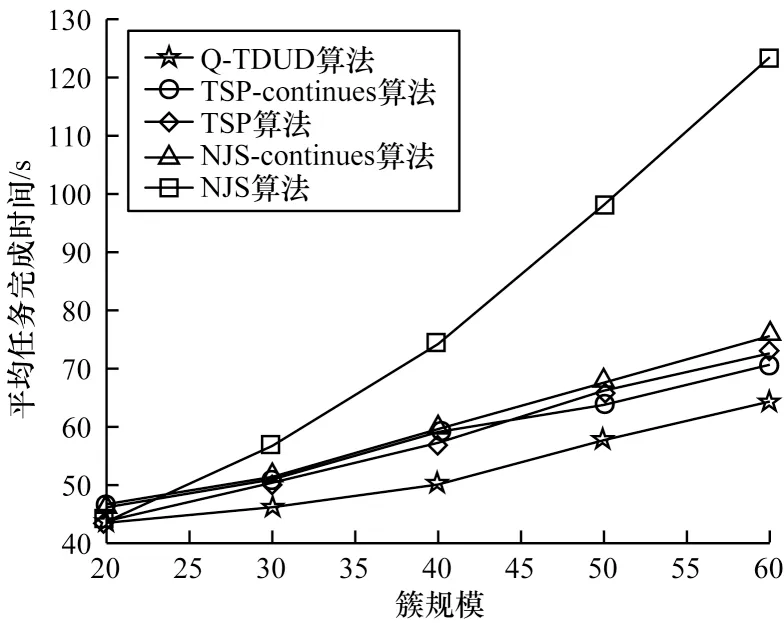
圖6 不同簇規模下的平均任務完成時間Fig.6 Average task completion times for different cluster sizes
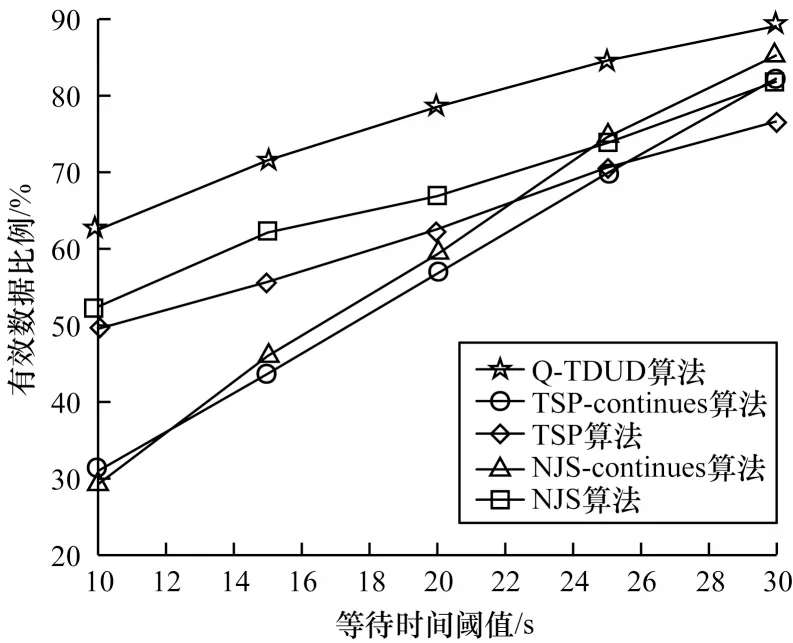
圖7 不同等待時間閾值下有效數據率Fig.7 Effective data rates at different waiting time thresholds

圖8 1 000 輪內有效數據收集情況Fig 8 Situation of the collection of valid data within 1 000 rounds

圖9 1 000 輪內有效數據和能耗比值Fig 9 Effective data and energy consumption ratio within 1 000 rounds
由圖6 可以看出,在網絡中不同的簇規模下,Q-TDUD 算法完成任務的時間比其他4 種算法完成任務的時間要小,這是因為Q-TDUD 算法考慮到了各匯聚節點的隨機性,優先對匯聚完成時間較小的節點執行數據采集任務,顯著降低了無人機完成數據采集任務的時間,使網絡負載更均衡。
等待時間閾值增大情況下各算法對應的有效數據率變化如圖7 所示。等待時間閾值根據式(4)計算得到,圖中的橫坐標分別是ξ=5,η={0.01, 0.015,0.025,0.03,0.035,0.045} 時計算得到的等待時間閾值。由于傳感器小巧輕便的外形設計,其數據緩存區大小受到相應限制,因此等待時間閾值的設置能夠揭示無人機是否能及時地執行數據采集任務。從結果圖中可以得出,當等待時間閾值增大時,各算法的有效數據比例在增大,但當等待時間閾值較小時,Q-TDUD 算法的性能明顯優于其他基準算法,這說明Q-TDUD 算法能使無人機及時地飛行至已完成數據匯集的節點上方采集數據,提高傳感器網絡的數據采集實時性。
各算法能量效率的比較如圖8 和圖9 所示。圖8顯示在η=0.01,ξ=3 的等待時間閾值下,各算法的有效數據量隨著循環次數增大而增加,其中Q-TDUD算法略高于其他基準算法,結合能耗情況來看,Q-TDUD 算法的能量效率明顯由于其他基準算法。圖9 中歸一化處理后的有效數據和能耗的比值也顯示Q-TDUD 算法性能更好。
5 結束語
針對無線傳感器網絡中各節點數據產生速率隨機和匯聚節點狀態不一致的場景,本文提出一種基于強化學習的無人機飛行軌跡規劃算法Q-TDUD。該算法采用強化學習的思想,根據無人機的數據傳輸速率和匯聚節點的反饋信息更新Q值,據此得到無人機當前狀態的下一步動作。無人機執行動作后會收到匯聚節點的反饋信息并用于Q 表的更新,經過迭代計算最終得到最佳無人機飛行軌跡。實驗結果表明,與連續式無人機軌跡規劃方案相比,非連續無人機軌跡規劃方案在收集的有效數據總量上約增加了1 倍,并且隨采集輪數的增加呈繼續增多的趨勢,在平均任務完成時間上也比連續式方案縮短近50%,更貼近無人機軌跡規劃中實時性這一設計要求。本文提出的單無人機輔助無線傳感器網絡的數據收集軌跡規劃方法較難適用于大規模無線傳感器網絡,因此,下一步將研究多無人機輔助數據收集的聯合軌跡規劃問題并設計相應求解算法。
猜你喜歡
房地產導刊(2021年6期)2021-07-22 09:12:46
中國石油石化(2021年9期)2021-07-17 09:24:00
中國農民合作社(2020年12期)2020-12-18 09:09:58
公民與法治(2020年11期)2020-07-25 02:02:06
河南水利年鑒(2020年0期)2020-06-09 05:43:30
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
制造技術與機床(2017年3期)2017-06-23 08:11:34
中國衛生(2016年2期)2016-11-12 13:22:16
華東科技(2016年10期)2016-11-11 06:17:41
